







 本文介绍了使用PyTorch进行图像分类项目中的关键步骤,包括数据预处理(如读取、增强和标准化),构建ImageFolder和DataLoader,以及网络构建和模型训练。通过数据增强技术扩展了训练数据集,提升模型性能。
本文介绍了使用PyTorch进行图像分类项目中的关键步骤,包括数据预处理(如读取、增强和标准化),构建ImageFolder和DataLoader,以及网络构建和模型训练。通过数据增强技术扩展了训练数据集,提升模型性能。
目录
1.导入各种库
上代码:
import os
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
#pip install torchvision
from torchvision import transforms, models, datasets
#https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image2.数据预处理
2.1数据读取
先看以下训练集和验证集存放的位置:


上代码:
data_dir = './flower_data/'
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'2.2图像增强
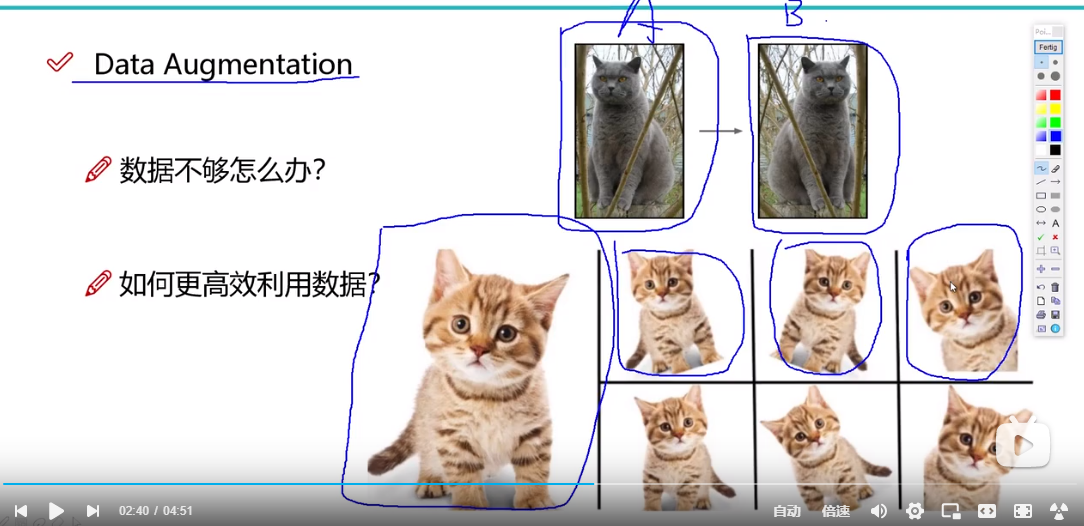
目的:我们所收集准备训练的数据都是很可贵的,数据越多成本也就越高,所以希望将有限的数据集最大化利用,这就时图像增强的目的。
定义:如下图小灰猫,进行翻转操作,小黄猫,进行不同角度的旋转操作,这样实现了一图多用的效果,在原数据的基础上,将数据集翻了几倍。比方说你现在有一个1w的数据集,经过数据增强,可以完成10w的数据集。
上代码:
data_transforms = {
'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪(224×224),因为训练集收集的图大小可能不同,但神经网络需要同样大小的输入.
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率,p=0.5就是说,有50%概率执行该操作。
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(), #将数据转化成tensor格式输入
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#因为本例是要用别人的模型训练,所以要参考别人例子中提供的均值,标准差,对自己的的训练集进行标准化操作。
]),
'valid': transforms.Compose([transforms.Resize(256), #验证集不需要做数据增强,其他处理方法和train一样。
transforms.CenterCrop(224), #验证集数据裁剪成和训练集一样,才能对比
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}3.构建数据网络
3.1网络构建
batch_size = 8
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']} # 构建分类任务数据集,注意不同任务数据集构建方式不同。
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']} # 按照batch_size = 8大小加载数据。
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']} # 看一下数据的数量,该例'train': 6552, 'valid': 818
class_names = image_datasets['train'].classes3.2读取标签对应的名字
网络最后的输出是一个代表类别的数值,比方说1,2,3,但我们希望看到这个数值对应的类别,所以json存这些信息,比方说{'1': 'pink primrose'}。
with open('cat_to_name.json', 'r') as f:
cat_to_name = json.load(f) 4.展示数据
4.1数据转换
注意:进行训练时需要tensor格式的数据,所以展示的时候tensor的数据需要转换成numpy的格式,而且还需要还原回标准化的结果。
def im_convert(tensor): #im_convert转化函数
""" 展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1,2,0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
image = image.clip(0, 1)
return image4.2画图
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2
dataiter = iter(dataloaders['valid'])
inputs, classes = dataiter.next()
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))])
plt.imshow(im_convert(inputs[idx]))
plt.show()
















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









