






你有没有遇到过这种情况:视频号里的视频居然没有直接的下载链接,想把喜欢的视频保存下来或者提取里面的文字内容,却不知道从何下手?别担心!今天我就来分享两个超实用的小技巧,让你轻松搞定视频号里的视频和文案提取。一起来看看吧!
第一种:提文案助手(简单高效)
今天给大家介绍一个超实用的工具——提文案助手。它专门为咱们自媒体从业者量身打造,能让你轻松搞定视频中的文案提取,简直是效率提升的好帮手!
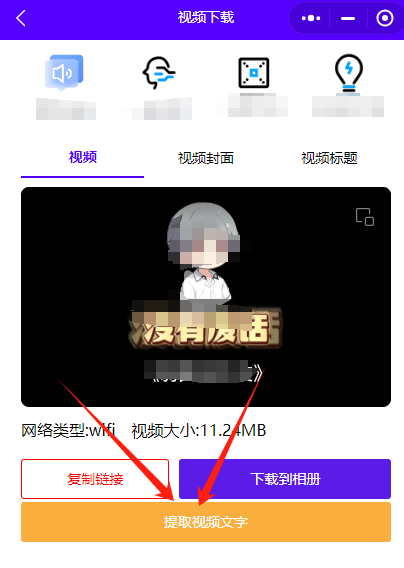
第一步:上传或转发你的视频或链接
提文案助手支持三种方式解析内容:你可以直接上传本地的视频文件,或者输入你想要解析的视频链接,视频号也支持一键提取文案。是不是很方便?
第二步:快速提取视频号文案
提文案助手收到你的视频后,后自主解析处理提取文案,你只需要等待1-2秒,点击复制即可。这个工具是专门为视频号文案提取而设计。转发视频給提文案助手可以直接从视频号中提取文案,操作简单快捷,省去了你手动打字的麻烦
第三步:直观的操作页面
整个操作页面设计得非常简单直观,即使你是技术小白,也能轻松上手。不需要复杂的设置和步骤,几分钟就能搞定。
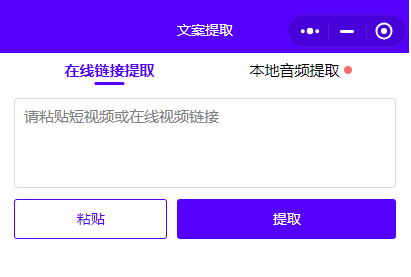
第二种:录屏内容上传第三方文案提取工具
1.录制视频:录制通过手机、电脑、平板等带有录屏功能的设备,开启录屏功能后播放完整视频即可录制完成。
2.上传音频:将提取的音频文件上传到语音识别工具或软件中,例如提取王。
3.运行工具识别:启动语音识别工具,运行语音识别过程。根据工具的不同,可能需要配置一些设置,如语言选择等。
4.获取文案:视频转文字工具将输出转换后的文字文案。您可以将这些文字复制到文本编辑器中进行进一步处理。
第三种:手动记录
这是最基础、最传统的一种方法,主要是边播放视频边手动记录。准备好耳机和文本编辑器,一边播放一边打字记录。这种方法的优势在于准确性和灵活性,但需要耗费大量的时间和精力,人工成本极高。
这三种从视频号里提取文案的方法都试过了吧?个人觉得第一种最香,操作简单又方便。咱们搞自媒体创作的,善用工具真的能省不少力气,达到事半功倍的效果。希望这篇小分享能对你有点帮助!

















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









