







 该文介绍了通过等距插点方法对形状轮廓进行离散化,并使用Jaccard相似度来评估采样点数量对形状保留程度的影响。通过Python的geopandas和shapely库,计算不同采样点下的Jaccard相似度,找出最佳采样策略。此方法能更精确地反映形状的增减变化,适用于地理空间数据处理和图像分析。
该文介绍了通过等距插点方法对形状轮廓进行离散化,并使用Jaccard相似度来评估采样点数量对形状保留程度的影响。通过Python的geopandas和shapely库,计算不同采样点下的Jaccard相似度,找出最佳采样策略。此方法能更精确地反映形状的增减变化,适用于地理空间数据处理和图像分析。
简介
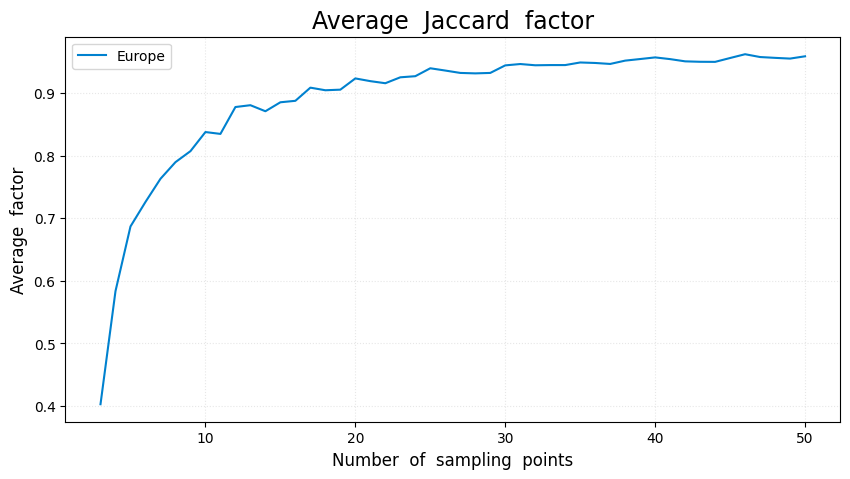
采用沿轮廓等距插点的方法对形状轮廓进行离散化,按照预定义的序列长度,在形状轮廓上进行等距采样,并计算采样点组成的形状和原始形状之间的Jaccard相似度,计算不同采样点的平均Jaccard相似度,确定最佳采样点。
Jaccard相似度是一种衡量有限样本集之间的相似性和差异的指标,通常用于计算集合的相似性、字符串相似性等。其定义为两个集合间交集和并集的比值,假设A和B是两个样本集合,则Jaccard相似度公式为:
J
(
A
,
B
)
=
∣
A
⋂
B
∣
∣
A
⋃
B
∣
J(A,B) = \frac{\mid A \bigcap B \mid}{\mid A \bigcup B \mid}
J(A,B)=∣A⋃B∣∣A⋂B∣
相比于制图综合中按照面积差的绝对值作为形状综合质量评价的指标,Jaccard相似度更能体现形状的损失情况,包括其增量和减量的区域。
代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import geopandas as gpd
from shapely import geometry as geo
'''定义函数:根据采样点数生成新多边形'''
def sampling_point_to_line(data_gdf, num_points):
# 创建一个空的GeoDataFrame来存储生成的多边形的轮廓
polygons = gpd.GeoDataFrame()
# 遍历每个面要素
for index, row in data_gdf.iterrows():
# 提取多边形的边界
boundary = row['geometry'].boundary
# 计算边界的总长度
boundary_length = boundary.length
# 设置点的距离间隔
distance_interval = boundary_length / num_points
# 生成等距离的点
points = []
for i in range(num_points):
point = boundary.interpolate(i * distance_interval)
points.append(point)
# 将第一个点添加至末尾防止不闭合
points.append(points[0])
# 生成线
line = geo.LineString(points)
# 转GeoDataFrame格式
gdf_line = gpd.GeoDataFrame(geometry=[line], crs=data_gdf.crs)
try:
gdf_line['FID'] = row['FID']
except:
gdf_line['name'] = row['name']
#将每个面轮廓线存入新的GeoDataFrame
polygons = pd.concat([gdf_line, polygons])
# 线转面
polygons['geometry'] = polygons['geometry'].apply(lambda x: geo.Polygon(x))
return polygons
'''采样并计算jaccard系数'''
# 使用geopandas自带的数据
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres')) # 世界地图
europe = world[world.continent == 'Europe'] # 欧洲地图
RUS_index = europe[europe.name == 'Russia'].index.tolist()[0] # 俄罗斯索引
europe1 = europe.drop(index=RUS_index).to_crs('32633') # 世界地图转投影
europe1['area'] = europe1.area # 计算每个国家的面积
# 存储采样后的数据
df = pd.DataFrame()
df = europe1['name']
df = pd.merge(df,europe1[['name','area']],on='name',how='left')
# 采样
for num in range(3,31):
europe2 = sampling_point_to_line(europe1,num) # 调用采样函数
europe2['area_'+str(num)] = europe2.area # 计算每个国家的面积
europe3 = gpd.overlay(europe1, europe2, how='intersection', keep_geom_type=True) # 计算两个地图的交集
europe3_continents = europe3.dissolve(by='name_1') # 按照国家名称进行融合
europe3_continents['area_'+str(num)+'_overlay'] = europe3_continents.area # 计算每个国家的面积
europe3_continents['name'] = europe3_continents.index # 重置索引
df = pd.merge(df, europe2[['name','area_'+str(num)]], on='name', how='left') # 合并数据
df = pd.merge(df, europe3_continents[['name','area_'+str(num)+'_overlay']], on='name', how='left') # 合并数据
df['jaccard_'+str(num)] = df['area_'+str(num)+'_overlay'] / (df['area'] + df['area_'+str(num)] - df['area_'+str(num)+'_overlay']) # 计算jaccard系数
df_jaccard = df[['jaccard_'+str(num) for num in range(3,31)]] # 提取jaccard系数
'''制图'''
df_jaccard1 = df_jaccard.apply(np.sum,axis=0)/len(df_jaccard) # 求均值
df_jaccard2 = df_jaccard1.reset_index(drop=True) # 重置索引
df_jaccard2.index = df_jaccard2.index + 3
# 绘图
df_jaccard2.plot(label='Europe',color='#0081CF',figsize=(10,5))
plt.xticks(size=10)
plt.yticks(size=10)
plt.xlabel('Number of sampling points',size=12)
plt.ylabel('Average factor',size=12)
plt.grid(ls=':',alpha=0.3)
plt.legend(loc='best',prop={'size':10})
plt.title('Average Jaccard factor',size=17)
plt.show()
结果
参考
[1]郑建滨. 基于深度学习的建筑形状匹配方法研究[D].武汉大学,2019.

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









