






之前主要搞搞ros小车方面的东西,由于本科是学机械方面的。对于深度学习,大模型一类的东西完全没有概念,但是由于需要,接触计算机视觉方面内容。过程很艰辛,即便是有很专业的女朋友帮助,初次跑完浅浅记录一下,希望对没接触过相关领域的同学们有一定的帮助。
跑的模型是行人重识别的经典模型,从零开始行人重识别 - 知乎,软件包需要有下图几种。
git官网上写得其实是GPU需要大于等于4G,查询自己GPU的大小以及nvidia版本和cuda版本的指令
首先cd到NVSMI目录下,一般都是以下的路径
cd C:/Program Files/NVIDIA Corporation/NVSMI然后
nvidia-smi得到,GPU只有4G,本地运行的话可能比较吃力,所以需要用服务器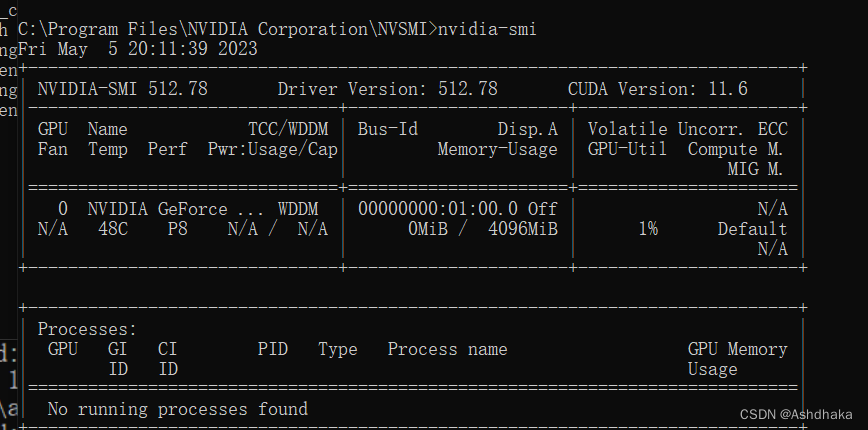
一开始用的是vscode,下载ssh插件远程连接服务器,不稳定经常容易掉,最讨厌的就是终端字体奇丑无比,老被女朋友吐槽,最后用的Xserve。
Xserve连接服务器步骤如下:

点击 sessions-new session 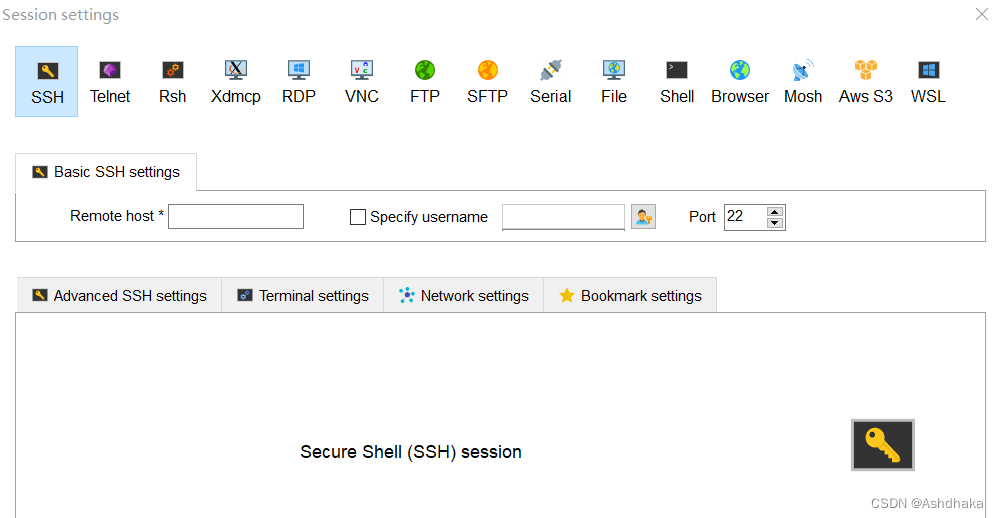
输入服务器ip地址和端口号,最好勾选specify username,输入root,登录。连接好服务器后选择合适的位置建立自己的文件夹,本来想直接把github上的代码和数据集直接git到服务器上的,结果这几天服务器也老出问题,不得已下载到本地再进行上传。
本地上传文件到服务器的两种方法:
1、windows+r,cmd打开命令提示行,cd到你要上传的文件路径下,输入
scp -P 端口号 -r * root@服务器ip地址:你要上传的服务器路径
有的时候会有问题,上传文件不全,然后女朋友告诉的第二种方法。
2、Xserve
session-new session-SFTP,输入ip地址和端口号,username:root
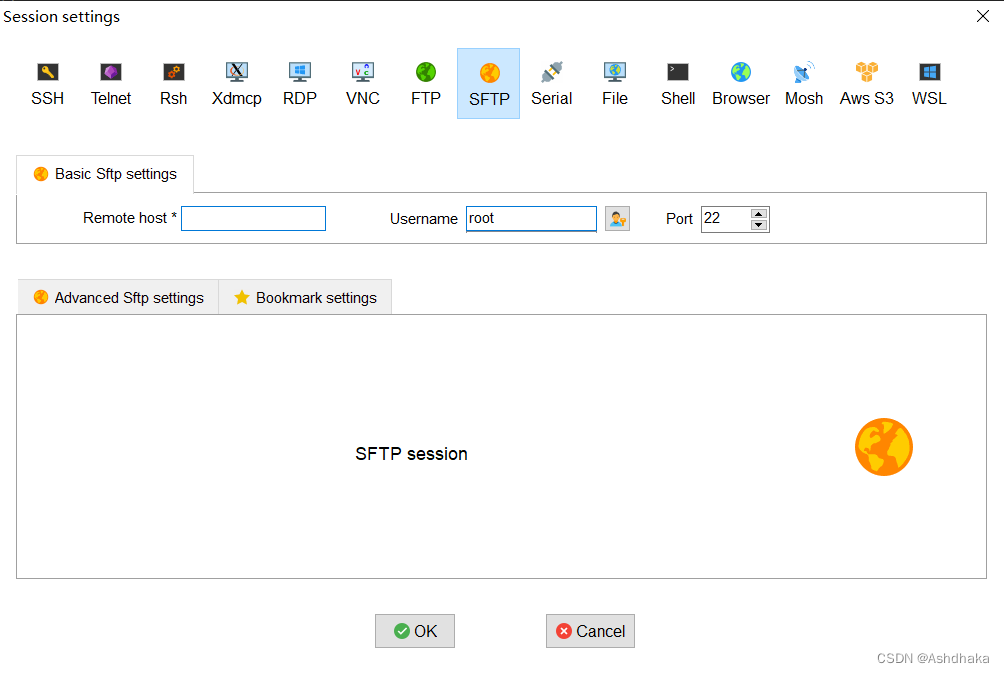
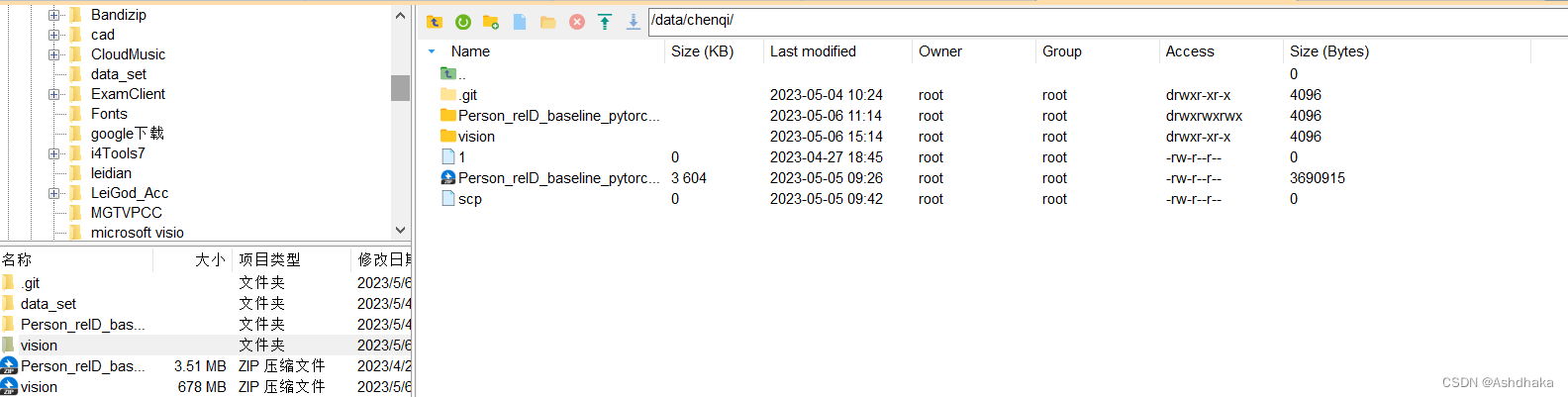
可以直接把本地文件拖到右边服务器上(炫耀一嘴我女朋友好厉害耶)
之后的运行步骤文章写的很清楚了从零开始行人重识别 - 知乎,一步步照做就可以,注意文章中那些前面不挂python的代码,首先要进入python环境下在运行哦

在1.3环节下运行
python train.py --gpu_ids 0 --name ft_ResNet50 --train_all --batchsize 32 --data_dir your_data_path
会报错
RuntimeError: Pin memory thread exited unexpectedly
参考了(10条消息) RuntimeError: Pin memory thread exited unexpectedly_小馆长布鲁克的博客-CSDN博客这篇文章,将pin_memory=True,改为False,结果再次运行时又出现报错
RuntimeError: DataLoader worker (pid(s) xxx) exited unexpectedly
出现这种问题的主要原因因为CPU加载数据和GPU处理数据速度不匹配了,(10条消息) RuntimeError: DataLoader worker (pid(s) 46220) exited unexpectedly_两面包+芝士的博客-CSDN博客 这篇文章写得非常详细,需要在对应的python文件中修改
batchsize
num_workers设的小一点,比如2,甚至不设置(默认为1)
pin_memory 等
后续过程遇到的问题雷同,依然采用上述办法。
从零开始行人重识别学习笔记_行人重识别过程_zhyue77yuyi的博客-CSDN博客
这篇文章对整体模型讲述比较详尽,需要的同学可以看看。
没用自己的机器跑,擦边的gpu估计八太兴,这两天尝试一下 zha 小部件















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









