






Q1. 定宽数组、动态数组、关联数组、队列各自特点和使用
-
队列:队列结合了链表和数组的优点,可以在一个队列的任何位置进行增加或者删除元素;
-
定宽数组:属于静态数组,编译时便已经确定大小。其可以分为压缩定宽数组和非压缩定宽数组:压缩数组是定义在类型后面,名字前面;非压缩数组定义在名字后面。Bit [7:0][3:0] name; bit[7:0] name [3:0];
-
动态数组:其内存空间在运行时才能够确定,使用前需要用new[]进行空间分配。
-
关联数组:其主要针对需要超大空间但又不是全部需要所有数据的时候使用,类似于
hash,通过一个索引值和一个数据组成,索引值必须是唯一的。
Q2.多线程fork join/fork join_any/fork join_none的用法差异
-
Fork join:内部begin end块并行运行,直到所有线程运行完毕才会进入下一个阶段。 -
Fork join_any:内部begin end块并行运行,任意一个begin end块运行结束就可以进入下一个阶段。 -
Fork join_none:内部begin end块并行运行,无需等待可以直接进入下一个阶段。 -
wait fork:会引起调用进程阻塞,直到它的所有子进程结束,一般用来确保所有子进程(调用进程产生的进程,也即一级子进程)执行都已经结束。 -
disable fork:用来终止调用进程 的所有活跃进程, 以及进程的所有子进程。
Q3. 多线程的同步调度方法
多线程之间同步主要由mailbox、event、 semaphore三种进行一个通信交互。
-
mailbox邮箱:主要用于两个线程之间的数据通信,通过put函数和 get 函数还有peek函数进行数据的发送和获取。 -
Event:事件主要用于两个线程之间的一个同步运行,通过事件触发和事件等待进行两个线程间的运行同步。使用@(event)或者 wait(event.trigger)进行等待,->进行触发。 -
Semaphore:旗语主要是用于对资源访问的一个交互,通过key的获取和返回实现一个线程对资源的一个访问。使用put和 get函数获取返回key。一次可以多个。
Q4. Task和function的区别
-
函数能调用另一个函数,但不能调用任务,任务能调用另一个任务,也能调用另一个函数
-
函数总是在仿真时刻0就开始执行,任务可以在非零时刻执行
-
函数一定不能包含任何延迟、事件或者时序控制声明语句,任务可以包含延迟、事件或者时序控制声明语句
-
函数至少有一个输入变量,可以有多个输入变量,任务可以没有或者多个输入(input)、输出(output)和双向(inout)变量
-
函数只能返回一个值,函数不能有输出(output)或者双向(inout)变量,任务不返回任何值,任务可以通过输出(output)或者双向(inout)变量传递多个值
Q5.简述在TB中使用interface和clocking blocking的好处
-
Interface是一组接口,用于对信号进行一个封装,捆扎起来。如果像verilog中对各个信号进行连接,每一层我们都需要对接口信号进行定义,若信号过多,很容易出现人为错误,而且后期的可重用性不高。因此使用interface接口进行连接,不仅可以简化代码,而且提高可重用性,除此之外,interface内部提供了其他一些功能,用于测试平台与DUT之间的同步和避免竞争。 -
Clocking block:在interface内部我们可以定义clocking块,可以使得信号保持同步,对于接口的采样vrbg和驱动有详细的设置操作,从而避免TB与DUT的接口竞争,减少我们由于信号竞争导致的错误。采样提前,驱动落后,保证信号不会出现竞争。
Q6. OPP(面向对象)的特性?
封装、继承和多态
-
封装:通过将一些数据和使用这些数据的方法封装在一个集合里,成为一个类。
-
继承:允许通过现有类去得到一个新的类,且其可以共享现有类的属性和方法。现有类叫做基类,新类叫做派生类或扩展类。
-
多态:得到扩展类后,有时我们会使用基类句柄去调用扩展类对象,这时候调用的方法如何准确去判断是想要调用的方法呢?通过对类中方法进行
virtual声明,这样当调用基类句柄指向扩展类时,方法会根据对象去识别,调用扩展类的方法,而不是基类中的。而基类和扩展类中方法有着同样的名字,但能够准确调用,叫做多态。
Q7. 简述UVM的工厂机制
-
Factory机制也叫工厂机制,其存在的意义就是为了能够方便的替换TB中的实例或者已注册的类型。一般而言,在搭建完TB后,我们如果需要对TB进行更改配置或者相关的类信息,我们可以通过使用factory机制进行覆盖,达到替换的效果,从而大大提高TB的可重用性和灵活性。 -
要使用factory机制先要进行:
-
将类注册到factory表中
-
创建对象,使用对应的语句 (type_id::create)
-
编写相应的类对基类进行覆盖。
Q8. SV中的interface的clock blocking的功能
-
Interface是一组接口,用于对信号进行一个封装,捆扎起来。如果像verilog中对各个信号进行连接,每一层我们都需要对接口信号进行定义,若信号过多,很容易出现人为错误,而且后期的可重用性不高。因此使用interface接口进行连接,不仅可以简化代码,而且提高可重用性,除此之外,interface内部提供了其他一些功能,用于测试平台与DUT之间的同步和避免竞争。 -
Clocking block:在interface内部我们可以定义clocking块,可以使得信号保持同步,对于接口的采样和驱动有详细的设置操作,从而避免TB与DUT的接口竞争,减少我们由于信号竞争导致的错误。采样提前,驱动落后,保证信号不会出现竞争。
Q9. 动态数组和联合数组的区别?
-
动态数组:其内存空间在运行时才能够确定,使用前需要用new[]进行空间分配。
-
关联数组:其主要针对需要超大空间但又不是全部需要所有数据的时候使用,类似于hash,通过一个索引值和一个数据组成: bit [63:0] name[bit[63:0]];索引值必须是唯一的。
-
【关联数组】可以用来保存稀疏矩阵的元素。当你对一个非常大的地址空间寻址时,该数组只为实际写入的元素分配空间,这种实现方法所需要的空间要小得多。
-
此外,关联数组有其它灵活的应用,在其它软件语言也有类似的数据存储结构,被称为哈希(Hash)或者词典(Dictionary),可以灵活赋予键值(key)和数值(value) 。
Q10. UVM从哪里启动,接口怎么传递到环境中
UVM的启动 总结:
-
在导入uvm_pkg文件时,会自动创建UVM_root所例化的对象UVM_top,UVM顶层的类会提供run_test()方法充当UVM世界的核心角色,通过UVM_top调用run_test()方法.
-
在环境中输入run_test来启动UVM验证平台,run_test语句会创建一个my_case0的实例,得到正确的test_name
-
依次执行uvm_test容器中的各个component组件中的phase机制,按照顺序:
-
build-phase(自顶向下构建UVM 树)
-
connet_phase(自低向上连接各个组件)
-
end_of_elaboration_phase
-
start_of_simulation_phase
-
run_phase() objection机制仿真挂起,通过start启动sequence(每个sequence都有一个body任务。当一个sequence启动后,会自动执行sequence的body任务),等到sequence发送完毕则关闭objection,结束run_phase()(UVM_objection提供component和sequence共享的计数器,当所有参与到objection机制中的组件都落下objection时,计数器counter才会清零,才满足run_phase()退出的条件)
-
执行后面的phase
Q11. 接口怎么传递到验证环境中(uvm_config_db)
-
传递virtual interface到环境中;
-
配置单一变量值,例如int、string、enum等;
-
传递配置对象(config_object)到环境;
-
传递virtual interface到环境中;
a) 虽然SV可以通过层次化的interface的索引完成传递,但是这种传递方式不利于软件环境的封装和复用。通过使用uvm_config_db配置机制来传递接口,可以将接口的传递与获取彻底分离开。
b) 接口传递从硬件世界到UVM环境可以通过uvm_config_db来实现,在实现过程中应当注意:
c) 接口传递应发生在run_test()之前。这保证了在进入build_phase之前,virtual interface已经被传递到uvm_config_db中。
d) 用户应当把interface与virtual interface区分开来,在传递过程中的类型应当为virtual interface,即实际接口的句柄。
-
配置单一变量值,例如int、string、enum等;在各个test中,可以在build_phase阶段对底层组件的各个变量加以配置,进而在环境例化之前完成配置,使得环境可以按照预期运行。
-
传递配置对象(config_object)到环境;
-
在test配置中,需要配置的参数不只是数量多,可能还分属于不同的组件。对这么多层次的变量做出类似上边的单一变量传递,需要更多的代码,容易出错且不易复用。
-
如果整合各个组件中的变量,将其放置在一个uvm_object中,再对中心化的配置对象进行传递,将有利于整体环境的修改维护,提升代码的复用性。
Q12. UVM的优势,为什么要用UVM
UVM其实就是SV的一个封装,将我们在搭建测试平台过程中的一些重复性和重要的工作进行封装,从而使我们能够快速的搭建一个需要的测试平台,并且可重用性还高。但是UVM又不仅仅是封装。
UVM做的事情就是给提高验证环境的复用性,那么相对SV,UVM 为什么提高了复用性?一下几点将回答这个问题。
总结为以下几点:
1.各个模块的验证环境是独立封装的,对外不需要保留数据端口,因此便于环境的进一步集成复用。
这也就是说每个模块单元都具有自闭性,自闭性是指单元组件(如uvm_agent 或者uvm_env)自身可以成为独立行为、不依赖于其他并行的组件。单元自闭性为日后的组件复用提供了良好的基础。各个子环境可以独立集成于顶层环境,互相也不需要额外的通信连接,各自划分“小世界”。
而在SV中则不行,例如例化driver就需要generator提供帮助,否则编译报错。2.由于UVM自身的phase机制,在顶层协调各个子环境时,无需考虑由于子环境之间的例化顺序而导致对象句柄引用悬空的问题
环境框架的创建就是依赖于回归创建。通过这种方式,上一级的组件在例化自身之后,会执行各个phase阶段,通过build_phase可以进一步创建子组件,而这些子组件也通过一样的过程去创建下一级组件。回归创建的实现依赖于自顶向下执行的 build_phase 。通过build_phase这种结构化创建,可以保证父组件必先于子组件创建,而创建过程包括以下步骤:
在定义成员变量时赋予默认值,或者在new( ) 函数中赋予初值
结构配置变量用来决定组件的条件生成,如agent依靠is active 判断是否需要例化sequencer和driver
模式配置变量用来决定各个子组件的工作模式
子组件按照自顶向下、从前到后的顺序依次生成
3.由于子环境的测试序列是相对独立的,这使得顶层在复用子环境测试序列而构成virtual sequence 时,不需要额外的迁移成本。
在完成整个环境创建以后,各个组件会通过通信端口的连接进行数据通信(TLM通信)
4.UVM提供config_db配置方式,使得整体环境的结构和运行模式都可以从树状的config中获取,这也使得顶层环境可以在不同uvm_test 进行集中管理。
Q13. 说一下ref类型,你用到过嘛
Ref参数类型是引用
-
向子程序传递数组时应尽量使用
ref获取最佳性能,如果不希望子程序改变数组的值,可以使用const ref类型 -
在任务里可以修改变量而且修改结果对调用它的函数随时可见。
Q14.说一下component和object的区别,item是component还是object
UVM中component也是由object派生出来的,不过相比于object, component有很多其没有的属性,例如phase机制和树形结构等。在UVM中,不仅仅需要component这种较为复杂的类,进行TB的层次化搭建,也需要object这种基础类进行TB的事务搭建和一些环境配置等。Item是object
Q15. UVM的树形结构
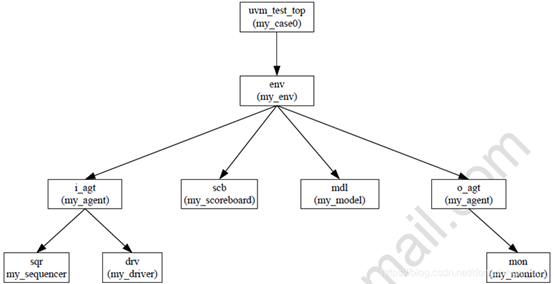
Q16. UVM验证环境的组成
-
Sequencer:负责将数据转给driver -
driver负责数据的发送;driver有时钟/时序的概念。 -
Agent:其实只是简单的把driver,monitor和sequencer封装在一起。 -
Agent:对应的是物理接口协议,不同的接口协议对应不同的agent,一个平台通常会有多个agent。 -
Env:则相当于是一个特大的容器,将所有成员包含进去。
Q17. Virtual sequencer 和sequencer的区别
-
Virtual sequencer主要用于对不同的agent进行协调时,需要有一定顶层的sequencer对内部各个agent中的sequencer进行协调 -
virtual sequencer是面向多个sequencer的多个sequence群,而sequencer是面向一个sequencer的sequence群。 -
Virtual sequencer桥接着所有底层的sequencer的句柄,其本身也不需要传递item,不需要和driver连接。只需要将其内部的底层sequencer句柄和sequencer实体对象连接。
Q18.平台往里边输入数据的话怎么输入sequence, sequence,sequencer,driver之间的通信
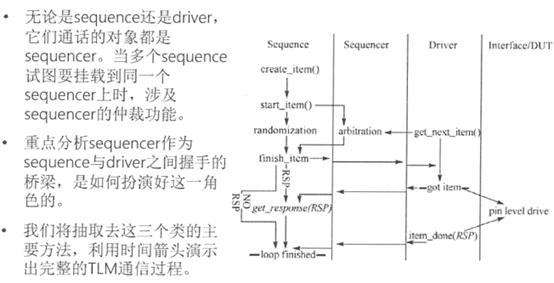


