





 本文介绍了一种在监控视频中检测遗留物的方法,结合长期和短期背景模型来提取前景目标,并利用像素级有限状态机和回溯验证确认是否为遗留物。首先,通过双学习率的背景消除算法,结合两种不同学习率的高斯混合模型来区分静止物体。接着,利用有限状态机判断静止物体是否满足遗留物的条件。最后,通过回溯跟踪验证,寻找遗留物的所有者,确保物体被遗弃且未被立即捡起。这种方法有效地减少了误报,提高了遗留物检测的准确性。
本文介绍了一种在监控视频中检测遗留物的方法,结合长期和短期背景模型来提取前景目标,并利用像素级有限状态机和回溯验证确认是否为遗留物。首先,通过双学习率的背景消除算法,结合两种不同学习率的高斯混合模型来区分静止物体。接着,利用有限状态机判断静止物体是否满足遗留物的条件。最后,通过回溯跟踪验证,寻找遗留物的所有者,确保物体被遗弃且未被立即捡起。这种方法有效地减少了误报,提高了遗留物检测的准确性。
Abandoned Object Detection via Temporal Consistency Modeling and Back-Tracing Verification for Visual Surveillance
摘要
本文提出了在监控视频下的遗留物检测算法,作者把long-term 和 short-term的背景模型结合在监控视频视频中提取前景目标。最后对提取的前景目标进行有限状态机(Pixel-Based Finite State Machine )和遗留物主人的轨迹回溯法(Back-Tracing)联合判断前景目标是否为遗留物。
一、双学习率的背景消除算法( Temporal Dual-rates foreground Integration Method)
1、双高斯模型的背景消除算法
背景消除算法用来得出图片的前景物体(foreground), 有限状态机用于判断前景物体是否为遗留物。
A. 背景建模和模型更新策略

首先, 需要对监控的视频环境进行建模,使用混合高斯模型GMM对监控的背景进行建模学习监控下的背景信息.混合高斯模型:

一般的高斯模型通过极大似然法来求解最优值(通常根据定义的表示特征需要混合3-5个高斯模型,根据EM算法(极大化Jensen不等式的lower bound)对高斯模型的参数进行学习)。
但是本文的背景建模的GMM模型的策略采用了Improved Adaptive Gaussian Mixture Model for Background Subtraction文中的GMM学习方式,自适应更新混合高斯模型的个数和高斯模型的参数。其更新方式如下:
- 1. 初始化一个背景模型 B ( x , y ) B(x,y) B(x,y);其中 ( x , y ) (x,y) (x,y)代表图像的每个像素点, 0 ≤ x ≤ m − 1 , 0 ≤ y ≤ n − 1 0\leq x \leq m-1,0\leq y \leq n-1 0≤x≤m−1,0≤y≤n−1。
- 2. 对于一张图像 I t I_{t} It的每个像素点 ( x , y ) (x,y) (x,y),如果 I t ( x , y ) ⊆ B ( x , y ) I_{t}(x,y) \subseteq B(x,y) It(x,y)⊆B(x,y) 就表示图像 I t I_{t} It的像素点 ( x , y ) (x,y) (x,y)属于背景(BG),否则像素点 ( x , y ) (x,y) (x,y)就是图片的前景(FG)。
- 3. 如果独立的像素点 ( x , y ) (x,y) (x,y)是图片的背景,那么需要把点 I t ( x , y ) I_{t}(x,y) It(x,y)作为训练样本更新我们的背景模型 B ( x , y ) B(x,y) B(x,y)。
- 4. 更新下一张图片 t = t + 1 t = t + 1 t=t+1, 重复步骤2。
其中通过对步骤3中学习率 λ ∈ [ 0 , 1 ] \lambda\in[0,1] λ∈[0,1]的调整来控制 λ B \lambda B λB和 ( 1 − λ ) I t (1-\lambda)I_{t} (1−λ)It的偏好。如果 λ \lambda λ的值较小,模型 B B B对新的训练样本 I t I_{t} It的学习速度就很快,高斯模型对新的样本适应很快(当FG物体静止较短时间后GMM就会快速适应,并在接下来识别成背景),反之若 λ \lambda λ的值较大,那么高斯模型对新的样本适应较慢(只有当FG停留很长的时间,模型才能判定其为背景)。
B. 静止物体检测-----长(Long-Term)短(Short-Term)时双背景建模

