






1.机器学习
让机器通过已有的数据进行学习,然后用学到的知识对新数据进行预测
大体分为三类:回归、分类、聚类
回归:预测某个数值
分类:预测属于哪个类别
聚类:自动进行分类

一.第一轮数据清洗
1.数据处理----缺失值(空值)
对于数据中的空值的处理方法:
(1)直接删除(大多数情况不建议,因为只缺失某项值但它其他的值是有意义的)
(2)填充。填充平均值或者中位数(实际操作中填充中位数比较好,因为均值易受特殊值得影响(比如小明收入0元但和马云的平均财产也很高))
2.独特率
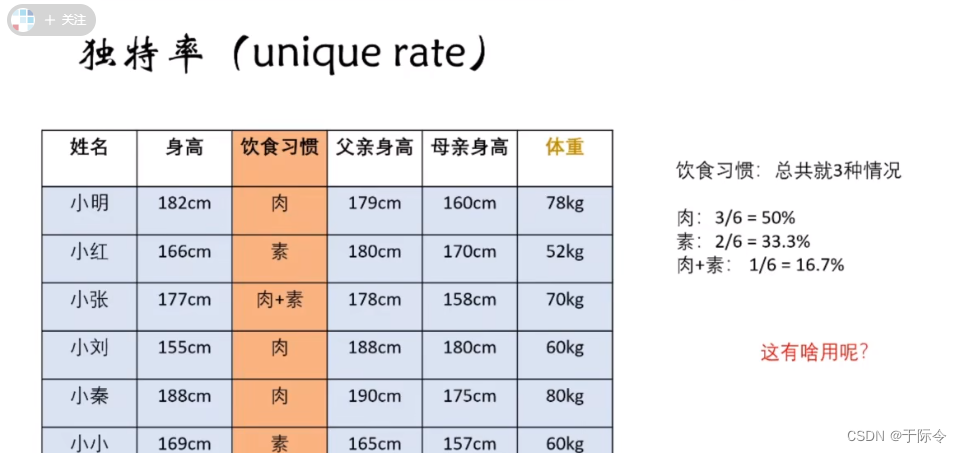
上图饮食习惯的独特率为3,即饮食习惯中只有三种不同类型的东西
二.第二轮数据清洗
1.异数
就是异常值,明显偏离整体数据的数据值。例:求均值时极大值对均值的影响,极大值就是异数
2.相关度检验
两个特征例:是男生吗,是女生吗这两个变量相当于重复了,
相关度很大的两个变量要删掉一个
三.数据分析三剑客
1.numpy
numpy是Python中做科学计算的基础库。重点 在于数值计算,也是大部分Python科学计算库的基础,多用于在大型、多维数组的数值计算
(1)numpy的创建
- 使用np.array()创建
- 使用plt创建
- 使用np的routines创建
使用np.array()创建一个一维数组
import numpy as np
arr1=np.array([1,2,3,4,5,6])
print(arr1)使用np.array()创建一个多维数组
import numpy as np
arr2=np.array([[123,456,789],[1,2,3]])
print(arr2)数组和列表的区别:
数组中只可以存储相同类型的元素
如果数组中出现了不同类型的元素,则根据数据类型的优先级会将不同类型的数据转换为相同类型的数据(数据的优先级::字符串>浮点型>整形)
(2)numpy的索引和切片
'''numpy索引操作'''
import numpy as np
arr=np.random.randint(0,100,size=(4,5)) #用random.randint(a,b)生成随机数包括范围的两个端点,size:生成4行5列的数
print(arr)
'''结果[[64 28 83 25 9] 索引为0
[25 49 17 72 2] 索引为 1
[ 2 24 27 8 21]
[71 6 52 55 85]]'''
print(arr[1]) #结果[25 49 17 72 2]
print(arr[1][3]) #结果72
'''numpy切片操作'''
import numpy as np
arr1=np.random.randint(0,100,size=(5,6))
print(arr1)
#切行
print(arr1[0:3])
#切列
print(arr1[:,0:3])
#即切行又切列
print(arr1[0:3,0:3])(3)变形reshape
注意:变形前和变形后数组的容量不可以发生变化(容量不能发生变化指:一维是9个元素,变成二维之后也得是九个元素)
import numpy as np
arr=np.array([1,2,3,4,5,6,7,8,9])
print(arr)
#将一维变成二维
arr1 = arr.reshape((3,3)) #三行三列
arr2 = arr.reshape((1,9)) #一行九列
arr3 = arr.reshape((9,1)) #九行一列
print(arr1)
print(arr2)
print(arr3)
'''不管九行一列还是一行九列,总之容量不能改变'''
#将二维变成一维
arr4 = arr1.reshape(1,9)
print(arr4)线性回归中用
X_train = X_train.values.reshape(-1,1)将数据转化成一列的原因:

(4)级联操作
---将多个numpy数组进行横向或者纵向的拼接
axis轴向:0表示按列拼接,1表示按行拼接
arr1 = np.random.randint(0,100,size=(3,4)) #用random.randint(a,b)生成随机数包括范围的两个端点,size:生成3行4列的数
arr2 = np.random.randint(0,100,size=(2,4))
#匹配级联:级联的数组形状一致(行数列数一样)
a=np.concatenate((arr1,arr1),axis=0) #axis=0表示按列拼接,axis=1表示按行拼接
b=np.concatenate((arr1,arr1),axis=1)
print('按列拼接:\n',a)
print('按行拼接:\n',b)
#不匹配级联:行数列数有一个不同,则只能按相同的那个轴向进行拼接,如:arr1和arr2只能按列进行拼接,按行拼接报错
c=np.concatenate((arr1,arr2),axis=0)
print('按列拼接:\n',c)结果:
注,random.randint(a,b)生成的是随机数,所以每次运行结果可能不一样

(6)矩阵相关

熟悉基本的矩阵操作:创建矩阵、矩阵转置、矩阵的乘法等
矩阵的转置 .T
#矩阵的转置
import numpy as np
arr1=np.random.randint(0,100,size=(3,5))
print(arr1)
arr2=arr1.T #.T表示矩阵的转置
print(arr2)矩阵的加法、减法:每个位置元素应相加减
一个数乘以一个矩阵:用这个数与矩阵中的每个元素分别相乘
矩阵的乘法:(矩阵乘矩阵)

2.pandas




(1)基于pandas的数据清洗
首先导入模块:
import numpy as np
import pandas as pd
from pandas import DataFrame
创建一个列表,并制造空值
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(10,8)))
#人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值)
df.iloc[3,3]=np.nan
df.iloc[4,5]=np.nan
df.iloc[6,6]=np.nan
print(df)
空值的处理:
pandas处理空值的操作:
- isnull
- notnull
- any
- all
- dropna
- fillna
-
方式一:对空值进行过滤(删除空所在的行数据)(比较麻烦一般不用,一般用方式二)
技术:isnull, notnull, any, all
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(10,8)))
#人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值)
df.iloc[3,3]=np.nan
df.iloc[4,5]=np.nan
df.iloc[6,6]=np.nan
print(df)
'''isnull和any结合删除表格中有空值的行'''
#any作用到df.isnull()返回的DataFrame的行中
#any的作用:检测一组数据中是否存有True,如果有则返回True否则返回False
print(df.isnull().any(axis=1)) #axis=1检测哪行有空,axis=0检测哪列有空
ex=df.isnull().any(axis=1)#将检测出有空值的行的行号赋值给ex
print(df.loc[ex]) #将有空值的行打印出来(ex中已有行号)。df.loc[]可以查询数据
#输出有空值行的索引
null_row_index = df.loc[ex].index
print(null_row_index)
#删除有空值的行,并把剩余行输出
print(df.drop(labels=null_row_index,axis=0))结果:
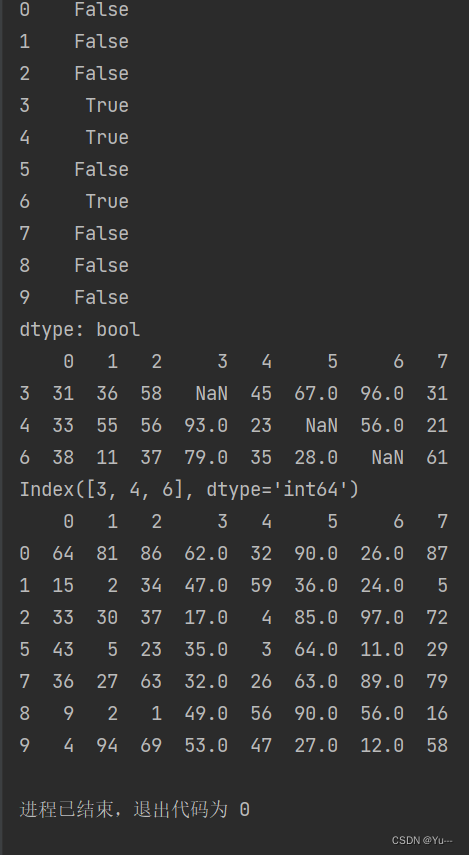
注意:notnull和all结合类似
方式二:dropna:可以直接将缺失的行或列进行删除
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(10,8)))
#人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值)
df.iloc[3,3]=np.nan
df.iloc[4,5]=np.nan
df.iloc[6,6]=np.nan
print(df)
a=df.dropna(axis=0) #axis=0表示将空值所在行删除
print(a)
b=df.dropna(axis=1) #axis=1表示将空值所在列删除
print(b)结果:

注意:方式二相当于对方式一的封装,比方式一简洁
方式三:对缺失值进行覆盖(fillna)
注意:该方法是使用任意值(666)填充空值,即所有空值都填充同一个值,这种意义不大,一般不常用。
用任意值填充空值
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(10,8)))
#人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值)
df.iloc[3,3]=np.nan
df.iloc[4,5]=np.nan
df.iloc[6,6]=np.nan
print(df)
#用fillna对缺失值进行覆盖
print(df.fillna(value=666))
结果:

使用近邻值填充空值
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(10,8)))
#人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值)
df.iloc[3,3]=np.nan
df.iloc[4,5]=np.nan
df.iloc[6,6]=np.nan
print(df)
#使用近邻值填充空值
#method:ffill(用前面的值填充),bfill(用后面的值填充) axis=0表示用列方向,axis=1表示用行方向。
print(df.fillna(method='ffill',axis=0)) #用列方向前面的数值填充空值
#用邻近值填充的特殊情况,假设用列前面的数值填充,空值在第一行(即它列方向前面没有值),处理方法如下
print(df.fillna(method='ffill',axis=0).fillna(method='bfill',axis=0)) #列方向前面没有值时用列方向后面的值,这样能保证所有空值都能填上
检测空值的个数
原理:
isnull()作用:非空显示为False,空值显示为True,False为0,True为1.则用sum()求每行或每列的和,若值为0说明全是False相加,即该行或该列全是非空值。若值为1说明有一个True,值为2说明有两个True,以此类推,能检测空值个数
import numpy as np import pandas as pd from pandas import DataFrame #创建一个列表 df=DataFrame(data=np.random.randint(0,100,size=(10,8))) #人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值) df.iloc[3,3]=np.nan df.iloc[4,5]=np.nan df.iloc[6,6]=np.nan print(df) #检测df中空值的个数 #isnull()作用:非空显示为False,空值显示为True。sum()是求和,axis是控置按行还是按列 a=df.isnull().sum(axis=0) #按列求和,只要不是0说明该列有空值(因为结果为0->是所有False相加->所有值非空)(结果不为0->是True相加->该列有空值) b=df.isnull().sum(axis=1) #按行求和,只要不是0说明该行有空值 print(a) print(b)
使用空值对应列的均值填充空值
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(10,8)))
#人为给列表制造空值(实际应用中数据是从外部导入的,这里为演示人为制造空值)
df.iloc[3,3]=np.nan
df.iloc[4,5]=np.nan
df.iloc[6,6]=np.nan
print(df)
#使用空值对应列的均值进行空值填充
#判断遍历的该列中是否存在空值
for col in df.columns: #df.columns返回列标签
if df[col].isnull().sum()>0: #如果>0说明存在空值
mean_value = df[col].mean() #df[col].mean() 求该列的均值
df[col].fillna(value=mean_value,inplace=True) #用均值填充该列的空值
print(df)
处理重复数据
方式一:(先检测重复行,再对重复行进行取反打印)(太麻烦,不常用)
#导入相关模块
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(8,4)))
print(df)
#人为给列表制造重复值(实际应用中数据是从外部导入的,这里为演示人为制造重复值)
df.iloc[2]=[1,1,1,1]
df.iloc[4]=[1,1,1,1]
df.iloc[6]=[1,1,1,1]
print(df)
#检测df中哪些行数据是重复的
print(df.duplicated()) #以True的形式返回重复行,在所有重复行中默认保留第一行重复数据,其余重复用True表示出
#~df.duplicated():对重复行进行取反得到不重复行,df.loc[]输出每行数据
print(df.loc[~df.duplicated()])
'''
经过以上操作所有重复行只保留了一个(不能把重复行全删,保留一行也能保证不重复)并且打印了去除重复数据的所有行
'''
方式二:(用df.drop_duplicates()方法,检测重复行加删除一起执行,直接出结果,常用)
#导入相关模块
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一个列表
df=DataFrame(data=np.random.randint(0,100,size=(8,4)))
print(df)
#人为给列表制造重复值(实际应用中数据是从外部导入的,这里为演示人为制造重复值)
df.iloc[2]=[1,1,1,1]
df.iloc[4]=[1,1,1,1]
df.iloc[6]=[1,1,1,1]
print(df)
#将重复行删除
print(df.drop_duplicates())
处理异常数据
- 自定义一个1000行3列(A,B,C)取值范围为0-1的数据源,然后将异常值设置为C列中大于其两倍标准差的值为异常值,对异常值进行清洗
#导入相关模块
import numpy as np
import pandas as pd
from pandas import DataFrame
#np.random.random():随机生成浮点数,范围0-1之间。size:定义行列值。columns:定义列名
df=DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C'])
print(df)
#两倍标准差的值
twice_std=df['C'].std()*2
print(twice_std)
#判定异常值的条件
ex = df['C'] > twice_std
#过滤异常值对应的行数据
print(df.loc[~ex]) #ex是异常值加~表示取反即正常值
(2)pandas高级操作
pandas替换操作