在多个sequence同时向sequencer发送item时,需要有ID信息表明该item从哪个sequence来,ID信息在sequence创建item时就赋值了。
Q19. 代码覆盖率、功能覆盖率和断言覆盖率的区别
-
代码覆盖率——是针对RTL设计代码的运行完备度的体现,包括行覆盖率、条件覆盖率、FSM覆盖率、跳转覆盖率、分支覆盖率,只要仿真就可以收集,可以看DUT的哪部分代码没有动,如果有一部分代码一直没动看一下是不是case没有写到。
-
功能覆盖率---与
spec比较来发现,design是否行为正确,需要按verification plan来比较进度。用来衡量哪些设计特征已经被测试程序测试过的一个指标
-
首要的选择是使用更多的种子来运行现有的测试程序;
-
其次是建立新的约束,只有在确实需要的时候才会求助于定向测试,改进功能覆盖率最简单的方法是仅仅增加仿真时间或者尝试新的随机种子。
-
验证的目的就是确保设计在实际环境中的行为正确。设计规范里详细说明了设备应该如何运行,而验证计划里则列出了相应的功能应该如何激励、验证和测量
-
断言覆盖率:用于检查几个信号之间的关系,常用在查找错误,主要是检查时序上的错误,测量断言被触发的频繁程度。
Q20. 为什么选验证?
这个问题很重要,建议好好准备,面试的时候经常会问~
Q21.ASIC设计流程和验证流程
ASIC设计流程:
芯片架构
RTL设计
功能仿真
综合&扫描链的插入(DFT)
等价性检查
形式验证
静态时序分析(STA)
布局规划
布局布线
布线图和原理图比较
设计规则检查
GDII
验证流程:
阅读功能描述文档
准备验证计划
提取验证功能点
绘制验证结构
搭建验证环境
编写测试用例
定义功能覆盖率
发现缺陷和验证计划修复
回归测试-收集覆盖率
分析覆盖率、修改或添加测试用例
最终全面通过回归测试和满足覆盖率要求
Q22. Find 队列和find index队列
find的队列应该是返回队列的值,一般的话是和with配合使用,find index应该是返回索引值
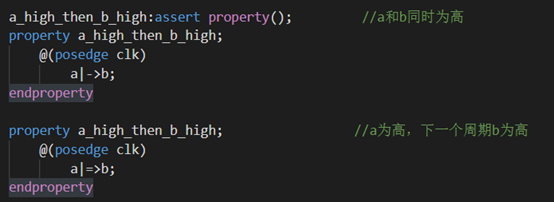
Q23. 用过断言嘛?写一个断言,a为高的时候,b为高,还有a为高的时候,下一个周期b为高
Q24. 断言的概念和作用,立即断言和并行断言
断言是设计的属性描述。如果在一个仿真中被检查的属性不像我们期望的那样表现,那么这个断言将失败;如果一个被禁止在设计中出现的属性在仿真中出现,那么这个断言将失败。
断言:可以检查时序,查找违例。
可以将断言分为两种常见的类型:
立即断言(immediate assertion) 。.非时序的。可以在initial/always过程块或者task/function中使用。
time t;
always@(posedge clk)
if(state==req)
assert(req||req2)
else begin
t=$time;
#5 $error("assert faile at time %0t",t);
end 并行断言(concurrent assertion ),时序性的。关键词property用来区分立即断言和并行断言。
之所以称之为并行,是因为它们与设计模块一同并行执行。
property req_grant_prop
@(posedge clk) req ##2 gnt ##1 !req !gnt;
endproperty
req_grantassert: assert property(req_grant_prop)
else
error();
req拉高 2个周期后gnt拉高 一个周期后 req拉低 一个周期后 gnt拉低
sequence 是用来表示在一个或多个时钟内的时序描述。
sequence s1;
@(posedge clk) a##1 b##c;
endsequence
sequence s2;
@(posedge clk) a##[2:3] b ##c;
endsequence
porperty p1;
@(posedge clk) disable iff(!rest)
s1!=s2;
endporertyQ25. 形式验证
-
形式验证指从数学上完备地证明或验证电路的实现方案是否确实实现了电路设计所描述的功能。形式验证方法分为等价性验证、模型检验和定理证明等。
-
形式验证主要验证数字IC设计流程中的各个阶段的代码功能是否一致,包括综合前RTL代码和综合后网表的验证,因为如今IC设计的规模越来越大,如果对门级网表进行动态仿真,会花费较长的时间,而形式验证只用几个小时即可完成一个大型的验证。另外,因为版图后做了时钟树综合,时钟树的插入意味着进入布图工具的原来的网表已经被修改了,所以有必要验证与原来的网表是逻辑等价的
Q26. 如何保证验证的完备性?
-
首先不可能百分百完全完备,即遍历所有信号的组合,这既不经济也不现实。
-
所以只能通过多种验证方法一起验证尽可能减少潜在风险,一般有这些验证流程:ip级验证、子系统级验证、soc级验证,除这些以外,还有upf验证、fpga原型验证等多种手段。
-
前端每走完一个阶段都需要跟设计以及系统一起
review验证功能点,测试用例,以及特殊情况下的波形等。 -
芯片后端也会做一些检查,像sta、formality、DFM、DRC检查等,也会插入一些DFT逻辑供流片回来测试用。流片归来进行测试,有些bug可以软件规避,有些不能规避,只能重新投片
Q27. 启动Sequence的方法(sequence挂载到sequencer上)
1.通过sequence.start的方式显示启动(例化sequence然后再调用start指定sequencer启动)
my_sequence my_seq;
my_seq=my_sequence::type_id::create("my_seq");
my_seq.start(sequencer);
2.通过default sequence来隐式启动
通过config_db将seq 传送到sequencer上
uvm_config_db#(uvm_object_wrapper)::set(thid, '''env.i_agt.sqr.main_phase',"default_sequencer",my_sequence::type_id::get());
3.也可以通过‘uvm_do系列宏启动
默认选择seq启动的seqr上seq中创建的tr会发送给seqr,seqr负责tr的调度,发送给driver。
Q28. 面向对象编程的优势
-
易维护:采用面向对象思想设计的结构,可读性高,由于继承的存在,即使改变需求,那么维护也只是在局部模块,所以维护起来是非常方便和较低成本的。
-
质量高:在设计时,可重用现有的,在以前的项目的领域中已被测试过的类使系统满足业务需求并具有较高的质量。
-
效率高:在软件开发时,根据设计的需要对现实世界的事物进行抽象,产生类。使用这样的方法解决问题,接近于日常生活和自然的思考方式,势必提高软件开发的效率和质量。
-
易扩展:由于继承、封装、多态的特性,自然设计出高内聚、低耦合的系统结构,使得系统更灵活、更容易扩展,而且成本较低。
Q29. 事件的触发
用来触发事件时,使用->;用来等待事件使用@或者wait。
Q30. 约束的几种形式
-
权重约束 dist:有两种操作符::=n :/n 第一种表示每一个取值权重都是n,第二种表示每一个取值权重为n/num。
-
条件约束 if else 和->(case):if else 就是和正常使用一样;->通过前面条件满足后可以触发后面事件的发生。
-
范围约束inside:inside{[min:max]};范围操作符,也可以直接使用大于小于符号进行,但是不可以连续使用,如 min<wxm<max 这是错误的
Q31. 哪些继承于component,哪些继承于object
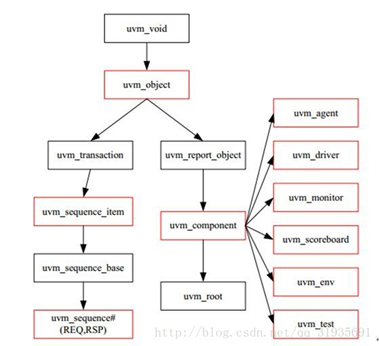
除了driver、monitor、agent、model、scoreboard、env、test之外全部用uvm_object。
Q32. get_next_item()和try_next_item()有什么区别
-
get_next_item()是一个阻塞调用,直到存在可供驱动的sequence item为止,并返回指向sequence item的指针。 -
try_next_item()是非阻塞调用,如果没有可供驱动的sequence item,则返回空指针。
Q33. 断言 and 和 和 intersect 区别
-
And指的是两个序列具有相同的起始点,终点可以不同。 -
Intersect指的是两个序列具有相同的起始点和终点。 -
Or指的是两个序列只要满足一个就可以 -
Throughout指的是满足前面要求才能执行后面的序列
Q34. Break;continue;return的含义,return之后,function里剩下的语句会执行吗
-
break语句结束整个循环。 -
continue立即结束本次循环,继续执行下一次循环。 -
return语句会终止函数的执行并返回函数的值(如果有返回值的话)。 -
return之后,function里剩下的语句不能执行,其是终止函数的执行,并返回函数的值。
Q35. 触发器和锁存器的区别
-
触发器:时钟触发,受时钟控制,只有在时钟触发时才采样当前的输入,产生输出。
-
锁存器由电平触发,非同步控制。在使能信号有效时锁存器相当于通路,在使能信号无效时锁存器保持输出状态。触发器由时钟沿触发,同步控制。
-
锁存器对输入电平敏感,受布线延迟影响较大,很难保证输出没有毛刺产生;触发器则不易产生毛刺
Q36. 一个简单的UVM验证平台
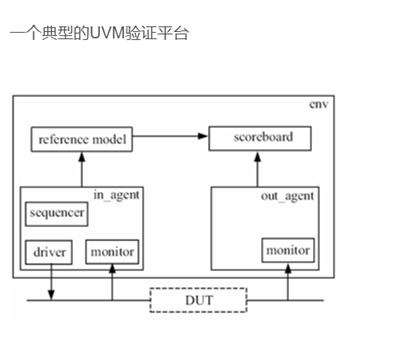
Q37. 怎么编写测试用例?
主要是编写sequence,然后在body里面根据测试功能要求写相应的激励,然后再通过ref_model和checker判断功能是否实现?
Q38. 如果有很多测试用例,如何让它们自动执行?
可以写脚本让它们自动执行,例如makefile...
Q39.断言$past, $stable, $fell, $rose,$isunknow的用法
$rose() 0到1 变化
$fell() 1到0 变化
$stable() 稳定没有变化
$past(a,2)表示a信号前2个周期的信号值;
$isunknow()表示检测信号值是否存在X态或Z态;
例如让你写abcd四个信号在时钟沿处监测,当cd同时为1时,在时钟的前两个周期要ab同时为1的断言
Q40. 如何关闭约束
-
通过
constraint_mode(0)关闭默认范围的约束块 -
constraint_mode(1)是打开约束 -
可以用
soft关键字修饰特定的约束语句,这样既可以让变量在一般的情况下取默认值,也可以直接给变量赋默认值范围外的取值。
Q41. 队列的使用方法,以及push back和pop front的区别
队列的使用方法:insert,delete,push_back和pop_frontPush插入,pop取出Front前边,back后边
Q42. Rand 和randc的区别
-
rand修饰符:rand修饰的变量,每次随机时,都在取值范围内随机取一个值,每个值被随机到的概率是一样的,就想掷骰子一样。 -
randc修饰符:randc表示周期性随机,即所有可能的值都取到过后,才会重复取值
Q43. 组件之间的通信机制,analysis port和其它的区别
-
通信分为,单向通信,双向通信和多向通信
-
单向通信:指的是从
initiator到target之间的数据流向是单一方向的 -
双向通信:双向通信的两端也分为
initiator和target,但是数据流向在端对端之间是双向的 -
多向通信:仍然是两个组件之间的通信,是指
initiator与target之间的相同TLM端口数目超过一个时的处理解决办法。
-
blocking阻塞传输的方法包含:
-
Put():
initiator先生成数据Tt,同时将该数据传送至target。 -
Get():
initiator从target获取数据Tt,而target中的该数据Tt则应消耗。 -
Peek():
initiator从target获取数据Tt,而target中的该数据Tt还应保留。
-
通信管道:
-
TLM FIFO:可以进行数据缓存,功能类似于mailbox,不同的地方在于uvm_tlm_fifo提供了各种端口(put、get、peek)供用户使用 -
analysis port:一端对多端,用于多个组件同时对一个数据进行处理,如果这个数据是从同一个源的TLM端口发出到达不同组件,则要求该端口能够满足一端到多端,如果数据源端发生变化需要通知跟它关联的多个组件时,我们可以利用软件的设计模式之一观察者模式实现,即广播模式 -
analysis TLM FIFO
a. 由于analysis端口提出实现了一端到多端的TLM数据传输,而一个新的数据缓存组件类uvm_tlm_analysis_fifo为用户们提供了可以搭配uvm_analysis_port端口uvm_analysis_imp端口和write()函数。
b.uvm_tlm_analysis_fifo类继承于uvm_tlm_fifo,这表明它本身具有面向单一TLM端口的数据缓存特性,而同时该类又有一个uvm_analysis_imp端口analysis_export并且实现了write()函数:
-
request & response通信管道 双向通信端口
transport,即通过在target端实现transport()方法可以在一次传输中既发送request又可以接收response。
Q44. 简述深拷贝和浅拷贝
-
浅拷贝可以使用列表自带的
copy()函数(如list.copy()),或者使用copy模块的copy()函数。深拷贝只能使用copy模块的deepcopy(),所以使用前要导入:from copy import deepcopy -
如果拷贝的对象里的元素只有值,没有引用,那浅拷贝和深拷贝没有差别,都会将原有对象复制一份,产生一个新对象,对新对象里的值进行修改不会影响原有对象,新对象和原对象完全分离开。
-
如果拷贝的对象里的元素包含引用(像一个列表里储存着另一个列表,存的就是另一个列表的引用),那浅拷贝和深拷贝是不同的,浅拷贝虽然将原有对象复制一份,但是依然保存的是引用,所以对新对象里的引用里的值进行修改,依然会改变原对象里的列表的值,新对象和原对象完全分离开并没有完全分离开。而深拷贝则不同,它会将原对象里的引用也新创建一个,即新建一个列表,然后放的是新列表的引用,这样就可以将新对象和原对象完全分离开。
Q45. 类的public、protected和local的区别
-
如果没有指明访问类型,那么成员的默认类型是public,子类和外部均可以访问成员。
-
如果指明了访问类型是
protected,那么只有该类或者子类可以访问成员,而外部无法访问。 -
如果指明了访问类型是
local,那么只有该类可以访问成员,子类和外部均无法访问。
Q46. 对UVM验证方法学的理解
-
刚开始接触的时候,我认为
UVM其实就是SV的一个封装,将我们在搭建测试平台过程中的一些重复性和重要的工作进行封装,从而使我们能够快速的搭建一个需要的测试平台,并且可重用性还高。因此我当时觉得它就是一个库。 -
不过,随着学习的不断深入,当我深入理解
UVM中各种机制和模型的构造和相互之间关系之后,我觉得其实UVM方法学对于使用何种语言其实并不重要,重要的是他的思想,比如:在UVM中有sequence机制,以往如果我们使用SV进行TB搭建时,我们一般会采用driver一个类进行数据的产生,转换,发送,或者使用generator和driver两个进行,这种方式可重用性很低,而且代码臃肿;但是在UVM中我们通过将sequence、sequencer、driver、sequence_item拆开,相互独立而又有联系,因此我们只需关注每一个类需要做的工作就可以,可重用性高。我在学习sequence时,我经常把sequence比作蓄水池,sequence_item就是水,sequencer就是一个调度站,driver就是总工厂,通过这种方式进行处理,我们的总工厂不需要管其他,只需处理运送过来的水资源就可以,而sequencer只需要调度水资源,sequence只需要产生不同的水资源。而这种处理方式和现实世界中的生产模式又是基本吻合的。除此之外,还有好多好多,其实UVM方法学中很多思想就是来源于经验,来源于现实生活,而不在乎是何种语言。