长短时背景建模的核心就是对GMM模型使用不同的学习率
λ
\lambda
λ。从之前的对
λ
\lambda
λ讨论中可以发现GMM模型的学习率越大,模型更新速度越慢,从而对静止的FG物体越不敏感。所以我们把使用小的学习率
λ
S
\lambda_{S}
λS背景模型称为Short-term短时背景模型
B
S
B_{S}
BS,同时其模型输出的二值背景图片记作
F
S
F_{S}
FS。相似的把较大的学习率
λ
L
\lambda_{L}
λL的背景模型称为Long-term长时背景模型
B
L
B_{L}
BL,同时其模型输出的二值背景图片记作
F
L
F_{L}
FL。长短时背景检测模型的结果如图3所示:

Short-term模型对新的图片的适应性很强会把静止的FG很快分类成BG背景,而Long-term模型对新的图片的适应性很较弱不会立刻把静止FG物体分类成BG信息。而静止的FG物体检测的核心是利用两个模型的输出的差来实现静止FG检测。具体流程如图2所示。对于FG的检测来说long-term长时模型会检测更多的FG信息(最直观的理解:long背景模型物体待的时间越long才是BG背景,short背景模型物体带的时间较短就可以是BG背景)。
对于一个图片的像素点
i
i
i,我们定义了
S
i
S_{i}
Si表示当前像素点长短时双背景模型的输出值:
其中, F S ( i ) F_{S}(i) FS(i) 和 F L ( i ) F_{L}(i) FL(i) 都属于[0,1],都表示一个二值的像素点。 对于双背景消除法的输出值 S i S_{i} Si 有四种情况如下表所示:
| S i S_{i} Si | 像素点 i i i的意义 |
|---|---|
| 00 | 长时模型检测为BG,短时模型检测模型为BG-> 背景像素BG |
| 01 | 长时模型检测为BG,短时模型检测模型为FG-> 突然暴露的背景像素BG ∗ ^{*} ∗ |
| 10 | 长时模型检测为FG,短时模型检测模型为BG-> 候选的静止FG |
| 11 | 长时模型检测为FG,短时模型检测模型为FG-> 移动中的FG |
*注(原论文的注释为这个像素点在图像中之前被物体遮挡然后才在接下来的图片中暴露出来, 个人理解:一个FG物体在这个像素点静止了一小会long模型没适应而short适应了即S=1,0,但是时间很短然后就离开了导致S=0, 1)
2、有限状态机(Pixel-Based FSM)

