






一.简介
⽀持向量机是在深度学习流⾏起来之前效果最好的模型。
基本原理是⼆分类线性分类器,但现在也可以解决多分类问题,⾮线性问题,和回归问题。
找到一个决策边界,使边界间隔最大

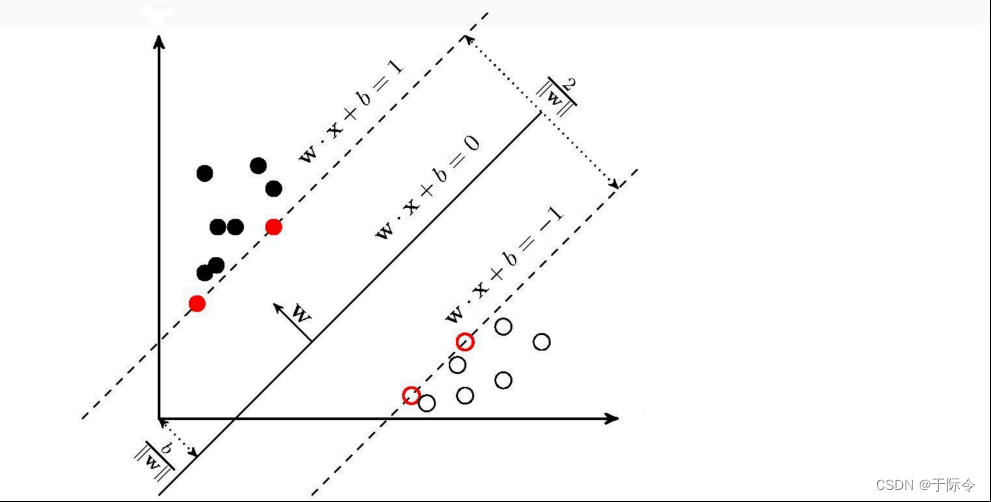
名词解释:
决策超平面:wx+b=0,超平面(中间实线)
决策边界:虚线所示,也即超平面的上下边界
支持向量:决策边界(虚线)所穿过的点,或者距离决策边界(虚线)最近的点。SVM的核心就是优化决策超平面的参数,使支持向量到决策超平面的距离最大
间隔:两条虚线之间的距离,间隔越大,意味着两类数据的差异越大
二.程序
1.个别参数
sklearn.svm.SVC( c=1.0 , #错误样本的惩罚参数
kernel='rbf', #使用何种核算法。linear:线性,poly:多项式,rbf:高斯(正态),sigmod,precomputed:自定义
degree=3, #多项式核函数的阶数
gamma='auto', #当kernel为'rbf','poly','sigmod'时的kernel的系数
coef0=0.0, #kernel函数的常数项。
shrinking=True,
probability=False, #是否估计概率,会增加计算时间
tol=0.001, #误差项达到指定值时停止训练,默认值为0.001
)
类的属性:
support_vectors
⽀持向量,
support_ ⽀持向量的索引, n_support_
个数
2.SVM分类
PS:下面是最简单的SVM分类的代码,主要用于熟悉SVM的流程及各函数的作用
from sklearn.svm import SVC #SVC表示分类,SVR表示回归
from sklearn.preprocessing import StandardScaler # 可先做标准化。
from sklearn import datasets
from sklearn.model_selection import train_test_split #用于划分数据集
# 读数据
iris = datasets.load_iris() #iris,经典鸢尾花数据集
X = iris.data
y = iris.target
# 标准化
std = StandardScaler()
X_std = std.fit_transform(X) #对X的数据集进行标准化处理,y是目标值0,1之类不用标准化
# 拆分训练集
X_train, X_test, y_train, y_test = train_test_split(X_std, y, test_size=0.3) #X_std是标准化之后的x(X = iris.data)的值
# SVM建模
svm_classification = SVC() #classification中文意思:分类
svm_classification.fit(X_train, y_train) #用训练集数据进行训练。fit()函数用于训练模型
# 模型效果
svm_classification.score(X_test, y_test) #用测试集数据进行测试模型效果。score()函数用于测试模型效果
print(svm_classification.score(X_test, y_test)) #这局代码用于输出测试结果,要不然代码运行完没有输出,看不到3.SVM回归
from sklearn.svm import SVR #SVC表示分类,SVR表示回归
from sklearn.preprocessing import StandardScaler #标准化库
from sklearn import datasets #sklearn内置的数据集
from sklearn.model_selection import train_test_split #数据集拆分
# 读数据
boston = datasets.load_boston() #波士顿房价数据集(sklearn内置数据集)
X = boston.data
y = boston.target
# 标准化
std = StandardScaler()
X_std = std.fit_transform(X)
# 拆分训练集
X_train, X_test, y_train, y_test = train_test_split(X_std, y, test_size=0.3)
# SVM建模
svm_regression = SVR() #regression的意思是回归
svm_regression.fit(X_train, y_train) #用训练集数据进行训练。fit()函数用于训练模型
# 模型效果
svm_regression.score(X_test, y_test) #用测试集数据进行测试模型效果。score()函数用于测试模型效果。score中文“得分”
print(svm_regression.score(X_test, y_test)) #这局代码用于输出测试结果,要不然代码运行完没有输出,看不到PS:回归效果不好,主要用于了解步骤















 1329
1329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









