






强化学习
1 定义
1.1 名称
强化学习、再励学习、评价学习或增强学习
Reinforcement Learning
RL
1.2 定义
强化学习是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略来实现收益最大化或实现特定目标的问题。
概括
- 强化学习是一种机器学习方法
- 强化学习关注智能体与环境之间的交互
- 强化学习是为了追求最大收益或实现特定目标
智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖励来指导行为,目标是使智能体获得最大的奖励。
1.3 与其它机器学习放方法的区别
- 监督学习:监督学习训练集中的每一个样本都带有标签,也就是正确的分类结果或实际值。监督学习的任务是通过对正确样本的学习构建一个模式来推断未知实例。当标签是有离散值(有限的一组值)时,判断实例的类别,称为分类问题,当标签为连续值(范围内无限的值)时,输出为实例的预测值,称为回归问题。
- 无监督学习:无监督学习训练集中的每一个样本都不带标签。无监督学习的任务是从无标签的数据集中发现隐藏的结构,将相似度高的样本聚集在一起,构建一个模式来推断未知实例。常用来解决聚类问题。
- 半监督学习:将监督学习和无监督学习融合在一起,训练集中既有带标签的样本,又有不带标签的样本。
- 强化学习:强化学习训练时不需要训练样本带标签,但需要环境给予反馈和具体的反馈值来作为评判智能体行为的标准,而不是通过标签训练智能体做出正确决策。强化学习主要任务是通过不断与环境交互、试错,指导训练对象每一步如何决策,采用什么样的行动可以完成特定的目的或者使收益最大化。
1.4 主要特点
- 试错学习:强化学习需要训练对象不停地和环境交互,通过试错的方式去总结出每一步的最佳行为决策,整个过程没有指导,只有反馈
- 延迟反馈:反馈可能等到训练结束才会出现,应该尽可能拆解训练过程,使每一步都能给出反馈
- 时间是强化学习的一个重要因素:强化学习环境状态的变化和反馈等都是与世界关联的。整个强化学习的训练过程随着时间变化,状态、反馈也在不停变化。
- 当前的行为影响后续接收到的数据:在监督学习和半监督学习中,每条训练数据都是独立的,相互之间没有任何关联。但是在强化学习中,当前状态以及采取的行动,将会影响下一步接收到的状态。数据与数据之间存在一定的关联性。
2 基本模型和原理
2.1 组成部分
Agent(智能体、机器人、代理):强化学习训练的主体,例如五子棋中的棋手。
- 特征:适应未知环境
- 关键属性:学习能力
Environment(环境):整个游戏的大背景就是环境
State(状态):当前Environment和Agent所处的状态,包含了Agent和Environment的状态。例如,当前棋局,包括了两方所有的棋子,以及量化的优劣势情况
- 分类
- 完全可观测的(fully observed):通常建模程马尔可夫决策过程(MDP)。其中 O t = S t e = S t a O_t=S^e_t=S^a_t Ot=Ste=Sta,即智能体的状态跟环境的状态等价的时候。
- 部分可观测的(partially observed):是智能体得到的观测并不能包含环境运作的所有状态(如:自动驾驶汽车,汽车的状态仅仅是传感器可探查的数据)。其通常采用部分可观测马尔科夫决策过程
Action(行动):基于当前的State,Agent可以采取哪些Action。例,棋手在某棋局下可以下落棋子的位置为Action
- 分类
- 离散动作空间(discrete action space):智能体的动作数量是有限的
- 连续动作空间(continuos action space):在连续空间中,动作是实值的向量
Reward(奖励):Agent在当前State下,采取了某个特定的action后,会获得环境的一定反馈。反馈可能是奖励也可能是惩罚。例如,本手、妙手、俗手对应于不同的奖励,对方连了个杀棋应给与惩罚
-
理解
-
奖励是一个标量的反馈信号
-
它能表征在某一步智能体的表现如何
-
智能体的任务就是使得一个时段内积累的总奖励值最大
-
模型(Model):模型是对环境的模拟;当给出了状态与行为后,有了模型就可以预测接下来的状态和对应的奖励。例如五子棋规则,胜利规则、活三、冲四、拦截、禁手等
-
理解
-
模型可以预测环境下一步的表现
-
表现具体可由预测的状态和奖励来反映
-
策略(Policy):Agent在某状态下决定采取何种动作。例,Agent根据当前棋局判断在何处落子可以使收益最大
-
理解
-
策略定义智能体的行为
-
它是从状态到行为的映射
-
策略本身可以是具体的映射也可以是随机的分布
-
-
分类
- 随机性策略(stochastic policy): π \pi π函数 π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s)=P(A_t=a|S_t=s) π(a∣s)=P(At=a∣St=s),表示在状态 s s s下输出动作为 a a a的概率。然后通过采样得到一个动作。
- 确定性策略(deterministic policy):采取最有可能的动作,即 a ∗ = a r g max a π ( a ∣ s ) a^*=arg \max_a \pi(a|s) a∗=argmaxaπ(a∣s), π ∗ = a r g m a x π V π ( s ) , ∀ s ∈ S \pi^*=\mathop {argmax}_\pi V^\pi(s),\forall s\in S π∗=argmaxπVπ(s),∀s∈S
价值函数、值函数(Value Function):价值函数是未来奖励的一个预测,用来评估状态的好坏。
- 折扣因子:希望尽可能在短的时间里面得到尽可能多的奖励。
- 分类
(1)状态价值函数(state-value function):表示在
π
\pi
π策略下,状态
s
s
s的价值函数。
v
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
,
∀
s
∈
S
v_\pi(s)=E_\pi[G_t|S_t=s]=E_\pi[\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}|S_t=s] \ , \forall \ s \in S
vπ(s)=Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1∣St=s] ,∀ s∈S
(2)动作状态价值函数(state-action-value function):表示采取策略
π
\pi
π时,在状态
s
s
s发生动作
a
a
a下,未来可以获得的奖励
q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
q_\pi(s,a)=E_\pi[G_t|S_t=s,A_t=a]=E_\pi[\sum_{k=0}^{\infty}\gamma^k R_{t+k+1}|S_t=s,A_t=a]
qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[k=0∑∞γkRt+k+1∣St=s,At=a]
(3)Q函数和V函数的关系:v函数表示在状态
s
s
s下,采取所有可能动作的未来奖励之和。
v
π
(
s
)
=
∑
a
∈
A
t
q
π
(
s
,
a
)
v_\pi(s)=\sum_{a \in A_t} q_\pi(s,a)
vπ(s)=a∈At∑qπ(s,a)
2.2 基本过程
强化学习的目的为选择action用以最大化所有未来的reward(reward之和,即value)
每 t t t时刻
-
Agent完成以下过程
