









背景问题
RNN 是解决时间序列数据的模型。但是他无法解决时间步过长而无法记住长期信息的这个问题。从而诞生了很多 RNN 的变种模型来解决这些问题。我们今天来看下他们的原理和手写他们的实现。
复杂 RNN
常规的 RNN 的逻辑图如下:
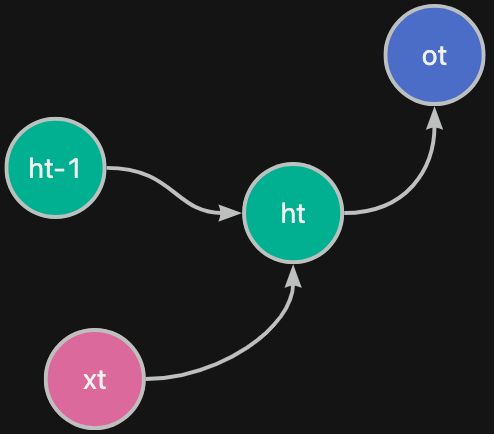
代码如下:
h
t
=
f
(
h
t
−
1
,
x
t
)
h_{t} = f(h_{t-1},x_t)
ht=f(ht−1,xt)
o
t
=
g
(
h
t
)
o_t = g(h_t)
ot=g(ht)
为了解决 传统 RNN 的问题,就有了以下的思路:
- 在不同的转换过程(每个连线)中增加多 一些轻量级的转换,增加记忆度
- 加上残差层
- 增加多更多的输出层,先抽取低维特征,再抽取高维特征的方法
各种的变体的 RNN 的架构图如下:
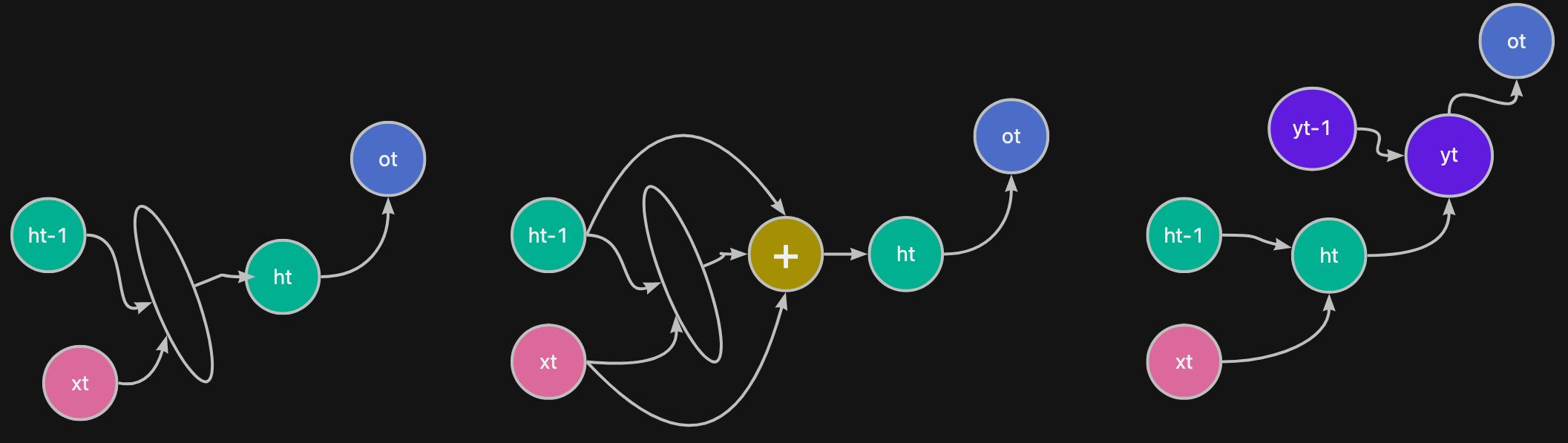
其中最优秀的两种变体模型就是 LSTM 和 GRU 的模型。下面分别对下面的模型进行介绍。
LSTM
LSTM(Long Short-Term Memory)全称 长短期记忆。简单的说,就是记忆分长期和短期的。长期的记忆,可以长时间存活;同理,短期记忆生存时间就比较短。
🔥 RNN 记忆是存在每个时间步的隐状态中的,随着时间的推移,会“遗忘”时间长的隐状态,即权重逐步减少; LSTM 就是 针对重要的记忆,拿个记事本记住,让他不会随着时间的推移而忘记了。
LSTM 与人类的日记习惯一致,每天记录到日记的事情都是重要的事情,但是不会 24 小时每分每秒的事情都记住。某年某月某日中了双色球头奖(长期记忆),都会记录下来,多年后再翻看,都会记忆犹新;同时,489 天前的晚饭吃了什么(短期记忆),大体不会出现在你日记本内,当然也不会在你的脑海内。
记住了原理就可以,不需要过多的细节
原理
原理图
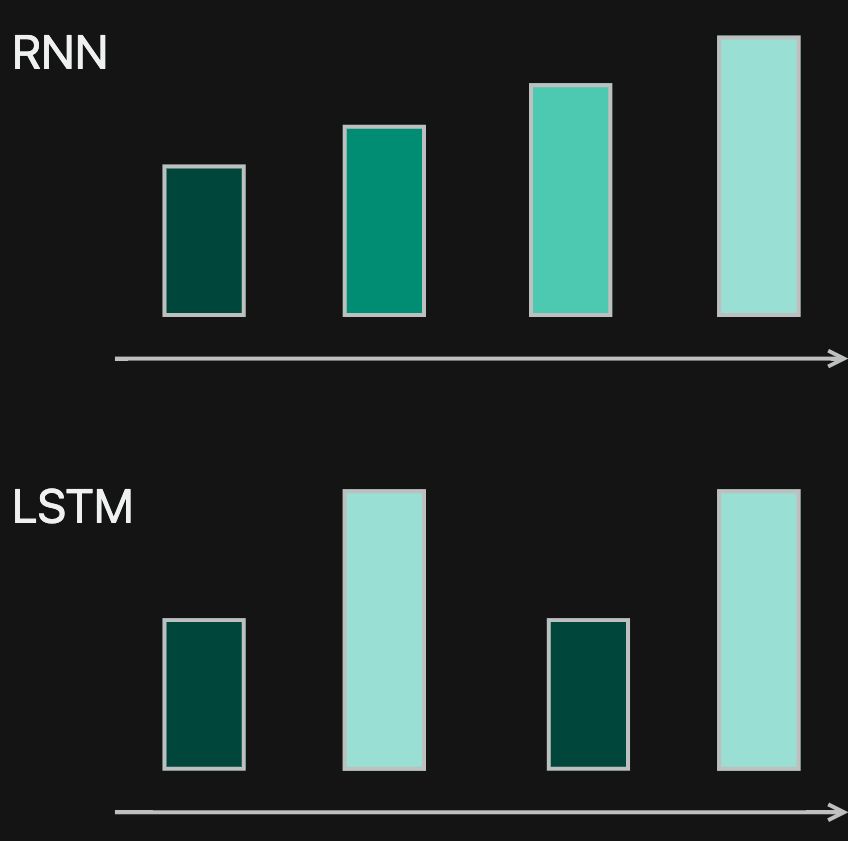
对比 RNN,LSTM 就可以对某些记忆认为是长期的且重要的,进行加权,让他的权重不减弱。
逻辑说明
这里出现了一个新的概念:Cell 记忆 他是包含在 LSTMCell 里面一个内置的记忆体,他就是用于记住哪些 Long Term Memory。
LSTMCell 就是 LSTMModel 的基础的组件,下图就是 LSTMCell 的原理图。整个 Cell 有 3 个门来控制记忆,包括了 遗忘门/输入门/输出门,由他们来控制 输入/输出/隐状态/记忆 之间的关系。
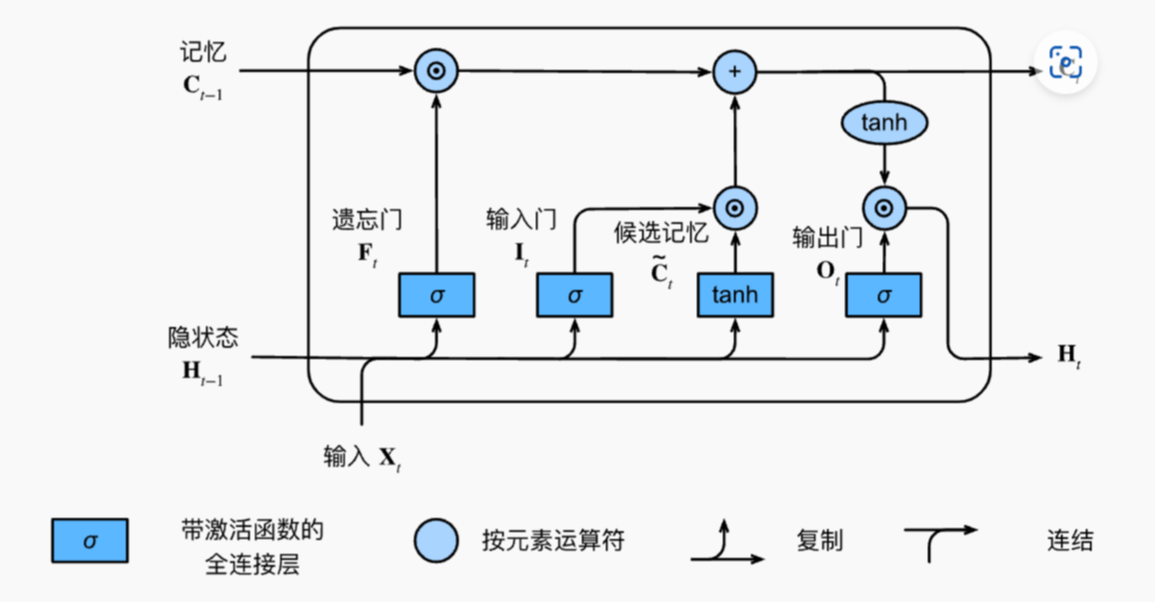
我们直接 dive deep into code,对照这个原理图,会更加容易理解。
