







Tubi 是谁?它做什么?
Tubi 是一个向用户提供高质量免费电影、电视剧和实时新闻的平台。2021 年拥有 4,000 万月活用户, 2022 年预期收益将达 7 亿美元,是该领域的领先玩家。
Tubi 拥有 35,000 优质媒体资源,基于与大量内容方的长期合作,Tubi 将高品质的视频面向用户免费放送,并通过广告创造营收,以此实现多方共赢。
观众可以在超过 25 种设备上观看 Tubi ,在国内比较常见的是 iOS 和 Andriod,在北美是 FireTV , Roku , Comcast 等 OTT 设备。
什么是 TMPP ?
TMPP 是 Tubi Multimedia Processing Platform 的简称,用于接收内容方提供的原始视频,并将原始视频处理为可在各个用户设备播放的视频流;这与多年前大家使用迅雷将视频下载到本地、网盘或者自己搭的平台有着本质区别,TMPP 在各个端传递视频流,而不是将视频下载下来再播放。
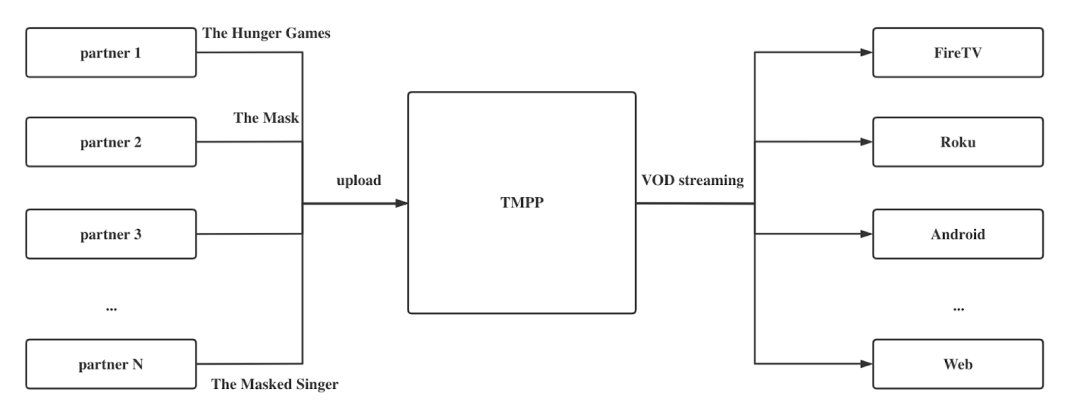
搭建和维护 TMPP ,我们遇到了三个痛点:
-
多
Tubi 的内容合作方数量很大,每一位合作方也会将多年的长尾视频全部给到我们,媒体的整体数量就会非常大。
-
大
Tubi 处理的视频都是长视频,视频长度变大后,体积也会随之增大,比较常见的体积大小是 40 - 50 G ,有些甚至达到 100 - 200 G。
-
繁
内容合作方提供给我们的视频可能年代较久,这样的媒体文件和当代的视频在制作标准上有很大的区别。处理不同视频时,需要不同的处理方式和参数。因此我们需要很好地兼容——不同的内容合作方、不同的文件格式、不同年代的视频格式——各种不同所带来的繁杂。
Processing Stage