- 执行动作 A t A_t At,影响环境观
- 接受到状态 S t S_t St
- 收到环境反馈的奖励 R t R_t Rt
-
Environment完成以下工作
- 接收动作 A t A_t At
- 更新状态 S t + 1 S_{t+1} St+1
- 产生奖励 R t R_t Rt
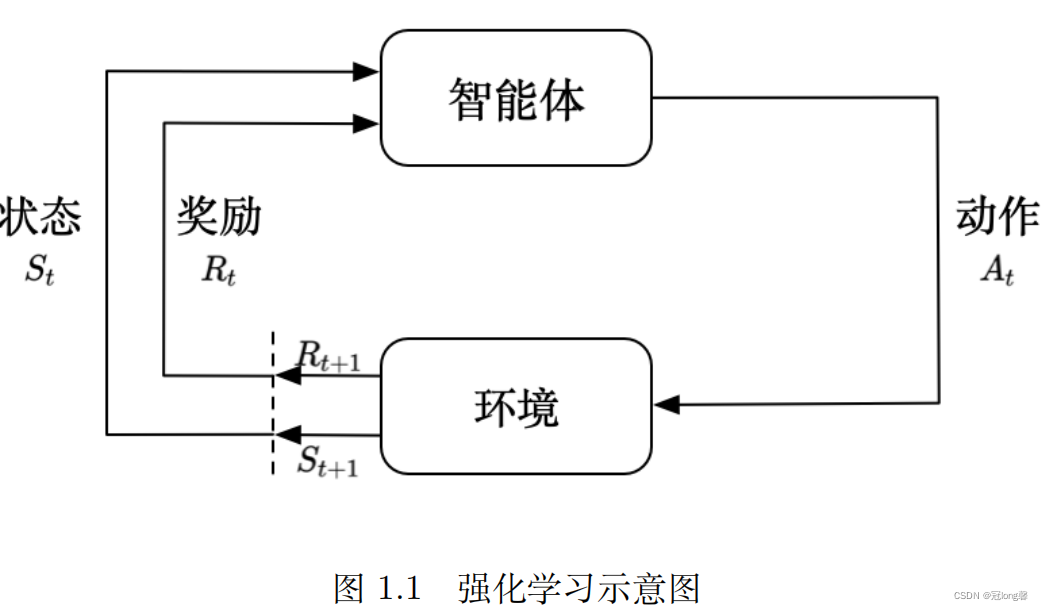
agent和environment 之间并不是严格的物理界限,比如一个机器人和外界这样的关系,当我们考虑机器人如何决策时(如决定往哪前进),机器人的决策部分作为一个agent,而他的控制系统则可以看做是environment的一部分。
从环境状态到动作映射的学习,以使动作从环境中获得的累积奖赏值最大该方法不同于监督学习技术那样通过正例、反例来告知采取何种行为,而是通过试错来发现最优行为策略。
2.3 基本原理
马尔可夫链:二十世纪初,数学家Andrey Markov 研究的没有记忆的随机过程。这样的过程具有固定数量的状态,并且在每个步骤中随机地从一个状态演化到另一个状态。它从状态
S
S
S演变为状态
S
′
S'
S′ 的概率是固定的,它只依赖于
(
S
,
S
′
)
(S,S')
(S,S′)对,而不是依赖于过去的状态(系统没有记忆)。
一个具有四个状态的马尔可夫链的例子。假设该过程从状态
S
0
S_0
S0开始,并且在下一步骤中有 70% 的概率保持在该状态不变中。最终,它必然离开那个状态,并且永远不会回来,因为没有其他状态回到
S
0
S_0
S0。如果它进入状态
S
1
S_1
S1,那么它很可能会进入状态
S
2
S_2
S2(90% 的概率),然后立即回到状态
S
1
S_1
S1 (以 100% 的概率)。它可以在这两个状态之间交替多次,但最终它会落入状态
S
3
S_3
S3并永远留在那里(这是一个终端状态)。
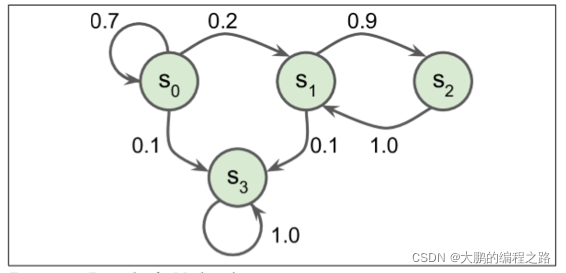
理解:像是图搜索,如果不记录是否搜索过某结点可能一直搜下去,马尔科夫链可以看作在无记忆的图搜索上加上搜索某节点的概率
马尔可夫决策过程(Markov Decision Process, MDP)
马尔可夫决策过程最初是在 20 世纪 50 年代由 Richard Bellman 描述的。它们类似于马尔可夫链,但有一个连结:在状态转移的每一步中,一个智能体可以选择几种可能的动作中的一个,并且转移概率取决于所选择的动作。此外,一些状态转移返回一些奖励(正或负),智能体的目标是找到一个策略,随着时间的推移将最大限度地提高奖励。
马尔可夫决策过程是基于马尔可夫过程的决策模型。MDP是状态(state)集
S
S
S、行为(action)集
A
A
A、状态转移概率(state transference概率)矩阵
P
P
P、补偿(response)函数
R
R
R、折扣因子
γ
\gamma
γ配置。
M
D
P
=
(
S
,
A
,
P
,
R
,
γ
)
M D P=(S, A, P, R, \gamma)
MDP=(S,A,P,R,γ)
状态集是
M
D
P
MDP
MDP可以具有的所有状态集
S
=
S
1
、
S
2
.
.
.
S
t
S={S _1、S_ 2... S_t}
S=S1、S2...St 。如下所示,任何时刻的状态
S
t
S_ t
St 都将成为状态集
S
S
S中包含的特定状态。
S
t
=
s
,
s
∈
S
S_{t}=s, s \in S
St=s,s∈S
行为集是作为行为主体的Agent可以执行的所有行为的集合
A
=
a
1
、
a
2
、
…
、
a
∣
A
∣
A=a1、a2、…、a|A|
A=a1、a2、…、a∣A∣。代理在某个时间点采取行动
A
t
=
a
,
a
∈
A
At=a,a∈A
At=a,a∈A 。
M
D
P
MDP
MDP中的状态转移概率比马尔可夫过程中的状态转移概率稍微复杂一些。$ MDP$中的状态转移概率公式如下:
P
s
,
s
′
a
=
P
(
S
t
+
1
=
s
′
∣
S
t
=
s
,
A
t
=
a
)
P_{s, s^{\prime}}^{a}=\mathbb{P}\left(S_{t+1}=s^{\prime} \mid S_{t}=s, A_{t}=a\right)
Ps,s′a=P(St+1=s′∣St=s,At=a)
P
s
,
s
′
a
P_{s,s^{'}}^a
Ps,s′a是当代理在某个状态下采取行为
a
a
a时变为状态
s
′
s'
s′的概率。
补偿函数用于补偿代理在任何状态下所采取的行为。其公式如下:
R
s
a
=
E
[
R
t
+
1
∣
S
t
=
s
,
A
t
=
a
]
R_{s}^{a}=\mathbb{E}\left[R_{t+1} \mid S_{t}=s, A_{t}=a\right]
Rsa=E[Rt+1∣St=s,At=a]
补偿函数返回在
R
s
a
R_{s}^{a}
Rsa 状态
s
s
s中执行行为
a
a
a时的补偿期望值。折扣因子是一个介于0和1之间的值,用于确定对过去行为的反映程度。折扣因素
γ
\gamma
γ如果是1,则为
<
1
、
1
、
1
、
1
和
1
<1、1、1、1和1
<1、1、1、1和1,并为折扣因素
γ
\gamma
γ如果是0.9,则
<
1
、
0.9
、
0.81
、
0.729
、
0.6561
>
<1、0.9、0.81、0.729、0.6561>
<1、0.9、0.81、0.729、0.6561>。也就是说,越是对遥远过去的补偿,越是削减并反映。
代理必须确定在任何状态下执行的行为
a
a
a,称为策略(policy),策略
π
π
π将朝着最大化总补偿的方向更新
π
(
a
∣
s
)
=
P
(
A
t
=
a
∣
S
t
=
s
)
\pi(a \mid s)=\mathbb{P}\left(A_{t}=a \mid S_{t}=s\right)
π(a∣s)=P(At=a∣St=s)
如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。Agent的目标是在每个离散状态发现最优策略以使期望的折扣奖赏和最大。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
2.4 算法原理
组成
-
状态感知器I
把环境状态s映射成内部感知i。
-
学习器L
根据环境状态的奖赏值r以及内部感知i,更新的策略知识W。
-
动作选择器P
根据当前策略选择动作a作用于环境W。
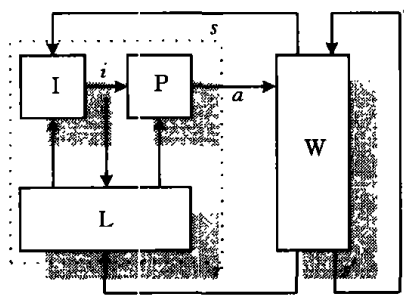
基本原理:如果agent的某个动作导致环境正的奖赏强化信号,那么agent以后产生这个动作的趋势便会加强,反之agent产生这个动作的趋势减弱。
强化学习的目标:学习行为策略 π : S → A \pi:S\to A π:S→A,使agent选择的动作能获得最大的奖赏。
考虑agent的长期行为,使agent获得长期或者最终的最大奖赏,而不是短期内最大奖赏。
目标函数:表明从长期的观点确定什么是优的动作。
表示:状态的值函数或状态—动作函数对的值函数。
- 无限折扣模型:考虑未来无限步的奖赏,并以某种形式的折扣累积在值函数中。
V π ( s t ) = ∑ i = 0 ∞ γ i r t + i , 0 < γ ≤ 1 V^\pi(s_t)=\sum_{i=0}^\infty\gamma^ir_{t+i},0<\gamma\le1 Vπ(st)=i=0∑∞γirt+i,0<γ≤1
- 有限模型:只考虑未来步的奖赏和。
V π ( s t ) = ∑ t = 0 h r i V^\pi(s_t)=\sum_{t=0}^hr_i Vπ(st)=t=0∑hri
