







我自己的原文哦~ https://blog.51cto.com/whaosoft/12163849
#Robin3D
3D场景的大语言模型:在鲁棒数据训练下的3DLLM新SOTA!
- 论文地址:https://arxiv.org/abs/2410.00255
- 代码将开源:https://github.com/WeitaiKang/Robin3D
介绍
多模态大语言模型(Multi-modal Large Language Models, MLLMs)以文本模态为基础,将其它各种模态对齐至语言模型的语义空间,从而实现多模态的理解和对话能力。近来,越来越多的研究聚焦于3D大语言模型(3DLLM),旨在实现对3D物体以及复杂场景的理解,推理和自由对话。
与2D MLLMs所能接触的广泛的多模态数据不同,3DLLMs的训练数据相对稀少。即便过去有些工作尝试生成更多的多模态指令数据,他们仍然在指令的鲁棒性上存在两点不足:
1)绝大多数3D多模态指令数据对是正样本对,缺乏负样本对或者对抗性样本对。模型在这种数据上训练缺乏一定的辨识能力,因为无论被问到什么问题,模型只会输出正面的回答。因此碰到问题与场景无关时,模型也更容易出现幻觉。这种模型有可能只是记住了正样本对,而非真正地理解被问及的场景、物体、以及具体的指令。
2)由于在造数据的过程中,人类标注员或者生成式大语言模型是按照既定的规则去描述物体的,很多由这些描述所转换而来的指令缺乏多样性。甚至有的数据是直接按照模板生成的。
为了解决以上问题,我们提出一个强大3DLLM--Robin3D。其在大规模鲁棒数据上得到训练。特别的,我们提出了“鲁棒指令数据生成引擎”(Robust Instruction Generation, RIG),旨在生成两种数据:
1)对抗性指令数据。该数据特点在于在训练集或者单个训练样本中,混合了正样本和负样本对(或者对抗样本对),从而使得模型在该类数据集训练能获得更强的辨识能力。我们的对抗性指令数据包含了物体层面到场景层面的、基于类别的指令和基于表达的指令。最终形成了四种新的训练任务,帮助模型解耦对正样本对的记忆。
2)多样化指令数据。我们首先全面收集现有研究中的各种指令类型,或将一些任务转化为指令跟随的格式。为了充分利用大语言模型 (LLMs) 强大的上下文学习能力,我们使用ChatGPT,通过为每个任务定制的特定提示工程模板来多样化指令的语言风格。
将这些与现有基准的原始训练集相结合,我们构建了百万级指令跟随样本,其中约有34.4万个对抗性数据(34%)、50.8万个多样化数据(50%)和 16.5 万个基准数据(16%),如图 1(右)所示。

图1 Robin3D在我们构建的百万级数据上训练(右),最终在所有3D多模态数据集上的性能超过之前的SOTA(左)
Robin3D在模型上与Chat-Scene类似。我们使用Mask3D, Uni3D来抽3D物体级别的特征,使用Dinov2来抽2D物体级别的特征,使用物体ID来指定和定位物体。可是先前的方法在抽物体特征的时候,由于其物体级别的规范化(normalization),不可避免的丢失了物体间的3D空间关系。同时他们简单的物体ID和物体特征拼接缺乏对ID-特征的充分联结,使其在我们这种复杂的指令数据上面临训练的困难。
因此,Robin3D引入了关系增强投射器来增强物体的3D空间关系,并使用ID-特征捆绑来增强指代和定位物体时ID与特征之间的联系。
最终Robin3D在所有的3D场景多模态数据集上达到一致的SOTA,并且不需要特定任务的微调。
方法

图2 Robin3D的模型结构
关系增强投射器
如图2所示,关系增强投射器(Relation-Augmented Projector, RAP)考虑三种特征:1)Mask3D所抽取的场景级别特征,这种特征经过多层cross-attention充分交互了语意和位置关系。2)Mask3D里的位置嵌入特征,这种特征由物体超点直接转换而来,代表了物体间的位置关系。3)Uni3D抽取的统一物体级别特征,这种特征和语言进行过大规模的对齐训练。

RAP公式
如图3所示,我们通过MLP和短接的方式,对三种特征进行高效的融合,最终实现了即保持强大的统一物体级别语意信息、又增强了物体之间的空间位置关系。
ID-特征捆绑
