







文章目录
CLGSI:一种基于情感强度引导的对比学习的多模态情感分析框架
总结:提出了一种利用情感强度引导的对比学习,并对模态之间的共性特征和特定特征进行联合学习,进而实现更为有效的MSA。解决了样本之间情感强度差异的问题。
文章信息
作者:Yang Yang,Xunde Dong
单位:South China University of Technology(华南理工大学)
会议/期刊:NAACL(CCF B)
发布日期:2024 年 6 月 16 日
代码:https://github.com/AZYoung233/CLGSI
数据集:CMU-MOSI、CMU-MOSEI、CH-SIMS
算力要求:NVIDIA RTX 4090 GPU(24G)
研究目的
现有的大多数基于对比学习的MSA方法,对具有不同情感强度差异的样本对的分布缺乏更详细的学习。而且,针对通过对比学习训练获得的模态表征的融合技术手段十分有限。(探究样本之间情感强度的差异)
解释:根据 HyCon 和 ConFEDE 的配对选择机制,情感强度为-0.2 和-0.4 的样本很可能被视为负面样本对。但是,它们在标签方面仍然具有相似性,不应在表征空间中被推开。
研究内容
提出了一种基于情感强度引导的对比学习(CLGSI)的多模态情感分析新框架:
- 提出了以情感强度为导向的对比学习方法。在对比学习中,根据情感强度差异选择正负样本对,并相应地分配权重。这就为对比学习过程提供了丰富的细粒度信息。
- 提出了一种模仿人类认知过程的多模态表征融合机制——全局-局部-细粒度-知识(GLFK)。利用 GLFK 机制融合通过对比学习训练获得的各模态表征,以提取不同模态的共性特征。同时,使用 MLP 处理每个模态编码器的输出,提取每个模态的特定特征。最后,通过共性特征和特定特征的联合学习来预测情感强度。
- 在公开的中英文 MSA 数据集上进行了广泛的实验。实验结果表明,CLGSI 能够更好地理解不同文化差异下的情感表达,这证明了 CLGSI 具有良好的泛化性能和有效性。
研究方法
1.总体结构
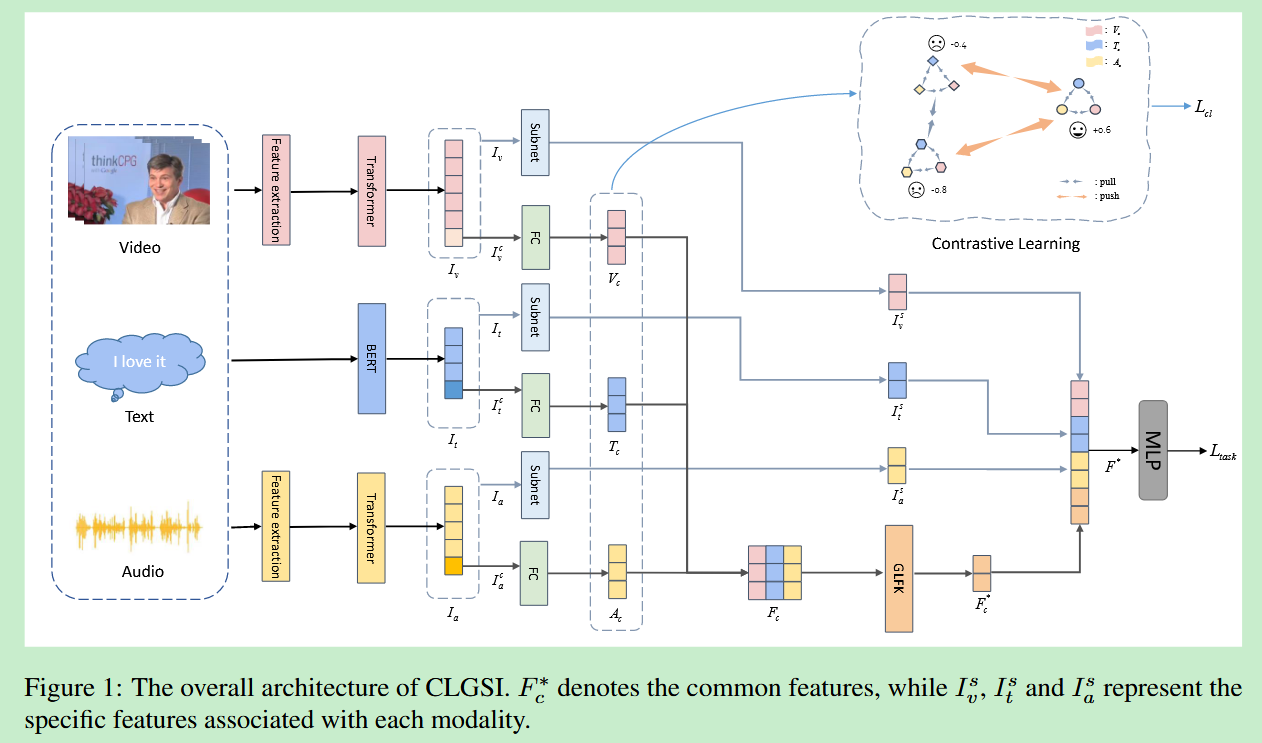