Q47. 请谈一下UVM的验证环境结构,各个组件间的关系
画出UVM的验证环境结构,如图所示
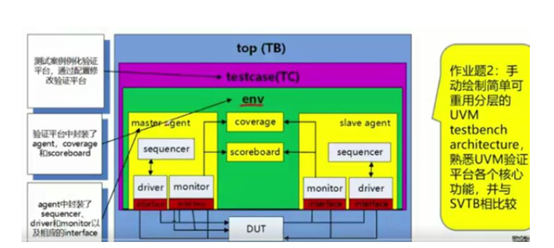
首先,UVM测试平台基本是由object和 component组成的,其中 component搭建了TB的一个树形结构,其基本包含了driver、monitor、sequencer、agent、scoreboard、model、env、test、top;然后object一般包含sequence_item、config和一些其他需要的类。各个组件相互独立,又通过TLM事务级传输进行通信,除此之外,DUT 与driver和 monitor 又通过interface进行连接,实现驱动和采集,最后在top层进行例化调用test进行测试。
Q48. 举例说明UVM组件中常用的方法,各种phase关系,phase机制作用
-
UVM中有很多非常有趣的机制,例如factory机制,field_automation机制,phase机制,打印机制,sequence机制,config_db机制等,这些机制使得我们搭建的UVM能够有很好的可重用性和使得我们平台运行有秩序稳定。 -
例如
phase机制,phase机制主要是使得UVM的运行仿真层次化,使得各种例化先后次序正确。UVM的phase机制主要有9个,外加12个小phase。主要的phase有build phase、connect phase、run phase、report phase、final phase等,其中除了run phase是** task**,其余都是function,然后build phase和final phase都是自顶向下运行,其余都是自底向上运行。Run phase和12个小phase(reset phase、configure phase、main phase、shutdown phase)是并行运行的,有这12个小phase主要是进一步将run phase中的事务划分到不同的phase进行,简化代码。注意,run phase和 12个小phase最好不要同时使用。从运行上来看,9个phase顺序执行,不同组件中的同一个phase执行有顺序,build phase为自顶向下,只有同一个phase全部执行完毕才会执行下一个phase。 -
所有的
phase按照以下顺序自上而下自动执行:(九大phase,其中run phase又分为12个小phase)build_paseconnect_phase
end_of_elaboration_phase
start_of_simulation_phase
run_pase
extract_phase
check_phase
report_phase
final_phase
其中,run_phase按照以下顺序自上而下执行:
pre_reset_phase
reset_phase
post_reset_phase
pre_configure_phase
configure_phase
post_configure_phase
pre_main_phase
main_phase
post_main_phase
pre_shutdown_phase
shutdown_phase
post_shutdown_phase
Q49. phase中的domain概念
Domain是用来组织不同组件,实现独立运行的概率。默认情况下,UVM的9个phase属于 common_domain,12个小phase属于uvm_domain。例如,如果我们有两个dirver类,默认情况下,两个driver类中的复位phase和 main phase必须同时执行,但是我们可以设置两个driver属于不同的domain,这样两个dirver就是独立运行的了,相当于处于不同的时钟域(只针对12个小phase有效)。
Q50. run_phase和main_phase之间的关系;
-
run_phase和main phase(动态运行)都是task phase,且是并行运行的,后者称为动态运行(run-time)的phase。 -
如果想执行一些耗费时间的代码,那么要在此
phase下任意一个component中至少提起一次objection,这个结论只适用于12个run-time的phase。对于run_phase则不适用,由于run_phase与动态运行的phase是并行运行的,如果12个动态运行的phase有objection被提起,那么run_phase根本不需要raise_objection就可以自动执行。
Q51. main_phase要如何跳转到reset_phase;
在main_phase执行过程中,突然遇到reset信号被置起,可以用jump()实现从mian_phase到reset_phase的跳转:
Q52. UVM组件的通信方式TLM的接口分类和用法,peek和get的差异
-
UVM中采用事务级传输机制进行组件间的通信,可以大大提高仿真的速度和使得我们简化组件间的数据传输,简化工作,TLM独立于组件之外,降低组件间的依赖关系。UVM接口主要由port、export、imp;驱动这些接口方式有put、get、peek、transport、analysis等。 -
其中
peek是查看端口内部的数据事务但是不删除,get是获取后立即删除。我们一般会先使用peek进行获取数据,但不删除(保证put端不会立马又发送一个数据),处理完毕后再用get删除。 -
lmp只能作为终点接口,transport表示双向通信,analysis可以连接多个imp(类似于广播)。
Q53. Analysis port是否可以不连或者连多个impport
都可以。Analysis port类似于广播,其可以同时对多个imp进行事务通信,只需要在每一个对应的imp端口申明write()函数即可。对比 put,get,peek port,他们都只能进行一对一传输,且也必须申明对应的函数如 put()、get()、peek()、can_put()/do_put()等。Fifo是可以不用申明操作函数的,其内部封装了很多的通信端口,如analysis_export等,我们只需要将端口与其连接即可实现通信。
sequence机制
sequence机制主要是用于控制和产生激励,并将产生的一系列transcation发送给driver。
其优点在于: 将激励的产生功能从driver中剥离出来,同时也将testcase和testbench分离开来, 在不同的testcase中,可以将不同的sequence配置成sequencer的main_phase中的default_sequence,当sequencer执行到main_phase时,就会启动sequence, 在不改变driver的情况下完成不同的激励驱动。
Q54. Sequence和item(uvm_sequece,uvm_sequence_item)以及sequence的分类
-
item是基于uvm_object类,这表明了它具备UVM核心基类所必要的数据操作方法,例如copy、 clone、compare、record等。 -
item对象的生命应该开始于sequence的body()方法,而后经历了随机化并穿越sequencer最终到达driver,直到被driver消化之后,它的生命一般来讲才会结束。 -
item与sequence的关系 一个
sequence可以包含一些有序组织起来的item实例,考虑到item在创建后需要被随机化,sequence在声明时也需要预留一些可供外部随机化的变量,这些随机变量一部分是用来通过层级传递约束来最终控制item对象的随机变量,一部分是用来对item对象之间加以组织和时序控制的。 -
Sequence的分类:
-
扁平类
(flat sequence):这一类往往只用来组织更细小的粒度,即item实例构成的组织。 -
层次类
( hierarchical sequence):这一类是由更高层的sequence用来组织底层的sequence,进而让这些sequence或者按照顺序方式,或者按照并行方式,挂载到同一个sequencer上。 -
虚拟类
(virtual sequence):这一类则是最终控制整个测试场景的方式,鉴于整个环境中往往存在不同种类的sequencer和其对应的sequence,我们需要一个虚拟的sequence来协调顶层的测试场景。之所以称这个方式为virtual sequence,是因为该序列本身并不会固定挂载于某一种sequencer类型上,而是将其内部不同类型sequence最终挂载到不同的目标sequencer上面。这也是virtual sequence不同于hierarchical sequence的最大一点。
Q55. Sequence和sequencer的关系
transaction是事务,是指一系列数据的集合;sequence是一系列transaction组成的发送序列。
-
sequence机制用于产生激励,它是UVM中最重要的机制之一。sequence机制有两大组成部分:sequence和sequencer。 -
在整个验证平台中
sequence处于一个比较特殊的位置。sequence不属于验证平台的任何一部分,但是它与sequencer之间有着密切的关系。 -
只有在
sequencer的帮助下,sequence产生的transaction才能最终送给driver;同样,sequencer只有在sequence出现的情况下才能体现出其价值,如果没有sequence,sequencer几乎没有任何作用。 -
除此之外,
sequence与sequencer还有显著的区别。从本质上说,sequencer是一个uvm_component,而sequence是一个uvm_object。与my_transaction一样,sequence也有其生命周期。它的生命周期比my_transaction要更长一点,其内部的transaction全部发送完毕后,它的生命周期也就结束了。
Q56. Sequencer的仲裁特性(set_arbitration)及锁定机制(lock和grab)
仲裁特性:
-
在实际使用中,我们可以通过
uvm_sequencer:set_arbitration(UVM_SEQ_ARB_TYPE val)函数来设置仲裁模式,这里的仲裁模式UVM_SEQ_ARB_TYPE有下面几种值可以选择:
UVM_SEQ_ARB_FIFO:默认模式。来自于sequences的发送请求,按照FIFO先进先出的方式被依次授权,和优先级没有关系。
UVM_SEQ_ARB_WEIGHTED:不同sequence的发送请求,将按照它们的优先级权重随机授权。 -
UVM_SEQ_ARB_RANDOM:不同的请求会被随机授权,而无视它们的抵达顺序和优先级
-
UVM_SEQ_ARB_STRICT_FIFO:不同的请求,会按照它们的优先级以及抵达顺序来依次授权,因此与优先级和抵达时间都有关
-
UVM_SEQ_ARB_STRICT_RANDOM:不同编辑会按照它们的最高优先级随机授权,与抵达时间无关。
-
UVM_SEQ_ARB_USER:用户可以自定义仲裁方法user_priority_arbitrationl)来裁定哪个sequence的请求被优先授权。
-
锁定机制
uvm_sequencer提供了两种锁定机制,分别通过lock()和grab()方法实现,这两种方法的区别在于:
lock()与unlock)这一对方法可以为sequence提供排外的访问权限,但前提条件是,该sequence首先需要按照sequencer的仲裁机制获得授权。而一旦sequence获得授权,则无需担心权限被收回,只有该sequence主动解锁(unlock)它的sequencer,才可以释放这一锁定的权限。lock()是一种阻塞任务,只有获得了权限,它才会返回。
grab(与ungrab)也可以为sequence提供排外的访问权限,而且它只需要在sequencer下一次授权周期时就可以无条件地获得授权。与lock方法相比,grab方法无视同一时刻内发起传送请求的其它sequence,而唯一可以阻止它的只有已经预先获得授权的其它lock或者grabi的sequence。
这里需要注意的是,由于“解铃还拥渠,如果sequence使用了lock()或者grab()方法,必须在sequence结束前调用unlock()或者ungrab)方法来释放权限,否则sequencer会进入死锁状态而无法继续为其余sequence授权。
Q57. Virtual sequence和virtual sequencer中virtual含义
Virtual含义就是其sequencer 并不需要传递item,也不会与driver连接,其只是一个去协调各个sequencer的中央路由器。通过virtual sequencer我们可以实现多个agent的多个sequencer他们的 sequence的调度和可重用。Virtual sequence可以组织不同sequencer 的sequence群落。
Virtual sequence和virtual sequencer的意义
如果只有一个激励驱动的 agent,则不需要virtual sequencer。如果你有多个驱动agent,但不需要激励之间的协调(在设计上是相互独立的),则不需要virtual sequencer。如果您有多个驱动 agent并且需要激励间的协调,则需要一个virtual sequencer。如果测试平台将来需要扩展成有多个agent,或者多个独立激励的测试平台需要设计成相互协调的激励,那么环境就要更新到包括一个或多个virtual sequencer。
虚拟sequence可以在多个实际sequencers上运行多种事务类型。 虚拟sequence通常只是在适当的子sequencer上协调其他sequences的执行。
virtual sequencer只不过是一个组件,它提供了一个位置和作用域来配置virtual sequence,并为virtual sequence所需的子序列提供句柄。
sequence在sequencer上运行,并被参数化为该sequencer处理的事务类型。
我们可以使用内置的sequence start()方法或使用`uvm_do()宏在sequencer上启动sequence。
每个sequence都有运行该sequence的sequencer句柄。 该句柄就是m_sequencer。
所有sequence都在sequencer上启动,通过tr_seq.start(env.vsqr)。当然`uvm_do宏也执行了该命令。 在sequencer上启动sequence后,该sequence的m_sequencer句柄被设置为env.vsqr。 m_sequencer句柄只是每个sequence中指向运行该sequence的sequencer的句柄,它是在将start()方法传递sequencer的句柄(env.vsqr)时设置的。
就像其他sequence一样,当使用start()方法或`uvm_do宏在虚拟sequencer上启动虚拟sequence时,虚拟sequence将自动具有正确指向虚拟sequencer的m_sequencer句柄。
常见问题有:(a)什么是p_sequencer?(b)p_sequencer与m_sequencer有何不同?
所有sequence都具有m_sequencer句柄,但是sequence不会自动设置p_sequencer句柄。 此外,m_sequencer变量是一个内部实现的变量,不应由验证工程师直接使用。 它是SystemVerilog语言的构件,缺少C ++的“friend”类概念,该变量是公共变量。 类似地,任何带有“ m_”前缀的变量或方法都不应直接使用。
p_sequencer不会自动声明和设置,但可以使用`uvm_declare_p_sequencer宏进行声明和设置。 如本文后续章节展示,`uvm_declare_p_sequencer宏和p_sequencer句柄对用户的便利。
从技术上讲,从不需要p_sequencer句柄,但与`uvm_declare_p_sequencer宏一起使用时,会在启动虚拟sequence时自动(1)声明,(2)设置和(3)检查,并正确指向该virtual sequencer, 运行virtual sequence。
下面介绍有关p_sequencer句柄及其用法。

