







我自己的原文哦~ https://blog.51cto.com/whaosoft/12131903
#视觉大模型
围绕基础模型在视觉领域的发展,综合全面的从经典的架构设计、训练目标以及主流的微调数据集等系统的梳理基础模型的发展脉络。
众所周知,视觉系统对于理解和推理视觉场景的组成特性至关重要。这个领域的挑战在于对象之间的复杂关系、位置、歧义、以及现实环境中的变化等。作为人类,我们可以很轻松地借助各种模态,包括但不仅限于视觉、语言、声音等来理解和感知这个世界。现如今,随着 Transformer 等关键技术的提出,以往看似独立的各个方向也逐渐紧密地联结到一起,组成了“多模态”的概念。
今天,我们主要围绕Foundational Models,即基础模型这个概念,向大家全面阐述一个崭新的视觉系统。例如,通过 SAM,我们可以轻松地通过点或框的提示来分割特定对象,而无需重新训练;通过指定图像或视频场景中感兴趣的区域,我们可以与模型进行多轮针对式的交互式对话;再如李飞飞团队最新展示的科研成果所示的那样,我们可以轻松地通过语言指令来操作机器人的行为。

该术语首次由
Bommasani等人在《Stanford Institute for Human-Centered AI》中引入。基础模型定义为“通过自监督或半监督方式在大规模数据上训练的模型,可以适应其它多个下游任务”。
具体地,我们将一起讨论一些典型的架构设计,这些设计结合了不同的模态信息,包括视觉、文本、音频;此外,我们还将着重讨论不同的训练目标,如对比式学习和生成式学习。随后,关于一些主流的预训练数据集、微调机制以及常见的提示模式,我们也将逐一介绍。
最后,希望通过今天的学习让大家对基础模型在计算机视觉领域的发展情况,特别是在大规模训练和不同任务之间的适应性方面的最新进展有一个大致的认知。共勉。
背景介绍
近年来,基础模型取得了显著的成功,特别是通过大型语言模型(LLMs),主要归因于数据和模型规模的大幅扩展。例如,像GPT-3这样的十亿参数模型已成功用于零/少样本学习,而无需大量的任务特定数据或模型参数更新。与此同时,有5400亿参数的Pathways Language Model(PaLM)在许多领域展现了先进的能力,包括语言理解、生成、推理和与代码相关的任务。
反观视觉领域,诸如CLIP这样的预训练视觉语言模型在不同的下游视觉任务上展现了强大的零样本泛化性能。这些模型通常使用从网络收集的数百上千万图像-文本对进行训练,并提供具有泛化和迁移能力的表示。因此,只需通过简单的自然语言描述和提示,这些预训练的基础模型完全被应用到下游任务,例如使用精心设计的提示进行零样本分类。

CLIP-DEMO
除了此类大型视觉语言基础模型外,一些研究工作也致力于开发可以通过视觉输入提示的大型基础模型。例如,最近 META 推出的 SAM 能够执行与类别无关的分割,给定图像和视觉提示(如框、点或蒙版),指定要在图像中分割的内容。这样的模型可以轻松适应特定的下游任务,如医学图像分割、视频对象分割、机器人技术和遥感等。

当然,我们同样可以将多种模态一起串起来,组成更有意思的管道,如RAM+Grounding-DINO+SAM:

这里我们用 RAM 提取了图像的语义标签,再通过将标签输入到 Grounding-DINO 中进行开放世界检测,最后再通过将检测作为 SAM 的提示分割一切。目前视觉基础大模型可以粗略的归为三类:
-
textually prompted models, e.g., contrastive, generative, hybrid, and conversational; -
visually prompted models, e.g., SAM, SegGPT; -
heterogeneous modalities-based models, e.g., ImageBind, Valley.

图1. 视觉基础模型预览
基础架构

图2.四种不同风格的架构类型
- 双编码器架构:其中,独立的编码器用于处理视觉和文本模态,这些编码器的输出随后通过目标函数进行优化。
- 融合架构:包括一个额外的融合编码器,它获取由视觉和文本编码器生成的表示,并学习融合表示。
- 编码器-解码器架构:由基于编码器-解码器的语言模型和视觉编码器共同组成。
- 自适应 LLM 架构:利用大型语言模型(LLM)作为其核心组件,并采用视觉编码器将图像转换为与 LLM 兼容的格式(模态对齐)。
目标函数
对比式学习
为了从无标签的图像-文本数据中学习,CLIP 中使用了简单的图像-文本对比(ITC)损失来通过学习正确的图像-文本配对来学习表示。此外还有图像-文本匹配(ITM)损失,以及包括简单对比式学习表示(SimCLR)和 ITC 损失的变体(如 FILIP Loss、TPC Loss、RWA、MITC、UniCL、RWC 损失)等其他对比损失。

这里 表示温度系数。因此我们可以将 简单表示为 . 可以看出, 本质上还是在计算图像与文本之间的相似度得分,比如常见的余弦相似性。
生成式学习
生成目标包括以下几种典型的损失:
- 掩码语言建模(MLM)损失
![]()
- 语言建模(LM)损失

- 标准字幕(Cap)损失

以及 Flamingo Loss、Prefix Language Modeling, PrefixML 等。从上述公式我们也可以很容易看出,生成式 AI 本质还是条件概率模型,如 Cap 损失便是根据上一个已知 token 或 图像来预测下一个 token。
预训练
预训练数据集
如上所述,现代视觉-语言基础模型的核心是大规模数据,大致可分为几类:
- 图像-文本数据:例如
CLIP使用的WebImageText等,这些数据通常从网络抓取,并经过过滤过程删除噪声、无用或有害的数据点。 - 部分伪标签数据:由于大规模训练数据在网络上不可用,收集这些数据也很昂贵,因此可以使用一个好的教师将图像-文本数据集转换为掩码-描述数据集,如
GLIP和SA-1B等。 - 数据集组合:有些工作直接将基准视觉数据集组合使用,这些作品组合了具有图像-文本对的数据集,如字幕和视觉问题回答等。一些工作还使用了非图像-文本数据集,并使用基于模板的提示工程将标签转换为描述。
微调
微调主要用于三个基本设置:
- 提高模型在特定任务上的性能(例如开放世界物体检测,
Grounding-DINO); - 提高模型在某一特定能力上的性能(例如视觉定位);
- 指导调整模型以解决不同的下游视觉任务(例如
InstructBLIP)。
首先,许多工作展示,即使只采用线性探测,也可以提高模型在特定任务上的性能。因此,特定任务的数据集(例如ImageNet)是可以用来改善预训练模型的特定任务性能。其次,一些工作已经利用预训练的视觉语言模型,通过在定位数据集上微调模型来进行定位任务。
例如,谷歌的一篇 OVD 工作 OWL-ViT,将 CLIP 预训练模型去掉 Token Pooling+projection 和 Image projection,加上一个新的 Linear Projection 作为分类头与文本进行匹配,学习出每个 Patch 的语义信息。此外在将 Patch 的表征经过 MLP head 回归出相应检测狂。通过 Patch 的语义特征与 BBox 的位置最终获得目标检测框。最后,像 InstructBLIP 则将视觉数据集转换为指导调整数据集,使视觉语言模型能够用于下游任务。

InstructBLIP
提示工程
提示工程主要是搭配大型语言模型(LLMs)一起使用,使它们能够完成某些特定的任务。在视觉语言模型或视觉提示模型的背景下,提示工程主要用于两个目的:
- 将视觉数据集转换为图像文本训练数据(例如,用于图像分类的 CLIP),为基础模型提供交互性
- 使用视觉语言模型进行视觉任务。
大多数视觉数据集由图像和相应文本标签组成。为了利用视觉语言模型处理视觉数据集,一些工作已经利用了基于模板的提示工程。在这种提示工程中,使用一组模板从标签生成描述。例如:
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()这种额外的上下文有助于模型学习,因此,这些文本提示可以在训练或评估期间被 VLM 所使用。下面让我们一起了解下这三类视觉基础模型。

基于文本提示的基础模型
在本章节中,我们专注于探讨依赖文本作为主要监督来源的方法。这些文字提示模型大致分为三个主要类型,即基于不同的训练目标:对比学习、生成学习和混合方法。
基于对比学习的方法
首先,让我们一起回顾下 CLIP 架构及其衍生的变体:

CLIP and it's variants.
CLIP 由 OpenAI 于 2021 年正式提出,其联合训练图像和文本编码器以预测图像与标题在批量中的正确配对。CLIP 由图像编码器和文本编码器组成。它们产生了N个图像-文本对的多模态嵌入空间。通过对称交叉熵损失来训练,以最小化N个正确图像-文本对的嵌入的余弦相似度,并最大化N²-N个不正确对的余弦相似度。作者还从互联网上策划了4亿图像-文本对的数据集。在这样的大规模数据集上训练时,表现非常出色,也激发了后续许多的工作。
此处我们集中探讨两类扩展方法,包括通用模型的对比方法和视觉定位基础模型的方法。
基于通用模型的对比方法

ALIGN
ALIGN 利用了一个超过10亿个图像-文本对的噪声数据集,无须进行昂贵的过滤或处理步骤即可在 Conceptual Captions 数据集中获得。一个简单的双编码器架构学习使用对比性损失来对齐图像和文本对的视觉和语言表示。结果表明,即便是这样一个简单的学习方案,只要数据库够大,便可以弥补它的噪声,并最终得到 SOTA 结果。

Florence
佛罗伦萨是微软、OpenAI 等联合提出的一个真正意义上的计算机视觉基础模型,能够处理不同的空间、时间和模态。它从CLIP样的预训练开始,然后扩展为具有三个不同适配器头的每个空间。弱弱的说一句,虽然这个模型的预训练参数只有 893M,但却需要在 512 块 A100 上训练 10 天的时间。

FILIP
FILIP 提出了一种交叉模态的后期交互方法,以捕捉细粒度语义对齐。FILIP 损失最大化了视觉和文本嵌入之间逐标记的相似性,有助于在不牺牲 CLIP 的推理效率的情况下,模拟两种模态之间的细粒度交互。【作者在 VALSE 第59期分享过,有兴趣的可以去看看,B站上有视频】
此外还有基于掩码对比学习的方法,这是一种通过遮挡输入像素来提高对比学习效率的有效方法。下面我们也将介绍几种典型方法。

FLIP
FLIP 是一种简单和更有效的训练 CLIP 的方法,其思想很简单,如图所示,就是将 MAE 的 Mask 操作引入到 CLIP 上,随机地 mask 掉具有高 mask 率的图像碎片,只对可见的碎片进行编码。不同之处在于,这里不会对被 masked 的图像内容进行重建。此外,对于文本也做同样处理,有点类似于 BERT 但又不一样,BERT 是用学习过的 mask token 来代替它们,这种稀疏的计算可以显著减少文本编码的成本。

MaskCLIP
MaskCLIP 强调了图像是一个连续且细粒度的信号,而语言描述可能无法完全表达这一点。因此,MaskCLIP 通过随机遮挡图像并利用基于 Mean Teacher 的自蒸馏来学习局部语义特征。

EVA
这是一个以视觉为中心的基础模型,旨在仅使用可公开访问的数据来探索大规模视觉表示的局限性。EVA 是由智源曹越团队最新开源的视觉预训练模型,通过将最强语义学习(CLIP)与最强几何结构学习(MIM)结合,仅需使用标准的 ViT 模型,并将其规模扩大到十亿参数(1-Billion)进行训练,即可得到当前最强大的十亿级视觉基础模型。
通过重构 CLIP 特征来进行 MIM 操作。首先, CLIP 模型输入为完整的图像,而 EVA 模型的输入为有遮挡的图像,训练过程是让 EVA 模型遮挡部分的输出去重构 CLIP 模型对应位置的输出,从而以简单高效的方式让 EVA 模型同时拥有了最强语义学习 CLIP 的能力和最强几何结构学习 MIM 的能力。
很多的方法,总体而言,这些方法通过各种技术,如调整架构,改进对比目标,引入噪声鲁棒性,和探索多模态交互等,不断推动了 CLIP 及其变种的发展。这些努力已经展示了在许多任务上,包括零样本分类和图像-文本检索任务等方面,如何改善模型的性能,从而使这些模型在计算机视觉和自然语言处理的交叉领域中变得越来越重要。
基于视觉定位基础模型的方法

首先我们看下上图展示的结果,可以观察到,原始的 CLIP 模型其实是不擅长视觉定位任务的,特别是针对语义分割这种像素级定位任务来说。

RegionCLIP
RegionCLIP 显着扩展了 CLIP 以学习区域级视觉表示,其支持图像区域和文本概念之间的细粒度对齐,从而支持基于区域的推理任务,包括零样本目标检测和开放词汇目标检测。

CRIS
CRIS则通过引入视觉-语言解码器和文本到像素对比损失,使 CLIP 框架学习像素级信息。

Grounding DINO 是由沈向洋领导的 IDEA 实验室开源的,该方案利用了强大的预训练模型,并通过对比学习进行修改,以增强与语言的对齐。当然,像 OWL-ViT 也是类似的工作。此外, IDEA 还基于 SAM 等基础模型开源了一个集各大基础模型的仓库Grounded-Segment-Anything,仓库几乎涵盖了市面上主流的视觉基础模型,感兴趣的也可以关注下:


最后,我们一起看下 OpenSeg 和 GroupViT,这些方法着重于分组机制和分割效果,以通过对比学习实现更好的语义分割和目标检测。
简单来说,以上讨论涵盖了一系列现代基础模型研究,这些方法试图通过对比学习、掩码学习、扩展和复现等技术来改进CLIP和其它基础模型。这些工作不仅推动了大规模图像-文本建模的前沿,还为诸如目标检测、语义分割等特定视觉任务的解决方案提供了新的方法和框架。
基于生成式的方法
基于生成式方法的视觉基础模型的总结涵盖了多个领域和方向,下面笔者简单归纳总结下。首先是结合大语言模型(Large Language Model, LLM)的多模态学习范式:
- 结合上下文的多模态输入学习:例如
Frozen 方法将图像编码器与 LLM 结合,无需更新 LLM 的权重,而是在带有图像标注的数据集上训练视觉编码器。类似地,Flamingo 模型采用了固定的预训练视觉和语言模型,并通过Perceiver Resampler进行连接。 - 使用
LLM作为其它模态的通用接口:如MetaLM模型采用半因果结构,将双向编码器通过连接层连接到解码器上,可实现多任务微调和指令调整零样本学习。此外,KOSMOS系列也在LLM上整合了多模态学习的能力。 - 开源版本的模型:如
OpenFlamingo,是Flamingo模型的开源版本,训练于新的多模态数据集。
其次我们来看下视觉-语言对齐与定位相关的模型:
- 具备定位能力的模型:
KOSMOS-2通过添加一条管线来抽取文本中的名词短语并将其与图像中的相应区域链接起来,进而实现视觉定位。
另外就是通用生成目标下的训练:
- 简化视觉语言建模:如
SimVLM使用前缀语言建模(PrefixLM)目标进行训练,不需要任务特定的架构或训练,可在多个视觉语言任务上实现优秀的性能。 - 掩码重构与对齐:如
MaskVLM,采用联合掩码重构语言建模,其中一个输入的掩码部分由另一个未掩码输入重构,有效对齐两个模态。 - 模块化视觉语言模型:如
mPLUG-OWL,由图像编码器、图像抽象器和冻结LLM组成,通过两阶段的训练实现多模态对话和理解。
此外还有与对比学习的比较与结合:

CapPa
CapPa 是基于字幕的模型与 CLIP 风格模型的比较得到的一种新的生成预训练方法,交替使用自回归预测和并行预测。
总体而言,上述的方法和模型通过在视觉条件下训练语言生成任务,为 LLM 增添了“看世界”的能力。这些工作在视觉语言任务,如图像标注、多模态对话和理解等方面取得了显著进展,有的甚至在少样本情况下达到或超越了最先进的性能。通过将视觉和语言模态结合,这些模型为计算机视觉和自然语言处理的交叉领域提供了强大的新工具。
基于对比学习和生成式的混合方法
通用视觉-语言学习的基础模型:
-
UNITER:结合了生成(例如掩码语言建模和掩码区域建模)和对比(例如图像文本匹配和单词区域对齐)目标的方法,适用于异构的视觉-语言任务。 -
Pixel2Seqv2:将四个核心视觉任务统一为像素到序列的接口,使用编码器-解码器架构进行训练。 -
Vision-Language:使用像 BART 或 T5 等预训练的编码器-解码器语言模型来学习不同的计算机视觉任务。
通用架构:

FLAVA
-
Contrastive Captioner (CoCa):结合了对比损失和生成式的字幕损失,可以在多样的视觉数据集上表现良好。 -
FLAVA:适用于单模态和多模态任务,通过一系列损失函数进行训练,以便在视觉、语言和视觉-语言任务上表现良好。 -
BridgeTower:结合了不同层次的单模态解码器的信息,不影响执行单模态任务的能力。 -
PaLI:一种共同扩展的多语言模块化语言-视觉模型,适用于单模态和多模态任务。 -
X-FM:包括语言、视觉和融合编码器的新基础模型,通过组合目标和新技术进行训练。
BLIP 框架范式:
-
BLIP:利用生成和理解能力有效利用图像文本数据集,采用Multimodal mixture of Encoder-Decoder (MED)架构。 -
BLIP-2:通过查询转换器来实现计算效率高的模态间对齐。
指令感知特征提取和多模态任务解决方案:
-
InstructBLIP:利用视觉编码器、Q-Former和LLM,通过指令感知的视觉特征提取来进行训练。对预训练模型的高效利用: -
VPGTrans:提供了一种高效的方法来跨 LLM 传输视觉编码器。 -
TaCA:提到了一种叫做 TaCA 的适配器,但没有进一步详细描述。

UniDetector
基于 Visual Grounding 的方法:
-
ViLD:这一方法使用了一个两阶段的开放词汇对象检测系统,从预训练的单词汇分类模型中提取知识。它包括一个 RPN 和一个类似于 CLIP 的视觉语言模型,使用 Mask-RCNN 创建对象提案,然后将知识提取到对象检测器中。 -
UniDetector: 此方法旨在进行通用对象检测,以在开放世界中检测新的类别。它采用了三阶段训练方法,包括类似于上面我们提到的RegionCLIP的预训练、异构数据集训练以及用于新类别检测的概率校准。UniDetector 为大词汇和封闭词汇对象检测设立了新的标准。 -
X-Decoder: 在三个粒度层次(图像级别、对象级别和像素级别)上运作,以利用任务协同作用。它基于 Mask2Former,采用多尺度图像特征和两组查询来解码分割掩码,从而促进各种任务。它在广泛的分割和视觉语言任务中展现出强大的可转移性。
这些方法共同探讨了视觉定位任务的不同维度,包括开放词汇对象检测、通用对象检测、两阶段训练、多级粒度和新颖的损失功能。它们共同通过以创新的方式整合视觉和语言来推动视觉理解的界限,往往超越了该领域以前的基准。简单总结下,上面我们展示了如何通过对比和生成式学习,以及混合这些方法,来设计和训练可以处理各种视觉和语言任务的模型。有些模型主要关注提高单模态和多模态任务的性能,而有些模型关注如何高效地训练和利用预训练模型。总的来说,这些研究提供了视觉-语言融合研究的丰富视角和多样化方法,以满足不同的实际需求和应用场景。
基于对话式的视觉语言模型
这一块我们不做过多介绍,仅介绍比较有代表性的几个工作:

GPT-4
GPT-4:这是首个结合视觉和语言的模型,能够进行多模态对话。该模型基于Transformer架构,通过使用公开和私有数据集进行预训练,并通过人类反馈进行强化学习微调。根据公开的数据,GPT-4 在多个 NLP、视觉和视觉-语言任务上表现出色,但很可惜目前并未开源。

miniGPT-4
miniGPT-4:作为GPT-4的开源版本,miniGPT-4 由预训练的大型语言模型Vicuna和视觉组件ViT-G和Q-Former组成。模型先在多模态示例上进行训练,然后在高质量的图像和文本对上进行微调。miniGPT-4 能够生成复杂的图像描述并解释视觉场景。XrayGPT:这个模型可以分析和回答有关 X 射线放射图的开放式问题。使用Vicuna LLM作为文本编码器和MedClip作为图像编码器,通过更新单个线性投影层来进行多模态对齐。LLaVA:这是一个开源的视觉指令调整框架和模型,由两个主要贡献组成:开发一种用于整理多模态指令跟踪数据的经济方法,以及开发一个大型多模态模型,该模型结合了预训练的语言模型LLaMA和CLIP的视觉编码器。

LLaMA-Adapter V2
LLaMA-Adapter V2:通过引入视觉专家,早期融合视觉知识,增加可学习参数等方式,改善了LLaMA的指令跟随能力,提高了在传统视觉-语言任务上的性能。综上所述,基于对话的视觉语言模型在理解、推理和进行人类对话方面取得了显著进展。通过将视觉和语言结合在一起,这些模型不仅在传统 NLP 任务上表现出色,而且能够解释复杂的视觉场景,甚至能够与人类进行复杂的多模态对话。未来可能会有更多的工作致力于提高这些模型的可解释性、可用性和可访问性,以便在更广泛的应用领域中实现其潜力。

基于视觉提示的基础模型
这一块内容我们先为大家阐述几个代表性的基于视觉提示的基础模型,如 SAM 和 SEEM 等;随后再介绍基于 SAM 的一系列改进和应用,例如用在医疗、遥感、视频追踪等领域;最后再简单介绍下几个通用的扩展。
视觉基础模型
CLIPSeg

CLIPSeg
- 概述:CLIPSeg 利用 CLIP 的泛化能力执行
zero-shot 和 one-shot 分割任务。 - 结构:由基于 CLIP 的图像和文本编码器以及具有 U-net 式跳跃连接的基于
Transformer 的解码器组成。 - 工作方式:视觉和文本查询通过相应的 CLIP 编码器获取嵌入,然后馈送到 CLIPSeg 解码器。因此,CLIPSeg 可以基于任意提示在测试时生成图像分割。
SegGPT

SegGPT
SegGPT 旨在训练一个通用模型,可以用于解决所有的分割任务,其训练被制定为一个上下文着色问题,为每个数据样本随机分配颜色映射。目标是根据上下文完成不同的分割任务,而不是依赖于特定的颜色。
SAM

概述:SAM 是一种零样本分割模型,从头开始训练,不依赖于 CLIP。结构:使用图像和提示编码器对图像和视觉提示进行编码,然后在轻量级掩码解码器中组合以预测分割掩码。训练方法:通过三阶段的数据注释过程(辅助手动、半自动和全自动)训练。
SEEM

与 SAM 相比,SEEM 涵盖了更广泛的交互和语义层面。例如,SAM 只支持有限的交互类型,如点和框,而由于它本身不输出语义标签,因此错过了高语义任务。
首先,SEEM 有一个统一的提示编码器,将所有视觉和语言提示编码到联合表示空间中。因此,SEEM 可以支持更通用的用途。它有潜力扩展到自定义提示。其次,SEEM 在文本掩码(基础分割)方面非常有效,并输出语义感知预测。
SAM 的改进与应用
SAM for Medical Segmentation

Medical SAM 总览
- Adapting by Fine-Tuning
MedSAM:通过在大规模医学分割数据集上微调 SAM,创建了一个用于通用医学图像分割的扩展方法 MedSAM。这一方法在 21 个 3D 分割任务和 9 个 2D 分割任务上优于 SAM。

MedSAM
paper: https://arxiv.org/pdf/2304.12306.pdf
github: https://github.com/bowang-lab/MedSAM
- Adapting through Auxiliary Prompt Encoder
AutoSAM:为SAM的提示生成了一个完全自动化的解决方案,基于输入图像由AutoSAM辅助提示编码器网络生成替代提示。AutoSAM 与原始的 SAM 相比具有更少的可训练参数。

AutoSAM
- Adapting Through Adapters

Learnable Ophthalmology SAM
在眼科的多目标分割:通过学习新的可学习的提示层对SAM进行了一次微调,从而准确地分割不同的模态图像中的血管或病变或视网膜层。

3DSAM-adapter
3DSAM-adapter:为了适应3D空间信息,提出了一种修改图像编码器的方案,使原始的2D变换器能够适应体积输入。

Medical SAM Adapter
Medical SAM Adapter:专为SAM设计了一个通用的医学图像分割适配器,能够适应医学数据的高维度(3D)以及独特的视觉提示,如 point 和 box。
- Adapting by Modifying SAM’s Decoder

DeSAM
DeSAM:提出了将 SAM 的掩码解码器分成两个子任务:提示相关的 IoU 回归和提示不变的掩码学习。DeSAM 最小化了错误提示在“分割一切”模式下对SAM性能的降低。
- SAM as a Medical Annotator

MedLAM
MedLAM:提出了一个使用 SAM 的医学数据集注释过程,并引入了一个少量定位框架。MedLAM 显著减少了注释负担,自动识别整个待注释数据集的目标解剖区域。

SAMM
Segment Any Medical Model, SAMM:这是一个结合了3D Slicer和SAM的医学图像分割工具,协助开发、评估和应用SAM。通过与3D Slicer的整合,研究人员可以使用先进的基础模型来分割医学图像。
总体来说,通过各种微调、适配和修改方法,SAM 已被成功适应了用于医学图像分割的任务,涵盖了从器官、病变到组织的不同医学图像。这些方法也突出了将自然图像的深度学习技术迁移到医学领域的潜力和挑战。在未来,SAM 及其变体可能会继续推动医学图像分析领域的进展。
SAM for Tracking
SAM 在跟踪任务方面的应用集中在通过视频中的帧跟踪和分割任意对象,通常被称为视频对象分割(VOS)。这个任务涉及在一般场景中识别和追踪感兴趣的区域。以下总结下 SAM 在跟踪方面的一些主要应用和方法:
- Track Anything (TAM)

TAM
概述:TAM 使用 SAM 和现成的跟踪器 XMem 来分割和跟踪视频中的任何对象。操作方式:用户可以简单地点击一个对象以初始化 SAM 并预测掩码。然后,XMem 使用 SAM提供的初始掩码预测在视频中基于时空对应关系跟踪对象。用户可以暂停跟踪过程并立即纠正任何错误。挑战:虽然表现良好,但 TAM 在零样本场景下不能有效保留 SAM 的原始性能。
- SAM-Track

SAM-Track
概述:与 TAM 类似,SAM-Track 使用 DeAOT 与 SAM 结合。挑战:与 TAM 类似,SAM-Track 在零样本场景下也存在性能挑战。
- SAM-PT

SAM-PT
概述:SAM-PT 通过结合 SAM 的稀疏点跟踪来解决视频分割问题。只需要第一帧的稀疏点注释来表示目标对象。强项:在开放世界 UVO 基准测试中展示了对未见对象的泛化能力。操作方式:使用像 PIPS 这样的先进点跟踪器,SAM-PT 为视频分割提供稀疏点轨迹预测。进一步地,为了区分目标对象及其背景,SAM-PT 同时跟踪正点和负点。
- SAM-DA

SAM-DA
概述:SAM-DA 是另一种使用 SAM 自动分割能力进行跟踪的方法。具体应用:通过使用 SAM 自动分割功能从每个夜间图像自动确定大量高质量目标域训练样本,从而跟踪夜间无人机(UAVs)。
SAM 在视频对象跟踪和分割方面的应用表明了其作为分割基础模型的潜力。尽管有一些挑战,特别是在未见数据和零样本场景下,但通过与现成的跟踪器的结合以及稀疏点跟踪的使用,SAM 能够实现在视频中跟踪和分割对象。这些方法为计算机视觉社区提供了一个实现通用场景中任意对象跟踪的有力工具,有助于推动视频分析和监控等领域的进展。
SAM for Remote Sensing
SAM 在遥感图像分割方面的应用集中在通过点、框和粗粒度掩码的引导来理解和分割遥感图像。以下是 SAM 在遥感分割方面的应用以及相关挑战。
SAM在遥感分割的基本应用
- 交互性质:由于 SAM 的交互特性,它主要依赖于点、框和粗粒度掩码的手动引导。
- 限制:
- 全自动分割困难:SAM在完全自动地理解遥感图像方面效果不佳。
- 结果依赖性:SAM的结果严重依赖于用于分割遥感图像目标的提示的类型、位置和数量。
- 手动提示优化需求:要实现理想的结果,通常需要对手动提示进行精炼。

RsPrompter
概述:RsPrompter 是一个将语义分类信息与 SAM 结合的方法,用于遥感图像的自动实例分割。
操作方式:学习生成提示:RsPrompter 提出了一种学习生成适当的SAM输入提示的方法。生成提示包含的信息:通过分析编码器的中间层来生成包含关于语义类别的信息的提示,并生成提示嵌入,这可以视为点或框嵌入。目标:通过自动化生成适当的输入提示,RsPrompter 试图克服 SAM 在遥感图像分割方面的局限性。
尽管 SAM 在遥感图像分割方面存在一些限制,主要与其交互性质和对手动引导的依赖有关,但通过引入如 RsPrompter 这样的方法,可以利用 SAM 实现遥感图像的自动实例分割。这些努力标志着朝着减少人工干预和提高遥感图像分析自动化的方向迈出的重要一步,有势必推动遥感科学、地理信息系统(GIS)和环境监测等领域的进展。
SAM for Captioning
SAM 与大型语言模型如 ChatGPT 的组合在可控图像字幕(controlled image captioning)方面开辟了新的应用领域。下面概述下这种组合在图像字幕上的具体应用。
先给大家介绍下概念,可控图像字幕使用自然语言来根据人类目标解释图像,例如检查图像的某些区域或以特定方式描述图像。然而,这种交互式图像字幕系统的可扩展性和可用性受到缺乏良好注释的多模态数据的限制。一个典型的案例便是 Caption AnyThing,下面一起看看。