CLGSI 模型首先利用三个模态编码器,提取三种模态的表征 I v , I t , I a I_v,I_t,I_a Iv,It,Ia ,在这些表征的基础上,分别提取不同模态之间的共性特征 V c , T c , A c V_c,T_c,A_c Vc,Tc,Ac 和每种模态的特定特征 I v s , I t s , I a s I_v^s,I_t^s,I_a^s Ivs,Its,Ias。在共性特征提取模块中,以情感强度为导向进行对比学习,以增强编码器的表征能力。最后,使用 3 层 MLP 联合学习共性特征和特定特征,以预测情感强度。
2.共性特征提取
共性特征提取的主要目标是将来自不同模态的信息投影到相同的表征空间中。
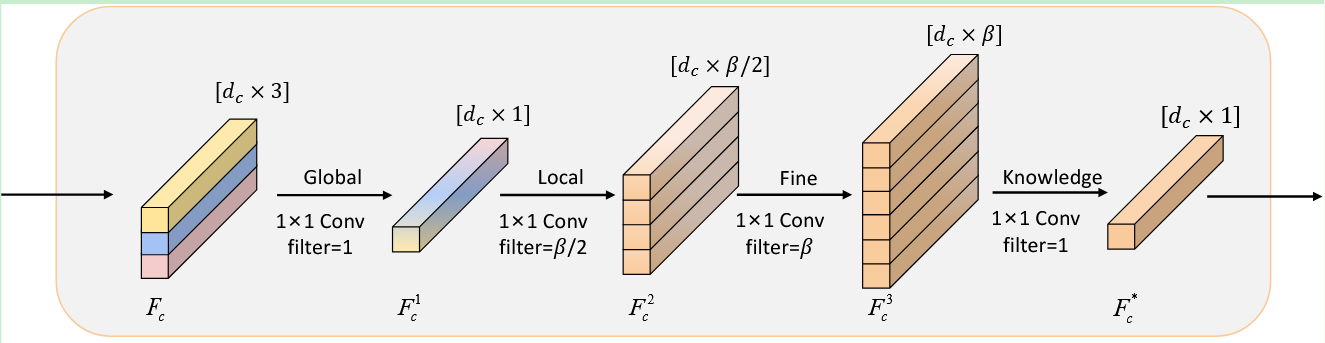
对于文本模态,BERT 的 [CLS] 向量 I t c I_t^c Itc 被用作共性向量表征。对于视觉和听觉模态,分别使用 Transformer 编码器最后一层的最后一个向量输出 I v c , I a c I_v^c,I_a^c Ivc,Iac 作为共性向量表征。随后,这三个向量通过全连接层和RELU激活函数得到三种模态的共性特征 T c , V c , A c T_c,V_c,A_c Tc,Vc,Ac 。此外,将 T c , V c , A c T_c,V_c,A_c Tc,Vc,Ac堆叠成一个新的矩阵,作为GLFK的输入。
GLFK 是一种受人类认知过程启发的新型表征融合机制,包含四个组件:全局、局部、细粒度和知识。采用 1×1 卷积操作对信息进行全局压缩, F c F_c Fc 被压缩为 F c 1 F_c^1 Fc1 。利用两个 1×1 卷积将 F c 1 F_c^1 Fc1 扩展为 F c 2 F_c^2 Fc2,然后在扩展为 F c 3 F_c^3 Fc3 。最后,采用 1×1 卷积将 F c 3 F_c^3 Fc3 减少到 F c ∗ F_c^* Fc∗ ,得到最终的共性特征 F c ∗ F_c^* Fc∗。
3.特定特征提取
特定特征提取的主要目标是高效地捕捉一个模态内的全面信息。
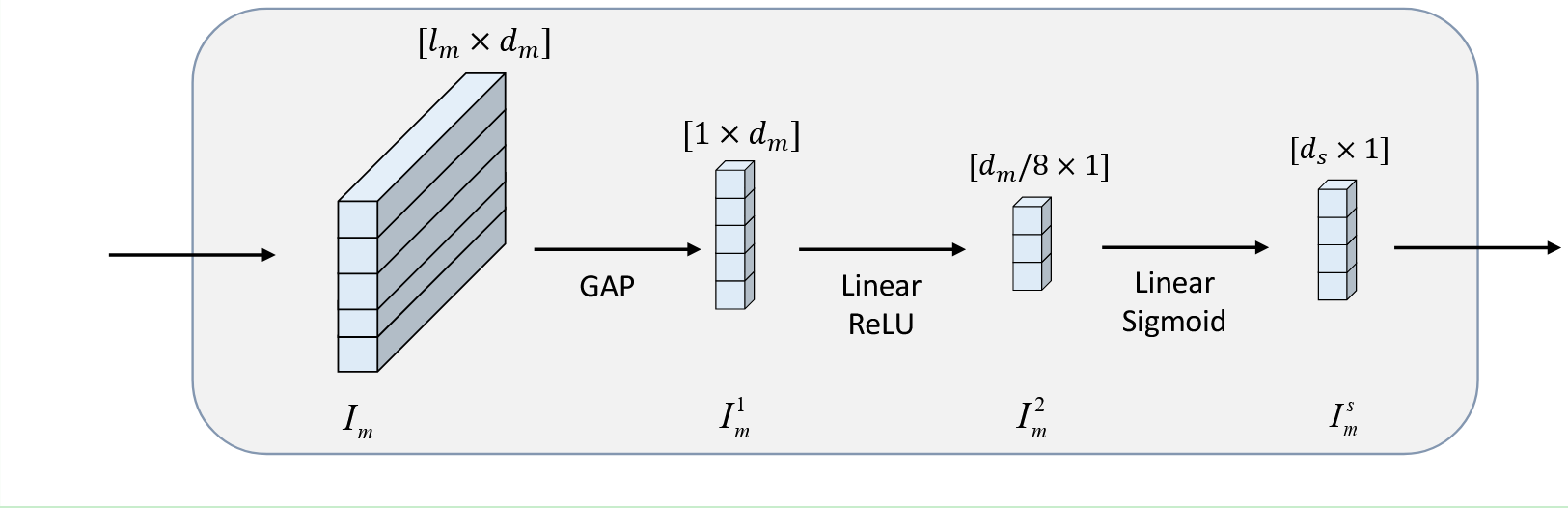
给定一个模态