组件
下面是节选例子中的 手写LSTM 的 LSTM Cell 代码片段。
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMCell, self).__init__()
self.hidden_size = hidden_size
# 输入门
self.input_gate = nn.Linear(input_size + hidden_size, hidden_size)
# 遗忘门
self.forget_gate = nn.Linear(input_size + hidden_size, hidden_size)
# 输出门
self.output_gate = nn.Linear(input_size + hidden_size, hidden_size)
# 本 Cell 的记忆门
self.cell_gate = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, x, interState):
h_prev, c_prev = interState
combined = torch.cat((x, h_prev), dim=1)
i_t = torch.sigmoid(self.input_gate(combined))
f_t = torch.sigmoid(self.forget_gate(combined))
o_t = torch.sigmoid(self.output_gate(combined))
c_tilde = torch.tanh(self.cell_gate(combined))
# 主要逻辑,下面两行
c_t = f_t * c_prev + i_t * c_tilde
h_t = o_t * torch.tanh(c_t)
return h_t, (h_t, c_t)
请结合注释和原理图,进行阅读
总结
- 上述逻辑 都是简单的 全链接 和 激活函数 构成,所以理解原理是最重要的,内部都是组装而已
- 因为是手写
LSTMCell,简化了逻辑,仅仅是针对 单个数据 + 记忆 处理;sequence 的数据 就是在训练的时候,进行循环;batch 的概念,当然也是没有的。
⚠️ 这里影响到了 1. X, y 的数据结构; 2. 模型内的 forward 的处理方法;3. train 的方法。可以对比文件后面的 nn.LSTM 的解决方法,来一起服用。
最好的方式当然是把 手写 LSTMCell 改写成 (batch, sequence, input_feature) X 数据结构 都适用的代码。
例子
例子目标: 输入 5 个数字,可以预测下一个数据是多少。