`uvm_declare_p_sequencer(SEQUENCER)宏执行了两个步骤:
(1)这个宏声明了SEQUENCER类型的p_sequencer句柄。
(2)然后将m_sequencer句柄$cast()到p_sequencer句柄,并检查确保执行此sequence的sequencer是合适的类型。
通常将此宏放在sequence基类中,该基类将被扩展以创建使用指定的sequencer的所有sequence,无论是否使用虚拟sequencer。
在第1行,用户调用此宏,并传递将由sequence使用的sequencer的类型。 对于虚拟sequence,这是将在其上执行的指定虚拟sequencer的类名。
在第2行,使用句柄名称p_sequencer声明指定的sequencer。 对于此宏以及用户定义的虚拟sequence基类和扩展虚拟sequence类中其他代码的部分,虚拟sequencer将使用名称p_sequencer进行引用。 从现在开始,无需引用正在使用的虚拟sequencer的名称,用户只需引用p_sequencer(virtual sequencer)句柄即可。 这仅仅是一种便利,而非必要。
第3行是从第9行开始的虚拟void函数声明的开始。该void函数称为m_set_p_sequencer,当在其中一个虚拟sequence上调用sequence的start()方法或使用`uvm_do_on( )宏启动虚拟sequence时该方法会被调用。
第4行是如果virtual sequence是另一个virtual sequence的扩展,则父类的virtual sequence还将执行其自己的m_set_p_sequencer方法。
第5行是强制转换内部m_sequencer句柄,该句柄应该是虚拟sequencer的句柄在第2行声明的本地p_sequencer句柄。if-test检查$cast()操作是否失败(!$cast(...)) 如果$cast确实失败了,则第6-8行上的fatal消息将终止UVM仿真并报告,说明在转换为指定的虚拟sequencer类型时存在问题,即sequence正在错误的类型的sequencer上执行 。
Q58. 为什么会有sequence、sequencer以及driver,为什么要分开实现,这样做的好处是什么?
-
在
UVM中有sequence机制,以往如果我们使用SV进行TB搭建时,我们一般会采用driver一个类进行数据的参数,转换,发送,或者使用genetor和driver两个进行,这种方式可重用性很低,而且代码臃肿; -
但是在UVM中我们通过将
sequence、sequencer、driver、sequence_item拆开,相互独立而又有联系,因此我们只需关注每一个类需要做的工作就可以,可重用性高。我在学习sequence时,我经常把sequence比作蓄水池,sequence_item就是水,sequencer就是一个调度站,driver就是总工厂,通过这种方式进行处理,我们的总工厂不需要管其他,只需处理运送过来的水资源就可以,而sequencer只需要调度水资源,sequence只需要产生不同的水资源。
Q59. 如何在driver中使用interface,为什么
-
Interface如果不进行virtual声明的话是不能直接使用在dirver中的,会报错,因为interface声明的是一个实际的物理接口。一般在dirver中使用virtual interface进行申明接口,然后通过config_db进行接口参数传递,这样我们可以从上层组件获得虚拟的interface接口进行处理。 -
Config_db传递时只能传递virtual接口,即interface的句柄,否则传递的是一个实际的物理接口,这在driver中是不能实现的,且这样的话不同组件中的接口一一对应一个物理接口,那么操作就没有意义了。
Q60. 你了解uvm的factory机制和callback机制嘛
Factory机制也叫工厂机制,其存在的意义就是为了能够方便的替换TB中的实例或者已注册的类型。一般而言,在搭建完TB后,我们如果需要对TB进行更改配置或者相关的类信息,我们可以通过使用factory 机制进行覆盖,达到替换的效果,从而大大提高TB的可重用性和灵活性。要使用factory机制先要进行:
-
将类注册到
factory表中 -
创建对象,使用对应的语句
(type_id::create) -
编写相应的类对基类进行覆盖。
Callback机制其作用是提高TB的可重用性,其还可进行特殊激励的产生等,与factory类似,两者可以有机结合使用。与factory不同之处在于 callback的类还是原先的类,只是内部的callback函数变了,而factory是产生一个新的扩展类进行替换。
-
UVM组件中内嵌callback函数或者任务 -
定义一个常见的
uvm_callbacks class -
从
UVM callback空壳类扩展uvm_callback类 -
在验证环境中创建并登记
uvm_callback
Q61. field_automation机制和objection机制
-
field_automation机制:可以自动实现copy、compare、print等三个函数。当使用uvm_field系列相关宏注册之后,可以直接调用以上三个函数,而无需自己定义。这极大的简化了验证平台的搭建,尤其是简化了driver和monitor,提高了效率。 -
UVM中通过objection机制来控制验证平台的关闭,需要在drop_objection之前先raise_objection。验证在进入到某一phase时,UVM会收集此phase提出的所有objection,并且实时监测所有objection是否已经被撤销了,当发现所有都已经撤销后,那么就会关闭此phase,开始进入下一个phase。当所有的phase都执行完毕后,就会调用$finish来将整个验证平台关掉。如果UVM发现此phase没有提起任何objection,那么将会直接跳转到 下一个phase中。 -
UVM的设计哲学就是全部由sequence来控制激励生成,因此一般情况下只在sequence中控制objection。另外还需注意的是,raise_objection语句必须在main_phase中第一个消耗仿真时间的语句之前。
Q62. Config_db的作用,以及传递其使用时的参数含义
-
Config_db机制主要作用就是传递参数使得TB的可配置性高,更加灵活。Config_db机制主要传递的有三种类型:
-
一种是
interface虚拟接口,通过传递virtual interface使得dirver和monitor能够与DUT连接,并驱动接口和采集接口信号。 -
第二种是单一变量参数,如
int,string,enum等,这些主要就是为了配置某些循环次数,id号是多少等等。 -
第三种是
object类,这种主要是当配置参数较多时,我们可以将其封装成一个object类,去包含这些属性和相关的处理方法,这样传递起来就比较简单明朗,不易出错。
-
Config_db的参数主要由四个参数组成,如下所示,第一个参数为父的根parent,第二个参数为接下来的路径,对应的组件,第三个是传递时的名字(必须保持一致),第四个是变量名。uvm_config_db #(virtual interface) :: set(uvm_root:.get(),"uvm_test_top.c1",'vif",vif); uvm_config_db #(virtual interface) :: get(this,"”,"vif",vif);
Q63. UVM中各个component之间是如何组织运行的,串行还是并行,通过什么机制进行调度的
Component 之间通过在new函数创建时指定parent参数指定子关系,通过这种方法来将TB形成一个树形结构。UVM中运行是通过Phase机制进行层次化仿真的。从组件来看各个组件并行运行,从phase上看是串行运行,有层次化的。Phase机制的9个phase是串行运行的,不同组件中的同一个phase都运行完毕后才能进入下一个phase运行,同一个phase在不同组件中的运行也是由一定顺序的,build 和 final是自顶向下。
Q64. UVM如何启动一个sequence
-
启动
sequence有很多的方法:常用的方法有使用default sequence进行调用,其会将对应的sequence与sequencer绑定,当dirver请求获得req时,sequencer就会调用对应的sequence去运行body函数,从而产生req。 -
除此之外,还可以使用
start函数进行,其参数主要就是对应的需要绑定的sequencer和该类的上层sequence。如此,就可以实现启动sequence的功能。 -
注意:一般仿真开始结束会在
sequence中raise objection和drop objection
Q65. 你所搭建的验证平台为什么要用RAL(寄存器)
-
首先,我们要了解寄存器对于设计的重要性,其是模块间交互的窗口,我们可以通过读寄存器值去观察模块的运行状态,通过写寄存器去控制模块的配置和功能改变。
-
然后,为什么我们需要RAL呢?由于前面寄存器的重要性,我们可以知道,如果我们不能先保证我们寄存器的读写正确,那么就不用谈后续 DUT是否正确了,因此,寄存器的验证是排在首要位置的。
-
那么我们应该用什么方法去读写和验证寄存器呢?采用RAL寄存器模型去测试验证,是目前最成功的方法吧,寄存器模型独立于
TB之外,我们可以搭建一个测试寄存器的agent,去通过前门或者后门访问去控制DUT的寄存器,使得DUT按照我们的要求去运行。 -
除此之外,
UVM中内建了很多RAL的sequence,用于帮助我们去检测寄存器,除此之外,还有一些其他的类和变量去帮助我们搭建,以提高RAL的可重用性和便捷性还有更全的覆盖率。
Q66. 前门访问和后门访问的区别
-
前门访问和后门访问的比较
-
前门访问,顾名思义指的是在寄存器模型上做的读写操作,最终会通过总线UVC来实现总线上的物理时序访问,因此是真实的物理操作。
-
后门访问,指的是利用
UVM DPI (uvm_hdl_read()、uvm_hdl_deposit()),将寄存器的操作直接作用到DUT内的寄存器变量,而不通过物理总线访问。 -
前门访问在使用时需要将
path设置为UVM_FRONTDOOR -
在进行后门访问时,用户首先需要确保寄存器模型在建立时,是否将各个寄存器映射到了
DUT一侧的HDL路径:使用add_hdl_path
5. 从上面的差别可以看出,后门访问较前门访问更便捷更快一些,但如果单纯依赖后门访问也不能称之为“正道”。
6. 实际上,利用寄存器模型的前门访问和后门访问混合方式,对寄存器验证的完备性更有帮助。
- 前门访问:通过寄存器配置总线SPI(如APB协议、OCP协议、I2C协议)来对DUT进行操作,前门访问操作只有两种方式:读和写操作
- 后门访问:是与前门访问相对的操作,从广义上讲所有不通过DUT的总线而对DUT内部的寄存器或者存储器进行存取的操作都是后门访问,利用UVM DPI(uvm_hdl_read()、uvm_hdl_deposit()),而不通过物理总线访问.
1.前门访问
第一种uvm_reg::read()/write(),在传递时,用户需要将参数path指定为UVM_FRONTDOOR。除了status和value两个参数需要传入,其他参数可采用默认值.
1.寄存器模型提供的方法
//reg_model寄存器模型实例名,reg寄存器实例名
reg_model.reg.write(status, value, UVM_FRONTDOOR, .parent(this));
reg_model.reg.read(status, value, UVM_FRONTDOOR, .parent(this));
第二种uvm_reg_sequence::read_reg()/write_reg(),在使用时,也要将path指定为UVM_FRONTDOOR
uvm_reg_sequence预定义方法
read_reg(rgm.ss, status, data, UVM_FRONTDOOR);
write_reg(rgm.ss, status, data, UVM_FRONTDOOR);
2.后门访问
1.确保寄存器模型在建立时将各个寄存器映射到DUT一侧的HDL路径
add_hdl_path("reg_backdoor_access.dut");
chnl0_ctrl_reg.add_hdl_path_slice($sformatf("regs[%0d]", `SLVO_RW_REG), 0, 32);
lock_model();
通过uvm_reg_block::add_hdl_path()将寄存器模型关联到DUT一端
通过uvm_reg::add_hdl_path_slice完成将寄存器模型各个寄存器成员与HDL一侧的地址映射
lock_model()函数结尾,结束地址映射关系,保证模型不会被其他用户修改
2.寄存器模型完成HDL路径映射后,利用uvm_reg或uvm_reg_sequence自带的方法进行后门访问
uvm_reg::read()/write(),在调用该方法时设置UVM_BACKDOOR的访问方式。
uvm_reg_sequence::read_reg()/write_reg(),在调用该方法时设置UVM_BACKDOOR的访问方式。
uvm_reg::peek()/poke()两个方法,分别对应了读取寄存器(peek)和修改寄存(poke)两种操作,本身只针对后门访问,所以无需设置UVM_BACKDOOR。
1. 寄存器模型提供的方法read()/write()
rgm.ctrl.read(status,data,UVM_BACKDOOR,.parent(this));
rgm.ctrl.write(status,'h11,UVM_BACKDOOR,.parent(this));
2. uvm_reg_sequence预定义方法read_reg()/write_reg()
read_reg(rgm.ss,status,data,UVM_FRONTDOOR);
write_reg(rgm.ss,status,'h22,UVM_FRONTDOOR);
3. 寄存器模型提供的方法peek()/poke()
rgm.ctrl.peek(status,data,.parent(this));
rgm.ctrl.poke(status,'h22,.parent(this));