如图1所示,我们的ID-特征捆绑(ID-Feature Bonding, IFB)主要包含两个操作。首先,我们使用两个相同的ID来包裹其物体特征。由于LLM的因果注意力机制,这种方法通过第一个ID将ID信息与物体特征关联起来,并通过第二个ID将物体信息与其ID关联起来。其次,我们提出了一个后视觉顺序,将视觉tokens放置在输入序列的末尾,靠近模型生成的答案标记。该方法减少了由于tokens间的相对距离和LLM中旋转位置嵌入所导致的从答案tokens到ID-特征tokens的注意力减弱问题,同时增强了视觉信息对答案tokens的注意力影响,从而提升答案生成效果。
鲁棒指令数据生成引擎
对抗性数据生成

图3 对抗性数据的四种任务
如图3,我们的对抗性数据形成了四种新的具备挑战性的任务HOPE、HROC、PF-3DVG和3DFQA,包含了从物体到场景、从基于类比到基于表达的不同指令。
Hybrid Object Probing Evaluation (HOPE)--图3左上
为了构建一个场景级别的基于类别的任务,我们引入了HOPE,灵感来自2D领域的POPE基准。POPE通过询问关于单个物体存在与否的是/否问题,评估2DMLLMs产生幻觉的倾向。在此基础上,HOPE将这种幻觉挑战扩展到3D领域的训练阶段,旨在让模型更具辨别力。此外,HOPE引入了一个混合场景,增加复杂性,进一步推动模型对记忆中的视觉与语言正样本的解耦。具体来说,在给定的3D场景中,我们要求模型判断多个随机指定的物体是否存在。物体可能存在或不存在,且每个存在的物体可能有一个或多个实例。当物体不存在时,模型需回答“否”;当物体存在时,需回答“是”并提供每个实例的物体ID。这一设置结合了正负物体的混合识别与多实例物体定位,具有很高的挑战性。
Hybrid Referring Object Classification (HROC)--图3右上
指代物体分类任务旨在评估模型在2D域中识别指代区域的能力,使用“区域输入,文本输出”的形式。我们的HROC将此任务扩展到3D领域,创建了一个物体级别的基于类别的任务,并结合了对抗性和混合挑战。在3D场景中,我们随机生成混合的正负ID-类别样本对来提出问题。正样本对包含一个有效的物体ID和对应的真实类别,负对则包含一个有效的物体 ID和随机选择的非真实类别,作为对抗性挑战。模型需对正样本对回答“是”,对负对回答“否”并给出正确类别。
Partial Factual 3D Visual Grounding (PF-3DVG)--图3左下
我们的 PF-3DVG 引入了一个场景级别的基于表达的任务,涵盖三种数据类型:非真实数据、部分真实数据和真实数据。非真实数据:在3D场景中,随机选择Sr3D+中的描述,其中所描述的物体不存在与当前3D场景。模型需回答“否”。
部分真实数据:给定Sr3D+的描述及对应的3D场景,随机修改描述中的空间关系。例如,将“沙发上的枕头”改为“沙发下的枕头”。模型需纠正信息并回答“它是在‘上面’”,同时提供物体ID。我们确保描述的目标物体类别是当前场景唯一的、无干扰项,以避免歧义。
真实数据:随机增强空间关系的同义词以提高多样性,例如,将“below”替换为“under”、“beneath”或“underneath”。
Faithful 3D Question Answering (3DFQA)--图3右下
原始的3D问答任务仅包含正样本,可能导致模型记住固定的3D场景和问答对。为了解决这一问题,我们提出3DFQA,一个结合了负样本和正样本的场景级别的基于表达的QA任务,其增加了定位的要求。
构建负样本时,我们从ScanQA中抽取问答对,并收集问题或答案中的相关物体,然后随机选择一个缺少这些物体的3D场景。在原来的问题上,我们新增一个指令:“如果可以,请回答……并提供所有ID……”。此时,模型必须回答“否”,并且不提供任何物体 ID,体现其对场景的依赖而不会胡言乱语总给出正面回复。正样本直接取自ScanQA,模型需回答问题并提供相关物体的ID作为答案的依据。因此,训练在我们的3DFQA数据集上的模型不能依靠记忆,而是要学会对正负样本做出忠实回应并有理有据。
多样化数据生成