- 平均奖赏模型:考虑其长期平均奖赏。
V π ( s t ) = lim h → ∞ ( 1 h ∑ t = 0 h r t ) V^\pi(s_t)=\lim_{h\to\infty}(\frac1h\sum_{t=0}^hr_t) Vπ(st)=h→∞lim(h1t=0∑hrt)
由目标函数
V
π
(
s
t
)
V^\pi(s_t)
Vπ(st)确定最优行为策略。
π
∗
=
a
r
g
m
a
x
π
V
π
(
s
)
,
∀
s
∈
S
\pi^*=\mathop {argmax}_\pi V^\pi(s),\forall s\in S
π∗=argmaxπVπ(s),∀s∈S
2.5 目标
强化学习系统学习的目标是动态地调整参数,以达到强化信号最大。若已知 r / A r/A r/A梯度信息,则可直接可以使用监督学习算法。因为强化信号 r r r与Agent产生的动作A没有明确的函数形式描述,所以梯度信息 r / A r/A r/A无法得到。因此,在强化学习系统中,需要某种随机单元,使用这种随机单元,Agent在可能动作空间中进行搜索并发现正确的动作。
学习从环境状态到行为的映射,使得智能体选择的行为能够获得环境最大的奖赏,使得外部环境对学习系统在某种意义下的评价(或整个系统的运行性能)为最佳。
2.6 任务
强化学习的两类任务
- 非顺序型任务:当agent学习环境状态空间到agent行为空间的映射时,agent的动作会瞬时得到环境奖赏值,而不影响后继的状态和动作。
- 顺序型任务:agent采用的动作可能影响未来的状态和未来的奖赏报酬在这种情况下,agent需要在更长的时间周期内与环境交互,估计当前动作对未来状态的影响。
2.7 与其他技术的差别
强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是Agent对所产生动作的好坏作一种评价(通常为标量信号),而不是告诉Agent如何去产生正确的动作。由于外部环境提供了很少的信息,Agent必须靠自身的经历进行学习。通过这种方式,Agent在行动一一评价的环境中获得知识,改进行动方案以适应环境。监督学习技术,强化学习是在线学习技术,不需要事先提供训练例,监督学习很难实现在线学习。
规划技术,规划需要构造复杂的状态图,而强化学习只需要记忆其所处的环境状态和当前策略知识;其次,规划技术总假定环境是稳定的,和环境的交互作用可以通过某种搜索过程来预测。由于规划技术并没有真正地考虑行为如何适应环境的问题,其只适用于系统完全了解并可控制的环境相反强化学习强调系统与环境的交互作用因此,强化学习技术比规划技术适用面更广。
自适应控制技术,本质是参数估计问题,都有共同的奖赏函数形式。自适应控制中,尽管不能事先确定系统的动态模型,但系统模型必须可以从统计数据中估计,而且系统的动态模型必须是固定的。
3 分类
3.1 按照是否有模型
**基于模型(Model-based)**中Agent理解整个游戏环境、能够预测接下来的所有情况,并能做出最好的选择。这种模型变成了一个动态规划的问题,可以直接应用贪心算法求解
**无模型(Model-free)**不依赖于模型,通过随机试错来获取环境反馈,由此得到经验,进而采取下一步动作。不对环境进行建模也能找到最优的策略
如果在Agent在 s s s状态下,执行 a a a动作之前就可以预测下一步状态和奖励,就是Model-based方法;否则是Model-free方法
3.2 按照原理
**基于策略(Policy-based)**是通过对策略抽样训练出一个概率分布,并增强回报值高的动作被选中的概率。算法:Policy Grandients。适用于连续的Action空间,每个State对应的Action不一定固定
**基于值(Value-based)**是通过潜在奖励计算出动作回报期望来作为选取动作的依据。算法:Q-Learning、SARSA(State-Action-Reward-State-Action)。适用于离散的Action空间
**Actor-Critic(AC)**将Value-Based和Policy-Based结合在一起
3.3 按照更新方式
**回合更新(Monte-Cario Update)**指的是游戏开始后,要等到打完这一局我们才对这局游戏的经历进行总结学习新的策略。每次训练结束才给出反馈,缺点是训练需要的数据量大,时间久,
**单步更新(Temporal-Difference Update)**是在游戏进行中每一步都在更新,这样就可以一边游戏一边学习不用等到回合结束。在训练中的每次Agent执行动作环境都做出反馈,缺点是可能导致局部最优
我认为可以在合适粒度上让环境做出反馈,比如Agent每做出几次动作反馈一次,使训练时间和训练效果平衡
3.4 按照学习方式
在线学习是指Agent必须在场,且必须是边训练边学习。算法:Sarsa和Sarsa(λ)
离线学习是指可以训练Agent,也可以让Agent观看对局。通过看着别人对局,学习行为准则,类似于读书或者听课。算法:Q Learning和Deep Q Network
3.5 深度强化学习
将深度学习模型应用在强化学习中
3.6 网络模型设计
每一个自主体是由两个神经网络模块组成,即行动网络和评估网络。行动网络是根据当前的状态而决定下一个时刻施加到环境上去的最好动作。
对于行动网络,强化学习算法允许它的输出结点进行随机搜索,有了来自评估网络的内部强化信号后,行动网络的输出结点即可有效地完成随机搜索并且大大地提高选择好的动作的可能性,同时可以在线训练整个行动网络。用一个辅助网络来为环境建模,评估网络根据当前的状态和模拟环境用于预测标量值的外部强化信号,这样它可单步和多步预报当前由行动网络施加到环境上的动作强化信号,可以提前向动作网络提供有关将候选动作的强化信号,以及更多的奖惩信息(内部强化信号),以减少不确定性并提高学习速度。
进化强化学习对评估网络使用时序差分预测方法TD和反向传播BP算法进行学习,而对行动网络进行遗传操作,使用内部强化信号作为行动网络的适应度函数。
网络运算分成两个部分,即前向信号计算和遗传强化计算。在前向信号计算时,对评估网络采用时序差分预测方法,由评估网络对环境建模,可以进行外部强化信号的多步预测,评估网络提供更有效的内部强化信号给行动网络,使它产生更恰当的行动,内部强化信号使行动网络、评估网络在每一步都可以进行学习,而不必等待外部强化信号的到来,从而大大地加速了两个网络的学习。
3.6 按搜索(Exploration)或利用(Exploitation)
强化学习的两难问题:搜索(exploration)或利用(exploitation),即选择搜索未知的状态和动作搜索新的知识,还是利用已获得的、可以产生高回报的状态和动作。搜索新动作能够带来长期的性能改善,因此搜索可以帮助收敛到最优策略而利用可以帮助系统短期性能改善,但可能收敛到次优解上。
最优搜索型算法(exploration oriented):强调获得最优策略的强化学习算法。
经验强化型算法(exploitation oriented):强调获得策略性能改善的强化学习算法。
| 代表算法 | 最优搜索型 | 经验强化型 |
|---|---|---|
| 非马尔科夫环境 | 连续状态 多agent 部分感知 | 规则抽取 偏差技术 学习分类器 |
| 马尔科夫环境 |
T
D
(
λ
)
TD(\lambda)
TD(λ) Q学习 Dyna-Q | Q-PSP |
4 算法、方法、综述
4.1 按搜索利用
强化学习研究综述 高阳 2004
4.1.1 最优搜索型强化学习算法
