







文章目录
SKESL:多模态情感分析中的情感知识增强型自监督学习
总结:从未标注的视频数据中挖掘情感先验信息可以为标注数据带来更好的预测效果。未标记视频数据量越大,语言建模能力越强,性能越好。(自监督学习,扩大数据集)
文章信息
作者:Fan Qian,Jiqing Han
单位:Harbin Institute of Technology(哈尔滨工业大学)
会议/期刊:Findings of the Association for Computational Linguistics: ACL 2023
题目:Sentiment Knowledge Enhanced Self-supervised Learning for Multimodal Sentiment Analysis
年份:2023
研究目的
由于缺乏标注数据,应用于多模态情感分析任务的监督模型存在严重的过拟合和泛化能力差的问题,所以想要促进在有限的标记数据上的进一步学习。
研究内容
提出了一种情感知识增强自监督学习(SKESL)方法,该方法使用上下文和非语言信息来预测单词的细粒度情感强度,以学习观点视频中常见的情感模式。
- 利用来自大规模未标记视频的情感知识来促进改进的情感表征学习(多模态情感分析的自监督学习)
- 提出了一种新的非语言信息聚合方法,用于获得音频和视觉信息增强的文本序列表征。
研究方法

SKESL流程:给定一个没有情感注释的说话人视频,首先使用自动语音识别(ASR)技术获得转录文本,然后根据预先指定的情感词典掩盖文本中最情感突出的单词。利用预训练的语言表征模型来获取处理后文本的序列表征。为了将非语言信息整合到文本表征中(其实就是多模态融合),使用了一种基于跨模态注意机制的非语言信息聚合方法,以获得非语言信息增强的文本表征。最后,利用掩蔽词表征来预测情感强度。
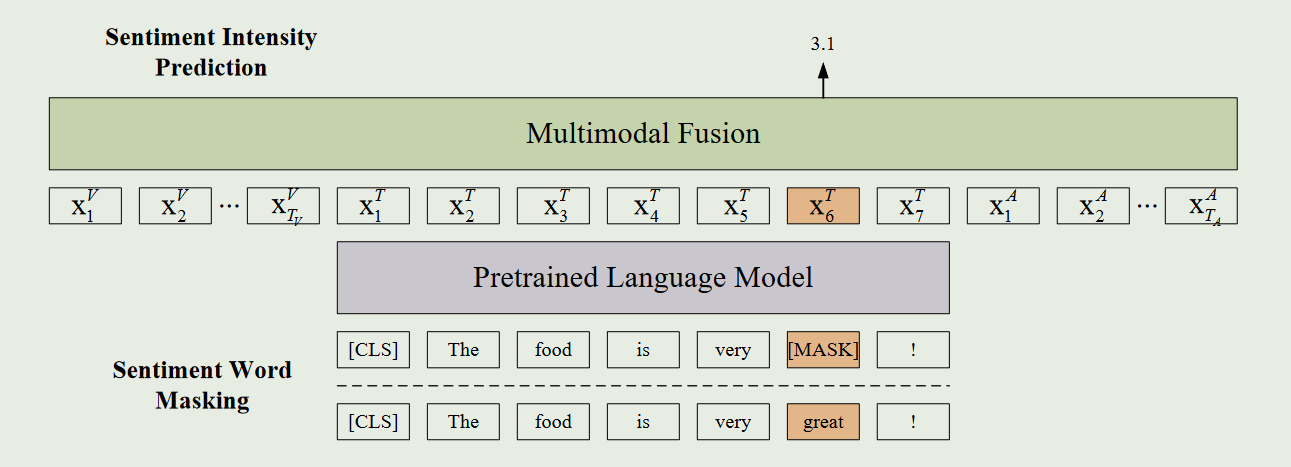
情感知识增强自监督学习(SKESL)包含两个部分:(1)情感词屏蔽 SWM,根据情感词典搜索输入句子中情感最突出的词,并用一个特殊标记[MASK]替换它,生成一个被破坏的版本。(2) 情感强度预测,要求模型根据上下文和非语言信息推断出准确的情感强度。
1.Sentiment Word Masking
情感词语屏蔽(SWM)旨在为每个输入序列构建一个情感信息被屏蔽的损坏版本。