为了满足不同媒体文件的处理需求,以及快速地完成一个长视频的处理,TMPP 会将处理过程拆分为若干个阶段,也称作 Processing Stage :
-
Parsing
这一阶段可以理解为对原始视频文件做简单的检测解析,解析之后进行切片,每 10 秒切一片。
-
Transcoding
这是整个系统中最复杂、最耗硬件资源的一个阶段,也就是将没有经过压缩的原始视频文件通过 decode 、 encode 和 compress 压缩成用户端可用的体积,同时兼容视频的体积和画质,这一阶段会产出 mp4 文件,体积依然较大。
-
Packaging
对于 VOD 长视频,我们会将其打包成符合 HLS (HTTP Live Streaming)协议的视频流。
-
Breakfinding
Tubi 通过广告创造营收,也就是说我们在视频播放中插入广告;因此,我们需要找到适合插入广告的点,breakfinding 可以实现自动化地找到这些点。
-
Checking
这一阶段也就是 Quality Control ,比如,原始视频长度和打包完的视频长度是否一致,还有其他多种自动化的 Quality Check 。
以上,我们可以看到不同的阶段之间存在依赖关系;同时我们用不同的微服务 Worker Clusters 处理不同的阶段,不同的阶段对应的硬件需求也是不同的。比如,对于 Parsing 来说,需要硬盘磁盘内存比较大;而对于 Transcoding 来说,CPU 消耗比其他阶段更多;在 Packaging 这一阶段,我们需要借用一个 Public IP 上传到不同的 storage ,并搭建在 AWS 平台上,因此网络上会有一些特殊的配置。
Processing Session
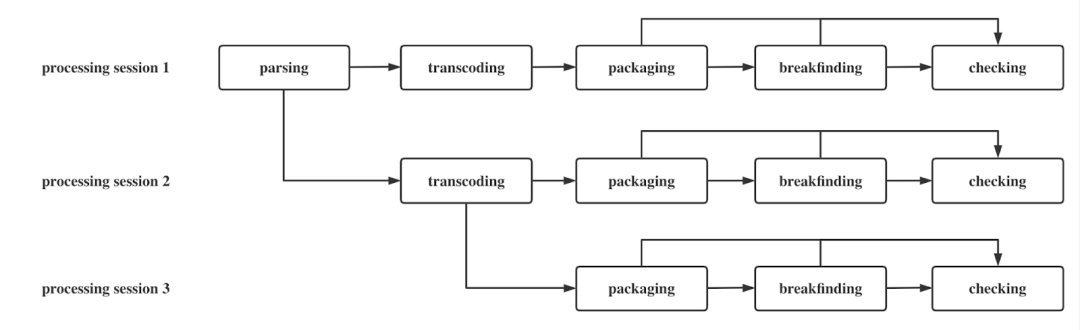