Q67. 后门访问的路径怎么配置

Q68. 如果寄存器的地址不匹配的错误怎么测试出来
在通过前门配置寄存器A之后,再通过后门访问来判断HDL地址映射的寄存器A变量值是否改变,最后通过前门访问来读取寄存器A的值。

Q69. 寄存器模型的常规方法(期望值、镜像值、真实值)
mirror、desired、actual value()
-
我们在应用寄存器模型的时候,除了利用它的寄存器信息,也会利用它来跟踪寄存器的值。寄存器有很多域,每一个域都有两个值。
-
寄存器模型中的每一个寄存器,都应该有两个值,一个是镜像值(
mirrored value) , 一个是期望值(desired value) 。 -
期望值是先利用寄存器模型修改软件对象值,而后利用该值更新硬件值;镜像值是表示当前硬件的已知状态值。
-
镜像值往往由模型预测给出,即在前门访问时通过观察总线或者在后门访问时通过自动预测等方式来给出镜像值
-
镜像值有可能与硬件实际值不一致
Q70. Prediction的分类(自动预测和显式预测)
-
UVM提供了两种用来跟踪寄存器值的方式,我们将其分为自动预测(
auto prediction)和显式预测(explicit)。 -
如果用户想使用自动预测的方式,还需要调用函数
uvm_reg_map::set_auto predict() -
两种预测方式的显著差别在于,显式预测对寄存器数值预测更为准确,我们可以通过下面对两种模式的分析得出具体原因。自动预测
-
如果用户没有在环境中集成独立的
predictor,而是利用寄存器的操作来自动记录每一次寄存器的读写数值,并在后台自动调用predict()方法的话,这种方式被称之为自动预测。 -
这种方式简单有效,然而需要注意,如果出现了其它一些
sequence直接在总线层面上对寄存器进行操作(跳过寄存器级别的write/read操作,或者通过其它总线来访问寄存器等这些额外的情况,都无法自动得到寄存器的镜像值和预期值。显式预测 -
更为可靠的一种方式是在物理总线上通过监视器来捕捉总线事务,并将捕捉到的事务传递给外部例化的
predictor,该predictor由UVM参数化类uvm_reg_predictor例化并集成在顶层环境中。 -
在集成的过程中需要将
adapter与map的句柄也一并传递给predictor,同时将monitor采集的事务通过analysis port接入到predictor一侧。 -
这种集成关系可以使得,
monitor一旦捕捉到有效事务,会发送给predictor,再由其利用adapter的桥接方法,实现事务信息转换,并将转化后的寄存器模型有关信息更新到map中。 -
默认情况下,系统将采用显式预测的方式,这就要求集成到环境中的总线
UVC monitor需要具备捕捉事务的功能和对应的analysis port,以便于同predictor连接。
Q71. 寄存器怎么配置,adapter怎么集成

Q72. AMBA总线中AHB/APB/AXI协议的区别
AHB(Advanced High-performance Bus)高级高性能总线。APB(Advanced Peripheral Bus)高级外围总线AXI (Advanced eXtensible Interface)高级可拓展接口
-
AHB主要是针对高效率、高频宽及快速系统模块所设计的总线,它可以连接如微处理器、芯片上或芯片外的内存模块和DMA等高效率模块。 -
APB主要用在低速且低功率的外围,可针对外围设备作功率消耗及复杂接口的最佳化。APB在AHB和低带宽的外围设备之间提供了通信的桥梁,所以APB是AHB的二级拓展总线。 -
AXI高速度、高带宽,管道化互联,单向通道,只需要首地址,读写并行,支持乱序,支持非对齐操作,有效支持初始延迟较高的外设,连线非常多。AHB协议
1. AHB的组成
-
Master:能够发起读写操作,提供地址和控制信号,同一时间只有1个Master会被激活。 -
Slave:在给定的地址范围内对读写操作作响应,并对Master返回成功、失败或者等待状态。 -
Arbiter:负责保证总线上一次只有1个Master在工作。仲裁协议是规定的,但是仲裁算法可以根据应用决定。 -
Decoder:负责对地址进行解码,并提供片选信号到各Slave。每个AHB都需要1个仲裁器和1个中央解码器。
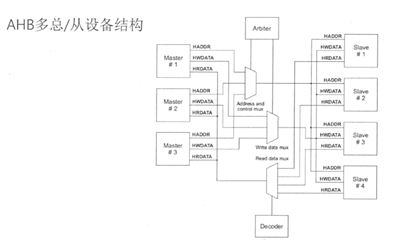 2. AHB基本信号(经常会问Htrans和Hburst,以及AHB的边界地址怎么确定)
2. AHB基本信号(经常会问Htrans和Hburst,以及AHB的边界地址怎么确定)
-
HADDR:32位系统地址总线。
-
HTRANS:M指示传输状态,NONSEQ、SEQ、IDLE、BUSY。
-
HWRITE:传输方向1-写,0-读。
-
HSIZE:传输单位。
-
HBURST:传输的burst类型,SINGLE、INCR、WRAP4、INCR4等。
-
HWDATA:写数据总线,从M写到S。
-
HREADY:S应答M是否读写操作传输完成,1-传输完成,0-需延长传输周期。
-
HRESP:S应答当前传输状态,OKAY、ERROR、RETRY、SPLIT。
-
HRDATA:读数据总线,从S读到M。
APB协议及读写操作
1. APB的状态转移
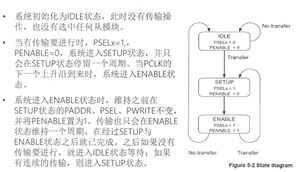
2. APB写操作
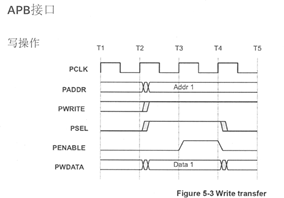
 3. APB读操作
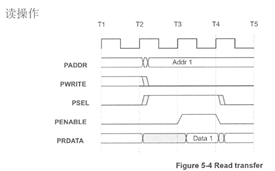
3. APB读操作

Q73. 你写过assertion嘛,assertion分几种?简述一下assertion的用法
-
Assertion可以分为立即断言和并发断言。 -
立即断言的话就是和时序无关,比如我们在对激励随机化时,我们会使用立即断言,如果随机化出错我们就会触发断言报错。
-
并发断言的话主要是用来检测时序关系的,由于在很多模块或者总线中,单纯使用覆盖率或者事务
check并不能完全检测多个时序信号之间的关系,但是并发断言却可以使用简洁的语言去监测,除此之外,还可以进行覆盖率检测。 -
并发断言的用法的话,主要是有三个层次:
-
序列
sequence编写,将多个信号的关系用断言中特定的操作符进行表示; -
属性
property的编写,它可以将多个sequence和多个property进行嵌套,外加上触发事件; -
assert的编写,调用property就可以。编写完断言后我们可以将它用在很多地方,比如DUT内部,或者在top层嵌入DUT中,还可以在interface处进行编写,基本能够检测到信号的地方都可以进行断言检测。
Q74. a[*3]、a[->3]和a[=3]区别
-
a[*3]指的是:重复3次a,且其与前后其他序列不能有间隔,a中间也不可有间隔。
-
a[->3]指的是:重复3次,其 a中间可以有间隔,但是其后面的序列与a之间不可以有间隔。
-
a[=3]指的是:只要重复3次,中间可随意间隔。
Q75. 项目中会考虑哪些coverage
-
主要会考虑三个方面吧,代码覆盖率,功能覆盖率,断言覆盖率。
-
代码覆盖率,主要由行覆盖率、条件覆盖率、
fsm覆盖率、跳转覆盖率、分支覆盖率,他们是否都是运行到的,比如fsm,是否各个状态都运行到了,然后不同状态之间的跳转是否也都运行到了。 -
功能覆盖率的话主要是自己编写
covergroup和coverpoint去覆盖我们想要覆盖的数据和地址或者其他控制信号。 -
断言覆盖率主要检测我们的时序关系是否都运行到了,比如总线的地址数据读写时序关系是否都有实现。
Q76. Coverage一般不会直接达到100%,当你发现condition未cover到的时候,你该怎么做?
Condition又称为条件覆盖率,当条件覆盖率未被覆盖时,我们需要通过查看覆盖率报告去定位哪些条件没有被覆盖到,是因为没有满足该条件的前提条件还是因为根本就遗漏了这些情况,根据这个我们去编写相应的case,进而将其覆盖到。
Q77. Function coverage和 code coverage的区别,以及他们分别对项目的含义
-
功能覆盖率主要是针对
spec文档中功能点的覆盖检测 -code覆盖率主要是针对RTL设计代码的运行完备度的体现,其包括行覆盖率、条件覆盖率、FSM覆盖率、跳转覆盖率、分支覆盖率(只要仿真就可以,看看DUT的哪些代码没有动,如果有一部分代码一直没动,看一下是不是case没写到)。 -
功能覆盖率和代码覆盖率两者缺一不可,功能覆盖率表示着代设计是否具备这些功能,代码覆盖率表示我们的测试是否完备,代码是否冗余。当功能覆盖率高而代码覆盖率低时,表示
covergroup是不是写少了,case写少了;或者代码冗余。当功能覆盖率很低而代码覆盖率高时,表示代码设计是不是全面,功能点遗漏;covergroup写的是不是冗余了。只有当两者覆盖率都高的时候才表明我们验证的大部分是可靠的。 -
代码覆盖率很难达到100%,一般情况下达到90%多已经非常不错了,如果有一部分代码没有被触动到,需要有经验的验证工程师去分析,如果确实没啥问题,就可以签字通过了
Q78. 你在做验证时的流程是怎么样的,你是怎么做的。
对于流程的话
-
首先第一步我会先去查看
spec文档,将模块的功能和接口总线时序搞明白,尤其是工作的时序,这对于后续写TB非常重要; -
第二步我会根据功能点去划分我的
TB应该怎么搭建,我的case大致会有哪些,这些功能点我应该如何去覆盖,时序应该如何去检查,总结列出这样的一个清单; -
第三步开始去搭建我们的
TB,包括各种组件,和一些基础的sequence还有test,暂时先就写一两个基础的sequence,然后还有一些环境配置参数的确定等,最后能够将TB正常运行,保证无误; -
第四步就是根据清单去编写
sequence和case,然后去仿真,保证仿真正确性,收集覆盖率; -
第五步就是分析收集的覆盖率,然后查看覆盖率报告去分析还有哪些没有被覆盖,去写一些定向
case,和更换不同的seed去仿真; -
第六步就是回归测试
regression,通过不同的seed去跑,收集覆盖率和检测是否有其它bug; -
第七步就是总结
79.你在进行验证的过程中,碰到过什么难点,重点是什么呢?
-
刚开始的难点还是TB的搭建,想要搭建出一个可重用性很高的TB,配置灵活的TB还是有一定困难,对于哪些参数应该放在配置类,哪些参数应该放在事务类的抉择,哪些单独配置。
-
除此之外,还有就是时序的理解,这对于
driver和monitor还有sequence和assertion的编写至关重要,只有正确理解时序才能编写出正确的TB。 -
最后就是实现覆盖率的尽可能高,这也是比较困难的,刚开始的
case好写,也比较快就可以达到较高的覆盖率,但是那些边边角角的case需要自己去琢磨,去分析还需要写什么case。这些难点就是重点,还要能够自动化监测判断是否正确。
Q80. 你发现过哪些验证过程中的 bug,如何发现的,怎么解决的?
这个问题面试的时候经常问,建议面试之前考虑一下,再做决定
Q81. 你的验证环境是什么?目录结构是什么样的
我是使用UVM验证方法学搭建的TB,然后在VCS平台进行仿真的。目录结构的话:主要由RTL文件、doc文件、tb文件、sim文件、script文件这几部分。
Q82. UVM有什么优缺点:
-
UVM的优点:UVM有各个机制、促进验证平台的标准化,UVM中
test sequence和验证平台是隔离独立的,可以更好的控制激励而不需要重新设计agent. 改变测试sequence可以简单高效提高代码覆盖率。UVM支持工业标准,这会促进验证平台标准化。此外,UVM通过OOP(面向对象编程)的特点(例如继承)以及使用覆盖组件提高了重复使用率。因此UVM环境方便移植,架构清晰,组件连接方便,有利于进行大规模的验证。 -
UVM的缺点:代码冗余,工作量大,运行速度有缺失
Q83. 通过工厂进行覆盖有什么要求?
-
无论是重载的类(
parrot)还是被重载的类(bird),都要在定义时注册到factory机制中。 -
被重载的类(
bird)在实例化时,要使用factory机制式的实例化方式,而不能使用传统的new方式。 -
最重要的是,重载的类(
parrot)要与被重载的类(bird)有派生关系。重载的类必须派生自被重载的类,被重载的类必须是重载类的父类。
Q84. 如果环境中有两个config_db set,哪个有效?
UVM更高的层次更接近用户,为了让用户少和底层组件打交道,所以层次越高优先级越高,高层次的set会覆盖底层次的set,如果是层次相同再看时间先后顺序,谁发生的晚谁有效,时间靠后的会覆盖之前的。
Q85. VIP怎么写?
-
阶段1(定义)。
-
功能特性提取
-
特性覆盖率创建及映射
-
VIP的架构
-
阶段2(VIP基本搭建)
-
driver,sequencer,monitor (少量特性实现)。
-
实现基本的端到端的sequence
-
阶段3(完成monitor与scoreboard)
-
完成monitor -100%实现(checkers,assertions)
-
完成scoreboard -100%实现(数据完整性检查)
-
在monitor中,完成监测到的transaction与function coverage实现映射。
-
为映射更多的基本功能覆盖率,创建其它sequences。
-
阶段4(扩充test和sequence阶段)
-
实现更多sequences,从而获得80%的功能覆盖率
-
阶段5(完成标准)
-
Sequence最终可以实现100%的功能覆盖率。
-
回归测试结果和最终的总结报告。
Q86. 验证流程,验证环境怎么搭
-
验证流程:
-
看
spec文档和协议,将DUT的功能和接口总线时序搞明白 -
制定验证计划和测试点分解
-
写
VIP或者是用别人给的VIP,搭建验证环境和TB,包括各种组件,各个模块的pkg,基础的sequence还有test,暂时先就写一两个基础的sequence,然后还有一些环境配置参数的确定等,最后能够将TB正常运行,保证无误; -
根据测试点编写
sequence和case,然后去仿真,保证仿真正确性,收集覆盖率; -
分析收集的覆盖率,然后查看覆盖率报告去分析还有哪些没有被覆盖,去写一些定向
case,和更换不同的seed去仿真; -
回归测试
regression,通过不同的seed去跑,收集覆盖率和检测是否有其它bug; -
总结
-
验证环境的搭建:
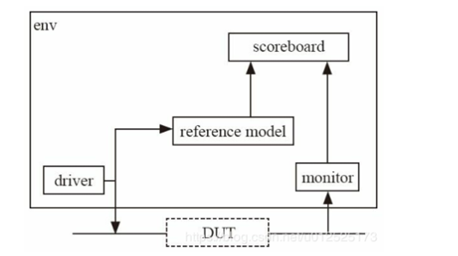
driver给 DUT 发送激励,montior监测 DUT 输出的数据,参考模型( reference model )能实现与 DUT相同的功能,scoreboard把 monitor接受到的数据和 reference model的输出数据进行比对,如果比对成功就表示 DUT 能完成设计的功能,
Q87. uvm_component_utils有什么作用
-
factory机制的实现被集成在了一个宏中:uvm_component_utils。 -
这个宏最主要的任务是,将字符串登记在
UVM内部的一张表中,这张表是factory功能实现的基础。只要在定义一个新的类时使用这个宏,就相当于把这个类注册到了这张表中。这样,factory机制可以实现:根据一个字符串自动创建一个类的实例,并且调用其中的函数(function)和任务(task),这个类的main_phase就会被自动调用。
Q88. TLM怎么用
-
TLM通信的步骤:
-
分辨出
initiator和target,producer和consumer。 -
在
target中实现tlm通信方法。 -
在俩个对象中创建
tlm端口。 -
在更高层次中将俩个对象进行连接。
-
端口类型有三种:
-
port,一般是initiator的发起端。 -
export,作为initiator和target的中间端口。 -
imp,只能作为target接受request的末端。 -
多个
port可以连接同一个export或imp,但是单个port或export不能连接多个imp。
-
端口的连接:通过
connect函数进行连接,例如A(initiator)与B进行连接,可以使用A.port.connect(B.export) -
uvm_*_imp#(T,IMP);IMP定义中第一个参数T是这个IMP传输的数据类型,第二个参数IMP是实现这个接口所在的
component。
Q89. MCDF 如何提高覆盖率
1.通过修改约束和创建新的条件进行测试
2.或者写新的测试来进行测试
3.创建conner case来进行测试
4.对于我们不需要的覆盖率,通过exclude的方式进行排除,也可以提高覆盖率的收集
5.使用不同的随机种子来进行测试(也就是说(随机测试+定向测试)
4.对于代码覆盖率:line、paths、toggle、FSM这几个的行覆盖率。
Q90.代码覆盖率的成果:
1.通过对MCDF 编写MCDF的测试用例使得寄存器的读写测试覆盖率达到100%
2.通过对异步fifo的读写寄存器编写,使得FIFO的代码覆盖率达到90%以上,
其中的一个难点就是:
1.分支覆盖率没有满足:回头review代码,发现满状态下写没有满足。
2.toggle覆盖率没有满足,是因为randmoize的次数不够。
Q91.MCDF验证点:
寄存器的读写测试
寄存器的稳定性测试
数据通道的开关测试
优先级测试
发包长度测试
下行从端低带宽测试
Q92.mcdf 的验证环境

