






文章从鲁棒优化的角度研究了神经网络的对抗鲁棒性。
鞍点问题可以视为内部最大化问题和外部最小化问题的组合。
- 内部最大化问题的目的:找到一个给定数据点x的对抗样本,从而实现高损失,这就是攻击给定神经网络的问题。
- 外部最小化问题的目的:找到模型参数。从而使内部攻击问题给出的对抗损失最小化
PGD(Project Gradient Descent)攻击是一种迭代攻击,可以看作是FGSM的翻版——K-FGSM (K表示迭代的次数),大概的思路就是,FGSM是仅仅做一次迭代,走一大步,而PGD是做多次迭代,每次走一小步,每次迭代都会将扰动clip到规定范围内。
PGD的攻击效果比FGSM要好原因:首先,如果目标模型是一个线性模型,那么用FGSM就可以了,因为此时loss对输入的导数是固定的,换言之,使得loss下降的方向是明确的,即使你多次迭代,扰动的方向也不会改变。而对于一个非线性模型,仅仅做一次迭代,方向是不一定完全正确的,这也是为什么FGSM的效果一般的原因。
对抗鲁棒性的优化观点
找出目标是找到最小化风险的
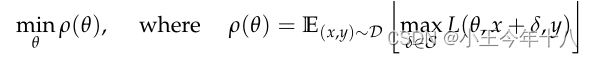
本文进行最大化交叉熵来获得最优攻击性的样本,再通过获得攻击性样本来最小化网络损失。
这是一个Min-max的目标函数,最里层得的目标函数
是无目标标签攻击者的目标函数。它的物理意义就是寻找合适的
使得损失函数在
这个样本点上的函数越大越好,这样才能让模型在它自己正确的标签上的损失特别大,从而导致正确标签对应的logit很小。可以使用单步的FGSM或迭代的FGSM等方法去寻找对抗样本。
外层的
就是防御者的目标函数,它们的目的是为了让模型在遇到对抗样本的情况下,整个数据分布上的损失的期望还是很小。如果可以做到这一点,那么再遇到对抗样本的时候也不用担心,因为这种对抗样本不能产生很大的损失值。这个可以通过先解决内层训练找到所有训练样本的对抗样本,然后用对抗样本替换原样本进行retrain来完成。
PGD攻击
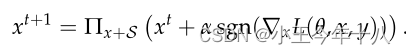
通过PGD方法找到的对抗样本进行训练使得在这些对抗样本上神经网络的loss很小,那么这个神经网络也就可以抵抗其他的对抗样本。尽管这些对抗样本可能跟PGD方法找到的对抗样本很不一样,但是它的loss是相似的,既然神经网络可以让PGD对抗样本的值很小,那么当遇到其他对抗样本,它的loss也不会高的那里去。
面向通用的鲁棒网络
PGD发现局部极大值对于正常训练网络和对抗训练网络都具有相似的损失值,,这提出了一个有趣的现象针对PGD攻击的鲁棒性会产生针对所有一阶攻击算法的鲁棒性,即仅依赖一阶信息的攻击。只要对手仅使用损失函数相对于输入的梯度,我们就可以推测,它不会找到比PGD更好的局部最大值。我们的实验表明,使用一阶方法很难找到这样更好的局部最大值:即使大量随机重启也找不到具有明显不同损失值的函数值。
对抗训练的下降方向
解决鞍点问题的外部问题:
实验结论
容量的作用:仅使用自然样本进行训练时,增加网络的容量会提高针对单步扰动的鲁棒性,当考虑到具有较小的对抗样本时,此效果会更大。
FGSM生成的样本不能增加鲁棒性,当使用FGSM生成的对抗样本训练网络时,我们观察到网络对这些样本过拟合。这种现象被称为标签露,因为:攻击算法产生了非常有限的一组对抗样本,网络会过拟合。
对于小容量网络,尝试针对强大的攻击PGD进行训练会阻止网络学习任何有意义的信息。
随着容量的增加,鞍点问题的损失减小。固定攻击的模型并对其进行训练,随着容量的增加目标函数的值会下降,表明改模型可以更好的拟合对应的对抗样本。
更大容量和更强大的攻击算法会降低可转移性。要么增加网络的容量,要么对内部优化问题使用更强大的方法,都会降低所传递对抗性输入的有效性。















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









