






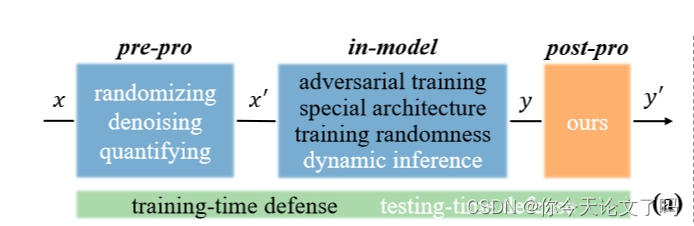
提出背景:
基于分数的查询攻击只能使用模型的输出分数,在数十个查询中制造对抗性扰动,对神经网络构成了实际威胁并且输出的损失趋势容易受到轻微干扰,从而变的不那么有效
本文提出了对攻击者进行对抗攻击的方法。通过稍微修改输出logits来混淆SQAs的错误攻击方向。这种方式:
- 1:无论模型的最坏情况鲁棒性如何都可以防止基于分数查询的攻击
- 2:原始模型的预测几乎没有变化,即干净精度没有下降
- 3:同时改进置信度得分的校准。
由于SQA是黑箱攻击,通过观察DNN的输出分数所指示的损失变化来找到更新AE的对抗方向,因此我们可以直接干扰这些分数,以欺骗攻击者进入错误的攻击轨迹。根据这一想法,我们提出了对攻击者的对抗性攻击(AAA),它操纵损失趋势,使试图按照原始趋势贪婪地更新AE的攻击者走上错误的道路。AAA直接优化DNN的logits,以控制输出损失,使其接近某些设计的曲线,这样攻击者看到我们混淆的输出,就会受到攻击,失去方向。
文章主要贡献:
•我们从SQA防御者的角度分析了当前的防御,并指出后处理模块不仅有效,而且用户友好和插件防御。
•我们设计了一种新的对攻击者的对抗性攻击(AAA)防御,通过轻微干扰DNN输出分数来欺骗SQA攻击者错误的攻击方向。
•我们进行了全面的实验,表明在各种设置下,AAA在准确性、校准和保护方面优于其他8种防御。
符号说明:
SQA在DNN f上生成对抗样本x'是通过最小化logits之间的裕度,定义的边际损失为:
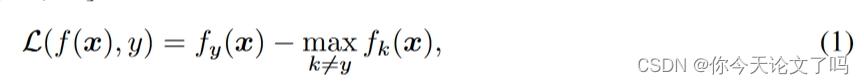
对于没有标签的防御者,可以仅基于logits向量z=f(x)计算无监督边际损失,假定模型的预测标签为正确标有:

对于标签为y的攻击者,如果![]() ,则说明攻击成功,SQA仅在查询后具有较低的边际损失情况下,更新AEs:
,则说明攻击成功,SQA仅在查询后具有较低的边际损失情况下,更新AEs:

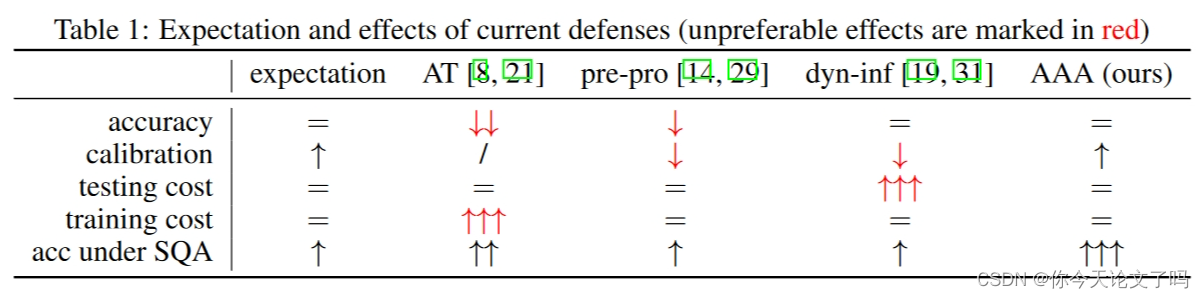
构成重大和实际的威胁。意识到这一点,最近提出了专门针对 SQA 的第一个防御措施,即通过随机噪声预处理输入。此外,其他现有的防御措施也有助于避免 SQA,其中最具代表性的是对抗训练 (AT)、动态推理和预处理。这些防御以不同的机制工作,关键特征如下表所示
 Adversarial attack on attackers
Adversarial attack on attackers
通过post-processing进行防御具有良好的准确性和校准,无需额外训练和可忽略的测试时间计算的优点,
开发了对攻击者的对抗攻击 (AAA) 来控制 SQA 攻击者的行动依据,即 DNN 输出分数指示的损失 。在这种直接的误导下,SQA 攻击者遵循他们原来的策略,由于他们的贪心策略,将被引导到防御者希望他们去的任何地方。但是这种输出变化应该很小,以确保只是攻击者(观察损失趋势)而不是用户(观察输出)被误导。因此,损失趋势不能完全逆转,只能在周期性设定的时间间隔内局部逆转。
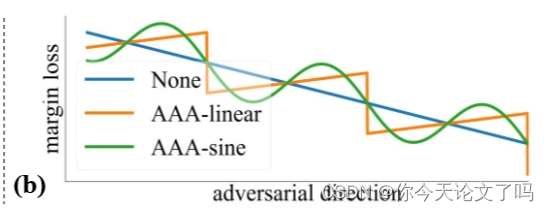
在每个局部区间,有很多设计来操纵损失趋势。 例如,可以让沿对抗方向的损失(几乎)总是增加,并且只会在间隔之间急剧减少,见上图的橙色线。 也可以通过使其像上图中的绿线那样振荡来平滑跨区间损失变化,这样攻击者就无法通过观察损失下降轻易地猜测防御者的策略。两种设计都通过轻微的输出修改来欺骗攻击者,以便用户获得准确的分数。 这是因为手动将损失值分成小区间并分别处理,这是通过设计基于周期损失吸引子(periodic loss attractors)的误导损失曲线实现的:
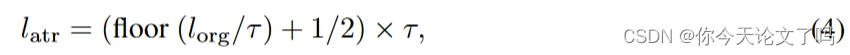