分析过程
- 是 回归问题
- “5 个数字” 是一个有连续先后关系的输入,所以使用类 RNN 的模型
- 定义 RNN 的时候 input_feature 和 output_feature 都是 1
详细的代码可以直接访问 ipynb 文件链接。里面有 手动LSTM 和 nn.LSTM 两种不同的实现方案。
训练后的结果
# 训练过程
epoch: 400 loss: 0.01360714
epoch: 450 loss: 0.00120955
epoch: 499 loss: 0.0031908983
# 在 500 后收敛
# 输入 45,46,47,48,49,50
# 输出
[49.966102600097656, 50.8197021484375, 51.54384231567383, 52.14518737792969, 52.62910842895508]
GRU
GRU(Gated Recurrent Unit)全称 门控循环单元,就是使用 逻辑电路的思路去解决模型的问题。
他和 LSTM 一样,都是为了解决 RNN 的长期记忆的问题。同时比 LSTM 的优势是,仅仅是用了两个门 – 重置门 和 更新门。门的数量的减少,自然参数量可以进一步的减少。
记住了原理就可以,不需要过多的细节
原理
原理图
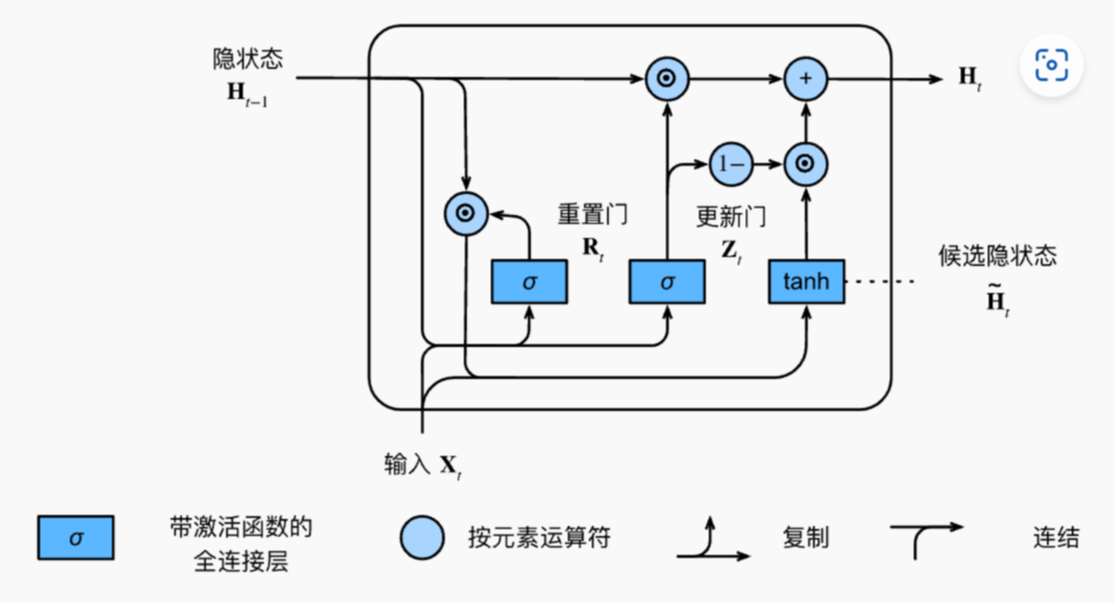
GRUCell 就是 GRUModel 的基础的组件,上图就是 GRUCell 的原理图。整个 Cell 有 2 个门来控制记忆,包括了 重置门/更新门,由他们来控制 输入/输出/隐状态 之间的关系。
⚠️ 注意,与 LSTM 对比,GRU 没有 记忆 的概念,他的所有的记忆都是隐状态中,并且他是使用 门 来更新/重置 隐状态。
组件
下面是节选例子中的 手写GRU 的 GRUCell 代码片段。
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(GRUCell, self).__init__()
self.hidden_size = hidden_size
self.update_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.reset_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.hidden_candidate = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, x, hidden):