对于已经建模好了的双背景模型,其 S i S_{i} Si初始状态主要包含有两个(11,00)。对于静止FG的定义中首先是移动的状态下停下并静止下来一段时间,所以FSM的触发条件为物体都是运动的FG前景 S i = 11 S_{i} = 11 Si=11, 然后物体静止下来状态就需要进入 S i = 10 S_{i} = 10 Si=10。如果物体静止的时间大于 T s T_{s} Ts,则判定其为静止的FG物体。注(如果物体静止的时间较短long没适应:11-10-01-00, 时间满足条件:11-10-00(这个状态下可能包含有遗留物的丢弃和背景捡走过程?);在验证的时候刚丢掉的物体突然被移动的物体遮挡了会不满足FSM)。具体过程见图4。
综上FSM规则是:如果连续子序列 S i S_{i} Si需要以11为触发状态,然后有足够长的时间序列 S i = 1 , 0 S_{i}=1,0 Si=1,0,我们才能判定这个像素点为静止FG像素点。同时考虑到遗留物的特征,对于检测到的静止FG像素点blobs设置一个阈值,既不能太小,同时不能太小。到此为止才能把检测出来的静止FG作为候选的遗留物信息。
二、回溯跟踪验证(Back-Tracing Verification)
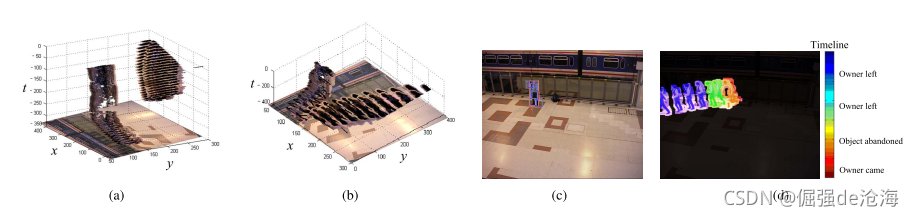
为了验证静止的FG是否是被遗留的物体还是仅仅放在这边一段时间(之后拿走!)。如果静止的FG物体的丢弃者不再返回到物体附近,那么这个物体就被判断成遗留物。具体的回溯验证流程如下:
当一个物体或者一个blob在FSM中在
t
t
t时刻被判定为静止的FG物体后而且在这个FG的周围
D
D
D的范围内没有移动的物体后(注意这个条件),我们回溯到视频的第
t
0
t_{0}
t0帧数(
t
0
=
t
−
T
s
t_{0}=t-T_{s}
t0=t−Ts)并假设在这一帧物体被人遗留。在
t
0
t_{0}
t0帧的图片上我们创建一个时空范围
W
0
W_{0}
W0(spatial-temporal window),
W
0
W_{0}
W0以
t
0
t_{0}
t0帧图片的遗留物物体的中心点
p
p
p为圆心大小为
(
r
2
,
δ
)
(r^2,\delta )
(r2,δ),其中
r
r
r为当前图片上的半径 ,
δ
\delta
δ为时间范围
[
t
0
,
t
0
+
δ
]
[t_{0},t_{0}+\delta ]
[t0,t0+δ]。
对于时空范围
W
0
W_{0}
W0我们重新审视在这个范围内的全部FG物体(blob)。我们使用合适的人形状的高宽估计和检测人的算法(Deformable Part Model)在blobs中检测人来判定遗留物的主人。如果在
W
0
W_{0}
W0的空间中我们检测到了多个人直接使用离遗留物中心点
p
p
p最近的人判定其为遗留物的主人并把
W
0
W_{0}
W0空间中的这个blob记录为
p
1
p1
p1。
下一步我们利用
p
1
p1
p1为中心再创建一个时空范围
W
1
W_{1}
W1其范围也为
(
r
2
,
δ
)
(r^2,\delta )
(r2,δ)。然后利用我们在
W
0
W_{0}
W0中找到的遗留物主人的颜色特征(颜色直方图)在
W
1
W_{1}
W1时空范围中blobs寻找最相似的blob(e Bhattacharyya coefficient巴氏系数作为判断依据)。最后找到另一个
p
2
p2
p2创建时空范围
W
2
W_{2}
W2。重复上述步骤直到我们找到的时间超过
t
t
t。完成这些后我们就实现了在
δ
\delta
δ范围内对遗留物主人的跟踪。优点:更有效的解决人被短暂的遮挡的问题而且由于时间范围的有效性所以该方法也的效率也很高。图5展示了本算法对遗留物主人的跟踪效果。
之前的文章中验证了双背景消除法检测的遗留物会带来很多的误报,所以本文了提出一种回溯验证的方法,主要是去寻找遗留物的owner的信息来辅助判断。
三、遗留物事件分析( Abandoned Object Event Analysis)

图5展示了遗留物检测事件的全部流程,一旦遗留物的主人的轨迹被侦测到,然后我们会根据以下连两个规则进行判断然后进行是否报警行为。
1.时序规则(Temporal rule):一个遗留物被人遗弃时间上要超过
T
=
30
s
T=30s
T=30s以上。否则不算遗留物。通常
T
=
30
s
T=30s
T=30s可以使用
T
=
30
f
p
s
T=30fps
T=30fps来计算
2.空间规则(Spatial rule):遗留物的定义是被人给遗留的物体而且遗留物不会被立马捡起来。所以在空间上遗留物和其主人的距离需要达到
D
=
3
m
D=3m
D=3m以上报警事件才会触发。

















 1873
1873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