多样化数据旨在通过结合多种不同任务类型的指令数据,并提高指令的语言多样性,从而增强模型的泛化能力。我们首先从基准数据集之外的不同任务中收集大规模数据。具体而言,给定一个3D场景,我们收集以下任务的问答对:
类别问答任务(来自Chat-Scene),Nr3D描述生成任务(转换自Nr3D),外观描述生成任务(来自Grounded-3DLLM),区域描述生成任务(来自Grounded-3DLLM),端到端3D视觉定位(转换自Nr3D),端到端3D视觉定位(转换自Sr3D+)。

图4 多样化数据的生成流程和详细的提示工程
为了丰富表述风格,我们开发了一个可扩展的流程,利用ChatGPT的上下文学习能力对上述数据进行重述。这通过一组示例和结构化提示工程实现,如图4(上)所示。具体而言,给定一个收集的指令数据集D_task(其中任务包括 ScanRefer、Multi3DRefer、Nr3D、Sr3D+、Nr3D Captioning、ScanQA、SQA3D、PF-3DVG和3DFQA),我们构建了一个系统提示P_system,以指示重述的要求和结构化的输出格式,同时提供一个示例提示P_eg,以帮助ChatGPT更好地理解要求。我们还随机选择一个温度参数T(从 [1.1, 1.2, 1.3]中选取)以增加输出的随机性和多样性。
我们的重述输出D_rephrase通过公式D_rephrase = M(P_system, P_eg, D_task, T)生成,其中M是ChatGPT的GPT-4o版本。图4(上)详细说明了P_system和P_eg的内容,以 ScanRefer数据为例。通过使用sentence=和rephrase=的结构化提示,GPT-4o能够轻松遵循要求,我们可以通过检测rephrase=关键字方便地收集输出。图 4(下)提供了每个任务的示例提示的详细信息。由于Nr3D Captioning源于Nr3D,PF-3DVG源于Sr3D+,而3DFQA源于ScanQA,因此我们不再为这些任务提供额外示例。
实验
主要结果

表1 性能对比结果
如表1所示,由于RIG生成的鲁棒指令数据,Robin3D在所有基准测试中显著超越了之前的模型。具体而言,Robin3D在Scan2Cap CIDEr@0.5上带来了 6.9% 的提升,在ScanRefer Acc@0.25上带来了 5.3% 的提升。值得注意的是,在包含零目标案例的Multi3DRefer评估中,这些案例对模型的区分能力提出了挑战,并要求模型能够回答 “No”。我们的Robin3D在F1@0.25上实现了 7.8% 的提升,在F1@0.5上实现了 7.3% 的提升。
消融实验

表2和表3 消融实验结果
如表2和表3所示,我们对提出的对抗性数据和多样化数据进行了消融实验,也对模型结构上RAP和IFB的提出做了消融实验。实验结果在所有benchmark上都证明了他们一致的有效性。特别的,在表2中,对抗性数据对描述生成任务Scan2Cap带来了 8.9% 的提升,然而对抗性数据是不存在描述生成任务的,并且也不存在同源的数据(Scan2Cap数据源自ScanRefer, 但我们对抗性数据无源自ScanRefer的数据)。这种大幅的提升体现了对抗性数据对模型识别能力的提升。
#SpikeYOLO
高性能低能耗目标检测网络
本文提出了目标检测框架SpikeYOLO,以及一种能够执行整数训练脉冲推理的脉冲神经元。在静态COCO数据集上,SpikeYOLO的mAP@50和mAP@50:95分别达到了66.2%和48.9%,比之前最先进的SNN模型分别提高了+15.0%和+18.7%。
中国科学院自动化所李国齐课题组
论文:https://arxiv.org/abs/2407.20708
代码:github.com/BICLab/SpikeYOLO
脉冲神经网络(Spike Neural Networks,SNN)因其生物合理性和低功耗特性,被认为是人工神经网络(Artificial Neural Networks,ANN)的一种有效替代方案。然而,大多数SNN网络都由于其性能限制,只能应用于图像分类等简单任务。为弥补ANN和SNN在目标检测上之间的性能差距,本文提出了目标检测框架SpikeYOLO,以及一种能够执行整数训练脉冲推理的脉冲神经元。在静态COCO数据集上,SpikeYOLO的mAP@50和mAP@50:95分别达到了66.2%和48.9%,比之前最先进的SNN模型分别提高了+15.0%和+18.7%;在神经形态目标检测数据集Gen1上,SpikeYOLO的mAP@50达到了67.2%,比同架构的ANN提高了+2.5%,并且能效提升5.7×。
