







整体模型
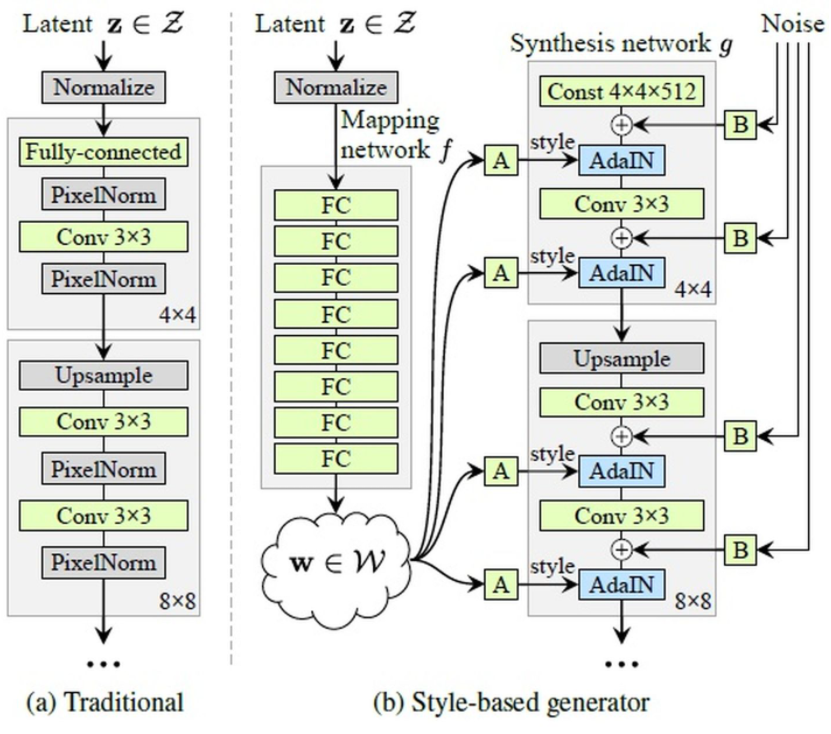
Mapping Network
Mapping Network作用:摆脱输入向量Z受输入数据集分布的影响,更好地实现属性解耦合。换句话说,z本身是一个高斯分布或者均匀分布的随机向量,特征之间的耦合性比较大,但我们希望z能够和真实数据分布更加接近,而如果真实数据集本身和z这个随机变量差距比较大,网络学习起来会比较困难。经过mapping network后的w就没有这样的问题,w可以更好地拟合真实数据分布。
为何Mapping network能够学习到特征解耦呢?
因为如果仅通过z来控制视觉特征,那么其能力十分有限,因为它必须遵循训练数据的概率密度。比如数据集中长头发并且长脸的人很常见,那么更多的输入值便会映射到该特征上,那么z中其他变量也会向着该值靠近、无法更好地映射其他特征。 所以通过Mapping network,该模型可以生成一个不必遵循训练数据分布地向量w,减少了特征之间的相关性,完成解耦。
Synthesis network
Synthesis network流程:w通过A(仿射变换)变成style(风格向量)(2*n, ys,i,yb,i),style与通过IN(instance normalization)地N个通道特征图进行AdaIN操作。
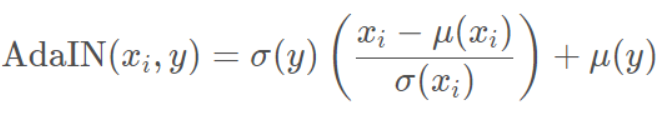
