







我自己的原文哦~ https://blog.51cto.com/whaosoft/13786675
#UV-Mamba
参数量减少40倍,推理速度提高6倍!结合变形卷积的网络如何克服SSM的内存问题?
这篇文章介绍了一种名为UV-Mamba的新型神经网络模型,该模型结合了变形卷积和状态空间模型,用于高分辨率遥感图像中精确检测城市村庄边界。
由于多样的地理环境、复杂的景观和高密度的居民区,利用遥感图像自动识别城中村边界是一个极其具有挑战性的任务。在本论文中,作者提出了一种新的、高效的神经网络模型UV-Mamba,用于在高分辨率遥感图像中准确检测边界。
UV-Mamba通过结合变形卷积(DCN)来抑制状态空间模型(SSM)中图像大小增加而带来的内存损失问题。其结构采用了一个编码器-解码器框架,包括一个拥有四个可变形状态空间扩展(DSSA)块的编码器用于高效的 multi-level语义提取,以及一个解码器用于集成提取的语义信息。
作者在北京和西安数据集上进行了实验,结果显示UV-Mamba达到了最先进的表现。具体而言,作者的模型在北京和西安数据集上的 IoU 分别达到了73.3%和78.1%,分别比现有最佳模型提高了1.2%和3.4%的 IoU,同时在推理速度上快6倍,参数数量上小40倍。源代码和预训练模型可在补充材料中找到。
I Introduction
城市村庄,作为城市化过程中的历史遗留物,由于其低层建筑和密集的建筑物,不理想的环保条件,以及过时的市政基础设施,在城市建设与经营管理中带来了较大的挑战。城市村庄的问题不仅关系到城市的形象美感和清洁,而且直接影响着居民的生活方式,公共安全和社会稳定 。传统收集城市村庄信息的方法主要依赖于人工实地调查,这既耗时又费力 [8]。
为了实现城市村庄边界的自动识别,利用卫星影像进行图像分割技术的探索已引起了广泛关注。一些研究利用先进的语义分割模型,包括全卷积网络(FCN)和U-Net,来映射城市村庄区域 [13, 14, 15] 利用对抗学习来调整语义分割网络,以适应输入图像在不同领域的一致输出。UisNet [16] 通过空间-通道特征融合模块,结合遥感影像和建筑轮廓,增强分割准确度。UV-SAM [17] 利用普通模型和专用模型的优势,将SAM [18]的零样本学习能力应用于城市村庄边界识别任务。
然而,现有研究中准确界定城市村庄边界具有挑战性,主要原因有两点:
一是城市村庄的独特建筑特征,如高密度、狭窄的街道和多样化的建筑形式,使其具有固有的困难;
二是卷积神经网络(CNN)在捕捉全局信息方面存在局限性,以及 Transformer 的计算复杂性,如图1所示,进一步复杂化了这项任务。此外,当超高分辨率(UHR)遥感图像被划分为较小的小块时,空间特征和依赖关系可能会丢失。

为了解决上述问题,作者提出了UV-Mamba模型,该模型利用SSM的全局建模能力和线性复杂度的变形卷积的 spatial几何变形能力。作者的模型通过使用DCN来为感兴趣的区域分配更大的权重,从而改善SSM在长时间序列建模中的内存损失问题,从而提高SSM在不同序列上保留信息的能力。作者的架构的主要贡献如下:
作者引入了UV-Mamba,这是一种基于SSM的新颖而高效的建筑,它既保留了线性计算复杂性,又具有加强的全局建模能力。
作者设计了一种DSSA模块,它通过使用变形卷积为感兴趣的区域分配更大的权重,以减轻SSM在长距离建模过程中的记忆损失,从而提高SSM在扩大序列后保留信息的能力。
作者在中国两个城市北京和西安进行了广泛的实验,结果表明作者的方法取得了优越的性能,超过了基于CNN的现有方法和基于Transformer的方法。
在城市化过程中,城市村庄是一个不可忽视的现象。然而,准确地定义城市村庄的边界是一个具有挑战性的任务。城市村庄具有独特的建筑特征,如高密度、狭窄的街道和多样化的建筑形式,这使得界定其边界具有固有困难。此外,卷积神经网络(CNN)在捕捉全局信息方面的局限性,以及 Transformer 的计算复杂性,如图1所示,进一步复杂化了定义城市村庄边界的过程。因此,开发一种能够高效准确界定城市村庄边界的技术,对于城市规划和管理工作具有重要意义。针对这个挑战,作者提出了UV-Mamba模型,它利用SSM的全局建模能力和线性复杂度的变形卷积的 spatial几何变形能力。作者的模型通过使用DCN为感兴趣的区域分配更大的权重,以改善SSM在长时间序列建模中的内存损失问题,从而提高SSM在不同序列上保留信息的能力。
作者的架构的主要贡献如下:作者引入了UV-Mamba,这是一种基于SSM的新颖而高效的建筑,它既保留了线性计算复杂性,又具有加强的全局建模能力。
作者设计了一种DSSA模块,它通过使用变形卷积为感兴趣的区域分配更大的权重,以减轻
II Methodology
在本节,作者将阐述一种基于深度学习的图像分类方法。首先,作者将介绍数据集的预处理方法,然后将描述模型架构的选择和训练过程,最后给出模型在实际应用中的评估结果。
Preliminaries: State Space Model
状态空间模型是现代控制论中线性时不变系统的概念衍生出的一个概念。状态空间模型将一个维度的输入信号 映射到一个 维的潜在状态 , 然后将其投影到一个一维的输出信号 。这个过程可以通过以下的线性一阶微分方程(ODE)来描述:
其中 是状态转移矩阵, 和 分别是投影矩阵。
为了更好地适应深度学习中如文本序列的离散输入, 和 使用零阶 hold ( ZOH 技术进行离散化, 引入可学习的时尺度参数 , 将连续状态空间模型转化为离散状态空间模型。离散化过程如下:
离散化后,第1式可表示为:
其中 和 分别表示 和 矩阵的离散版本。 表示前一个状态信息, 表示当前状态信息。
模型概述
如图2 (a) 所示, 所提出的 UV-Mamba 模型由三个主要组成部分组成:一个具有可变卷积核大小的茎模块、一个层次化的多路径扫描编码器和一个轻量级的解码器。茎模块执行初始特征提取并下采样输入图像 by a factor of 2 , 由四个卷积层组成, 卷积核大小分别为 和 ,填充分别为 3 和 1 , 步长分别为 2 和 1 。多路径扫描编码器由四个可变形状态空间扩展(DSSA)块组成, 每个阶段都可以将特征图大小减半, 从而相对于模型输入产生各种尺度的特征图: 。解码器包含四个上采样模块, 每个模块通过转置卷积将特征图从编码器中上采样两倍, 随后由两个 卷积进行特征融合。最后, 双线性插值用于将图像恢复到输入大小。
Deformable State Space Augmentation Block
对于UHR远程 sensing密集城市环境,两个主要挑战是:提高像素 Level 的表示和确保SSM的鲁棒全局建模以进行准确的边界提取。为了解决这些挑战,作者设计了一个DSSA块,如图2(b)所示,它包括以下部分:分块嵌入(patch embeddings)、空间适应可变形增强器(SADE)、多路径扫描SSM模块(MSSM)和分块合并。特别的是,作者的SADE和MSSM模块作为中间模块堆叠了两次。通过SADE对感兴趣区域赋予更重的权重,可以缓解全局建模过程中由于SSM导致的内存损失。这种方法在获得线性复杂度的同时,增强了SSM模型的全局建模能力,使其可以更有效地对建筑物进行区分,如图3所示。

多路径扫描SSM模块(MSSM)。 一系列研究【21, 22, 23, 24】已经表明,在基于SSM的模型中,增加扫描方向的数量对于实现全面的全球建模能力至关重要。为了更好地划分城乡界限,作者聚合了来自八个方向的扫描结果(水平、垂直、对角和反对角,前后都可以),以捕捉周围结构的复杂空间关系,并对上下文环境有全面的了解。为了更好地适应不同的输入大小,作者引入了Mix-FFN,它比传统的位置编码(positional encoding)更有效【25】来提供位置信息,通过在Feed-Forward网络中应用3x3卷积。
空间适应可变形增强器(SADE)。 如图2(c)所示,SADE的设计采用了类似于 Transformer 的结构。【29】。通过利用可变形卷积的空间几何变形学习能力,它可以更好地适应城市村庄的多样化空间分布特征。具体来说,作者使用DCNv4操作符对空间特征进行增强,因为其速度快、计算效率高。这个过程如下:
其中 表示聚合组的总数。对于第 组, 表示与位置无关的投影权重, 是第 个采样点的调制 scalar, 表示分块输入特征图, 是网格采样位置的偏移 的。然后, 作者使用 Mix-FFN对提取的特征进行聚合, 这可以减少计算复杂度, 同时保持模型的表示能力。
III ExperimentsExperimental Settings
数据集:作者使用来自北京和西安的两个具有独特建筑风格的中国城市[17]的数据集,这两个城市由于其显著的地理位置差异而具有不同的建筑方式。这两个城市都有传统和现代建筑的混搭,形成了复杂的都市结构,这对作者的模型在提取都市村庄边界方面提出了挑战。北京数据集包含531张图像,西安数据集包括205张图像。作者将这些数据集划分为训练、验证和测试集,比例为6:2:2。每张图像的分辨率均为1024X1024,以确保包含主要的城市信息。
实现细节:作者的实验在单张Tesla V100 GPU上进行,训练100个周期。为了防止过拟合并提高泛化能力,作者在所有实验中应用了统一的数据增强策略,其中包括随机旋转、水平翻转和垂直翻转。模型在城市景观数据集[31]上预训练,然后在对都市村庄数据集进行微调。在预训练过程中,作者使用Adam[32]优化器,初始学习率为0.001。学习率在第一十个周期内 Warm up ,然后逐渐减小到1e-6。跨熵损失[33]在预训练阶段用于优化模型的性能。
预训练权重随后在对都市村庄数据集上进行微调。对于北京和西安数据集上的微调,作者继续使用Adam优化器。学习率在第一个三十个周期内 Warm up ,然后逐渐减小到1e-6。具体来说,对于北京数据集,作者将学习率设置为0.0004,并使用Dice损失函数[34]。对于西安数据集,学习率设置为0.0002,并采用交叉熵损失函数。模型的准确性采用交点与一致性(IoU)、准确率(ACC)和总体准确性(OA)进行评估。效率通过对参数(Params, M)和浮点运算次数(Flops, G)进行评估,分别以#P和#F表示,以便于阅读表格。
Ablation Studies
图像大小: 为了评估上下文信息和空间特征对城市村庄边界检测的影响,作者使用不同大小的输入图像来评估模型性能,结果如表1所示。实验结果显示,随着图像大小的增加,城市村庄检测的准确性持续提高,这可能是由于这些区域的空间持续分布。这一发现强调了使用UHR遥感图像进行精确边界检测的重要性。
DSSA模块: 为了评估UV-Mamba中DSSA模块的有效性,作者在表2中展示了不同模型变体在北京和西安数据集上的分割性能。结果表明,在去掉SADE模块后,模型的性能降低了2.4%和5.5%;同样,去掉MSSM模块后,性能降低了2.8%和6.7%。这些结果强调了准确城市村庄分割对强大的全局建模能力的重要性。此外,作者在DSSA模块内尝试了SADE和MSSM模块的各种位置组合。结果表明,当将SADE和MSSM模块并排时,性能次优,分别达到了72.7%和74.9%的IoU。相反,将SADE模块放在MSSM模块后面会导致整体模型性能最差,这表明SSM的长序列建模限制导致特征图信息丢失,从而误导模型。总之,这些结果表明SADE可以部分补充SSM的全局建模能力,帮助在SSM模型中处理高分辨率遥感图像时减轻内存损失问题。

Comparison to the State-of-the-Arts
如图III所示,UV-Mamba优于先进的市区村庄识别模型 [38, 35, 36, 37, 38],在两个数据集上都达到了最新的性能。可视化的分割结果见图4。关于分割精度,与先前最佳的城市村边界识别模型UV-SAM相比,作者的模型在两个数据集上的IoU提高了1%-3%,而参数大小只有UV-SAM的1/40。此外,在ACC和OA的准确性指标中也观察到了类似的性能提升。

IV 结论
在本文中,作者提出了UV-Mamba模型,该模型通过减小长序列SSM建模中的内存损失,在稠密环境中保持全局建模能力,且线性复杂度的高精度分割和定位城市村建筑。
作者预计,这项研究将为城市村现代化提供重要的技术支持,推动城市发展朝着更高的宜居性、和谐性和可持续性方向迈进。
#GOT-OCR-2.0
OCR研究不曾结束,它才刚刚开始
本文提出通用或者广义OCR(也就是OCR-2.0)的概念,并设计开源了第一个起步OCR-2.0模型GOT。
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model

图1. 通用OCR模型须“通用”
论文地址:https://arxiv.org/abs/2409.01704
项目地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0
OCR一直是离落地最近的研究方向之一,是AI-1.0时代的技术结晶。到了以LLM(LVLM)为核心的AI-2.0时代,OCR成了多模大模型的一项基本能力,各家模型甚至有梭哈之势。多模态大模型作为通用模型,总有种降维打击OCR模型的感觉。那么纯OCR的研究真的到头了吗?我们想说:当然没有!没准才刚刚开始。首先盘一下AI-1.0 OCR系统和LVLM OCR的缺点:
首先是AI-1.0流水线式的OCR系统,缺点不用多说,各个模块比较独立,局部最优,维护成本也大。最重要的是不通用,不同OCR任务需路由不同模型,不太方便。那么多模态大模型在pure OCR任务上有什么缺陷呢?我们认为有以下两点:
为Reasoning让路必然导致image token数量过多,进而导致在纯OCR任务上存在bottle-neck。Reasoning(VQA-like)能力来自LLM(decoder),要想获得更好的VQA能力(至少在刷点上),就要充分利用起LLM来,那么image token就得越像text token(至少高维上,这样就会让LLM更舒服)。试想一下,100个text token在LLM词表上能编码多少文字?那么一页PDF的文字,又需要多少token呢?不难发现,保VQA就会导致在做OCR任务上,尤其是dense OCR任务上,模型搞得比较丑陋。例如,一页PDF图片只有A4纸大小,很多LVLM要都需要切图做OCR,切出几千个image token。单张都要切图,拿出多页PDF拼接图,阁下又当如何应对?我们认为对于OCR模型这么多token大可不必。
非常直观的一点就是模型太大,迭代困难。要想引入新OCR feature如支持一项新语言,不是SFT一下就能训进模型的,得打开vision encoder做pre-training或者post-training,这都是相当耗资源的。对于OCR需求来说太浪费了。有人会说,小模型能同时做好这么多OCR任务吗?我们的答案是肯定的,而且甚至还能更好。

图2. GOT结构与训练流程图
GOT: Towards OCR-2.0
通用OCR模型须要够通用,体现在输入输出都要通用上。我们可以笼统地将人造的所有信号都叫字符,基于此,我们提出通用或者广义OCR(也就是OCR-2.0)的概念,并设计开源了第一个起步OCR-2.0模型GOT,该模型名字就是由General OCR Theory的首字母组成。
在输入方面,模型支持图1中全部的OCR任务;输出方面,模型同时支持plain texts输出以及可读性强、可编辑的formatted文本输出,如markdown等。
模型的结构和训练方法如图2所示,采用vision encoder+input embedding layer+decoder的pipeline。Encoder主体采用带local attention的VITDet架构,这不至于CLIP方案的全程global attention在高分辨率下激活太大,炸显存。Encoder后两层采用Vary的双卷积设计方案。整个Encoder将1024×1024×3的图像压缩为256×1024的image tokens,这足以做好A4纸级别的dense OCR。
整个训练过程分为3个步骤,没有一个阶段锁LLM,也就是不会存在图像到文本的对齐阶段,进而导致损害image token的文字压缩率。3个训练阶段分别为:
- 高效预训练encoder,GOT在整个训练过程中,没有A100级别的卡,为了节省资源,该阶段使用小型OPT-125M作为decoder为encoder提供优化方向,快速灌入大量数据。
- 联合训练encoder-decoder,该阶段GOT的基本结构搭建完成,为上一阶段预训练好的encoder,以及Qwen团队预训练好的Qwen0.5B。我们稍稍加大了decoder的大小,因为该阶段需要喂入大量OCR-2.0的知识,而不少数据(如化学式的OCR)其实也是带点reasoning的,更小的decoder未敢尝试。
- 锁住encoder,加强decoder以适配更多的OCR应用场景,如支持坐标或者颜色引导的细粒度OCR(点读笔可能会用到),支持动态分辨率OCR技术(超大分辨率图可能会用到),多页OCR技术(该feature主要是为了后续follower能更好地训练Arxiv这种数据,我们的设想是多页PDF直接训练,无须再对.tex断页而苦恼!)