Caption AnyThing
概述:Caption AnyThing 是一种零样本图像字幕模型,通过与 SAM 和大型语言模型(例如ChatGPT)结合,使用预训练的图像字幕器实现。
工作流程:
- 定义视觉控制:用户可以通过视觉提示定义视觉控制。
- 使用SAM转换为掩码:视觉提示随后使用SAM转换为掩码,以选择感兴趣的区域。
- 预测原始字幕:基于原始图像和提供的掩码,图像字幕器预测原始字幕。
- 文本优化:使用大型语言模型(例如ChatGPT)的文本精炼器,根据用户的偏好定制语言风格,从而优化原始描述。
结果:用户可以通过控制视觉和语言方面,更精确地描述图像中的特定部分或属性。
优势和意义
- 用户自定义:通过允许用户定义视觉和语言控制,提供了高度定制的解释。
- 灵活性和准确性:通过结合视觉分割和自然语言处理,增强了描述的灵活性和准确性。
- 零样本学习:由于是零样本模型,因此可以在未经特定训练的新图像和场景上工作。
通过结合 SAM 的图像分割能力和大型语言模型如 ChatGPT 的自然语言处理能力,Caption AnyThing 为可控图像字幕开辟了新的可能性。这不仅增强了字幕的灵活性和准确性,还允许用户定制语言风格和焦点,从而促进了交互图像分析和解释的发展
SAM for Mobile Applications
这一节我们重点梳理下 SAM 的一些移动端应用,主要就是加速 SAM 的推理和提升 SAM 的分割质量。

FastSAM
FastSAM 基于 YOLOv8-seg 实现,它比 SAM 快50倍,且训练数据只有SAM的1/50,同时运行速度不受 point 输入数量的影响

MobileSAM
MobileSAM:将原始 SAM 中的图像编码器 ViT-H 的知识蒸馏到一个轻量化的图像编码器中,该编码器可以自动与原始 SAM 中的 Mask 解码器兼容。训练可以在不到一天的时间内在单个 GPU 上完成,它比原始 SAM 小60多倍,但性能与原始 SAM 相当。

MobileSAM
RefSAM:这是一种高效的端到端基于 SAM 的框架,用于指代视频对象分割(RVOS)。它使用了高效且轻量级的CrossModal MLP,将指代表达的文本特征转换为密集和稀疏的特征表示。

HQ-SAM
HQ-SAM: HQ-SAM 为了实现高质量的掩膜预测,将 HQ-Output Token(高质量输出标记)和全局-局部特征融合引入到SAM中。为了保持SAM的零样本能力,轻量级的 HQ-Output Token 复用了 SAM 的掩膜解码器,并生成了新的 MLP(多层感知器)层来执行与融合后的 HQ-Features(高质量特征)的逐点乘积。在训练期间,将预训练的 SAM 的模型参数固定,只有 HQ-SAM 中的少数可学习参数可以进行训练。
通才模型
这一类主要描述如何使用上下文学习快速适应具有不同提示和示例的各种任务。这里特别突出了几个被称为通才模型(Generalist Models)的模型,它们可以执行多个任务,甚至可以通过提示和少量特定于任务的示例来适应新任务。
Painter

Painter
Painter是一种通才模型,可以同时执行不同的任务,甚至可以根据提示和非常少的特定于任务的示例适应新任务。
工作方式:给定某个任务的输入和输出图像,输出图像的像素被遮挡。Painter 模型的目标是对 masked 的输出图像进行填充。训练目标:这个简单的训练目标允许统一几个视觉任务,包括深度估计、人体关键点检测、语义分割、实例分割、图像去噪、图像去雨和图像增强。推理流程:在训练后,Painter 可以使用与输入条件相同任务的输入/输出配对图像来确定在推理过程中执行哪个任务。
VisionLLM

VisionLLM
VisionLLM是另一个通才模型,可以对齐视觉和语言模态以解决开放式任务。
工作方式:给定图像,VisionLLM 使用视觉模型学习图像特征;这些图像特征与例如“详细描述图像”的语言指令一起传递给语言引导的图像分词器。任务解码器:图像分词器的输出连同语言指令被提供给一个开放式 LLM 为基础的任务解码器,旨在根据语言指令协调各种任务。
Prismer

Prismer
Prismer也是一种视觉语言模型,可以执行多个推理任务。
特点:Prismer 利用各种预训练的领域专家,例如语义分割、对象、文本和边缘检测,表面法线和深度估计,来执行多个推理任务。应用:例如图像字幕和视觉问题回答。
通才模型表示了一种通用的趋势,其中模型可以通过改变输入或少量特定于任务的训练来适应新的或多样化的任务。这些模型在解决问题时可以灵活地适应,克服了单一任务模型的限制。尤其是在输出表示在任务之间有很大差异的计算机视觉中,这一点变得尤为重要。通过简化训练目标和建立跨任务的框架,这些通才模型为未来计算机视觉任务的多功能性提供了新的机会。
综合性基础模型
基于异构架构的基础视觉模型
在这一部分,我们集中讨论不同的基础视觉模型,这些模型通过对齐多个成对的模态,如图像-文本、视频-音频或图像-深度等,来学习更有意义的表示。
CLIP 与异构模态的对齐

CLIP2Video
CLIP2Video:这一模型扩展了CLIP模型,使其适用于视频。通过引入时序一致性和提出的时序差异块(TDB)和时序对齐块(TAB),将图像-文本的CLIP模型的空间语义转移到视频-文本检索问题中。

AudioCLIP
AudioCLIP:这一模型扩展了CLIP,使其能够处理音频。AudioCLIP结合了ESResNeXt音频模型,并在训练后能够同时处理三种模态,并在环境声音分类任务中胜过先前方法。
学习共享表示的多模态模型

ImageBind
Image Bind:这一模型通过学习配对数据模态(如(视频,音频)或(图像,深度))的共同表示,包括多种模态。ImageBind 将大规模配对数据(图像,文本)与其他配对数据模态相结合,从而跨音频、深度、热和惯性测量单元(IMU)等四种模态扩展零样本能力。

MACAW-LLM
MACAW-LLM:这是一种指令调谐的多模态 LLM(大型语言模型),整合了图像、视频、音频和文本等四种不同模态。通过模态模块、对齐模块和认知模块,MACAW-LLM 实现了各种模态的统一。
视频和长篇幅文本的处理

COSA
COSA:通过将图像-文本语料库动态转换为长篇幅视频段落样本来解决视频所需的时序上下文缺失问题。通过随机串联图像-文本训练样本,确保事件和句子的显式对应,从而创造了丰富的场景转换和减少视觉冗余。

Valley
Valley: 是另一个能够整合视频、图像和语言感知的多模态框架。通过使用简单的投影模块来桥接视频、图像和语言模态,并通过指令调谐流水线与多语言 LLM 进一步统一。
这一节主要强调了将不同的感知模态(如视觉、听觉和文字)结合到统一框架中的重要性。通过跨模态学习和对齐,这些模型不仅提高了特定任务的性能,还扩展了多种模态的零样本学习能力。此外,考虑到视觉和听觉之间的时序一致性也是重要的创新方向。通过强调如何整合这些不同的输入形式,本节揭示了深度学习在处理更复杂和多样化数据方面的潜力。
基于代理的基础视觉模型
基于代理的基础视觉模型将语言学习模型(LLMs)与现实世界的视觉和物理传感器模式相结合。这不仅涉及文字的理解,还涉及与现实世界的互动和操作,特别是在机器人操作和导航方面。
机器人操控

Palm-E
Palm-E:该模型将连续的传感器输入嵌入到 LLM 中,从而允许机器人进行基于语言的序列决策。通过变换器,LLM将图像和状态估计等输入嵌入到与语言标记相同的潜在空间,并以相同的方式处理它们。

ViMA
ViMA:使用文本和视觉提示来表达一系列机器人操控任务,通过多模态提示来学习机器人操控。它还开发了一个包含600K专家轨迹的模拟基准测试,用于模仿学习。
持续学习者

MineDojo
MineDojo:为 Minecraft 中的开放任务提供了便利的API,并收集了丰富的 Minecraft 数据。它还使用这些数据为体现代理制定了新的学习算法。

VOYAGER
VOYAGER:这是一种由 LLM 驱动的终身学习代理,设计用于在 Minecraft 中探索、磨练技能并不断发现新事物。它还通过组合较小的程序逐渐构建技能库,以减轻与其他持续学习方法相关的灾难性遗忘。
导航规划

LM-Nav
LM-Nav:结合预训练的视觉和语言模型与目标控制器,从而在目标环境中进行长距离指导。通过使用视觉导航模型构建环境的“心理地图”,使用 GPT-3 解码自由形式的文本指示,并使用 CLIP将这些文本地标连接到拓扑图中,从而实现了这一目标。然后,它使用一种新的搜索算法找到了机器人的计划。
总体而言,基于代理的基础视觉模型突出了语言模型在现实世界任务中的潜力,如机器人操作、持续学习和复杂导航。它们不仅推动了机器人技术的进展,还为自然语言理解、多模态交互和现实世界应用开辟了新的研究方向。通过将预训练的大型语言模型与机器人技术和视觉导航相结合,基于代理的基础视觉模型能够解决现实世界中的复杂任务,展示了人工智能的跨学科整合和应用潜力。
总结
具有对多种模式(包括自然语言和视觉)基础理解的模型对于开发能有效感知和推理现实世界的AI系统至关重要。今天主要为大家概括了视觉和语言基础模型,重点关注了它们的架构类型、训练目标、下游任务适应性和提示设计。
多模态理解: 我们提供了对文本提示、视觉提示和异构模态模型的系统分类。这些模型不仅涵盖了自然语言,还包括了视觉和其他感知模式的理解。
应用广泛性: 这些模型在各种视觉任务中的应用非常广泛,包括零样本识别和定位能力、关于图像或视频的视觉对话、跨模态和医疗数据理解。
通用模型: 视觉中的基础模型可以作为通用模型来解决多个任务。当与大型语言模型相结合时,它们促生了可以在复杂环境中持续学习和导航的基础实体代理。
整体而言,基础视觉和语言模型的研究不仅深入了解了各种架构和训练目标,还展示了这些模型在多个领域和应用中的潜力。通过集成文本、视觉和其他模态的理解,这些模型促进了机器人技术和现实世界任务的进展。然而,还需要进一步的研究来充分挖掘这些模型的潜力,并解决一些存在的挑战和局限性。
#CD-ViTO
跨域小样本物体检测CD-FSOD新数据集、CD-ViTO新方法
本篇分享 ECCV 2024 论文Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector,跨域小样本物体检测 CD-FSOD 新数据集、CD-ViTO新方法(数据代码均已开源)。
作者单位:复旦大学,苏黎世联邦理工学院,INSAIT,东南大学,BOE科技
论文链接:https://arxiv.org/pdf/2402.03094
网页链接:http://yuqianfu.com/CDFSOD-benchmark/
中稿会议:ECCV 2024
摘要:这篇文章针对目前大多数跨域小样本学习方法均集中于研究分类任务而忽略了目标检测,因而提出研究跨域小样本物体检测任务, 文章中提出了一个用于算法评测的CD-FSOD数据集及用于衡量领域差异的style、ICV、IB数据集指标,对现有目标检测算法进行了广泛实验评估,以及基于优化一个在经典 FSOD 上达到 SOTA 的开放域物体检测器得到的 CD-ViTO 新方法。
1 研究目的
跨域小样本学习任务(Cross-Domain Few-Shot Learning,CD-FSL)解决的是源域与目标域存在领域差异情况下的小样本学习任务,即集合了小样本学习与跨域两个任务的难点问题:1)源域S与目标域T类别集合完全不同,且目标域T中的类别仅存在少量标注样本,例如1shot,5shot;2)S与T属于两个不同领域,例如从自然图像迁移到医疗图像。
大多数的现有方法均集中于研究分类问题,即Cross-Domain Few-Shot Classification, 但是同样很重要的物体检测任务(Object Detection,OD)却很少被研究,这促使了我们想要探究OD问题在跨域小样本的情况下是否也会遭遇挑战,以及是否会存在跟分类任务表现出不同的特性。
与CD-FSL是FSL在跨域下的分支类似,跨域小样本物体检测(Cross-Domain Few-Shot Object Detection,CD-FSOD)同样也可以堪称是FSOD在跨域下的分支任务,所以我们先从经典的FSOD开始分析:
大多数的FSOD方法都可以被粗略地划分为1)meta-learning based,典型方法包括Meta-RCNN;2)finetuning based,例如TFA,FSCE,DeFRCN,然而近期一个名为DE-ViT的开放域方法通过基于DINOv2构建物体检测器同时在FSOD以及开放域物体检测(OVD)上都达到了SOTA的效果,性能明显高于其他的FSOD方法,因此这引发了我们思考:
- 现有的FSOD方法,尤其是SOTA的DE-ViT open-set detector能不能在跨域的情况下仍表现优异?
- 如果不能,什么是难点问题,以及我们是否有办法能够提升open-set detector的性能?
我们先用以下的图来揭示一下问题的答案:

- 左图: 哪怕是SOTA的open-set detector DE-ViT (绿色星形) 在跨域泛化的情况下性能也会出现急剧下降;
- 左图: 我们基于DE-ViT搭建的CD-ViTO方法 (橙色星形) 能够使原本性能下降的模型得以进一步提升。
- 右图: 相比于in-domain的小样本物体检测,跨域小样本物体检测通常会面临三个问题:
- 目标域T的类间距离(ICV)通常较少;
- 目标域的图像可能会出现前景与背景边界模糊(Indifinable Boundary,IB);
- 目标域T得图像相交于源域S而言视觉风格(style)发生变化。
ICV、IB、Style也成为了我们用于衡量不同数据集在跨域下的特性。
2 主要贡献
首先总结一下我们在解答两个问题的过程中的主要工作及贡献:
2.1 Benchmark, Metrics, and Extensive study:
为了回答问题1,即研究现有的物体检测器能不能泛化至跨域小样本物体检测任务中,
- 我们研究了CD-FSOD任务下的三个影响跨域的数据集特性:Style, ICV, IB;
- 我们提出了一个CD-FSOD算法评测数据集,该数据集包含多样的style,ICV,IB;
- 我们对现有物体检测器进行了广泛研究,揭示了 CD-FSOD 带来的挑战。
2.2 New CD-ViTO Method:
为了回答问题2,即进一步提升基础DE-ViT在CD-FSOD下的性能,我们提出了一个新的CD-ViTO方法,该方法提出三个新的模块以解决跨域下的small ICV, indefinable boundary, 以及changing styles问题。
- Learnable Instance Features:通过将初始固定的图像特征与目标类别之间进行对齐,通过增强特征可分辨程度来解决目标域ICV距离小的问题 。
- Instance Reweighting Module: 通过给不同的图像设置不同的权重,使得严具有轻微 IB 的高质量实例分配更高的重要性,从而缓解显著的 IB 问题;
- Domain Prompter:通过合成虚拟领域而不改变语义内容来鼓励模型提升对不同style的鲁棒性。
3 CD-FSOD数据集 & Extensive Study3.1 CD-FSOD数据集
如下图所示为我们构建的CD-FSOD数据集,该数据集以MS-COCO作为源域S,以ArTaxOr、Clipart1K,DIOR,DeepFish,NEU-DET,UODD作为六个不同的目标域T;
我们也分析并在图中标注了每个数据集的Style,ICV,IB特征,每个数据与数据之间也展现了不同的数据集特性。
所有的数据集都整理成了统一的格式,并提供1shot、5shot、10shot用于模型测评。

数据集更多的介绍,比如数据类别数,样本数等可以在论文中找到细节。
3.2 Extensive Study
我们对现有的四类目标检测器进行了实验,包括:
- 典型的FSOD方法: Meta-RCNN、TFA、FSCE、DeFRCN
- 现有的CD-FSOD方法: Distill-cdfsod
- 基于ViT的方法:ViTDeT-FT
- 开放域方法:Detic(-FT), DE-ViT(-FT) (DE-ViT仅利用视觉信息,Deti则依赖视觉-文本相似性)
其中“-FT”表示我们用目标域T的少量样本对方法进行了微调。

我们结合实验结果对这个任务以及相关方法展开了详细的分析,主要有以下这几点结论:
- 现有FSOD方法可以泛化到跨域问题吗?A:不能
- 基于ViT的方法会比基于ResNet的方法好吗?A:看情况
- 开放域方法能够直接用于应对CD-FSOD问题?A:不能
- 开放域方法的性能可以进一步得到提升吗?A:可以
- 不同的开放域方法是否呈现不同的特性?A:是的
- Style,ICV,IB是如何影响domain gap的?A:在分类里影响巨大的style对于OD任务而言影响相对较少;ICV有较大影响但是可以被有效缓解;IB是这三者中最具挑战的。
(详细的分析就不在这里展开了,感兴趣的朋友可以去看看文章
4 CD-ViTO 方法 & 主要实验
我们方法的整体框架结构图如下所示:

整体来看,我们的方法是基于DE-ViT搭建的(图中蓝色块), 我们首先将DE-ViT方法简化为图中所示的几个模块主要包括Pretrained DINOv2 ViT, RPN,ROI Align, Instance Features, Dection Head,One-vs-Rest Classification Head。DE-ViT的核心想法是利用DINOv2提取出来的视觉特征对query image boxes与support images中所构建出来的类别prototypes进行比较,从来进行分类和定位。
基于DE-ViT方法,我们提出了三个新的模块(图中黄色块)以及finetune(图中火苗)以搭建我们的CD-ViTO。如contribution章节所描述,每个模块都各自对应解决CD-FSOD下存在的一个挑战。
4.1 Learnable Instance Features
原本的DE-ViT首先利用DINOv2获取instance features,然后简单对同类特征求和的方式得到support的class prototypes。然而在面对目标域类别之间可能很相似的情况,直接使用这种预训练的模型所提取出的特征会导致难以区分不同类别。
因此我们提出将原本固定的特征设置为可学习参数,并通过结合finetune方法将其显式地映射到目标域类别中,以此增加不同类之间的特征差异程度,缓解ICV问题。
我们对比了使用该模块前后的类间cosine相似性,结果说明我们的模块可以降低类间相似度,从而提升ICV。

4.2 Instance Reweighting Module
图像模糊边界的问题本身很难得到解决,这个模块的主要想法是通过学习可调整的权重给不同质量的样本赋不同的权重,使得严重IB的图像被抑制,没有或者轻微IB地图像被鼓励。
模块的设计如框架图右上所示,主要包含一个可学习的MLP。同样的,我们也对该模块做了可视化分析,我们按照所分配到的权重从高到低给图像排序,得到如下结果。从图中可见,前后景边缘模糊的图像得到的权重要低于边缘清晰的图像。

4.3 Domain Prompter
Domain Prompter的设计主要是希望方法能够对不同的domain鲁棒,如框架图右下所示,在原有object prototype的基础上,我们额外引入数量为维度为D(等于prototype维度)的虚拟domains变量作为可学习参数。通过学习和利用这些domains,我们希望最终达到:
- 不同domain之间相互远离,增加多样性 (domain diversity loss)
- 添加不同domain至同一类别prototype所生成得到的两个变种仍为正样本,添加不同domain至不同类别prototype生成得到的两个变种为负样本 (prototype consistency loss)
两个loss与finetuning所产生的loss叠加使用进行网络的整体训练。如下T-SNE可视化图说明我们学习到的domains之间相互远离;叠加不用domains至class prototype不影响语义变化。

Finetuning:作为简单但有效的迁移学习方法,我们也采用了在目标域T上对模型进行微调的思路,文章附录部分有提供不同finetune策略的不同性能表现,我们主方法里采用的是仅微调两个头部。
4.4 主要实验
我们在1/5/10shot上与其他方法进行了对比实验,实验说明经过优化后的CD-ViTO方法在大多数情况下都优于其他的对比方法,达到了对基本DE-ViT的有效提升,构建了这个任务的新SOTA。

文章所有数据集、代码、以及相关资源都已开源,也有相应的讲解视频,感谢大家关注。
- code:https://github.com/lovelyqian/CDFSOD-benchmark
- 中文讲解视频:https://www.bilibili.com/video/BV11etbenET7/?spm_id_from=333.999.0.0
- 英文讲解视频:https://www.bilibili.com/video/BV17v4UetEdF/?vd_source=668a0bb77d7d7b855bde68ecea1232e7#reply113142138936707
#VIT细节
详解ViT那些容易忽略的细节。
作为当前最热门的CV大模型backbone之一,我觉得单开一篇文章再写写它,非常有意义。
一、模型架构
提起一个新模型,我想大家最关心的事就是:它到底长什么样?输入输出是什么?我要怎么用?
所以,我们先来看模型架构。
1.1 Bert架构
前面说过,VIT几乎和Bert一致,我们来速扫一下Bert模型:

- input:输入是一条文本。文本中的每个词(token)我们都通过embedding把它表示成了向量的形式。
- 训练任务:在Bert中,我们同时做2个训练任务:
- Next Sentence Prediction Model(下一句预测):input中会包含两个句子,这两个句子有50%的概率是真实相连的句子,50%的概率是随机组装在一起的句子。我们在每个input前面增加特殊符,这个位置所在的token将会在训练里不断学习整条文本蕴含的信息。最后它将作为“下一句预测”任务的输入向量,该任务是一个二分类模型,输出结果表示两个句子是否真实相连。
- Masked Language Model(遮蔽词猜测):在input中,我们会以一定概率随机遮盖掉一些token,以此来强迫模型通过Bert中的attention结构更好抽取上下文信息,然后在“遮蔽词猜测”任务重,准确地将被覆盖的词猜测出来。
- Bert模型:Transformer的Encoder层。
1.2 VIT模型架构
我们先来看左侧部分。
- Patch:对于输入图片,首先将它分成几个patch(例如图中分为9个patch),每个patch就类似于NLP中的一个token(具体如何将patch转变为token向量,在下文会细说)。
- Position Embedding:每个patch的位置向量,用于指示对应patch在原始图片中的位置。和Bert一样,这个位置向量是learnable的,而并非原始Transformer中的函数式位置向量。同样,我们会在下文详细讲解这一块。
- Input: 最终传入模型的Input = patching_emebdding + position embedding,同样,在输入最开始,我们也加一个分类符,在bert中,这个分类符是作为“下一句预测”中的输入,来判断两个句子是否真实相连。在VIT中,这个分类符作为分类任务的输入,来判断原始图片中物体的类别。
右侧部分则详细刻画了Transformer Encoder层的架构,它由L块这样的架构组成。图片已刻画得很详细,这里不再赘述。
总结起来,VIT的训练其实就在做一件事:把图片打成patch,送入Transformer Encoder,然后拿对应位置的向量,过一个简单的softmax多分类模型,去预测原始图片中描绘的物体类别即可。
你可能会想:“这个分类任务只用一个简单的softmax,真得能分准吗?”其实,这就是VIT的精华所在了:VIT的目的不是让这个softmax分类模型强大,而是让这个分类模型的输入强大。这个输入就是Transformer Encoder提炼出来的特征。分类模型越简单,对特征的要求就越高。
所以为什么说Transformer开启了大一统模型的预训练大门呢?主要原因就在于它对特征的提炼能力——这样我们就可以拿这个特征去做更多有趣的任务了。这也是VIT能成为后续多模态backbone的主要原因。
二、从patch到token
讲完了基本框架,我们现在来看细节。首先我们来看看,图片的patch是怎么变成token embedding的。
2.1 patch变token的过程

如图,假设原始图片尺寸大小为:224*224*3 (H * W * C)。
现在我们要把它切成小patch,每个patch的尺寸设为16(P=16),则每个patch下图片的大小为16*16*3。
则容易计算出共有个patch。
不难看出每个patch对应着一个token,将每个patch展平,则得到输入矩阵X,其大小为(196, 768),也就是每个token是768维。
通过这样的方式,我们成功将图像数据处理成自然语言的向量表达方式。
好,那么现在问题来了,对于图中每一个16*16*3的小方块,我要怎么把它拉平成1*768维度的向量呢?
比如说,我先把第一个channel拉成一个向量,然后再往后依次接上第二个channel、第三个channel拉平的向量。但这种办法下,同一个pixel本来是三个channel的值共同表达的,现在变成竖直的向量之后,这三个值的距离反而远了。基于这个原因,你可能会想一些别的拉平方式,但归根究底它们都有一个共同的问题:太规则化,太主观。
所以,有办法利用模型来做更好的特征提取吗?当然没问题。VIT中最终采用CNN进行特征提取,具体方案如下:

采用768个16*16*3尺寸的卷积核,stride=16,padding=0。这样我们就能得到14*14*768大小的特征图。如同所示,特征图中每一个1*1*768大小的子特征图,都是由卷积核对第一块patch做处理而来,因此它就能表示第一块patch的token向量。
【备注】:
你可能会问,前面不是说VIT已经摆脱CNN了吗?这里怎么又用卷积了?由于这一步只是输入预处理阶段,和主体模型没有关系,只要将其试为一致特征提取方法即可,并不影响我们之前的结论。
2.2 为什么要处理成patch
你可能想问,为什么一定要先分patch,再从patch转token呢?
第一个原因,是为了减少模型计算量。
在Transformer中,假设输入的序列长度为N,那么经过attention时,计算复杂度就为,因为注意力机制下,每个token都要和包括自己在内的所有token做一次attention score计算。
在VIT中,,当patch尺寸P越小时,N越大,此时模型的计算量也就越大。因此,我们需要找到一个合适的P值,来减少计算压力。
第二个原因,是图像数据带有较多的冗余信息。
和语言数据中蕴含的丰富语义不同,像素本身含有大量的冗余信息。比如,相邻的两个像素格子间的取值往往是相似的。因此我们并不需要特别精准的计算粒度(比如把P设为1)。这个特性也是之后MAE之类的像素级预测模型能够成功的原因之一。
三、Emebdding
如下图,我们知道在Bert(及其它NLP任务中):
输入 = token_embedding(将单个词转变为词向量) +position_embedding(位置编码,用于表示token在输入序列中的位置) + segment_emebdding(非必须,在bert中用于表示每个词属于哪个句子)。
在VIT中,同样存在token_embedding和postion_emebedding。

3.1 Token Emebdding
我们记token emebdding为,则是一个形状为(768, 768)的矩阵。
由前文知经过patch处理后输入的形状为(196, 768),则输入X过toke_embedding后的结果为:你可能想问,输入X本来就是一个(196,768)的矩阵啊,我为什么还要过一次embedding呢?
这个问题的关键不在于数据的维度,而在于embedding的含义。原始的X仅是由数据预处理而来,和主体模型毫无关系。而token_embedding却参与了主体模型训练中的梯度更新,在使用它之后,能更好地表示出token向量。更进一步,E的维度可以表示成(768, x)的形式,也就是第二维不一定要是768,你可以自由设定词向量的维度。
3.2 Position Embedding(位置向量)
在NLP任务中,位置向量的目的是让模型学得token的位置信息。在VIT中也是同理,我们需要让模型知道每个patch的位置信息(参见1.2中架构图)。
我们记位置向量为,则它是一个形状为(196,768)的矩阵,表示196个维度为768的向量,每个向量表示对应token的位置信息。
构造位置向量的方法有很多种,在VIT中,作者做了不同的消融实验,来验证不同方案的效果(论文附录D.4)部分,我们来详细看看,作者都曾尝试过哪些方案。
方案一:不添加任何位置信息
将输入视为一堆无序的patch,不往其中添加任何位置向量。
方案二:使用1-D绝对位置编码
也就是我们在上文介绍的方案,这也是VIT最终选定的方案。1-D绝对位置编码又分为函数式(Transformer的三角函数编码,详情可参见这篇文章)和可学习式(Bert采用编码方式),VIT采用的是后者。之所以被称为“绝对位置编码”,是因为位置向量代表的是token的绝对位置信息(例如第1个token,第2个token之类)。
方案三:使用2-D绝对位置编码

如图所示,因为图像数据的特殊性,在2-D位置编码中,认为按全局绝对位置信息来表示一个patch是不足够的(如左侧所示),一个patch在x轴和y轴上具有不同含义的位置信息(如右侧所示)。因此,2-D位置编码将原来的PE向量拆成两部分来分别训练。
方案四:相对位置编码(relative positional embeddings)

相对位置编码(RPE)的设计思想是:我们不应该只关注patch的绝对位置信息,更应该关注patch间的相对位置信息。如图所示,对于token4,它和其余每一个token间都存在相对位置关系,我们分别用这5个向量来表示这种位置关系。那么接下来,只在正常计算attention的过程中,将这5个向量当作bias添加到计算过程中(如图公式所示),我们就可以正常训练这些相对位置向量了。为了减少训练时的参数量,我们还可以做clip操作,在制定clip的步数k之后,在k范围之外的w我们都用固定的w表示。例如图中来替代,如果token1之前还有token,那么它们的w都可用替代。向token4的后方找,发现大家都在k=2步之内,因此无需做任何替换操作。
关于相对位置编码的更多信息,可以阅读原始论文(https://arxiv.org/pdf/1803.02155.pdf
实验结果
这四种位置编码方案的实验结果如下:

可以发现除了“不加任何位置编码”的效果显著低之外,其余三种方案的结果都差不多。所以作者们当然选择最快捷省力的1-D位置编码方案啦。当你在阅读VIT的论文中,会发现大量的消融实验细节(例如分类头<cls>要怎么加),作者这样做的目的也很明确:“我们的方案是在诸多可行的方法中,逐一做实验比对出来的,是全面考虑后的结果。”这也是我一直觉得这篇论文在技术之外值得借鉴和反复读的地方。
四、模型架构的数学表达
到这一步位置,我们已基本将VIT的模型架构部分讲完了。结合1.2中的模型架构图,我们来用数学语言简练写一下训练中的计算过程:

(1)即是我们说的图像预处理过程:
- :第i块patch
- :Token Embedding,1-D Positional Embedding
- :和Bert类似,是额外加的一个分类头
- :最终VIT的输入
(2)即是计算multi-head attention的过程,(3)是计算MLP的过程。(4)是最终分类任务,LN表示是一个简单的线性分类模型,则是<cls>对应的向量。
五、微调(fine-tune)
目前为止,按照一至五部分所说的内容,通过让模型做分类预测,我们可以预训练(pretrain)好一个VIT了。
前面说过,预训练好的VIT模型是个有力的特征提取器,我们可以用它输出的特征,去做更多有趣的下游任务(downstream task)。例如拿它去做类型更丰富的分类,目标检测等事情。在做这些任务时,我们会喂给预训练模型一堆新的数据,同时尽量保证模型的主体架构不变(例如VIT整体参数不动,只在输出层后接一个新模型,再次训练时只对新模型做参数更新之类)。这种既利用了已有模型的特征提取能力,又能让模型更好适应不同任务的操作,称为微调(fine-tune)。
在fine-tune的时候,我们用的图像大小可能和预训练时的并不一致,比如:
- 预训练时用224*224*3大小的图片,fine-tune时为了效果更好,一般选择分辨率更高的图片,例如1024*1024*3
- 假设保持patch尺寸P=16不变,则预训练时产生的patch数有196个,fine-tune时产生的patch数有4096个
- 我们知道,Transformer主体架构理论上是可以处理任意长度的输入序列的(相关分析参见这篇文章)。但是可学习的(learnable)位置编码不是,由于一个位置对应一条位置编码,它和输入序列长度密切相关。
那么多出来的patch,在fine-tune时要怎么给它们位置编码呢?如果统一都赋成0向量,然后在fine-tune的时候再去训练这些向量,看起来可以,但这样粗暴的赋值不仅增加了计算量,也浪费了已有的信息(例如,是否能从已有的位置编码粗略地初始化一些新的位置编码出来?)考虑到这一点,VIT在fine-tune时,对预训练阶段的位置编码做了2D插值处理。

如图绿色部分所示,在fine-tune阶段要处理的patch/token数可能比预训练阶段要处理的要多。图中红色部分演示了如何通过插值方法将扩展至。其中interpolate部分就是2D插值,这部分是重点,我们直接看下代码中的操作:
new_pos_embedding_img = nn.functional.interpolate(
pos_embedding_img,
size=new_seq_length_1d,
mode=interpolation_mode,
align_corners=True,
)可以发现这里用了pytorch内置的interpolate函数,mode表示具体的插值方法,在VIT中采用的是bicubic。align_corners=True 的意思是在固定原矩阵四角的情况下按mode进行插值,可以参加图中,白色圆圈表示原始的矩阵,蓝色点表示做完插值后的矩阵。插值后矩阵的四角保持不变,中间则按设置的方法做插值。关于插值位置编码更详细的讲解,可以参考:https://blog.csdn.net/qq_44166630/article/details/127429697
六、VIT效果
到目前为止,我们已讲完了预训练和微调的内容。接下来,我们来看VIT的效果,及一些有趣的实验结果。
6.1 不同VIT模型的表示符号

VIT预训练了三种不同参数规模的模型,分别是VIT-Base ,VIT-Large和VIT-Huge。其规模可具体见上图。
在论文及实际使用中,我们常用VIT-size/patch_size的形式来表示该模型是在“什么规模”及“多大的patch尺寸”上预训练出来的。例如VIT-H/14就表示该模型是在Huge规模上,用patch尺寸为14的数据做预训练的。
6.2 VIT VS 卷积神经网络
既然VIT的目的是替换卷积神经网络,那么当然要比较一下它和目前SOTA的卷积网络间的性能了。
作者选取了ResNet和Noisy Student这两种经典高性能的卷积神经网络与VIT进行比较,比较内容为“预测图片类别的准确性”与“训练时长”,结果如下:

前三列Ours-JFT(VIT-H/14),Ours-JFT(VIT-L/16),Ours-I12K(VIT-L/16)表示三个VIT预训练模型,它们分别在不同规模和不同数据集(JFT, I12K)上预训练而来。后两列表示两个卷积神经网络模型。
纵向的ImageNet,ImageNet Real等表示不同的图像数据集,当我们的VIT模型和卷积模型预训练好后,我们就可以借助这些pretrain模型,在图像数据集上做fine-tune,而表格里给出的就是fine-tune后的准确率。
观察表格,我们发现一个有趣的现象:VIT和卷积神经网络相比,表现基本一致。关于这一点,我们会在下文详细分析。虽然准确率没有突出表现,但是训练时间上VIT的还是有亮点的,表格最后一行表示,假设用单块TPU训练模型,所需要的天数。我们发现VIT最高也只需要2500核-天(当然其实这个值也不小啦),卷积网络要花至9900核-天以上。所以VIT的一个优势在于,训练没那么贵了。关于这点,我的猜想是基于Transformer架构的VIT,和卷积神经网络相比,更适合做切分均匀的矩阵计算,这样我们就能把参数均匀切到不同卡上做分布式训练,更好利用GPU算力,平衡整个训练系统了。
现在,我们回到刚才的问题,为什么VIT相比卷积网络,在准确率上没有突出优势?为了解答这个问题,我们先来看卷积神经网络的归纳偏置(inductive biases)
6.2.1 卷积神经网络的归纳偏置
归纳偏置用大白话来说,就是一种假设,或者说一种先验知识。有了这种先验,我们就能知道哪一种方法更适合解决哪一类任务。所以归纳偏置是一种统称,不同的任务其归纳偏置下包含的具体内容不一样。
对图像任务来说,它的归纳偏置有以下两点:
- 空间局部性(locality):假设一张图片中,相邻的区域是有相关特征的。比如太阳和天空就经常一起出现。
- 平移等边性(translation equivariance): 卷积, 平移。假设一张图中,左上角有一个太阳,你对这张图正常做卷积得到特征图,则左上角的卷积可表示为,做完卷积后,你想把左上角的特征图移动到右上角去,则你这一顿操作可以用来表示。这一系列操作等同于,你先把左上角的太阳移动到右上角去,然后再做卷积,这就是图像的平移等边性。不论物体移动到哪里,只要给卷积核的输入不变,那么输出也是一致的。
在这两种先验假设下,CNN成为了图像任务最佳的方案之一。卷积核能最大程度保持空间局部性(保存相关物体的位置信息)和平移等边性,使得在训练过程中,最大限度学习和保留原始图片信息。
好,那么现在,如果说VIT相比于卷积,在图像任务上没有显著优势,那大概率VIT对这两种先验的维护没有CNN做的好,具体来看:

图中箭头所指的两部分都属于同一栋建筑。在卷积中,我们可以用大小适当的卷积核将它们圈在一起。但是在VIT中,它们之间的位置却拉远了,如果我把patch再切分细一些,它们的距离就更远了。虽然attention可以学习到向量间的想关系,但是VIT在空间局部性的维护上,确实没有卷积做的好。而在平移等边性上,由于VIT需要对patch的位置进行学习,所以对于一个patch,当它位置变幻时,它的输出结果也是不一样的。所以,VIT的架构没有很好维护图像问题中的归纳偏置假设。
但是,这就意味着VIT没有翻盘的一天了吗?当然不是,不要忘了,Transformer架构的模型都有一个广为人知的特性:大力出奇迹。只要它见过的数据够多,它就能更好地学习像素块之间的关联性,当然也能抹去归纳偏置的问题。
6.2.2 VIT:大力出奇迹
作者当然也考虑到了这点,所以采用了不同数量的数据集,对VIT进行训练,效果如下:

如图,横轴表示不同量级的数据集(越往右数据集越大),纵轴表示准确率。图中灰色阴影部分表示在相应数据集下,不同架构的卷积神经网络的准确率范围。可以发现,当数据集较小时,VIT表现明显弱于卷积网络。但当数据量级大于21k时,VIT的能力就上来了。
6.3 VIT的Attention到底看到了什么
讲完了VIT的整体效果,我们来探究下VIT具体学到了什么,才能帮助它达到这样的效果。我们首先来看attention层。

这张实验图刻画了VIT的16个multi-head attention学到的像素距离信息。横轴表示 网络的深度, 纵轴表示“平均注意力距离”, 我们设第 个和第 个像素的平均注意力 距离为 , 真实像素距离为 , 这两个像素所在patch某一个head上的attention score为 , 则有: 。当 越大时, 说明VIT的attention机制能让它关 注到距离较远的两个像素, 类似于CNN中的“扩大感受野”。
图中每一列上,都有16个彩色原点,它们分别表示16个head观测到的平均像素距离。由图可知,在浅层网络中,VIT还只能关注到距离较近的像素点,随着网络加深,VIT逐渐学会去更远的像素点中寻找相关信息了。这个过程就和用在CNN中用卷积逐层去扩大感受野非常相似。
下图的左侧表示原始的输入图片,右侧表示VIT最后一层看到的图片信息,可以清楚看见,VIT在最后一层已经学到了将注意力放到关键的物体上了,这是非常有趣的结论:
6.4 VIT的位置编码学到了什么
我们在上文讨论过图像的空间局部性(locality),即有相关性的物体(例如太阳和天空)经常一起出现。CNN采用卷积框取特征的方式,极大程度上维护了这种特性。其实,VIT也有维护这种特性的方法,上面所说的attention是一种,位置编码也是一种。
我们来看看VIT的位置编码学到了什么信息:

上图是VIT-L/32模型下的位置编码信息,图中每一个方框表示一个patch,图中共有7_7个patch。而每个方框内,也有一个7_7的矩阵,这个矩阵中的每一个值,表示当前patch的position embedding和其余对应位置的position embedding的余弦相似度。颜色越黄,表示越相似,也即patch和对应位置间的patch密切相关。
注意到每个方框中,最黄的点总是当前patch所在位置,这个不难理解,因为自己和自己肯定是最相似的。除此以外颜色较黄的部分都是当前patch所属的行和列,以及以当前patch为中心往外扩散的一小圈。这就说明VIT通过位置编码,已经学到了一定的空间局部性。
七、总结:VIT的意义何在
到此为止,关于VIT模型,我们就介绍完毕了。一顿读下来,你可能有个印象:如果训练数据量不够多的话,看起来VIT也没比CNN好多少呀,VIT的意义是什么呢?
这是个很好的问题,因为在工业界,人们的标注数据量和算力都是有限的,因此CNN可能还是首要选择。
但是,VIT的出现,不仅是用模型效果来考量这么简单,今天再来看这个模型,发现它的意义在于:
- 证明了一个统一框架在不同模态任务上的表现能力。在VIT之前,NLP的SOTA范式被认为是Transformer,而图像的SOTA范式依然是CNN。VIT出现后,证明了用NLP领域的SOTA模型一样能解图像领域的问题,同时在论文中通过丰富的实验,证明了VIT对CNN的替代能力,同时也论证了大规模+大模型在图像领域的涌现能力(论文中没有明确指出这是涌现能力,但通过实验展现了这种趋势)。这也为后续两年多模态任务的发展奠定了基石。
- 虽然VIT只是一个分类任务,但在它提出的几个月之后,立刻就有了用Transformer架构做检测(detection)和分割(segmentation)的模型。而不久之后,GPT式的无监督学习,也在CV届开始火热起来。
- 工业界上,对大部分企业来说,受到训练数据和算力的影响,预训练和微调一个VIT都是困难的,但是这不妨碍直接拿大厂训好的VIT特征做下游任务。同时,低成本的微调方案研究,在今天也层出不穷。长远来看,2年前的这个“庞然大物”,已经在逐步走进千家万户。
参考
1、https://arxiv.org/pdf/2010.11929.pdf
2、https://www.bilibili.com/video/BV15P4y137jb/?spm_id_from=333.337.search-card.all.click
3、https://arxiv.org/pdf/1803.02155.pdf
4、https://blog.csdn.net/qq_44166630/article/details/127429697
#Co-Instruct
让通用多模态大模型学会比较视觉质量
本篇分享 ECCV 2024 Oral 论文Towards Open-ended Visual Quality Comparison, Co-Instruct: 让通用多模态大模型学会比较视觉质量。
- 作者:Haoning Wu等
- 论文链接:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/00422.pdf
- Git链接:https://github.com/Q-Future/Co-Instruct
亮点直击
- 本文提出了Co-Instruct数据集,通过训练激发通用多模态大模型潜在的对多图的理解能力,从而实现开放式的视觉质量比较。这一数据集协同利用了蒸馏GPT-4V对多图质量的判断+LLM对人类单图质量标注的整合,在感知类开放式质量比较任务上实现了超过GPT-4V的效果。
- 经过Co-Instruct训练的多模态大模型不止可以比较多张图片整体质量的好坏,还可以更细粒度的比较各种和质量相关的问题(“哪一张图片清晰度最高?”,“哪一张图片更真实?”;尽管训练数据全部是定性比较,在Compare2Score(Neurips2024)测试中,Co-Instruct也证明了拥有最好的零样本定量比较能力。
- 作为多模态大模型基础的能力之一,Co-Instruct数据集已经被集成到多个知名开源框架中,如最新的LLaVA-OneVision, mPLUG-Owl3等,为这些通用模型赋予了相同的开放式的视觉质量比较能力;Co-Instruct亦已被集成到开源多模态大模型多图训练框架Mantis)中。
方法总览:数据建构的原则
尽管人工标注被广泛认为是收集数据的最直接方法,但在大量图像上获取足够的比较数据相较于在相同图像集合上获取意见需要显著增加的标注量。为了避免这种难以承受的成本,我们提出了一种无需额外人工标注的合成式数据构建策略,遵循以下三个关键原则:
- 转换(Convert):利用现有数据集中的可靠信息。
- 从模型中学习(Learn-from-Model):利用模型经过验证的能力。
- 共同指导(Co-Instruct):收集能够相互补充的多样化子集。
基于这些原则,我们收集了用于指令微调的两个不同子集:Merge2Compare,该方法将人类对单幅图像的质量描述以及单模态大模型比较和分析文本的能力相结合;以及 Teach2Compare,该方法利用了 GPT-4V 在图像比较上的验证能力。最后,我们探讨了在共同指导(co-instruct)框架下,这两个子集如何相互补充。
第一个子集:Merge2Compare

作为第一个子集(不依赖任何其他的多模态大模型),Merge2Compare通过对图像描述进行配对、筛选和合并,用于生成高质量的比较数据。其目标是最大程度利用现有的图像描述以及开源的单模态模型,减少人工标注成本,并确保最终数据的准确性和多样性。
流程:
- 配对/分组匹配:从现有的图像质量描述中(Q-Instruct数据集,CVPR2024)随机选取81K图像对、27K三图组和18K四图组,以确保涵盖不同场景和多样化的图像组合。
- 去除高相似度配对:使用文本嵌入模型计算描述之间的相似性,去除任何高相似度的配对或分组,确保对比数据具备信息增益。筛选后,保留70K图像对、20K三图组和10K四图组。
- 大模型合并:利用大模型(LLMs)将单幅图像的评价转化为对比性文本,并为描述添加合理推理。最终的人工抽检验证显示,Merge2Compare生成的比较数据准确率高达96%,验证了其高质量的数据构建能力。
第二个子集:Teach2Compare

作为第二个子集,Teach2Compare 方法的选择来自于GPT-4V已经被验证的强大的视觉比较能力。因此,本文用GPT-4V生成两种伪标签子集:Teach2Compare-general(整体质量比较)和 Teach2Compare-Q&A(问答对)。首先,作为Teach2Compare的准备,本文从各种来源收集9K图像,以涵盖不同质量和视觉外观:
- 5.4K原始世界图像:从 YFCC-100M 数据库中提取。
- 1.8K人工失真的图像:来自 COCO 数据库,包括 15 种 ImageCorruptions 和 KADIS-700K 中的失真类型。
- 1.8K AI生成的图像:来自 ImageRewardDB。这些图像进一步分组为 18K 对、6K 三图组和 6K 四图组,由 GPT-4V 提供伪标签,生成以下两种格式的子集:
- Teach2Compare-general:类似于 Merge2Compare,general 子集也包含整体质量比较及其推理。具体来说,将 Merge2Compare 提示模板中的 <desc_i> 替换为相应真实图像 <img_i>,并输入至 GPT-4V。为了验证伪标签的质量,对 250 个样本进行检查,准确率约为 94%。尽管略低于 Merge2Compare(96%),但人工评估表明,GPT-4V 标签包含了更多的内容信息,从而增强了模型对质量的理解。这两个不同来源的子集彼此互补,有助于更好地学习。
- Teach2Compare-Q&A:除了整体比较,Teach2Compare 还收集了一个专门子集,以提升多模态大模型在处理开放性问题上的能力。为了收集这些问答,本文首先列出参考维度(例如清晰度、光照、颜色等);然后要求 GPT-4V 基于这些维度生成关于图像对比的提问(以及相应的正确答案和错误答案);最终删除生成失败的问答对,保留 230K 个问答对,涵盖 30K 张图像组。这些问答对转换为直接问答训练样本和多选样本,以支持开放式问题(简答题)和多选题的训练。
为什么选择这样的结合?
本文将 Merge2Compare 和 Teach2Compare 这两个子集结合的动机在于它们的互补性,这体现在两个方面:
- 首先,在一般的图像比较中,Merge2Compare 具有更高的准确率,但由于高相似度配对移除的原因,缺乏对更细粒度比较的支持。而 Teach2Compare-general 虽然准确率略低,但提供了更加多样化的场景,并且包含了内容信息作为背景。因此,将这两个子集共同用于训练,有助于模型在整体上进行更全面的质量比较。
- 此外,Teach2Compare 还包含了一个独特的问答子集(Q&A subset),显著提升了模型回答开放式问题的能力。这进一步增强了模型在广泛应用中的表现。因此,通过整合这两个子集,我们可以构建一个在质量比较和问答能力上都更为强大的模型。
模型设计

基于所采集的数据集,本文进一步提出所模型 Co-Instruct,并针对多图像比较的场景进行了两项简单而有效的设计创新:
- 视觉Token压缩:目前大多数先进的大语言模型(LMMs)使用的是简单的投影器,保留了大量的token(例如1,025个)。这种结构不适合多图像的场景:仅传递两张图像就会超过LLaVA模型的最大长度(2,048个),而传递四张图像则会超过LLaMA-2的上下文窗口大小(4,096个)。为了解决这个问题,我们采用了一种广泛使用的压缩结构,将视觉嵌入的token数量在传入模型之前进行压缩,从而能够更好地适应多图像场景。
- 图文交错格式:传统的单图像指令微调通常不考虑图像的“位置”。大多数方法直接将所有图像堆叠在文本之前<img0> (<img1>...) <text>,这样多个图像就没有区分,LMM可能会混淆来自不同图像的信息,无法有效比较(参见基线结果)。为了改进这一点,我们提出了一种图文交错的格式用于多图像训练:每一张图像之前都会有明确的文本说明其序号,例如:第一张图像:<img0> 第二张图像:<img1> (…) 在我们的实验中,这种交错格式显著提高了 Co-Instruct 的性能,并且明显优于使用特殊token(如 <img_st> 和 <img_end>)来划分图像的方法。
实验分析
双图比较&选择题

Q-Bench 是一个视觉质量比较的基准测试,包含1,999道由专家精心编写的开放式多选题(MCQs),用来比较图像对的质量。在上表中,我们将 Co-Instruct 与现有的开源和专有模型在这个基准上进行了比较。
Co-Instruct 在准确率上远超开源的多模态大模型,比其基线模型(mPLUG-Owl2)高出 64%,比没有多图像子集(Merge2Compare 和 Teach2Compare)的模型变体高出 51%,并且比所有开源模型的最佳性能还高出 23%。同时,它在准确率上也大幅领先于专有模型 Qwen-VL-Max 和 Gemini-Pro,分别高出 21% 和 33%。
尽管所有训练所用的MCQ数据都来自 GPT-4V,但 Co-Instruct 在这个MCQ评估集上的表现仍比它的“老师”(GPT-4V)高出 2.7%,说明这种协作教学策略的有效性。此外,Co-Instruct 也是唯一一个在基准测试中准确率超过非专家人类水平(尤其在 Compare 子集上)的多模态大模型。这强烈支持了未来使用模型来减轻人类在真实世界视觉质量比较上的工作量的愿景。
双图比较&长描述

Q-Bench-A2 是一个基准测试,专门用于对图像对进行整体和详细的视觉质量比较,并提供详细的推理。它包含了 499 对图像,通过 GPT 对多模态大模型的输出在完整性(Completeness)、准确性(Precision)和相关性(Relevance)方面进行评估。
如上表所示,Co-Instruct 在比较输出的完整性和准确性上都有显著提升,相较于不包含比较数据的版本,分别提高了 57% 和 59%。在与同类 LMMs 的比较中,Co-Instruct 的表现与 GPT-4V 相当,并且显著超过其他现有多模态大模型。
通过比较进行定量打分

上表展示了来自 Compare2Score(NeurIPS 2024,改进自2AFC-LMM测试)的 SRCC 结果,该论文提供了一种测试方式,通过两种方式将多模态大模型的定性对比输出转化成定量分数(Count:基于生成的文本次数;Prob:基于生成的logits),从而衡量定量意义上的视觉质量比较能力。
Co-Instruct 在两种转换方式下都证明了更好的能力,实现了全数据集领先,相比每个数据集上最强的现有模型大幅提升了38%-83%不等。
多图比较&选择题
在 MICBench 基准测试(多图比较的选择题)中,Co-Instruct 展现出了极具竞争力的表现。在针对三至四幅图像的开放性质量比较问题上,Co-Instruct 的准确率比目前表现最好的 GPT-4V 高 5.7% ,比非专家人类高 6.4% 。相比之下,其他开源的大模型(LMMs)在此场景下的准确率甚至难以达到 50% 。
此外,值得注意的是,LLaVA 系列和 XComposer2-VL 的原始上下文长度不足以处理四幅图像的任务,因此需要扩展上下文窗口。然而,这些模型在四幅图像组上的表现显著低于三幅图像组,强调了对视觉 token 压缩的重要性(参见方法部分)。这表明 Co-Instruct 在多图像比较任务中的表现优异,部分原因在于其对视觉 token 的有效处理。
单图问答&选择题
在 Q-Bench-SINGLE-A1 中,我们也评估了 Co-Instruct 在单图像多选题(MCQ)上的表现,以验证比较微调对单图像质量感知的影响。如上表所示,Co-Instruct 相比仅基于单图像训练的模型提高了 5% 的准确率,比 GPT-4V 高 4%,并成为唯一一个超越非专家人类表现的大语言模型(LLM)。
这些结果表明,比较训练对大语言模型在总体质量相关理解上的贡献,并暗示单图像质量评估与多图像质量比较并不冲突,可以在一个统一的模型中共同提升。
结论
本文研究了开放式视觉质量比较问题,目标是构建一个能够在多图像间进行质量比较、并对开放式问题提供答案和详细推理的模型。为实现此目标,我们收集了首个用于微调多模态大模型(LMMs)的指令数据集——Co-Instruct-562K,包括两个子集:由 LLMs 合并的单图像人工标注,以及 GPT-4V 的输出。
在此数据集上,我们提出了 Co-Instruct 模型,其不仅在视觉质量比较中超越了所有现有的 LMMs(包括其“老师”GPT-4V),也是首个在相关任务上超越人类准确率的 LMM。此外,我们还对多图像质量比较进行了基准测试评估,为三张和四张图像的比较提供了参考。我们希望这项工作能够激发未来在视觉质量比较领域的研究。