为完成对某一个媒体文件的处理,我们将前文提到的多个 Processing Stage 封装进一个 Session,叫作 Processing Session,一个 Processing Session 完成对某个 media 的一次处理;而实际场景中,我们需要对一个 media 进行 n 次处理,因此也会对应到 n 个 Processing Session。一个 Processing Session 至少包含一个 Processing Stage,一个 Processing Stage 对应一个 Processing Job。
如下图所示, Processing Session 1 是一个全阶段的完整 Session,我们也可以清晰地看到不同 Processing Stage 之间的依赖关系。不同的 Processing Session 可以有不同的处理参数,比如当 Session 1 的处理结果不满足需求,我们需要调整 Transcoding 的参数,通常 Parsing 很少出问题,因此当 Session 2 继承 Session 1,会继承 Parsing 这个阶段,在此基础上开始新的 Stage。如此,我们可以尽可能地节省资源,借由 Processing Sessiong 的灵活性,我们可以处理十分繁杂的需求。
Processing Job
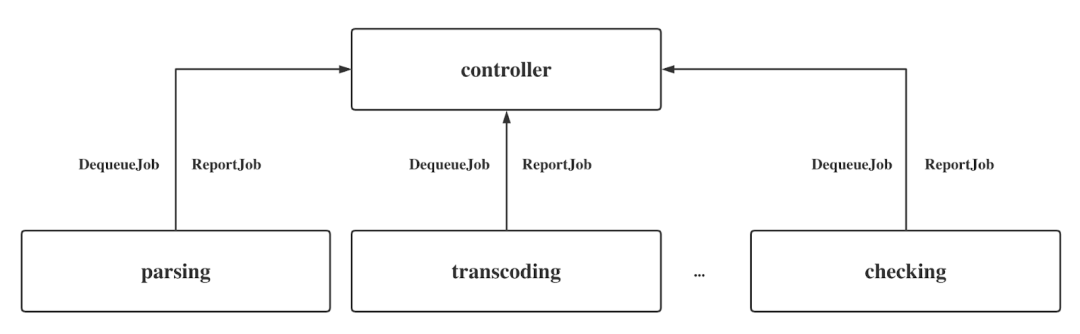
在 TMPP 中,我们主动地 Dequeue Processing Job。Controller 作为中枢提供调动服务,它集中调动 Parsing、Transcoding、Checking 等这些不同的阶段,不同的 Worker Cluster 对应不同的 Processing Job。