对于没有情感注释的说话者视频,首先要利用良好的 ASR 技术将语音转录为文本 S = { w 1 , w 2 , . . . , w N } \mathrm{S}=\{w_1,w_2,...,w_N\} S={w1,w2,...,wN}。然后使用情感词典(包含每个情感词的明确情感强度得分)来搜索文本中情感最突出的情感词并屏蔽它们(即使用特殊标记[MASK]来代替它们),同时选择情感强度最高的得分 y M A S K y_{MASK} yMASK 作为引导 SKESL 的标签。这样就得到了一个情感信息被屏蔽的句子, S ′ = { w 1 , w 2 , . . . , w M A S K , . . . , w N } \mathrm{S'}=\{w_1,w_2,...,w_{\mathrm{MASK}},...,w_N\} S′={w1,w2,...,wMASK,...,wN}其中 wMASK 表示屏蔽词。
⚠注意:有情感倾向的句子不一定有情感词。为了应对这种情况,采用了随机屏蔽策略,并为被屏蔽词赋予情感强度为 "0.0 "的标签。这样做可以诱导预训练模型根据上下文和非语言信息来区分被屏蔽位置是否包含没有任何情感的词语。这样,模型对句子中的单词就有了更强的情感语义认知,并能学习到更好的情感多模态表征。
2.Text representation learning
在得到被破坏的句子 S′ 后,将其通过文本编码器BERT,提取文本模态特征。
X
T
:
=
{
x
1
T
,
x
2
T
,
.
.
.
,
x
N
T
}
=
f
θ
L
M
(
S
′
)
\mathbf{X}^T:=\{x_1^T,x_2^T,...,x_N^T\}=f_{\theta_{\mathrm{LM}}}\left(S^{\prime}\right)
XT:={x1T,x2T,...,xNT}=fθLM(S′)
| 符号 | 含义 |
|---|---|
| X m = { x 1 m , x 2 m , . . . , x T m m } \mathbf{X}^m=\{x_1^m,x_2^m,...,x_{T_m}^m\} Xm={x1m,x2m,...,xTmm} | 多模态序列 |
| x i m ∈ R d m {x_i^m}\in\mathbb{R}^{d_m} xim∈Rdm | 与模态 m 相对应的提取后的情感特征 |
| d m d_m dm | 特征维度 |
| T m T_m Tm | 模态 m 的序列长度 |