#stable diffusion原理
超详细stable diffusion论文解读,读完这篇再也不会学不懂了!一、前言
stable diffusion作为Stability-AI开源图像生成模型,其出现也是不逊于ChatGPT,其发展势头丝毫不差于midjourney,加上其众多插件的加持,其上线也是无线拔高,当然,手法上也稍微比midjourney复杂点。
至于为什么开源,创始人:我这么做的原因是,我认为这是共同叙事(shared narrative)的一部分,有人需要公开展示发生了什么。再次强调,这应该默认就是开源的。因为价值不存在于任何专有模型或数据中,我们将构建可审计(auditable)的开源模型,即使其中包含有许可数据。 话不多说,开整。
二、stable diffusion
对于上面原论文的图片可能小伙伴理解有困难,但是不打紧,我会把上面图片分成一个个单独的模块进行解读,最后组合在一起,相信你们一定可以理解图片每一步干了什么事。
首先,我会画一个简化模型图对标原图,以方便理解。让我们从训练阶段开始,可能你们发现少了VAEdecoder,这是因为我们训练过程是在潜空间完成,decoder我们放在第二阶段采样阶段说,我们所使用的stablediffusion webui画图通常是在采样阶段,至于训练阶段,目前我们大多数普通人是根本完成不了的,它所需要训练时间应该可以用GPUyear来计量,(单V100的GPU要一年时间),如果你有100张卡,应该可以一个月完成。至于ChatGPT光电费上千万美金,上万GPU集群,感觉现在AI拼的就是算力。又扯远了,come back
1.clip
我们先从提示词开始吧,我们输入一段提示词a black and white striped cat(一条黑白条纹的猫),clip会把文本对应一个词表,每个单词标点符号都有相对应的一个数字,我们把每个单词叫做一个token,之前stablediffusion输入有限制只能75个单词(现在没了),也就是75个token,看上面你可能发现6个单词怎么对应8个token,这是因为还包含了起始token和结束token,每个数字又对应这一个768维的向量,你可以看作每个单词的身份证,而且意思非常相近的单词对应的768维向量也基本一致。经过clip我们得到了一个(8,768)的对应图像的文本向量。
stable diffusion所使用的是openAi的clip的预训练模型,就是别人训练好的拿来用就行,那clip是怎么训练出来的呢?他是怎么把图片和文字信息对应呢?(下面扩展可看可跳过,不影响理解,只需要知道它是用来把提示词转成对应生成图像的文本向量即可)
CLIP需要的数据为图像及其标题,数据集中大约包含4亿张图像及描述。应该是直接爬虫得来,图像信息直接作为标签,训练过程如下:
CLIP 是图像编码器和文本编码器的组合,使用两个编码器对数据分别进行编码。然后使用余弦距离比较结果嵌入,刚开始训练时,即使文本描述与图像是相匹配的,它们之间的相似性肯定也是很低的。
随着模型的不断更新,在后续阶段,编码器对图像和文本编码得到的嵌入会逐渐相似。在整个数据集中重复该过程,并使用大batch size的编码器,最终能够生成一个嵌入向量,其中狗的图像和句子「一条狗的图片」之间是相似的。
给一些提示文本,然后每种提示算相似度,找到概率最高的即可
2.diffusion model
上面我们已经得到了unet的一个输入了,我们现在还需要一个噪声图像的输入,假如我们输入的是一张3x512x512的猫咪图像,我们不是直接对猫咪图像进行处理,而是经过VAE encoder把512x512图像从pixel space(像素空间)压缩至latent space(潜空间)4x64x64进行处理,数据量小了接近64倍。
潜在空间简单的说是对压缩数据的表示。所谓压缩指的是用比原始表示更小的数位来编码信息的过程。维度降低会丢失一部分信息,然而在某些情况下,降维不是件坏事。通过降维我们可以过滤掉一些不太重要的信息你,只保留最重要的信息。
得到潜空间向量后,现在来到扩散模型,为什么图像加噪后能够还原,秘密都在公式里,这里我以DDPM论文作为理论讲解,论文,当然还有改进版本DDIM等等,感兴趣自己看
forward diffusion (前向扩散)
首先是forward diffusion (前向扩散),也就是加噪过程,最后就快变成了个纯噪声
每一个时刻都要添加高斯噪声,后一时刻都是由前一刻是增加噪声得到
那么是否我们每一次加噪声都要从前一步得到呢,我们能不能想要第几步加噪图像就能得到呢?答案是YES,作用是:我们训练过程中对图像加噪是随机的,假如 我们随机到100步噪声,(假设设置时间步数200步),如果要从第一步加噪,得到第二步,循环往复,太费时间了,其实这些加的噪声有规律的,我们现在的目标就是只要有原始图像X0,就可以得到任意时刻图像加噪声的图像,而不必一步一步得到想要的噪声图像。
我来对上述作讲解,其实该标住的我都标的很清楚了,
第一,αt范围0.9999-0.998,
第二,图像加噪是符合高斯分布的,也就是在潜空间向量加的噪声是符合均值为0,方差为1的,将Xt-1带入Xt中,为什么两项可以合并,因为Z1Z2都是符合高斯分布,那么他们相加Z2'也符合,并且它们的方差和为新的方差,所有把他们各自的方差求和,(那个带根号的是标准差),如果你无法理解,可以把它当做一个定理。在多说一句,对Z-->a+bZ,那么Z的高斯分别也从(0,σ)-->(a,bσ),现在我们得到了Xt跟Xt-2的关系
第三,如果你再把Xt-2带入,得到与Xt-3的关系,并且找到规律,就是α的累乘,最后得到Xt与X0的关系式,现在我们可以根据这个式子直接得到任意时刻的噪声图像。
第四,因为图像初始化噪声是随机的,假设你设置的时间步数(timesteps)为200,就是把0.9999-0.998区间等分为200份,代表每个时刻的α值,根据Xt和X0的公式,因为α累乘(越小),可以看出越往后,噪声加的越快,大概1-0.13的区间,0时刻为1,这时Xt代表图像本身,200时刻代表图像大概α为0.13噪音占据了0.87,因为是累乘所以噪声越加越大,并不是一个平均的过程。
第五,补充一句,重参数化技巧(Reparameterization Trick)如果X(u,σ2),那么X可以写成X=μ十σZ的形式,其中Z~Ν(0,1)。这就是重参数化技巧。
重参数化技巧,就是从一个分布中进行采样,而该分布是带有参数的,如果直接进行采样(采样动作是离散的,其不可微),是没有梯度信息的,那么在BP反向传播的时候就不会对参数梯度进行更新。重参数化技巧可以保证我们从进行采样,同时又能保留梯度信息。
逆向扩散(reverse diffusion)
- 前向扩散完毕,接下来是逆向扩散(reverse diffusion),这个可能比上面那个难点,如何根据一个噪声图像一步步得到原图呢,这才是关键,
- 逆向开始,我们目标是Xt噪声图像得到无噪声的X0,先从Xt求Xt-1开始,这里我们先假设X0是已知(先忽略为什么假设已知),后面会替换它,至于怎么替换,前向扩散不是已知Xt和X0的关系吗,现在我们已知的是Xt,反过来用Xt来表示X0,但是还有一个Z噪声是未知的,这个时候就要Unet上场了,它需要把噪声预测出来。
- 这里借助贝叶斯公式(就是条件概率),我们借助贝叶斯公式结果,以前写过一个文档 (https://tianfeng.space/279.html)
就是已知Xt求Xt-1,反向我们不知道怎么求,但是求正向,如果我们已知X0那么这几项我们都可以求出来。
开始解读,既然这三项都符合高斯分别,那带入高斯分布(也可以叫正态分布),它们相乘为什么等于相加呢,因为e2 * e3 =e2+3,这个能理解吧(属于exp,就是e次方),好,现在我们得到了一个整体式子,接下来继续化简
首先我们把平方展开,未知数现在只有Xt-1,配成AX2+BX+C格式,不要忘了,即使相加也是符合高斯分布,现在我们把原高斯分别公式配成一样的格式,红色就是方差的倒数,把蓝色乘方差除2就得到了均值μ(下面显示是化简的结果,如果你有兴趣自己,自己化简),回归X0,之前说X0假设已知,现在转成Xt(已知)表示,代入μ,现在未知数只剩下Zt,
- Zt其实就是我们要估计的每个时刻的噪声- 这里我们使用Unet模型预测- 模型的输入参数有三个,分别是当前时刻的分布Xt和时刻t,还有之前的文本向量,然后输出预测的噪声,这就是整个过程了,
- 上面的Algorithm 1是训练过程,
其中第二步表示取数据,一般来说都是一类猫,狗什么的,或者一类风格的图片,不能乱七八糟什么图片都来,那模型学不了。
第三步是说每个图片随机赋予一个时刻的噪声(上面说过),
第四步,噪声符合高斯分布,
第五步,真实的噪声和预测的噪声算损失(DDPM输入没有文本向量,所有没有写,你就理解为多加了一个输入),更新参数。直到训练的输出的噪声和真实噪声相差很小,Unet模型训练完毕
- 下面我们来到Algorithm2采样过程
- 不就是说Xt符合高斯分布嘛
- 执行T次,依次求Xt-1到X0,不是T个时刻嘛
- Xt-1不就是我们逆向扩散推出的公式,Xt-1=μ+σZ,均值和方差都是已知的,唯一的未知噪声Z被Unet模型预测出来,εθ这个是指已经训练好的Unet,
采样图
- 为了方便理解,我分别画出文生图和图生图,如果使用stable diffusion webui画图的人一定觉得很熟悉,如果是文生图就是直接初始化一个噪声,进行采样,
- 图生图则是在你原有的基础上加噪声,噪声权重自己控制,webui界面是不是有个重绘幅度,就是这个,
- 迭代次数就是我们webui界面的采样步数,
- 随机种子seed就是我们初始随机得到的一个噪声图,所以如果想要复刻得到一样的图,seed要保持一致
阶段小结
我们现在再来看这张图,除了Unet我没讲(下面会单独介绍),是不是简单多了,最左边不就是像素空间的编码器解码器,最右边就是clip把文本变成文本向量,中间上面的就是加噪,下面就是Unet预测噪声,然后不停的采样解码得到输出图像。这是原论文采样图,没画训练过程。
3.Unet model
unet模型相信小伙伴们都或多或少知道,就是多尺度特征融合,像FPN图像金字塔,PAN,很多都是差不多的思想,一般使用resnet作为backbone(下采样),充当编码器,这样我们就得到多个尺度的特征图,然后在上采样过程中,上采样拼接(之前下采样得到的特征图),上采样拼接,这是一个普通的Unet
那stablediffusion的Unet有什么不一样呢,这里找到一张图,佩服这位小姐姐有耐心,借一下她的图
我解释一下和ResBlock模块和SpatialTransformer模块,输入为timestep_embedding,context 以及input就是三个输入分别是时间步数,文本向量,加噪图像,时间步数你可以理解为transformer里的位置编码,在自然语言处理中用来告诉模型一句话每个字的位置信息,不同的位置可能意思大不相同,而在这,加入时间步数信息,可以理解为告诉模型加入第几步噪声的时刻信息(当然这是我的理解)。
timestep_embedding采用正余弦编码
ResBlock模块输入为时间编码和卷积后图像输出,把它们相加,这就是它的作用,具体细节不说了,就是卷积,全连接,这些很简单。
SpatialTransformer模块输入为文本向量和上一步ResBlock的输出,
里面主要讲一下cross attention,其他都是一些维度的变换,卷积操作和各种归一化Group Norm,Layer norm,
利用cross attention将latent space(潜空间)的特征与另一模态序列(文本向量)的特征融合,并添加到diffusion model的逆向过程,通过Unet逆向预测每一步需要减少的噪音,通过GT噪音与预测噪音的损失函数计算梯度。
看右下角图,可以知道Q为latent space(潜空间)的特征,KV则都是文本向量连两个全连接得到,剩下就是正常的transformer操作了,QK相乘后,softmax得到一个分值,然后乘V,变换维度输出,你可以把transformer当做一个特征提取器,它可以把重要信息给我们显现出来(仅帮助理解),差不多就是这样了,之后操作都差不多,最后输出预测的噪声。
这里你肯定得熟悉transformer,知道什么是self attention,什么是cross attention不懂找篇文章看看,感觉不是可以简单解释清楚的。
完毕,拜拜,显示一些webui对比图
三、stable diffusion webui扩展
参数clip
#人体姿态估计(HPE)入门教程
作者总结了人体姿态估计入门需要学习的一些知识,在学习过程中的一些感悟和踩过的坑,列举主要的工作脉络和一些细节。
0.前言
自己的研究方向属于人体姿态估计领域,但是学了大概两年了,才感觉刚入门(主要是自己太菜...),一开始对各种各样的名词和网络方法摸不着头脑,没有建立属于自己的研究体系,论文堆积如山,各种方法层出不穷,研究生就这么几年,哪能看的完呢?没有一个指路人,真的太难,而且这个领域的应用和教程属实没有检测和分割多......这里总结一下自己在学习过程中的一些感悟和踩过的坑,列举主要的工作脉络和一些细节,还有前期主要看的论文。主要以帮助后来者入门使用,肯定有一些内容属于自己主观理解,纯属个人经验,若有错误,麻烦一起讨论交流,感谢指正!欢迎留言私信哈~~
1.总述
人体姿态估计按照不同的标准有着各种各样的分类。包括2D/3D/mesh,单人/多人,自顶向下(top-down)/自底向上(bottom-up),图像(image)/视频(video),坐标/热图(heatmap), 检测(detection-based)/回归(regression-based) , 单阶段(single-stage)/多阶段(multi-stage)......等等,各种分类方法之间相互嵌套,每篇文章都有作者按照自己理解划分的类别,真的很让人摸不着头脑。但实际上,很多分类都有着递进的关系,例如:
图 分类关系
大部分论文在讲述的时候,都是继承之前的论文方法,因此很多细节讲的不是很清楚,一篇参考文献就一笔带过,如果没有完整的体系架构,直接看最新的文献会很乱,发现需要补充的知识越来越多,导致知识体系细碎繁杂,看完了也不知道讲的是什么。这里给出姿态估计的几篇综述文献,里面从各个角度讲述了姿态估计的一些经典方法和分类,有助于建立整个框架体系:
[1] Single Person Pose Estimation: A Survey(2021.09)https://arxiv.org/abs/2109.10056v1
[2] Monocular human pose estimation: A survey of deep learning-based methods(2020.06) https://arxiv.org/abs/2006.01423
[3] Deep Learning-Based Human Pose Estimation: A Survey(2020.11) https://arxiv.org/abs/2012.13392v1)
[4] Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective (2021.04)https://arxiv.org/abs/2104.11536
[5] Recovering 3D Human Mesh from Monocular Images: A Survey(2022.03)https://arxiv.org/abs/2203.01923v1
在写这篇文章的时候,发现了大神刚出的一篇比较好的总结,链接放到这里,供大家学习参考,可先阅读,对比和本文的异同,以作参考:
人体姿态估计的过去,现在,未来https://zhuanlan.zhihu.com/p/85506259
还有OpenMMlab有一期卢策吾老师的视频讲解,总结了pose相关的方法,链接如下,建议观看,以作参考:
https://www.bilibili.com/video/BV1kk4y1L7Xb
这里使用上面文献[4]的一张图展示一下相关研究和论文,按照时间顺序展示,清晰明了,推荐阅读这篇综述:
图 里程碑、想法或数据集突破,以及2014年至2021年2D(上)和3D(下)姿态估计的SOTA方法
另外上面文献[5]是关于人体Mesh研究的,也是我研究的一个领域,所以把这篇综述也放了上来,同样有一张图:
图 相关的参数化人体模型和三维人体网格重建方法
建立思路:按照时间建立自己的知识体系,个人认为是一个很好的方式,感受这个领域的方法一步一步的推进过程,一点一点构建自己的知识领域框架,后面读论文不再是一行一行读,而是一块一块地读;而且可以在阅读的过程中,从后面的研究者在Related Work中对早期的文章的见解和描述,是一种感受不同人对某一方法的不同见解的过程,幸运的话甚至可以从中得到启发。从一篇文献中追根溯源,并总结流派和方法,然后再继续关注当前的最新进展,逐步完善自己的领域,是我个人认为比较好的一种科研思维。
2. 体系架构
本文以如下结构进行介绍,包括人体2D,3D,Mesh;分别介绍每个类别的开山之作,主要流派(其中的经典代表网络和方法),以及最新进展,如果有更新的作品,欢迎大家进行补充。
图 文章体系架构
- 这里推荐OpenMMLAB实验室的mmpose项目:上面有很多总结、经典以及最新方法的实现和讲解,有框架,有代码,有教程,可快速复现,而且维护和更新也很块。
https://github.com/open-mmlab/mmpose
3. 2D姿态估计
3.0 必读论文总览
下图是2D姿态估计领域比较经典的论文,也是我认为必读的一些论文,建议按照时间顺序来阅读,可以从中感受2D姿态估计的层层递进。阅读的时候建议大家关注一下作者,因为很多论文包含了同一作者,说明两篇论文之间是有联系的,例如,Openpose的前身就是CPM,MSPN是基于CPN的修改,另外Hpurglass、CPN、SimpleBaseline2D在HRNet论文中做了比较......这些论文之间的异同以及包含关系,也是比较有趣的。所有论文的题目和链接也一起放在了下面,感兴趣的童鞋可以直接下载阅读。每一篇文章的详细讲解,大家可以在各大分享平台找到,很多大佬也都分享过自己的见解,本文仅对部分文章进行简单的介绍,梳理论文逻辑,详细的内容大家可以自行阅读论文或者搜索参考其他作者讲解的内容。
当然,只看论文是不够的,因为论文对网络结构的讲解比较抽象,进一步的学习一定要亲自敲一遍网络结构的代码,这一部分后续有时间也可以整理一下(挖坑1...)。
图 2D必读论文总览
3.1 开山之作(DeepPose)
《[DeepPose: Human Pose Estimation via Deep Neural Networks]》(CVPR'2014)https://arxiv.org/abs/1312.4659
图 DeepPose网络结构(蓝色卷积,绿色全连接)
DeepPose是姿态估估计领域中使用深度学习检测人体关节点的最初的论文,在它之前,很多文章都是基于身体部位(part)检测的。它 (1)继承了AleXNet网络结构,AlexNet 作为 backbone,是第一个DNN姿态估计网络;(2)采用级联(cascade)结构细化(refine)姿态。这对后面的网络结构思想有了很大启发,后续的很多网络也都采用了cascade的这种结构。
这篇文章提出了姿态估计的两个概念:
- 姿态估计的公式化定义
图 论文描述
- 级联(cascade)结构
cascade这个单词在后面的很多网络中都会用到,例如Hourglass和CPM,但我一开始并不太明白,后来翻看英文释义,表示“串联,级联”,也就是说,它将一个网络模块重复地使用多次,串在一起,形成multi-stage,相当于加深了层数,第一个stage粗检测,后面逐渐精细,类似于“从粗到细”的策略,逐渐纠正,不断细化。事实证明这种结构的有效性非常好。后续我们也会经常见到这个词,以及这种结构。
与之对应的还有一个词:stacked,堆叠,Hourglass使用了这个词的表述。两个词都表示同样或相似的Block结构多层连接。
论文使用的数据集有两个:FLIC和LSP,评价指标分别为PDJ(=0.9+)和PCP@0.5(=0.61),评价指标和数据集都比较旧了,现在已经很少使用。建议大家看看上面提到的综述论文,里面有数据集和评价指标的详细总结,后期有空,可以单独写一个总结(挖坑2...)。
填坑2:人体姿态估计评价指标见下文。
陌尘小小:【人体姿态估计评价指标】https://zhuanlan.zhihu.com/p/646159957
3.2 必看论文
- ResNet:
ResNet就不用多说了,源自何恺明论文《Deep Residual Learning for Image Recognition》。它几乎是现在深度学习框架的基石,几乎所有的backbone都用到它或者它的变体,当然,几乎所有的姿态估计的结构代码中都用到了这种残差结构。在使用代码的时候,主要注意三个函数,这也是后续所有网络结构代码经常用到的三个函数:BasicBlock;Bottleneck;_make-layer方法。具体原理大家可看论文或者其他大佬讲解。
图 ResNet的BasicBlock和Bottleneck结构
具体的代码可以看下面这个博文:
ResNet _make_layer代码理解https://blog.csdn.net/cangafuture/article/details/113485879
- FPN特征金字塔网络,是常用的Neck网络,后续有它的诸多变体,很多网络会用到它。写到这里大家要注意区分一下:图像金字塔和特征金字塔的概念,从下图(a)就可以很明显地看出来了。
图 特征金字塔
具体的代码和讲解可以看这个博文:
FPN网络结构及Pytorch实现https://blog.csdn.net/qq_41251963/article/details/109398699
下面还有一些方法网络很经典,每一篇都逐渐递进,每一篇都值得去看并且复现其网络结构,例如Hourglass的网络,甚至用了递归的方法构建网络,其中的细节就涉及到算法层面的知识了,但是了解每一种算法的输入输出和整体框架搭建思路,先构建体系,再深入了解细节,注意实际上手和操练,还是很不错的学习过程。这些论文的讲解网上有一大堆,大家可以自行查阅,后续有时间可以对其中的细节进行单独的写作,但是本篇仅作为入门使用。
- CPM
- Hourglass
- CPN
- MSPN
- HRNet:HRNet很经典,所以推一个B站的学习教程:
HRNet网络详解https://www.bilibili.com/video/BV1bB4y1y7qP
以上都是经典的人体姿态估计网络,或许称之为经典的单人姿态估计网络,对于多人姿态估计,分为自顶向下和自底向上,代表作分别是AlphaPose和OpenPose。
- 自顶向下(top-down) :AlphaPose
- 自底向上(bottom-up) :OpenPose。参考下面唐宇迪的讲解。
openpose教程人体姿态估计网络https://www.bilibili.com/video/BV1JD4y1W7jZ
3.3 最新进展
看完这些经典的论文之后自然要有所比较,在数据集那个哪个最优,这一部分可以看上文提到的综述[2],里面有每个方法的亮点和每个数据集相应的精度。进一步的精度对比可以看这个网站paperswithcode,里面有所有最新算法在数据集上的精度比较,记录了论文和代码,非常方便来个示例图,:
图 2DHPE在COCO数据集上的精度指标
链接如下:大家可以看最新的精度和效果在MSCOCO、MPII数据集上的榜单,从而对比自己正在阅读的论文和所做的工作有多大差距。
paperswithcode.comhttps://paperswithcode.com/area/computer-vision/pose-estimation
截至写本文的时候,最好的是基于Transformer的ViTPose。《ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation》,讲解可参考下文:
论文阅读:ViTPose27https://zhuanlan.zhihu.com/p/527877998
4. 3D姿态估计
4.0 必读论文总览
问题本质:
3D人体姿态估计是从图片或视频中估计出关节点的三维坐标 (x, y,z),它本质上是一个回归问题。
挑战:
(1)单视角下2D到3D映射中固有的深度模糊性与不适定性:因为一个2D骨架可以对应多个3D骨架,它具有在单视角下2D到3D映射中固有的深度模糊性与不适定性,这也导致了它本身就具有挑战性。
(2)缺少大型的室外数据集和特殊姿态数据集:这主要由于3D姿态数据集是依靠适合室内环境的动作捕捉(MOCAP)系统构建的,而MOCAP系统需要带有多个传感器和紧身衣裤的复杂装置,在室外环境使用是不切实际的。因此数据集大多是在实验室环境下建立的,模型的泛化能力也比较差。
研究方法:3D姿态估计受限于数据集和深度估计,大部分方法还是和2D姿态估计有着非常强的联系。
感兴趣的同学可以看一下这篇CSDN的博客,有个大致了解,下面的部分内容摘自其中。当然这篇里面的分类只是一种,大家参考综述[4]里面的配图9,也可以作为一种分类,不过大家注意每种分类方法,一些重要的文献总是归在同一类别的。
3D人体姿态估计论文汇总(CVPR/ECCV/ACCV/AAAI)https://yongqi.blog.csdn.net/article/details/107625327
4.1 开山之作:(DconvMP)
《3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network》,第一篇用卷及网络直接回归3D姿态的文章。
图 DconvMP网络结构图
- 总结:网络框架包含两个任务:(1)a joint point regression task;(2)joint point detection tasks。
- 输入:包含human subjects的bounding box图片。
- 输出:N×3(N=17)关节坐标
- 数据集:Human3.6M;
- 结果:MPJPE,使用Pearson correlation 和 LP norm探讨了DNN如何编码人体结构的依赖性与相关性。
4.2 必看论文基于回归
[1]《3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network》 (2014)[2]《VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera》 (ACM-2017)[3]《Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose》(CVPR-2017)[4]《Integral Human Pose Regression》(CVPR-2018)[5]《Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image》 (ICCV2019)
其中3-4-5是具有相关性的三篇论文
- 上述论文 [3](CVPR 2017)从2D图片中直接得到体素(Volumetric representation),而不是直接回归关节点的坐标,并取最大值的位置作为每个关节点的输出。体素是从2D姿态估计的heatmap学习而来,其实就是3D heatmap。第一步:ConvNet直接回归生成关节体素(传统是直接回归3D坐标),用到了Hourglass;第二步:采用从粗到细的Coarse-to-Fine预测策略。
论文3 配图
- 上述论文 [4] (ECCV 2018)是论文[3]的扩展工作,引入了积分回归(Integral Pose Regression)模块,也叫soft-argmax,将原先的取heatmap最大值对应的位置改成对heatmap求关节点的期望,使这一过程可微。全文就基于Integral Pose Regression模块做了大量的实验并验证其有效性,在3个数据集上分别实验成文。
论文4 配图
- 上述论文 [5] 是一个Top-Down的多人姿态估计,提出了一个模块化的整体结构:DetectNet+RootNet+PoseNet,DetectNet是目标检测网络,RootNet是本文重点,提出了一个深度估计方法,PoseNet借鉴了上述论文[4]的方法。论文代码在github分别提供了RootNet和PoseNet,便于实际项目应用.https://github.com/mks0601/3DMPPE_POSENET_RELEASE
论文5 配图
- 积分回归的代码讲解可以看我个人的B站视频,感兴趣的同学可以看一下。
ChatGPT助你理解积分人体姿态估计https://www.bilibili.com/video/BV1oM411A79c
基于2D->3D
- 《3D Human Pose Estimation = 2D Pose Estimation + Matching》
总结:首先是做2D的人体姿态估计,然后基于Nearest neighbor最近邻的match来从training data中找最像的姿态。2D的姿态估计算法是基于CPM来做的。3D的match方法是KNN(https://blog.csdn.net/u010608296/article/details/120640343)方法,先把training data中的人体3d骨架投射到2D空间,然后把test sample的2d骨架跟这些training data进行对比,最后使用最相近的2d骨架对应的3D骨架当成最后test sample点3D骨架。当training数据量非常多的时候,这种方法可能可以保证比较好的精度,但是在大部分时候,这种匹配方法的精度较粗,而且误差很大。
图 思路框架图
- SimpleBasline-3D:《A Simple Yet Effective Baseline for 3d Human Pose Estimation》https://github.com/weigq/3d_pose_baseline_pytorch
论文动机:论文作者开头就提到,目前最先进的 3d 人体姿态估计方法主要集中在端到端(直接回归)的方法,即在给定原始图像像素的情况下预测 3d 关节位置。尽管性能优异,但通常很难理解它们的误差来源于 2d姿态估计部分过程(visual),还是将 2d 姿势映射到 3d关节的过程。因此,作者将 3d 姿态估计解耦为2d 姿态估计和从2d 到 3d 姿态估计(即,3D姿态估计 = 2D姿态估计 + (2D->3D)),重点关注 (2D->3D)。所以作者提出了一个从2D关节到3D关节的系统,系统的输入是 2d 个关节位置数组,输出是 3d 中的一系列关节位置,并将其误差降到很低,从而证明3D姿态估计的误差主要来源于图像到2D姿态的过程,即视觉理解(visual)的过程。
图 SimpleBasline-3D网络结构
同样,从这个工作的名字可以看出,这个工作提出了一个比较simple的baseline,但是效果还是非常明显。方法上面来讲,就是先做一个2d skeleton的姿态估计,方法是基于Hourglass的,文章中的解释是较好的效果以及不错的速度。基于获得的2d骨架位置后,后续接入两个fully connected的操作,直接回归3D坐标点。这个做法非常粗暴直接,但是效果还是非常明显的。在回归之前,需要对坐标系统做一些操作。
基于时序(视频序列)
- VideoPose3D:《3D human pose estimation in video with temporal convolutions and semi-supervised training》利用这篇是利用视频做姿态估计的比较经典的论文,使用了多帧的图像来估计姿态,直觉上应该比单帧姿态估计要更加准确。两个贡献:1. 提出了一种基于2D关节点轨迹的空洞时域卷积方法,简单、有效的预测出视频中的3D人体姿态;2. 引入了一种半监督的方法,它利用了未标记的视频,并且在标记数据稀缺的情况下是有效的。
图 temporal convolutional model
图 An instantiation of our fully-convolutional 3D pose estimation architecture.
4.3 最新进展
关于最新进展,大家同样可以在paperswithcode网站去关注数据集Human3.6的榜单。
下面这个榜单是没使用2DGT数据集的:
monocular-3d-human-pose-estimation
https://paperswithcode.com/task/monocular-3d-human-pose-estimation
下面这个榜单是使用2DGT数据集:
Human3.6M Benchmark (3D Human Pose Estimation)
https://paperswithcode.com/sota/3d-human-pose-estimation-on-human36m
5. 3D形态重建(SMPL)
5.0 必读论文总览
3D形态估计是一个更新的任务,旨在恢复人体的三维网格,我的研究课题正好与此相关。研究这个方向的同学应该并不陌生,但是这里我们只介绍有关于SMPL的内容,再次推荐之前提到的综述论文[5] Recovering 3D Human Mesh from Monocular Images: A Survey(2022.03),里面的总结也是非常全的,截止2022年论文如下图所示:
图 Human Mesh
其论文可以归类为两类型:
- Optimization-based Paradigm 基于优化: Optimization-based approaches attempt to estimate a 3D body mesh that is consistent with 2D image observations.( 2D keypoints, silhouettes, segmentations.)即根据2D检测结果优化生成3Dmseh。代表作:SMPLify(ECCV'2016).https://smplify.is.tue.mpg.de/
- Regression-based Paradigm 基于回归: Regression-based methods take advantage of the thriving deep learning techniques to directly process pixels.即使用深度学习技术直接处理图像像素生成3Dmesh。代表作:HMR(CVPR'2018).https://akanazawa.github.io/hmr/
- 基于优化+回归。代表作: SPIN(ICCV'2019)(相当于HMR+SMPLify)https://www.seas.upenn.edu/~nkolot/projects/spin/
5.1 开山之作:《Smpl: A skinned multi-person linear model》
这篇是Michael J. Black实验室的SMPL开山之作,后续的大部分SMPL方法等也是该实验出品,大部分SMPL相关论文均是这个研究所出来的。
图 SMPL流程
- 核心思想就是将通过网络回归输出的姿态参数θ(_∈24×3_)和形态参数β(_∈10×1_)送入一个基础人体模板(Template mesh)T(_∈6480×3_),然后形成各种姿态和体型的人体姿态。
- 姿态参数控制(23+1)个关节点。与之前的3D关节点坐标回归不同,每个关节点由3个旋转参数控制,一共有23个,还有一个控制全局旋转,相当于根关节点(root),所以姿态参数θ共有[(23+1)×3]=72个参数;
- 形态参数控制人的体型,每个参数分别控制包括高矮、胖瘦、身体的局部比例等。1.0版本共有10个参数,后来的1.1版本拓展到300个参数,但是影响明显的仍然是前10个;
- 基本模板是个固定姿态的人体mesh,也就是[θ=0 和_β=0_ ]的情况,因此这个姿态也被称为“zero pose”[零姿态]。
- SMPL还训练了一个关节矩阵J ,可以从生成的人体mesh映射得到23个人体关节点坐标(x,y,z),所以基于SMPL的方法通过J 得到关节点坐标和3Dpose的方法对比,例如评价指标MPJPE。
- 后续论文方法均是致力于恢复更准确的3D Human mesh.
- 文章总结可参考下面的博文:
SMPL模型学习https://www.cnblogs.com/sariel-sakura/p/14321818.html
5.2 必看论文
以下必读论文来自商汤OpenMMLAB实验室的mmhuman3d项目,与之前提到的mmpose3d类似:上面有很多总结、经典以及最新方法的实现和讲解,有框架,有代码,有教程,可快速复现,而且维护和更新也很块。
https://github.com/wmj142326/mmhuman3dgithub.com/wmj142326/mmhuman3d
[1] SMPLify(ECCV'2016):《Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image》。 https://smplify.is.tue.mpg.de/
[2]SMPLify-X (CVPR'2019):《Expressive Body Capture: 3D Hands, Face, and Body from a Single Image》https://smpl-x.is.tue.mpg.de/
[3]HMR(CVPR'2018) :《End-to-end Recovery of Human Shape and Pose》https://link.zhihu.com/?target=https%3A//akanazawa.github.io/hmr/
[4] SPIN(ICCV'2019):《 Learning to Reconstruct 3D Human Pose and Shapevia Model-fitting in the Loop 》https://www.seas.upenn.edu/~nkolot/projects/spin/
[5] VIBE(CVPR'2020):《 Video lnference for Human Body Pose and Shape Estimation》https://github.com/mkocabas/VIBE
[6] HybrIK (CVPR'2021):《HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation》 https://jeffli.site/HybrIK/
[7] PARE (ICCV'2021):《PARE: Part Attention Regressor for 3D Human Body Estimation》 https://pare.is.tue.mpg.de/
[8] HuMoR (2021) :《3D Human Motion Model for Robust Pose Estimation》
[9] DeciWatch(ECCV'2022):《DeciWatch: A Simple Baseline for 10× Efficient 2D and 3D Pose Estimation》 https://ailingzeng.site/deciwatch
[10] SmoothNet (ECCV'2022):《SmoothNet:A Plug-and-Play Network for Refining Human Poses in Videos》 https://ailingzeng.site/smoothnet
[11] ExPose (ECCV'2020):《Monocular Expressive Body Regression through Body-Driven Attention》 https://expose.is.tue.mpg.de/
[12]BalancedMSE (CVPR'2022):《Balanced MSE for Imbalanced Visual Regression 》https://sites.google.com/view/balanced-mse/home
对其中的部分论文作简要介绍:
- SMPLify:基于优化的方法。给定一个图像,使用基于 CNN 的方法来预测 2D 关节位置。然后将 3D 身体模型拟合到此,以估计 3D 身体形状和姿势。https://smplify.is.tue.mpg.de/
- SMPLify奠定了SMPL重建算法的基石,它从单张图像中重建人体的SMPL姿态;
- 流程分为两步:1)单张图像经过DeepCutc恢复人体的2D关键点,2)然后利用2D关键点恢复SMPL姿态(这有点类似于2D->3D的提升);
- 提出了SMPL重建的损失函数(objective function),由5部分组成,包括:a joint-based data term and several regularization terms including an interpenetration error term(这个互穿项在SPIN中舍弃了,因为它使得拟合变慢,而且性能并没有提高多少), two pose priors, and a shape prior.后续的方法基本都使用该损失函数或对其进行改进。
图 SMPLify
- HMR:基于回归的方法。图像 I 通过卷积编码器传递。输入到迭代 3D 回归模块,该模块推断人类的潜在 3D 表示,以最小化联合重投影误差。3D 参数也被发送到鉴别器 D,其目标是判断这些参数是来自真实的人类形状和姿势。这里用到了GAN对抗生成网络。https://akanazawa.github.io/hmr/
图 HMR
- SPIN:基于优化+回归的方法。这篇文章主要是将基于迭代优化的方法(SMPLify)和基于网络回归的方法(HMR)进行结合。网络预测的结果作为优化方法的初始值,加快迭代优化的速度和准确性;迭代优化的结果可以作为网络的一个强先验。两种方法相互辅助,使整个方法有一种自我提升的能力,称之为SPIN(SPML oPtimization IN the loop)。https://www.seas.upenn.edu/~nkolot/projects/spin/
- SPIN算是HMR和SMPLify的结合,分别作为回归网络和优化网络,与SMPLify的区别(改进)如下:
- SPIN舍弃了损失函数中的互穿项;
- SPIN使用HMR的回归结果作为初始化结果,然后迭代优化一次;SMPLif使用0姿态初始化,迭代优化了4次;
- SPIN使用HMR回归的相机参数,SMPLify使用了三角形相似;
- SPIN的2D关节点使用了OpenPose, SMPLify使用了DeepCut;
- SPIN提供了GPU并行处理图片,SMPLify延时较高不适合处理单张图像。
图 SPIN
- VIBE:[参考文章:https://zhuanlan.zhihu.com/p/397553879]基于视频帧的方法。提出了一个利用视频进行动作估计的新方法,解决了数据集缺乏和预测准确率不佳的问题。本文的主要创新之处在于利用对抗学习框架来区分真实人类动作和由回归网络生成的动作。本文提出的基于时间序列的网络结构可以在没有真实3D标签的情况下生成序列级合理的运动序列。这一思想借鉴了2018年提出的HMR模型,这项工作从单张图片重建人体模型,而本文则将这一模型由图片扩展到了视频,在原有模型基础上加入了GRU和motion discriminator。https://github.com/mkocabas/VIBE
图 VIBE
- SmoothNet:解决姿态抖动问题。爱玲姐姐的佳作,解决3Dmesh的视频抖动问题。属于一个后处理操作,去抖动明显,只用了一个简单的全连接层设计,从位置、速度和加速度的三个量进行建模,进行了大量的试验证明其有效性。https://ailingzeng.site/smoothnet
图 SmoothNet的基础模块
图 SmoothNet 流程结构
作者有过一期视频讲解,链接放在这里,大家可以进一步听听,爱玲姐姐还讲了一些姿态的总结知识(人美声甜的大佬~):
【社区开放麦】第 14 期 从时间序列角度破解姿态估计中的两大问题https://www.zhihu.com/zvideo/1534485957927075840
5.3最新进展:
CLIFF(2022):《CLIFF: Carrying Location Information in Full Frames into Human Pose and Shape Estimation》
[参考链接:https://zhuanlan.zhihu.com/p/556885801]这篇是华为诺亚方舟出品。3D Human mesh中采用Top-Down策略的多人姿态估计。以极其优雅的方式,将原图的信息融合到人体姿态估计的神经网络的输入中,巨大提升了估计的准确度,刷到了3dpw的rank 1,并赢得了ECCV 2022的oral。正如参考的博文所说,他的处理方式极其优雅:
- 大部分的多人姿态估计都是对图像中的人体目标作裁剪然后运行单人姿态估计方法,这就缺失了每个人体目标在图像中的全局坐标信息;
- CLIFF在以HMR作为baseline的基础上,仅仅增加了3个输入,,分别为bbox的中心相对于原图中心的距离以及bbox的大小;
- 即考虑了人体目标在全局图像的信息作为监督,直觉上自然会有更多的监督信息,自然也就会得到更高的精度。最重要的是,这种处理方式就是看起来相当的......优雅!
- 原论文提供的Github源码貌似只有demo,不过好在mmlab代码仓库已经支持支持了CLIFF,可前往查看Train源码。
图 CLIFF
OSX(CVPR2023-IDEA)《One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer》, 2023年CVPR的最新文章,提供了一个Ubody上身数据集。个人感觉,这是个“大团队+工作量+SOTA”的结果。
- 大团队包括“清华大学和IDEA研究院”,也有港中文大学参与,二作是我前面提到的女神曾爱玲姐姐;
- 工作量包括全身关节点和mesh网格,而且制作了一个大数据集;
- SOTA结果,里面用到的算法主要是ViTPose, 基于Transformer的,算是最先进的算法了,当然本论文也取得了SOTA。
模型结构
数据集构建流程
其他的最新进展,大家可以关注3DPW这个数据集的paperswithcode榜单。https://paperswithcode.com/sota/3d-human-pose-estimation-on-3dpw?metric=MPJPE
6. 应用
那么,问题来了,关于HPE的方法,论文已经这么多了,最终它的应用场景是什么?学习这个领域,最终的目的也是工作,再好的方向跟不上工业界的需要也是瞎扯,闭门造车!这里写一些本人在学习和实习中的一些发现。
前情提要:本人硕士[现在是"菜博"了~:(],没有工作。但是有过相关实习,另外实验室也有相关的师兄弟从事这个方向,简单写一些所见所闻和个人感受,就当交流了,简单滴发表一些个人看法,后期发现说的不对了,再改hhhh~~。
6.1 学术研究
单纯的看姿态估计,它是一个基础任务,目的是从图像中获得信息,更重要的是如何利用这一部分信息,或者说用这一信息可以用在什么地方,所以这一任务在学术界是为其他任务提供数据支撑的,追求的是更高的精度,更快的速度,俗称“打榜”,更注重于方法研究。
现在的方法,层出不穷,但是个人认为,工业界的落地还是不多。学术界与工业界就像是一个狭窄的漏斗的两边,大量的方法研究堵在上头,却因为种种原因难以落地~
6.2 行为识别
自动驾驶的感知领域,行人行为识别、手势识别等是可以看得见的应用。但是,目前的自动驾驶好像并没有做到这一块,因为目前的自动驾驶还在“躲避障碍物”的阶段,检测任务还是应用的主流,行人的行为识别还存在比较远的路,精度、速度都是限制。
6.3 虚拟驱动
数字人、数字驱动、游戏建模,AR,VR,游戏和动画是目前的应用主流,这种限制场景下的姿态有实现的硬件基础;但是,单目的姿态估计感觉还是没有多视角的应用多,因为多一个摄像头不会花很多钱,还能提高精度;但是少一个摄像头的精度下降可能会带来体验感的下降。
6.4 感知皆可,格局打开
其实,人体姿态估计只是深度学习的一个任务罢了,它的基础知识,学习流程和其他的任务没有本质的区别,一通百通,手势的关节点不也是关键点吗?动物的关键点不也是关键点吗?只会一种任务适应不了时代的发展,我们学习的主要是一个领域,不要只把目光限制在“人体”和“姿态”,感知任务,皆可!7. 总结
这些大概就是关于人体姿态估计入门需要学习的一些知识了,相信看完这些,HPE的体系架构可以建立个七七八八了,其他具体的一些算法层面的知识,大家可以基于这个框架体系流程逐步完善,网上的大佬教程也是相当之多,写此篇的目的:
一算整理,避免资源过多,学习凌乱;二来帮助后人少走坑,尽量节省时间快速掌握;三来也算自己的笔记整理,方便日后查询;
#FastScene
更快、更便捷的3D场景生成算法
论文 FastScene: Text-Driven Fast 3D Indoor Scene Generation via Panoramic Gaussian Splatting已被国际人工智能顶级学术会议IJCAI-2024主会收录,由中山大学智能工程学院完成。论文第一作者为2023级硕士研究生马义坤,通讯作者为其导师金枝副教授。
- 原文链接:https://arxiv.org/abs/2405.05768
- Code:https://github.com/Mr-Ma-yikun/FastScene
三维模型在虚拟现实增强、游戏电影行业、智能家居等有着广泛应用。生成式模型的发展使得建立三维模型更加便捷,例如根据文本或图像生成三维物体。然而三维场景的生成仍具有较大挑战性。
该工作提出了一种新颖的三维场景快速生成方法,基于文本提示,利用全景图和空间运动约束,提出了渐进式全景修复策略,旨在得到高质量的多视角图像。此外,设计了全景图的高斯训练方法,能够更好的解决高斯泼溅无法处理非透视视角的问题。
Abstract
本文提出了一种快捷有效的3D室内场景生成算法,称为FastScene。对于用户,只需要输入一段描述室内的文本,便能快速且高质量的生成3D高斯场景。
本文的贡献与创新点如下:
- 提出了一个新颖的文本到3D室内场景生成框架FastScene,能够较为快速且高质量的生成3D高斯场景,且不需要预定义相机参数和运动轨迹,是一种友好的场景生成范式。
- 提出了一种渐进式的全景图新视角修复算法PNVI,能够逐渐得到不同视角的干净全景图。并且合成了一个大规模的球面掩码数据集。
- 通过引入多视角投影策略,解决了3D高斯无法使用全景图重建的问题。
Method