不同的 Worker Cluster 都需要和 Controller 进行交互,这种交互通过 Dequeue Job 和 Report Job 实现,而 Worker Cluster 之间保持完全独立。Dequeue Job 就是拿来 Job 进行处理,处理结束后进行 Report Job。
这是一个非常典型的交互模型, Worker Cluster 可以通过 Elixir 实现的,也可以使用 Scala 实现。
通过不同 Worker Cluster 主动 Pull Job 的方式与使用中枢服务直接下发 Processing Job 的方式是非常不同的,大家可以自行对比优缺点。
基于 Parsing、Transcoding 等不同的 Stage, Controller 会有一个 DAG 结构,并维护不同阶段之间的阶段跳转。如下图所示,当 Parsing Job 结束后,我们将 Parsing 对应的 Processing Job 标记为 Finished,当 Processing Session 中的所有 Stage 都完成了,我们将这一 Processing Session 标记为 Finished。
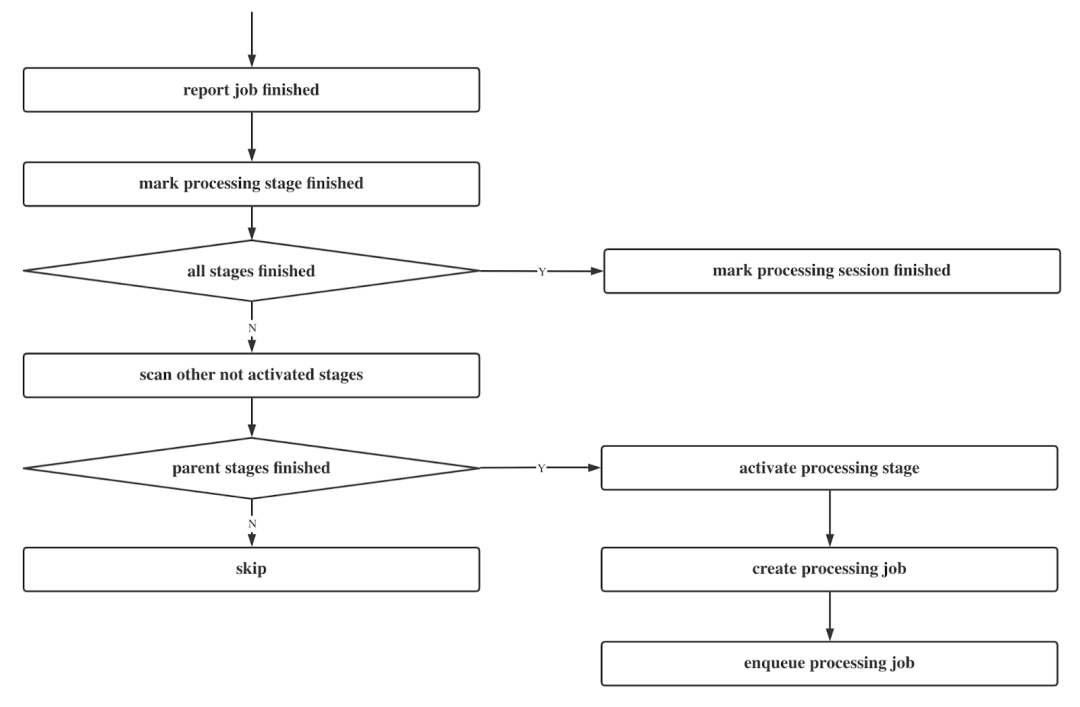
Communication
在 TMPP 中我们使用 gRPC 作为 Worker Cluster 和 Controller 之间的通信方式。我们实现了两个接口 - Dequeue Job 和 Report Job,还有中枢服务用于定期 Check 进度的其他接口。最大的特点是 Worker Cluster 的实现是互不干预的,我们可以用任意的方式实现。
Flexibility and Scalability