| θ L M \theta_{\mathrm{LM}} θLM | BERT的参数 |
3.Non-verbal information injection(multimodal fusion)
通过学习两种模态特征的注意力,利用音频和视觉模态的低级特征反复强化文本表征。低级特征有利于模型保留非语言行为的原始情感语义,并学习以文本为中心的多模态表征。

CMA单元:首先计算相应模态的 Q、K、V。其次分别计算文本模态与视觉模态,文本模态与语音模态的注意力权重。然后利用注意力权重对视觉与语音表征进行加权,得到对文本模态有用的视觉信息与音频信息。
Q
m
T
=
L
N
(
X
l
−
1
T
)
⋅
W
Q
m
K
m
=
L
N
(
X
0
m
)
⋅
W
K
m
V
m
=
L
N
(
X
0
m
)
⋅
W
V
m
\mathbf{Q}^{mT}=\mathrm{LN}\left(\mathbf{X}_{l-1}^T\right)\cdot\mathbf{W}_Q^m\\\mathbf{K}^m=\mathrm{LN}\left(\mathbf{X}_0^m\right)\cdot\mathbf{W}_K^m\\\mathbf{V}^m=\mathrm{LN}\left(\mathbf{X}_0^m\right)\cdot\mathbf{W}_V^m
QmT=LN(Xl−1T)⋅WQmKm=LN(X0m)⋅WKmVm=LN(X0m)⋅WVm
Y l m = C M A ( Q m T , K m , V m ) = s o f t m a x ( Q m T ⋅ K m d T ) ⋅ V m \begin{aligned} \mathbf{Y}_{l}^{m}& =\mathrm{CMA}\left(\mathbf{Q}^{mT},\mathbf{K}^m,\mathbf{V}^m\right) \\ &=\mathrm{softmax}\left(\frac{\mathrm{Q}^{mT}\cdot\mathrm{K}^m}{\sqrt{d_T}}\right)\cdot\mathrm{V}^m \end{aligned} Ylm=CMA(QmT,Km,Vm)=softmax(dTQmT⋅Km)⋅Vm
接着将增强后的文本表征
Y
l
m
{Y}_{l}^{m}
Ylm 与之前的文本表征
X
l
−
1
T
{X}_{l-1}^T
Xl−1T 融合在一起。=>将音频和视频信息注入文本表征中。