Network Architecture
图1给出了本文所提出的FastScene框架,包括:根据文本生成全景图与粗视角合成、渐进式新视角全景图修复、以及使用全景图进行3D高斯重建。

文本生成全景图与粗视角合成。与透视视角相比,全景图的一个关键几何特性是边界的连续性。此外,全景图囊括了整个场景表面的信息,相比透视图具有更加显式的几何约束。因此,我们选择全景图作为本文的操作对象。具体来说,首先输入一段文本,例如“一个带有沙发和桌子的舒适的客厅”,然后使用Diffusion360算法生成一张具有连续边界的全景图。然后,我们使用EGformer估计其深度,从而得到空间的立体信息。
为了得到不同位姿下的新视角,我们设计了粗视角合成策略(图2)。首先根据全景图坐标计算每个点的经纬角度:

然后,根据这两种角度,计算三维球面基坐标:

因此三维球面坐标可以表示为基坐标与深度值的相乘:

对于移动后的新坐标系,其基坐标可以用原坐标系表示为:

那么,新坐标系下的全景坐标可以表示为:

因此,接下来只需要判断哪些点位于有效坐标范围,并将无效坐标设为mask,从而得到带有孔洞的新视角全景图:
渐进式全景修复。 得到了带有Mask的全景图后,我们希望修复它获得干净视角。然而,



当我们尝试直接对大距离的全景图修复时,由于无效像素过多,因此修复质量并不理想。如表1所示,直接移动0.33m的孔洞占比为64.3%,这是不利于修复的。因此我们将大距离的移动划分为多个小微元的移动叠加,例如每次只移动0.02m。
此外,我们发现直接对全景图修复,随着移动步数的增加,容易造成扭曲和伪影。因此我们提出使用等距投影,将全景图投影到六张cubemap图像,然后进行修复。
全景3D高斯重建。 得到了多视角的干净的全景图后,我们希望我使用3D高斯重建场景。3D高斯需要先使用COLMAP,从输入视角重建稀疏点云。然而,现在有的COLMAP架构只能处理透视视角输入,无法处理全景图结构。因此,我们引入了一种多视角投影策略,根据用户需求,将全景图投影为多张透视视角,继而使用COLMAP进行稀疏点云重建。图4表明,经过我们的多视角投影策略,可以较好的重建出场景与位姿:

Experiments
Main Results

表2给出了FastScene和其它三维场景生成模型的对比,我们选择CLIP评分、NIQE以及BRISQUE作为评价指标。从表中可以发现,我们的方法不仅具有较好的指标评估性能,且生成速较快。
此外,为了更全面的展示我们的方法的性能,我进行了了定性的评估:

图5给出了不同场景生成方法的渲染视角的视觉效果对比,可以看到:我们的FastScene不仅生成的视角质量较高,且场景连续性也能够较好的保证。
更多的实验结果和实验细节,欢迎阅读我们的论文原文以及补充材料。
Ablation Studies
为了验证我们的渐进式全景视角合成策略的有效性,我们设计了两组消融实验:
直接对全景图修复。我们首先在合成的全景数据集上重新训练AOT-GAN。然而,我们发现小距离移动下的修复结果较好。但随着移动步数增加,图像扭曲和畸变越来越严重,我们认为这是由于移动过程中不可避免的深度估计误差以及全景特殊的形状结构导致的。
直接修复大距离移动的全景图。我们直接对大距离移动下全景图进行修复,由于其具有较大的孔洞占比,因此难以得到干净的图像。
表4和图8的对比结果可以进一步验证我们的渐进式修复方法的有效性。


中山大学智能工程学院的前沿视觉实验室( FVL: https://fvl2020.github.io/fvl.github.com/ )由学院金枝副教授建设并维护,实验室目前聚焦在图像/视频质量增强、视频编解码、3D 重建和无接触人体生命体征监测等领域的研究。
旨在优化从视频图像的采集、传输到增强以及服务后端应用的完整周期。我们的目标是开发通用的概念和轻量化的方法。为了应对这些挑战,我们将持之以恒地进行相关的研究,并与其他实验室进行合作,希望利用更多关键技术,解决核心问题。长期欢迎有志之士加入我们!
#COCO 数据集
COCO 数据集
MS COCO 数据集是 Microsoft 发布的大规模对象检测、图像分割和字幕数据集。机器学习和计算机视觉工程师广泛使用 COCO 数据集进行各种计算机视觉项目。
理解视觉场景是计算机视觉的主要目标;它涉及识别存在的对象、在 2D 和 3D 中定位对象、确定对象的属性以及描述对象之间的关系。因此,可以使用数据集训练对象检测和对象分类算法。

什么是COCO?
COCO 代表 Common Objects in Context 数据集,因为创建图像数据集的目的是为了推进图像识别。COCO 数据集包含用于计算机视觉的具有挑战性的高质量视觉数据集,其中大部分是最先进的神经网络。
例如,COCO 通常用于对算法进行基准测试,以比较实时对象检测的性能。COCO 数据集的格式由高级神经网络库自动解释。
COCO 数据集的特点
- 带有详细实例注释的对象分段
- 情境中的识别
- 超像素内容分割
- 在总共 330'000 张图像中,有超过 200'000 张图像被标记
- 1.5 Mio 对象实例
- 80 个对象类别,即“COCO 类”,其中包括可以轻松标记单个实例的“事物”(person、car、chair 等)。
- 91 个素材类别,其中 “COCO Stuff” 包括没有明确边界的素材和对象(天空、街道、草地等),这些素材和对象提供了重要的上下文信息。
- 每张图片 5 个字幕
- 250'000 人,有 17 个不同的关键点,常用于姿势估计
COCO 对象类列表
用于对象检测和跟踪的 COCO 数据集类包括以下预先训练的 80 个对象:
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis','snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
COCO 关键点列表
COCO 关键点包括 17 个不同的预训练关键点(类),这些关键点用三个值 (x,y,v) 进行注释。x 和 y 值标记坐标,v 表示关键点的可见性 (可见、不可见)。
"nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_elbow", "right_elbow", "left_wrist", "right_wrist", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle", "right_ankle"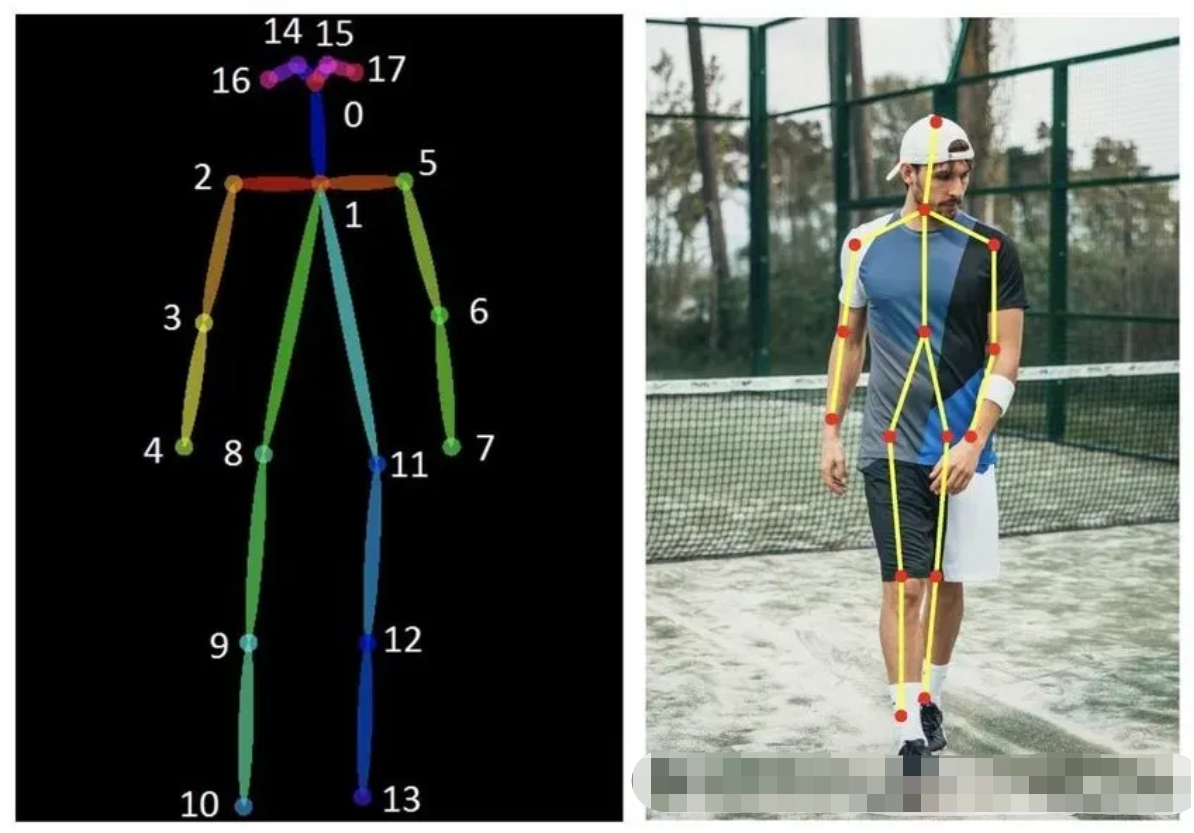
带标注的 COCO 图像
大型数据集包括常见物体在自然环境中的日常场景的注释照片。这些对象使用预定义的类(如 “chair” 或 “banana”) 进行标记。标记过程,也称为图像注释,是计算机视觉中非常流行的技术。
虽然其他对象识别数据集侧重于 1) 图像分类,2) 对象边界框定位,或 3) 语义像素级实例分割,但 mscoco 数据集侧重于 4) 分割单个对象实例。


为什么在自然环境中是常见的物体?
对于许多类别的对象,都有可用的图标视图。例如,当对特定对象类别(例如,“椅子”)执行基于 Web 的图像搜索时,排名靠前的示例将出现在 Profile 中,畅通无阻,并且靠近非常有序的照片的中心。请参阅下面的示例图像。
虽然图像识别系统通常在此类标志性视图上表现良好,但它们很难识别显示复杂场景或部分遮挡对象的真实场景中的物体。因此,Coco 图像的一个重要方面是它们包含包含多个对象的自然图像。

如何使用 COCO 计算机视觉数据集
COCO 数据集可以免费使用吗?
是的,MS COCO 图像数据集根据 Creative Commons Attribution 4.0 许可证获得许可。因此,此许可证允许您分发、重新混合、调整和构建您的作品,甚至是商业用途,只要您注明原始创作者。
如何下载 COCO 数据集
有不同的数据集分割可以免费下载。每年的图像都与不同的任务相关联,例如对象检测、点跟踪、图像描述等。
要下载它们并查看最新的 Microsoft COCO 2020 挑战赛,请访问 MS COCO 官方网站。为了高效下载 COCO 镜像,建议使用 gsutil rsync 来避免下载大型 zip 文件。您可以使用 COCO API 设置下载的 COCO 数据。
COCO 建议使用开源工具 FiftyOne 来访问 MSCOCO 数据集以构建计算机视觉模型。

COCO 数据集与开放图像数据集 (OID) 的比较
COCO 数据集的一个流行替代方案是由 Google 创建的开放图像数据集 (OID)。在将可视化数据集 COCO 和 OID 用于项目以优化所有可用资源之前,必须了解和比较视觉数据集 COCO 和 OID 的差异。
开放图像数据集 (OID)
是什么让它与众不同?Google 使用图像级标签、对象边界框、对象检测分割掩码、视觉关系和本地化叙述对 OID 数据集中的所有图像进行注释。与 COCO 相比,这使得它用于计算机视觉任务略多,因为它的注释系统略宽。OID 主页还声称它是现有最大的具有对象位置注释的数据集。
Open Image 是一个包含大约 900 万张预注释图像的数据集。Google 的 Open Images Dataset 的大多数(如果不是全部)图像都是由专业图像注释员手动注释的。这确保了每张图像的准确性和一致性,并在使用时为计算机视觉应用带来更高的准确率。
上下文中的常见对象 (COCO)
是什么让它与众不同?借助 COCO,Microsoft 引入了一个视觉数据集,其中包含大量照片,这些照片描绘了复杂的日常场景中的常见物体。这使 COCO 有别于其他对象识别数据集,这些数据集可能是人工智能的特定特定领域。这些部门包括图像分类、对象边界框定位或语义像素级分割。
同时,COCO 的注解主要集中在多个独立对象实例的分割上。与 CIFAR-10 和 CIFAR-100 等其他流行的数据集相比,这种更广泛的关注点使 COCO 能够在更多实例中使用。但是,与 OID 数据集相比,COCO 并没有太突出,在大多数情况下,两者都可以使用。
COCO 在 328k 图像中拥有 250 万个标记实例,是一个非常大且广泛的数据集,允许多种用途。但是,这个数量无法与 Google 的 OID 相提并论,后者包含高达 900 万张带注释的图像。
Google 的 900 万张带注释的图像是手动注释的,而 OID 披露它使用自动化和计算机化的方法生成了对象边界框和分割掩码。COCO 和 OID 都没有透露边界框的准确性,因此他们是否认为自动边界框比手动创建的边界框更精确,这仍然取决于用户。

#Matching Anything
继分割一切后,匹配一切
MASA(Matching Anything By Segmenting Anything)提供了一个通用的实例外观模型,用于匹配任何 domain 中的任何对象。

在复杂场景中,相同对象跨视频帧的稳健关联对于许多应用程序至关重要,尤其是多对象跟踪 (MOT)。目前的方法主要依赖于标记的特定领域的视频数据集,这限制了学习到的相似性嵌入的跨域泛化。我们提出了 MASA,这是一种用于稳健实例关联学习的新方法,能够跨不同域匹配视频中的任何对象,而无需跟踪标签。利用 Segment Anything Model (SAM) 中丰富的对象分割,MASA 通过详尽的数据转换来学习实例级对应关系。我们将 SAM 输出视为密集对象区域建议,并学习从大量图像集合中匹配这些区域。我们进一步设计了一个通用的 MASA 适配器,它可以与基础分割或检测模型协同工作,并使它们能够跟踪任何检测到的物体。这些组合在复杂域中表现出很强的零镜头跟踪能力。对多个具有挑战性的 MOT 和 MOTS 基准的广泛测试表明,所提出的方法,仅使用未标记的静态图像,在零镜头关联中,比使用完全注释的域内视频序列训练的最先进的方法取得了更好的性能。
🏋 优势:
✅ 创新方法:MASA(通过分割任何内容匹配任何内容)框架是一种开创性的方法,它利用细分任何内容模型 (SAM) 进行关联学习,而无需依赖跟踪标签。这允许跨不同域匹配视频中的任何对象,从而提高对象跟踪系统的灵活性和稳健性。
✅ 通用适配器:MASA 适配器可以与各种基础分割和检测模型集成,显著提高它们跟踪任何检测到的对象的能力。这种普遍适用性证明了令人印象深刻的零镜头跟踪能力,使该方法具有高度的通用性。
✅ 综合评估:本文对几个具有挑战性的基准进行了广泛的评估,包括 TAO MOT、开放词汇 MOT、MOT 和 MOTS on BDD100K 以及 UVO。结果表明,MASA 的性能优于使用完全注释的域内视频序列训练的最先进的方法,凸显了其卓越的性能。
✅ 自我监督学习:该方法通过从丰富的未标记图像集合中构建密集的实例级对应关系,有效地利用了自我监督学习。这种方法增强了模型跨不同领域泛化的能力,从而减少了对大型带注释数据集的需求。
✅ 效率改进:MASA 适配器将分割过程显着加快了 10 倍以上,这对于实时跟踪应用程序至关重要。这种效率提升是在不影响跟踪准确性的情况下实现的,因此该方法可用于各种实际场景的部署。
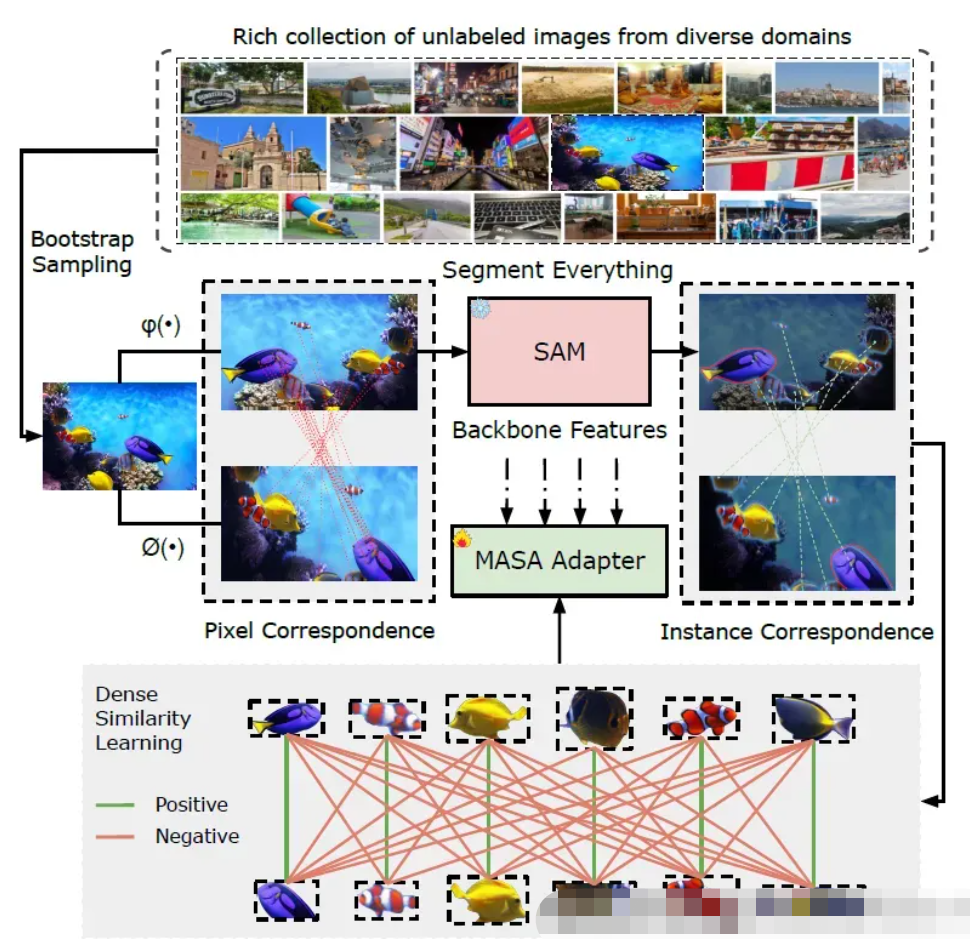
📊 算法核心:
SAM 组件:Segment Anything Model (SAM) 包括图像编码器、提示编码器和掩码解码器。这些组件协同工作,从输入图像生成详尽的实例掩码。
MASA 管道:MASA 管道采用强大的数据增强来创建同一图像的不同视图,从而有助于生成密集的实例级对应关系,以实现自我监督学习。此过程允许模型在没有显式跟踪标签的情况下学习强大的实例关联。
实例相似性学习:通过利用对比学习技术,该方法可确保同一实例的对象嵌入在特征空间中更接近,而不同实例的嵌入距离更远。这种学习策略使模型能够获得用于对象跟踪的高度判别性特征。
特征转换:MASA 适配器使用多尺度特征金字塔和可变形卷积转换基础模型的冻结主干中的特征。这些转换增强了实例表示,使其更适合用于跟踪目的。
性能指标:该白皮书提供了各种基准测试的详细性能指标,表明 MASA 不仅实现了更高的准确性,而且还提高了处理速度。这种双重优势强调了该方法在学术研究和工业应用中的实用性。
🌟 技术亮点:
图像编码器:利用高级架构从输入图像中提取高级特征,为后续处理阶段提供强大的基础。
提示编码器:对指导掩码生成过程的各种提示进行编码,从而实现灵活且上下文感知的分段。
掩码解码器:生成详细的实例蒙版,准确描绘图像中的对象,为有效的实例关联奠定基础。
数据增强:实施一系列增强,包括几何变换和颜色调整,以创建用于自我监督学习的多样化视图。
对比学习:采用对比损失函数来学习判别特征,增强模型区分不同实例的能力。
可变形卷积:采用标准卷积运算,以更好地捕获复杂的物体形状和运动,从而提高跟踪精度。
#MatchDiffusion
零训练的自动化视频匹配剪辑生成
本文为粉丝投稿,原文链接:https://zhuanlan.zhihu.com/p/11907467340,完整代码将在论文被录用后公开。
- 论文标题:MatchDiffusion: Training-free Generation of Match-Cuts
- 论文链接:https://arxiv.org/pdf/2411.18677
- 项目链接:https://matchdiffusion.github.io/
,时长00:48

效果示例
1. 简介
在电影制作中,匹配剪辑(Match-Cut)是一种强大的叙事工具,通过将两个场景以视觉上无缝连接的方式过渡,可以传达深刻的意象和情感。《2001太空漫游》中骨头变为宇宙飞船的经典剪辑便是一个绝佳示例。然而,制作匹配剪辑需要高度精心的策划和大量资源,普通视频生成模型难以实现。
,时长00:03
正如 John Lasseter 所说:“The art challenges the technology, and the technology inspires the art.” 这句话完美诠释了艺术与技术之间的相互促进关系。在匹配剪辑的领域,技术的突破不仅让艺术创作更加丰富多样,也让普通创作者得以用更少的资源实现更高的艺术追求。
为此,MatchDiffusion 提出了一种基于文本提示生成视频匹配剪辑的零训练方法。无需训练数据,仅借助预训练的扩散模型,通过“联合扩散(Joint Diffusion)”和“分离扩散(Disjoint Diffusion)”机制,生成视觉上连贯但语义上独特的视频对,极大简化了匹配剪辑的生成过程。以下展示的是基于 MatchDiffusion 模型的复现案例。通过这些案例可以看到,无需额外训练,仅通过文本提示即可生成视觉协调且语义独特的视频,完美契合匹配剪辑的需求。