马尔可夫决策过程:包含一个环境状态集 S S S,agent行为集合 A A A,奖赏函数 R R R和状态转移函数 T : S × A → P D ( S ) T:S\times A\to PD(S) T:S×A→PD(S)。记 R ( s , a , s ′ ) R(s,a,s') R(s,a,s′),为在状态 s s s采用 a a a动作使环境状态转移到 s ’ s’ s’获得的瞬时奖赏值;记 T ( s , a , s ′ ) T(s,a,s') T(s,a,s′)为在状态 s s s采用 a a a动作使环境状态转移到 s ’ s’ s’的概率。
马尔可夫随机过程
本质:当前状态向下一状态转移的概率和奖赏值只取决于当前状态和选择的动作,而与历史状态和历史动作无关。因此已知状态转移概率函数T和奖赏函数R的环境模型知识时,可以采用动规求解最优策略。而顺序型的问题有时间信度分配难题,不能采用动态规划解决,目前主流方法采用迭代技术调整当前和下一状态的值函数的估计值。
最优策略下的值函数
V
∗
(
s
)
=
max
a
(
γ
∑
s
′
∈
S
T
(
s
,
a
,
s
′
)
(
r
(
s
,
a
,
s
′
)
+
V
∗
(
s
′
)
)
)
,
∀
s
∈
S
V^*(s)=\max_a(\gamma\sum_{s'\in S}T(s,a,s')(r(s,a,s')+V^*(s'))),\forall s\in S
V∗(s)=amax(γs′∈S∑T(s,a,s′)(r(s,a,s′)+V∗(s′))),∀s∈S
V ( s ) = ( 1 − α ) V ( s ) + α ( r ( s , a , s ′ ) + γ V ( s ′ ) ) V(s)=(1-\alpha)V(s)+\alpha(r(s,a,s')+\gamma V(s')) V(s)=(1−α)V(s)+α(r(s,a,s′)+γV(s′))
通过Bellman迭代逼近最优策略下的值函数。一般通过修改 V ( s ) V(s) V(s)来满足学习速度和收敛性。
查bellman迭代
-
模型无关法(Model-Free):在学习过程中无需学习马尔可夫决策模型知识即函数和函数,而直接学习最优策略。由于没有充分利用每次学习中获取的知识,比基于模型的方法收敛慢很多。
-
TD算法
-
Q-学习
-
-
基于模型法(Model-Base):在学习过程中先学习模型知识,然后根据模型知识推导优化策略的方法。
-
Sarsa(改进的Q-学习算法)
-
Dyna-Q算法
-
4.1.1.1 TD算法
TD(Temporal Difference)学习:结合蒙特卡洛和动态规划思想,不需要系统模型就可以从agent经验学习,和动态规划一样利用估计值函数迭代。
一步TD算法(TD(0)算法):自适应测量迭代算法,agent获得瞬时奖赏值时只回退一步,即只迭代修改相邻状态的估计值。迭代公式:
V
(
s
t
)
=
V
(
s
t
)
+
α
(
r
t
+
1
+
γ
V
(
s
t
+
1
−
V
(
s
t
)
)
V(s_t)=V(s_t)+\alpha(r_{t+1}+\gamma V(s_{t+1}-V(s_t))
V(st)=V(st)+α(rt+1+γV(st+1−V(st))
- α \alpha α,学习率
- V ( s t ) V(s_t) V(st),状态值函数,agent在 t t t时刻访问环境状态 s t s_t st
- V ( s t + 1 ) V(s_{t+1}) V(st+1),状态值函数,agent在 t + 1 t+1 t+1时刻访问环境状态 s t + 1 s_{t+1} st+1
- r t + 1 r_{t+1} rt+1,瞬时奖励值,agent从状态 s t s_t st向状态 s t + 1 s_{t+1} st+1转移
过程:首先初始化 V V V值;然后agent在 s t s_t st状态,根据当前策略确定动作 a t a_t at,得到经验知识和训练例 < s t , a t , s t + 1 , r t + 1 > <s_t,a_t,s_{t+1},r_{t+1}> <st,at,st+1,rt+1>;其次根据此经验知识依据式(7)修改状态值函数。当agent访问到目标状态,算法终止一次迭代循环。算法继续从初始状态开始新的迭代循环,直至学习结束。
提出:1988,Sutton,Sutton R S. Learning to predict by the methods of temporal differences. Machine Learning,1988,3:9~44
当系统满足马尔可夫属性, α \alpha α绝对递减条件下,TD算法必然收敛。
局限:存在收敛慢的间题,原因:TD(0)中agent获得的瞬时奖赏值只修改相邻状态的值函数估计值。
方案:agent获得的瞬时奖赏值可以向后回退任意步,称为TD(
λ
\lambda
λ)算法,迭代公式
V
(
s
)
=
V
(
s
)
+
α
(
r
t
+
1
+
γ
V
(
s
t
+
1
−
V
(
s
t
)
)
e
(
s
)
V(s)=V(s)+\alpha(r_{t+1}+\gamma V(s_{t+1}-V(s_t))e(s)
V(s)=V(s)+α(rt+1+γV(st+1−V(st))e(s)
- e ( s ) e(s) e(s),状态 s s s的选举度,计算方法,
e ( s ) = ∑ k = 1 t ( λ γ ) t − k δ s , s k , δ s , s k = { 1 , if s = s k 0 , otherwise e(s)=\sum_{k=1}^t(\lambda\gamma)^{t-k}\delta_{s,s_k},\delta_{s,s_k}=\begin{cases}1,&\text{if}\ s=s_k\\0,&\text{otherwise}\end{cases} e(s)=k=1∑t(λγ)t−kδs,sk,δs,sk={1,0,if s=skotherwise
奖赏值向后船舶 t t t步,某状态历史的 t t t步中,若一个状态 s s s被多次访问,其选举度 e ( s ) e(s) e(s)越大,说明对当前的奖赏值的贡献最大,在通过迭代公式修改。
改进方法
e
(
s
)
=
{
γ
λ
(
s
)
+
1
,
if
s
是当前状态
γ
λ
(
s
)
,
otherwise
e(s)=\begin{cases}\gamma\lambda(s)+1,&\text{if}\ s\ \text{是当前状态}\\\gamma\lambda(s),&\text{otherwise}\end{cases}
e(s)={γλ(s)+1,γλ(s),if s 是当前状态otherwise
Sutton,1988
Sutton R S. Learning to predict by the methods of temporal differences. Machine Learning,1988,3:9~44
4.1.1.2 Q学习
Q-学习(Q-Learning),离策略TD学习(off-policy TD):模型无关,不同于TD算法,Q-学习迭代时采用状态一动作对的奖赏和 Q ∗ ( s , a ) Q^*(s,a) Q∗(s,a)作为估计函数,而非算法中的状态奖赏和 V ( s ) V(s) V(s),因此在每一次学习迭代时都需要考察每一个行为,可确保学习过程收敛。
基本形式
Q
∗
(
s
,
a
)
=
γ
∑
s
∈
S
′
T
(
s
,
a
,
s
′
)
(
r
,
a
,
a
s
′
)
+
max
a
′
Q
∗
(
s
′
,
a
′
)
)
Q
(
s
t
,
a
t
)
=
Q
(
s
t
,
a
t
)
+
α
(
r
t
+
1
+
γ
max
a
Q
(
s
t
+
1
,
a
)
−
Q
(
s
t
,
a
t
)
)
