







深度学习中的编码器-解码器和Seq2Seq
“Encoder-Decoder和“Seq2Seq”之间的关系
Seq2Seq并不特指具体的方法,这个名词强调的是目的,以”输入序列,输出序列“为目的的,可以统称为Seq2Seq模型。Seq2Seq使用的具体方法基本上都在Encoder-Decoder框架的范围内。
- Seq2Seq属于Encoder-Decoder框架的范围内
- Seq2Seq这个名词(概念)强调的是目的,而Encoder-Decoder强调的是框架
Encoder-Decoder
Encoder-Decoder模型主要是NLP领域的一个概念。它不是一种特殊的算法,而是一类算法的总称,也就是一个通用的框架,可以使用不同的算法来解决不同的任务
Encoder-Decoder这个框架很好的诠释了机器学习中的核心思想
将现实世界中的问题转化为数学问题,并通过解决数学问题来解决现实世界的问题


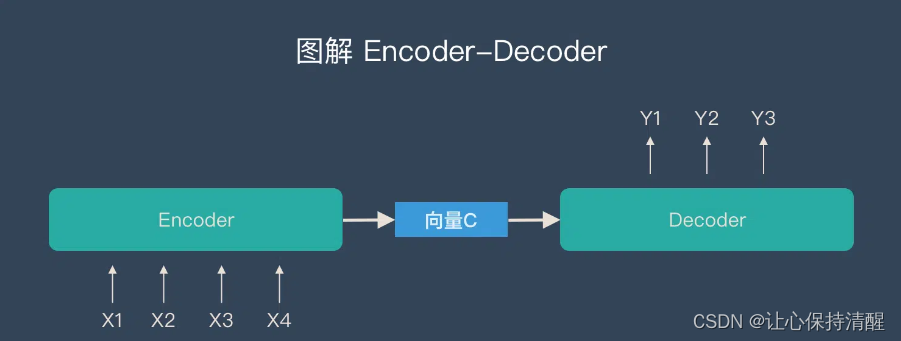
关于Encoder-Decoder,有两点需要说明:
1.不管输入和输出的长度如何,中间的”向量c“是固定的(这也是它的缺点,当输入太大时会丢失信息)
2.可以根据任务选择不同的编码器和解码器(比如RNN、LSTM、GRU等)
Seq2Seq
Seq2Seq(Sequence-to-sequence的缩写),顾名思义,就是输入一个序列,输出另一个序列。该结构最重要的方面是输入序列和输出序列的长度是可变的。比如下面这张图
 如上图:输入6个汉字,输出3个英文单词。输入和输出的长度不同。
如上图:输入6个汉字,输出3个英文单词。输入和输出的长度不同。
Seq2Seq的起源
在Seq2Seq框架提出之前,深度神经网络在图像分类等问题上取得了非常好的效果。在它擅长解决的问题中,输入和输出通常可以表示为固定长度的向量。如果长度稍有变化,则使用补零操作。
然而,许多重要的问题,如机器翻译、语音识别、自动对话等,都是按顺序表达的,它们的长度是事先无法得知的。因此,如何突破之前深度神经网络的限制,使其能够适应这些场景,成为了13年的研究热点,Seq2Seq框架应运而生。
编码器-解码器的应用
 机器翻译、对话机器人、诗歌生成、代码补全、文章摘要(文本-文本)
机器翻译、对话机器人、诗歌生成、代码补全、文章摘要(文本-文本)
编码器-解码器的缺陷
如上所述:Encoder和Decoder之间只有一个“向量c”来传递信息,并且c的长度是固定的。
为了便于理解,我们比喻为“压缩-解压缩”的过程:
将 800X800 像素的图像压缩为 100KB 看起来更清晰。将 3000X3000 像素的图像压缩为 100KB 会显得模糊。
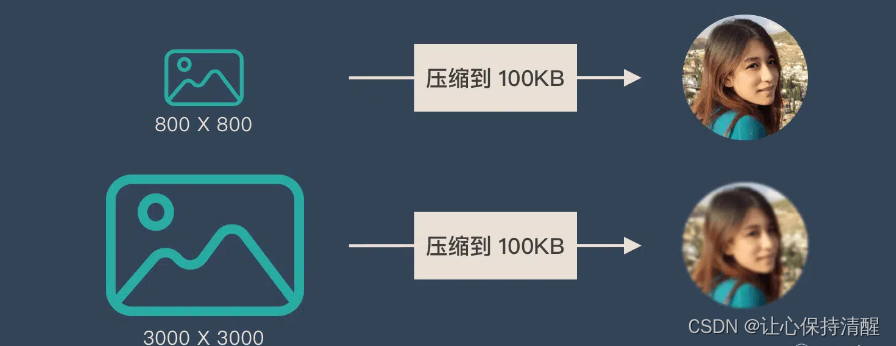 Encoder-Decoder也是类似的问题:当输入信息过长时,会丢失一些信息。
Encoder-Decoder也是类似的问题:当输入信息过长时,会丢失一些信息。
为了解决这个问题,Attention机制应运而生














 7371
7371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