Y
l
=
Y
l
A
+
L
N
(
X
l
−
1
T
)
+
Y
l
V
\mathbf{Y}_l=\mathbf{Y}_l^A+\mathrm{LN}\left(\mathbf{X}_{l-1}^T\right)+\mathbf{Y}_l^V
Yl=YlA+LN(Xl−1T)+YlV
最后,将融合后的表征
Y
l
Y_l
Yl 经过LayerNorm与FFNN,并使用残差连接,得到最终的文本表征。
X
l
T
=
f
θ
F
F
(
L
N
(
Y
l
)
)
+
Y
l
\mathbf{X}_l^T=f_{\theta_{\mathrm{FF}}}\left(\mathrm{LN}\left(\mathbf{Y}_l\right)\right)+\mathbf{Y}_l
XlT=fθFF(LN(Yl))+Yl
| 符号 | 含义 |
|---|---|
| L N ( ⋅ ) \mathrm{LN}(\cdot) LN(⋅) | 层归一化 |
| Y l m {Y}_{l}^{m} Ylm | 通过音频和视频信息增强后的文本模态表征 |
| θ F F \theta_{\mathrm{FF}} θFF | FFNN 的参数 |
4.Sentiment Intensity Prediction
使用一个具有非线性激活函数的双层全连接网络来预测屏蔽词的情感强度。
y
p
r
e
d
=
f
θ
F
C
(
x
M
A
S
K
,
L
T
)
y_{\mathrm{pred}}=f_{\theta_{\mathrm{FC}}}\left(x_{\mathrm{MASK},L}^T\right)
ypred=fθFC(xMASK,LT)
| 符号 | 含义 |
|---|---|
| X L T X_L^T XLT | 经过 L 个区块后,提炼出的文本表征 |
| x M A S K , L T x_{\mathrm{MASK},L}^T xMASK,LT | 屏蔽词[MASK]对应的表征 |
| θ F C \theta_{\mathrm{FC}} θFC | 全连接层的参数 |
| y p r e d y_{\mathrm{pred}} ypred | 预测的情感强度 |
5.Loss Function
L
\mathcal{L}
L 为平均绝对误差 (MAE) 损失函数
θ
∗
=
arg
min
θ
L
(
y
p
r
e
d
,
y