周期性设置的损失吸引器将具有不同的logits划分为有区别。这样可以操纵每个区间中的损失趋势,形成所设计的欺骗攻击者的损失曲线
上图两条误导性曲线中的目标损失值可以表示为:
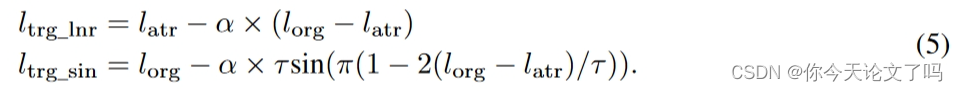
通过控制损失,同时鼓励输出置信度 ![]() ,即softmax之后的最大概率,在单个AAA模块中,可以同时进行防御和较真,以接近校准的一个
,即softmax之后的最大概率,在单个AAA模块中,可以同时进行防御和较真,以接近校准的一个
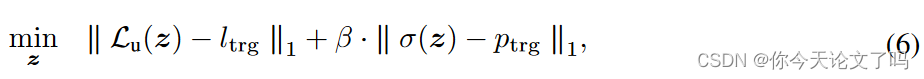
第一项:鼓励扰动logits z具有接近目标值的损失
,从而形成SQA的误导性曲线
第二项:激励输出置信度接近校准的一个
,以便用户获得准确的置信度分数。
在上述两个目标之间取得平衡
算法流程:

AAA首先计算原始损失,根据该原始损失设置形成误导性损失曲线的目标损失
。
然后,AAA优化logits以达到,以及目标置信度
,该目标置信度是通过使用预调温度T划分原始logits而获得的。
整个过程处于测试阶段,仅对logits进行了优化,使AAA成为一种计算高效、插件式和模型无关的方法,具有良好的准确性、校准和对SQA的防御。
总结
我们开发了一种新的防御基于分数的查询攻击(SQA)的方法。我们的主要想法是积极攻击攻击者(AAA),误导他们进入错误的攻击方向。AAA通过对DNN的logits进行后处理来实现这一点,同时强制执行要校准的新输出置信度,使AAA成为一种确定性的插件测试时间防御,通过花费微不足道的计算开销来提高校准和准确性。根据我们对不同环境下的8种防御、6种SQA和8种DNN的研究,与替代防御相比,AAA在减轻SQA方面是有效的。
作为现实应用中的一种防御,AAA在不需要巨大计算负担的情况下大大减轻了对抗性威胁。例如,在自动驾驶或监控系统中,后处理防御模块可以直接在预先训练的模型中实现。尽管成本较低,但采用AAA的好处是深远的。在大多数情况下,用户将获得更准确的置信度分数,以便他们更好地了解模型何时会失败。在对抗性案件中,SQA是真实案件中最具威胁性的攻击,将得到有效预防。
AAA是专门为预防SQA而开发的。因此,防御其他类型的攻击超出了我们的范围。例如,在攻击者完全了解模型的情况下,AAA不会提高白盒设置[16,47]中评估的最坏情况鲁棒性(AAA会以不希望的方式提高AutoAttack[16]的鲁棒准确性)。此外,AAA不适用于避免基于转移的攻击和基于决策的查询攻击,这些攻击在现实世界中要么不可行,要么效率低下,因为AAA对决策边界的影响可以忽略不计。















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