Q93.功能覆盖组的定义

Q94.具体收集那些测试点

Q95.APB协议
1.APB有8个信号: clk与rst信号、psel片选信号与penble使能信号、pwrite读写信号(高为写入、低为读出信号)、paddr 地址位、还有padta与rdata信号
2.APB:有3个状态、idel状态、setup状态与enable状态,各个状态的使能拉高情况
3.APB的VIP实现的功能,有slave、maser连个agent。agent中有dr、mon、sequencer、等。从master—driver中发的数据,直接传输到slaver-DRIVER
中的一个小的men然后与test中的men进行比较。
实现了读操作、写操作、先读后写和先写后读的操作。连续写再连续读的操作。
Q96.断言分为:
立即断言:非时序的,如同过程语句、可以在initial过程块中执行
并行断言:proporty为关键字,与时序有关。他们可以与设计模块一同执行。
先定义sequence,然后在定义proprety。
比如:
psel信号拉高的时候penable不能为x。
psel信号拉高的上一个周期,penable为高。
penable拉高的下一个周期,penable应该为低。
psel与pwrite同时保持为高的阶段,pdata需要保持。
对同一个地址做两次写操作再从中读数据。
写操作时,先分别发生连续写和非连续写。
当然我写的case比较简单,所以覆盖率也达到了100%。
Q97.AHB总线的协议:
1.AHB中包括master、slave译码器与编码器,
有两个类型的突发操作:增量突发、回环突发。
基本传输:包括地址相位与数据相位。地址相位只存在单个周期。数据相位:可存在多个周期,这里通过HREADY信号实现。
HTRANS[1:0],有四种状态。空闲、忙、非连续、连续的传输。
突发操作由HBURST的来表示SINGLE 单一传输 \INCR4\8\16突发传输 \WRAP4\8\16增量回环。
Router
于这里是sa是固定的端口,而da是随机的端口。所以实现了,由不同的端口向不同的端口传输数据的实现。
在scoraboard中可以表示出先将driver中的数据push_back到队列中,之后根据pak中的da的值与reciver中的匹配,然后进习性比较。
也收获了关于覆盖率。可以将覆盖率100%作为表示将每一个端口都覆盖到。
0-15一共是16个端口进行操作从一个端口写,在另一边的端口读出数据,进行比较。看内容是否一样,发数的端口属于轮寻的机制,就是在这边写完在另一边进行读数据,读的端口是随机的,所义randmoize的次数需要足够才可以。
PCIE
物理层(PhysicalLayer)。电力方面,使用两个单向的低电压差分信号实现数据传输。也承担8b/10b的数据解码。
2 数据链路层(DataLink Layer)。对该层传输的TLPs进行组装和分拆。为上下两层服务。
3传输层(TransactionLayer)。接受从软件方面送来的请求,并生成请求包传输到数据层时接受从数据链路层来的数据包,传递给软件。也就是对TLPs进行分装和组装。
Q98.多时域设计中,如何处理信号跨时域?
不同的时钟域之间信号通信时需要进行同步处理,这样可以防止新时钟域中第一级触
发器的亚稳态信号对下级逻辑造成影响。
信号跨时钟域同步: 当单个信号跨时钟域时, 可以采用两级触发器来同步; 数据或地址
总线跨时钟域时可以采用异步FIFO 来实现时钟同步;第三种方法就是采用握手信号。

Q99.MOORE 与MEELEY 状态机的特征?
Moore 状态机的输出仅与当前状态值有关, 且只在时钟边沿到来时才会有状态变化。
Mealy 状态机的输出不仅与当前状态值有关, 而且与当前输入值有关。
Q100.时序约束的概念
1.通俗来讲,就是设计者需要告诉软件(Quartus、Vivado、ISE等工具)应该从哪个引脚输入信号、输入信号需要延迟多长时间、时钟周期是多少。这样软件在布局布线的时候就知道怎么去操作,从而满足设计要求。
2.时序约束主要包括:
周期约束、偏移约束、静态时序路径约束。
3.时序分析和时序约束的区别:
a.时序分析:检查设计的时序是否合格;
b.时序约束:满足设计的时序要求。
4.时序约束相关概念
建立时间(setup time):触发器在时钟上升沿到来之前,其数据输入端的数据保持不变的最小时间。
保持时间(hold time): 触发器在时钟上升沿到来之后,其数据输入端的数据保持不变的最小时间。
建立时间和保持时间是由器件的特性决定的,当决定使用那款芯片时,就意味着建立时间和保持时间也就确定了。
5.时序路径
典型的时序路径有4类,可分为片间路径和片内路径。

时钟偏斜:指同一个时钟信号到达两个不同寄存器之间的时间差值。
Q101.寄存器的前后门访问的区别与联系
Q102. Dut是如何与interface连接到一起的
Q103.Message的几个冗余程度:low mediem high none full debug
Set_report_verbosity_level_hire
Q104.还有是关于memary的储存的方式是怎么样的?
Q105. 异部fifo的功能测试点的描述。
1、复位:读复位、写复位(复位后读写地址都是默认值,满标志为0,空标志为1)
2、读写:读写数据
3、时钟:相同时钟读写、写快读慢、写慢读快
4、异常:空满(空读、满写)
Q106.异步FIFO和同步FIFO的使用场景?
FIFO全称 First In First Out,即先进先出。
Q107.FIFO主要用于以为下几个方面:
跨时钟域数据传输
将数据发送到芯片外之前进行缓冲,如发送到DRAM或SRAM
存储数据以备后用
FIFO是异步数据传输时常用的存储器,多bit数据异步传输时,无论是从快时钟域到慢时钟域,还是从慢时钟域到快时钟域,都可以使用FIFO处理。
数据缓冲:也就是数据写入过快,并且间隔时间长,也就是突发写入。那么通过设置一定深度的FIFO,可以起到数据暂存的功能,且使得后续处理流程平滑。
时钟域的隔离:主要用异步FIFO。对于不同时钟域的数据传输,可以通过FIFO进行隔离,避免跨时钟域的数据传输带来的设计和约束上的复杂度。比如FIFO的一端是AD,另一端是PCI;AD的采集速率是16位100KSPS,每秒的数据量是1.6Mbps。而PCI总线的速度是33MHz,总线宽度是32位
用于不同宽度的数据接口。例如单片机是8位,DSP是16。
Q108. 简单阐述一下你的这个MCDF项目,他是怎么运作的。MCDF的验证平台与其他的是有什么区 别。是否有用到总线,他们是如何相连接的。是用SV集成的还是通过MCDF集成的?reference modle是如何收集数据的?
(1)寄存器控制3个channl的开关、arbiter的优先级、还有formater的发包的长度
叫做多通道数据整形器。
由于设计分为了3个channel slave、一个arbiter、一个formater、一个register
所以我们的tb设计成了4个package。对应各个模块。
最重要的一个package为mcdf_package.主要是包含了各个sequence和test、ref_model
还有checker。
(2)Ref model是通过mailbox在各个3个发送数据的channel和reg agent中将数据通过reference model中,通过model,出来的数是完全按照formater的逻辑出来的,最后通过out-mailbox放入compare中formayter中monitor中检测到的数据进行比较
(3)在uvm中也是通过在mailbox做了buffer将channel和reg的uvm-blocking_port
Q109.模块级和系统级验证的区别
1)模块级
模块级验证,又叫做UT,主要关注内部的功能,比如配置通路、数据通路、中断上报、输出接口这些细节,工作量一般比较大一些。
2)子系统级
子系统验证,又叫做IT,主要关注模块间的信号连接性,对于一些模块级无法覆盖到的功能点进行检查和测试。
3)系统级
系统级验证,又叫做ST,比较完整的描述系统功能,主要关注一些功能场景和性能方面,一般规模较大,仿真速度较慢。
Q110.中断的概念,应用场景,中断的向量地址?
中断就是CPU在执行当前程序时由于内外部事件引起CPU暂时停止当前正在执行的程序而转向执行请求CPU暂时停止的内外部事件的服务程序,该程序处理完后又返回继续执行被停止的程序;中断向量是中断处理子程序的入口地址
中断向量:每个中断源都有对应的处理程序,这个处理程序称为中断服务程序,其入口地址称为中断向量。所有中断的中断服务程序入口地址构成一个表,称为中断向量表;也有的机器把中断服务程序入口的跳转指令构成一张表,称为中断向量跳转表。
中断向量表的功能是什么?若中断向量号分别为1AH和20H,则它们的中断向量在中断向量表的什么位置上?
答:中断向量表的功能是当中断源发出中断请求时,即可查找该表,找出其中断向量,就可转入相应的中断服务子程序。1AH在中断向量表的位置是1AH*4=68H在中断向量表0000:0068处;20H在中断向量表的位置是80H在中断向量表0000:0080处。
中断地址:中断向量表或中断向量跳转表中每个表项所在的内存地址或表项的索引值,称为向量地址或中断类型号。
向量中断:是指—种识别中断源的技术或方式。识别中断源的目的就是要找到中断源对应的中断服务程序的入口地址的地址,即获得向量地址。
Q111.脉冲同步器介绍,展宽电路的时钟是?

在跨时钟域处理单bit信号时,快时钟域的信号由于频率较快,信号的脉宽如果不足时,不能被慢时钟采样到,因此需要将快时钟产生的信号进行展宽,然后再进行打两拍来处理亚稳态。