特征图的均值和方差中带有图像的风格信息。所以在这一层中,特征图减去自己的均值除以方差,去掉自己的风格。再乘上新风格的方差加上均值,以实现转换的目的。StyleGAN的风格不是由图像的得到的,而是w生成的。
图中每一个灰色方块为一个风格化模块,整个模型一共9个模块,每个模块有两个AdaIN层,共18个AdaIN层,公式中ys,i为缩放系数;yb,i为偏移系数,各有18组,对应每一个AdaIN层。i为通道数,即每一个通道都是独立的。实际上,y就是所谓的风格,也就是style,是整个模型中真正控制生成图片风格的向量。
输入4x4x512常数矩阵(z独立出来后,生成器的输入不再依赖于噪声输入)从第二个风格化模块开始,每个风格化模块将图像长宽翻倍(Upsample),经过八个风格化模块后输出1024x1024x3的图像。
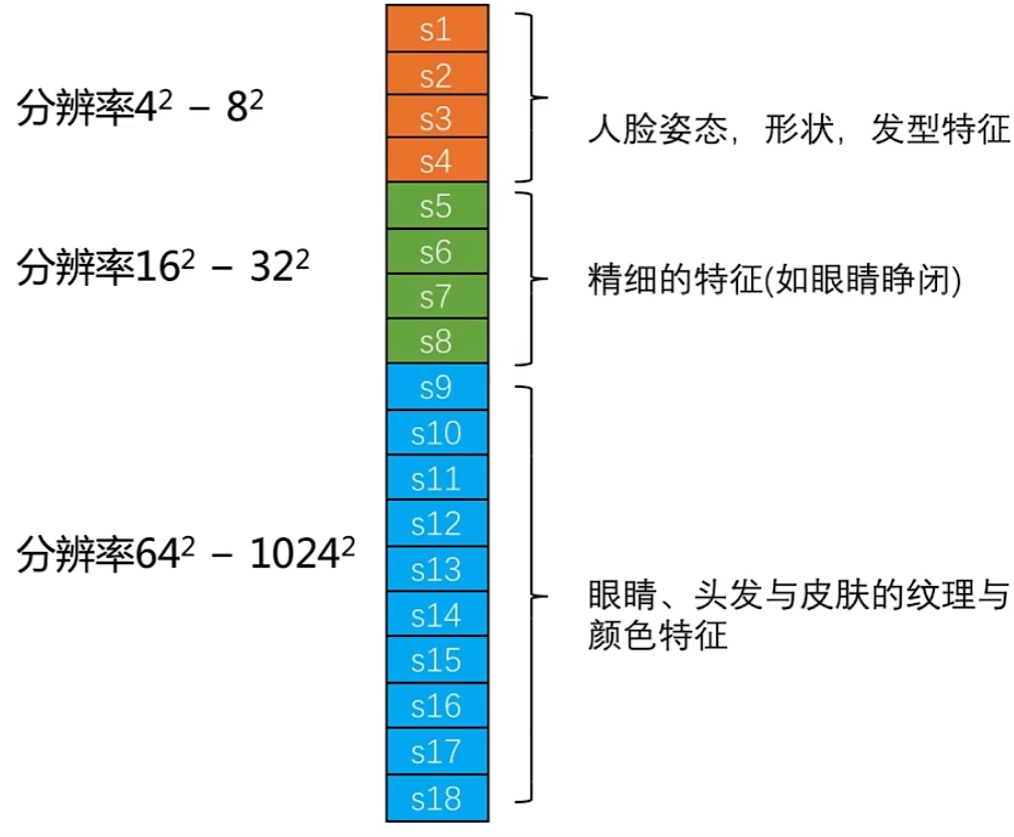
如图,分辨率越低,style层影响(控制)越宏观的图像特征,而分辨率越高时的style层影响(控制)越微观的特征。
额外Noise
图中,最右侧的Noise噪声为一个特征图级别的噪声,通过B(可学习的权重系数)后和特征图相加作为新的特征图。
**额外噪声Noise的作用:**主要影响生成图像细节,增加图像的多样性。如下图,作者做了100次实验对比加入noise的影响,并计算标准差,图c中越白的地方表示越容易受noise影响。