代码解释:
import numpy as np
import pandas as pd
from pandas import DataFrame
#创建一组数据
df=DataFrame(data=np.random.randint(0,20,size=(8,5)))
print(df)
#全局替换,将满足条件的所有数据都进行替换
df.replace(to_replace=1,value='one') #to_replace:要替换的数据。value:用于替换的新的值
#多值替换:将多个值替换成指定形式
df.replace(to_replace={1:'one',3:'three'}) #用字典的形式,把1替换成one,3替换成three
#指定列的替换
df.replace(to_replace={1:1},value='one') #将第一行的1替换成one,其他行的1不做变换
pandas映射操作:

注:映射关系列表一般是字典
import numpy as np
import pandas as pd
from pandas import DataFrame
dic={
'name':['张三','李四','王五','张三'],
'薪资':[5000,6000,5500,5000]
}
df=DataFrame(data=dic)
print(df)
#映射关系表
dic={
'李四':'jerry',
'王五':'jack',
'张三':'tom',
}
别名=df['name'].map(dic)
df['别名']=别名
print(df)结果:
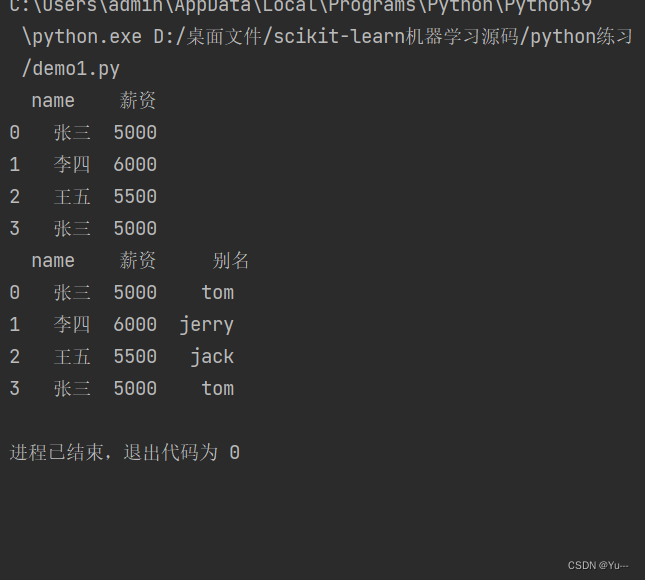















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