module Sync_Pulse
(
input clka,//快时钟
input clkb,//慢时钟
input Rst_n,
input Pulse_a, //快时钟域中的脉冲信号
output pulse_outb, //脉冲信号
output signal_outb //电平信号
);
reg signal_a;
reg signal_b;
reg signal_b_r1;
reg signal_a_r1;
reg signal_a_r2;
//展宽信号
always @ (posedge clka or negedge Rst_n)
if(!Rst_n)
signal_a <= 1'b0;
else if(Pulse_a)
signal_a <= 1'b1;
else if(signal_a_r2)
signal_a <= 1'b0;
else
signal_a <= signal_a;
//将展宽信号同步到慢时钟域,两拍
always @ (posedge clkb or negedge Rst_n)
if(!Rst_n) begin
signal_b <= 1'b0;
signal_b_r1 <= 1'b0;
end
else begin
signal_b <= signal_a;
signal_b_r1 <= signal_b;
end
//将慢时钟域采集到的展宽信号,同步到快时钟域中
//作为展宽信号结束的一个反馈
always @ (posedge clka or negedge Rst_n)
if(!Rst_n) begin
signal_a_r1 <= 1'b0;
signal_a_r2 <= 1'b0;
end
else begin
signal_a_r1 <= signal_b_r1;
signal_a_r2 <= signal_a_r1;
end
//检测上升沿,得到慢时钟域的输出脉冲信号
assign pulse_outb = signal_b & ~signal_b_r1;
//输出电平信号,慢时钟域的展宽信号
assign signal_outb = signal_b_r1;
endmoduleQ112.单比特数据为什么可以用两级同步?
单比特信号在跨时钟域时可以打两拍来避免亚稳态在新时钟域内传播,因为第二级触发器已经可以大概率的避免亚稳态了,只不过要采样的电平信号可能会晚1T或2T到来。接收端通过检测上升沿或者下降沿就可以检测到这个事件,这样便不会引起功能出错。
Q113.多比特信号为什么不能用两级DFF同步?
有人会问了,既然单比特信号可以通过两级同步,那么多比特信号为什么不能通过两级同步器进行同步呢?答案其实也很简单,clk1不知道clk0什么时候把数据准备好了。必须要通过相应的握手信号由发送端告知接收端什么时候可以去采样。如果不这样直接同步的话便会导致错误的数据在接收端传播,导致下游模块功能出错。怎么理解呢?多比特信号同步时,由于信号skew的存在,使得这些信号的变化可能不会同时到来,这样接收端去采样的话有些信号线已经变化了而有些还没变,这样导致采集一些不希望出现的错乱值。所以要用握手信号告诉接收端采样的时机。
Q114.为什么FIFO中可以用格雷码打拍同步?
假设在A时钟域,一个数从5变成6,要同步到B时钟域。
二进制表示为101->110
格雷码表示为111->101
假设用二进制数直接同步,那么同步后的值就可能是110,也可能是101,或者从没出现过的100,111,虽然最终还是会输出正确的110,但是中间不该出现的值可能已经导致了FIFO的空满标志位判断错误。
用格雷码同步呢?由于两个数据之间只有一个比特翻转,即使有skew的存在,同步过后的值要么是111要么下一个周期之后变成101。不管是111还是101都不会导致接收端FIFO的标志位判断错误。
Q115.前仿和后仿的概念?
仿真可以分为前仿真和后仿真,前仿真是功能仿真,目标是分析电路的逻辑关系的正确性,仿真速度快,可以根据需要观察电路输入输出端口和电路内部任一信号和寄存器的波形,后仿真是将电路的门延迟参数和各种电路单元之间的连线情况考虑在内后进行仿真,得到的仿真结果接近真实的应用情况,后仿真的速度相对于前仿真慢得多,在观测内部节点波形时比较困难,在一个完整的电路设计中应该包括这两个过程。
前仿真也可以叫功能仿真、行为仿真,主要验证电路在理想环境下的行为和设计构想是否一致,电路功能是否符合Spec和设计要求。
后仿真也可以叫时序仿真、布局布线后仿真,主要针对布局布线之后的网表,加入时序分析,对功能正确性进行仿真验证。
前仿真主要验证的是功能正确性,后仿真主要验证的是时序正确性。
前仿真需要在RTL代码设计环节进行,后仿真要在布局布线环节之后进行。
Q116.前仿真可以检查亚稳态的问题吗?
不能
Q117.综合的输出有SDF文件吗?
DC一般完成综合后,主要生成.ddc、.def、.v和.sdc,.sdf格式的文件(当然还有各种报告和log)。
.sdc文件:
标准延时约束文件
里面都是一些约束,用来给后端的布局布线提供参考。
Scan_def.def文件:
DFT、形式验证可能用到;另外svf文件也可用于formality,记录了DC综合的一些映射信息,门控的插入等,加快比对。
.sdf、.v文件:
标准延时格式和网表格式文件,用于后仿真。
Q118.$display和$monitor的区别?
$monitor 用来监视参数的变化,如果参数一旦发生变化就会打印,在一个simulation session中,可以有多条$monitor语句,但是在任何时刻只有一条$monitor语句会生效(截至该时刻最晚碰到的那条,通俗一点说就是后来的$monitor语句会覆盖前面的$monitor语句)。
$display 是普通的显示函数(是的,我觉得它更像一个函数,而不像是一个任务。类似于C/C++、matlab和python等对应的控制台打印函数),它在任何它被调用的地方被即时执行。换句话说,程序执行过程中碰到它的时候就立即执行。
$write与$display几乎相同,差异仅在于后者缺省第带换行符,而前者不带。所以当你需要将多次调用的语句打印的内容显示在同一行,那就是应该用$write的地方。
如果不带任何参数调用$display()的话,就相当于一个单纯的换行,而不带任何参数调用$write()的话则什么都不会发生。
$strobe 在一个仿真时间步(time-step)中,仅在当前time-step中所有的处理都结束后执行一次。
Q119.Timeslot?
时间片time-slot(后简称ts)是EDA工具进行仿真进程中的抽象时间单位,该时间点内所有线程被划分为相应的优先级进行调度。如果线程在同一ts内被调度,从外部看他们仿佛属于同一时间点“并行”执行的,但是实际上是有先有后,因为软件行为中不存在绝对的并行。ts存在的主要价值是解决仿真中的竞争与冒险,使仿真行为尽量与实际电路行为保持一致。
归结起来一句话:通过一个ts中发生的行为,可以认为是实际电路中同一时刻并行完成的,而在仿真中是有先后顺序调度的。

Q120.IIC项目介绍,apb_agt和IIC_agt
Q121.IIC中断功能的验证,举例
Q122.UVM的factory机制
Q123.UVM的phase机制
Q124.仿真软件?
Q125.ASIC设计和验证 流程