StyleGAN 采用类似于 AdaIN 机制的方式添加噪声(噪声输入是由不相关的高斯噪声组成的单通道数据,它们被馈送到生成网络的每一层)。在 AdaIN 模块之前向每个通道添加一个缩放过的噪声,并稍微改变其操作的分辨率级别特征的视觉表达方式。 加入噪声后的生成人脸往往更加逼真与多样。
训练技巧
样式混合
**目的:**进一步明确风格控制,同时防止相邻特征耦合
在训练过程中,stylegan采用混合正则化的手段,即在训练过程中使用两个latent code w (不是1个)。通过Mapping network输入两个latent code z,得到对应的w1和w2(代表两个风格),接下来为它们生成中间变量w’。然后利用第一个w1映射转换后来训练一些网络级别,用另一个w2来训练其余的级别,于是便能生成混合了A和B的样式特征的新人脸。

截断技巧(Truncation Trick)
问题:从数据分布来说,低概率密度的数据在网络中的表达能力很弱,直观理解就是,低概率密度的数据出现次数少,能影响网络梯度的机会也少,网络学习到其图像特征的能力就会减弱。
**解决方法:**首先找到数据中的一个平均点,然后计算其他所有点到这个平均点的距离,对每个距离按照统一标准进行压缩,这样就能将数据点都聚拢了(相当于截断了中间向量𝑊′,迫使它保持接近“平均”的中间向量𝑊′ 𝑎𝑣𝑔),但是又不会改变点与点之间的距离关系。
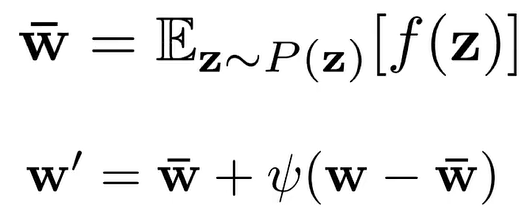

StyleGAN2
stylegan2主要是为了解决stylegan的不足之处,最重要的一点就是stylegan生成的图像上容易出现“水滴”。
导致水滴的原因是Adain操作,Adain对每个feature map进行归一化,因此有可能破坏掉feature之间的信息,产生上述现象。而去除了Adain后,该问题便解决了。

Adain问题解决 (水滴问题)
- 移除最开始的数据处理
- 在标准化特征时取消均值 (可以对照上文Adain查看)
- 将noise模块在外部style模块添加
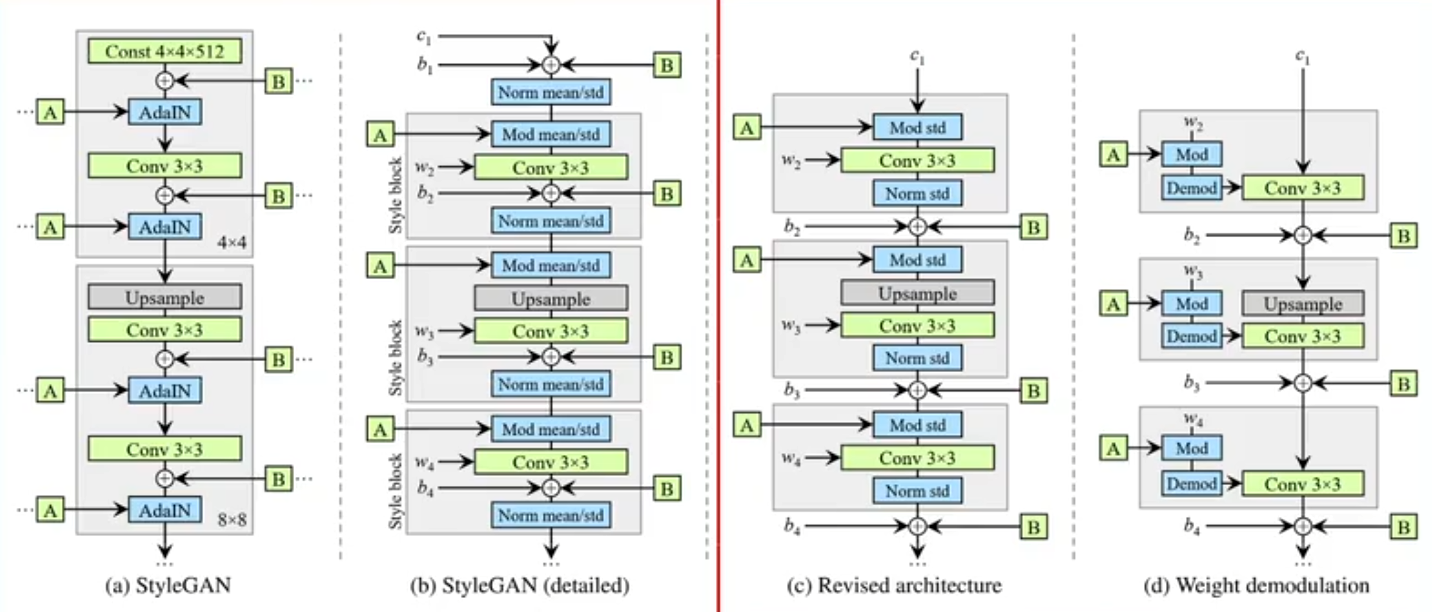
weight demodulation
在样式混合(style mixing)中,容易将某个特征放大一个数量级或更多,而在去除了Adain后,便无法有效控制这个问题(因为移除了mean),但style mixing又是stylegan的亮点,如何能够在保留style mixing的同时有效地解决特征放大问题呢?这便是weight demodulation设计的原因。
Lazy regularization
Path length regularization
StyleGAN3
在GAN的合成过程中,某些特征依赖于绝对像素坐标,这会导致:【细节似乎粘在图像坐标上,而不是所要生成对象的表面】
而stylegan3从根本上解决了stylegan2图像坐标与特征粘连的问题,实现了真正的图像平移、旋转等不变性,大幅度提高了图像合成质量。