在 TMPP 维护和演进的过程中,我们发现这种模型相对更灵活,扩展性也比较高。在 Media 对应的 Processing Session 中,我们完全可以定制这一 Session 中的 Processing Stage,我们不一定需要 Full Stages,以此可以节省资源,也能满足我们的业务需求。如果将来有新加入的需求,只需要加入一个新的 Processing Stage,对应地增加一个新的 Worker Cluster 就可以了。
Transcoding
Transcoding Worker Cluster 是整个视频处理过程中最为复杂的,资源消耗非常大。
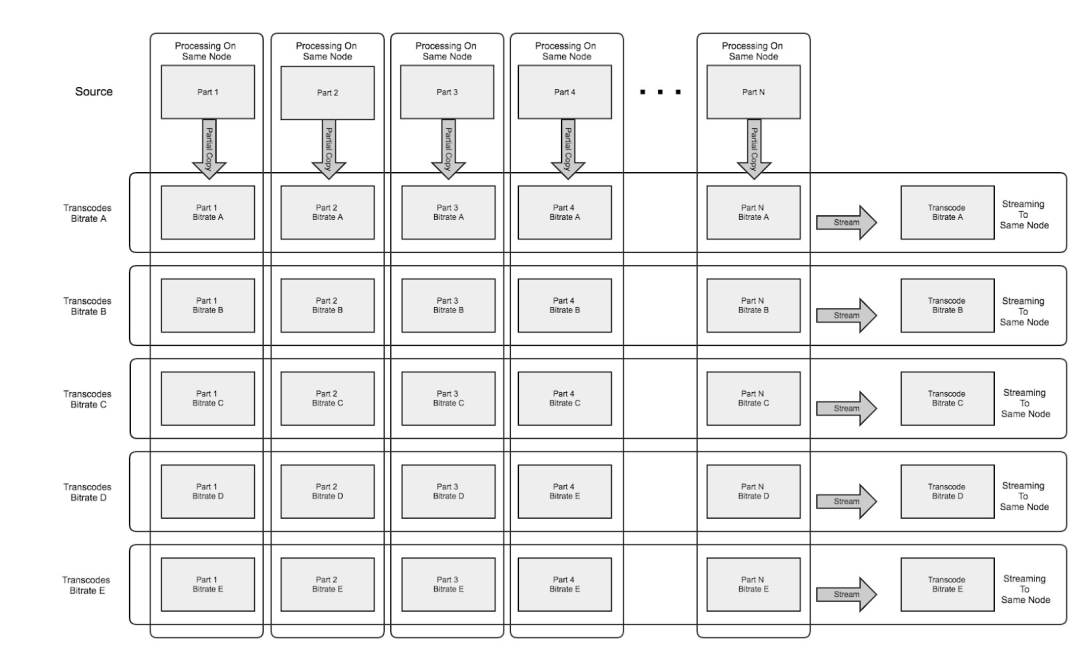
我们使用分片的方式处理视频,这样做的原因是:第一,如果不经过分片处理,整个视频处理过程需要 7 - 8 小时,过程中可能会出现的磁盘异常、网络异常、 CPU 中断都会导致重新开始,因此浪费许多时间和资源。第二,如果长视频不切片,我们将无法使用多 CPU 多节点的方式,使用单节点将使处理效率变得很低。经过分片处理,一个视频分为上千片,我们通过分治的方式分别处理不同的切片,最终合并起来。
Resource Mangement
这种将一个视频分为上千片后分别进行 Transcoding 的处理方式,叫作 Parallel Processing ,如下图所示。过程中涉及多个节点、多个 CPU,因此我们需要对资源进行管理。
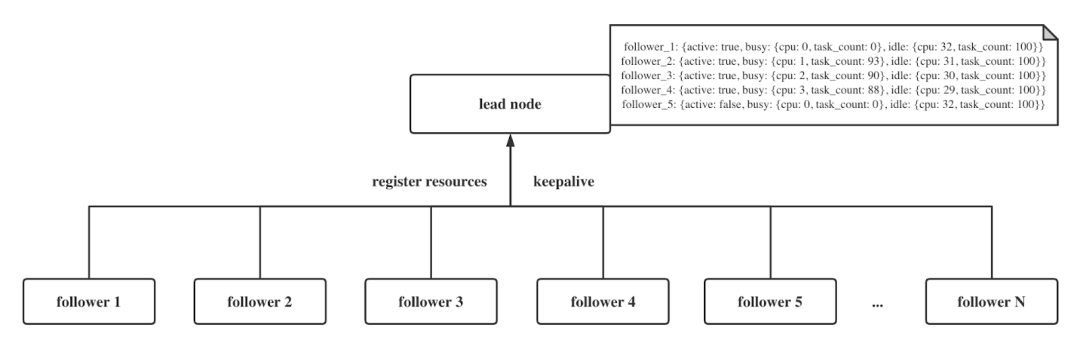
首先,需要选主 Lead Node,接着进行注册资源信息,最后是保活。当我们有了一个 Lead Node,紧跟着的几个 Follower Node 需要用 CPU 作为度量,向 Lead 注册自己有多少资源可用,Lead 和 Follower 之间建立了联系,即当某一个 Follower 崩溃,Lead 需要在注册资源信息中将这一 Follower 移走,也将不再分配任务给这个 Follower 了。我们在注册资源信息和保活中都使用的是 Erlang rpc call,同时都是内置机制,这可以很大地简化开发量,更好地分配资源。