图3. GOT使用到的数据渲染工具
当然,整个GOT模型设计最困难的还是数据工程。为了构造各种各样的数据,我们学习了众多数据渲染工具,如图3所示,包括Latex,Mathpix-markdown-it,Matplotlib,Tikz,Verovio, Pyecharts等等。
结果可视化:
多说无用,效果才是一切,GOT的输出可视化效果如下:

例1:最常用的PDF image转markdown能力

例2:双栏文本感知能力

例3:自然场景以及细粒度OCR能力

例4:动态分辨率OCR能力

例4:多页OCR能力

例5:更多符号的OCR能力
总结:
尽管GOT模型表现不错,但也存在一些局限,如更多的语言支持,更复杂的几何图,chart上的OCR性能。OCR-2.0的研究还远的很,GOT也还有不小提升空间(该项目在数据和算力资源上都是非常受限的),正是因为深知GOT以及OCR-2.0的潜力,我们希望通过开源GOT吸引更多的人,放弃VQA,再次投向强感知。都说纯OCR容易背锅,但也正好说明做的不够work,不是吗?
#速览多模态模型 Transfusion 和 Show-o
用 Transformer + 扩散模型同时处理文本和图像
本文介绍了Transfusion和Show-o两个多模态模型,它们结合了Transformer和扩散模型来处理文本和图像,Transfusion在图像生成上表现更佳,Show-o则在资源需求上更为高效。
近期,有两个大型多模态模型于同期公布:一个是来自 Meta 的 Transfusion,另一个是来自 Show Lab 和字节跳动的 Show-o 。好巧不巧,二者都宣称自己的模型是几乎最早将多模态任务用一个 Transformer 完成的,不需要借助额外的文本编码器实现图像生成,同时结合了自回归生成和扩散模型。我很好奇这两篇工作究竟有多少创新,于是快速扫完了这两篇论文,并简单给大家分享一下它们的核心内容。在这篇文章中,我会快速介绍两篇工作的核心模型架构与部分实验结果。由于我仅对视觉任务比较熟悉,对语言和多模态没有那么了解,我的分析将主要围绕视觉任务。
论文 Arxiv 链接:
Transfusion: https://arxiv.org/pdf/2408.11039
Show-o: https://arxiv.org/pdf/2408.12528
读前准备
在阅读这两篇新工作时,建议大家先熟悉以 Transformer 为代表的自回归生成、以 DDPM、LDM、DiT 为代表的扩散模型、以 MaskGIT (Masked Generative Image Transformer), MAR (Masked autoregressive models, 于 Autoregressive Image Generation without Vector Quantization 论文中提出) 为代表的掩码自回归图像生成这三类生成模型,并简单了解此前较为先进的 Chameleon (Chameleon: Mixed-Modal Early-Fusion Foundation Models) 多模态模型。本文不会对这些知识做深入回顾,如果读者遇到了不懂的旧概念,请先回顾有关论文后再来看这两篇新文章。
自回归模型
自回归模型用于生成形如 这样的有序序列。自回归算法会逐个生成序列中的元素。假设正在生成第 个元素, 则算法 会参考之前所有的信息 , 得到 。比如:
自回归任务最常见的应用场景是文本生成。给定第一个词,生成第二个词;给定前两个词,生成第三个词……。
为了训练实现这一算法的模型,一般我们需要假设每个元素的取值是有限的。比如我们要建模一个生成单词的模型,每个元素是小写字母,那么元素的取值只有 a, b, c, ..., z。满足这个假设后,我们就可以像分类任务一样,用神经网络模型预测的类别分布建模已知之前所有元素时,下一个元素的分布,并用交叉熵损失函数去优化模型。这种训练任务被称为下一个词元预测 (next token prediction, NTP)。
用自回归生成建模某类数据时,最重要的是定义好每个元素的先后顺序。对于文本数据,我们只需要把每个词元 (token) 按它们在句子里的先后顺序编号即可。而对于图像中的像素,则有多种编号方式了。最简单的一种方式是按从左到右、从上到下的顺序给像素编号。
掩码自回归模型
由于图像的像素数很多,用自回归模型一个一个去生成像素是很慢的;另外,按从左到右、从上到下的顺序给像素编号显然不会是最合理的。为了提升自回归模型的速度和表现,研究者提出了掩码自回归模型。它做了两个改进:
1) 相比按序号一个一个生成元素的经典自回归模型,这种模型在每轮生成时可以生成多个像素(下图中的橙色像素)。
2) 相比从左到右、从上到下的固定顺序,像素的先后顺序完全随机(下图中的 (b) 和 (c) )。
由于这种方式下必须一次给模型输入所有像素,并用掩码剔除未使用的像素,所以这种自回归被叫做掩码自回归。

扩散模型
扩散模型将图像生成表示成一个噪声图像 从时刻 开始随时间变化 , 最后得到目标图像 的过程。和输入输出为部分像素的自回归模型不同, 扩散模型的输入输出自始至终都是完整图像。
为了减少扩散模型的计算量,参考 Latent Diffusion Model (LDM) 的做法,我们一般会先用一个自编码器压缩图像,再用扩散模型生成压缩过的小图像。正如 NLP 中将文本拆成单词、标点的「词元化」(tokenize) 操作一样,这一步操作可以被称为「图块化」(patchify)。当然,有些时候大家也会把图块叫做词元,把图块化叫做图像词元化。
严格来说,本文讲到的「像素」其实是代表一个图块的图像词元。用「像素」是为了强调图像元素的二维空间信息,用「图像词元」是强调图像元素在自回归模型中是以一维序列的形式处理的。
有人认为,掩码自回归模型是一种逐渐把纯掩码图像变成有意义图像的模型,它和逐渐把纯噪声图像变成有意义图像的扩散模型原理类似。因此,他们把掩码自回归模型称为离散扩散模型。还有人认为扩散模型也算一种更合理的自回归,每轮输入一个高噪声图像,输出一个噪声更少的图像。但这些观点仅仅是从称呼上统一两种模型,两种模型在实现上还是有不少差别的。
Chameleon
Chameleon 似乎是此前最为先进的多模态模型,它是这两篇新工作的主要比较对象。在语言模型的基础上,Chameleon 并没有对图像的处理多加设计,只是以离散自编码器(如 VQGAN)的编码器为图像词元化工具,以其解码器为图像词元化还原工具,让被词元化后的图像词元以同样的方式与文本词元混在一起处理。

功能与效果
看方法前,我们先明确一下两个多模态模型能做的任务,及各任务的输入输出。
Transfusion 是一个标准多模态模型,也就是一个输入输出可以有图像词元的语言模型。它输入已知文本和图像,输出后续文本和图像。

基于这个多模态模型,可以做文生图任务。

这个模型似乎没有为特定任务设置特殊词元,所有图像功能完全靠文本指定。因此,要做图像编辑任务的话,需要在带文本标注的图像编辑数据集上微调。文章指出,只需要在一个仅有 8000 项数据的数据集上微调就能让模型具有一定的编辑能力。

相比之下,Show-o 可以在序列前多输入一个区分任务的特殊词元。因此,Show-o 可以完成多模态理解(输入多模态,输出文本描述)、图像生成(根据文字生成图像或填补图像)、多模态生成(输入输出都包含图片、文本)等丰富的任务。似乎特殊词元仅有多模态理解 (MMU, Multi-modal Understanding MMU)、文生图 (T2I, Text to Image) 这两种。

Transfusion 的基础模型在微调后才能做根据文本提示来编辑图像的任务,而 Show-o 的基础模型默认是在此类带有文本提示的图像编辑数据集上微调的。
方法
对于熟悉此前图像生成模型、语言模型的研究者来说,这两篇工作都仅用了现有技术,核心方法非常易懂。这两篇工作并不是试图开发一种新的图像生成技术,而是在考虑如何更好地将现有图像模型融入多模态模型。
在读新技术之前,我们先以 Chameleon 为例,看一下之前的多模态模型是怎么做生成的。在我看来,之前的多模态模型不应该叫「多模态模型」,而应该叫「强行把图像当成词元的语言模型」。语言模型在处理文本时,文本中的词语、标点会根据规则被拆成「词元」,成为模型的最小处理单位。然而,要用同样的方式处理图像,就要定义什么是「图像词元」。受到之前图像离散压缩模型(以 VQGAN 为代表)的启发,大家用一个编码器把图像切成图块,每个图块可以用一个 1, 2, 3 这样的整数序号表示,再用一个解码器把用序号表示的图块翻译回真实图像。这里的带序号图块就和文本里的单词一样,可以用「词元」来表示。文本、图像都被统一成词元后,就能用标准 Transformer 的下一个词元预测任务来训练多模态模型。
如下图所示,训练时,文本基于程序规则变成词元,而图像经过一个编码器模型变成词元。两类词元被当成一类数据,以同样的方式按下一个词元预测任务训练。生成时,多模态模型自回归地生成所有词元,随后文本词元基于程序规则恢复成文本,而图像词元通过解码器模型恢复成图像。

这种多模态模型最大的问题是没有充分设计图像词元生成,还是暴力地用 Transformer 自回归那一套。虽然有些模型会多加入一些图像生成上的设计,比如 LaVIT (Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization) 用扩散模型来做图像词元的解码,但核心的图像词元生成还是离不开标准自回归。
Transfusion 和 Show-o 的设计初衷都是引入更先进的图像生成技术来改进图像词元生成。先看 Show-o。要改进标准的一个一个按顺序生成图像词元的图像自回归模型,最容易想到的做法就是按照 MaskGIT, MAR 那一套,将标准自回归换成掩码自回归。在做掩码自回归时,像素的先后顺序完全随机,且一次可以生成多个像素。另外,图像词元之间可以两两互相做交叉注意力,而不用像文本词元一样只能后面的对前面的做交叉注意力。

Show-o 莫名其妙地把自己的图像生成模型称为离散扩散模型。如前文所述,叫离散扩散模型还是掩码自回归,只是一个称呼上的问题。由于问题建模上的重大差异,大家一般还是会把扩散模型和掩码自回归看成两类模型。
而 Transfusion 更加激进地在革新了多模态模型中的图像生成方式。现在最好的图像生成技术不是扩散模型吗?我们干脆直接把整个扩散模型搬过来。于是,在 Transfusion 生成多模态内容时,程序会交替执行两种模式:在语言模型模式下,程序按标准自回归逐个生成文本词元。一旦生成了特殊词元 BOI (begin of image),就切换到扩散模式。在扩散模式下,程序按 DiT, SD 3 (Stable Diffusion 3) 那种标准扩散模型的方式,一次性生成所有图像词元。结束此模式后,程序往词元序列里填一个 EOI (end of image),重返语言模型模式。

同理,在训练时,两种模态也用不同的任务来训练。语言模型老老实实地按下一个词元预测训练,而扩散模型那部分就按照训练扩散模型的标准方式,先给所有图像词元加噪,再预测噪声。因此,只看图像生成任务的话,Transfusion 更像 SD 3 这种文生图模型,而不像此前的基于语言模型的多模态模型。
Transfusion 和 SD 3 之间的最大区别在于,文本词元还是按照语言模型那一套,只能在交叉注意力看到之前的文本词元。而图像词元之间两两都能看到。这种交叉注意力的设计和 Show-o 是一模一样的。当然,由于现在文本也会在同一个 Transformer 里处理,所以 Transfusion 自己就扮演了解读文本的工作,而不像 SD 3 那样还需要单独的文本编码器。

定量评测结果
我们最后来看一下两篇文章展示的定量评测结果。
Transfusion 用了许多篇幅来展示它与 Chameleon 之间的对比。从数值指标上看,Transfusion 全面领先 Chameleon。明明没有对文本任务做特别的优化,Transfusion 却在文本任务超越了 Chameleon,这挺令人惊讶的。为了探究这一现象的原因,作者从同一个预训练语言模型开始,以同样的配置训练了 Transfusion, Chameleon。结果显示,相比加入图像扩散模型,加入 Chameleon 那种离散图像词元对文本指标的损害更大。作者猜测,这是因为扩散模型更加高效,模型能够把更多精力放在文本任务上。
而从图像生成模型的对比上看,Transfusion 比之前多数文生图模型都要好,只是比顶尖文生图模型 SD 3 要差一点。

再来看 Show-o 的评测结果。Show-o 在部分文本指标上超过了之前的语言模型。作者也坦言,这些指标仅表明 Show-o 有潜力在文本任务上做到顶尖。

Show-o 也展示了图像任务的指标。和 Transfusion 一样,Show-o 展示了表示图像质量的 COCO FID 指标以及评价文本图像匹配度的 GenEval 指标。Show-o 在图像指标上超越了此前多数多模态模型,且超越了 Stable Diffusion 2.1 等图像生成模型。但是其图像指标比 Transfusion 还是差了不少。Show-o 的最大优点是需要的图像训练数据远远少于其他模型。

总结与讨论
此前多模态模型都只是强行把图像变成离散图像词元,再用标准自回归来生成图像词元。为了改进这些多模态模型,无独有偶,Transfusion 和 Show-o 都用到了更先进的图像生成技术。Show-o 将标准自回归改成了更强大的掩码自回归,而 Transfusion 激进地引入了完整的图像扩散模型,并把文本生成和图像生成当成两个相对独立的任务。二者的相同之处如下:
两个多模态模型都用同一个 Transformer 来处理文本和图像。
两个模型的 Transformer 都使用了同样的交叉注意力机制。文本词元只能看到此前的图像、文本词元,而图像词元可以看到此前的文本词元和当前所有图像词元。
二者的不同之处在于:
- Transfusion 使用标准扩散模型实现图像生成,而 Show-o 使用掩码自回归实现图像生成。Show-o 强行将自己的图像生成模型称为「离散扩散模型」,有借扩散模型的名头宣传之嫌。
- Transfusion 没有用特殊词元来区分不同任务。要用 Transfusion 编辑图像,需要在基础模型上用图像编辑数据集微调。Show-o 用特殊词元来区分不同任务,默认支持文本理解、图像生成、图像编辑、多模态生成等多种任务。
- 二者在文本、图像指标上都超越了之前的多模态模型。但二者相互对比之下,Transfusion 的表现更好,而 Show-o 需要的训练资源少得多。
我再来谈一下我看完这两篇文章后的一些感想。此前我对多模态模型很不感兴趣,觉得它们就是在语言模型的基础上,强行加入图像信息,然后加数据、加显卡,大火乱炖,没有太大的创新。而 Transfusion 和 Show-o 的设计令我眼前一亮。我觉得这两篇文章的结果再次表明,图像和文本的处理方法不应该是一致的,不能强行把文本自回归那套方法直接搬到图像任务上。不管是换成 MaskGIT 掩码自回归那一套,还是完全用扩散模型,都比之前的方法要好。
而究竟是掩码自回归好还是扩散模型更好呢?在我看来,扩散模型是更好的。文本是离散的,而图像是连续的。这种连续性不仅体现在图像的颜色值上,还体现在图像像素间的位置关系上。强行用 Transformer 自回归生成图像,一下子把这两种连续信息都破坏了。而何恺明团队近期的 MAR 工作则试图找回图像在颜色值上的连续性,但依然无法充分利用空间上的连续性。相比之下,扩散模型每步迭代都是对整幅图像做操作,不会破坏图像的连续性。这两个多模态工作也反映了这一点,Transfusion 的表现要比 Show-o 好很多。
在生成图像时,Transfusion 的行为几乎和 SD 3, FLUX.1 这些文生图模型一样了。两类模型的区别在于,SD 3 它们得用一个预训练的语言处理模型。而 Transfusion 用同一个 Transformer 来处理文本、图像信息。尽管现在 Transfusion 还没有超过 SD 3,但我认为文生图任务本质上是一个多模态任务,这两类模型的后续发展路线很可能会交汇到一起。文生图也应该从多模态中汲取经验。比如我们在 SD 3 的基础上,加入一些语言任务上的学习,说不定能进一步提升文生图时的图文匹配度。
当然,仅根据我读完这两篇文章后有限的认知,我认为多模态并不是一个值得广大科研人员投入的研究方向,而只适合有足够资源的大公司来做。其根本原因是验证多模态设计的代价太大了。在图像生成领域,要验证一个生成模型好不好,我们拿 ImageNet,甚至拿只有几万张图像的人类数据集训练及评测,都很有说服力。而多模态任务必须在大量文本、图像数据集上训练,评测文本、图像上的多种指标,小一点的团队根本做不来。这样,各种小创新都难以验证。而没有各种各样的小创新,领域也就很难快速发展。所以多模态只能不断从纯语言生成、纯图像生成方向找灵感,很难有仅属于多模态任务的创新。
#PointRWKV
3D点云学习新架构!刷新点云表征学习性能及FLOPs!
本文提出了一种基于RWKV的算法,该算法可以在极小的线性复杂度和参数量上达到较高的效率,并且能够处理多尺度的点云输入。
Transformer彻底改变了点云学习任务,但其二次复杂度阻碍了其向长序列的扩展,这给有限的计算资源带来了负担。最近出现的 RWKV 是一种新型的深度序列模型,在 NLP 任务中显示出序列建模的巨大潜力。在这项工作中提出了PointRWKV,这是一种线性复杂度的新模型,具有 3D 点云学习任务所需的适应性。通过对不同点云学习任务的大量实验表明,所提出的 PointRWKV 优于基于 transformer 和 mamba 的同类网络,同时显著节省了约 42% 的 FLOPs,展示了构建基础3D点云表征学习模型的优越性。
论文:https://arxiv.org/abs/2405.15214
主页:hithqd.github.io/projects/PointRWKV/
代码:https://github.com/hithqd/PointRWKV
背景
3D 点云分析是众多现实应用的基础,包括自动驾驶、虚拟现实和机器人技术等。与 2D 图像不同,点云的内在不规则性和稀疏性使得进行准确的点云特征学习成为一项具有挑战性的任务。并且同时平衡准确性和复杂性仍然是一个持久的问题。现有的点云特征学习方法主要是基于自注意力结构(Transformer)或者是线性时间序列结构(Mamba)的,如下图所示。然而,基于自注意力结构的算法对扩展点标记进行全面注意力机制的部署会显著增加对计算资源的需求,这种效应直接归因于注意力计算中固有的二次复杂性,影响了计算和内存。而基于线性时间序列结构的算法尽管有效,但原始的单向建模的固有属性阻碍了它们达到卓越的性能。本文提出了一种基于RWKV的算法,该算法可以在极小的线性复杂度和参数量上达到较高的效率,并且能够处理多尺度的点云输入。

方法

PointRWKV 的整体流程如上图所示,其中通过分层网络架构对点云进行编码。给定一个输入点云,首先采用多尺度掩蔽策略在不同尺度上对不同点数进行采样。然后应用轻量级 PointNet来嵌入点并生成embedding嵌入。这些点标记由块堆叠编码器(即 PRWKV 块)使用,其中每个块由两个并行分支组成,用于分层局部和全局特征聚合。每个PRWKV块,采用两个并行分支的处理策略来聚合局部和全局特征。上面的是综合特征调制流程,具有空间混合和通道混合,下面的是基于局部图的合并。最后,两个分支的连接用作每个块的输出。
Integrative Feature Modulation (IFM)
综合特征调制分支由空间混合模块和通道混合模块组成。空间混合模块作为一种注意力机制,执行线性复杂度的全局注意力计算,而通道混合模块则作为前馈网络(FFN)运行,促进沿通道维度的特征融合。
空间混合模块:经过一个前置的LayerNorm 之后,输入特征的token 首先通过双向二次展开 (BQE) 函数进行移位,然后输入到四个并行的线性层中,以获得多头向量:

其中,BQE的计算为:

BQE函数使注意力机制能够在不同通道上自然地关注相邻的token,而无需显著增加FLOPs。这一过程还扩展了每个token的感受野,从而显著提升了标记在后续层中的覆盖范围。此外,通过以下公式计算出一个新的时变衰减w:

然后,将K_S和V_S传递以使用新的衰减参数w计算全局注意力结果wkv。在这里,我们引入了具有线性复杂度的双向注意力机制,并进行了两项修改:(1)衰减参数独立变化,以动态方式依赖于数据,(2)在求和公式中,将原始RWKV注意力的上限从当前标记t扩展到最后一个标记T-1,以确保在每个结果的计算中所有标记都是相互可见的。对于第t个标记,注意力结果通过以下公式计算:

最终的概率输出为:

通道混合模块:来自空间混合模块的token进一步传递到通道混合模块。同样地,使用前置的LayerNorm,并在BQE操作后获得R_C和K_C:

之后,分别执行线性投影和门机制。最终输出的公式如下:

Local Graph-based Merging (LGM)
局部几何特征已被证明对点云特征学习至关重要,但RWKV结构的全局感受野无法全面捕捉局部点几何,限制了其学习细粒度特征的能力。因此我们将点云直接编码为图,使用点作为图的顶点。图的边连接在设定半径内的相邻点,允许这些点之间传递特征信息。这种图表示可以适应点云的结构,而无需对其进行规则化。此外,为了最小化局部图中的平移方差,引入了图稳定器机制。该机制允许点根据其独特特征对齐其坐标,从而提高网络的整体有效性。
通常,我们可以通过在图神经网络中沿着边聚合特征来优化顶点特征。在点云的场景中,我们旨在包含顶点所属对象的局部信息。因此,在第 (t + 1) 次迭代中,我们使用邻居的相对坐标进行边特征提取,这可以表示为:

为了减少这种平移方差,本文进一步提出基于结构特征对邻近坐标进行对齐,而不是依赖中心顶点的坐标。由于中心顶点已经包含了上一迭代中的一些结构特征,它可以用来估计对齐偏移,这促使本文设计了一个图稳定器机制。上述公式可以重写为:

实验结果

如上图所示,在 ShapeNet上进行自监督预训练后,PointRWKV 在 ScanObjectNN上实现了 93.63% (+4.66%) 的整体准确率,在 ModelNet40上实现了 96.89% (+1.79%) 的分类准确率,在 ShapeNetPart上实现了 90.26% (+3.16%) 的实例 mIoU,在预训练模型中创下了新的最先进 (SoTA)。同时,与基于 transformer 和 mamba 的同类工作相比,PointRWKV 的参数减少了 13%,FLOP 减少了 42%,展示了 RWKV 在 3D 视觉任务中的潜力。
3D点云分类

Few-shot分类

Part Segmentation

总结
在本文中,我们介绍了一种基于 RWKV 的新型点云学习架构 PointRWKV。PointRWKV 采用分层架构,通过对多尺度点云进行编码来学习生成强大的 3D 表示。为了促进局部和全局特征聚合,我们设计了并行特征合并策略。实验结果表明,PointRWKV 在不同的点云学习数据集上表现出优于基于 transformer 和 mamba 的同类工作的性能,同时显著减少了参数和 FLOP。凭借其线性复杂性能力,我们希望 PointRWKV 将成为更多 3D 任务的高效且经济高效的基准。
#RMoK
KAN专家混合模型在高性能时间序列预测中的应用:RMoK模型架构探析与Python代码实验
这篇文章探讨了可逆KAN混合模型(RMoK)在时间序列预测中的应用,RMoK结合了不同类型的KAN专家层来捕捉时间序列数据的多种特征。通过在电力变压器数据集上的实验,RMoK模型显示出在长期预测任务中与其他先进模型相比具有竞争力的性能。
Kolmogorov-Arnold网络(KAN)的提出为深度学习领域带来了重要突破,它作为多层感知器(MLP)的一种替代方案,展现了新的可能性。MLP作为众多深度学习模型的基础构件,包括目前最先进的预测方法如N-BEATS、NHiTS和TSMixer,已经在各个领域得到广泛应用。
但是我们在使用KAN、MLP、NHiTS和NBEATS进行的预测基准测试中发现,KAN在各种预测任务中表现出较低的效率和准确性。这项基准测试使用了M3和M4数据集,涵盖了超过99,000个独特的时间序列,频率范围从每小时到每年不等。这些结果表明,KAN在时间序列预测领域的应用前景并不乐观。
近期,随着论文《KAN4TSF: KAN和基于KAN的模型对时间序列预测有效吗?》中引入的可逆KAN混合模型(Reversible Mixture of KAN, RMoK)号称能够提高KAN的性能。本文将深入探讨RMoK模型的架构和内部机制,并通过Python实现一个小型实验来验证其性能。
为了全面理解本研究,建议读者参考原始论文以获取更详细的信息(本文最后的参考附带所有内容链接)。
KAN模型回顾
在深入RMoK架构之前,我们首先回顾KAN的基本原理和工作机制。
图1MLP与KAN的比较:MLP在连接上具有可学习的权重,节点上有固定的激活函数。KAN在连接上使用可学习的激活函数,节点执行求和操作。
上图展示了MLP和KAN的核心差异。在MLP中连接代表可学习的权重,节点是固定的激活函数(如ReLU、tanh等)。而KAN采用了不同的方法,在连接上使用可学习的激活函数,节点则执行这些函数的求和操作。
这种设计体现了Kolmogorov-Arnold表示定理,该定理指出多元函数可以通过单变量函数的组合来表示。具体而言,KAN使用B样条作为可学习函数来模拟非线性数据,如图2所示。这种方法为模型提供了极大的灵活性,使其能够学习复杂的非线性关系。
图2:三次样条拟合非线性数据示例。
尽管样条函数具有很强的灵活性,研究人员仍然提出了多种KAN变体,以进一步扩展其应用范围和提高性能。其中,Wav-KAN、JacobiKAN和TaylorKAN是RMoK模型中采用的三种重要变体。
Wav-KAN
Wav-KAN使用小波函数代替样条函数。小波函数在处理信号(如时间序列)时特别有效,因为它们能同时提取频率和位置信息。
图3:使用Ricker小波(又称墨西哥帽小波)对信号进行变换的示例。
图3展示了Ricker小波如何将输入信号转换。下图中的振荡变化反映了原始信号的特征,而在-2.5和2.5标记附近的深色区域则表示原始信号的突变。这种特性使Wav-KAN特别适合处理时间序列数据,能够有效捕捉位置和频率的变化。
JacobiKAN和TaylorKAN
除了样条函数,雅可比多项式和泰勒多项式也是常用的函数近似方法,分别导致了JacobiKAN和TaylorKAN的开发。
TaylorKAN
泰勒多项式是函数在展开点处导数的无限和的近似。展开点是函数和其近似的导数相等的位置。
图4:使用泰勒多项式近似sin(x)函数。随着多项式阶数增加,近似效果逐渐改善。
图4展示了使用不同阶数的泰勒多项式对sin(x)函数的近似,其中π/2是展开点。可以观察到,随着阶数增加,近似效果显著提升。然而,值得注意的是,当远离展开点时,近似效果会迅速下降。
JacobiKAN
雅可比多项式形成一个函数基,可以组合使用来近似更复杂的函数,类似于B样条的作用。
图5:使用雅可比多项式近似sin(x)函数。同样,随着多项式阶数增加,近似效果不断改善。
图5再次展示了对sin(x)函数的近似,这次使用雅可比多项式。与泰勒多项式相比,雅可比多项式在整个函数域内提供了更均衡的近似效果。
雅可比多项式更适合全局近似,其误差通常均匀分布。相比之下,泰勒多项式更适合局部近似。
综上所述,我们可以看到,将Wav-KAN用于信号处理,JacobiKAN用于准确的全局近似,以及TaylorKAN用于局部近似相结合,有可能在学习时间序列数据的复杂关系方面取得显著成效。这正是RMoK模型的核心思想。
RMoK模型架构解析
可逆KAN混合模型(Reversible Mixture of KAN, RMoK)是一种结构简洁而高效的模型,它巧妙地将门控网络与由不同专家KAN层组成的单一"KAN混合"层相结合。图6详细展示了RMoK的完整架构。
图6:RMoK模型架构示意图。
从图6中我们可以看到,RMoK模型采用了RevIN(Reversible Instance Normalization,可逆实例归一化)技术。RevIN是一种先进的预处理方法,专门用于处理非平稳时间序列数据,它显著提高了预测模型的性能。
数据流和处理流程
RMoK模型中的数据处理流程如下:
数据输入:时间序列数据从模型顶部输入。
RevIN处理:数据首先通过RevIN进行归一化处理。
KAN混合层:归一化后的数据进入KAN混合(MoK)层。
预测生成:MoK层输出经过反归一化处理,得到最终预测结果。
KAN混合(MoK)层
MoK层是RMoK模型的核心组件,它由以下部分组成:
- 门控网络:负责为数据的不同部分激活适当的专家层。
- 专家KAN层:包括Wav-KAN、JacobiKAN和TaylorKAN,每种专家层专注于捕捉时间序列数据的特定特征:
- Wav-KAN:专门学习频率和位置特征
- JacobiKAN:擅长捕捉长期变化
- TaylorKAN:专注于局部短期变化的学习
门控网络的作用是动态地决定在处理数据的不同部分时应该激活哪些专家层。这种机制使得模型能够灵活地应对时间序列中的各种模式和变化。
预测生成过程
在MoK层中,每个专家层独立生成预测,然后这些预测被组合起来形成一个综合预测。这个过程发生在归一化的数据空间中。综合预测通过反归一化处理,得到最终的时间序列预测结果。
RMoK的优势
RMoK模型的设计理念虽然简洁,但其效果却非常显著。它的主要优势在于:
- 灵活性:通过组合不同的KAN专家层,模型能够适应各种复杂的时间序列模式。
- 精确性:每个专家层都专注于特定类型的特征,使得模型能够全面且精确地捕捉时间序列的各个方面。
- 可解释性:模型的分层结构和专家机制提高了预测结果的可解释性。
RMoK模型的核心创新在于为时间序列预测任务选择了合适的"专家"组合。Wav-KAN处理信号特征,JacobiKAN负责全局趋势,而TaylorKAN则关注局部变化,这种组合使得模型能够全面地分析和预测复杂的时间序列数据。
通过深入理解RMoK模型的架构和工作原理,我们可以更好地认识其在时间序列预测任务中的潜力。接下来将通过一个Python实验来实际验证RMoK模型的性能。
实验设计与实施
为了验证RMoK模型的有效性,我们设计了一个对比实验,将RMoK模型与其他先进的时间序列预测模型(如PatchTST、iTransformer和TSMixer)进行性能比较。本实验聚焦于长期预测任务,使用了电力变压器数据集(ETT)作为基准。
数据集介绍
本实验采用的ETT数据集是记录了中国某省两个地区的电力变压器油温数据。数据集包含四个子集,分别以每小时和每15分钟的频率采样。我们的实验专注于使用两个15分钟采样频率的数据集(ETTm1和ETTm2)。
实验环境配置
为了简化实验流程并确保结果的可复现性,我们基于官方仓库的RMoK模型实现,扩展了neuralforecast库。这使我们能够以统一的方式使用和测试不同的预测模型。需要注意的是,在本文撰写时RMoK模型尚未被纳入neuralforecast的稳定版本。因此要复现实验结果,需要克隆特定的代码仓库分支。如果该分支已合并到主分支,可以通过以下命令安装:
pip install git+https://github.com/Nixtla/neuralforecast.git代码实现1、环境准备
首先导入必要的库和模块:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datasetsforecast.long\_horizon import LongHorizon
from neuralforecast.core import NeuralForecast
from neuralforecast.losses.pytorch import MAE, MSE
from neuralforecast.models import TSMixer, PatchTST, iTransformer, RMoK
from utilsforecast.losses import mae, mse
from utilsforecast.evaluation import evaluate2、数据加载函数
定义了一个辅助函数来加载数据集,并设置相应的实验参数:
def load\_data\(name\):
if name \== 'Ettm1':
Y\_df, \*\_ \= LongHorizon.load\(directory\='./', group\='ETTm1'\)
Y\_df\['ds'\] \= pd.to\_datetime\(Y\_df\['ds'\]\)
freq \= '15T'
h \= 96
val\_size \= 11520
test\_size \= 11520
elif name \== 'Ettm2':
Y\_df, \*\_ \= LongHorizon.load\(directory\='./', group\='ETTm2'\)
Y\_df\['ds'\] \= pd.to\_datetime\(Y\_df\['ds'\]\)
freq \= '15T'
h \= 96
val\_size \= 11520
test\_size \= 11520
return Y\_df, h, val\_size, test\_size, freq设置预测horizon为96个时间步,这相当于预测未来24小时的数据。
3、模型初始化和训练
为每个数据集初始化并训练模型:
DATASETS \= \['Ettm1', 'Ettm2'\]
for dataset in DATASETS:
Y\_df, horizon, val\_size, test\_size, freq \= load\_data\(dataset\)
rmok\_model \= RMoK\(input\_size\=horizon,
h\=horizon,
n\_series\=7,
num\_experts\=4,
dropout\=0.1,
revine\_affine\=True,
learning\_rate\=0.001,
scaler\_type\='identity',
max\_steps\=1000,
early\_stop\_patience\_steps\=5\)
\# 初始化其他模型...
models \= \[rmok\_model, patchtst\_model, iTransformer\_model, tsmixer\_model\]
nf \= NeuralForecast\(models\=models, freq\=freq\)
\# 使用交叉验证进行训练和预测
nf\_preds \= nf.cross\_validation\(df\=Y\_df, val\_size\=val\_size, test\_size\=test\_size, n\_windows\=None\)
nf\_preds \= nf\_preds.reset\_index\(\)
\# 保存预测结果
evaluation \= evaluate\(df\=nf\_preds, metrics\=\[mae, mse\], models\=\['RMoK', 'PatchTST', 'iTransformer', 'TSMixer'\]\)
evaluation.to\_csv\(f'\{dataset\}\_results.csv', index\=False, header\=True\)在RMoK模型中,使用了4个专家(Wav-KAN、JacobiKAN、TaylorKAN和一个简单的MLP)。学习率设置为0.001,最大训练步数为1000,早停值为5。
4、结果评估
使用平均绝对误差(MAE)和均方误差(MSE)来评估模型性能:
ettm1\_eval \= pd.read\_csv\('Ettm1\_results.csv'\)
ettm1\_eval \= ettm1\_eval.drop\(\['unique\_id'\], axis\=1\).groupby\('metric'\).mean\(\).reset\_index\(\)
ettm2\_eval \= pd.read\_csv\('Ettm2\_results.csv'\)
ettm2\_eval \= ettm2\_eval.drop\(\['unique\_id'\], axis\=1\).groupby\('metric'\).mean\(\).reset\_index\(\)实验结果与分析
表1总结了各模型在ETTm1和ETTm2数据集上的性能:
表1:不同模型在96时间步预测horizon上的性能指标。最佳结果以粗体显示。
可以观察到:
- 对于ETTm1数据集,RMoK模型在MSE指标上取得了最佳成绩。
- 在ETTm2数据集上,RMoK模型在MAE和MSE两个指标上都优于其他模型。
这些结果表明,RMoK模型在长期时间序列预测任务中展现出了强大的性能,能够与当前最先进的预测方法(如TSMixer和PatchTST)相媲美,甚至在某些情况下表现更优。
总结
本研究深入探讨了可逆KAN混合(RMoK)模型,这是一种将不同KAN专家层巧妙结合的创新模型,专门用于时间序列预测任务。RMoK模型的核心优势在于:
- 利用Wav-KAN提取频率和位置信息
- 通过JacobiKAN捕捉长期变化趋势
- 使用TaylorKAN精确建模局部短期变化
实验结果证实,将这些专家层作为混合专家系统组合使用,能够显著提升模型在预测任务中的表现。需要强调的是,本实验旨在展示如何在Python环境中实现和应用RMoK模型,而非提供一个全面的基准测试。尽管如此,实验结果仍然令人鼓舞,表明RMoK模型在实际应用中具有巨大潜力。
未来研究方向
- 在更多样化的数据集上进行全面的基准测试,以进一步验证RMoK模型的泛化能力。
- 探索RMoK模型在不同领域(如金融、气象学、生物信息学等)中的应用潜力。
- 研究如何进一步优化RMoK模型的架构,以提高其计算效率和预测准确度。
- 调研RMoK模型与其他先进技术(如注意力机制、图神经网络等)的结合可能性。
通过持续的研究和改进,相信RMoK模型将在时间序列预测领域发挥越来越重要的作用,为解决复杂的预测问题提供有力支持。
参考资料:
KAN4TSF: Are KAN and KAN-based models Effective for Time Series Forecasting
https://arxiv.org/pdf/2408.11306
KAN: Kolmogorov-Arnold Networks
https://arxiv.org/pdf/2404.19756
RMoK
https://github.com/2448845600/KAN4TSF
#SDM
第三代神经网络和扩散模型强强联合!FID最多超基线12倍,能耗省60%,实力SOTA!
本文介绍了一种新型的脉冲扩散模型(SDM),它结合了第三代神经网络和扩散模型的优势,在图像生成领域实现了显著的性能提升。SDM通过引入时间脉冲机制(TSM)和阈值引导策略,提高了去噪图像的质量,并在CIFAR-10数据集上的FID分数上超越了SNN基线模型多达12倍,同时节省了约60%的能耗。
论文链接:https://arxiv.org/pdf/2408.16467
代码链接:https://github.com/AndyCao1125/SDM
亮点直击
- 本文提出了脉冲扩散模型(Spiking Diffusion Model, SDM),一种高质量的图像生成器,在基于SNN的生成模型中实现了SOTA性能。
- 从生物学的角度出发,本文提出了一种时间脉冲机制(Temporal-wise Spiking Mechanism, TSM),使脉冲神经元能够捕捉更多的动态信息,从而提高去噪图像的质量。
- 大量结果显示,SDM在CIFAR-10数据集上的FID分数上超越了SNN基线模型多达12倍,同时节省了约60%的能耗。此外,本文提出了一种阈值引导策略,以进一步提高生成性能。
近年来,脉冲神经网络(Spiking Neural Networks, SNNs)因其超低能耗和高生物可塑性相比传统人工神经网络(Artificial Neural Networks, ANNs)而受到关注。尽管SNNs具有独特的优势,但其在计算密集型的图像生成领域的应用仍在探索之中。本文提出了脉冲扩散模型(Spiking Diffusion Models, SDMs),一种创新的基于SNN的生成模型家族,能够以显著降低的能耗生成高质量样本。特别地,本文提出了一种时间脉冲机制(Temporal-wise Spiking Mechanism, TSM),使SNNs能够从生物可塑性角度捕捉更多的时间特征。此外,本文提出了一种阈值引导策略,可以在不进行额外训练的情况下将性能提高多达16.7%。本文还首次尝试使用ANN-SNN方法进行基于SNN的生成任务。大量实验结果表明,本文的方法不仅在少量脉冲时间步中表现出与其ANN对应模型相当的性能,而且在很大程度上优于之前基于SNN的生成模型。此外,本文还展示了SDM在大规模数据集(例如LSUN卧室)上的高质量生成能力。这一发展标志着SNN基生成能力的一个重要进步,为未来实现低能耗和低延迟的生成应用开辟了新的研究途径。
方法A. 峰值前残差学习
本文首先分析了先前脉冲神经网络(SNNs)中的残差学习方法存在的局限性和概念不一致性,特别是SEW ResNet,其公式可以表示为:
其中, 表示在第 层经过批归一化(BN)和卷积操作后的输出, 表示在公式 (2) 中的脉冲神经元激活函数。这种残差结构直接继承自传统的人工神经网络(ANN)ResNet 架构。然而, 这种方法存在一个根本性的问题, 即残差块的输出范围问题。问题的核心在于脉冲神经元的输出 和 是二进制脉冲序列, 取值在集合 中。因此, 当这些序列在残差结构 中相加时, 结果的输出范围扩展到 。在这种情况下, 值 的出现是非生物学的, 代表了与合理的神经激活模式的偏离。这种溢出情况不仅削弱了模型的生物真实性, 还可能在前向传播过程中破坏信息的有效传递。
受 [61], [62] 的启发,本文在本文的脉冲UNet中采用了激活-卷积-批量归一化(Activation-Conv-BatchNorm)结构的预脉冲残差学习方法,解决了基于卷积的SNNs中梯度爆炸/消失和性能下降的双重挑战。通过预脉冲块,残差和输出通过浮点加法操作进行求和,确保在进入下一个脉冲神经元之前表示是准确的,同时避免了上述病态情况。整个预脉冲残差学习过程在一个残差块内可以表示如下:
通过预脉冲残差机制, 残差块的输出可以通过两个浮点数 和 在相同尺度上进行求和, 然后进入下一个块的脉冲神经元, 这确保了能量消耗仍然非常低。
B. 时间明智的峰值机制
首先从生物学角度重新审视了传统脉冲神经网络(SNNs)的不足, 并提出了一种新的时间脉冲机制(TSM), 通过引入时间参数来调整权重, 以捕捉时间动态。考虑在第 层的脉冲输入为 ,其中 表示小批量大小。对于每个时间步 ,神经元将通过方程(1)更新其暂时的膜电位, 其中 , 而 表示第 卷积层的权重矩阵。传统的SNNs会在进行膜电位更新时将输入的时间维度 和通道维度 融合为 , 然后通过二维卷积操作计算。这导致每个时间步的输入都由相同的权重矩阵操作。然而, 在真实的神经系统中, 皮质锥体细胞在常规网络活动中会接收到强烈的兴奋性和抑制性突触后电位。此外, 不同的觉醒状态可以改变膜电位并影响突触整合。这些研究共同表明, 每一时刻的神经元输入由于网络状态和其他因素的影响而经历了显著的波动, 而不是主要由固定的突触权重控制。
为了在时间上提供更多的动态信息, 本文提出了时间脉冲机制(TSM, 见下图3), 这保证了每一时刻的输入信息都通过与时间步 相关的时间参数 进行计算:

在下面算法1中精确描述了SDMs的整个学习过程。具体来说, 学习流程包括:(1)训练阶段和(2)微调阶段。在训练阶段, 本文首先使用预脉冲块训练SDMs, 然后在微调阶段利用TSM块对模型进行微调。本文仅使用少量迭代(如果 训练迭代次数)来微调本文的模型。值得注意的是, 由于 只是一个标量, TSM引起的额外计算成本可以忽略不计。通过计算 , 本文可以进一步优化 和 的参数, 以获得令人满意的网络。SNN-UNet和 的详细学习规则可以在附录中找到。
总而言之,TSM允许膜电位在时间域内动态更新,从而提高捕捉潜在时间依赖特征的能力。后续实验表明,TSM机制优于传统的固定更新机制。
C. SDM 中的阈值指导
如前文所述, 可以通过将得分 替换为得分网络 或缩放噪声网络 来实现采样, 同时按照方程(5)离散化反向SDE。由于网络估计的不准确性, 本文有 在大多数情况下。因此, 为了获得更好的采样结果, 本文可以离散化以下修正后的反向SDE:

这里, 表示得分网络或缩放噪声网络, 而 表示原始反向SDE的修正项。省略修正项 会导致离散化误差减少, 并提高采样性能。然而, 由于 的难以计算, 实际计算存在挑战。
鉴于存在估计误差, 方程(17)促使本文研究是否可以在无需额外训练的情况下, 通过计算 来提升采样性能。SNN 中的一个关键参数是脉冲阈值, 记为 , 它直接影响 SNN 的输出。例如, 较小的阈值会鼓励更多的脉冲发生, 而较大的阈值会抑制这些脉冲。在训练过程之后, 本文可以在 SNN 中调整阈值, 以估计修正项 , 具体如下:
在训练阶段使用的阈值记为 , 而在推理阶段调整后的阈值记为 。通过泰勒展开可以得到第一个方程。方程 (18) 表明, 当导数项与修正项相关时, 调整阈值可以提升最终的采样结果。本文将阈值降低的情况称为抑制性引导, 反之称为兴奋性引导。
理论能耗计算
在本节中,本文描述了计算脉冲UNet架构理论能耗的方法。该计算包括两个主要步骤:确定架构中每个模块的突触操作(SOPs),然后基于这些操作估算整体能耗。脉冲UNet每个模块的突触操作可以如下量化:
![]()
其中, 表示脉冲 UNet中的模块编号, 是该模块输入脉冲序列的发放率, 是脉冲神经元的时间步长。 指的是第 个模块的浮点运算次数, 即乘加(MAC)操作的次数。而SOPs 是基于脉冲的累加(AC)操作的次数。
为了估算脉冲扩散模型的理论能耗, 本文假设MAC和AC操作是在 45 nm 硬件上实现的, 其能耗分别为 和 。根据 [65], [66], 脉冲扩散模型的理论能耗计算如下:
其中, 和 分别表示卷积层(Conv)和全连接层(FC)的总层数。
和 分别是每次 MAC 和 AC 操作的能耗。FLOPSNNConv 指的是第一个卷积层的浮点运算次数, SOPSNNConv 和 SOPSNNFC 分别是第 个卷积层和第 个全连接层的突触操作次数。
通过 ANN-SNN 转换实施尖峰扩散模型
在本文中,本文首次利用ANN-SNN方法成功实现了SNN扩散。本文采用了Fast-SNN方法来构建量化ANN与SNN之间的转换。由于这一实现并不是本文论文的主要贡献,本文将简要描述ANN-SNN的原理,更多细节可以在[67]中找到。
从ANN转换为SNN的核心思想是将量化ANN的整数激活映射为脉冲计数, 即将 转换为脉冲计数 , 即将 转换为 。构建具有整数激活的量化 ANN自然等同于使用输出均匀分布值的量化函数来压缩激活。这种函数将ANN中具有ReLU激活函数的神经元 i 在第1层的全精度激活 进行空间离散化, 公式如下:

其中, 表示空间量化值, 表示位数(精度), 状态数为 表示四舍五入操作符, 表示剪切阈值, 决定输入 的剪切范围, 是一个剪切操作符, 将 限制在 范围内。
在SNN中, 脉冲积分发放 (IF) 神经元本质上将膜电位 量化为一个由发放率 表示的量化值

其中, 表示基于脉冲的量化值, floor 表示向下取整操作符。假设膜电位的值总是满足为输入电流值的 倍: 。将公式 (22) 与公式 (21) 进行比较, 本文令 , 。由于向下取整操作符可以转换为四舍五入操作符:

通过将下一层的权重缩放到,本文将公式 (22) 重写为以下公式:

因此, 通过建立离散ReLU值与脉冲发放率 (见公式24) 的等价关系, 本文在量化的人工神经网络(ANN)与脉冲神经网络(SNN)之间架起了一座桥梁。需要注意的是, 的假设仅在直接接收电流作为输入的第一个脉冲层中成立。然而, 随着网络的加深, 膜电位与输入电流之间的相互作用变得越来越复杂, 偏离了简单的线性关系。这种复杂性是ANN-SNN转换过程中误差逐渐积累的根本原因之一。
实验A. 实验设置数据集和评估指标
为了展示所提算法的有效性和效率,本文在以下数据集上进行实验:32×32 MNIST、32×32 FashionMNIST 、32×32 CIFAR-10和 64×64 CelebA。定性结果根据Frechet Inception Distance(FID,越低越好)和Inception Score(IS,越高越好)进行比较。FID分数是通过比较50,000张生成图像与数据集的相应参考统计数据来计算的。
实现细节
对于直接训练方法, 本文的Spiking UNet继承了标准的UNet架构, 且不使用注意力块。在超参数设置方面, 本文将公式 (1) 中的衰减率 设置为 1.0 , 脉冲阈值 设置为 1.0 。SNN 的仿真时间步长为 。学习率设置为 , 批量大小为 128 , 并且本文在没有使用指数移动平均 (EMA) 的情况下训练模型。ANN UNet同样不使用注意力块, 其训练过程与SNN-UNet—致。对于ANN-SNN方法, 本文采用与Fast-SNN相同的实现, 但不使用signed-IF神经元, 因为该神经元在扩散任务中起负面作用。更多的超参数设置细节可以在附录中找到。
B. 与最先进的方法比较
在下表 I 中,本文展示了本文的脉冲扩散模型(SDMs)与当前最先进的生成模型在无条件生成任务中的比较分析。本文还包括了ANN的结果作为参考。定性结果展示在下图4中。本文的结果表明,SDMs在所有数据集上均显著优于SNN基线,即使在较少的脉冲仿真步数(4/8)下也是如此。特别是,SDDPM在CelebA数据集上相比FSVAE和SGAD(两者均为16个时间步)分别有4倍和6倍的FID提升,而在CIFAR-10数据集上则有11倍和12倍的提升。正如预期的那样,随着时间步的增加,样本质量也会提高。本文还注意到,结合TSM后,性能进一步提升,而模型参数仅有微小增加(2e-4 M)。SDMs还可以处理快速采样求解器,并在较少的步骤中获得更高的采样质量(见下表VI)。重要的是,SDMs在使用相同的UNet架构下获得了与ANN基线相当的质量,甚至超过了一些ANN模型(例如,15.45 vs. 19.04)。这一结果突显了本文模型中使用的SNN的卓越表达能力。
C. 与 ANN-SNN 方法的比较
为了验证SDM在ANN-SNN方法下的生成能力,本文在32×32 CIFAR-10和64×64 FFHQ数据集上进行了实验。如下表II所示,ANN-SNN方法在CIFAR-10上表现出色(即51.18 FID),并且在微调策略后显著提高了图像质量(即29.53 FID)。然而,ANN-SNN的结果与直接训练的结果之间仍存在差距。尽管ANN-SNN方法在基于分类的任务中表现出与ANN相当的性能,但在生成任务方面仍缺乏深入的研究。ANN-SNN方法的定性结果展示在下图7中。
D. 时间性尖峰机制的有效性
为了更好地可视化TSM模块带来的性能提升,本文提供了使用SDDIM生成的CIFAR-10图像结果,分别展示了有和没有TSM模块的情况。这里本文使用DDIM而不是DDPM进行比较,因为DDIM基于常微分方程(ODEs)操作,确保了确定性和一致的生成结果。相比之下,DDPM依赖于随机微分方程(SDEs),在生成过程中引入了随机性,导致输出图像的可变性,从而使直接比较变得具有挑战性。
下图5中的结果显示,带有TSM模块的生成图像质量有显著提高。与没有TSM模块的图像相比,这些图像的轮廓更加清晰,背景更为清晰,纹理细节更丰富,从而证明了TSM的有效性。
E. 阈值指导的有效性
在前文中,本文提出了一种无需训练的方法:阈值引导(Threshold Guidance,TG),旨在通过在推理阶段仅略微调整脉冲神经元的阈值水平来提高生成图像的质量。如下表III所示,通过阈值调整进行抑制性引导显著提升了图像质量,在两个关键指标上都有所改善:FID分数从19.73下降到19.20,阈值减少0.3%;IS分数从7.44上升到7.55,阈值减少0.2%。相反,在某些条件下,兴奋性引导同样可以提高采样质量。这些发现强调了阈值引导作为一种在训练后显著提高模型效果的方法的潜力,而无需额外的训练资源。本文在附录中提供了更多关于阈值引导的解释。
F. TSM方法分析
为了评估前文中提出的时间脉冲机制(Temporal-wise Spiking Mechanism,TSM)的效果,本文计算了所有层的时间参数的平均值。如图6所示,每个实例都展示了不同的TSM值,这强调了每个时间步的重要性是独特的。本文注意到,随着时间步数的增加,的变化趋势呈现出递增的模式,这表明在传输过程中,后期阶段传递的信息具有更大的重要性。因此,TSM值可以作为时间调整因子,使SNN能够理解和融合时间动态,从而提高生成图像的质量。
G. 计算成本评估
为了进一步强调本文SDM的低能耗特性,本文对比分析了所提出的SDDPM与其对应的ANN模型在FID和能耗方面的表现。如表IV所示,当时间步长设定为4时,SDDPM的能耗显著降低,仅为其ANN对应模型的37.5%。此外,SDDPM的FID也提高了0.47,表明本文的模型在有效减少能耗的同时保持了竞争力的性能。当本文将分析扩展到不同的时间步长增量时,可以观察到一个明显的模式:随着时间步长的增加,FID分数有所改善,但代价是能耗的增加。这一观察结果表明,随着时间步长的增加,FID改善与能耗之间存在权衡。
H. 消融研究不同组件对SDM的影响
本文首先在CIFAR-10数据集上进行消融研究,以探讨时间脉冲模块(TSM)和阈值引导(TG)的影响。如下表V所示,本文发现TSM和TG都对图像质量的提升有贡献。通过同时使用TSM和TG,本文获得了最佳的FID结果,相较于原始的SDDIM提升了18.4%。
SDM在不同求解器上的有效性
在下表VI中,本文验证了SDM在各种扩散求解器上的可行性和有效性。SDDIM在采样步骤上表现出更稳定的性能,而Analytic-SDPM展示了卓越的能力,达到了新的最先进性能,超越了ANN-DDIM的结果。总之,本文的SDM证明了其在处理任何扩散求解器方面的高效性,并且本文相信利用本文的SDM还有很大的潜力进一步提升FID性能。
讨论 & 结论
本研究提出了一种新的基于SNN的扩散模型家族,称为脉冲扩散模型(SDMs),它结合了SNN的能效优势和卓越的生成性能。SDMs在SNN基线中以更少的脉冲时间步长达到了最先进的结果,并且与ANNs相比,能耗更低。SDMs主要受益于两个方面:(1) 时间脉冲机制(TSM),它使去噪网络SNN-UNet的突触电流在每个时间步长中能够收集更多的动态信息,而不是像传统SNN那样由固定的突触权重控制;(2) 无需训练的阈值引导(TG),通过调整脉冲阈值进一步提高采样质量。
然而,本文工作的一个限制是SNN-UNet的时间步长相对较小,未能充分挖掘SDMs的全部潜力。此外,还应考虑在更高分辨率的数据集(如ImageNet)上进行测试。在未来的研究中,本文计划探索SDMs在生成领域的进一步应用,例如文本-图像生成,并尝试将其与先进的语言模型结合,以实现更有趣的任务。
#KAN干翻MLP
开创神经网络新范式!一个数十年前数学定理,竟被MIT华人学者复活了
KAN的诞生,开启了机器学习的新纪元!而这背后,竟是MIT华人科学家最先提出的实践想法。从KAN到KAN 2.0,这个替代MLP全新架构正在打开神经网络的黑盒,为下一步科学发现打开速通之门。
KAN的横空出世,彻底改变了神经网络研究范式!
神经网络是目前AI领域最强大的工具。当我们将其扩展到更大的数据集时,没有什么能够与之竞争。
圆周理论物理研究所研究员Sebastian Wetzel,对神经网络给予了高度的评价。
然而,万事万物并非「绝对存在」,神经网络一直有一个劣势。
其中一个基本组件——多层感知器(MLP),尽管立了大功,但这些建立在MLP之上的神经网络,却成为了「黑盒」。
因为,人们根本无法解释,其中运作的原理。

