







一、加载数据
1.使用torchvision.datasets的方法加载经典数据集
在此网址查看支持哪些经典数据集:Datasets — Torchvision 0.18 documentation (pytorch.org)
data_train = torchvision.datasets.CIFAR10(root="CIFAR10", train=True, transform=ToTensor(),
target_transform=None, download=True)
data_test = torchvision.datasets.CIFAR10(root="CIFAR10", train=False, transform=ToTensor(),
target_transform=None, download=True)下面三个参数是所有加载经典数据集的函数共有的参数:
- root:存储数据集的目录
- transform:通常为对图像数据进行一系列转换操作的函数
- transform_target:通常为对目标数据进行一系列转换操作的函数
2.自己收集的数据集
(1)使用列表缓存图像和标签
root = "./data"
x = []
y = []
label_to_int = {}
int_to_label = {}
for kind in os.listdir(root):
label = len(label_to_int)
label_to_int[kind] = label
int_to_label[label] = kind
kind_root = os.path.join(root, kind)
images_path = os.listdir(kind_root)
for img_path in images_path:
img = Image.open(os.path.join(kind_root,img_path)).convert("RGB")
img = torchvision.transforms.ToTensor()(img)
x.append(img)
y.append(label)(2)使用自定义Dataset 动态加载
class MyDataset(Dataset):
def __init__(self, root):
self.root = root
self.image_paths = []
self.labels = []
self.label_to_int = {}
self.int_to_label = {}
for kind in os.listdir(self.root):
label = len(self.label_to_int)
self.label_to_int[kind] = label
self.int_to_label[label] = kind
kind_root = os.path.join(root, kind)
for img_path in os.listdir(kind_root):
self.image_paths.append(os.path.join(kind_root,img_path))
self.labels.append(label)
def __getitem__(self, idx):
image = Image.open(self.image_paths[idx]).convert("RGB")
image = torchvision.transforms.ToTensor()(image)
label = self.labels[idx]
return image, label
def __len__(self):
return len(self.labels)(3)注意事项
字符串标签需要转换成非负整数标签,可以用字典来存储两者之间的映射关系。在上述示例中,label_to_int和int_to_label用于存储这种映射关系。
二、数据预处理
1.标准化
- 先检查数据是否已经标准。
- 如果数据处于0-255之间,可以直接除以255。
- 如果需要其他的数值范围,具体情况具体分析。
2.分割数据
- 数据集通常划分为训练、验证、测试三个数据集。
- 训练集和验证集用于模型训练,测试集用于模型测试。
- 验证集不是必须存在。
(1)使用PyTorch的random_split
train_size = int(0.8*len(data_train))
val_size = len(data_train) - train_size
data_train, data_val = random_split(data_train, [train_size, val_size])(2)使用sklearn的train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y,test_size=0.2, shuffle=True)3.创建数据加载器
(1) 对于Dataset缓存数据,直接创建DataLoader
batch_size = 32
dataloader_train = DataLoader(data_train, batch_size=batch_size, shuffle=True)
dataloader_val = DataLoader(data_val, batch_size=batch_size, shuffle=True)
dataloader_test = DataLoader(data_test, batch_size=batch_size, shuffle=True)(2) 对于列表缓存数据,先整合数据到Dataset,再创建DataLoader
batch_size = 32
dataloader_train = DataLoader(StackDataset(x_train,y_train),
batch_size=batch_size, shuffle=True)
dataloader_test = DataLoader(StackDataset(x_test,y_test),
batch_size=batch_size, shuffle=True)三、配置模型
1.创建模型实例
model = torchvision.models.resnet18()
model.fc = nn.Linear(model.fc.in_features, 10)2.加载模型到指定硬件设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)3.创建损失函数、优化器、调度器实例
loss_function = nn.CrossEntropyLoss()
opt = Adam(model.parameters(), lr=1e-3)