1. 背景
脉冲神经元模拟了生物神经元的复杂时空动态,其利用膜电势融合时空信息,仅在膜电势超过阈值时发射二值脉冲信号。因此,脉冲神经网络只有在接收到脉冲信号时才会触发稀疏加法运算。当脉冲神经网络部署到神经形态芯片时,能发挥其最大的低功耗优势。例如,神经形态感算一体芯片Speck[1]采用异步电路设计,具有极低的静息功耗(低至0.42mW),在典型神经形态边缘视觉场景的功耗低至0.7mW。
然而,脉冲神经元的复杂内在时空动态和二值脉冲活动是一把“双刃剑”。一方面,复杂内在时空动态特性带来强大的信息表达能力,结合脉冲信号使能事件驱动计算获得低功耗特性;而另一方面,二值脉冲活动不可微分的特性使得SNN难以训练。因此,SNN在计算机视觉中的大多数应用仅限于简单的图像分类任务,而很少应用于更常用且具有挑战性的目标检测任务,且和ANN之间有着明显的性能差距。
2020年,Spiking-YOLO[2]提供了第一个利用深度SNN进行目标检测任务的模型,利用数千个时间步长将ANN转换为SNN。2023年,EMS-YOLO[3] 成为第一个使用直接训练SNN来处理目标检测的工作。2024年,直接训练的Meta-SpikeFormer[4]成为首个通过预训练微调方式处理目标检测任务的SNN。然而,这些工作和ANN之间的性能差距显著。
2. 本文主要贡献
本文目标是弥合SNN和ANN在目标检测任务上的性能差距。我们通过两项努力实现了这一目标。第一,网络架构方面,我们发现过于复杂的网络架构在直接加入脉冲神经元后会导致脉冲退化,从而性能低下。第二,脉冲神经元方面,将连续值量化为二值脉冲不可避免会带来信息损失,这是SNN领域长久存在且难以克服的一个问题。
基于此,本工作的主要贡献包括:
简化SNN架构以缓解脉冲退化。 本文提出了SpikeYOLO,一个结合YOLOv8宏观设计和Meta-SpikeFormer微观设计的目标检测框架,主要思想是尽量避免过于复杂的网络架构设计。
设计整数训练脉冲推理神经元以减少量化误差的影响。 提出一种I-LIF神经元,可以采用整数值进行训练,并在推理时等价为二值脉冲序列,有效降低脉冲神经元的量化误差。
最佳性能。 在静态COCO数据集上,本文提出的方法在mAP@50和mAP@50:95上分别达到了66.2%和48.9%,比之前最先进的SNN模型分别提高了+15.0%和+18.7%;在神经形态数据集Gen1上,本文的mAP@50达到了67.2%,比同架构的ANN提高了+2.5%,并且能效提升5.7×。
3. 方法
3.1 架构设计
本文发现,YOLO过于复杂的网络模块设计会导致在直接加入脉冲神经元后出现脉冲退化现象。因此,本文提出的SpikeYOLO在设计上倾向于简化YOLO架构。SpikeYOLO将YOLOv8[5]的宏观设计与meta-SpikeFormer[4]的微观设计相结合,在保留了YOLO体系结构的总体设计原则的基础上,设计了meta SNN模块,包含倒残差结构、重参数化等设计思想。SpikeYOLO的具体结构如图1所示:
图1 SpikeYOLO总体架构
宏观设计: YOLO是一个经典的单阶段检测框架,它将图像分割成多个网格,每个网格负责独立地预测目标。其中一些经典的结构,如特征金字塔(FPN)等,在促进高效的特征提取和融合方面起着至关重要的作用。然而,随着ANN的发展,YOLO的特征提取模块愈发复杂。以YOLOv8的特征提取模块C2F为例,其通过复杂的连接方式对信息进行多次重复提取和融合,这在ANN中能增加模型的表达能力,但在SNN中则会引起脉冲退化现象。作为一种折衷方案,本文提出了SpikeYOLO。其保留了YOLO经典的主干/颈部/头部结构,并设计了Meta SNN模块作为微观算子。