Q126.讲讲DUT 的功能,验证环境
QQ127.cgm收集了那些信息,有做cross吗?
128.sbd如何比较数据的
Q129.uvm_do的执行过程
①创建一个my_transaction的实例m_trans;
②将其随机化;
③最终将其送给sequencer;
④等待driver返回item_done信号;
⑤开始执行下一个uvm_do,并产生新的transaction。
如果不使用uvm_do宏,也可以直接使用start_item与finish_item的方式产生transaction,对于初学者来说,使用uvm_do宏即可。在sequence中,向sequencer发送transaction使用的是uvm_do宏。这个宏什么时候会返回呢?uvm_do宏产生了一个transaction并交给sequencer,driver取走这个transaction后,uvm_do并不会立刻返回执行下一次的uvm_do宏,而是等待在那里,直到driver返回item_done信号。此时,uvm_do宏才算是执行完毕,返回后开始执行下一个uvm_do,并产生新的transaction。
Q130.#0的作用
但实际上所有可综合代码都是可以映射成门级电路,是有延迟的。只是在没有综合成实际电路之前,我们不知道延迟是多少而已。为了描述没有定义延迟的电路信号发生先后顺序,verilog HDL里面引入了0延迟的概念,如果写了#0就称之为显性0延迟,如果什么都没写则为隐性0延迟。如果你有了解verilog 0延迟的概念,你就可以把这里的0想象成一个具体的概念,无限接近0但比0大的数,比如0.1或更小
Q131.sv除了三种同步方法还有其他方法吗?
Q132.进程和线程的区别
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
协程:是一种比线程更加轻量级的存在。一个线程也可以拥有多个协程。其执行过程更类似于子例程,或者说不带返回值的函数调用。
Q133.验证环境获取DUT内部信号的方法
在UVM寄存器模型的操作中,寄存器用于设置DUT状态和芯片状态信息的上报,有前门和后门读写两种方式。
推而广之,其他的DUT内部信号,由于验证的需要,有时也需要进行后门读写。这些信号除了包含前门可读的寄存器以外,还会包含reg/wire信号、状态机的状态值、memory内容等。
总的来看,获取DUT内部状态分为前门和后门两种方式。
前门读写:使用总线对DUT发起真实的读写,一般需要总线VIP支持,仅针对DUT内部可访问的地址空间,如配置和上报寄存器、memory。这种方式好处在于能够和芯片真实的工作场景保持高度相似,能够发现时序配合上的一些问题。缺点一方面也是前门的“真实性”,当需要读写的地址空间数量很大时,会消耗非常多的仿真时间,影响用例的执行效率。另一方面是这种耗时的读写不满足“实时性”比对的验证要求。某些验证环境中,可能需要在几个cycle内完成对DUT状态的获取和比对,这种场景下前门读取方式则无法满足。
1. 信号的Hierarchy读取
DUT经过编译后,内部的信号都有对应的hierarchy路径,如dut.a.b.c,dut.out。在验证环境中可以直接使用,例如:
bit A;
A=dut.sub_block.A;
if(A==0) begin
.....
end
此种方式的缺点是会直接在环境中出现各种繁杂的hierarchy路径,当dut的层次变化时,环境也需要做适配,如此不利于环境管理。
另外最重要的特点在于:使用hierarchy不能出现在package中。
package的定义和使用是systemverilog的一大特色,可以进行组件结构化设计,package之间互不影响,如UVM的env、agent、driver等组件,一般都会封装在一个package内。
2. interface连接
对上述方式改进后,可以使用interface作为DUT和验证环境的中间代理。在testbench的顶层完成DUT和interface的连接,并将interface传递到验证环境中。virtual interface可以出现package、class内,验证环境内使用interface中的信号,尽可能减少DUT改动对验证环境内部的影响。
3. VPI访问
systemverilog支持VPI接口,DUT经过编译后,可以通过VPI接口访问DUT内部信号,把信号的hierarchy换成字符串即可。经过UVM封装后,可以直接使用uvm_hdl_force/read等接口。
bit A;
bit[15:0] B
if(uvm_hdl_read("dut.sub_block.A",A)) begin
.....
end
//bit[31:0] Y
uvm_hdl_read("dut.X.Y[15:0]",B) //错误!
使用VPI访问缺点:不能按位域驱动和读取。对于多bit信号,无法只对其中的部分bit操作。
一般而言对于黑盒验证中的加密代码,使用Hierarchy和VPI方式都是无法获取加密代码内部信号的状态。当然如果在已知加密代码层次前提下,通过一些处理,还是可以通过Hierarchy方式进行后门操作。
利用寄存器模型的内建seq来检查。
通过读取寄存器模型的复位值(与寄存器描述文件一致),与前门访问获取的寄存器复位值进行比较,以此判断硬件各个寄存器的复位值是否按照寄存器描述去实现。
Q135.寄存器读写是怎么检查的?前门访问,你怎么知道对不对?
读写测试
随机值测试:随机写一个寄存器值,然后读出check。
位粘连测试:采用00...001和11...110进行移位操作写入读出对比测试防止寄存器某些位粘连。
位翻转测试:写0x55...555(0101...0101)、0xaa...aaa(1010...1010),读出check。
位边界测试:写00...00,fff...ff(1111...1111),读出check。
Q136.代码覆盖率不满足100%怎么办?
代码覆盖率的主要作用
保证基本逻辑的正确性(要结合有效的校验,这点很容易在实际中变形)
引入对未覆盖代码的思考,分析是编码本身逻辑混乱,还是需求实现有问题
促进代码重构,得到更优的代码
最主要的提升代码覆盖率的方法是增加用例和优化代码。
根据业务流程规划测试用例,设计用例场景、提供校验准则,保证用例的有效性,从而提高代码覆盖率。
构造异常用例,对其他异常场景补充用例。
剔除不需要计算覆盖率的代码,例如库代码等。
减少不必要的判断,例如不必在每次new以后都做指针判空。
简化逻辑,消除重复代码。
Q137.断言覆盖率怎么写的,验证了哪些?
断言是一种声明性的代码,验证设计功能和时序。断言可以检查信号的值或者设计的状态,cover property语句用来测量这些关系是否发生。
其作用是提高TB的可重用性,其还可进行特殊激励的产生等callback的类还是原先的类,只是内部的callback函数变了,而factory这是产生一个新的扩展类进行替换。在不创建复杂的OOP层次结构前提下,针对组件中的某些行为,在其之后,内置一些函数,增加或者修改UVM组件的操作,增加新的功能,从而实现一个环境多个用例。还可以通过callback机制构建异常的测试用例。
操作步骤:
1、UVM组件中内嵌callback函数或者任务
2、定义一个常见的uvm_callbacks class
3、从UVM callback空壳类扩展uvm_callback类
4、在验证环境中创建并登记uvm_callbac
Q139.Gvim的操作模式,搜索是如何让写的。
/***
Q140.Linux的搜索是怎么搜索的。他里面的数据的权限是如何让进行修改的。
Gerp …* find
Q141.Logic与wire和reg的区别是什么与联系是什么。
wire表示导线结构,reg表示存储结构
wire使用assign赋值,reg赋值定义在always、initial、task或function代码块中。
wire赋值综合成组合逻辑,reg可能综合成时序逻辑,也可能综合成组合逻辑。
单驱动时logic可完全替代reg和wire,除了Evan提到的赋初值问题。
多驱动时,如inout类型端口,使用wire。
Q142.Prority的测试你是如何发的。
在checker中设定了一个任务,直接在dut抓取到优先级最高的信号(此时arbiter的优先级最高,通过这个req的信号拉高得到,最高的优先级的channel的id,然后再放到另一个task内看对应的ack信号是否为高)(arbter的interferce里面有信号ack),在这里面是新建了一个接口与reference module是如何相连接的。是在test中例化,然后create+ configu+build+lockmodel(锁定模型,不允许加入新的寄存器)+reset(复位)+rgm.default_map.set_sequencer(env.bus_agt.sqr,reg_sqr_adapter)通过set_sequencer函数将其连接在一起。
Q143.异步的fifo都分为哪几个模块。
将计数器跟空满的信号关联起来
计数器的模块,采用counter的计数器,分为4个模块,同写同读、只读、只写、不独不写、
写入数据和读出数据时,将数据放入men中
读写状态下的指针变化情况。
Q144.各个变量的数据类型都是什么,我们在tb里面写的数如果传到dut里面,这里的所有的变量是如何让进行转换的。
通过interferce中的logic进行转换
Q145.寄存器模型写一下?
由reg_filed、 uvm_reg、 uvm_reg_block这三个块所构成。
Q146.reg map与reg block的区别是什么?
每个寄存器在加入寄存器模型之后都有其对应的地址,map就是储存这些地址,并将其转化为可以访问的物理地址。
Q147.Fifo的空满的覆盖率你是如何描述的。
直接写进去16个数,在读出来16个数,这样就知道了FIFO的空满状态。得出结论。
Q148.Vcs在仿真的时候都经历哪3步,编译的时候生成了simv的文件然后编译器才会仿
Q149.Ahb的burst的总线操作是什么样的。如果连续发了两个数的话,burst信号是如何发生变化的。
Q150.阻塞和非阻塞赋值的联系与区别是什么?用什么符号进行表示的。
阻塞= 常用于组合逻辑电路。需要等上一条执行完了在执行下一条命令。
非阻塞<=常用于时序逻辑电路,不需要等,都是同时执行。
Q151.描述一个简单的时钟产生信号。是用什么样的赋值语句实现:<=是非阻塞赋值实现的。
Q152.Assign和always的区别。
Assign用于组合逻辑电路,不可综合 wire型,开始就执行。
Always用于时序逻辑电路。可综合 reg型 等always块中有时序变化的时候可以执行
Q153.Class的子类可以继承于class的父类的哪些东西
方法和属性。
如果是virtual class呢
Virtual task与virtual function的区别:如果使用了virtual 那么父类的句柄可以直接调用子类的改写之后的方法。
Virtual class的方法我们可以得出一个结论,就是,可以被扩展但是不可以被实力化的类。
Q154.约束里面的solve before
Solve X before Y 代表的是关于先解决X的·分布概率,在解决Y的分布概率。
Q155.异或的工作原理是什么
相同为0,不同为1
Q156.Router的运行原理是什么样的?
如何将·APB-UVC和UART-UVC,集成到验证环境中去?
例化
157.三分频和二分频的verilog实现
Q158.Makefile后面的编译命令都是什么意思
Q159.跨时钟域CDC的基础概念:FIFO 格雷码
Q160FIFO为啥会打慢了3拍
1拍是由于读指针需要用wclk来进行同步。读指针需要用写时钟同步,同步了一拍
异步的空信号同步到读时钟,经过了两个d触发器,同步了两拍
Q161.Conpnent与object的区别:?
有无phase
Component是一直存在的,而对于component的不一样的
有无parent,New函数是否一样
继承的关系,component是继承于object的,object是继承于void的
哪些是component哪些是object?
Object:sequence 、sequence_item、config
Component:driver、monitor、scoreboard、agent、test 、reg、adapter、sequencer、
Q162.Uvm中为什么要phase机制?
目的就是用来做不同的component做同步的。
Q163.哪些是重上到下的phase,哪些是从下到上的?
Bulid是从uvm_void,开始重上致下。是从上往下派生的。
Connect的参数是parent,所以是从下往上长的
一种sequence只能是sequence item
Q164.Filed automation的标志位的使用:
`uvm_component_utils_begin
Q165.Copy与colne的需要写一些utils begin utilus end的区别。
表示的是这样的是写一些,copy和colne的说明。
Compare、pack、pack_byte
`uvm_component_utils_end
Apb的信号的只需要两个周期。
Idel、setup、ENABLE三个状态
Q166.UVM中是如何开始的,如何结束的?
会检查phase中有无raise_objection提起,必须要在消耗时间的语句之前完成。
Drop_objection的时候代表仿真的结束。
Q166.Run-phase与main_phase的区别?
main_phase执行run_phase一定会执行的,反过来不会执行。
Q167.Sequence和driver的握手机制?
sequence_item port sequence_item_export
有两种方式:1.通过driver中的put_response(rsp)、和sequence中的get_response(rsp).
在driver中调用seq_item_port.item_done(rsp);
俩步的关键就是设定rsp.set_id_info(req).这个函数将req的id信息复制到rsp。
uvm可重用性性主要是要用uvc的sequence
Q168.I2c与apb的时序图是如何画的?
Q169.APB与URAT的接口是如何做的?
Q170.解释一下config函数的各个参数的意义:(能不能写出来)
Config#db(virtual interfere)::set(uvm_root::get(),”uvm_test_top.uart_env*”,”vif”,”apb_vif”)
Q171.多态:
不同的子类,在继承父类的方法之后,分别都重写,覆盖了父类的方法,即父类的同一方法在,在继承的子类中出现了不同的形式。所以多态和继承是密不可分的。
当一个父类被扩展之后,其所有的变量和方法(local)的除外,都会被其扩展类所继承。
一般情况下,父类是不会访问派生类的重写和新增的部分的,假如希望重写的方法被看到,就需要依靠虚方法和多态。
Q172.I2C与UART总线的区别:
区别主要是:I2C可以1对多,而UART只可以一对一的发
12c接口带有同步时钟,而uart没有,所以对时钟的要求远不如uart那么高。
波特率是指每秒可以传输9600个bit位
25Mhz=25000000/9600*16=162.7604.
常见的波特率有1200、2400、4800、9600、19200.这几种。
Q173.覆盖的操作是什么?
Set_type_override();
Q174.同步复位与异步复位怎么写
同步always@(posedge clk)
优点:1. 一般能够确保电路是百分之百同步的
确保复位只发生在有效时钟沿,可以作为过滤掉毛刺的手段
缺点:1.复位信号的有效时长必须大于时钟周期
2.由于大多数的厂商目标库内的触发器都只有异步复位端口,采用同步复位的话,就会耗费较多的逻辑资源
异步always@(posedge clk or negedge rst_n)
优点:1.异步复位信号识别方便,而且可以很方便的使用全局复位;
2.由于大多数的厂商目标库内的触发器都有异步复位端口,可以节约逻辑资源
异步复位缺点:
1.复位信号容易受到毛刺的影响;
2.复位结束时刻恰在亚稳态窗口内时,无法决定现在的复位状态是1还是0,会导致
Q175.APB-UART画一下apb的协议?
Q176.Config#db如何去写?里面的参数都有什么意义?写一下你这个项目里面用到的都是如何去用的?
Q177.UVM中的compnent的上一层是什么,他是怎么来的,再上一层是什么?
Q178.如何再linux下写一段话,把下面的.C文件替换为.cpu文件?
Q179.功能覆盖率
·每一次仿真都会产生一个带有覆盖率信息的数据库,记录随机游走的轨迹。把这些信息全部含并在一起就可以得到功能覆盖率,从而衡量整体的进展程度。
·通过分析覆盖率数据可以决定如何修改回归测试集。
·如果覆盖率在稳步增长,那么添加新种子或者加长测试实际即可。如果覆盖率增速放缓,那么需要添加额外的约束来产生更多"有意思“的激励。如果覆盖率停止增长,然而设计某些测试点没有被覆盖到,那么就需要创建新的测试了。
·如果覆盖率为100%但依然有新的设计漏洞,那么覆盖率可能没有覆盖到设计中的某些设计功能区域。
Q180.如何通过uvm_top调用方法run_ tstet(test_name), uvm _top做了如下的初始化:
1.得到正确的test_ name。
2.初始化objection机制。
3.创建uvm_ test _top实例。
4.调用phase控制方法,安排所有组件的phase方法执行顺序。
5.等待所有phase执行结束,关闭phase控制进程。
6.报告总结和结束仿真。
Q181. uvm_ _top承担的核心职责包括:
1.作为隐形的UVM世界顶层,任何其它的组件实例都在它之下,通过创建组件时指定parent来构成层次。
2.如果parent设定为null, 那么它将作为uvm_ _top的子组件。
3.phase控制。控制所有组件的phase顺序。
4.索引功能。 通过层次名称来索引组件实例。
5.报告配置。通过uvm_ top来全局配置报告的繁简度(verbosity) 。
6.全局报告设备。由于可以全局访问到uvm_ top实例,因此UVM报告设备在组件内部和组件外部(例如module和sequence)都可以访问。
Q182.System Verilog中带符号的数据类型:
bit b; //双状态,单比特
bit [31:0] b32; //双状态,32比特无符号整数
int unsigned ui; //双状态, 32比特无符号整数
int i; //双状态,32比特有符号整数
byte b8; //双状态,8比特有符号整数
shortint s; //双状态,16比特有符号整数
longint |; //双状态,64比特有符号整数
integer i4:; //四状态,32比特有符号整数
time t; //四状态,64比特无符号整数
real r; //双状态,双精度浮点数
Q183.流操作符>>和<<
Q184. .sv,.svh, include, import,ifndef, ifdef, endif的含义
.sv文件用于正常编写systemVerilog文件
.svh文件是用于开发VIP时,将一些类、成员方法定义在内部,具体方法实现通过extern在另外一个.sv文件中声明
include将文件中所有文本原样插入包含的文件中。这是一个预处理语句,include在import之前执行。他的主要作用就是在package中平铺其他文件,从而在编译时能够将多个文件中定义的类置于这个包中,形成一种逻辑上的包含关系。
import不会复制文本内容。但是import可将package中内容引入import语句所在的作用域,以帮助编译器能够识别被引用的类,并共享数据。
ifndef 是为了避免仿真器重复编译文件
ifdef是如果编译过了则继续执行后面的代码
endif程序快结束标志
在SystemVerilog中,所有`define语句仅对特定的编译步骤有效,因为它们由编译器的预处理程序处理,它们不能成为SV软件包的一部分,所以在包里面是不参与预处理的编译的,因此每次都必须include宏定义的头文件。 因为include是比import更早地编译,所以增加`include "uvm_macros.svh,这样预编译有了这个头文件的加入,代码中的宏定义就会识别成功,否则编译器就会报错。
Q185.描述从芯片spec到tapeout的整个过程,重点介绍哪些步骤需要验证,以及所需的文件和验证重点
(1)从spec到模块级RTL时,除了RTL文件,还需要寄存器文件来生成高存器模型,构建UVM验
证环境,主要验证每项RTL功能。
(2)从模块到子系统时除了之前的文件,如果在子系统级别需要模拟电源域开关,那么还需要
URE 如果子系统单独综合且较为独立,可能还需要做门级仿真,那么需要综合网表和SDF文件,
验证的重点将是子系统的各项完整功能。
(3)在系统级别时,除了系统级的RTL仿真,也需要进行UPF仿真和]级仿真,因此也需要对应
的UPF文件、网表和SDF文件,验证的重点是各个子系统之间的交互和协调情况。集成连线情况。
Q186、在验证中,一种常用的方法是将输入激励同时给参考模型及被测试设计,然后比较他们的响应以确定设计是否符合预期,请问在比较其响应时需要注意什么?
如果参考模型是非时序的,则主要比较数据内容。如果参考模型有时序模拟,那么还应该比较实际输出数据和期望输出数据在时序上的差异。
对于一些数据可能经过重组,而无法通过单参考模型来比较的情况, 除了在比较数据完整性方面需要考虑,还需要针对数据重组、打包、排序等设计功能设置独立的检查机制,确保所有设计功能都得到监测和检查。
对于比较数调时的调试需要注意,无论比较成功还是失数,都应该打印必要的比较信息, 便于调试打印的信息中,成该有消息源数据比较信息失数信息可能原因等如果比较失败,般需要停止仿真,便于在比较失败现场进行调试。
Q187、在验证工作中,对于激励或者配置的随机化,在进行随机过程中需要注意哪
些方面?
(1)如果激励或者配置已经有约束,那么在随机化时可能会添加外部约束(内嵌约束with{)),那么应该保证外部约束和类原有约束不发生冲突从而使得导致随机化失败。
(2)对于些随机化失败的场景, 应该从仿真日志中获得调试信息,理解哪些约束发生了冲突。
(3)无论是激励还是配置,都应该与测试功能点有关,应当避免与测试目的无关的、相违背的随
机数据产生。
(4)在同一个仿真、或者不同的仿真中,都可以变化随机约束,使得之前的覆盖率可以影响并驱动新的随机数据,继而不断提高覆盖率。
(5)配置的随机化应该只在build phase中完成,避免仿真过程中对配置做次随机,从而发生不可预期的情况。
Q188三段式状态机概念
一段式: 一个 always 块,既插述状态转移,又对描述状态输入输出,当前状态用寄存器输出。
二段式:两个always块, 一个always块采用同步时序描述状态转移, 一个always块采用组合逻辑判断状态转规律及输出,当前状态用寄存器输出。二段式可能出现竞争冒险、产生毛刺.不利于约束.
三段求:三个always块,一个always块采用同步时序描述状态转移,一个always块采用组合逻辑判断状态转规律和条件,一个always块采用同步时序描述状态输出(寄存器输出)。
Q189UVM机制
Factory机制。顾名思义,这是UVM家开的工厂,在这家工厂里面,你可以登记所有你定义的类,当你需要创属对像的时候,只要让工帮你生产出来阅可:当你想要更换对象类物的时候,跟工厂交代下,它会帮你把后续生产的对象都换成你想要的类型。
Config Database机制。翻泽过来就是配置教据库,编写Conig_db,数据库无非就是用来存放
数据的,UVM提供的这个配置教据库功能很齐全,它可以存放一切你想要存放的数据, 井且提供
完善的匹配查询服务。配置数据库的用处在于,可以在不同对象之间传递数据。
Phase机制。这套机制定义了基于UM的仿夏步调也就是说它将整个仿真分成了不同的阶段(phase): 在什么时候实例化还境相件什么时候连接组件什么时段复位、什么时候产生激励什么时候产生报告等等,这些步调都是提前安排好的。
Objection机制。作为软件程序的验证环境,它总是想要不断往下执行,最好不要停下来。然而,
phase机制为所有环境组件都定好了基调,它要协调大家步调致地往前走。 于是Objection机制就出现了,它是协调各个环境组件遵守Phase机制的手段,有时候也会被用来同步跟RTL的步调。
Sequence机制。测试用例如果想要构造稍微复杂-点的测试场景,可以率先构造能够复用的测试序列,然后再根据不同的测试场景组合起来。多个测试序列可能是串行的,也可能是并行的,但都没关系,sequence机制会协通好测过序列通驱动通Driven 之间关系,好让测过向星一个不落地驱动到待测设计按口上。
Reporting机制。 信息的打印对于验证 人员来说至关重要,关系到问题定位的效率,UVM的消息机到韭常强大,消息分了严重等级severity,不同等级的消息对应不同的处理方式, 其中INFO等级的消息还被赋予冗余,便于信息的简选和分类; 此外还提供了相关的宏和函数来便利不同数据结构的打印。
寄存器抽象层(RAL Register AbstactinLayer) 。在数字系统中,寄存器常被用于功能配置、状态记灵和查询,数值传递笔等,切实影响着数字系统的行为, 为了实时最踪这些寄存器的状态,或者方便根据测试意图来配置奇存器,可以使用UVM的寄存器抽象层来完整地映射RTL中的寄存器组,这样除了便利存器的访问,还提供了收集寄存器覆盖率的方法。
事务级建校(TIM, Tansacton Level Modelig) 。事务级区别于信号级不再关心员体某个信号的逻辑值。事务级建模处理的数据对象是一组有关联的数据 可以是数据包(Package)的形式,同时事务Itransaction,也是UVM环境组件之间交互的信息单元。抽象层的建立,使得数据的传递和处理变得更加高效。
Q190. 突发Brust的概念
突发Brust是指同一行相邻的存储单元连续进行数据传输的方式,连续传输的周期就是突发长度。















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