为此,AI界的研究人员们一直在想,是否存在不同类型的神经网络,能够以更透明的方式,同样输出可靠的结果?
是的,的确存在。
2024年4月,MIT、加州理工等机构研究人员联手提出,新一代神经网络架构——Kolmogorov-Arnold network(KAN)。
它的出现,解决了以上的「黑盒」问题。
论文地址:https://arxiv.org/pdf/2404.19756
比起MLP,KAN架构更加透明,而且几乎可以完成普通神经网络,在处理某类问题时的所有工作。
值得一提的是,它的诞生源于上个世纪中期一个数学思想。
数学家Andrey Kolmogorov和Vladimir Arnold
这个已经埋了30多年的数学原理,如今在DL时代被这位华人科学家和团队重新发现,再次发光发亮。
虽然,这项创新仅仅诞生了5个月的时间,但KAN已经在研究和编码社区,掀起了巨浪。
约翰霍普金斯大学计算机教授Alan Yuille赞扬道,KAN更易于解释,可以从数据中提取科学规则,因此在科学领域中有着极大的应用」。
让不可能,成为可能
典型的神经网络工作原理是这样的:
一层层人工神经元/节点,通过人工突触/边,进行连接。信息经过每一层,经过处理后再传输到下一层,直到最终将其输出。
对边进行加权,权重较大的边,比其他边有更大的影响。
在所谓的训练期间,这些权重会不断调整,最终使得神经网络输出越来越接近正确答案。
神经网络的一个常见的目标是,找到一种数学函数、曲线,以便最好地连接某些数据点。
它们越接近这个函数,预测的结果就越准确。
假设神经网络模拟了物理过程,理想情况下,输出函数将代表描述该物理过程的方程,相当于物理定律。
对于MLP来说,会有一个数学定理,告诉你神经网络能多接近最佳可能函数。
这个定理表明,MLP无法完美地表示这个函数。
不过,在恰当的情况下,KAN却可以做到。
KAN以一种不同于MLP的方式,进行函数拟合,将神经网络输出的点连接起来。
它不依赖于带有数值权重的边,而是使用函数。
同时,KAN的边函数是非线性和可学习的,这使得它们比MLP更灵活、敏感。
然而,在过去的35年里,KAN被认为在实际应用中,切不可行。
1989年,由MIT物理学家转计算机神经科学家Tomaso Poggio,共同撰写的一篇论文中明确指出:
KAN核心的数学思想,在学习神经网络的背景下是无关紧要的。
Poggio的一个担忧,可以追溯到KAN核心的数学概念。
论文地址:http://cbcl.mit.edu/people/poggio/journals/girosi-poggio-NeuralComputation-1989.pdf
1957年,数学家Andrey Kolmogorov和Vladimir Arnold在各自但相互补充的论文中证明——如果你有一个使用多个变量的单一数学函数,你可以把它转换成多个函数的组合,每个函数都有一个变量。
然而,这里有个一个重要的问题。
这个定理产生的单个变量函数,可能是「不平滑的」,意味着它们可能产生尖锐的边缘,就像V字的顶点。
这对于任何试图使用这个定理,重建多变量函数的神经网络来说,都是一个问题所在。
因为这些更简单的单变量部分,需要是平滑的,这样它们才能在训练过程中,学会正确地调增匹配目标值。
因此,KAN的前景一直以来黯淡无光
MIT华人科学家,重新发现KAN
直到去年1月,MIT物理学研究生Ziming Liu,决定重新探讨这个话题。
他和导师Max Tegmark,一直致力于让神经网络在科学应用中,更加容易被人理解,能够让人们窥探到黑匣子的内部。
然而,这件事一直迟迟未取得进展。
可以说,在这种「走投无路」的情况下,Liu决定在KAN上孤勇一试。
导师却在这时,泼了一盆冷水,因为他对Poggio论文观点太过熟悉,并坚持认为这一努力会是一个死胡同。
不过,Ziming Liu却没有被吓到,他不想在没有先试一下的情况下,放弃这个想法。
随后,Tegmark也慢慢改变了自己的想法。
他们突然认识到,即使由该定理产生的单值函数,是不平滑的,但神经网络仍可以用平滑的函数逼近数值。
Liu似乎有一种直觉,认定了KAN便是那个拯救者。
因为自Poggio发表论文,已经过了35年,当下的软件和硬件取得了巨大的进步。
在2024年,就计算来讲,让许多事情成为可能。
大约肝了一周左右的时间,Liu深入研究了这一想法。在此期间,他开发了一些原型KAN系统,所有系统都有两层。
因为Kolmogorov-Arnold定理本质上为这种结构提供了蓝图。这一定理,明确地将多变量函数分解为,不同的内部函数和外部函数集。
这样的排列,使其本身就具备内层和外层神经元的两层架构。
但令Liu沮丧的是,所设计的原型KAN并没有在科学相关任务上,表现地更好。
导师Tegmark随后提出了一个关键的建议:为什么不尝试两层以上的KAN架构,或许能够处理更加复杂的任务?
一语点醒梦中人。
这个开创性的想法,便成为他们突破的关键点。
这个羽翼未丰的原型架构,为他们带来了希望。很快,他们便联系了MIT、加州理工、东北大学的同事,希望团队能有数学家,并计划让KAN分析的领域的专家。
实践证明,在4月份论文中,小组团证明了三层KAN,确实是可行的。
他们给出了一个示例,三层KAN可以准确地表示一个函数,而两层KAN却不能。
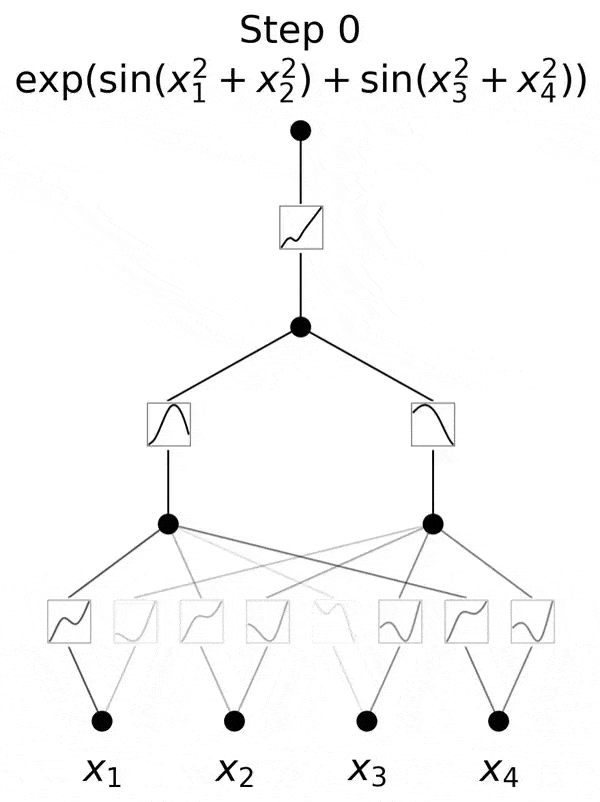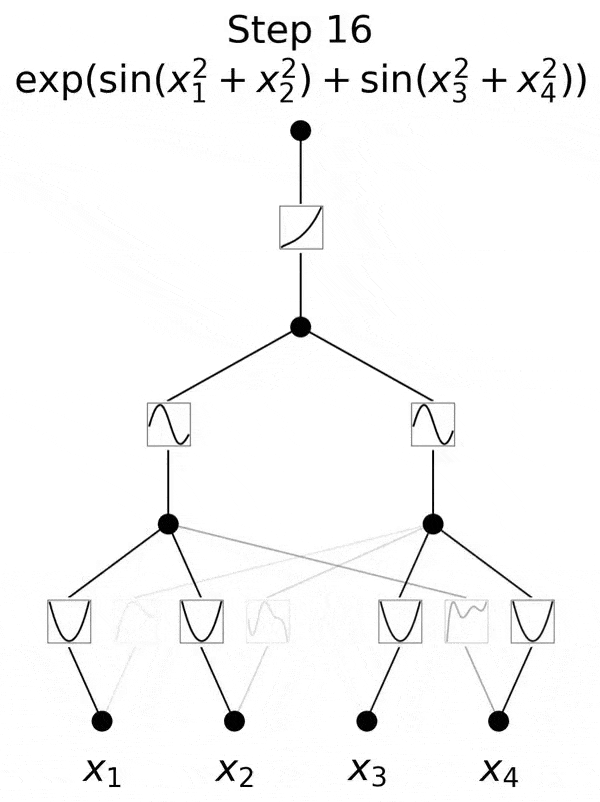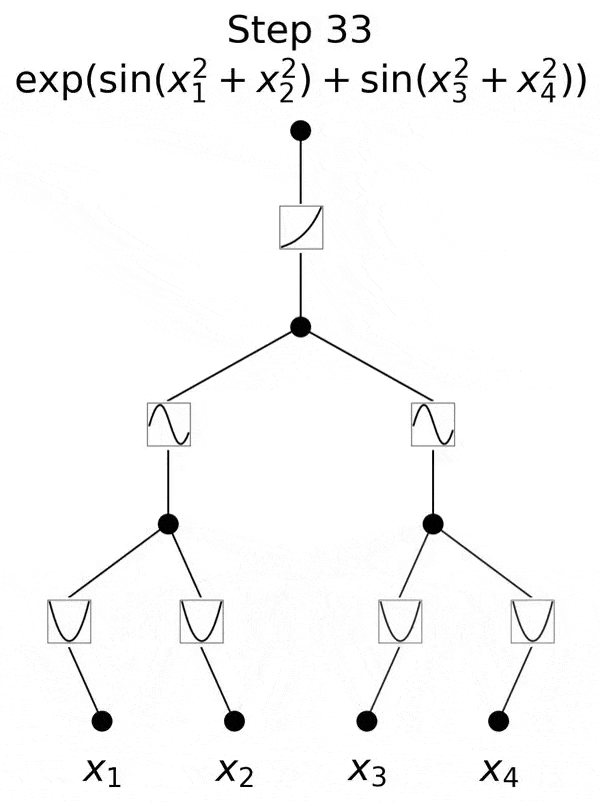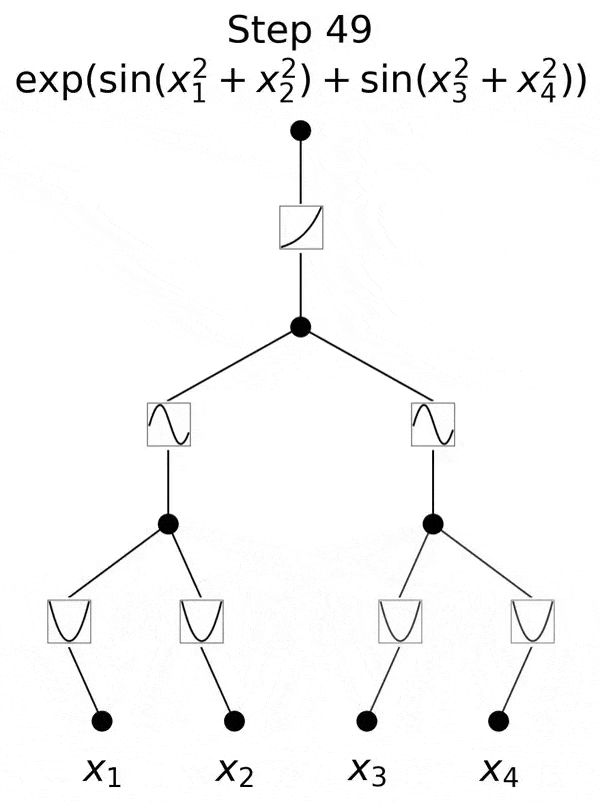
不过,研究团队并没有止步于此。自那以后,他们在多达六层的KAN上进行了实验,每一层,神经网络都能与更复杂的输出函数,实现对准。
论文合著作者之一 Yixuan Wang表示,「我们发现,本质上,可以随心所欲堆叠任意多的层」。
发现数学定理碾压DeepMind
更令人震惊的是,研究者在两个现实的世界问题中,对KAN完成了验证。
第一个,是数学一个分支中的「纽结理论」。
2021年,DeepMind团队曾宣布,他们已经搭建了一个MLP,再获得足够纽结的其他属性后,可以预测出给定纽结的特定拓扑属性。
三年后,全新的KAN再次实现了这一壮举。
而且,它更进一步地呈现了,预测的属性如何与其他属性相关联。
论文一作Liu说,「这是MLP根本做不到的」。
第二个问题是,设计凝聚态物理中的一种现象,称为Anderson局域化。
其目的是,预测特定相变将发生的边界,然后确定描述该过程的数学公式。同样,也只有KAN做到了在这一点。
Tegmark表示,「但与其他形式的神经网络相比,KAN的最大优势在于其可解释性,这也是KAN近期发展的主要动力」。
在以上的两个例子中,KAN不仅给出了答案,还提供了解释。
他还问道,可解释性意味着什么?
「如果你给我一些数据,我会给你一个可以写在T恤上的公式」。
终极方程式?
KAN这篇论文的出世,在整个AI圈引起了轰动。
AI大佬们纷纷给予了高度的评价,有人甚至直呼,机器学习的新纪元开始了!
目前,这篇论文在短短三个月的时间里,被引次数近100次。
很快,其他研究人员亲自入局,开始研究自己的KAN。
6月,清华大学等团队的研究人员发表了一篇论文称,他们的 Kolmogorov-Arnold-informed neural network(KINN),在求解偏微方程(PDE)方面,明显优于MLP。
对于研究人员来说,这可不是一件小事,因为PED在科学中的应用无处不在。
论文地址:https://arxiv.org/pdf/2406.11045
紧接着,7月,来自新加坡国立大学的研究人员们,对KAN和MLP架构做了一个全面的分析。
他们得出结论,在可解释性的相关任务中,KAN的表现优于MLP,同时,他们还发现MLP在计算机视觉和音频处理方面做的更好。
而且,这两个网络架构在NLP,以及其他ML任务上,性能大致相当。
这一结果在人意料之中,因为KAN团队的重点一直是——科学相关的任务,而且,在这些任务中,可解释性是首要的。
论文地址:https://arxiv.org/pdf/2407.16674
与此同时,为了让KAN更加实用、更容易使用。
8月,KAN原班人马团队再次迭代了架构,发表了一篇名为「KAN 2.0」新论文。
论文地址:https://arxiv.org/pdf/2408.10205
他们将其描述为,它更像是一本用户手册,而非一篇传统的论文。
论文合著者认为,KAN不仅仅是一种达到目的的手段,更是一种全新的科学研究方法。
长期以来,「应用驱动的科学」在机器学习领域占据主导地位,KAN的诞生促进了所谓的「好奇心驱动的科学」的发展。
比如,在观察天体运动时,应用驱动型研究人员,专注于预测它们的未来状态,而好奇心驱动型研究人员,则希望揭示运行背后的物理原理。
Liu希望,通过KAN,研究人员可以从中获得更多,而不仅仅是在其他令人生畏的计算问题上寻求帮助。
相反,他们可能会把重点放在,仅仅是为了理解,而获得理解之上。
参考资料:
#英伟达Laplacian Diffusion Models
AI图像生成新高度!将图像拆成不同频率分量并分别生成
本文介绍了英伟达新提出的Laplacian Diffusion Models,这是一种受拉普拉斯金字塔启发的像素空间扩散模型,能够将图像拆分为不同频率成分并分别生成,用于实现文生图、超分辨率等多种任务。文章还对LaDM的设计思路进行了分析,并探讨了其在图像生成任务中的潜在优势和改进方向。
受到经典图像表示方法拉普拉斯金字塔(Laplacian Pyramid)的启发,英伟达最近公布了一种叫做 Laplacian Diffusion Model (拉普拉斯扩散模型,后文简称 LaDM)的新型像素空间扩散模型,并用这种架构实现了文生图、超分辨率、ControlNet 等多种任务。在这篇博文里,我们来着重学习一下这种新型扩散模型的设计思想。
以往工作
扩散模型奠基之作 DDPM 及其升级版 ADM (Diffusion Models Beat GANs on Image Synthesis) 都是像素空间里的扩散模型。相比 LDM (隐扩散模型,即 Stable Diffusion),这类扩散模型不需要额外的自编码器来压缩图像,避免了编码解码带来的精度损失。
将图像从分辨率的维度拆解是一种很常见的思想。比如 Cascaded Diffusion Models 就是一种先生成低分辨率图像,再不断超分的扩散模型。今年比较有名的 VAR(Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction)也是一种按分辨率自回归的生成模型。
和这篇工作非常相关的早期工作是苹果在 2022 发表的f-DM: A Multi-stage Diffusion Model via Progressive Signal Transformation。f-DM 将扩散模型的加噪推广到了降采样、模糊等其他退化策略上。降采样版的 f-DM 有非常多的设计和本工作很像。苹果该团队次年发表的Matryoshka Diffusion Models 也用到了按分辨率逐次生成的设计。
将拉普拉斯金字塔融入扩散模型
拉普拉斯金字塔是一种图像表示方法,它把图像按频率成分拆成几张分辨率不同的图像,分辨率越低的图像表示频率越低的图像成分。我们直接通过下面的例子学习它的原理。假如x 是原图,那么x(3)=down(down(x)),x(2)=down(x)-up(x(3)),x(1)=x-up(down(x))。对x(1), x(2), x(3) 求加权和就可以还原输入图像。

受此启发, LaDM 将扩散模型的训练过程也用类似的方法分解:设 为训练图片集合, 分别是拉普拉斯金字塔不同成分构成的集合,那么我们在 , 上分别训练三个去噪模型。也就是说,不同分辨率的模型生成不同层级的拉普拉斯金字塔复原结果。
根据经验,扩散模型早期(加噪后期)生成低频内容,后期(加噪前期)生成高频内容,所以训练时我们让不同分辨率的输入图像随噪声的衰退速度也不同。图像所代表的频率越低,衰减速度越慢,越需要从早期开始去噪。这样,在生成时,我们能生成到中途后再逐渐加上高频细节。

在采样过程中,我们按照下图所示的路线从低频到高频生成图像。有了该分辨率的初始图像后,按正常 DDPM 采样的步骤就可以生成当前分辨率的图像了。问题在于某分辨率的初始图像怎么从上一个分辨率过渡而来。
在切换当前带噪图像的分辨率时,我们既要放大其中的清晰图像(信号),也要放大其中的噪声。观察上一张图和下面的图,在分辨率切换时,新的高频成分(上图中的 在时刻 3 及 在时刻 2) 是一张纯黑图,新信号为零,所以对于信号的部分我们可以直接放大。而放大噪声时, 我们要做一些噪声强度上的修改, 保证放大后信噪比不变。这部分的细节详见论文。

1K 图像生成
为了生成 分辨率的图像, LaDM 采用了两阶段 Cascaded Diffusion Model 的设计, 让生成高分辨率的图像约束于低分辨率图像。另外, 由于注意力操作的时间复杂度很高,一般的像素扩散模型只能做到 大小。为了解决此问题, LaDM 依然用一个 的去噪模型来生成 1 K 图片, 但输入前后用小波变换来压缩/复原图像。