Q^*(s,a)=\gamma\sum_{s\in S'}T(s,a,s')(r,a,as')+\max_{a'}Q^*(s',a'))\\ Q(s_t,a_t)=Q(s_t,a_t)+\alpha(r_{t+1}+\gamma\max_aQ(s_{t+1},a)-Q(s_t,a_t))
Q∗(s,a)=γs∈S′∑T(s,a,s′)(r,a,as′)+a′maxQ∗(s′,a′))Q(st,at)=Q(st,at)+α(rt+1+γamaxQ(st+1,a)−Q(st,at))
Q
∗
(
s
,
a
)
Q^*(s,a)
Q∗(s,a) 表示在状态
s
s
s下采用动作
a
a
a所获得的最优奖赏折扣和。最优策略为
s
s
s状态下选用
Q
Q
Q值最大的行为。
步骤
- 初始化 Q Q Q值
- agent在 s t s_t st状态下根据 ϵ \epsilon ϵ-贪心算法确定动作 a a a,得到经验知识和训练例 < s t , a t , s t + 1 , r t + 1 > <s_t,a_t,s_{t+1},r_{t+1}> <st,at,st+1,rt+1>
- 根据有经验知识用上式修改 Q Q Q值。
- 当agrnt到达目标状态时,算法完成一次迭代循环
- 继续从初始状态开始迭代,知道学习结束
与TD算法的不同
- Q学习迭代的是状态动作的值函数
- Q学习中只需要采用贪心策略选择动作,不依赖模型的最优策略
在一定条件下只使用贪心学习即可保证收敛,Q学习是目前(2004)最有效的模型无关算法。
利用随机过程和不动点理论,可以证明当满足一定条件时,MDP模型Q学习过程的收敛性。同样,学习也可根据TD( λ \lambda λ)算法的方式扩充到Q( λ \lambda λ)算法。
Watkins,1992
Watkins P.Dayan.Q-learning.Machine Learning,1992,8(3):279~292
Tsitsiklis,John N. Asynchronous stochastic approximation and Q-learning. Machine Learning,1994,16(3):185~202
4.1.1.3 Sarsa算法
Sarsa算法,改进的Q-学习算法,在策略(on-policyTD)TD学习:基于模型,Q值迭代,一步Sarsa算法
Q
(
s
t
,
a
t
)
=
Q
(
s
t
,
a
t
)
+
α
(
r
t
+
1
+
γ
Q
(
s
t
+
1
,
a
t
+
1
)
−
Q
(
s
t
,
a
t
)
)
Q(s_t,a_t)=Q(s_t,a_t)+\alpha(r_{t+1}+\gamma Q(s_{t+1},a_{t+1})-Q(s_t,a_t))
Q(st,at)=Q(st,at)+α(rt+1+γQ(st+1,at+1)−Q(st,at))
在每步agent
- 首先根据 ε \varepsilon ε-贪心策略确定动作 a t a_t at,得到经验知识和训练例 < s t , a t , s t + 1 , r t + 1 > <s_t,a_t,s_{t+1},r_{t+1}> <st,at,st+1,rt+1>
- 根据 ε \varepsilon ε-贪心策略确定状态 s t + 1 s_{t+1} st+1时的动作 a t + 1 a_{t+1} at+1并根据上式修改
- 将确定的 a t + 1 a_{t+1} at+1作为agent所采取的下一个动作。
与Q-学习的区别:Q采用值函数最大值(确定性策略)迭代,Sarsa采用实际的Q值进行迭代。Sarsa每此迭代agent根据当前Q值确定下一状态的动作,Q依据修改后的Q值确定动作。
Rummery和Niranjan,1994
Rummery G,Niranjan M. On-line Q-learning using connectionist systems. Technical Report CUED/F-INFENG/TR 166,Cambridge University Engineering Department,1994
4.2.2 经验强化型强化学习算法
对比上一种:在最优搜索型强化学习算法中,动作的选择总是基于当前值函数采用贪心策略。而在经验强化型学习算法中,为充分利用已获得的经验知识,根据经验维持的动作规则进行动作的选择。
古典的强化学习都是经验强化型学习算法。
例子
-
Samuel西洋跳棋游戏中的动作选择
-
Holland在分类器系统中的救火龙算法
-
Q-PSP(Profit sharing plan)算法:Horiuchi等人
类似于 Q ( λ ) Q(\lambda) Q(λ)算法,有限状态回退。
- agent获得经验知识,后遭规则集合 R R R
- 在状态 s t + 1 s_{t+1} st+1生成备选规则集合 R ′ R' R′,基于 R ′ R' R′确定动作 a t + 1 a_{t+1} at+1
- 再次获得奖赏时,分配到 R ′ R' R′上
- 进行下一次学习
问题:学习速度比Q(1)更快,但会强化无用规则,可能不收敛。对于动态环境性能较差,如何设计奖赏分配函数。
Horiuchi T,Katai O.Q-PSP learning:An exploitation-oriented Q-learning algorithm and its applications. Transac-tions of the Society of Instrument and Control Engineers,1999,39(5):645~653
4.2 按研究方向
强化学习研究综述 马骋乾 2018
4.2.1 深度强化学习
背景:传统强化学习在模型较为简单的场景取得了较好的效果,但现实中的问题往往都比较复杂,状态空间和动作空间维数很大,此时传统的表格型强化学习不再适用。
谷歌DeepMind团队将具有强大感知能力及表征能力的深度学习与具有决策能力的强化学习相结合,形成了深度强化学习(Deep Reinforcement Learning,DRL)
代表算法:
深度Q网络(Deep Q Network,DQN)
在DQN算法中,使用深度神经网络来代替Q表,能够适用状态空间和动作空间非常复杂的场景,将当前状态值作为神经网络的输入,输出端输出所要采取的动作。并采用Q学习的方式对神经网络的参数进行更新,利用经验回放机制减小了数据之间的相关性,缩短了训练时间。
问题:DQN算法在进行优化时,每次都会选取下一个状态最大Q值所对应的动作,这会带来过估计的问题
Mnih,Volodymyr,et al.Playing Atari with deep reinforcement learning[EB/OL].[2013-10-22]https: ∥ arXiv.org /abs/1312. 5602.
深度双Q网络(Deep Double Q-Network,DDQN)
有两套不同的参数网络,分别是当前值网络和目标值网络,当前值网络用来选取动作,目标值网络用来对动作做出评估,这样使动作选择和策略评估得以分离,有效降低了Q值过估计的风险。
Maruan AI-Shedivat,Trapit Bansal,et al.Continuous adaptation via meta-learning in nonstationary an competitiveenvironments[C]. In: International Conference on Learning,2018,pp1024-1043
Hado van Hasselt,Arthur Guez,David Silver. Deep reinforcement learning with Double Q-learning[C].In: Association for the Advancement of Artificial Intelligence,2016,pp.453-466.