复现结果示例
2.核心方法
2.1 扩散模型简介
扩散模型是一种强大的生成模型,其核心通过逐步从高斯噪声中去噪以生成高质量的符合文本描述的视频。在扩散过程的初期阶段,模型构建视频的总体结构,包括场景布局、色彩分布和运动轨迹,这些被称为“广义结构特征”。
随着去噪的逐步进行,模型逐渐引入更细粒度的细节,如纹理、物体形状和光影效果,从而形成完整且逼真的视频。MatchDiffusion 充分利用了这一特性,在前几个去噪步骤中通过“联合扩散” (Joint Diffusion) 共享视频的整体结构,使两个视频在视觉上协调一致;随后,通过“分离扩散” (Disjoint Diffusion) 分别生成两个视频的语义细节。
这样的分阶段去噪策略保证了视频既能保持结构一致性,又能展示语义多样性,从而完美适配匹配剪辑的需求。类比艺术家作画,扩散过程的前几步专注于“打草稿”,决定了场景的整体布局和运动方向,而后几步则负责“上色”,将细节填充到每一帧中。
2.2 MatchDiffusion 的两阶段策略

技术框架
2.2.1 联合扩散(Joint Diffusion)
联合扩散是 MatchDiffusion 的第一阶段,其目标是通过共享噪声样本确保视频的结构一致性。在这一阶段:
- 两个文本提示的噪声预测 和 被通过函数 平均组合。
- 这种组合方法可以保证视频初期的布局、运动模式等结构特征对两个场景保持一致。模型通过前 次去噪迭代建立了“骨架”,这种骨架既符合两个文本提示的要求,又提供了足够的灵活性,为后续生成细节奠定了基础。
- 比如,如果两个提示分别描述“阳光下的沙滩”和“雪山顶的风暴”,联合扩散将为两个视频构建相同的地平线布局和大致色彩过渡。
2.2.2 分离扩散(Disjoint Diffusion)
在联合扩散完成后,模型进入分离扩散阶段,使两个视频根据各自的文本提示生成独立的语义细节:
- 从第 步开始,模型分别以 和 为条件,生成符合提示语义的视频细节。
- 在这一阶段,两个视频独立去噪,生成特定的纹理、颜色和语义内容,同时保留在联合扩散中共享的结构一致性。模型可以分别根据两个提升展开去噪,添加独属于每个场景的细节,比如沙滩的波浪和雪山的暴风雪。
- 这种方法确保最终的视频不仅在整体视觉效果上协调一致,还能通过语义上的差异性形成有趣的匹配剪辑。为匹配剪辑提供丰富的可能性。
2.2.3 用户介入(User Intervention)
MatchDiffusion 引入了用户干预机制,允许在生成过程中融入用户的修改以实现更细致的个性化调整。通过一种人机交互策略(human-in-the-loop strategy),用户可以对生成的视频进行进一步定制,例如调整色调以更好地匹配先前序列的视觉风格,或修改背景以增强场景的连贯性。这种干预不是通过后期处理完成,而是直接嵌入到扩散过程中的,从而保持生成结果的真实性和一致性。
具体来说,用户干预被定义为一种通用的用户驱动修改,记作 ,可以是自动化的(如颜色查找表调整)或手动的(如添加场景元素)。
在去噪视频的分离扩散路径中,我们将 应用于去噪结果 ,公式如下:。然后将修改后的结果编码为其对应的潜在表示,并通过分离扩散路径继续生成,直到完成剩余的去噪迭代。这样的设计确保即使用户的干预可能在后处理中影响场景的真实性,扩散过程的后续迭代也能够自然地优化和整合这些修改。
如图 4 所示,用户可以通过掩码操作或背景替换等直接参与修改,从而生成更符合需求的最终视频。

用户介入示例
3.实验与结果
3.1 实验设置
- 模型:统一使用预训练的 CogVideoX-5B 扩散模型。
- 视频长度:40 帧,匹配剪辑由前 20 帧和后 20 帧拼接组成。
- 运行环境:NVIDIA A100 上生成一个匹配剪辑需要约 7 分钟。
3.2 定量指标
我们选择了两个具有代表性的基线模型 (Baseline):
- Video-to-Video Translation (V2V):通过先生成一个符合第一个提示的场景,再对其进行噪声注入,调整为符合第二个提示的场景。CogVideoX-5B-V2V 在保持视频结构一致性方面表现良好,但当两个提示语义差距较大时容易失效。
- Motion Transfer: 基于 SMM 或 MOFT 的运动迁移方法,从生成的第一个视频中提取运动模式并应用于第二段提示的视频生成。通过分离运动与内容,这类方法允许更大的语义灵活性,但可能导致场景结构的显著偏离。我们在实验中重新实现了 SMM 和 MOFT,以确保与 CogVideoX-5B 的兼容性。这种方法的灵活性较强,但容易破坏整体结构一致性。结果表明,相较于 MOFT,SMM 在生成的运动平滑性和一致性上表现得更为优异。这是因为 SMM 更加注重运动特征的提取与保留,使其能更好地适应匹配剪辑的需求,而 MOFT 虽然提供了更高的语义灵活性,但在多帧场景中容易引入不必要的视觉扭曲,从而破坏整体的结构连贯性。

定量分析
在评估模型时,我们选用了以下三种核心指标来对比不同方法的性能:
- CLIPScore:衡量生成视频与文本提示匹配程度的关键指标。数值越高,视频与文本提示的语义契合度越高。CLIPScore 的计算基于视频 和 每帧与 、 的匹配得分的平均值。在表 1 中,MatchDiffusion 和 SMM 共同实现了最高得分 0.34,显示了其在文本语义匹配上的可靠性。
- Motion Consistency:用于评价两个视频在运动模式上的一致性,即场景连接是否自然流畅。较高的数值表明运动衔接更流畅。MatchDiffusion 在此指标上达到 0.70,显著高于其他方法,表明其在运动一致性上的领先性能。
- LPIPS:基于帧间感知相似性,用于评估两个视频之间的结构一致性。较低的 LPIPS 值表示过渡更平滑、结构更一致。V2V 方法在结构一致性上表现最佳(0.31),但其语义变化较小,而 MatchDiffusion 在兼顾结构一致性和语义变化方面取得了更好的平衡(0.32)。
综上,通过与基线模型(如 V2V 和运动迁移方法 MOFT、SMM)的对比可以看出,MatchDiffusion 通过与基线模型(如 V2V 和运动迁移方法 MOFT、SMM)的对比可以看出,MatchDiffusion 在匹配剪辑的连贯性和视觉一致性上表现显著更优。
图 9 展示了控制参数 K 对 CLIPScore、Motion Consistency 和 LPIPS 的影响,进一步验证了 MatchDiffusion 在不同生成需求下的灵活性和稳定性。
当 K 较小时,CLIPScore 保持在较高水平(约 0.32),视频的文本语义契合度较高,但 LPIPS 指标较高,表明两个视频在视觉上更独立,语义切换明显。
随着 K 增加,Motion Consistency 指标逐渐提升,视频的运动轨迹愈加协调一致,LPIPS 减小,结构连贯性增强,但 CLIPScore 稍有下降。这是因为较大的 K 值生成了混合视频,融合了两个提示的特性,导致语义契合性略微减弱。
总的来说,MatchDiffusion 能够通过调整 K 值在语义切换和视觉一致性之间灵活平衡,这是现有基线方法难以企及的优势。

K值分析
3.3 用户干预分析

用户介入评估
我们对 MatchDiffusion 的用户干预机制进行了系统的实验分析,以验证其是否能够在不破坏匹配剪辑真实感的情况下,灵活地修改视频内容。
具体而言,我们评估了三种用户干预操作 τ:(1)颜色抖动(Color Jittering),(2)直方图匹配(Histogram Matching)和(3)伽马校正(Gamma Correction)。这些操作被应用于 ,以进一步调整视频的视觉属性。
从图 8(a) 的结果可以看出,MatchDiffusion 能够有效处理用户的修改需求。例如,在第一行的样例中,颜色抖动引入了蓝色调的变化,但在分离扩散路径中,修改被自然整合,最终生成的结果保持了视觉真实感和一致性。
类似地,第二行和第三行的背景替换和色调调整也在修改后的扩散过程中得到了良好的整合。我们进一步通过 CLIPScore 和 SSIM 对生成结果进行了量化分析(图 8(b))。尽管用户干预可能会降低结构相似性(SSIM 值下降),但 MatchDiffusion 的 CLIPScore 保持稳定,表明生成视频依然能够很好地匹配提示文本。
这表明,与后处理方法相比,MatchDiffusion 的用户干预策略能够在保留匹配剪辑真实性的同时,实现灵活的修改。

用户介入评估
3.4 用户研究
在用户研究中,我们从视觉一致性、文本提示契合度和语义切换效果三个维度对生成方法进行了全面评估。
首先,MatchDiffusion 在视觉一致性维度表现最为突出。接近 80% 的用户对其生成的匹配剪辑表示“认同”或“强烈认同”,这一比例远远高于 MOFT 和 V2V。尤其是在“强烈反对”的选项上,V2V 的占比高达 25%,表明传统方法在生成自然流畅的视觉过渡方面存在明显缺陷。MatchDiffusion 的高视觉一致性得益于其独特的扩散策略,能够在生成视频时同时保持结构的稳定性和细节的丰富性 。
其次,在文本提示契合度上,MatchDiffusion 以 39.44% 的“强烈认同”获得了最优评价,这一比例显著高于 MOFT 的 12.36% 和 V2V 的不足 10%。

用户定性分析
这一结果表明 MatchDiffusion 能够更好地捕捉和反映文本提示的语义内容,为用户提供与提示紧密相关的视频生成结果。
最后,在语义切换效果方面,MatchDiffusion 展现了兼顾视觉一致性和语义灵活性的能力。MOFT 在语义灵活性上具有一定优势,但因其视觉一致性不足,用户整体评价不高。而 MatchDiffusion 则在两个维度上均表现优秀,获得了用户的高度认可。
综合来看,MatchDiffusion 在所有维度的表现均衡且出色,不仅在视觉一致性和文本契合度上表现最佳,同时也展现了在语义切换效果上的独特优势,是生成匹配剪辑的理想方案。
3.5 结果比较

MatchDiffusion 生成结果示例

Matchdiffusion 与 Baseline 生成结果比较
4. 优势与局限性
MatchDiffusion 的一个显著优势是完全依赖于预训练模型,无需额外的数据集或训练过程,这大幅降低了技术门槛,使其更加适合资源有限的创作者。此外,MatchDiffusion 在生成多样性方面表现出色。通过调整扩散步骤 K,用户可以灵活控制两个视频之间的相似度。
具体来说,当 K 较大时,两个视频共享更多的扩散步骤,结构和内容会更加相似,适合生成具有高度视觉连贯性的匹配剪辑;而 K 较小时,两个视频更早进入独立扩散阶段,各自的语义特性更加突出。这样的灵活性让 MatchDiffusion 能够适应从统一风格的视频到完全独立的语义切换等多种需求。
不过,这种方法也有一些不足之处。首先,生成效果高度依赖提示文本的质量,用户需要具备一定的设计能力,才能发挥 MatchDiffusion 的潜力。此外,尽管生成过程非常便捷,但它对细节的控制能力有限。例如,用户无法直接调整视频的某些具体属性,比如颜色搭配或光影效果,这对一些高要求的项目来说可能会有所局限。
5. 未来研究方向
未来的研究方向可以从以下关键领域展开,以进一步提升 MatchDiffusion 的性能和适用性。
首先,自动提示生成是一个值得关注的方向。当前方法的生成质量高度依赖用户输入的文本提示,这对非专业用户可能构成障碍。因此,通过自然语言生成技术,自动生成符合目标需求的高质量提示文本,可以显著降低使用门槛,并帮助用户更好地实现创意表达。
其次,在生成过程中的细粒度控制方面还有很大的改进空间。当前 MatchDiffusion 的自动化生成过程尽管方便,但缺乏对视频具体属性的调整能力,例如颜色风格、场景结构和运动模式等。
如果未来可以通过设计可调控参数或交互式生成工具,让用户对这些细节有更多掌控权,将显著提升方法的应用广度。
6. 总结
MatchDiffusion 开创了匹配剪辑生成这一全新的任务领域,并通过创新性的扩散生成策略实现了无需额外训练的高质量视频生成。模型提出的联合扩散和分离扩散机制,使其能够同时保持视觉一致性和语义切换的灵活性,在实验中全面超越现有基线方法。
此外,作为匹配剪辑生成的首个解决方案,MatchDiffusion 在 CLIPScore、Motion Consistency 和 LPIPS 等指标上树立了新的基准,为后续研究提供了明确的性能目标。尽管未来可能会有方法尝试挑战这些指标,MatchDiffusion 的表现已经证明了其在这一领域的领先性和开创性意义。
无论是探索创意还是快速制作视觉内容,这项技术都为创作者提供了强有力的支持。
#UNet 架构的8个热门面试问题
主要介绍关于UNet架构的8个热门面试问题,希望对你有所帮助。
UNet架构是专门为图像分割任务设计的深度学习模型。由于其能够处理高分辨率图像并生成准确的分割图,因此广泛应用于各种应用,例如医学图像分割、卫星图像分析和自动驾驶车辆中的目标检测。UNet 非常适合多类图像分割任务,但可能需要平衡训练数据或使用概率分割图来处理类重叠或不平衡的类分布。本文主要介绍关于UNet架构的8个热门面试问题,希望对你有所帮助。
面试问题与答案
【1】您能解释一下什么是UNet架构以及它是如何使用的吗?
UNet架构是专门为图像分割任务设计的深度学习模型。Olaf Ronneberger 等人在论文“U-Net:用于生物医学图像分割的卷积网络”中介绍了它。
UNet架构由两部分组成:收缩路径和扩展路径。收缩路径是一系列卷积层和最大池化层,用于对输入图像进行下采样并提取特征。扩展路径是一系列卷积层和上采样层,它们对收缩路径中的特征图进行上采样,并将它们与输入图像中的特征组合以生成最终的分割图。
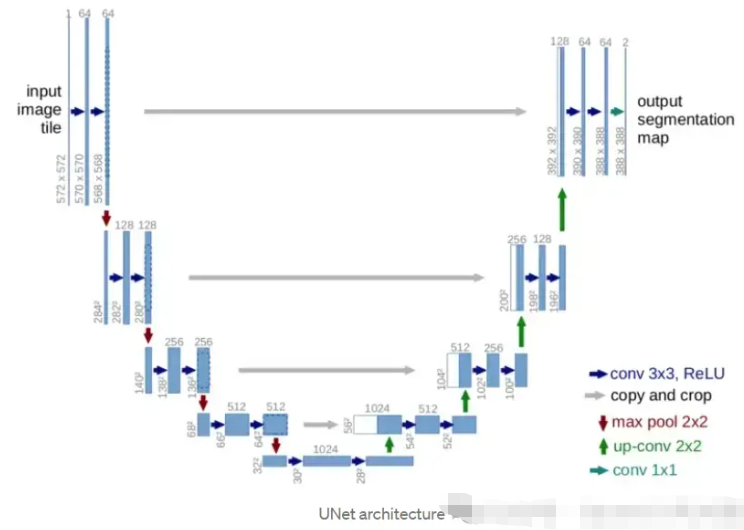
UNet 架构通常在大型带注释图像数据集上进行端到端训练,以预测每个图像的像素级分割图。可以训练模型来分割单个类别或多个类别,具体取决于具体任务。
UNet 广泛应用于各种图像分割任务,例如医学图像分割、卫星图像分析和自动驾驶车辆中的目标检测。它以其处理高分辨率图像和生成准确分割图的能力而闻名。
【2】UNet架构的主要组成部分是什么,它们如何协同工作?
UNet架构的主要组成部分是收缩路径、扩展路径和跳跃连接。
收缩路径是一系列卷积层和最大池化层,它们对输入图像进行下采样并从中提取特征。卷积层将一组滤波器应用于输入图像并生成特征图,而最大池化层通过在像素窗口内获取最大值来对特征图进行下采样。
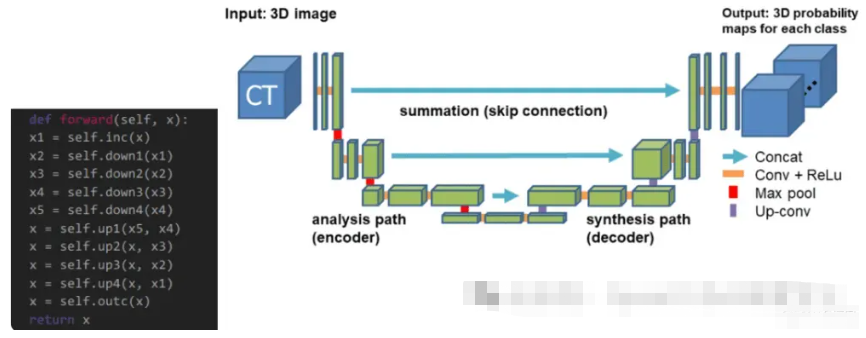
最终的分割图是通过对收缩路径中的特征图进行上采样并将其与扩展路径中输入图像的特征相结合而创建的,扩展路径是一系列卷积层和上采样层。卷积层将一系列滤波器应用于上采样的特征图以创建最终的分割图。相反,上采样层通过重复像素窗口内的值来提高特征图的空间分辨率。
这些连接(称为“跳跃连接”)绕过扩展路径中的一个或多个级别,并将它们链接到收缩路径中的相应层。它们使输入图像中的高级和低级信息能够合并到模型中,从而提高分割图的精度。
总体而言,UNet 架构的工作原理是使用收缩路径从输入图像中提取特征,使用扩展路径和跳跃连接将这些特征与输入图像的特征组合起来,并使用扩展路径中的卷积层生成最终的分割图。
【3】UNet 架构与全卷积网络 (FCN) 等其他图像分割系统有何区别?
UNet架构和全卷积网络(FCN)都是常用于图像分割任务的深度学习架构。然而,这两种架构之间存在一些关键差异:
- 架构:
UNet架构由收缩路径和扩展路径组成,它们通过跳跃连接连接。收缩路径用于从输入图像中提取特征,扩展路径用于对特征图进行上采样并生成最终的分割图。相比之下,FCN 由单个编码器-解码器结构组成,其中编码器是一系列卷积层和最大池化层,用于对输入图像进行下采样并提取特征,解码器是一系列卷积层和上采样层,用于对特征图进行上采样并生成最终的分割图。 - 参数数量:
由于跳跃连接和扩展路径中的附加层,UNet 架构通常比 FCN 具有更多参数。这会使 UNet 更容易出现过度拟合,尤其是在处理小型数据集时。 - 计算效率:
FCN 通常比 UNet 具有更高的计算效率,因为它的参数更少,并且不需要对跳跃连接进行额外的计算。这可以使 FCN 更适合需要快速推理时间或低计算资源的任务。 - 性能:
一般来说,UNet 在图像分割任务上往往比 FCN 表现更好,特别是在处理高分辨率图像或具有大量类别的数据集时。然而,两种架构的性能可能会根据具体任务和训练数据的质量而有所不同。
【4】您能讨论一下使用UNet架构进行图像分割任务的优点和缺点吗?
以下是使用 UNet 架构进行图像分割任务的一些优点和缺点:
优点:
高性能:UNet 以生成准确的分割图而闻名,特别是在处理高分辨率图像或具有许多类别的数据集时。
良好处理多类任务:UNet 非常适合多类图像分割任务,因为它可以处理大量类并为每个类生成像素级分割图。
训练数据的有效利用:UNet 使用跳跃连接,这使得模型能够合并输入图像中的高级和低级特征。这可以使 UNet 更有效地使用训练数据并提高模型的性能。
缺点:
大量参数:由于跳跃连接和扩展路径中的附加层,UNet 具有许多参数。这可能会使模型更容易过度拟合,尤其是在处理小型数据集时。
高计算成本:由于跳跃连接,UNet 需要额外的计算,这使得它比其他架构的计算成本更高。
对初始化敏感:UNet 对模型参数的初始化敏感,因为跳跃连接会放大初始权重中的任何误差。与其他架构相比,这使得训练 UNet 变得更加困难。
【5】您能提供一个 UNet 架构的实际应用示例吗?
UNet 架构的实际应用示例之一是医学图像分割。在此应用中,UNet 模型在带注释的医学图像(例如 CT 扫描或 MRI)的大型数据集上进行训练,目的是预测每个图像的像素级分割图。分割图可以识别图像中的不同结构或组织,例如器官、骨骼或肿瘤。

医学图像分割是医学中的一项重要任务,因为它可以帮助医生和研究人员更好地了解身体的解剖学和生理学并识别异常或疾病。UNet 架构非常适合这项任务,因为它能够处理高分辨率图像并生成准确的分割图。
UNet 架构的其他实际应用包括卫星图像分析、自动驾驶车辆中的物体检测和土壤测绘。
【6】UNet架构如何处理多类图片分割任务?您介意概述一下任何挑战或需要记住的事情吗?
UNet 架构非常适合处理多类图像分割任务,因为它可以为每个类生成像素级分割图。在多类图像分割任务中,UNet 模型在大型带注释图像数据集上进行训练,其中每个像素都标有其所属的类。然后使用该模型来预测新图像中每个像素的类标签。
多类图像分割的挑战之一是训练数据中类的分布不平衡。例如,如果图像中存在多个类别的对象,则某些类别可能比其他类别更常见。这可能会导致模型出现偏差,因为它在预测更常见的类别时可能更准确,而在预测不太常见的类别时则不太准确。为了解决这个问题,可能需要通过对不太常见的类进行过采样或使用数据增强技术来平衡训练数据。
多类图像分割的另一个挑战是处理类重叠,其中像素可能属于多个类。例如,在医学图像分割任务中,两个器官之间的边界可能难以区分,因为该区域中的像素可能属于两个器官。为了解决这个问题,可能需要使用能够生成概率分割图的模型,其中每个像素都被分配属于每个类别的概率。
【7】您能讨论一下使用 UNet 架构进行图像分割任务的最新进展或趋势吗?
以下是使用 UNet 架构进行图像分割任务的一些最新进展或趋势:
深度学习技术的使用:UNet架构的使用趋势之一是越来越多地使用深度学习技术,例如卷积神经网络(CNN)和循环神经网络(RNN),以提高模型的性能。这些技术可以让模型从输入图像中学习更复杂的特征并提高分割图的准确性。
使用注意力机制:另一个趋势是使用注意力机制,例如自注意力或空间注意力,以提高模型关注输入图像特定区域的能力。这在图像的某些区域比其他区域更重要或信息更丰富的任务中特别有用。
使用数据增强:另一个趋势是使用数据增强技术,例如图像裁剪、旋转或噪声注入,以提高模型的泛化能力并降低过度拟合的风险。当处理小型或不平衡的数据集时,这一点尤其重要。
迁移学习的使用:另一个趋势是迁移学习的使用,其中预训练的模型在新数据集上进行微调,以提高 UNet 架构的性能。这在处理小型数据集时特别有用,因为它可以允许模型利用从更大的相关数据集中学到的知识。
【8】如何为 UNet 模型选择合适的参数,例如滤波器数量或内核大小?您能否讨论一下选择这些参数时遵循的任何注意事项或最佳实践?
为 UNet 模型选择适当的参数是模型开发过程中的重要步骤,因为它可以显着影响模型的性能。以下是为 UNet 模型选择参数时可以遵循的一些注意事项或最佳实践:
滤波器的数量:UNet 模型中滤波器的数量决定了卷积层生成的特征图的数量。大量的滤波器可以让模型从输入图像中学习更复杂的特征,但也会增加参数数量和过度拟合的风险。通常建议从少量过滤器开始,并根据需要逐渐增加。
内核大小:内核大小确定卷积层用来生成特征图的像素窗口的大小。较大的内核大小可以让模型从输入图像中捕获更多上下文,但也会增加计算成本和过度拟合的风险。通常建议从较小的内核大小开始,然后根据需要逐渐增加。
步幅:步幅确定将滤波器应用于输入图像时卷积层使用的步长。较大的步幅可以减小特征图的大小和计算成本,但也会降低模型从输入图像中捕获细粒度细节的能力。通常建议从小步开始,如果需要的话逐渐增加。
池化大小:池化大小决定了最大池化层用于对特征图进行下采样的像素窗口的大小。较大的池化大小可以减小特征图的大小和计算成本,但也会降低模型从输入图像中捕获细粒度细节的能力。通常建议从较小的池大小开始,然后根据需要逐渐增加。
结论
以下是关于 UNet 架构讨论的要点的总结:
- UNet架构是专门为图像分割任务设计的深度学习模型。它由收缩路径和扩展路径组成,这些路径通过跳跃连接连接。
- 收缩路径是一系列卷积层和最大池化层,它们对输入图像进行下采样并从中提取特征。扩展路径是一系列卷积层和上采样层,它们对收缩路径中的特征图进行上采样,并将它们与输入图像中的特征组合以生成最终的分割图。
- UNet 广泛应用于各种图像分割任务,例如医学图像分割、卫星图像分析和自动驾驶车辆中的目标检测。它以其处理高分辨率图像和生成准确分割图的能力而闻名。
- UNet 非常适合多类图像分割任务,因为它可以处理大量类并为每个类生成像素级分割图。然而,可能需要平衡训练数据或使用概率分割图来处理类重叠或不平衡的类分布。
- UNet 架构使用的一些最新发展或趋势包括深度学习技术、注意力机制、数据增强和迁移学习的使用。
- 在为 UNet 模型选择参数时,重要的是要考虑滤波器的数量、内核大小、步幅和池化大小,因为这些会显着影响模型的性能。通常建议从这些参数的较小值开始,并根据需要逐渐增加它们。
#U-REPA
U-Net和ViT凑一块,会发生什么?U-REPA:精准对齐Diffusion U-Net与ViT特征空间,训练提速42%
一种将 Diffusion U-Net 架构对齐到 ViT(Vision Transformer)特征空间的新方法U-REPA
把 REPA 用到 Diffusion U-Net 架构的尝试。
Representation Alignment (REPA)[1]是一种对齐 Diffusion Transformer (DiT) 和 ViT 视觉编码器的文章,可以作为 DiT 辅助训练的一种有效手段。
但是,把 REPA 用到 U-Net 架构还没有过尝试。这会有些挑战,比如:
- 不同的 Block 功能需要改变对齐的策略。
- U-Nets 的空间下采样会造成空间维度不一致。
- U-Net 和 ViT 之间的特征差距阻碍了 token 有效对齐。
为此,本文提出了 U-REPA,一种新的表征对齐范式,意在对齐 U-Net hidden state 和 ViT feature。
U-REPA 做法:
- 观察到因为 U-Net 中 skip connection 的存在,U-Net 的中间 stage 是最好的对齐选项。
- 先把 U-Net 特征通过 MLP,再对其结果进行上采样。
- 观察到作 token 相似性对齐时有困难,因此引入了一个流形损失,规范了样本之间的相似性。
U-REPA 可以实现出色的生成质量,且大大加快收敛速度。U-REPA 在 ImageNet 256 × 256 上训练 200 epochs 可以实现 FID<1.5 的结果,比 REPA 表现更好。
1 U-REPA:将 Diffusion U-Nets 和 ViTs 对齐
论文名称:U-REPA: Aligning Diffusion U-Nets to ViTs
论文地址:http://arxiv.org/pdf/2503.18414
1.1 U-REPA 研究背景
表征对齐 (Representation Alignment, REPA)[1]是一种将 Diffusion Transformer (DiT) 的特征与现代视觉编码器 (MAE, DINOv2 等等) 对齐的方法,已被证明可以显著加速 DiT 的训练。鉴于 DiT 的日益突出,这种方法具有特别重要的意义。
像 U-DiT[2],DiC[3]这样的工作证明,基于 U-Net 的模型可以表现出更快的收敛速度,同时实现与基于 Transformer 的模型相当的生成质量。这个现象启发作者进行探究:基于现代 Vision Transformer (ViT) 的视觉编码器能否通过类似于 REPA 的对齐机制来指导 Diffusion U-Net 的训练,从而潜在地提高扩散模型的收敛速度上限?
但是,对齐 U-Net 架构和基于 ViT 的模型存在挑战。与 DiTs 不同,U-Net 架构与 ViT 的操作完全不同。具体来说,其一,DiT 和 ViT 都采用各向同性架构的 Transformer Block 组成,从架构上就固有地促进了两者参数的对齐。相比之下,U-Net 的 skip connection 通过将浅层和深层网络层连接在一起来创建强大的相互依赖性,产生了不同的特征传播动态。这种架构差异使得为 DiT 架构开发的 REPA 表征对齐策略不适用于 U-Net。其二,与 ViT 编码器中的固定尺度特征表示相比,U-Net 中的渐进下采样操作使得特征的空间维度不匹配,为接下来对齐操作带来了额外的复杂性。其三,U-Net 和 ViT 的特征有很大差距,使用余弦相似度作为指标可能有阻碍。像 REPA 那样使用 token 相似性作为损失不一定是最佳选项。这促使作者重新思考优化目标。
1.2 REPA 回顾
表征对齐 (Representation Alignment, REPA)[1]从现成的基于 ViT 的视觉编码器 (例如 DINOv2、CLIP、MAE 等) 中提取具有语义特征,来蒸馏 Diffusion Transformer。
给定一个基于 ViT 的视觉编码器 和干净图像 ,令 表示其 patch embedding,其中 和 分别表示 Patch 的数量和嵌入维度。REPA 把 patch embedding 和 diffusion 模型输出 对齐,其中, 是时间步 处 DiT 的 latent 表征, 代表可训练的 MLP。
REPA 通过最大化 token 特征相似性来强制对齐,即 DiT hidden-state 的 token 与 ViT Encoder 特征的 token 之间的相似性:

其中, 表示相似性度量(例如余弦相似度)。通常, 为 DiT 早期层输出(原始工作 REPA 采用第 8 层),以更好对齐。通过可调的系数 与 flow-based 的扩散目标(即 SiT)相结合,扩散模型训练的最终损失函数如下:

1.3 U-REPA 做法
在扩散模型中,U-Net 和 Isotropic 的 DiT 架构设计理念不同。基于 U-Net 的方法相比 DiT 强调更快的收敛。作者研究了 U-Net 的2个核心组件:skip connection 和下采样。
- Skip connection: 在 Encoder 和 Decoder 层之间提供快捷连接,理论上有助于梯度流和特征重用
- 下采样: 降低空间分辨率 (每个阶段为 2),以实现分层、多尺度特征学习。下采样总是与跳过连接配对,以减轻信息损失。
作者首先通过一个 toy experiment 评估 U-Net 不同组件在收敛方面的贡献。

图1:评估 U-Net 中的各个组件在快速收敛方面的贡献
图 1 表明,U-Net 的快速收敛主要源于通过下采样的多尺度分层建模,而不是 skip connection。下采样将特征压缩为紧凑、语义丰富的表征,加速学习,同时保持信息流通过跳过增强 Decoder。但是 skip connection 并非无用的,因其补偿了下采样造成的信息丢失。
本文动机是研究 REPA 是否可以在 U-Net 上 work。

图2:U-REPA 框架。作者发现语义丰富的中间层最适合表征对齐。但是 channel 维度和空间特征不同阻碍了对齐效果。为了应对这些挑战,作者把特征放大,提出流行对齐
对齐的位置
U-Net 和 DiT 之间的 Block 功能存在差异。U-Net 架构通常使用中间网络层进行高级语义合成,同时保留浅层用于低级图像细化,而 DiT 表现出完全不同的模式,浅层主要控制语义丰富的轮廓形成,更深的层处理详细的图像细化。
REPA 的实验结果也支持这些结论,也就是把表征对齐用在初始的 Transformer Block 是最有效的。这个现象的原因是 DiT 浅层编码了丰富的语义信息,这些表征与基于 ViT 的视觉编码器的输出很好地对齐,从而实现有意义的指导。
与 DiT 相比,U-Net 架构中的 skip connection 会产生根本不同的 Block 功能。U-Net 的跨层快捷连接在浅层和深层之间建立直接依赖关系,从根本上改变了特征图的演化模式。如图 3 所示,带有 skip connection 的 DiT 的中间层最适合做表征对齐。尽管 U-Net 有下采样操作,但也是这样。

图3:对齐扩散模型的深度与性能的关系。左:带有 skip connection 的 SiT 模型。右:基于 U-Net 的 SiT 模型。在更高的 U-Net stage 进行对齐是必要的
特征尺寸对齐
Diffusion U-Net 中间阶段和 ViT 没法直接对齐,因为特征大小不一致。这种维度的不匹配阻碍了 REPA 的 token 相似度计算,因为这需要比较特征之间的严格基数匹配。
为了对齐 2 个特征图 (U-Net 和 ViT 编码器的特征),作者试了下面 3 个方案:
- 先 Upscale,再 MLP:特征先上采样再给 MLP。
- 在 MLP 过程中 Upscale:MLP 充当特征上采样器。
- 先 MLP,再 Upscale:特征首先通过 MLP,然后进行上采样。
在以上方案中,作者发现 "先 MLP,再 Upscale" 在性能和效率方面是最好的。
流形空间对齐
虽然在上面的步骤中选择出了最合适的 U-Net 特征来对齐,也已经在空间维度上匹配了,但是还有一个问题就是特征空间本身的问题。
首先,DiT 和 ViT 的结构是一致的,但是 U-Net 却不是,因其 skip connection 和下采样。因此,其隐藏状态和视觉编码器输出之间有明显的特征分布差距。其次,对齐所需的维度转换不可避免地修改了 U-Net 的原生特征空间特征。
最近,一些关于 Diffusion U-Net 的研究表明,高 stage 的 U-Net 特征会丢弃高频分量,包括噪声。作者认为原始 REPA Loss 这样的严格 token-level 的对齐是次优的,因为它假设对齐模态之间的隐式特征空间的同质性。
如图 4 所示,作者测量了在训练期间与 ViT 特征的 cosine similarity。对比的 2 个模型分别是 SiT-L/2 (Isotropic 模型) 和 SiT↓-L/2 (带有下采样的 U-Net 架构)。实验现象很有趣:虽然 SiT↓-L/2 在训练的早期相似性的提升稍快 (可能由于 skip-connection),但是在收敛的时候,与 ViT 的 token 相似性相比于 SiT-L/2 是更低的 (约 0.60 < 约 0.63)。
这个现象说明,通过这样的相似性度量方式对齐 U-Net 和 ViT 编码器,会受到架构不相容造成的限制的影响。

图4:平均 tokenwise 相似度表现出收敛性。SiT-L/2 的特征与 ViT 的相似度更高,SiT↓-L/2 的特征与 ViT 的相似度更低,说明表征对齐更困难
为此,作者没有采用严格的 token-wise 正则化,而是认为对齐来自同一特征空间的样本之间的相似性可能是一个解决方案。因此,定义 Manifold Loss 为:

其中,

式中,采用余弦相似度作为相似度度量, 表示矩阵的 Frobenius Norm。通过引入超参数 ,整体优化目标可表示为:

1.4 其他改进
Time-aware MLP
作者遵循之前工作的看法,在采样过程中,channel 维度对某个时间子集特别敏感。ViT Encoder 提取的特征是时不变特征,而 Diffusion 模型的特征是时变特征,因此作者认为,当 MLP 是 time-aware 的,可以从扩散模型中提取到时不变特征,以进行更好的对齐。
具体而言,作者加了一个模块来预测 channel-wise shift 和 scale 向量 。该模块与 MLP 并行,并遵循 DiT 的 AdaLN 的设计,是 SiLU 和线性层的串联。shift 和 scale 向量施加在输出 MLP 上,如下所示:

1.5 实验设置
模型配置
作者把本文的 U-REPA 架构在 channel 维度和 FLOPs 与标准的 DiT 或者 SiT 对齐。各种尺寸模型的配置如下。值得注意的是,当 FLOPs 对齐时,由于深度的增加,SiT↓ 通常比 SiT 有更多的宽度。

图5:不同模型大小的 SiT↓ 架构的配置。本文提出的 U-Net 架构的 SiT↓ 模型在 FLOPs 和 channel 维度方面与 DiT 对齐
对于主实验,作者采用 1.65 的 cfg,与 SiT 不一样,guidance 间隔 [0, 0.7]。对于所有消融实验,训练 100K 次迭代的模型,足以展示模型性能的趋势;采样是使用官方 REPA 代码库的默认设置进行的,即 ODE 中的 cfg = 1.8,guidance 间隔 [0, 0.7]。
1.6 实验结果
不同尺度的 SiT↓ 与 SiT 进行比较
作者在 cfg = 1 的设置下在 ImageNet 256 上评估了本文的 U-REPA 对齐方法。如下图 6 所示,本文的方法不断提高生成质量,同时显著降低了模型的计算成本。对于基本的 SiT-B/2 模型,U-REPA 在 FID 上实现了 39.3% 的改进 (使用相当的 FLOPs 和训练迭代数),表明特征对齐在不增加训练开销的情况下提高了参数效率。在更大的模型中,加速度效应变得更加明显:对于 SiT-L/2,U-REPA 将所需的迭代次数减少了 42.9% (700K→400K),同时降低了 FLOPs (79.3G 与 80.8G),并实现了 30.9% 的 FID 改进 (8.4→5.8)。如图 7 所示,具有 U-REPA 的 SiT-XL/2↓ 模型与基线相比,使用 90% 的迭代轮数 (400K 与 4M) 和更少的 FLOPs (108.8G 与 118.6G) 实现了最先进的 FID 是 5.4,证明本文方法的快速收敛性。

图6:U-REPA 和 REPA 在不同尺寸模型的对比,cfg=1。使用了 U-REPA 的 U-Nets 展示出了很好的性能

图7:收敛速度方面将 SiT↓+U-REPA 与 SiT+REPA 进行比较。在 U-REPA 的帮助下,SiT↓-XL/2 的收敛速度比 SiT-XL/2 快得多
作者还展示了 U-REPA 在参数量上的优势,如图 8 所示。虽然当 FLOP 与 DiT 对齐时,U-Net 带来了额外的参数,但 SiT↓+U-REPA 的优势显而易见。

图8:在参数量方面对比 SiT↓+U-REPA 与 SiT+REPA
收敛性能
将本文方法与之前的最新技术进行了比较,如图 9 所示,SiT↓+U-REPA 在只训练 200 Epochs 的情况下实现了 1.48 的 FID,显着优于现有方法。值得注意的是,像 MDTv2-XL/2 这样的最先进的 masked diffusion transformer 需要 1,080 Epochs 才能达到 1.58 的 FID,本文方法获得了更好的性能 (1.48),迭代次数减少了80%。即使与 SOTA SiT-XL/2 + REPA 基线 (800 Epochs,1.42 的 FID) 相比,本文方法仅训练 400 Epochs,同时实现了更好的生成质量 (1.41 的 FID)。这些结果证明了 U-REPA 的性能和效率。

图9:将 U-REPA 与最先进的基线进行比较。U-REPA 只能在 200 个 epoch 内达到 FID<1.5
在什么深度进行对齐
如图 10 所示,尽管渐进式的下采样会降低空间分辨率,但是在中间层进行对齐的结果是最好的。对于 SiT↓-XL/2 模型,在第 18 层对齐特征实现了 6.25 FID 和 156.2 的 IS,优于在浅层或者更深的层对齐的结果。中间层的特征维度只有 8×8,小于前面和后面层的 16×16,但是 FID 却更低,说明语义丰富度对于生成质量的影响超过了空间分辨率。

图10:SiT↓ 中对齐的深度。在中间层 (U-Net 中的 higher stage) 进行对齐的性能最好
特征上采样方式
如图 11 所示,作者发现通过 MLP 后上采样 U-Net 的隐藏状态是最好的选择,达到 5.72 FID 和 161.6 IS。

图11:特征上采样方式
Manifold Loss 的权重
如图 12 所示,Manifold Loss 的权重 实现了最低的 FID(5.72)和最高的 IS(161.6)。这个最佳的权重很好地平衡了 Manifold Loss 与原始的 REPA loss 和 Diffusion 损失。正则化不足( 会限制特征空间的协调,过度正则化 则会使得 FID 低到 5.79 的结果。

图12:Manifold Loss 的权重消融实验结果
参考
- ^abcRepresentation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
- ^U-dits: Downsample tokens in u-shaped diffusion transformers
- ^Dic: Rethinking conv3x3 designs in diffusion models
#VARGPT-v1.1
视觉自回归生成理解编辑大一统!北大团队多模态新突破
该模型通过迭代视觉指令微调和强化学习等创新训练策略,结合大规模视觉生成数据集和升级的语言模型主干,显著提升了图像生成质量和泛化能力,同时实现了无架构修改的图像编辑功能,相关代码和数据已全面开源。
最近Google的Gemini Flash和OpenAI的GPT-4o等先进模型又一次推动了AI浪潮。这些模型通过整合文本、图像、音频等多种数据形式,实现了更为自然和高效的生成和交互。
北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。
该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度4
目前训练、推理和评估代码,数据,模型均已开源。
VARGPT-v1.1延续了前作的设计理念,采用了创新的“next-token”与“next-scale”自回归预测机制,同时引入四大关键创新点:
- 迭代视觉指令微调与强化学习结合的训练策略: 通过交替进行监督微调(SFT)与基于偏好直接优化(DPO)的强化学习,有效提高了模型的图像生成质量。模型逐步提升图像生成分辨率,从256×256扩展至512×512像素,图像细节与真实性显著增强。
- 更大规模的视觉生成训练数据集: VARGPT-v1.1采用了多达830万条视觉生成指令数据,包括真实世界的LAION-COCO数据集以及由Midjourney与Flux模型生成的合成数据。大规模数据的使用显著扩大了模型对不同类型图像生成的泛化能力。
- 升级语言模型主干至Qwen2: 引入最新的Qwen2-7B语言模型主干,利用其高效的注意力机制与更好的token化策略,有效提升了模型的视觉理解能力。
- 无架构修改的图像编辑能力: VARGPT-v1.1在不改动模型架构的基础上,通过专门构建的图像编辑数据集,实现了图像编辑功能。这使得模型不仅可以理解和生成图像,还能根据用户指令对图像进行编辑。
1 模型架构
VARGPT-v1.1 遵循 VARGPT 的模型架构设计,以统一视觉理解和生成,其架构如上图所示。由(1)一个大语言模型(Qwen2-7B)、视觉编码器和用于视觉理解的理解投影器;(2)视觉解码器和用于视觉生成的双生成投影器组成。VARGPT-v1.1在大语言模型主干中采用因果注意力机制,同时在视觉解码器中使用块因果注意力机制。
2 训练策略
VARGPT-v1.1的训练遵循VARGPT的三阶段训练方法,整体训练过程如上图所示。区别于VARGPT,在第三阶段, VARGPT-v1.1提出了迭代指令微调和强化学习的方法,以增强统一模型的视觉生成能力。具体来说,第三阶段的迭代训练过程如下图所示:
2.1 视觉指令微调
视觉生成的指令微调旨在通过监督微调赋予VARGPT-v1.1视觉生成能力。这个阶段,首先解冻视觉解码器和两个投影器,并冻结其他参数以进行有监督微调,如上图所示。本文采用一种逐步提高图像分辨率的训练方法来训练VARGPT-v1.1。具体来说,在第一个SFT阶段,图像分辨率设置为256x256,模型训练40K步,以赋予其生成图像的初始能力。在第二个SFT阶段,图像分辨率设置为512x512 ,模型训练30K步,以进一步增强其高分辨率视觉生成能力。该视觉指令微调阶段的训练数据包括8.3M收集和构建的指令对。
2.2 基于人类反馈的强化学习
除了指令微调外,VARGPT-v1.1提出迭代指令微调与强化学习来训练视觉自回归的大视觉语言模型。VARGPT-v1.1通过将生成质量的提升表述为一个偏好选择问题,并采用直接偏好优化(DPO)来对模型进行训练。这种方法激励模型倾向于生成高质量的图像输出,同时拒绝质量较差的输出。具体来说,VARGPT-v1.1训练时将倾向于拒绝低质量的图像,接受高质量的图像来优化策略模型:
2.3 视觉编辑的有监督微调
经过有监督微调(SFT)和直接偏好优化(DPO)的多阶段渐进式分辨率迭代后,我们系统地构建了一个包含来自Style-Booth的11325个样本的指令调优数据集,以使VARGPT-v1.1具备视觉编辑能力。该流程通过视觉编码器处理目标图像,同时利用编辑指令作为文本提示,来监督模型对编辑后图像分布的逼近。这种方法实现了:(1)架构保留式适配,无需引入的冗余设计实现编辑能力;(2)通过联合文本-图像标记预测实现统一的多模态编辑。在该监督微调期间,所有模型参数均未冻结,以在保持生成多样性的同时最大化编辑保真度。
3 实验与结果
遵循VARGPT和其他多模态大语言模型的设置,本文在一系列面向学术任务的基准测试和最新的视觉理解基准测试中,评估了VARGPT-v1.1在视觉理解方面的有效性,总共涉及11个基准测试:在包括 MMMU、MME、MMBench、SEEDBench 和 POPE (包括不同的设置,随机、流行和对抗)在内的多模态基准上进行零样本多模态评估。总体来说,VARGPT-v1.1 实现了显著的视觉理解性能,在各种统一模型和各类多模态大语言模型的对比上均占优势。
3.1 Zero-shot multi-modal evaluation
对VARGPT-v1.1与各种先进的多模态模型进行了全面评估,结果如下表。实验结果表明VARGPT -v1.1在所有基准测试中表现出色,在MMBench上达到81.01,在SEED上达到76.08,在MMMU上达到48.56,取得了先进水平的结果。此外,在LLaVA - Bench基准测试上的持续性能提升验证了我们的架构选择和训练策略的有效性,确立了VARGPT-v1.1作为一个强大且通用的多模态模型的地位。
3.2 Performance comparison on visual question answering tasks
本文在多个视觉问答数据集上评估了VARGPT - v1.1的性能,并将其与几种最先进的多模态模型进行了比较。结果见表3。我们的实验结果表明VARGPT-v1.1在所有视觉问答(VQA)基准测试中均取得了卓越的性能,相较于现有模型有显著提升。
3.3 Performance comparison on visual question answering tasks.
为了评估VARGPT的视觉生成能力,我们使用广泛采用的GenEval基准和DPG - Bench基准进行了全面评估,定量结果分别见下表。这些数据集为文本到图像的生成能力提供了严格的评估框架。我们的实验结果表明,VARGPT-v1.1优于许多专门的图像生成模型,包括基于扩散的架构(如SDv2.1)和自回归方法(如LlamaGen)。
3.4 Performance comparison on the DPG-Bench benchmark.
3.5 视觉理解的比较
VARGPT-v1.1 展现了更强的理解和解读视觉内容中幽默元素的能力。
3.6 多模态图像文本生成
VARGPT-v1.1生成的一些512 x 512的样本如下所示。VARGPT-v1.1支持用户输入文本和图像指令,并同时输出文本和图像的混合模态数据。此外,与现有的统一模型基线相比,我们的方法在准确的文本到图像生成方面取得了显著改进。如下图所示,我们展示了VARGPT-v1.1生成的代表性图像输出和对话交互。定性分析表明,VARGPT-v1.1始终能生成与给定文本指令紧密匹配的高质量图像。
3.7 图像编辑能力
视觉编辑结果可视化如下图所示,本文对视觉编辑能力进行的定性评估表明,VARGPT-v1.1具备基本的图像操作能力。这种能力仅通过使用视觉编辑指令微调数据进行训练即可获得,无需对架构进行任何修改。此外,这些观察结果证实了统一模型架构在单一框架内实现通用视觉理解、生成和编辑方面具有巨大潜力。
4 结论与展望
VARGPT-v1.1通过采用为多模态大模型设计的灵活的训练策略使其具有可扩展性,同时为多模态系统架构设计开辟了新的技术途径。尽管VARGPT-v1.1取得了重大进展,但团队指出目前版本和商用生成模型之间仍存在差距,此外在图像编辑能力方面也存在局限性。未来,团队将进一步扩展训练数据规模,探索新型token化方法,并尝试更多的强化学习策略,进一步推动多模态生成理解统一大模型的发展。
project: https://vargpt1-1.github.io/
code: https://github.com/VARGPT-family/VARGPT-v1.1
arxiv: https://arxiv.org/abs/2504.02949
#TransXNet
通用的视觉Backbone!全局动态性+局部动态性=性能强大
香港大学俞益洲团队提出通用视觉模型TransXNet,创新引入动态融合全局与局部特征的D-Mixer模块,在ImageNet分类、COCO检测等任务中性能领先,代码已开源。
论文标题:TransXNet: Learning both global and local dynamics with a dual dynamic token mixer for visual recognition
论文链接:
https://goo.su/Y7FONnb (Arxiv版本)
https://goo.su/zcWOp7x (TNNLS版本)
代码链接:https://github.com/LMMMEng/TransXNet
香港大学计算机系俞益洲教授(https://i.cs.hku.hk/~yzyu/index.html)及其研究团队开发了一种新型的通用视觉backbone—TransXNet,该模型同时融合了全局和动态性。其创新之处在于引入了一个即插即用的模块,名为Dual Dynamic Token Mixer(D-Mixer)。与以往的卷积和self-attention混合模块或全局与局部信息融合模块不同,D-Mixer专注于动态性的捕捉。具体来说,D-Mixer能够利用网络上一层的feature maps信息,生成用于提取当前feature maps的全局和局部动态权重,从而显著增强模型对多尺度特征的动态表征能力。 为了验证TransXNet的性能,研究团队分别在ImageNet-1K、COCO 2017和ADE20K数据集上进行了广泛的实验,结果表明,TransXNet作为一个通用视觉模型,展现出了卓越的性能。
动机:
在本文中,作者深入探讨了self-attention和卷积在权重计算方式上的不同,并基于此提出了改进方案。作者指出,self-attention之所以性能卓越,部分原因在于其权重(即attention matrix)会根据不同的输入动态变化,这种input-dependent的特性使得模型能够更好地捕捉输入数据的特征。相比之下,传统的卷积操作中的权重是静态的,与输入数据无关,即input-independent,这限制了其表征能力。据此,作者进一步分析了将self-attention和卷积简单结合时可能遇到的问题:
- 表征能力差异:由于卷积缺乏类似self-attention的动态性,这导致在卷积-attention混合模块中,self-attention的语义建模能力可能会被削弱,因为卷积部分的静态特性限制了整体模块的表征能力。
- 深层模型的挑战:在深层模型中,self-attention能够利用先前特征图的全局和局部信息来生成动态的attention matrix,从而提高模型的性能。然而,卷积核的静态特性使其无法利用这些信息来动态调整,这限制了模型在深层结构中的表现。
方法:
为了解决上述问题,作者提出了一个即插即用模块 D-Mixer。该模块能够动态地捕获全局和局部信息,从而使网络兼具大感受野和稳定的归纳偏置。如图1(a)所示,对于给定的输入特征图,D-Mixer 首先会将其沿通道拆分为两部分,并分别将这两部分输入到两个不同的模块中,即 Input-dependent Depthwise Convolution(IDConv)以及 Overlapping Spatial Reduction Attention(OSRA)。输出结果会进一步进行拼接,并且由一个轻量级的 Squeezed Token Enhancer(STE)进行整合。以下为不同模块的具体描述:

图1 D-Mixer
**Input-dependent Depthwise Convolution (IDConv)**:如图1(b)所示,对于任意输入特征图,作者首先使用一个自适应平均池化层聚合空间上下文,并将空间维度压缩为 K×K 大小,其中 K 为待生成的动态卷积核的大小。紧接着,输出的特征图被送入两个 1×1 卷积层中,并生成一个多组空间注意力图,维度为 A∈G×C×K×K,其中 G、C 分别表示注意力图的组数以及输入特征图的通道大小。并且在 G 维度上使用 softmax 函数对注意力图进行归一化,使其具备自适应的选择能力。最后,通过将注意力图和一组维度同为 G×C×K×K 的可学习参数进行逐元素相乘来生成动态卷积核,并将其用于输入特征图的特征提取。IDConv 可以根据上一层特征图携带的语义信息来动态地生成卷积核的权重,进而可以与 self-attention 进行深度嵌合。
Overlapping Spatial Reduction Attention (OSRA): 如1图(c)所示,OSRA 的整体流程和 PVT 中提出的 Spatial Reduction Attention(SRA)类似,都采用了 token-to-region 的全局建模方式。主要不同之处在于,SRA 在降采样的过程中使用的是 Non-overlapping 的卷积,即卷积核大小和步长大小一致。因此,一些连续的局部信息会在这个过程中被破坏,从而降低 key/value 分量包含的空间结构信息。据此,OSRA 引入了 Overlapping 卷积来进行降采样,即卷积核的大小大于步长。此外,OSRA 还引入了一个轻量的局部算子(以 3×3 的 depthwise 卷积实现)来进一步提炼 key/value 分量的局部信息。
**Squeezed Token Enhancer (STE)**:为了高效地将 IDConv 和 OSRA 处理后的特征进行融合,本文引入了一个轻量级的特征融合模块 STE。如图1(d)所示,STE 通过一个 3×3 的 depthwise 卷积和两个通道压缩的 1×1 卷积来实现特征融合。值得一提的是,STE 相较于直接使用一个全连接层进行特征融合具有更好的性能以及更优的计算复杂度。
TransXNet 整体架构:如图 2 所示,TransXNet 的基本构成部分主要包含 D-Mixer 和 Multiscale Feed-forward Network(MS-FFN)。其中,MS-FFN 使用了基于不同卷积核大小的 depthwise 卷积来提取多尺度信息。由于 TransXNet 同样沿用了 ResNet 和 Swin Transformer 中的金字塔设计,因此,该网络可以应用到各类视觉任务中。

图2 TransXNet整体架构
实验结果:
- 图像分类:TransXNet 在大规模数据集 ImageNet-1K 上表现出了卓越的性能,相较于现有方法,展现出更为出色的性能以及更加优秀的tradeoff,如图 3 所示。

图3 不同模型在ImageNet-1K上的性能对比
- 目标检测:如表 1 所示,在 COCO 2017 数据集上,TransXNet 同样展示出了更优的性能。值得注意的是,TransXNet 在处理小目标时比强调局部性的 Slide-Tranformer 性能更好,充分展现了 TransXNet 利用全局和局部动态性的强大能力。
- 语义分割:如表 2 所示,TransXNet 在 ADE20K 上也进行了全面的评估,其性能在与一些强大的 Vision Backbones 的比较中脱颖而出,并且有着更优秀的tradeoff。
- 消融研究:如表 3 所示,TransXNet 对核心模块进行了广泛的消融实验,例如与不同 token mixer 的性能对比以及和不同动态卷积的性能对比等。可以看出,TransXNet 中的核心部件相较于其他算法有着更加出众的性能。除此之外,原文还包含有更多的性能和效率对比及分析。

表1 目标检测和实例分割性能对比

表2 语义分割性能对比

表3 核心部件的消融研究
5.可视化研究:
- 动态卷积在卷积 - Attention 混合模型中重要性: 如图 4 (a) 所示,在动态卷积的加持下,卷积-Attention 混合模型能够拥有更大的有效感受野(Effective Receptive Field, ERF)。其中,所提出的 IDConv 展现出了最好的性能,表明其可以更好地配合 self-attention 模块来捕获上下文信息。
- 不同 Vision Backbones 的 ERF 对比: 如图 4 (b) 所示,TransXNet 在具有最大感受野的同时还具备显著的局部敏感度,这是其他模型无法兼备的能力,进一步表明了全局和局部动态性的重要性。

图4 不同模型有效感受野(Effective Receptive Field, ERF)对比
#NLPrompt
MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法
本文为大家介绍上海科技大学 YesAI Lab 在 CVPR 2025 上入选 Highlight 的工作。本研究针对视觉语言模型提示学习中的带噪标签问题,提出了一种新的鲁棒提示学习方法 NLPrompt。
该研究发现在提示学习场景中使用平均绝对误差(MAE)损失能显著提高模型在噪声数据集上的鲁棒性。利用特征学习理论,本文从理论上证明了 PromptMAE 策略能够有效减少噪声样本的影响,增强模型的鲁棒性。
此外,该研究还提出了基于提示的最优传输数据净化方法 PromptOT,通过优化传输矩阵,精确地将数据集划分为干净和带噪的子集。
NLPrompt 使用 PromptMAE 和 PromptOT 来处理噪声标签,融合了 CE 损失和 MAE 损失的优势。NLPrompt 充分利用了视觉语言基础模型的丰富表达能力和精准对齐能力,为存在噪声标签的鲁棒提示学习提供了一种简单有效的解决方案。
上海科技大学信息学院 2023 级博士生潘比康和 2024 级硕士生李群为论文共同第一作者,石野教授为通讯作者。
论文标题:NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
论文链接:https://arxiv.org/abs/2412.01256
代码链接:https://github.com/qunovo/NLPrompt
01 研究背景
视觉语言基础模型的出现,如CLIP,彻底改变了图像及其文本描述的表示方式,使得两种模态在同一潜在空间内实现精准对齐。
由于手工提示的敏感性,提示学习已成为微调视觉语言模型的关键方法。提示学习通过反向传播更新可学习的文本提示,由于涉及的参数数量相对较少,通常只有几千个,因此提供了一种轻量级的解决方案,使模型能够迅速适配特定任务。
然而,在实际应用中,数据集的标签并非准确无误的。标签错误是常见的问题。在大规模数据采集过程中,由于人工标注的失误、自动标注工具的不准确、或者数据本身的模糊性,都会导致部分标签错误。例如,一张“猫”的图像被标注为”狗“。而错误的标签会严重干扰模型的性能。
先前的研究表明提示学习对带噪的标签具有一定的弹性。尽管如此,在噪声条件下采用交叉熵(CE)损失训练时,模型仍容易过拟合错误标签,从而影响模型最终的预测效果。因此,增强噪声环境中提示学习的鲁棒性仍然是一个关键问题。
02 研究方法
本文提出的 NLPrompt 主要由两大模块构成——PromptMAE 和 PromptOT。
PromptMAE:鲁棒损失的创新应用与理论分析
在噪声标签学习领域,平均绝对误差(MAE)已被确定为传统训练范式中的一种鲁棒损失函数。然而,MAE 在训练过程中往往存在收敛速度慢和性能差的问题,这使得它很少被用作噪声标签学习中的分类损失。
然而,我们的研究发现了一个有趣的现象:在提示学习中,相比于传统的交叉熵(CE)损失,采用 MAE 损失(PromptMAE)能显著提高模型的鲁棒性,保证模型在高噪声环境下依然保持较高的准确率。
如图 1 所示,我们在不同的噪声水平下比较了 CE 损失和 MAE 损失对 CoOp 方法性能的影响。
实验结果表明,随着数据集噪声水平的增加,使用CE损失的模型性能显著下降,而MAE损失在噪声数据集上更具鲁棒性。即使在大量噪声存在的情况下,MAE 损失也能保持出色的准确性和较快的收敛性。