批判性分析与总结
这篇文章是一篇由公司发表的技术报告,展示了很多可视化结果,却没有任何定量结果,代码也没有开源,不知道它的生成能力和其他模型比起来如何。
这篇文章提出的模型虽然是像素空间扩散模型,但是其拉普拉斯金字塔的设计与模型是像素空间模型还是隐空间模型无关。我们完全可以把这套设计搬到隐空间上。VAR 已经向我们证明了对隐空间图像做拉普拉斯分解是可行的。另外,这篇文章的主干网络是 U-Net 而不是 DiT。想对这个工作做一点简单的改进的话,可以弄一个 LDM + DiT 版本的。
LaDM 设计最巧妙的点是其加噪过程,频率越高的成分越早变成纯噪声。这样的话我们可以在图像生成到一半的时候再直接把高频成分加上。如果高频成分一直在的话,我们还需要额外的设计在切换分辨率时把缺少的高频加上。
有工作证明神经网络不擅长拟合高频信息。因此,在图像任务中,手动将输入图像拆成不同频率成分可能有助于网络的学习。我们可能可以沿着这个思路去改进之前多种图像任务的输入。
#HazyDet
带有场景深度的雾天无人机目标检测开源基准
本文介绍了一个名为HazyDet的开源基准数据集,它专注于雾天条件下的无人机目标检测。文章还提出了一个深度感知检测器DeCoDet,该检测器利用场景深度信息来提升恶劣天气下的检测性能。HazyDet数据集包含了上万张无人机图像和大约383,000个不同类别物体的高质量边界框标注,旨在推动无人机在恶劣天气条件下的目标检测技术研究。
arXiv 地址 :https://arxiv.org/abs/2409.19833
开源地址 :https://github.com/GrokCV/HazyDet
一句话概括:
本文介绍了 HazyDet,一个在恶劣天气条件下用于无人机目标检测的开源基准数据集,并提出了一个深度感知的检测器(DeCoDet),利用场景深度信息提升检测性能。
研究背景
在现代社会,无人机已经成为我们生活中不可或缺的一部分。它们被广泛应用于物流配送、农业监测、安防巡逻等多个领域。然而,无人机在恶劣天气条件下执行任务仍然面临着诸多挑战。
图 1. 恶劣天气下工作的无人机
恶劣天气,如浓雾、大雨、暴风雪等,不仅会影响无人机的飞行稳定性,还会对其所搭载的传感器造成严重干扰。在这样的环境中,无人机需要更加可靠的感知能力,以确保任务的顺利完成和飞行的安全性。研究和开发能够在恶劣天气下有效工作的无人机视角目标检测技术,不仅能提高无人机的工作效率,还能拓展其在极端环境中的应用范围,确保在各种天气条件下都能可靠地执行任务。
相关数据集的匮乏
图 2. 相关数据集
在计算机视觉领域,COCO 和 VOC 等数据集扮演了至关重要的角色,为目标检测和图像分割等任务提供了丰富的标注数据。近年来,针对无人机视角目标检测任务,研究者们也开发了多个数据集。例如,CARPK 数据集包括 1,448 张无人机拍摄的停车场图像,标注了 89,777 辆汽车。UAVDT 数据集提供了约 40,000 张图像,每张图像的分辨率约为 1080×540 像素,标注了城市环境中的汽车、公交车和卡车。VisDrone 是最广泛使用的数据集之一,包含 10,209 张图像,详细标注了十个物体类别,包括边界框、遮挡和截断比例。这些数据集的出现极大地推动了深度学习算法的发展,使得研究人员能够在标准化的环境中测试和比较不同的方法。
然而,这些数据集通常集中在清晰、理想的正常天气条件下。随着无人机在恶劣环境中的部署日益增多,对于相关场景的数据需求更加明显。针对大雨、浓雾、暴风雪等极端天气的无人机视角目标检测数据集相对缺乏,已成为一个亟待解决的问题。
现有方法
尽管通用目标检测领域取得了重要进展,但将这些方法直接应用于恶劣天气下的无人机目标检测往往未能达到预期效果,这主要是由于无人机视角和环境条件所致:
- 尺度变化:无人机图像由于视角和高度的变化,通常表现出显著的尺度变化,同时小物体的比例更高。
- 非均匀分布:与常规视角下目标集中于画面中心不同,无人机拍摄的图像中物体分布更为分散。
- 图像退化:在恶劣天气条件下,大气传输受损,导致能见度降低和图像颜色失真,影响图像质量,进而影响基于视觉的感知。
- 域间差距:天气引起的图像退化会影响特征识别,导致特征语义模糊,形成显著的域间差距。
为应对这些挑战,研究人员提出了一些针对性的设计:
- 多尺度特征融合 :通过特征金字塔和多分辨率架构捕捉不同尺度的物体,改善检测精度,缓解尺度变化的影响。
- 粗到细策略 :采用粗略检测器识别较大实例,再应用细粒度检测器定位较小目标,提高检测精度和效率。
- 图像恢复与检测结合 :将图像恢复与检测任务结合,学习从清晰和退化图像中提取域不变特征,增强对恶劣天气场景的理解。
尽管这些方法在某些方面取得了一定进展,但往往忽视了关键的辅助信息,例如场景深度。深度信息能够揭示物体与探测器之间的空间关系,从而帮助我们更好地理解场景中物体的布局和相对位置。此外,现有的检测流程通常表现出较为僵化和繁琐的设计,具体体现在多个方面:首先,许多检测流程需要进行多次前处理和后处理以及特种融合步骤,使得整个流程显得笨重且耗时;其次,结合图像恢复网络的方法往往受退化域数据的限制。此外,由于这检测和复原两种任务的优化目标存在差异,图像复原对检测任务的具体增益也存在不确定性。
HazyDet 数据集
图 4. HazyDet 中的样本示例
为了解决数据集的空白,我们推出了 HazyDet 数据集,重点关注雾这种普遍且会严重影响无人机感知的天气状况。HazyDet 包含了上万张精心挑选的无人机图像,并为大约 383,000 个不同类别的物体标注了高质量的边界框。据我们所知,这是第一个专门为不利天气场景下的无人机检测设计的大规模数据集。
HazyDet 包含真实和仿真两种类型的数据。对于真实数据,我们采集了大量的真实雾霾场景下的无人机图像并进行了标注。然而,获取大量恶劣天气下包含目标的无人机图像十分困难,而且标注这些质量较低的图像需要耗费大量的人力和时间成本。因此,我们尝试利用现有已标注数据构建仿真数据。通过大气散射模型(Atmospheric Scattering Model,ASM)和精心设计的仿真参数,我们生成了高质量的仿真数据。
DeCoDet
我们提出了一种新的检测框架 —— 深度调制检测器(DeCoDet),如图 6 所示。DeCoDet 通过利用深度信息,而非显式的图像恢复,来增强雾霾条件下的检测性能。该框架建立在两个观察之上:一是无人机图像中物体特征与深度之间的相关性,二是场景中雾浓度分布与深度的关系。
由于视角和高度的变化,无人机平台下的成像透视效应更加明显,远处物体的视觉尺寸显得更小,而近处物体则显得更大。此现象在常规视角和遥感视角中通常不明显。以往研究主要集中于利用深度数据检测伪装和显著目标,因为深度模态中的物体难以用颜色伪装 [11][12][13]。然而,现有研究尚未充分利用深度信息与目标检测的更多联系,例如深度与场景中目标尺度的关系及不同深度下的目标分布。我们认为这些知识对于检测是有益的。
另一方面,在仿真过程中我们发现,雾天图像中的传输图(transmission map)与像素深度之间存在简单的负指数函数关系,也就是说,距离较远区域的传输图衰减程度更强。以往的去雾研究中,很多工作已经注意到深度信息的作用并将其引入到网络中 [14][15],但我们认为深度信息的价值不仅限于低级视觉任务中的图像复原,它同样有助于网络在雾霾环境中进行更高阶的视觉感知,例如目标检测。
基于上述发现,我们在现有网络中融合深度信息,并利用学习到的深度线索动态调整检测行为,最终得到深度调制检测器(Depth-cue Conditional Detector,DeCoDet),以有效应对雾霾环境和无人机视角带来的挑战,从而显著提高检测性能。
实验
我们建立了一个全面的基准,以评估当前主流算法和 DeCoDet 在 HazyDet 数据集上的表现。首先,我们评估检测算法的性能;随后,我们评估最先进的去雾模型对检测效果的影响,相关结果如表 1、表 2 所示。
表 1. HazyDet 数据集上不同检测器的性能表现
表 2. HazyDet 上不同去雾模型的表现
致谢
我们感谢天津视觉计算与智能感知重点实验室(VCIP)提供的宝贵资源。特别感谢天津大学的朱鹏飞教授和 AISKYEYE 团队,他们对数据方面的重要支持对我们的研究工作至关重要。同时,我们对李翔辉、冯钰新及其他研究人员表示深切的感谢,他们在数据仿真和数据集构建方面提出了宝贵的意见。此外,我们也要感谢 Metric3D 对本文所呈现方法的贡献。
#INP-Former
超强异常检测新方法!从单张图像中提取正常模式
清华大学和华中科技大学的研究团队提出一种新型异常检测方法INP-Former,该方法通过从单张测试图像中动态提取内在正常原型(INPs),并利用这些INPs指导图像重建,通过重建误差实现异常检测,展现出卓越的性能和强大的泛化能力,为异常检测领域带来了新的突破。

工业检测和医疗筛查等领域对异常检测技术的需求日益增长,而现有方法通常依赖于将测试图像与训练集中学习到的正常模式进行比较,这在面对外观和位置变化时容易导致对齐问题,影响检测准确性。
为解决这一难题,来自清华大学和华中科技大学的研究团队提出了一种全新的方法 ——INP-Former,它能够从单张测试图像中提取内在正常原型(INPs),并利用这些 INPs 指导图像重建,通过重建误差实现异常检测。这项研究由清华大学精密仪器系的罗威、姚海明、张效天和楼家楠,以及华中科技大学机械科学与工程学院的曹云康、程育奇、沈卫明和余文勇等人共同完成。相关代码已开源,可供研究者进一步探索和应用。
论文标题:Exploring Intrinsic Normal Prototypes within a Single Image for Universal Anomaly Detection
论文地址:https://arxiv.org/pdf/2503.02424
项目地址:https://github.com/luow23

核心创新
- 从单张图像提取 INPs:INP-Former 通过独特设计的 INP 提取器,从测试图像本身动态提取与异常区域具有相同几何上下文和外观的正常区域作为 INPs,避免了传统方法中因训练集正常模式与测试图像不匹配导致的检测误差。
- INP 指导的重建框架:引入 INP 指导解码器,利用 INPs 重建正常模式,有效抑制异常特征的重建,使重建误差成为可靠的异常分数,提升检测精度。
- 损失函数优化:提出 INP 相干性损失,确保 INPs 准确代表正常特征,避免捕获异常信息;同时引入软挖掘损失,聚焦于难以优化的样本,进一步提升模型性能。
性能表现
INP-Former 在多个数据集上进行了全面实验,展现出卓越性能:
- MVTec-AD 数据集:图像级指标达到 99.7/99.9/99.2,像素级指标达到 98.5/71.0/69.7/94.9,显著优于现有方法。
- VisA 数据集:图像级指标达到 98.9/99.0/96.6,像素级指标达到 98.9/51.2/54.7/94.4,取得最佳或第二佳成绩。
- Real-IAD 数据集:图像级指标达到 90.5/88.1/81.5,像素级指标达到 99.0/47.5/50.3/95.0,刷新了该数据集上的检测记录。


此外,INP-Former 在少样本和单类别异常检测任务中同样表现出色,并展现出一定的零样本检测能力。



组件有效性验证
我们首先验证了INP-Former各个组件的有效性。通过在MVTec-AD和VisA数据集上的实验,我们发现:
INP提取器和INP指导解码器: 引入INP提取器和INP指导解码器后,模型性能显著提升。这是因为INP提取器能够从测试图像中动态提取与异常区域具有相同几何上下文和外观的正常区域作为INPs,为后续的特征重建提供了关键信息。
INP相干性损失(Lc): Lc的加入进一步提升了模型性能。它确保提取的INPs能够一致地表示正常模式,避免捕获异常信息,为异常特征的抑制奠定了坚实基础。
软挖掘损失(Lsm):Lsm的引入使模型能够更加关注难以优化的样本,从而进一步提升整体性能。



INPs数量的影响
我们研究了不同数量的INPs(M)对模型性能的影响。实验结果表明,当M超过4时,模型性能趋于稳定。然而,如果M过大,可能会引入异常信息,导致性能略有下降。在我们的研究中,将M设置为6,既能保证性能,又能有效避免异常信息的干扰。

方法优势
- 泛化能力强:INP-Former 从单张图像中提取 INPs 的能力使其具有强大的泛化能力,能够适应不同类别和场景的异常检测任务。
- 计算效率高:通过提取简洁的 INPs,INP-Former 有效降低了计算复杂度,适合实际应用中的高效检测需求。
- 鲁棒性强:在面对复杂背景和多种异常类型时,INP-Former 能够稳定地提取正常模式,提供可靠的检测结果。
未来展望
INP-Former 的提出为异常检测领域开辟了新方向。未来,研究团队计划进一步优化 INP 提取和利用方式,结合更多先验知识和上下文信息,提升模型对复杂异常模式的检测能力,推动异常检测技术在更多领域的广泛应用。
#Infrared and Visible Image Fusion
全新视角红外与可见光图像融合完整理解与入门!论文信息
标题:Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption
作者:Jinyuan Liu, Guanyao Wu, Zhu Liu, Di Wang, Zhiying Jiang, Long Ma, Wei Zhong, Xin Fan, Risheng Liu
机构:大连理工大学
原文链接:
https://ieeexplore.ieee.org/abstract/document/10812907
Git仓库链接:https://github.com/RollingPlain/IVIF_ZOO
可以直接检索论文标题 或IVIF_ZOO直达
1. 引言简介
红外-可见光图像融合(IVIF)是计算机视觉领域的一个基础性关键的任务,旨在将红外和可见光光谱的独特特征集成到整体表示中。

图1 详细的光谱图,展示了几乎所有波长和频率范围,并标注了可见光范围和对应的IVIF图像数据集。
将一对红外图像和可见光图像进行融合,这一过程称为红外-可见光图像融合,是计算机视觉领域的一个基础性关键的任务,融合图像具有
1)增强信息表达能力;
2)抑制噪声引起的干扰等优势,可以更好地支持诸如遥感、军事监视和自动驾驶等广泛的实际应用。
自 2018 年以来,IVIF方法获得了长足的发展。相比传统方法,这些基于学习的解决方案在视觉质量、鲁棒性和计算效率方面表现更好,因此受到越来越多的关注。然而现有的调查大多数专注于综述传统的或基于学习的IVIF方法,并没有从多个方面(数据、融合和任务)对IVIF进行研究。
2. 本文主要贡献

图2 面向实际应用的红外与可见光图像融合流程图。
我们的综述采用了更全面的视角,细致审查了多个关键因素。并且们强调了初步数据兼容性和后续任务的关键作用,这对于IVIF的实际应用至关重要。本研究的主要贡献有四个方面:
- 1)本综述首次从多维视角(数据、融合与任务)出发,统一理解并系统组织了基于学习的红外与可见光图像融合方法。整理了180多个基于学习的方法。
- 2)我们针对每个视角进行了深入讨论,包括最近采用的架构和损失函数。同时,讨论了代表性方法的核心思想,为后续的研究人员提供便利。
- 3)为了阐明面向应用的红外与可见光图像融合方法,我们用分层和结构化的方式系统地概述了技术层面和数据集的最新进展。
- 4)我们首次比较了初步配准和后续任务(如目标检测和语义分割)的融合性能。
3. 全新的分类方法

图3 文中关键方法分类图表整合 详细大图请参考原文


为了更直观地梳理红外与可见光图像融合领域的研究脉络,文章中的关键图表进行了整合。文内包含方法汇总大表格:按类别整理了已有方法,涵盖代表模型、特征处理方式、融合策略等关键信息,一目了然地展示了当前研究热点与发展趋势。数据集概览表:罗列并比较了该领域主流数据集,包含采集方式、模态类型、任务适用性等,为研究选型和复现提供参考依据。桑基图:可视化展示了不同方法与任务之间的流向关系,帮助读者理解各类方法的适用场景。
我们总体上将IVIF分为三类,并且在文章中进行了详细的说明:
A:用于视觉增强的融合:提升融合图像的视觉效果,让图像所呈现的信息更加清晰、全面。
基于自编码器(AE)的方法:先预训练 AE,再用其编码器提取特征、解码器重建图像,融合方式有手动规则或二次训练。现有方法可分为改进融合规则和数据集成、创新网络架构两类。
基于卷积神经网络(CNN)的方法:包含特征提取、融合、重建三步。创新点在基于优化、修改损失函数和架构改进。
基于生成对抗网络(GAN)的方法:分为单重判别和双重判别。单重判别易导致模态不平衡,双重判别旨在解决此问题,但面临引导判别器提取多样模态特征的挑战。
基于 Transformer 的方法:结合 CNN 和 Transformer,利用自注意力机制,但计算资源需求大。
B:面向应用的融合:在实际高级视觉任务中具有广泛的应用场景
目标检测:有的方法通过双层优化等手段结合图像融合与目标检测;也有直接用红外和可见光图像检测的方法,通过多种机制增强精度。
语义分割:包括级联融合与分割任务、提出多功能框架、引入渐进式语义注入等方法。
其他感知任务:在目标跟踪、人群计数、显著目标检测、深度估计等方面,多模态融合都起到重要作用。
C:数据兼容融合:解决数据兼容性问题的相关方法。
免配准方法:分为伪标签生成(基于风格迁移)和构建模态无关特征空间(基于潜在空间)两类,用于解决配准问题。
通用融合方法:它能够有效整合不同的成像技术,有着优秀的算法通用性和可拓展性,潜力巨大。
4.全面评价和总结
我们不仅对大量的IVIF方法进行了分类,还对这些方法进行了极为全面的评价,包括配准、融合及其他后续下游操作等任务的定性和定量结果,并进行了计算复杂度分析。
在评价中,我们针对分类法中不同的融合方法选用多个数据集,并将各个方法的性能进行对比,得出全面的性能总结。

图4 文中关键对比结果图表整合 详细大图、大表请参考原文



这些旨在为红外与可见光图像融合领域的研究人员,工程师和爱好者提供一个核心库,促进红外-可见图像融合技术的进步和协作。
所有的结果,包括基准数据集、评价指标和定性定量结果都已开源至我们的Git仓库IVIF_ZOO中:

5. 未来趋势分析
目前基于学习的IVIF方法获得了长足的发展。但仍存在几个关键问题,需要未来的研究加以关注。
A.处理错位/攻击数据
图像融合网络在复杂对抗情境下的鲁棒性,仍然是一个重大挑战。
B.开发基准
高质量的基准对于IVIF研究至关重要,尽管已经出现了许多相关的数据集,满足了一定的需要,但是仍有三大紧迫问题需要关注。
- 1)创建红外和可见光图像配准基准至关重要,因为现有基准主要关注像素对齐的图像对。
- 2)扩展IVIF基准以包含各种高层次任务。
- 3)探索多样化的挑战性场景。
C.更有效的评价指标
传统的指标如EN、MI、CC和SCD各自仅衡量图像质量的一个方面,且可能与主观评价不一致,特别是在高噪声水平等条件下。因此,这些指标单独使用无法全面捕捉图像融合质量的本质。
D.轻量化设计
大多数现有设备(如无人机(UAV)和手持设备)无法支持重型GPU的计算需求,这需要探索更高效且资源占用更少的网络架构。
E.多任务结合
6.结语
红外与可见光图像融合,正站在从理论研究走向实际应用的关键十字路口。本综述不仅系统梳理了当前主流方法与数据集,也首次从“数据-融合-任务”的完整链路出发,搭建起了一个统一的研究框架。我们希望这份工作,能为研究者提供参考,为工程实践者带来启发,也为未来的发展方向提供一些思路。欢迎关注本文的 GitHub 项目,共同完善红外与可见光融合技术的知识地图!
#DashGaussian
200 秒内优化 3D高斯
在消费级显卡上将3DGS的训练耗时降低到了200秒以内。
我们提出一种即插即用的3DGS训练加速策略——DashGaussian,其成功地在多个数据集上将多种3DGS骨干的训练速度提升了平均一倍,且保留甚至改进了这些3DGS骨干对场景的重建质量。使用DashGaussian增强先前的3DGS快速训练方法,我们成功地在消费级显卡上将3DGS的训练耗时降低到了200秒以内。
论文网址:https://arxiv.org/abs/2503.18402
1.概要
在3DGS的训练过程中,渲染分辨率与高斯基元数量作为决定渲染 (forward rendering)、梯度反传 (gradient backward propagation) 以及高斯基元优化 (optimization) 这三者时间复杂度的主要因素,极大地影响了3DGS的训练速度。我们将这两者合并称为3DGS的“计算复杂度”。在常规的3DGS训练框架下,早期训练使用高分辨率图像监督少量的高斯基元,极为浪费计算复杂度;同时在训练的半段,随着高斯基元数量的增大,计算复杂度增大导致耗时激增,而对于场景的重建质量提升却收效甚微(见图1右侧曲线图)。这些现象都表明现有的3DGS训练框架存在较大的计算复杂度冗余。
为了减小3DGS训练的计算复杂度,常见地我们可以使用coarse-to-fine的训练策略——在3DGS训练的前期使用低分辨率训练,后期使用原本的高分辨率训练。然而现有的coarse-to-fine策略面临着训练速度与训练质量的抉择:coarse阶段占比增大固然会加快3DGS的训练,但是这将导致aliasing问题并降低最终训练得到的3DGS质量,反之亦然。
为了解决这一问题,我们借鉴了传统图像分析理论。考虑两幅数字图像,其中一幅低分辨率图像由另外一幅高分辨率图像通过频域低通滤波获得。从频域分析两幅图像之间的差异(见图2):将两者的频谱中心(最高频位置)对齐,发现两幅图像的差异其来自于高分辨率图像比低分辨率图像多出的高频频谱(外围部分),而两者频谱中心部分是相同的。受上述分析启发,我们认为3DGS从低分辨率图像到高分辨率图像的训练等价于让3DGS从低频到高频逐渐拟合场景。于是,我们提出一种基于训练图像频域信息显著度的场景自适应3DGS训练分辨率规划策略。
进一步地,我们认为某一具体的分辨率应当配合恰当数量的高斯基元进行3DGS训练,以平衡场景的拟合程度和训练效率。我们提出一种基于训练分辨率规划的高斯基元增长规划策略,为每个训练分辨率配备恰当数量的高斯基元。与此同时,为了让高斯基元增长规划不再需要事先通过专家先验指定最终的高斯基元数量,我们还提出了一种基于动量场景自适应3DGS基元增长终点估计方法,使得我们可以在不事先指定最终高斯基元数量的前提下合理规划高斯基元的增长。
本工作的贡献总结为以下三点:
- 我们通过合理地规划3DGS训练过程中的计算复杂度,剔除大量冗余计算,极大地加速了3DGS的训练。
- 我们提出一种场景自适应规划策略,同时地控制3DGS训练过程中的训练分辨率以及高斯基元数量的增长,来确保3DGS的重建质量。
- 我们设计了一种场景自适应的高斯基元增长终点估计策略,使得我们可以在不事先指定最终高斯基元数量的情况下合理地规划高斯基元增长。
图1 DashGaussian能力概览
2. 方法介绍
图2 DashGaussian框架图
2.1 基于图像频率信息的场景自适应3DGS训练分辨率规划
假设我们目前有个3DGS训练视角 ,它们的分辨率都为 。我们定义这一分辨率的显著度为, , 其中, 为 通过离散傅里叶变换(Discrete Fourier Transform ,DFT)获得的频谱。类似地,在将 下采样到原分辨率 的情况下 ,我们可以得到分辨率 的显著度 。
直觉上,当 远大于 时,意味着分辨率 远比分辨率 更加显著,则整个3DGS的训练过程应当由较高的原分辨率主导。基于这一性质,我们定义一比率函数如下, , 基于这一比率函数,我们为原分辨率 分配个训练轮数 ,其中 为3DGS的总共训练轮数。我们在第 步训练时将训练分辨率由 升至 。我们可以通过回归法将情况推广至使用多个训练分辨率的情况。
2.2 基于自适应分辨率规划的3DGS基元增长规划
由于3DGS主要描述场景的几何表面,我们认为高斯基元的数量应与场景表面的复杂程度相关,而训练视角观察到的场景表面复杂程度又与训练视角的分辨率有关。于是,我们建立高斯基元与训练分辨率的联系如下: , 其中, 表示规划下第 步训练应有的高斯基元数量, 表示初始高斯基元数量, 表示规划下的最终高斯基元数量, 表示第 步训练的降采样倍数。我们通过乘方因子 来抑制高斯基元在早期的增长,鼓励其在中后期的增长来使得高斯基元更好地收敛。
2.3 基于动量的场景自适应3DGS基元增长终点估计
现有的研究通常基于专家先验或是数据集先验来在训练开始前决定 。通过此类手段定下的 通常难以被解释是否足以充分地描述一个三维场景,且这类手段难以被未经专业训练的普通算法用户使用。为了解决这一问题,我们提出一种基于动量的 估计策略,将 作为一个变量,在训练过程中实时更新, , 其中, 表示第 步训练时估计得到的高斯基元增长终点; 为DashGaussian所增强的 3DGS骨干无额外限制条件下在第 步训练时自身增长的高斯基元数量; 为两超参数,论文中分别统一指定为 0.98 和 1.0 。 通过上述方法,我们将高斯基元早期的增长累积到 中,随着训练的进行,通过高斯基元增长规划释放,最终实现了高斯基元与训练分辨率协同的先慢后快的增长。
3. 实验3.1 实验设置
我们在Mip-NeRF 360, Deep Blending, Tanks&Temples等三个数据集上验证了DashGaussian的能力,并进一步在论文附录中报告了DashGaussian对3DGS大场景重建的增益。我们汇报了PSNR, SSIM, LPIPS等三项指标以衡量场景重建质量,并同时汇报了最终模型中的高斯基元数量以及训练耗时(分钟)。
3.2 DashGaussian与其他快速训练方法的比较
在表1中,我们汇报了使用DashGaussian增强Taming-3DGS的结果。DashGaussian在大幅提升训练速度的同时显著地提升了对场景的重建质量,重建质量明显高于各比较方法,且在三个数据集上的平均重建用时均在200秒以内。
表1 DashGaussian与其他快速训练方法的比较
图3 表1的可视化结果
3.3 使用DashGaussian增强不同3DGS骨干
在表2中,我们汇报了使用DashGaussian增强不同3DGS骨干的结果。DashGaussian在不同3DGS骨干和不同数据集上实现了平均的训练耗时减少,训练速度提升将近一倍,维持甚至提升了训练质量,且减少了最终模型中的高斯基元数量。更多丰富的可视化结果见论文主页https://dashgaussian.github.io/。
表2 DashGaussian增强不同的3DGS骨干
3.4 消融实验
我们在表3中对DashGaussian提出的分辨率规划以及高斯基元增长规划策略进行了消融实验。我们在Mip-NeRF 360数据集上使用Taming-3DGS作为3DGS骨干进行消融实验,将仅使用分辨率规划和仅使用高斯基元增长规划分别记为+Reso-Sche.以及+Prim-Sche.,并将完整的DashGaussian记为Full。结果表明,两个模块皆能有效地降低训练时间以及提高渲染质量。
表3 消融实验
4. 总结
本文介绍了DashGaussian,一种即插即用的3DGS训练加速策略。DashGaussian将3DGS的coarse-to-fine训练过程建模为从低频到高频的场景拟合,并基于此提出了对训练分辨率以及高斯基元增长的协同规划策略。DashGaussian成功在多个数据集上将不同3DGS骨干的训练速度提升了一倍,且维持甚至改进了3DGS骨干原有的重建质量。更多方法细节请见论文原文:https://arxiv.org/abs/2503.18402。
#SAGE_IVIF
融入SAM语义信息的双层优化蒸馏:多模态图像融合新思路
本文介绍了一种多模态图像融合的新方法,通过双层优化蒸馏框架将Segment Anything Model (SAM)的语义先验信息融入图像融合流程,实现了视觉质量与任务精确性的统一,并通过轻量级子网络设计提高了实际应用中的推理效率。
项目信息
- 文章链接:https://arxiv.org/abs/2503.01210
- 项目链接:https://github.com/RollingPlain/SAGE_IVIF
亮点直击
- 统一视觉质量与任务精确性:如下图Ⅰ所示,传统方法和早期基于深度学习的融合网络主要关注融合的视觉效果,忽略了下游任务的需求。而图Ⅱ展示的特定任务方法虽然引入了任务损失和特征,但导致优化目标不一致。我们的创新在于,如图Ⅲ所示,通过双级蒸馏框架弥合了这一差距,大型融合网络首先利用Segment Anything Model (SAM)提供的语义先验信息增强性能,真正实现了视觉质量与任务精确性的统一。
- 轻量高效的实用化设计:将融合知识蒸馏到轻量级子网络中,使其在保持高质量视觉融合的同时,能够无缝支持分割等下游任务。通过充分利用SAM对分割任务的固有适应性(如图右下角所示),我们的方法不仅在理论上实现了"两全其美"——平衡视觉融合与任务性能,更确保了实际推理阶段的高效可行性,为多模态图像融合领域提供了新的技术范式。

图1. 本文所提方法与现有主流对比方法的差异。
解决的问题
- 传统方法的局限性:传统基于信息理论的融合方法在图像质量优化上存在明显局限,特别是处理冗余信息和特定场景时表现不佳。而早期深度学习方法则常出现边缘模糊、伪影产生等问题,难以满足下游任务对高质量感知信息的严格要求。
- 优化目标的冲突:更为棘手的是,当前将融合与下游任务耦合的方法导致优化目标相互冲突,在平衡视觉质量与任务适应性之间形成了难以逾越的鸿沟。研究者们不得不在两个关键目标间做出取舍,难以同时兼顾两者的优化。
- SAM模型的计算负担:虽然SAM模型在多模态图像融合领域展现出巨大潜力,但实际应用中完整SAM模型的高计算成本成为另一个严峻挑战。这种计算负担严重限制了基于SAM的融合方法在资源受限场景下的实际部署和应用,使其难以在移动设备或边缘计算环境中发挥作用。
提出的方法
- 融入SAM丰富语义先验:将SAM的丰富语义先验知识融入多模态图像融合流程,深度挖掘场景语义信息,有效增强了系统对复杂场景的理解能力,从根本上提升了融合效果,使融合图像在视觉质量和下游任务适配性两方面都取得了显著进步。
- SPA特征保留与整合机制:SPA模块通过特殊的持久存储库(PR)机制精准保留源图像的关键特征信息,并利用高效的交叉注意力机制将这些特征与SAM提取的高级语义信息无缝整合,实现了不同模态信息的深度融合,为生成语义丰富、结构清晰的高质量融合图像提供了坚实基础。
- 双层优化驱动蒸馏机制:提出的双层优化驱动蒸馏机制结合创新的三元组损失函数,在训练阶段将主网络中包含SAM语义知识的复杂表征有效转移到轻量级子网络,使得在实际推理时子网络能够独立运行而无需依赖计算密集型的SAM模型,大幅降低了计算复杂度,同时保持了卓越的融合性能,极大提高了模型在实际场景中的应用价值。
设计动机与整体架构
核心挑战:我们旨在推理阶段利用SAM语义先验提升跨模态融合质量,但直接使用大规模SAM模型计算开销过大。虽然知识蒸馏可将SAM驱动的主网络信息转移到轻量级子网络,但主子网络间的能力差距常导致语义转移不完整或结构不一致,阻碍了理想融合性能的实现。
创新框架:为解决这一问题,我们提出如图2所示的双层优化框架,包含SAM增强的主网络与轻量级子网络。在这个框架中,优化过程可通过公式1表示,明确了两个网络在优化过程中的相互关系与目标。通过精心设计的优化机制实现网络间协同进化,在保持高质量融合的同时显著降低推理成本。
技术亮点:采用类DARTS训练策略实现网络交替优化,结合损失函数(包含特征对齐、上下文一致性和对比语义),确保子网络高效获取主网络知识,最终消除对计算密集型SAM模型的依赖。

公式1. 所提出的双层优化框架数学表达,通过嵌套优化目标实现主子网络协同学习。

图2. 所提方法的整体架构,包括基于SAM的主网络结构、语义持久化注意力模块、知识蒸馏范式及轻量级子网络设计,共同构成了高效的跨模态融合框架。
实验设置
选用五个具有代表性的数据集,即TNO、RoadScene、MFNet、FMB和M3FD,用于模型的训练与评估。
评估指标
- 图像融合:采用如EN、SD、SCD和MS-SSIM,从不同角度衡量融合图像对源图像信息的保留程度、细节丰富度以及结构一致性。同时引入无参考图像质量评估指标BRISQUE、NIQE、MUSIQ和PaQ-2-PiQ,评估融合图像的质量,判断其与人类视觉系统感知的契合度。
- 基于融合的语义分割:使用IoU评估语义分割的性能,计算预测结果与真实标签之间的重叠程度,直观反映模型在不同类别上的分割准确性。通过mIoU综合评估模型在多个类别上的整体分割效果。
实验结果
定性结果
在TNO、RoadScene、M3FD和FMB多个常用数据集上,SAGE方法展现了两个明显优势:
- 信息保留能力:成功保留了可见光图像中的纹理细节(如植被)和红外图像中的热信息(如烟囱烟雾),实现了"两全其美"的融合效果。
- 抗干扰能力:在夜间浓雾等复杂场景下,能够准确重建地面上的反光人行横道线和远处建筑轮廓,显示出强大的环境适应性。
在FMB和MFNet数据集上的语义分割任务中,SAGE方法借助SAM的语义先验知识,实现了更准确的分割效果:
- 白天场景优势:在白天交叉路口场景中,成功区分了卡车和公交车
- 夜间场景优势:在夜间道路场景中,准确分割出人行道
- 小目标识别:对远距离小目标行人和夜间几乎不可见的车道线也能进行精确分割

图3:定性结果概要图,详情见原文。
定量结果
在FMB数据集的语义分割任务上,SAGE方法展现了显著优势:
- 在Segformer-B3框架下,mIoU达到61.2%,比第二好的方法提高了3.0%
- 即使在无需重新训练的开放词汇分割网络(X-Decoder)上,我们的方法也表现出色,mIoU达到51.1%