I
m
I_m
Im,首先利用全局平均池化(GAP)按照序列长度对
I
m
I_m
Im 进行压缩得到
I
m
1
I_m^1
Im1。随后,应用两步非线性变换将
I
m
1
I_m^1
Im1 投影到一个新的低维空间
I
m
s
I_m^s
Ims。
I
m
s
=
σ
2
(
W
2
σ
1
(
W
1
I
m
1
T
)
)
,
m
∈
{
t
,
v
,
a
}
I_m^s=\sigma_2(W_2\sigma_1(W_1I_m^{1\text{T}})),m\in\{t,v,a\}
Ims=σ2(W2σ1(W1Im1T)),m∈{t,v,a}
4.对比学习
4.1 正负样本对的构造
1)首先通过计算相应情感强度之间的差值来确定初始正负对。由于情感强度范围不同(MOSI/MOSEI 中为[-3,3],SIMS 中为[-1,1]),仅在对比学习时使用统一映射将标签值转换为[-1,1]。给定一个批次
B
B
B,用以下公式计算样本
i
∈
B
i\in B
i∈B与不同样本之间的情感强度差异:
D
(
i
,
j
)
=
∣
y
i
−
y
j
∣
,
j
∈
B
&
j
≠
i
D_{(i,j)}=|y_i-y_j|,j\in B\quad\&\quad j\neq i
D(i,j)=∣yi−yj∣,j∈B&j=i
随后,利用情感强度差异阈值
κ
\kappa
κ(超参数,设为了0.4)来确定样本
j
j
j 是被归类为
i
i
i 的初始正样本还是负样本。
{
D
(
i
,
j
)
>
κ
,
(
i
,
j
)
∈
i
n
i
t
i
a
l
n
e
g
a
t
i
v
e
p
a
i
r
s
D
(
i
,
j
)
≤
κ
,
(
i
,
j
)
∈
i
n
i
t
i
a
l
p
o
s
i
t
i
v
e
p
a
i
r
s
\left.\left\{\begin{array}{l}D_{(i,j)}>\kappa, (i,j)\in initial \ negative \ pairs\\D_{(i,j)}\leq\kappa, (i,j)\in initial \ positive \ pairs\end{array}\right.\right.