scheduler = lr_scheduler.StepLR(opt, step_size=5, gamma=0.5)4.查看模型结构(torchinfo.summary)
summary(model, input_size=(batch_size,3, 32, 32))四、模型训练
1.设置回合数,并创建一些列表缓存训练历史
epochs = 10
losses_train = []
losses_val = []
accuracies_train = []
accuracies_val = []2.训练与验证部分
for epoch in range(epochs):
print(f"------- Epoch {epoch} -------")
# train
model.train()
train_loss = 0
train_acc = 0
for images, targets in dataloader_train:
# load data to device
images = images.to(device)
targets = targets.to(device)
# predict
output = model(images)
loss = loss_function(output,targets)
# update parameters
opt.zero_grad() # reset gradient
loss.backward() # backpropagation
opt.step() # update
# evaluate
train_loss += loss.item()
train_acc += torch.sum(torch.argmax(output,dim=1) == targets).item()/batch_size
print(f"Train Loss: {train_loss/len(dataloader_train)}")
print(f"Train Accuracy: {train_acc/len(dataloader_train)}")
losses_train.append(train_loss/len(dataloader_train))
accuracies_train.append(train_acc/len(dataloader_train))
scheduler.step()
# validate
model.eval()
val_loss = 0
val_acc = 0
for images, targets in dataloader_val:
with torch.no_grad(): # disable gradient calculation
# load data to device
images = images.to(device)
targets = targets.to(device)
# predict
output = model(images)
loss = loss_function(output,targets)
# evaluate
val_loss += loss.item()
val_acc += torch.sum(torch.argmax(output,dim=1) == targets).item()/batch_size
print(f"Val Loss: {val_loss/len(dataloader_val)}")
print(f"Val Accuracy: {val_acc/len(dataloader_val)}")
losses_val.append(val_loss/len(dataloader_val))
accuracies_val.append(val_acc/len(dataloader_val))3.绘制历史数据图表
(1)损失
plt.plot(range(epochs), losses_train)
plt.title("Train Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()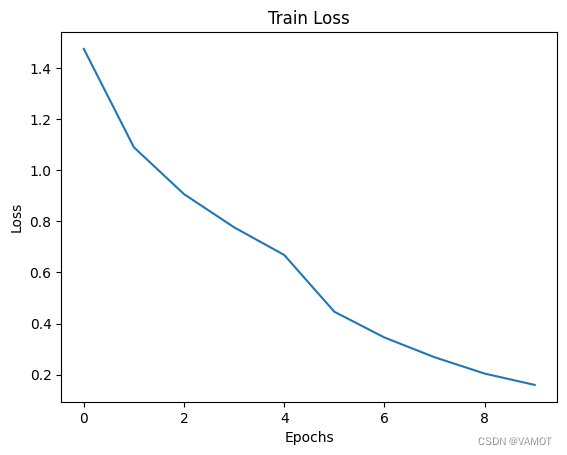
(2) 准确率
plt.plot(range(epochs), accuracies_train)
plt.title("Train Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.show()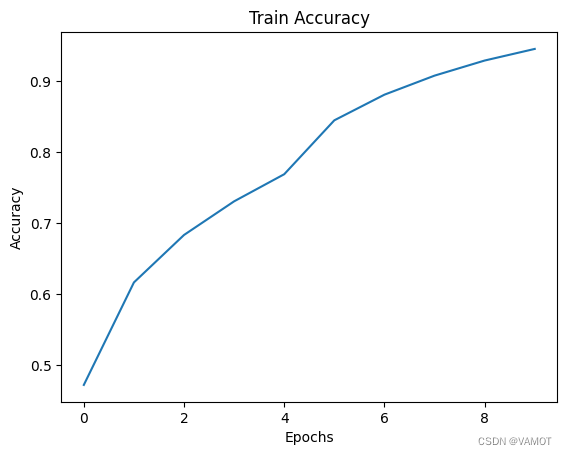
五、模型测试
model.eval()
test_loss = 0
test_acc = 0
for images, targets in dataloader_test:
with torch.no_grad(): # disable gradient calculation
# load data to device
images = images.to(device)
targets = targets.to(device)
# predict
output = model(images)
loss = loss_function(output,targets)
# evaluate
test_loss += loss.item()
test_acc += torch.sum(torch.argmax(output,dim=1) == targets).item()/batch_size
print(f"Test Loss: {test_loss/len(dataloader_test)}")
print(f"Test Accuracy: {test_acc/len(dataloader_test)}")六、引入
import torch
import torch.nn as nn
import torchvision
from torchvision.transforms import ToTensor
from torch.optim import Adam, lr_scheduler
from torch.utils.data import DataLoader, random_split
from torchinfo import summary
import matplotlib.pyplot as plt
import os
from PIL import Image
from torch.utils.data import Dataset七、视频版及代码文件
视频版: PyTorch图像分类系列——流程概览_哔哩哔哩_bilibili
代码文件: https://download.csdn.net/download/weixin_48633207/89492296
















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