Task Scheduling
建立好了资源分配机制,我们需要进行 Task Scheduling,也就是任务调度。我们会将一个 Transcoding Job 拆分为多个 task,task 又会分为不同的 type,每一个 task 都有明确的定义,包括 deps inputs 以及 outpus。
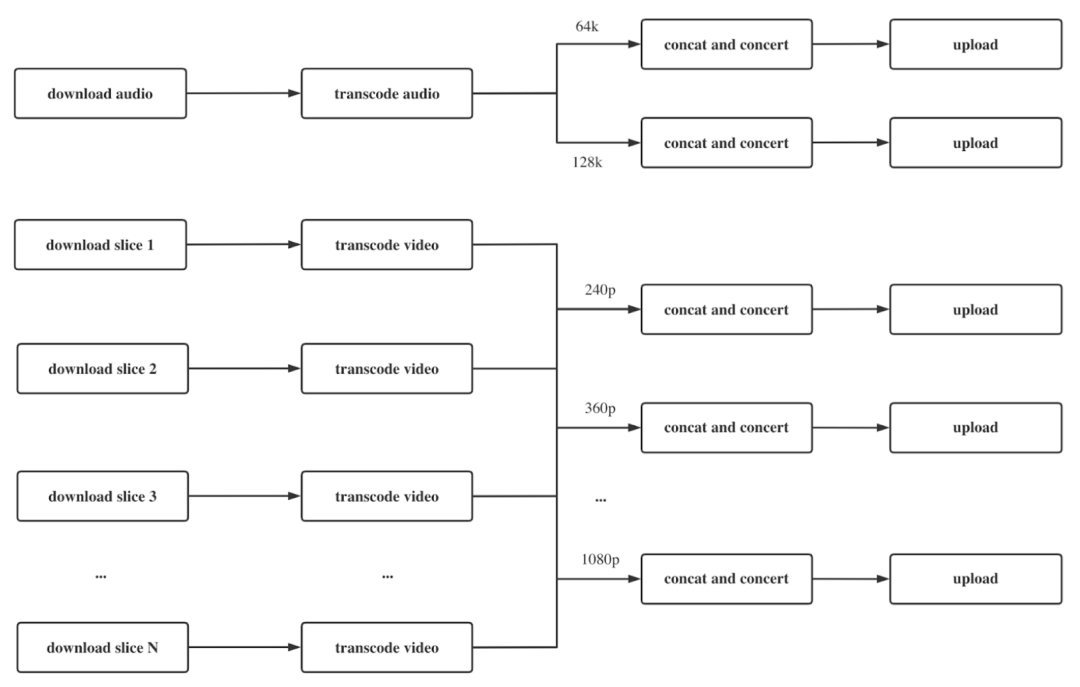
我们遵循由 Lead Node 来管理和调度任务的方式,Follower Node 只提供 CPU 资源,Lead Node 和 Follower Node 之间通过 Erlang rpc 实现通信,如下图所示。另外,我们选择 Elixir/Erlang OTP 的考虑是,我们需要使用超过本地的 CPU 数量,Erlang 提供了 rpc 的机制,即执行在远端,而非在本地。
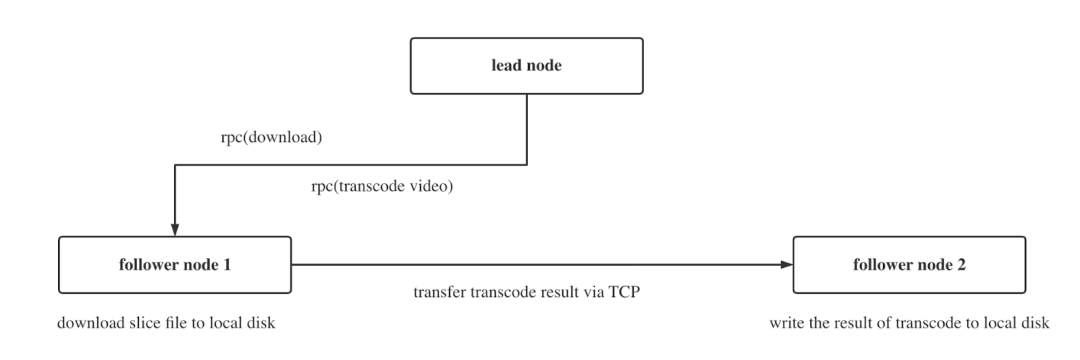
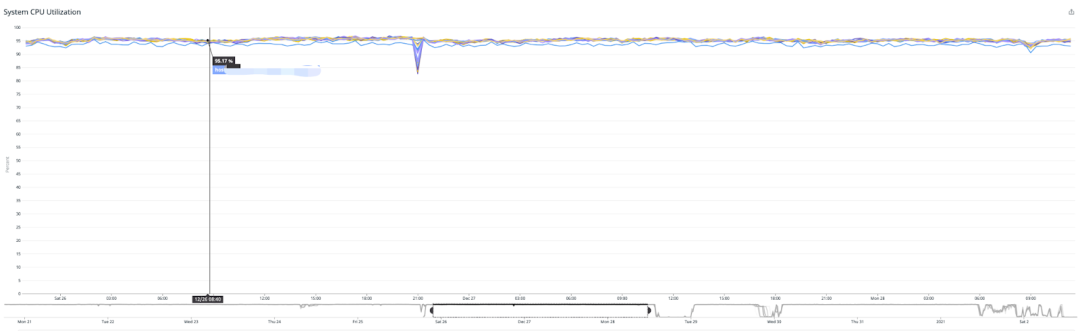
这一套架构在 Tubi 已经运行两年多,是成本最低、性能很高的一套解决方案,可以同时调动足够多的 CPU,也可以极大程度地压榨 CPU,达到 95.17% ,如下面两图所示。
作者:Taotao Lin, Tubi Senior Tech Lead















 6366
6366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