{D(i,j)>κ,(i,j)∈initial negative pairsD(i,j)≤κ,(i,j)∈initial positive pairs
| 符号 | 含义 |
|---|---|
| y i , y j y_i,y_j yi,yj | 分别代表样本 i i i 和样本 j j j 的情感强度标签 |
2)根据模内和模间情况,对正负样本对进行了详细划分。给定一组初始正负样本对,对于样本 i i i,模内和模间正负样本对的选择如下:

最终,由样本内正对与样本间正对共同构成样本
i
i
i 的正对,样本内负对与样本间负对共同构成样本
i
i
i 的负对。
P
i
=
P
i
n
t
r
a
i
∪
P
i
n
t
e
r
i
N
i
=
N
i
n
t
r
a
i
∪
N
i
n
t
e
r
i
P^i=P_{intra}^i\cup P_{inter}^i\\N^i=N_{intra}^i\cup N_{inter}^i
Pi=Pintrai∪PinteriNi=Nintrai∪Ninteri
4.2 对比损失
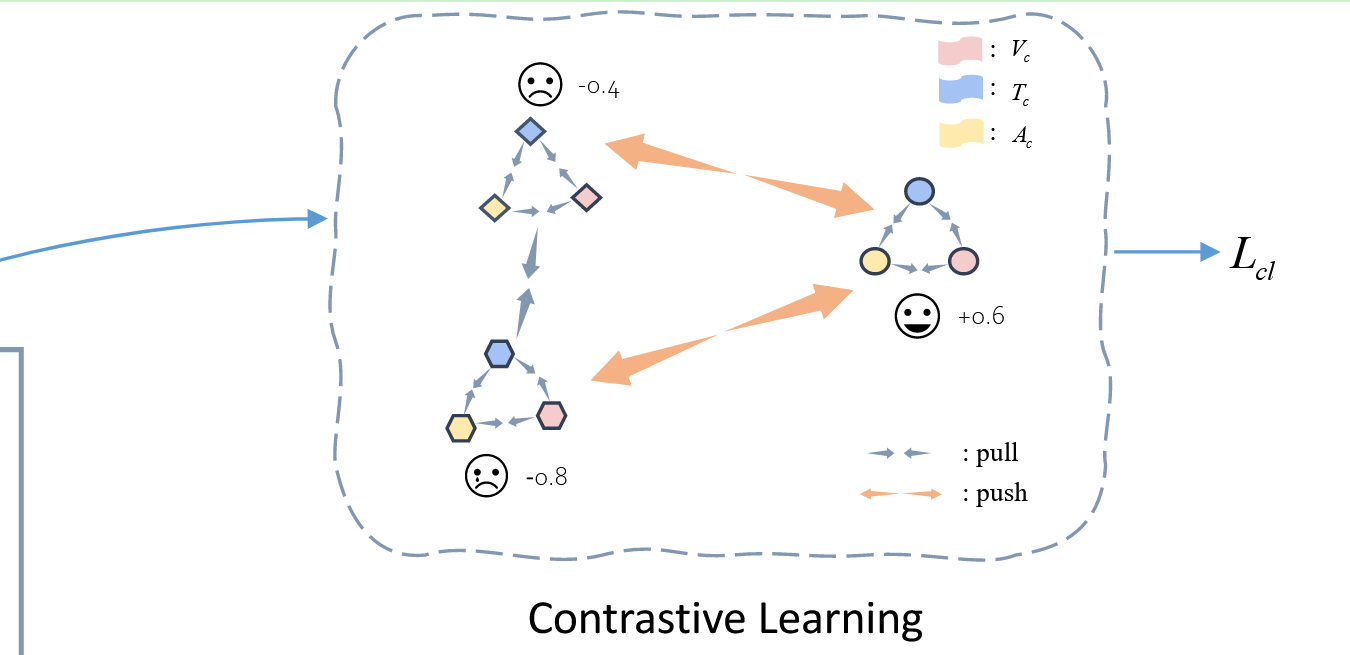
给定样本 i i i、 j j j 和 k k k,其中从 i i i 到 j j j 和 k k k 的情感强度差分别为 0.5 和 1.6, ( i , j ) (i, j) (i,j) 和 ( i , k ) (i, k) (i,k)都是 i i i 的初始负样本对。然而,样本 i i i 和 k k k 之间的情感强度差明显更大。因此,在计算对比损失时,我们对 ( i , k ) (i, k) (i,k) 赋予更高的权重,以便将样本 i i i 和 k k k 在表征空间中推得更远。
为了实现权重分配设计了一种权重函数,如下:
ω
(
i
,
j
)
=
{
∣
tanh
(
D
(
i
,
j
)
−
2
κ
)
∣
×
1.5
,
(
i
,
j
)
∈
initial
positive
pairs
∣
tanh
(
D
(
i
,
j
)
)
∣
×
1.5
,
(
i
,
j
)
∈
initial
negative
pairs