M
A
S
K
)
θ
=
{
θ
L
M
,
θ
C
M
A
,
θ
F
F
,
θ
F
C
}
\theta^*=\arg\min_\theta\mathcal{L}(y_{\mathrm{pred}},y_{\mathrm{MASK}})\\ \theta=\{\theta_{\mathrm{LM}},\theta_{\mathrm{CMA}},\theta_{\mathrm{FF}},\theta_{\mathrm{FC}}\}
θ∗=argθminL(ypred,yMASK)θ={θLM,θCMA,θFF,θFC}
6.Fine-tuning
在预训练语言模型和多模态融合模块的基础上,添加了一个输出层来执行特定任务的预测。然后在标注的多模态数据上对神经网络进行微调。
实验分析
- 本文介绍了一种基于无监督预训练的多模态情感分析模型,该模型在两个数据集上均取得了最先进的性能表现。
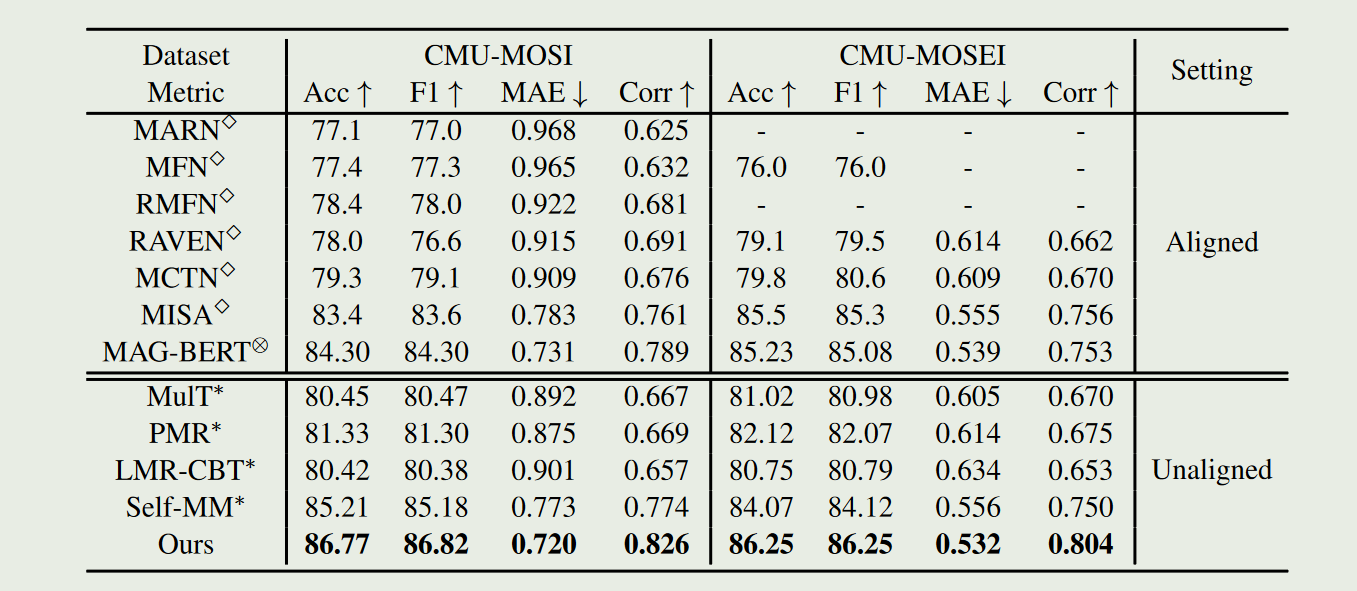
- 作者还研究了无标签视频数据量(预训练数据量)和语言模型大小对模型性能的影响,发现更多的预训练数据和更强的语言模型可以显著提高模型性能。
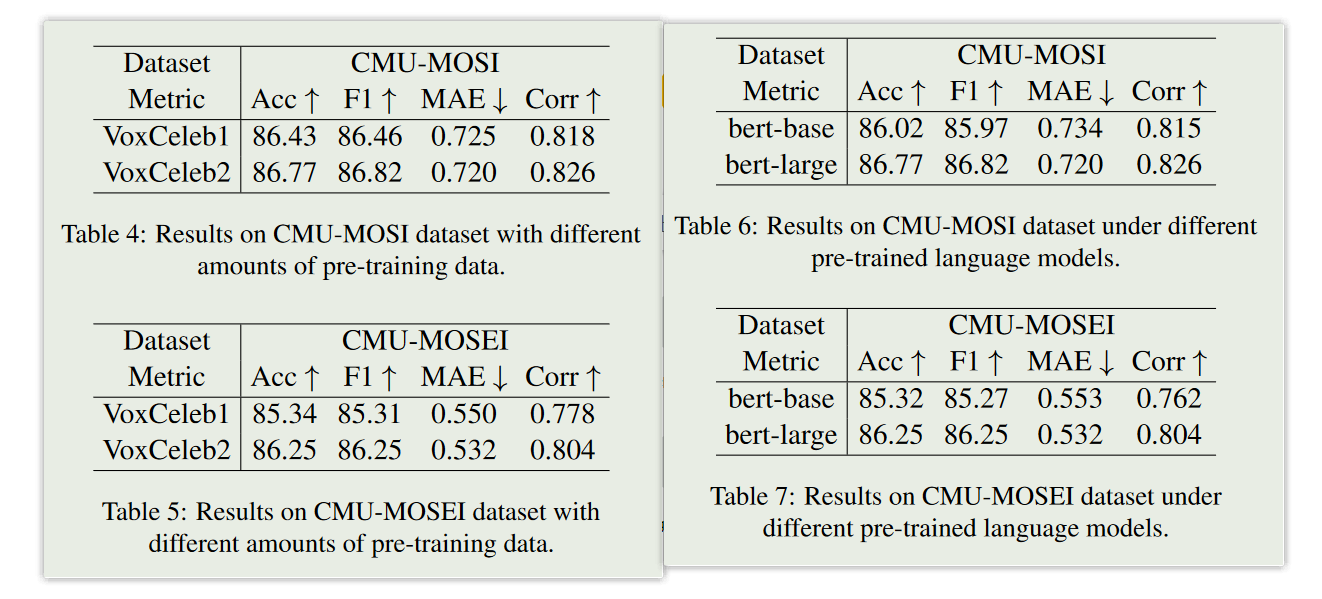
- 通过在CMU-MOSI数据集上进行了消融实验,结果表明SKESL对情感预测任务的准确性和F1分数有显著贡献。同时,如果只使用BERT语言模型进行情感预测,而不使用音频和视觉模态,性能将进一步降低。

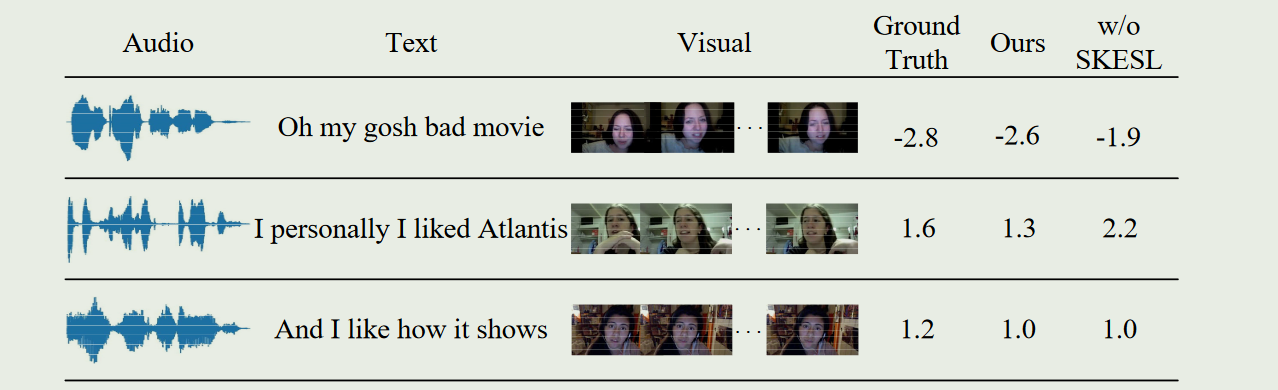
- 作者在CMU-MOSI数据集的测试集中展示了一些例子来验证模型的可靠性。
局限性
- 情感知识增强的自监督学习方法存在一些限制,包括视频预处理耗时费力、模型预训练对GPU资源要求较高。
- 避免模型存在偏差和无法学习情感知识,应避免过多没有情感词的视频。
代码和数据集
代码:https://github.com/qianfan1996/SKESL
数据集:VoxCeleb1与VoxCeleb2用于预训练模型;CMU-MOSI与CMU-MOSEI用于微调和测试模型。
实验环境:NVIDIA RTX 3090(24G)
😃😃😃


















 2969
2969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