为了深入理解 PromptMAE 的鲁棒性,我们引入了特征学习理论,该理论将潜在特征分为任务相关和任务无关两部分。通过对基于梯度下降训练过程中这两类特征的动态优化进行分析,我们可以获得关于模型收敛和泛化的重要见解。
结果表明,当任务相关特征占主导地位时,可以实现鲁棒的提示学习。我们的分析表明,PromptMAE可以有效抑制噪声样本的影响,从而增强视觉语言模型提示学习的鲁棒性。
PromptOT:基于最优传输的数据净化
在噪声标签学习领域,一种常见的策略是利用样本选择技术对数据集进行清洗,以提升模型在噪声条件下的表现。例如,传统的基于最优传输(OT)的样本选择方法利用随机初始化的原型来计算从图像特征到这些原型的最优传输矩阵,将特征和原型之间的相似性作为成本矩阵。
然而,由于这些方法最初并非为提示学习而设计的,因此它们的直接适用性可能会受到限制。为此,我们的目标是充分利用视觉语言基础模型中的丰富表达能力和精确对齐特性,从而改进数据净化过程。

本文提出了一种基于提示的最优传输数据净化方法 PromptOT,PromptOT 利用文本特征作为传输矩阵的原型,旨在增强视觉语言基础模型中提示学习的鲁棒性。NLPrompt 算法通过 PromptOT 将带噪数据集划分为“干净”和“带噪”的子集来促进稳健的提示学习。
考虑到交叉熵(CE)损失在干净数据集上通常优于 MAE,我们应用 CE 损失来训练干净子集以保证高精度,应用 MAE 损失来训练带噪子集以增强鲁棒性。
这种双重策略在 PromptOT 的支持下,有效融合了 CE 损失和 MAE 损失的优势,在不同的噪声条件下协调了 CE 和 MAE 损失的强度,从而提升了模型的整体性能。
传统的基于 OT 的伪标签方法从随机初始化原型开始,然后根据图像和这些原型之间的相似性推导出伪标签。然而,在视觉语言模型的提示学习中,潜在空间是对齐的,PromptOT 利用提示输入文本编码器生成的文本特征替换随机初始化的原型。这些文本特征中嵌入的丰富语义信息为原型初始化提供了坚实的基础。
具体来说,OT 问题涉及基于给定的成本矩阵求解传输矩阵,同时保持边缘分布不变。计算原型和图像特征之间的相似性,并将得到的相似性矩阵的负对数用作成本矩阵。由于边缘分布约束,OT 矩阵的每一列被归一化后得到图像的伪标签。
NLPrompt 中的具体计算过程为:
对于图像数量为 的数据集,我们首先使用 CLIP 的预训练图像编码器来生成图像特征矩阵 ,其中 表示潜在空间的维度。
此外,给定数据集的类别集合,我们生成与这些类别相对应的提示,并将提示传递给 CLIP 的预训练文本编码器,以创建文本特征矩阵 ,其中 是类别的数量。
接下来,我们计算相似度矩阵 。将该相似性矩阵的负对数用作 OT 问题中的成本矩阵,样本和类别均为均匀的边缘分布。要解决的 OT 问题如下:

其中 表示一个维度为 的全为 1 的向量。根据该公式利用 Sinkhorn 算法求解出最优传输矩阵 ,然后我们对 的每一列采用 Argmax 运算以找到最大值求解出伪标签:

利用 PromptOT 生成的伪标签 和数据集的带噪标签 将数据集净化为两个子集:干净数据集 和有噪声数据集 ,定义如下:

在数据划分后,NLPrompt 分别对两个子集采用不同的损失函数进行训练,对干净子集采用 CE 损失以实现高性能,对噪声子集采用 MAE 损失以增强鲁棒性,以综合利用 CE 损失 MAE 损失的优势。NLPrompt 的综合损失为:

其中 表示目标标签, 表示第 个样本的输出相似度。
NLPrompt 利用 OT 巧妙地协调了 CE 和 MAE 损失的优势,同时充分利用了视觉语言基础模型在提示学习方面的潜力。首先,我们利用提示学习的文本表示作为强大的初始原型,从而保持全局标签的一致性,区别于其它基于预测的方法。
此外,NLPrompt 通过对数据集进行净化,使得在对噪声样本训练时能够充分利用 MAE 的鲁棒性,而不是对所有样本统一采用相同的损失函数。这种灵活的策略不仅大大增强了模型在噪声环境下的鲁棒性,也使得我们能够更好地整合 CE 和 MAE 的优势,从而整体提升模型性能。
03 实验结果
对于合成的带噪数据集,在不同的噪声强度下,图像分类任务的准确率如下表所示,验证了 NLPrompt 在处理提示学习中的噪声标签问题上具有有效性和优越性。

在真实世界的带噪数据集 Food101N 上的结果如下表所示,NLPrompt 优于所有的基准方法。

NLPrompt 的泛化性
NLPrompt 不仅对 CoOp 有效,还可以扩展到其它提示调优方法上,如 VPT,MaPLe,PromptSRC,这些方法都是 CoOp 的后续方法。在 EuroSAT 数据集上的实验结果如下表所示,NLPrompt 显著提升了各种提示学习方法在面对噪声标签问题时的鲁棒性,验证了 NLPrompt 具有强大的泛化能力。

消融实验
为了评估 NLPrompt 各个组成部分的有效性,我们在 Flowers102 数据集上进行了消融实验。为了验证 OT 的有效性,我们设计了两组实验:一组不使用 OT 进行数据净化,另一组使用 OT 进行数据净化。具体的实验设计如下:
(a)对所有数据采用交叉熵损失;
(b)对所有数据采用平均绝对误差损失;
(c)使用随机初始化的原型代替 CLIP 文本特征作为初始化原型;
(d)去除噪声数据,仅对干净数据采用交叉熵损失;
(e)去除干净数据,仅对噪声数据采用平均绝对误差损失。
实验结果如下表所示,其中平均结果表明(b)优于(a),验证了我们的 PromptMAE 的有效性。此外,平均结果表明(d)优于(a),(e)优于(b),进一步验证了 PromptOT 在数据净化过程中的有效性。
此外,(c)和 NLPrompt 之间的比较突出了文本特征初始化在我们的方法中的重要性。在所有方法中,NLPrompt 实现了最佳性能,与其他基线方法相比有了显著改进,进一步验证了 NLPrompt 各个组成部分的有效性。

04 结论
在这项研究中,我们通过引入 PromptMAE 和 PromptOT,有效解决了视觉语言基础模型提示学习中噪声标签这一关键挑战。
尽管在传统的噪声标签场景中采用 MAE 损失较为少见,但我们的研究发现,将 MAE 损失应用于提示学习,能够显著增强模型的鲁棒性并保持高精度。通过特征学习理论,我们阐明了MAE损失如何有效抑制噪声样本的影响,从而提升整体鲁棒性。
此外,本文引入了基于提示的 OT 数据净化方法 PromptOT,能够将带噪数据集准确地划分为干净数据和噪声数据子集。在 NLPrompt 中,我们对干净数据采用交叉熵损失,对噪声数据采用 MAE 损失,这种差异化的策略展示了一种简单且强大的鲁棒提示学习方法。
在各种噪声场景下进行的大量实验证实了该方法在性能上的显著提升。NLPrompt 充分利用了视觉语言模型的丰富表达能力和精准对齐能力,为提升现实场景中提示学习的鲁棒性提供了一个前景广阔的解决方案。
#Q-Insight
画质理解新突破!北大字节提出Q-Insight,让大模型深度思考推理!
本篇分享论文Q-Insight: Understanding Image Quality via Visual Reinforcement Learning,北大字节提出Q-Insight,让大模型深度思考推理!
- 论文作者:Weiqi Li(李玮琦), Xuanyu Zhang(张轩宇), Shijie Zhao†(赵世杰), Yabin Zhang(张亚彬), Junlin Li(李军林), Li Zhang(张莉) and Jian Zhang†(张健)(†通讯作者)
- 作者单位:北京大学信息工程学院、字节跳动
- ArXiv版本:https://arxiv.org/pdf/2503.22679
- 仓库地址:https://github.com/lwq20020127/Q-Insight
任务背景:画质理解需求的新挑战与机遇
近年来,随着智能手机摄影、视频流媒体和AI生成内容(AIGC)的快速发展,人们对图像画质的要求持续攀升,图像质量评估(Image Quality Assessment, IQA)任务的重要性日益凸显。以往的IQA方法主要分为两类:
- 评分型方法,这类方法通常只能提供单一的数值评分,缺乏明确的解释性,难以深入理解图像质量背后的原因;
- 描述型方法,这类方法严重依赖于大规模文本描述数据进行监督微调,对标注数据的需求巨大,泛化能力和灵活性不足。
针对上述问题,北大与字节跳动联合提出了基于强化学习的图像质量理解新模型—Q-Insight。与以往方法不同的是,Q-Insight不再简单地让模型拟合真实评分(GT),而是将评分视作一种引导信号,促使模型深入思考、推理图像质量的本质原因。
通过这种创新思路,Q-Insight在质量评分、退化感知、多图比较、原因解释等多个任务上均达到业界领先水平,具备出色的准确性和泛化推理能力,有望为图像画质增强、AI内容生成等多个领域提供强有力的技术支撑。
主要贡献
Q-Insight首次将强化学习引入图像质量评估任务,创造性地运用了“群组相对策略优化”(GRPO)算法,不再依赖大量的文本监督标注,而是挖掘大模型自身的推理潜力,实现对图像质量的深度理解。
如图所示,Q-Insight不仅输出单纯的得分、退化类型或者比较结果,而是提供了从多个角度综合评估画质的详细推理过程。

在实际训练过程中,研究团队发现单独以评分作为引导无法充分实现良好的画质理解,原因是模型对图像退化现象不够敏感。
为了解决这一问题,论文创新性地引入了多任务GRPO优化,设计了可验证的评分奖励、退化分类奖励和强度感知奖励,联合训练评分回归与退化感知任务。
这种多任务联合训练的策略,显著提高了各个任务的表现,证明了任务之间存在的强互补关系。

实验结果
实验结果充分验证了Q-Insight在图像质量评分、退化检测和零样本推理任务中的卓越表现:
- 在图像质量评分任务上,Q-Insight在多个公开数据集上的表现均超过当前最先进的方法,特别是在域外数据上的泛化能力突出,并能够提供完整详细的推理过程。


- 在退化感知任务上,Q-Insight的表现显著优于现有的退化感知模型,尤其是在噪声(Noise)和JPEG压缩退化类型识别的准确性上。

- 在零样本图像比较推理任务上,Q-Insight无需额外监督微调,即可准确、细致地分析和比较图像质量,展示出强大的泛化推理能力。

VILLA实验室简介
视觉信息智能学习实验室(VILLA)由北京大学长聘副教授张健于2019年创立,致力于视觉重建与生成、AIGC内容安全等前沿领域的研究,成立以来已在TPAMI、TIP、IJCV、CVPR、ICCV、NeurIPS等顶级期刊会议上发表论文100余篇,其开源项目在GitHub平台获得广泛关注,累计star数超过10k。
实验室负责人张健副教授谷歌学术引用逾1.1万次,h-index达52,其单篇一作论文最高被引超1300次,累计荣获国际期刊/会议最佳论文奖6项及全球挑战赛冠军1项。
近期代表工作包括:图像条件可控生成模型T2I-Adapter、拖拽式细粒度图像/视频编辑DragonDiffusion/ReVideo、全景视频生成模型360DVD、全景内容处理/增强方案ResVR/OmniSSR、零值域扩散重建模型DDNM、高效扩散超分方案AdcSR、动态场景重建框架HiCoM/OpenGaussian、实用图像压缩感知重建PCNet、多模态篡改检测大模型FakeShield、支持AIGC篡改定位与版权保护水印技术OmniGuard/EditGuard、多模态画质理解大模型Q-Insight等。多项技术已成功应用于产业界,获得国内外知名企业的产品化落地。
#MonSter
拿下多个第一!双目深度估计大模型
本文介绍了一种用于双目深度估计的大模型MonSter,通过结合单目深度估计和立体匹配的互补优势,解决了现有方法在遮挡、无纹理等不适定区域的挑战。MonSter在五个常用基准测试(Sceneflow、KITTI 2012、KITTI 2015、Middlebury和ETH3D)上均达到SOTA水平,并展现出强大的泛化性能。
本文介绍了MonSter,一种用于立体深度估计的基础模型,旨在利用单目深度估计和立体匹配的互补优势,解决现有立体匹配方法难以处理匹配线索有限的不适定区域,如遮挡、无纹理、细结构、反光等区域,在提升精度的同时增强泛化性能。通过双分支结构,循环迭代优化单目深度与双目深度,并设计了“单目引导增强(MGR)”和“立体引导对齐(SGA)”的模块,充分结合两分支深度的优势。实验结果表明,MonSter在五个最常用的benchmark上均达到SOTA——Sceneflow、KITTI 2012、KITTI 2015、Middlebury和ETH3D。在泛化性方面,MonSter仅仅使用少量公开训练集就达到最优水准。
相关论文 MonSter: Marry Monodepth to Stereo Unleashes Power 获得 CVPR 2025 Highlight,代码已开源。
论文地址:https://arxiv.org/abs/2501.08643
项目代码:https://github.com/Junda24/MonSter
目前 MonSter在 ETH3D, KITTI 2012, KITTI 2015等多个排行榜位列第一/并列第一。
KITTI 2015:

KITTI 2012:

ETH3D:

1. 引言:
立体匹配从经过校正的立体图像中估计视差,然后可转换为绝对深度。它是自动驾驶、机器人导航和三维重建等许多应用的核心。基于深度学习的方法在标准基准测试上表现出了令人瞩目的性能。这些方法大致可分为基于代价滤波的方法和基于迭代优化的方法,但本质上都是从相似性匹配中推导出视差,基于两幅图像中存在可见匹配关系的假设。这就给匹配线索有限的病态区域(如遮挡、无纹理区域、重复/细长结构以及像素表示较低的远处物体)中带来了挑战。
与立体匹配不同,单目深度估计直接从单幅图像中恢复三维信息,因此不会遇到误匹配的挑战。尽管单目深度能够为立体匹配提供结构信息,但其深度不可避免的具有尺度和偏移模糊性,直接将这种相对深度和立体匹配的绝对深度进行融合无法充分结合二者的优势。
如图所示,单目深度模型的预测与真实值存在很大差异。即使在全局尺度和偏移对齐之后,仍然存在大量误差,这使得单目深度和立体视差的像素级融合变得复杂。基于这些见解,我们提出了MonSter,这是一种将立体匹配分解为单目深度估计和逐像素尺度-偏移恢复的新方法,它充分结合了单目和立体算法的优点,克服了缺乏匹配线索的局限性。主要贡献如下:
1.我们提出了一种新颖的立体匹配方法MonSter,充分利用像素级的单目深度先验,显著提高了立体匹配在病态区域和精细结构中的深度感知性能。
2.MonSter在五个广泛使用的排行榜上排名第一:KITTI 2012、KITTI 201、Scene Flow、Middlebury和ETH3D,将当前SOTA提高了多达49.5%。
3.与SOTA方法相比,MonSter在不同数据集上始终如一地实现了最佳的零样本泛化。仅在合成数据上训练的MonSter在各种真实世界数据集上均表现出色。
2. 方法

核心方法:
1.双支路架构:
MonSter由两个主要支路组成:单目深度支路和立体匹配支路。单目支路负责从单幅图像中提取深度信息,而立体支路则从立体图像对中估计视差。
2.互相强化:
这两个支路通过名为“单目引导增强(MGR)”和“立体引导对齐(SGA)”的模块进行多次迭代,增强彼此的性能。初始的单目深度和立体视差会被互相使用,从而不断优化。
3.自适应选择和引导:
在每次迭代中,根据置信度引导选择可靠的立体特征,以便更新每个像素的单目视差。这一过程能够有效减小因光照变化、纹理缺失等导致的错误匹配。MGR模块则利用优化后的单目深度来进一步改善立体视差。
4.尺度、偏移优化:
在执行互相改进之前,首先需要对单目深度进行全局的尺度和偏移对齐,以将其转换为与立体视差粗略对齐的视差图。这一对齐过程通过最小化预测的单目深度与已有立体视差之间的误差来实现。但直接将单目视差单向融合到立体匹配中仍然会受到尺度-偏移模糊性的影响,这通常会在复杂区域(如倾斜或曲面)中引入噪声。因此使用SGA模块有效地解决了这一问题,确保了MonSter的鲁棒性
5.条件引导卷积GRU:
在每一轮迭代,使用条件引导卷积GRU来处理不同分支的输入及其置信度,实现对未匹配区域的细致修正。这样能保证单目深度为立体匹配提供稳定可靠的指导。
3. 实验结果
- Benchmark performance

我们在五个benchmark上均达到SOTA,均显著提升。
2. 病态区域等挑战场景表现

我们在KITTI 2012的反光区域上排行第一,且相比SOTA在Out-3(All)和Out-4(All)指标上大幅提升58.32%和65.02%。同时,在细小边缘区域,我们相比我们的基线方法提升了24.39%。这证明了我们结合单目深度的有效性,大大提升了立体匹配在病态区域的性能。
3. 零样本泛化性

仅仅使用Sceneflow进行训练,我们的泛化性就已大幅超越SOTA方案。有趣的是,仅仅只需要增加CREStereo和TartanAir进训练集,我们的泛化性就能显著增强,在ETH3D上相比baseline方案提升49.16%。
4. 消融实验

在消融实验中,我们系统验证了模型各关键组件的有效性,通过比较MGR、SGA模块和普通卷积融合,证明MGR、SGA模块的有效性。这证明仅仅是简单的普通卷积融合,并不能充分发挥二支路信息互补的优势。

我们还证明了我们方法的高效性,当使用我们的框架时,仅需要4次迭代就可以达到相比baseline更高的精度,推理速度更快。同时我们还通过替换单目深度估计模型,证明了我们方法的通用性,相比baseline均具有显著提升。
5. 可视化结果
Zero-Shot performance in the wild

Zero-Shot performance in KITTI

展望
我们致力于提供一个更轻量化版本的MonSter,并且由于MonSter的强泛化性(我们仅仅使用少量公开训练集),我们将提供一个更多数据集混合训练的版本供给社区使用,除此以外,MVS的版本即将release!欢迎关注!
团队介绍:
该论文来自于华中科技大学、道通智能以及英特尔。其中论文一作程俊达为华中科技大学在读博士,此前曾在大疆、英特尔和道通智能实习。研究方向为3D 视觉。
#MatAnyone
视频抠图MatAnyone来了,一次指定全程追踪,发丝级还原
本文由南洋理工大学和商汤科技联合完成。第一作者杨沛青为南洋理工大学 MMLab@NTU 在读博士生,在 CVPR、NeurIPS、IJCV 等国际顶级会议与期刊上发表多篇研究成果。项目负责作者为该校研究助理教授周尚辰和校长讲席教授吕建勤。
视频人物抠像技术在电影、游戏、短视频制作和实时视频通讯中具有广泛的应用价值,但面对复杂背景和多目标干扰时,如何实现一套兼顾发丝级细节精度及分割级语义稳定的视频抠图系统,始终是个挑战。
来自南洋理工大学 S-Lab 与商汤科技的研究团队最新提出了一个高效、稳定、实用的视频抠图新方法 ——MatAnyone。与传统无辅助方法不同,MatAnyone 提出一种基于记忆传播的「目标指定型」视频抠像方法:只需在第一帧通过人物遮罩指定抠像目标,即可在整个视频中实现稳定、高质量的目标提取。

论文标题:MatAnyone: Stable Video Matting with Consistent Memory Propagation
论文链接:https://arxiv.org/abs/2501.14677
视频:https://youtu.be/oih0Zk-UW18
代码:https://github.com/pq-yang/MatAnyone
网页:https://pq-yang.github.io/projects/MatAnyone/
MatAnyone 一经发布在社交媒体上获得了大众的讨论和关注,其核心亮点总结如下:
- 快速抠图,目标可控
仅需首帧目标指定,无需额外辅助信息,支持灵活定义抠图对象,满足多场景需求。
- 稳定跟踪,全程不抖
创新 “区域自适应记忆融合” 机制,有效保持目标一致性,实现长视频中的稳定人像跟踪。
- 细节出众,发丝级还原
融合真实分割数据与高质量新数据集,边界处理自然平滑,抠图效果更贴近真实。

「目标指定型」:更贴近真实使用场景
目前主流的视频抠图方法根据 “除输入视频外是否有其他辅助输入” 这一条件可以分为两类:
- 无辅助型方法(如 RVM):用户只需上传输入视频即可。
- 辅助引导型方法(如 MaGGIe):除输入视频外,用户需通过如三分掩膜(trimap)或分割掩膜(segmentation mask)等方式在一帧或多帧指定抠像目标。
无辅助型方法虽然方便,但是由于主体目标不明确,在真实使用场景中容易出现影响实际使用的错抠、漏抠等现象。
- 【场景一】前景存在多个主要人物:在实际应用中,很可能出现的需求是单独抠出其中特定一位,合成到另外场景中制作视频,无辅助型方法不能实现目标的指定,导致输出的结果无法直接投入使用。
- 【场景二】背景存在混淆人物:即使前景只存在一位主体人物,背景中来来往往的行人往往会 “混淆视听”,尤其是行人路过前景人物时,无辅助型方法往往会把背景行人的肢体也一并抠出,使输出结果不够准确干净。
因此,为了让视频抠像技术能被更好地使用,MatAnyone 选择了辅助引导型的设定,并专注解决的是这样一个场景:
「设定主角,其他交给模型」:给定目标人物在第一帧的掩膜,后续的抠像自动锁定目标完成。无需逐帧修正,准确、自然、连贯地抠出整段视频。
这种设置既兼顾用户可控性,又具有更强的实用性和鲁棒性,是当前视频编辑领域最具潜力的落地方案之一。

面向「视频抠图」任务:记忆传播与训练策略的新范式
任务对比:「视频抠图」比「视频分割」更难一层
虽然 “目标指定型” 的任务设定在视频目标分割(Video Object Segmentation, VOS)中已经被广泛研究,通常被称为 “半监督” 分割(即只给第一帧的掩膜),但视频抠图(Video Matting, VM)的难度却更进一步。
在 VOS 中,模型的任务为“是 / 否为目标前景” 的二值判断题;而在 VM 中,基于这个语义判断,模型还需预测目标前景在每个像素点上的 “透明度(alpha)”—— 这不仅要求核心区域的语义精准,更要求边界细节的提取(如发丝、衣角的半透明过渡)。

MatAnyone 正是在这一背景下提出了面向视频抠图任务的全新记忆传播与训练策略,在达到分割级语义稳定的基础上进一步实现了发丝级细节精度。

1. 一致性记忆传播机制:Matting 专属的 “记忆力”
相比静态图像抠图,视频抠图面临更大的挑战,不仅需要逐帧生成高质量的透明通道( alpha matte),还必须确保前后帧之间的时序一致性,否则就会出现闪烁、跳变等明显视觉问题。为此,MatAnyone 借鉴视频分割中的记忆机制,在此基础上提出了专为视频抠图设计的一致性记忆传播机制(Consistent Memory Propagation)。
区域自适应融合记忆(Region-Adaptive Fusion)
模型会在每一帧中预测哪些区域与上一帧差异较大(如身体边缘),哪些区域变化很小(如身体主干),并分别处理:
- 对于变化幅度较大的区域(通常出现在目标边缘,如头发、衣摆),模型更依赖当前帧从记忆库中检索到的记忆信息;
- 而对变化较小的区域(如身体内部),则更多保留上一帧的记忆信息,避免重复建模,减少误差传播。
边界细节增强,核心区域稳定
这种区域感知式的信息融合方式,在训练阶段引导模型更专注于细节边界,在推理阶段则提升了语义稳定性与时间一致性。尤其在复杂背景或人物交互频繁的场景下,MatAnyone 能够稳准地识别目标、抠出清晰自然的边缘效果,极大提升了视频抠图的可用性与观感质量。

2. 共头监督策略:让分割数据 “真正为抠图所用”
一直以来,「视频抠图」的一个核心难点始终是真实训练数据的缺失。相较于「视频分割」在真实数据上的标注成本,「视频抠图」所需要的带透明度标注的数据格外昂贵,这限制了模型在稳定性与泛化能力上的进一步提升。
在真实透明度数据稀缺的背景下,Video Matting 模型往往会引入大量真实分割数据进行辅助训练,以提升模型在复杂环境中的稳定性和泛化能力。
- 传统做法通常采用 “平行预测头” 结构:在输出层增加一个仅用于训练阶段的分割头,用于分割数据的监督,而抠图主头则仅由合成抠图数据驱动。
这种结构虽然能一定程度引入语义信息对抠图头的监督,但其不直接的监督方式导致语义信息在特征传播过程中被稀释,无法充分发挥分割数据对提升稳定性的优势。
- MatAnyone 提出了结构创新的 “共头监督策略”:抛弃 “平行预测头”,直接将真实分割数据引入抠图主头进行训练,让所有数据源在同一个通道上对模型进行统一监督。
这种方式极大提高了语义信息的共享效率,也最大程度地利用了真实分割数据对透明通道预测的泛化性和稳定性的提升。
具体操作上:
- 在核心区域,使用分割掩膜进行逐像素监督,确保模型对语义结构的稳定理解;
- 在边界区域,引入改进版的 DDC 损失(Scaled DDC Loss),即便分割数据没有 alpha 标签,也能通过图像结构引导模型生成过渡自然的边缘。
这一策略的核心优势在于:让分割数据 “真正服务于抠图任务本身”,而非仅仅提供辅助信号。
3. 自建高质数据集:训练更稳,评估更难
高质量的数据始终是训练稳定、泛化强的视频抠图模型的基础。针对现有数据集在规模、细节和多样性上的不足,MatAnyone 团队自建了两套关键数据资源:
- VM800 训练集:相较于主流的 VideoMatte240K,VM800 的规模翻倍,覆盖更多发型、服饰和运动状态,在核心区域和边界区域的质量都显著提升,有效增强了模型在抠图任务中的鲁棒性;
- YouTubeMatte 测试集:相较于主流的 VideoMatte240K 测试集,我们构建了一个前景更加多样的测试集,并且在合成前后景的过程中进行了和谐化的后处理,使其更加贴近真实分布,有效提高了该测试集的难度。
这两套数据集为 MatAnyone 提供了扎实的训练基础与更贴近真实世界的验证标准,在推动模型性能提升的同时,也为未来视频抠图研究提供了更具挑战性的新 benchmark。

多场景适用性:灵活应对多类应用场景
MatAnyone 在模型设计与推理机制上的灵活性,使其具备良好的任务泛化能力,能够适配多种实际视频处理场景(更多例子请移步主页):
通用视频抠图(General Matting):适用于短视频剪辑、直播背景替换、电影 / 广告 / 游戏后期等常见场景,仅需第一帧提供目标掩膜,后续帧即可自动完成稳定抠图,具备边界清晰、背景干净、跨帧一致性强的优势。
,时长00:03
,时长00:04
,时长00:55
实例抠图(Instance Matting):面对多人物或复杂背景的视频内容,MatAnyone 支持通过第一帧掩膜指定目标对象,进行后续稳定追踪与抠图,有效避免目标混淆或漂移,适合虚拟人剪辑、人物聚焦等实例级编辑任务。
,时长00:31
推理阶段增强(Iterative Refinement):对于高精度场景,如广告制作、影视后期等,MatAnyone 提供可选的首帧迭代优化机制,通过多轮推理精细化第一帧 alpha matte,从而进一步提升整段视频的细节还原与边界自然度。
,时长00:03
实验结果:领先的细节质量与时序稳定
为了系统评估 MatAnyone 在视频抠图任务中的综合表现,我们从定性与定量两个角度进行了对比实验,结果显示 MatAnyone 在精度、稳定性与视觉质量等多个维度均优于现有主流无辅助型及辅助引导型方法。
定性评估(Qualitative)
在真实视频案例中,我们展示了 MatAnyone 与现有方法 RVM、FTP-VM、MaGGIe 的可视化对比。结果表明,MatAnyone 能够更准确地提取目标人物轮廓,尤其是在人物动作剧烈或背景复杂的情况下,依然能保持头发、边缘衣物等细节的清晰度,并有效避免背景穿透与边界断裂等常见问题。同时,它也具备更强的实例区分能力,即使画面中存在多个显著人物,也能准确锁定目标对象并保持一致跟踪。


定量评估(Quantitative)
在合成数据集 VideoMatte 和自建的 YouTubeMatte 上,我们使用五个关键指标对各方法进行全面评估:
- MAD(Mean Absolute Difference)与 MSE(Mean Squared Error)用于衡量语义准确性;
- Grad(Gradient)用于细节锐利度评估;
- Conn(Connectivity)代表整体视觉连贯性;
- dtSSD 则衡量跨帧间的时序一致性。
如 Table 1 所示,MatAnyone 在高、低分辨率的所有数据集上均取得最低的 MAD 和 dtSSD,表现出极高的语义稳定性与时间一致性;同时在 Conn 指标上也位居首位,验证了其在整体观感和边缘处理上的领先表现。

总结与展望
MatAnyone 是一套面向真实使用场景的人像视频抠图系统,专注于在仅提供首帧目标的前提下,实现语义稳定且边界精细的视频级抠图。根据「视频抠图」任务的特性,它引入了区域自适应的记忆融合机制,在保持语义稳定性的同时,精细提取了头发等细节区域。借助新构建的 VM800 高质量数据集与全新的训练策略,MatAnyone 显著提升了在复杂背景下的抠图稳定性。
面对真实训练数据的制约,「视频抠图」任务仍然像是在 “戴着镣铐跳舞”,当前的效果虽有显著突破,但仍有广阔的提升空间。未来,我们团队将继续探索更高效的训练策略、更泛化的数据构建方式,以及更通用的记忆建模机制,推动视频抠图技术在真实世界中实现更强鲁棒性与更广应用性。

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