\left.\omega_{(i,j)}=\left\{\begin{array}{ll}\left|\tanh\left(D_{(i,j)}-2\kappa\right)\right|\times1.5,&(i,j)\in\textit{initial positive pairs}\\|\tanh\left(D_{(i,j)}\right)|\times1.5,&(i,j)\in\textit{initial negative pairs}\end{array}\right.\right.
ω(i,j)={
tanh(D(i,j)−2κ)
×1.5,∣tanh(D(i,j))∣×1.5,(i,j)∈initial positive pairs(i,j)∈initial negative pairs

给定一个批次B,对比损失为:
L
c
l
=
−
E
i
∈
B
log
∑
(
a
,
p
)
∈
P
i
δ
(
a
,
p
)
∑
(
a
,
q
)
∈
P
i
∪
N
i
δ
(
a
,
q
)
δ
(
a
,
p
)
=
e
[
w
(
i
,
j
)
∗
s
i
m
(
a
,
p
)
τ
]
\begin{aligned} &L_{cl}=-\mathbb{E}_{i\in B}\log\frac{\sum_{(a,p)\in P^i}\delta(a,p)}{\sum_{(a,q)\in P^i\cup N^i}\delta(a,q)} \\ &\delta(a,p)=e^{[w_{(i,j)}*\frac{sim(a,p)}{\tau}]} \end{aligned}
Lcl=−Ei∈Blog∑(a,q)∈Pi∪Niδ(a,q)∑(a,p)∈Piδ(a,p)δ(a,p)=e[w(i,j)∗τsim(a,p)]
5.总损失
在提取了共性特征和特定特征后,将共性特征向量
F
c
∗
F_c^*
Fc∗ 和三种模态的特定特征向量
I
v
s
,
I
t
s
,
I
a
s
I_v^s,I_t^s,I_a^s
Ivs,Its,Ias 进行拼接,得到拼接后的向量
F
∗
F^*
F∗。最终,将
F
∗
F^*
F∗ 输入到一个3层的 MLP中,预测情感强度