微观设计: SpikeYOLO的微观设计参考了Meta-SpikeFormer[3],一个典型的脉冲驱动CNN+Transformer混合架构。我们发现Transformer结构在目标检测任务上表现不如简单的CNN架构,作为一种折中方案,本文提出的SpikeYOLO尽量避免过于复杂的网络架构设计。SpikeYOLO包含两种不同的卷积特征提取模块:SNN-Block-1和SNN-Block-2,分别应用于浅层特征提取和深层特征提取。两种特征提取模块的区别在于他们的通道混合模块(ChannelConv)不同。SNN-Block-1采用标准卷积进行通道混合(ChannelConv1),SNN-Block-2采用重参数化卷积进行通道混合(ChannelConv2),以减少模型参数量。SpikeYOLO的特征提取模块可被具体表示为:
3.2 神经元设计
脉冲神经元通过模拟生物神经元的通信方案,在空间和时间域上传播信息。然而,在将尖峰神经元的膜电位量化为二值脉冲时存在严重的量化误差,严重限制了模型的表达能力。为解决这个问题,本文提出了一种整数训练,脉冲推理的神经元I-LIF。I-LIF在训练过程中采用整数进行训练,在推理时通过拓展虚拟时间步的方法将整数值转化为二值脉冲序列以保证纯加法运算。
考虑传统的软重置的LIF神经元,其内部时空动力学可以被表示为:
上式中,Θ(·)是指示函数,将小于0的值置零,否则置1。这种二值量化方式带来了严重的量化误差。相比之下,I-LIF不将膜电势与神经元阈值做比较,而是对膜电势四舍五入量化为整数,其脉冲函数S[t]被重写为:
其中,round(·)是四舍五入量化函数,Clip(·)是裁剪函数,D是最大量化值。S[t]的发放结果被量化为[0,D]的整数,以降低模型量化误差。
推理时,I-LIF通过拓展虚拟时间步的方法,将整数值转化为二值脉冲序列,以保证网络的脉冲驱动特性,如图2所示。
图2 I-LIF训练和推理原理(在训练过程中发放的整数值2,在推理过程中转化为两个1)
图3展示了一个更加细节的例子(T=3,D=2)。在训练时,当膜电势为1.9时(如第一列),I-LIF发放一个值为2的整数,并将膜电势减去相应量化值;当膜电势为2.6时(如第三列),由于其高于最大量化值,I-LIF也只发放一个值为2的整数,而不会发放值为3的整数。在推理时,I-LIF拓展虚拟时间步(图中红色虚线部分),将整数值转化为二值脉冲序列,保证脉冲驱动。
图3 I-LIF发放模式举例
4.1 静态数据集
如图4所示,SpikeYOLO在COCO数据集上达到了66.2%的mAP@50和48.9%的mAP@50:95,分别比之前SNN领域的SOTA结果提升了+15.0%和+18.7%,超越DETR等ANN模型,并且仅需要84.2mJ的能耗。此外,增大量化值D的效果远远优于增加之间步长T,且能耗增幅更小。
图4 COCO 静态数据集实验结果
4.2 神经形态数据集
如图5所示,SpikeYOLO在神经形态数据集Gen1上同样取得了SNN领域的SOTA结果,map@50:95超过SNN领域的SOTA结果+9.4%。和同架构ANN网络相比,SpikeYOLO的mAP@50:95提高了+2.7%,并且能效提升5.7×。
图5 Gen1 神经形态数据集实验结果
4.3 消融实验
4.3.1 架构消融实验
本文在COCO数据集上进行不同模块的消融实验,包括移除重参数化卷积、采用SNN-Block-2替换SNN-Block-1,以及将Anchor-free检测头替换为Anchor-based检测头等。结果证明,SpikeYOLO拥有最先进的性能。
图6 COCO数据集架构消融实验结果
4.3.2 量化值实验
图7 Gen1数据集量化值消融实验结果
本文在Gen1数据集上分别测试了不同时间步T和量化值D对精度和能耗的影响。实验表明。适当增加T或D都有助于提升模型性能。另外,当提升D时,模型的能耗反而降低,一个可能的原因是输入数据是稀疏的事件数据,包含的有效信息较少,此时采用更精细的膜电势量化方案可以避免网络发放冗余脉冲,从而降低模型的平均发放率。
综上所述,本文提出了目标检测框架SpikeYOLO,以及一种整数训练脉冲推理的神经元I-LIF,并在静态和神经形态目标检测数据集上均进行了验证。全文到此结束,更多细节建议查看原文。
参考文献
https://github.com/ultralytics/ultralytics
#NV-CLIP
多模态嵌入模型赋能视觉应用:高性能、可扩展、灵活集成
国庆期间,NVIDIA又悄咪咪地发布了一个好东西:
NV-CLIP是NVIDIA NIM(NVIDIA AI微服务)平台的一部分,是一款强大的多模态嵌入模型。作为OpenAI的CLIP(对比语言-图像预训练)模型的商业版本,NV-CLIP旨在将图像转换为三维(3D)文本嵌入,从而成为广泛应用于视觉领域的有价值工具。
NVIDIA NIM是NVIDIA AI Enterprise的一部分,它提供了一系列易于使用的微服务,旨在加速企业在生成式AI方面的部署。NVIDIA NIM支持包括NVIDIA AI基础模型和自定义模型在内的广泛AI模型,确保无缝、可扩展的AI推理,无论是在本地还是在云端,都利用行业标准的API。
NVIDIA NIM为生成式AI和视觉AI模型提供了预构建的容器,这些容器可用于开发视觉应用、视觉聊天机器人或任何需要理解视觉和人类语言的应用。每个NIM都由一个容器和一个模型组成,并利用针对所有NVIDIA GPU优化的CUDA加速运行时,同时提供了适用于多种配置的特别优化。无论是在本地还是在云端,NIM都是实现大规模加速生成式AI推理的最快方式。
NV-CLIP的工作原理
NV-CLIP基于7亿张专有图像进行训练,使其能够准确地将图像与相应的文本描述相匹配。这是通过对比学习实现的,即训练模型区分图像和文本匹配对与非匹配对。最终得到一组嵌入,这些嵌入能够以易于与文本数据比较的方式表示图像。
NV-CLIP NIM微服务的应用
NV-CLIP NIM微服务凭借其将图像转换为三维(3D)文本嵌入的强大能力,在视觉领域开辟了广泛的应用前景。让我们深入了解一下其中的一些关键应用:
多模态搜索:NV-CLIP能够实现准确的图像和文本搜索,使用户能够快速浏览庞大的图像和视频数据库。这在用户需要根据文本描述查找特定视觉内容或反之的情境中特别有用。例如,在数字图书馆或媒体档案中,NV-CLIP可以根据关键词或短语帮助检索相关图像或视频,使搜索过程更加高效和准确。
零样本和少样本推理:NV-CLIP的一个突出特点是它能够在无需重新训练或微调的情况下对图像进行分类。这使其成为标签数据有限或不存在的情况下的宝贵工具。通过零样本和少样本推理,NV-CLIP可以根据其训练过的文本描述对图像进行分类,即使在缺乏大量标签数据集的情况下也能实现快速准确的分类。这种能力在诸如产品识别等应用中特别有用,因为新产品不断推出,而标签数据可能无法获得。
下游视觉任务:NV-CLIP生成的嵌入可以用于实现一系列下游复杂的视觉AI任务。这些任务包括分割、检测、视觉语言模型(VLMs)等。例如,在医学影像领域,NV-CLIP的嵌入可以用于准确分割和检测图像中的异常,辅助诊断和治疗各种医疗状况。同样,在自动驾驶领域,NV-CLIP的嵌入可以用于实时检测和识别物体,提高这些系统的安全性和效率。
NV-CLIP的高性能特性
NV-CLIP提供了一系列高性能特性,使其成为视觉应用的理想选择。这些特性包括:
可扩展部署:NV-CLIP性能出色,能够轻松无缝地从少数用户扩展到数百万用户,适用于大规模应用。
模型:NV-CLIP基于先进的CLIP架构构建,为各种流行模型提供了优化和预生成的引擎。
灵活集成:NV-CLIP可以轻松集成到现有的工作流和应用中,并提供了与OpenAI API兼容的编程模型和额外的NVIDIA扩展,以实现更多功能。
企业级安全性:NVIDIA NIM通过使用safetensors、持续监控和修补堆栈中的CVE漏洞以及进行内部渗透测试来确保数据隐私,从而强调安全性。
NV-CLIP入门指南
部署和集成NV-CLIP非常简单,基于行业标准的API。要开始使用,只需参考NV-CLIP NIM微服务文档,其中提供了关于如何部署和使用该模型的详细说明。
综上所述,NV-CLIP作为一款强大的多模态嵌入模型,在视觉领域具有广泛的应用前景和巨大的潜力。它不仅能够提高图像和文本搜索的准确性和效率,还能够实现零样本和少样本推理以及复杂的下游视觉任务,为企业的生成式AI部署提供有力的支持。
更多NV-CLIP的信息请访问:
https://catalog.ngc.nvidia.com/orgs/nim/teams/nvidia/containers/nvclip
https://docs.nvidia.com/nim/nvclip/latest/getting-started.html
#RT-DETR
号称YOLO终结者?