图4:定量结果概要图,详情见原文。
结语
在这次研究中,我们探索了如何利用语义信息来改进红外与可见光图像融合的效果,并通过双层蒸馏方案来解决计算效率问题。这项工作为红外与可见光图像融合领域提供了一个值得探索的新方向,我们期待未来能有更多研究者加入,共同推动这一领域的发展。如果您对我们的工作感兴趣,欢迎查阅我们的论文全文和GitHub资源库。
最新研究成果
我们的survey研究工作《Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption》近期被计算机视觉领域期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 接收发表。
作者: Jinyuan Liu, Guanyao Wu, Zhu Liu, Di Wang, Zhiying Jiang, Long Ma, Wei Zhong, Xin Fan, Risheng Liu*您可以通过以下链接了解更多:
- Paper https://ieeexplore.ieee.org/abstract/document/10812907
- 中文版 https://pan.baidu.com/s/1EIRYSULa-pd2FRmIdG693g?pwd=aiey
- Github https://github.com/RollingPlain/IVIF_ZOO
如果您对红外与可见光图像融合领域有兴趣,或正在从事相关研究,希望这项工作能为您提供一些参考。欢迎下载阅读,如有帮助,也欢迎在您的工作中引用。
我们在GitHub上整理了图像融合领域的各种方法总结、相关论文、代码实现、数据集资源以及评价指标链接,希望能为研究者提供便利。如果您觉得有帮助,欢迎给我们的仓库点个星标,这将鼓励我们继续完善和更新这一资源库。
#B200
谷歌最新AI芯片打平英伟达B200,专为推理模型打造,最高配每秒42500000000000000000次浮点运算
谷歌首款AI推理特化版TPU芯片来了,专为深度思考模型打造。
代号Ironwood,也就是TPU v7,FP8峰值算力4614TFlops,性能是2017年第二代TPU的3600倍,与2023年的第五代TPU比也有10倍。
(为什么不对比第六代,咱也不知道,咱也不敢问。)
第七代TPU还突出高扩展性,最高配集群可拥有9216个液冷芯片,峰值算力42.5 ExaFlops,也就是每秒运算42500000000000000000次。
是目前全球最强超级计算机EL Capitan的24倍。
谷歌称,AI正从响应式(提供实时信息供人类解读)转变为能够主动生成洞察和解读的转变。
在推理时代,Agent将主动检索和生成数据,以协作的方式提供洞察和答案,而不仅仅是数据。
而实现这一点,正需要同时满足巨大的计算和通信需求的芯片,以及软硬协同的设计。
谷歌AI芯片的软硬协同
深度思考的推理模型,以DeepSeek-R1和谷歌的Gemini Thinking为代表,目前都是采用MoE(混合专家)架构。
虽然激活参数量相对少,但总参数量巨大,这就需要大规模并行处理和高效的内存访问,计算需求远远超出了任何单个芯片的容量。
(o1普遍猜测也是MoE,但是OpenAI他不open啊,所以没有定论。)
谷歌TPU v7的设计思路,是在执行大规模张量操作的同时最大限度地减少芯片上的数据移动和延迟。
与上一代TPU v6相比,TPU v7的高带宽内存 (HBM) 容量为192GB,是上一代的6倍,同时单芯片内存带宽提升到7.2 TBps,是上一代的4.5倍。
TPU v7系统还具有低延迟、高带宽的ICI(芯片间通信)网络,支持全集群规模的协调同步通信。双向带宽提升至1.2 Tbps,是上一代的1.5倍。
能效方面,TPU v7每瓦性能也是上一代的两倍。
硬件介绍完,接下来看软硬协同部分。
TPU v7配备了增强版SparseCore ,这是一款用于处理高级排序和推荐工作负载中常见的超大嵌入的数据流处理器。
TPU v7还支持Google DeepMind开发的机器学习运行时Pathways,能够跨多个TPU芯片实现高效的分布式计算。
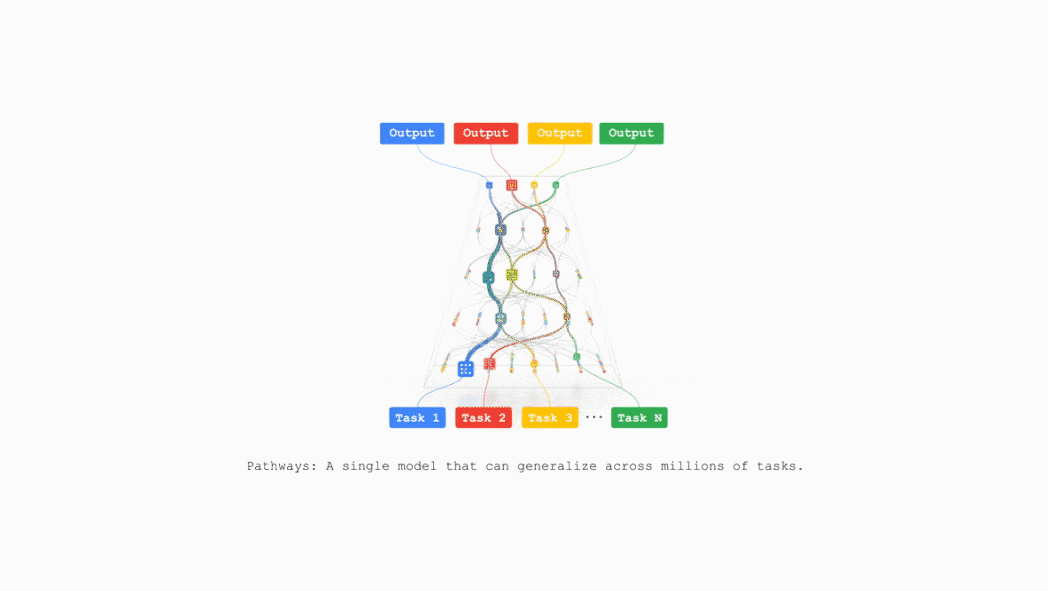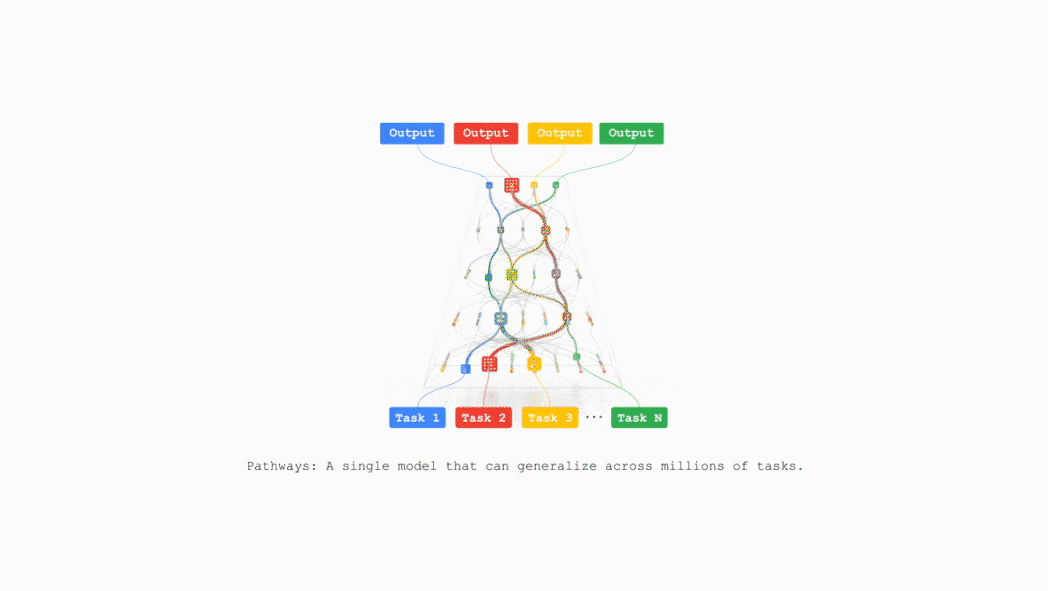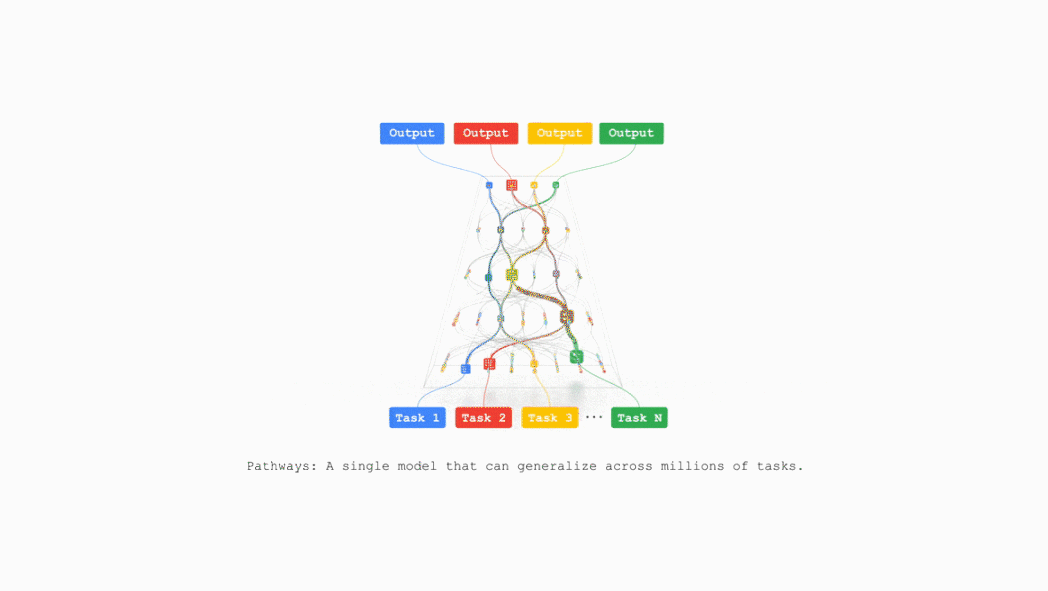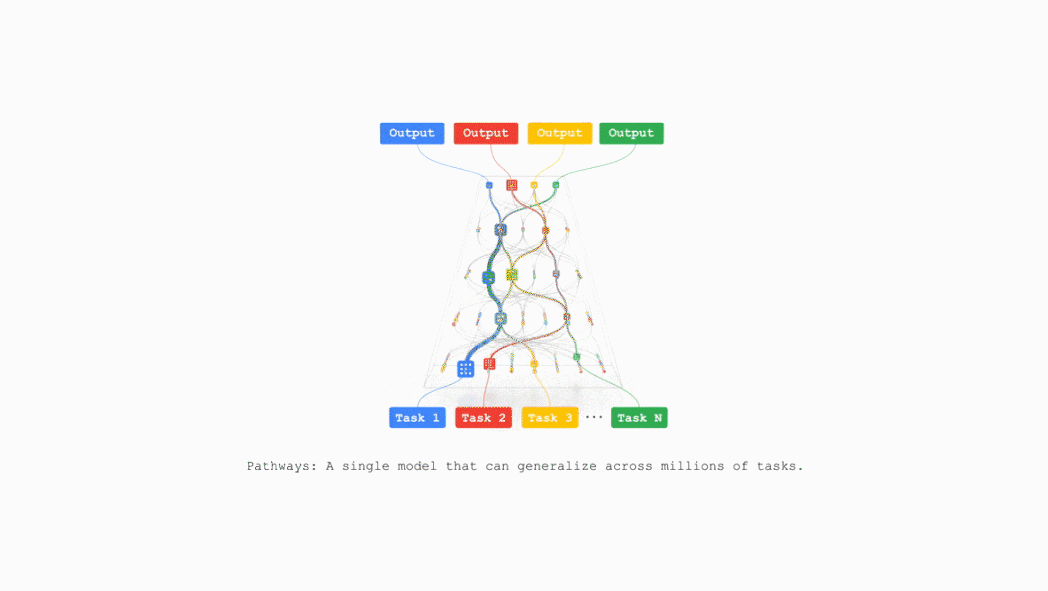
谷歌计划在不久的将来把TPU v7整合到谷歌云AI超算,支持支持包括推荐算法、Gemini模型以及AlphaFold在内的业务。
网友:英伟达压力山大了
看过谷歌最新TPU发布,评论区网友纷纷at英伟达。
有人称如果谷歌能以更低的价格提供AI模型推理服务,英伟达的利润将受到严重威胁。
还有人直接at各路AI机器人,询问这款芯片对比英伟达B200如何。
简单对比一下,TPU v7的FP8算力4614 TFlops,比B200标称的4.5 PFlops(=4500 TFlops)略高。内存带宽7.2TBps,比英伟达B200的8TBps稍低一点,是基本可以对标的两款产品。
实际上除了谷歌之外,还有两个云计算大厂也在搞自己的推理芯片。
亚马逊的Trainium、Inferentia和Graviton芯片大家已经比较熟悉了,微软的MAIA 100芯片也可以通过Azure云访问。
AI芯片的竞争,越来越激烈了。
参考链接:
[1]https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/[2]https://x.com/sundarpichai/status/1910019271180394954
#STI-Bench
时空理解基准:评估MLLMs的精确时空理解能力
本篇分享论文STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?,上交、NTU、BAAI、斯坦福等提出时空理解基准STI-Bench:评估MLLMs的精确时空理解能力。
- 论文: https://arxiv.org/abs/2503.23765
- 主页: https://mira-sjtu.github.io/STI-Bench.io/
MLLMs真的具备精确时空理解能力吗?
当前,将多模态大模型(MLLM)作为具身智能和自动驾驶的端到端方案已成趋势。但这些模型在理解语义之外,是否真正具备了对现实世界精确、定量的时空理解能力?这直接关系到它们在物理世界中行动的可靠性。
作者们认为,现有对MLLM的评估大多集中在2D视觉感知和语义问答上,缺乏对精确时空理解(如距离、速度、姿态变化等精确3D空间和时序动态)能力的严格考察。 因此,这篇论文提出一个核心问题:当前的MLLMs是否已准备好迎接需要精确时空理解的现实世界任务?

因此作者提出一个新基准STI-Bench
专门设计用于评估MLLM的精确时空理解能力,即时空智能 (Spatial-Temporal Intelligence)。 使用视频作为输入,覆盖桌面、室内、室外三大真实场景。 包含8大类挑战性任务,强制模型进行精确定量的估计和预测,例如:物体的尺寸/距离测量、空间关系判断、3D定位、位移/路径长度计算、速度/加速度分析、自身朝向变化、轨迹描述、姿态估计。

一个关键发现
通过对包括GPT-4o、Gemini系列、Claude 3.7、Qwen2.5-VL等在内的顶尖MLLM进行广泛测试,发现它们在STI-Bench上的表现普遍不佳,尤其是在需要精确定量(如距离、运动参数)的任务上得分很低,显示其精确时空理解能力远未达到实际应用的要求。

三大核心挑战
通过针对Gemini-2.5-Pro这个有详细思考过程的模型作为代表,分析错误模式后,作者指出现有MLLM主要存在定量空间属性不准确、时间动态理解缺陷、跨模态信息整合能力薄弱等三大局限性,阻碍了其精确时空理解。

STI-Bench的意义
它不仅是一个评测工具,更像是一次现实检验,揭示了当前MLLM在迈向真正理解和交互于物理世界的道路上,尤其在精确时空理解方面存在的显著差距。这项工作为社区指明了未来需要攻克的方向,以开发出更可靠、真正具备精确时空理解能力的MLLM,服务于具身智能、自动驾驶等关键领域。
#强化学习发展这十年
详细回顾强化学习在过去十年的发展历程,分析其从经典定义到多子领域扩展,再到概念泛化的过程,并对未来强化学习的发展趋势进行了预测,探讨了强化学习与监督学习、无监督学习的关系及其对强化学习研究者的影响。
(前言: 这篇文章我从祖师爷评上图灵奖的时候开始写的,但不停的在删了重写,删了重写,到现在为止才出一个我勉强接受的版本。我从我的视角来描述下我觉得这些年来强化学习的发展风向。先叠个甲,本人学术不精,本文所有观点都乃我一家之言,欢迎大家批评指正。)
最近在帮忙给强化学习立标准,我发现这是一件非常痛苦的任务。因为随着这两年强化学习的大力发展,强化学习衍生出了许许多多的子课题方向,除了最经典的online RL以外,例如offline model-free RL,model-based RL,RLHF,multi-agent,risk-sensitive,inverse RL等等,要给这些子课题找共性非常困难。
而在传统教科书中,强化学习的标准制定时由于这些子课题还未出现,导致定义早已过时。举个例子,例如强化学习强调智能体跟环境交互,而offline RL方向偏说我就不跟环境交互。再例如强化学习强调无需人类标签还是采用奖励信号,RLHF说我就不是这样。
所以我打趣说,这就像以前府里有个RL的老太爷。老太爷年轻气壮的时候,所有的子子孙孙都说自己是RL府里的。结果随着日子发展,RL府里的少爷们走了不同的方向,一个个飞黄腾达,有些混的比老太爷都好了。这时你说要在RL几个儿子里找到相同特性,只能说有点不合时宜了,勉强只能说他们都留着RL的血脉吧。
于是我只能根据强化学习这10年左右的发展时光,看看每个阶段给强化学习做了怎么样的注解。
强化学习一阶段:
大概在十年前,在我刚做RL的时候,其实RL没有定义,只有描述,大家认为RL是一种解决马尔可夫决策过程的方法,典型算法包括DQN、PPO。当然那时我们有一种历史局限,就认为这个描述是个充要条件。也就是认为只有value-based算法(DQN),policy-based算法(PPO)这种才算是强化学习,其他统统不算。
同时这个阶段,有大量的强化学习研究者开始涌入这个方向,大家总体分为两拨,学术界的学者试图研究通用的强化学习算法,而工业界的人则在给强化学习找应用场景。
那像作者这样天资愚笨的同学自然在通用算法上没有办法做出太多创新,于是大家开始给强化学习的问题定义做细致扩展,出现了多智能体强化学习, 安全强化学习等等的强化学习子方向。从后验角度出发,其中某些子方向的问题定义其实缺乏实践依据,导致强化学习产生了一个后遗症:给人留下了没法用的污点。
强化学习二阶段:
随着第一批强化学习研究生的毕业,强化学习也进入了大应用时代。最开始,人们对强化学习应用的要求也非常严格,在强化学习应用的论文描述里必须有以下内容:
- 非常准确的状态空间和动作空间定义
- 必须存在状态转移函数,不允许单步决策,也就是一个动作就gameover
- 必须有过程奖励,且需要存在牺牲短期的过程奖励而获取最大累计回报的case案例
说个开玩笑的话,如果DS的文章放到几年前RL的审稿人手里,他大概率会得到这样的回复:这只是采用了策略梯度的方式将不可导的损失/奖励函数用于优化神经网络参数而已,请不要说自己使用了强化学习。
这导致像作者这样的old school,在看到最新的强化学习应用文章时,总会试图问文章作者几个基础的问题,状态是啥,动作是啥,奖励是啥。但其实现在很多文章已经不考虑这些问题了。
那时大家普遍认可的应用方向是游戏AI,因为游戏AI符合上述所有的定义,并且游戏环境较为容易获得。但较为可惜的是,以强化学习为核心的游戏AI应用市场份额不大,随着PR价值的慢慢淡去,这个领域渐渐容纳不下日益增长的强化学习研究生。
而在落地其他工业场景的时候,由于仿真器的不完善,导致强化学习难以开展智能体训练。如果仿真器投入程度不高,同时又存在sim2real这个难以逾越的问题,市场慢慢对其失去了信心。
大家只好开始自谋生路。
强化学习三阶段:
作为经历过二阶段的研究者们发现,强化学习落地的真正难点在于问题的真实构建,而非近似构建或策略求解等等方面的问题。所以首先强化学习的概念扩大了,从原先任务只有求解策略的过程是强化学习,变成了构建问题+求解策略统称为强化学习。
典型如offline model-based RL和RLHF,其中核心的模块变成了通过神经网络模拟状态转移函数和奖励函数,策略求解反而在方法论中被一句带过。我个人觉得这件事是具有强化跨时代意义的,因为理论上这个过程可以被解耦,变成跟强化学习毫无相关的名词概念,例如世界模型概念等等。非常感谢RL方向大牛研究者的持续输出,是他们工作的连续性,保证了强化学习的火焰没有在这次迭代中熄灭。
继续发展下去,人们发现:可以解决一切问题的强化学习被证明,没有有效的交互环境下的就没法达到目标,有这种有效交互环境的实际应用场景却非常少。导致把决策问题的过程步骤:问题建模、样本收集、策略训练、策略部署的周期拉得更长了,这几个步骤不是跟在线强化一样那么紧凑,是断开了链路的。
于是神奇的事情发生了:中间过程的任何一个步骤都变成了强化学习!
但实话实说,即使出现了这样程度的概念扩大,强化学习的应用落地仍然不太乐观。
直到大模型训练把整套逻辑发扬光大了。
强化学习四阶段(猜测未来):
直到现在,我们有一次在讨论强化学习和监督学习分界线的时候,大家都一时语塞。某数学系的老哥给出一个定义。
- 监督学习优化的是 非参分布下的含参loss function
- 强化学习优化的是 含参分布下的非参loss (cost/reward) function?
公式如下:
但我说这个公式可以做轻微推导:
这时我们得到了一个暴论:监督学习只是强化学习的一个特例。
具体的case也不难获得,例如在二分类问题中,状态是输入特征,输出是0/1,奖励是分类正确了给1,分类错误了给0。基于PG的推导公式跟二分类entropy loss是完全一致的。无监督的例子跟强化学习的关系也可以得到类似的推导。
那我们熟知的概念:机器学习分为监督学习、无监督学习和强化学习。
变成了:机器学习就是强化学习,监督学习和无监督学习只是其中的特例。
那么强化学习的应用也就会变得越来越多,让人们觉得它越来越有用。
后记:
写到这一块我开始杞人忧天,难以下笔。我开始思考这种发展对于RLer来说是否健康的。
持反对意见的领域就是文章开头的祖师爷sutton,祖师爷理论上是这一波RL概念扩大收益最大的人,但祖师爷在talking上表达了他的观点:
甚至在某次和小伙伴的交流中,祖师爷说RLHF是scam,持完全的否定态度。
但作为一个强化学习研究者,并尝试去进行AI应用落地的人来说,至少这波RL概念扩大,让RLer吃上了饭,甚至吃上了好饭,应该还是要对此心怀感激的吧。

















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