深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法
DDPG使用深度神经网络来表示策略,并使用策略梯度的方式来更新策略。
优:DDPG同时具备AC算法和深度学习的优点,在实际运用中,这种学习方式往往能够带来更加有效的学习过程。
4.2.2 元强化学习
目标:学会学习,从一系列学习任务中训练一个模型,这个模型在面对新的学习任务时只需要少量的样本便可以实现快速学习。
思想:将同一系列任务的内在特征分成两类,一类是通用特征,另一类是灵敏度较高的特征。在试验过程中,首先通过求最小方差的方式得到通用特征,面对新任务时只需要少量样本就可以学习到具体任务中其他灵敏度较高的特征。
框架最早由Schmidhuber等人提出
JX等人将深度学习与元强化学习相结合提出深度元强化学习(Deep Meta Reinforcement Learning)概念
Model-Agnostic Meta-Learning,MAML算法
不针对某种特定的模型,采用梯度下降方式进行更新,在面对新任务时,模型微调之后便可以获得较好的泛化性能。
Maruan等人将MAML算法和循环神经网络相结合研究,实现了强化学习模型在动态环境中的策略自适应。
被认为是最可能实现通用AI的方式
DeepMind团队在用深度学习复现大脑的导航功能后[16],又利用元强化学习框架探索研究了大脑中的多巴胺在学习过程中所发挥的作用[17],帮助解释了神经科学和心理学的一系列发现,也说明了元强化学习和人类智能存在的紧密联系。
4.2.3 逆向强化学习
背景:强化学习是求累计奖赏期望最大时的策略,求解过程中的奖赏函数是人为给定的,但在很多复杂的任务中,奖赏函数往往难以直接给定,而奖赏函数的好坏又对学习结果有着非常重要的影响。
提出:吴恩达等人
Ng A Y,Russell S J. Algorithms for inverse reinforcement learning[C]. In: Proceedings of the 16st International Conference on Machine Learning,2000.
主要算法
-
基于学徒学习
使用函数逼近的方法从专家示例中学习奖赏函数,使得在该奖赏函数下所得的最优策略在专家示例策略附近,主要用来解决退化解和奖赏函数歧义性问题。
-
最大边际规划
找到使专家示例策略具有比其他策略更大累计奖赏的状态到奖赏的映射,在这个映射下,最优策略能够逼近专家示例策略。
-
结构化分类
用分类的思想考虑最优的策略,并将估计的专家期望特征作为奖赏函数,这种做法避免了多次迭代计算过程。
问题:最大边际规划法和结构化分类方法往往会产生歧义,很多不同的奖赏函数会导致相同的专家策略
-
概率模型形式化
- 基于最大熵概率模型
- 基于交叉熵概率模型
问题:经典的逆向强化学习算法不能很好地扩展到状态空间维数很大的系统
4.3 按策略
强化学习研究综述 马骋乾 2018
4.3.1 基于值函数的强化学习方法
基于值函数的强化学习方法通过评估值函数,并根据值的大小来选择相应的动作
包括
- 动态规划(Dynamic Programming)
- 蒙特卡洛(Monte Carlo)
- 时间差分(Temporal Difference)
- 值函数逼近(Value Function Approximation)
动规:模型已知
在策略迭代和值迭代的过程中利用值函数来评估和改进策略
蒙特卡洛:模型未知
利用部分随机样本的期望来估计整体模型的期望,在计算值函数时,蒙特卡洛法利用经验平均来代替随机变量的期望。
问题:解决了模型未知的问题,但更新方式是回合制,学习效率很低。
时间差分法(TD):改善动规问题
时间差分法采用自举(Bootstrapping)方法,在回合学习过程中利用后继状态的值函数来估计当前值函数,使得智能体能够实现单步更新或多步更新,从而极大地提高了学习效率。
目前大部分的强化学习研究都基于时间差分方法,如Q学习、Sarsa等相关算法。
三者问题
动态规划、蒙特卡洛、时间差分三种方法应用的同一前提是状态空间和动作空间都必须离散,且状态空间和动作空间不能过大。当状态空间维数很大,或者为连续空间时,使用值函数方法会带来维数爆炸的问题。
值函数逼近:维数很大或连续空间的问题
使用函数逼近的方式来表示值函数,然后再利用策略迭代或值迭代方法来构建强化学习算法。
4.3.2 基于直接策略搜索的强化学习方法
将策略进行参数化,优化参数使得策略的累计回报期望最大
优:策略参数化更简单、具有更好的收敛性且能较好地解决连续动作选取问题
包括
- 经典策略梯度
- 置信域策略优化(Trust Region Policy Optimization,TRPO)
- 确定性策略搜索
经典策略梯度
通过计算策略期望总奖赏关于策略参数的梯度来更新策略参数,通过多次迭代后最终收敛得到最优策略。
在进行策略参数化时,一般通过使用神经网络来实现,在不断试验的过程中,高回报路径的概率会逐渐增大,低回报路径的概率则会逐渐减小。
策略梯度的参数更新方程式为
θ
n
e
w
=
θ
o
l
d
+
α
∇
θ
J
θ_{new}=θ_{old}+α\nabla_θJ
θnew=θold+α∇θJ
其中,
α
α
α为更新步长,
J
J
J为奖赏函数。
问题:选取合适的更新步长,步长选取是否合适又直接影响学习的效果,不合适的步长都导致策略越学越差,最终崩溃。
TRPO方法:为了解决更新步长的选取问题,John Schulman等人提出。
将新的策略所对应的奖励函数分解为旧策略所对应的奖励函数和其他项两个部分,只要新策略中的其他项满足大于等于零,便可以保证新策略所对应的奖励函数单调不减,策略就不会变差。
问题:经典策略梯度和TRPO采用的均是随机策略,相同的状态选取的动作可能不一样,这使得算法模型要达到收敛需要相对较多的试验数据。
确定性策略方法:为了提高算法效率,Silver等人提出。
利用异策略学习方式,执行策略采用随机策略来保证探索性,为了使状态对应的动作唯一,评估策略采取确定性策略,也称AC(Actor-Critic)方法。
优:采样数据较少,且能够实现单步更新,算法性能有较大提升
4.4 部分感知
部分感知:agent无法感知全部的环境信息。即使是马尔可夫环境,也无法区别状态间的差异。部分感知问题属于非马尔科夫环境。需要对强化学习算法进行处理,否则将发散。
主流方法:预测模型法
- 部分可观察马尔可夫决策过程POMDP(Partially Observable MDP)
- 基于最优搜索型强化学习算法
POMDP模型:在 马尔可夫决策模型 S , A , T , R S,A,T,R S,A,T,R上, Ω \Omega Ω是可以感知的世界状态集合,观察函数 O : S × A → P D ( Ω ) O:S\times A\to PD(\Omega) O:S×A→PD(Ω)。在采取动作a转移到状态s‘时,观察函数O确定其在可能观察上的概率分布 O ( s ′ , a , o ) O(s',a,o) O(s′,a,o)。
需要考虑动作和状态的不确定性,比MDP模型应用范围更广。
基本思路:将系统转化为MDP描述,假设存在部分可观测的隐含状态集S具有马尔可夫性
将状态迁移的历史知识应用于agent预测模型或构建内部状态,同时引人对内部状态的里信度,将POMDP转化为统计上的MPD求解,状态的置信度又称为信用状态。信用状态b定义为在隐状态集S上的概率分布,记b(s)为对状态s的置信度。在信用状态 b,Agent 执行动作 a,得到新的观察 o,此时根据 Bayes 原理,新信用状态b’计算如下:
b
′
(
s
′
)
=
P
r
(
s
′
∣
o
,
a
,
b
)
=
O
(
s
′
,
a
,
b
)
∑
s
∈
S
T
(
s
,
a
,
s
′
)
b
(
s
)
P
r
(
o
∣
a
,
b
)
b'(s')=\mathrm{Pr}(s'|o,a,b)=\frac{O(s',a,b)\sum_{s\in S}T(s,a,s')b(s)}{\mathrm{Pr}(o|a,b)}
b′(s′)=Pr(s′∣o,a,b)=Pr(o∣a,b)O(s′,a,b)∑s∈ST(s,a,s′)b(s)
当信用状态是可计算时,POMDP问题最优策略学习转变为"信用状态 MDP"(belief MDP)最优策略的学习。
信用状态 MDP模型:B是agent所有信用状态的集合,A是动作集合,记状态转移函数为
τ
(
b
,
a
,
b
′
)
\tau(b,a,b')
τ(b,a,b′),奖赏函数为
p
(
b
,
a
)
p(b,a)
p(b,a)。
τ
(
b
,
a
,
b
′
)
=
∑
o
∈
O
P
r
(
b
′
∣
a
,
b
,
o
)
P
r
(
o
∣
a
,
b
)
ρ
(
b
,
a
)
=
∑
s
∈
S
b
(
s
)
R
(
s
,
a
)
\tau(b,a,b')=\sum_{o\in O}\mathrm{Pr}(b'|a,b,o)\mathrm{Pr}(o|a,b)\\ \rho(b,a)=\sum_{s\in S}b(s)R(s,a)
τ(b,a,b′)=o∈O∑Pr(b′∣a,b,o)Pr(o∣a,b)ρ(b,a)=s∈S∑b(s)R(s,a)
对POMDP问题的学习,目前是强化学习中一个非常重要的研究方向。信用状态MDP模型是一个连续状态的模型,随着环境复杂程度增加,预测模型的大小呈爆炸性的增大,算法实际上不可行。因此,如何结合第节的函数估计方法有效地减少计算量、加快学习算法的收敛速度是待解决的研究课题之一。
Lovejoy W S. A survey of algorithmic methods for partially observed Markov decision processes. Annals of Opera-tions Research,1991,28:47~65
Leslie Pack Kaelbling,Michael L Littman,Anthony R Cassandra. Planning and acting in partially observable sto-chastic domains. Artificial Intelligence,1998,101:99~134
4.5 符号学习
系统模型已知时,强化学习变为规划问题。此时,经验知识可以直接用例进行优化策略的学学习或模型估计,直接从估计的模型中的规划动作。
4.5.1 Dyna-Q
Dyna-Q学习:基于模型的算法,Sarsa模型隐含在Q函数中,二Dyna-Q可以明确学习系统的模型。目的:充分利用经验获取知识,解决TD和Q迭代慢的问题。
- 根据Q值,在 s t s_t st选择 a t a_t at
- 观察到转移状态和奖赏值得到经验知识
- 根据Q学习的方式迭代
- 根据经验集合采用概率统计技术建立模型T函数和R函数估计
- 利用模型随机模拟K个经验知识,进行值函数迭代
- 根据Q值选已知动作,转回2
Sutton 1991
Sutton R S,Barto A G,Williams R.Reinforcement learning is direct adaptive optimal control. IEEE Control Systems Magazine,1991,12(2):19~22
4.6 论文
-
综述类:简单看看发展状态
-
Deep Reinforcement Learning: A State-of-the-Art Walkthrough(2020)
-
Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms(2019)
-
-
算法类:经典算法
-
[DPG] Deterministic policy gradient algorithms (ICML 2014)
-
[DDPG] Continuous control with deep reinforcement learning (ICLR 2016)
-
[PPO] Proximal policy optimization algorithms (2017)
-
[TRPO] Trust region policy optimization (2017)
-
[Rainbow] Rainbow_ combining improvements in deep reinforcement learning (AAAI 2017) 这篇文章建议看看,它是对前面多种DQN方法的一个总结,能让你比较省时全面的综合下自己前面学的东西
-
关于rainbow的一些补充
- https://link.zhihu.com/?target=https%3A//github.com/Curt-Park/rainbow-is-all-you-need)
基于Q-learning的算法
- DQN——离散,off-policy
Human-level control through deep reinforcement learning | Naturewww.nature.com/articles/nature14236
DQN算法是深度强化学习中最经典的算法,它适用于离散问题,是一种off-policy的算法。DQN将Q-learning算法与深度学习结合起来,标志着深度强化学习的开端。尽管有些人觉得DQN已经过时了,但我认为它是DRL中最重要的算法之一,并且仍然能够在许多问题中展现出比较好的效果。另外,之后的DDPG、TD3以及SAC等off-policy算法实际上都是在DQN算法的基础上做各种类型的改进,因此在入门时掌握DQN算法是十分必须的。
策略梯度算法
- REINFORCE(VPG)——离散/连续,on-policy,随机策略
REINFORCE是直接根据策略梯度定理所得到的算法,该算法所涉及的理论推导在Sutton的书以及Spinning up中均有详细介绍。尽管在实际应用中,我们一般不会再使用REINFORCE这一较老的算法,但是它所涉及到的理论推导是所有on-policy算法的基础,十分重要。
- TRPO——离散/连续,on-policy,随机策略
[[1502.05477] Trust Region Policy Optimization (arxiv.org)arxiv.org/abs/1502.05477](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1502.05477)
TRPO的采用了信任域策略优化的方法,相较于REINFORCE,样本利用率更高。但是TRPO算法较为复杂,大家一般使用TRPO的简化版本,PPO。
- PPO——离散/连续,on-policy,随机策略
