





本文总结翻译自:https://towardsdatascience.com/stop-one-hot-encoding-your-categorical-variables-bbb0fba89809
独热编码的不足:
1. 产生许多的特征;
2. 产生的特征没有带来的更多的信息;
3. 产生的特征反而带来了具有共线性的特征。
改进方法:
1. 目标编码(target encoding):
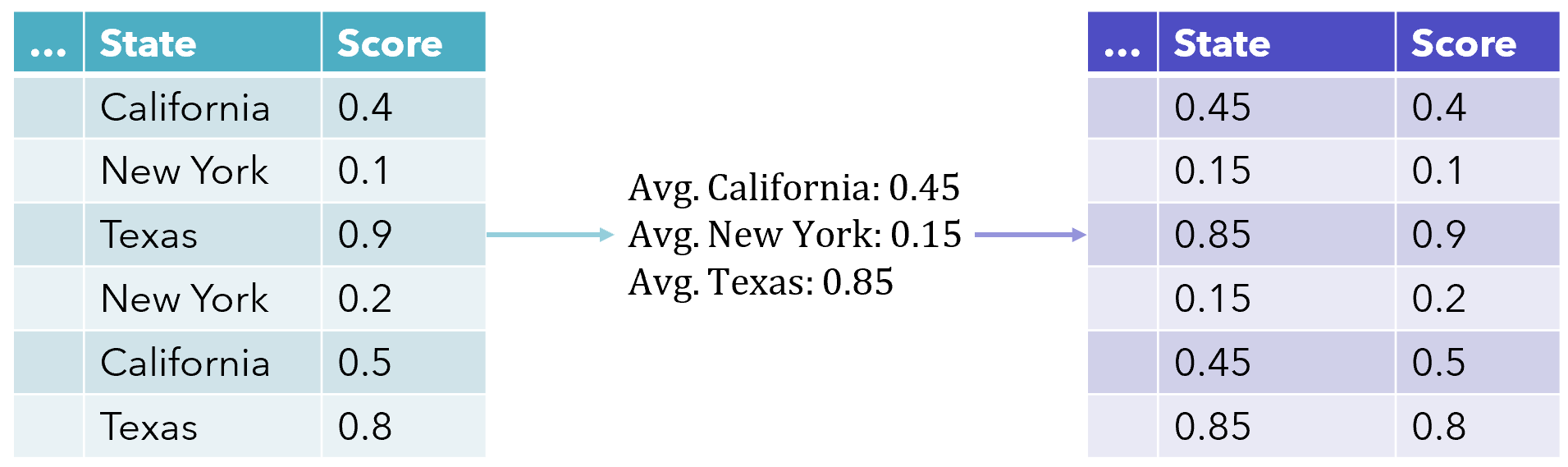
使用target值的均值作为category变量的替换值。
代码:
from category_encoders import TargetEncoder
enc = TargetEncoder(cols=['Name_of_col','Another_name'])
training_set = enc.fit_transform(X_train, y_train)但是这种方法也有缺点:
- 依赖于y值
- 对于category的值,全都来自训练集,因此更容易出现overfitting过拟合问题
2. 留一编码(Leave-One-Out encoding):

改进了target encoding,使用除了改行target值外的其他同类target来计算。
代码:
from category_encoders import LeaveOneOutEncoder
enc = LeaveOneOutEncoder(cols=['Name_of_col','Another_name'])
training_set = enc.fit_transform(X_train, y_train)3. 贝叶斯目标编码(Bayesian target encoding):
贝叶斯目标编码在目标编码的算平均值(期望值)的基础上,增加了方差和倾斜(variance/skewness)作为考量,生成贝叶斯模型,再具体给出编码值。
4. WoE(Weight of Evidence):
编码公式为:ln (% of non events / % of events)
代码:
from category_encoders import WOEEncoder
enc = WOEEncoder(cols=['Name_of_col','Another_name'])
training_set = enc.fit_transform(X_train, y_train)
以上均为监督学习的角度的独热编码,除此之外还有非监督学习的,即没有target或者label的情况下:
5. 非线性PCA(Nonlinear PCA):
大致解释就是:
使常规PCA的性能(解释方差)最大化,来得到该类别的最佳编码值。
非线性PCA的具体解释:

















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