y
^
\hat{y}
y^ 。预测损失如下:
L
t
a
s
k
=
1
N
b
∑
i
N
b
∣
y
i
−
y
^
i
∣
L_{task}=\frac1{N_b}\sum_i^{N_b}|y_i-\hat{y}_i|
Ltask=Nb1i∑Nb∣yi−y^i∣
总损失如下:
L
o
v
e
r
a
l
l
=
L
t
a
s
k
+
γ
L
c
l
L_{overall}=L_{task}+\gamma L_{cl}
Loverall=Ltask+γLcl
| 符号 | 含义 |
|---|---|
| N b N_b Nb | 批次B中的样本数量 |
| L t a s k L_{task} Ltask | MSA任务损失 |
| L c l L_{cl} Lcl | 对比损失 |
| L o v e r a l l L_{overall} Loverall | 总损失 |
| γ \gamma γ | 超参数 |
实验分析
- 在MOSI与MOSEI数据集上进行了实验,CLGSI在多数指标下的效果均优于基线模型。
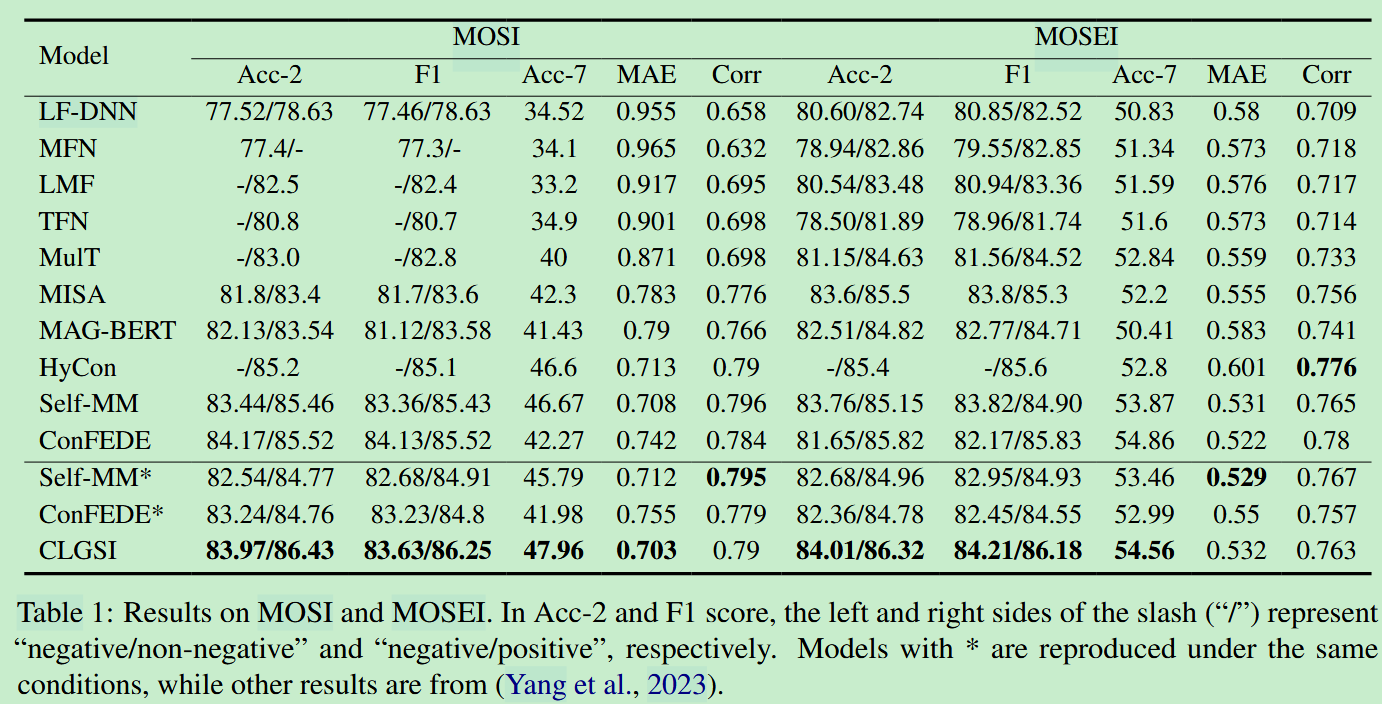
- 在SIMS数据集上进行了实验,CLGSI效果没有超过基线模型ConFEDE,这是因为ConFEDE使用了数据集中额外提供的单模态标签对单模态编码器进行了预训练,从而提高了在中文数据集中的性能。

- 消融研究。
通过对对比学习以及权重分配机制进行消融实验,验证了通过情感强度所引导的对比学习是有效的。

为了证明GLFK的有效性,将GLFK融合机制与普通的Add和Concatenate以及两种GLFK的变体(GK,省略了GLFK中的局部和细粒度部分;LFK,省略了全局部分)进行比较,表明GLFK可以促进多种模态之间的完整信息交互,从而提取全面而详细的信息。

为了证明联合学习的有效性,对共性特征和特定特征进行消融。结果表明当共性特征和特定特征被联合学习时,性能会得到提升。

😃😃😃


















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