[[1707.06347] Proximal Policy Optimization Algorithms (arxiv.org)arxiv.org/abs/1707.06347](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1707.06347)
PPO对TRPO算法进行了简化,在不降低算法性能的情况下使得算法操作性更强,是目前大家用得比较多的一个算法。
XuanAxuan:【深度强化学习】PPO 算法理解39 赞同 · 5 评论文章
确定性策略梯度算法
- DPG——DDPG的基础
上面提到的策略梯度算法均基于策略梯度定理,适用于随机策略。而在DPG中,作者针对确定性策略,提出了确定性策略梯度定理,并相应地提出了DPG算法。尽管我们一般不用DPG算法,但是该算法涉及到的理论推导是DDPG的基础,对于理解DDPG算法以及区分确定性策略与随机策略十分重要,因此我十分推荐大家阅读这篇论文。
XuanAxuan:【深度强化学习】确定性策略梯度:DPG 阅读笔记15 赞同 · 0 评论文章
- DDPG——连续,off-policy,确定性策略
Continuous control with deep reinforcement learningarxiv.org/abs/1509.02971
DDPG算法是DPG算法与深度学习的结合,同时也是DQN算法与确定性策略梯度定理的结合,是一种适用于连续动作空间的off-policy算法。尽管目前许多人反映DDPG已经有些过时了,在许多问题上效果并不是特别好,但是我依然推荐大家入门时学习甚至尝试着跑一跑这个算法,毕竟它也是十分经典的算法之一。
XuanAxuan:【深度强化学习】确定性策略梯度:DDPG算法理解13 赞同 · 0 评论文章
- TD3——连续,off-policy,确定性策略
http://arxiv.org/abs/1802.09477arxiv.org/abs/1802.09477
TD3算法是DDPG的进阶版,也是目前大家比较推荐的算法,我尝试过感觉该算法超参数比较多,适合调参经验丰富的同学使用。
XuanAxuan:【深度强化学习】升级版 DDPG:TD3 阅读笔记1 赞同 · 0 评论文章
基于最大熵的算法
- SQL——连续/离散,off-policy,随机策略
https://arxiv.org/abs/1702.08165arxiv.org/abs/1702.08165
SQL是SAC的前身,实际应用中一般不会使用该算法,但是为了读懂SAC的论文,必须首先阅读SQL的论文。
- SAC——连续/离散,off-policy,随机策略
http://arxiv.org/abs/1812.05905arxiv.org/abs/1812.05905
[[1801.01290] Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor (arxiv.org)arxiv.org/abs/1801.01290](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1801.01290)
[[1812.11103] Learning to Walk via Deep Reinforcement Learning (arxiv.org)arxiv.org/abs/1812.11103](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1812.11103)
SAC(soft actor-critic)基于最大熵(maximum entropy)框架,是一类特殊的off-policy的随机策略算法(一般随机策略算法都是on-policy的),兼具探索能力强(随机策略)与样本效率高(off-policy)的特点,是目前公认比较好的算法(在我个人的任务中,SAC的表现最好,无需调参就能很快收敛)。SAC算法涉及到很多篇论文,单看一篇很难看明白,需要仔细地把作者同一时期写的好几篇论文都阅读一遍,才能捋清楚背后所涉及的原理。目前就我用SAC达到的效果来看,在原理学习阶段所花的时间是十分值得的。
XuanAxuan:【深度强化学习】最大熵 RL:从Soft Q-Learning到SAC61 赞同 · 27 评论文章
5 背景描述
但现实中很多问题无法提供大量的有标签数据,如机器人路径规划、自主驾驶、玩游戏等,这些涉及决策优化以及空间搜索的问题,深度学习并不擅长,但强化学习却可以有效地解决这些问题,因此,近年来关于强化学习的研究越来越受到重视。
6 发展、领域现状
强化学习在与神经网络结合之前,没有像现在这样收到过关注,虽然之前早有值函数近似方法 (Function Approximation),而让学者们具有深刻印象的转折点就是2013年Google DeepMind的一个研究小组设计的用深层神经网络去逼近值函数的方法,他们在Atari游戏中,只通过视频图像输入和游戏分数反馈,就取得了人类水平的高分,这一过程并没有经过细致的、针对性的特征设计。此方法一举将强化学习提升到最前沿水平。
他们设计的方法就是 Deep Q-Learning(或者叫DQN,Deep Q-Network),而后续领域内的大神们各显神通,在此基础上进行魔改强化,让Q-Learning这一经典算法重回大众的视野。Q-Learning的创造者可能也想不到,经过了二十多年,它的后辈们居然在短短四五年内凭借神经网络创造了如此庞大的算法家族:
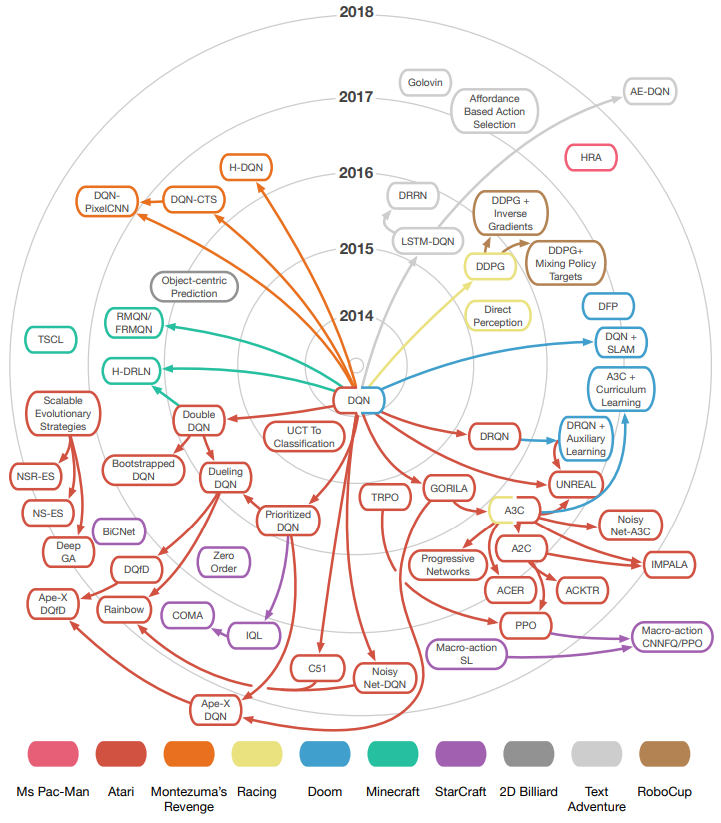
- Double DQN
- Dueling DQN
- Prioritized DQN
它们代表了DQN最重要的三个优化方式
Q-Learning在强化学习算法中的分类
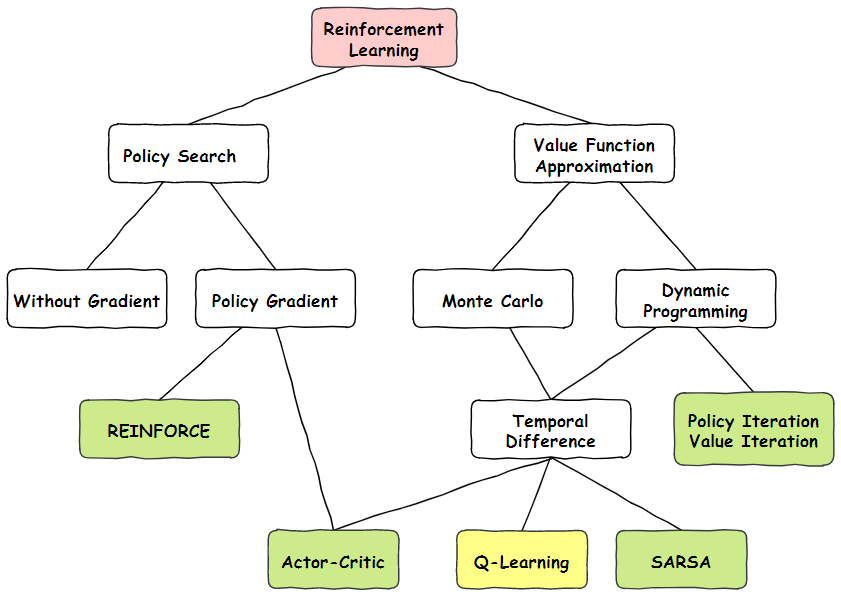
研究方向
-
将其作为一类问题
搜索agent的行为空间,以发现agent最优的行为,遗传算法等。
-
将其作为解决这类问题的技术
采用统计技术和动态规划方法来估计在某一环境状态下的动作的效用函数值。
从目前(2004)研究分析,首先是进一步发展马尔可夫环境下的高效的学习算法,其次是对经验强化型强化学习算法进行理论分析。
在马尔可夫环境中,最优搜索型强化学习算法已经被证明收敛性。
2004年左右研究热点:非马尔可夫环境下的强化学习,分为
- 部分感知强化学习
- 函数估计
- 多强化学习
- 强化学习偏差技术
7 问题、设计考虑
一,如何表示状态空间和动作空间。
二,如何选择建立信号以及如何通过学习来修正不同状态-动作对的值。
三,如何根据这些值来选择适合的动作。用强化学习方法研究未知环境下的机器人导航,由于环境的复杂性和不确定性,这些问题变得更复杂。
标准的强化学习,智能体作为学习系统,获取外部环境的当前状态信息s,对环境采取试探行为u,并获取环境反馈的对此动作的评价r和新的环境状态 。如果智能体的某动作u导致环境正的奖赏(立即报酬),那么智能体以后产生这个动作的趋势便会加强;反之,智能体产生这个动作的趋势将减弱。在学习系统的控制行为与环境反馈的状态及评价的反复的交互作用中,以学习的方式不断修改从状态到动作的映射策略,以达到优化系统性能目的。















 4037
4037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