# print(f"cell forward : {x.shape} {hidden.shape}")
# cell forward : torch.Size([1]) torch.Size([50])
combined = torch.cat((x, hidden), dim=0)
update_gate = torch.sigmoid(self.update_gate(combined))
reset_gate = torch.sigmoid(self.reset_gate(combined))
# process reset
combined_hidden = torch.cat((x, reset_gate * hidden), dim=0)
# activate after process reset
hidden_candidate = torch.tanh(self.hidden_candidate(combined_hidden))
# process update
hidden = (1 - update_gate) * hidden + update_gate * hidden_candidate
return hidden
请结合注释和原理图,进行阅读。
与 LSTM 对比
- 没有了
Cell的记忆,他是直接修改了 隐状态hidden - 只有两个门,更新门 和 重置门,结构更加的简单
总结
- 上述逻辑 都是简单的 全链接 和 激活函数 构成,所以理解原理是最重要的,内部都是组装而已
- 因为是手写
GRUCell,简化了逻辑,仅仅是针对 单个数据 + 记忆 处理;sequence 的数据 就是在训练的时候,进行循环;batch 的概念,当然也是没有的。
⚠️ 这里影响到了 1. X, y 的数据结构; 2. 模型内的 forward 的处理方法;3. train 的方法。可以对比文件后面的 nn.GRU 的解决方法,来一起服用。
最好的方式当然是把 手写 GRUCell 改写成 (batch, sequence, input_feature) X 数据结构 都适用的代码。
例子
与 LSTM 的例子的题目是一致的,分析的过程也是一致。
详细的代码可以直接访问 ipynb 文件链接。里面有 手动GRU 和 nn.GRU 两种不同的实现方案。
总结
- 无论是
RNN和类RNN模型LSTM/GRU都是 输出时间步的隐状态,这是 时序序列相关的模型的关键 LSTM和GRU,具有模型的可解释性,同时他是解决其他问题的方式用在定义模型上,体现跨学科学习的重要性LSTM和GRU在使用场景上都可以交替使用,看哪个比较适合
















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