通过上图可以看出来stylegan2生成的毛发等细节会粘在屏幕上,和人物的形态变化不一致。Stylegan生成的过程并不是一个自然的层次化生成。粗糙特征(GAN的浅层网络的输出特征)主要控制了精细特征(GAN的深层网络的输出特征)的存在与否,并没有精细控制它们的出现的精确位置。
改进
-
傅里叶特征以及基线模型简化
- 利用Fourier特征(傅里叶特征)代替了stylegan2生成器的常数输入
- 删除了noise输入(特征的位置信息要完全来自前层粗糙特征)
- 降低了网络深度(14层,之前是18层),禁用mixing regularization和path length regularization,并且在每次卷积前都使用简单的归一化 (这里有点直接推翻了stylegan2的一些思想)
-
边界及上采样问题优化
- 理论上特征映射有一个无限的空间范围(就是特征不能局限固定在某些坐标域),引入了一个固定大小的boundaries来近似,每一层操作后再crop到这个扩展的空间。用理想低通滤波器来代替双线性采样。 改进后的boundaries和upsampling得到了更好的平移性,但是fid变差了。
-
非线性滤波改进
- 工程化的操作,改进了非线性滤波,并将整个upsample-LReLU-downsample过程写到一个自定义的CUDA内核中
-
非临界采样改进
- 为了抑制 aliasing(混淆对于生成器的Equivariance很有害),可以简单地将截止频率降低,从而确保所有混叠频率都在阻带。【丢掉了浅层的高频细节,因为作者认为浅层中高频细节并不重要】
-
傅里叶特征改进
- 为了应对每层的全局变换能力有限的问题,加入了一个仿射层,通过输出全局平移和旋转参数输入傅里叶特征,稍微改善了FID
-
平移不变性
- 虽然提高了平移不变性,但是一些可见的伪影仍然存在。这是因为滤波器的衰减对于最低分辨率的层来说仍然是不够的,而这些层往往在其带宽限制附近有丰富的频率信息,这就需要有非常强的衰减来完全消除混叠。提出:跳频在最低分辨率层中较高,以最大化提高阻带的衰减;在最高分辨率层中较低,以匹配高层细节
-
旋转不变性
-
将所有层的卷积核大小从3 * 3替换为1 * 1
-
通过将feature map的数量增加一倍,用来弥补减少的特征容量
实验表明,一个基于 1 * 1的卷积操作能够产生强旋转的等变生成器,一旦适当地抑制了混叠,便可以迫使模型实现更自然的层次细化。
-















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