实时目标检测中击败YOLO家族?来看看百度飞桨的PaddleDetection团队提出的 RT-DETR究竟强在哪里。
众所周知,实时目标检测(Real-Time Object Detection)一直被YOLO系列检测器统治着,YOLO版本更是炒到了v8,前两天百度飞桨的PaddleDetection团队发布了一个名为 RT-DETR 的检测器,宣告其推翻了YOLO对实时检测领域统治。论文标题很直接:《DETRs Beat YOLOs on Real-time Object Detection》,直译就是 RT-DETR在实时目标检测中击败YOLO家族!
论文链接:https://arxiv.org/abs/2304.08069
代码链接:
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr
去年各大YOLO争相发布各显神通的场景才过去没多久,如今RT-DETR发布,精度速度都完胜所有YOLO模型,是否宣告了YOLO系列可以淘汰了?其实之前本人已经写过3篇文章介绍各个YOLO【从百度飞桨PaddleYOLO库看各个YOLO模型】(https://zhuanlan.zhihu.com/p/550057480),【YOLO内卷时期该如何选模型?】(https://zhuanlan.zhihu.com/p/566469003)和 【YOLOv8精度速度初探和对比总结】,如今还是想再结合 RT-DETR的论文代码,发表一下自己的一些浅见。
关于RT-DETR的设计:
结合PaddleDetection开源的代码来看,RT-DETR是基于先前DETR里精度最高的DINO检测模型去改的,但针对实时检测做了很多方面的改进,而作者团队正是先前PP-YOLOE和PP-YOLO论文的同一波人,完全可以起名为PP-DETR,可能是为了突出RT这个实时性的意思吧。

RT-DETR模型结构
(1)Backbone: 采用了经典的ResNet和百度自研的HGNet-v2两种,backbone是可以Scaled,应该就是常见的s m l x分大中小几个版本,不过可能由于还要对比众多高精度的DETR系列所以只公布了HGNetv2的L和X两个版本,也分别对标经典的ResNet50和ResNet101,不同于DINO等DETR类检测器使用最后4个stage输出,RT-DETR为了提速只需要最后3个,这样也符合YOLO的风格;
(2) Neck: 起名为HybridEncoder,其实是相当于DETR中的Encoder,其也类似于经典检测模型模型常用的FPN,论文里分析了Encoder计算量是比较冗余的,作者解耦了基于Transformer的这种全局特征编码,设计了AIFI (尺度内特征交互)和 CCFM(跨尺度特征融合)结合的新的高效混合编码器也就是 Efficient Hybrid Encoder ,此外把encoder_layer层数由6减小到1层,并且由几个通道维度区分L和X两个版本,配合CCFM中RepBlock数量一起调节宽度深度实现Scaled RT-DETR;

HybridEncoder设计思路
(3)Transformer: 起名为RTDETRTransformer,基于DINO Transformer中的decoder改动的不多;
(4)Head和Loss: 和DINOHead基本一样,从RT-DETR的配置文件其实也可以看出neck+transformer+detr_head其实就是一整个Transformer,拆开写还是有点像YOLO类的风格。而训练加入了IoU-Aware的query selection,这个思路也是针对分类score和iou未必一致而设计的,改进后提供了更高质量(高分类分数和高IoU分数)的decoder特征;
(5)Reader和训练策略: Reader采用的是YOLO风格的简单640尺度,没有DETR类检测器复杂的多尺度resize,其实也就是原先他们PPYOLOE系列的reader,都是非常基础的数据增强,0均值1方差的NormalizeImage大概是为了节省部署时图片前处理的耗时,然后也没有用到别的YOLO惯用的mosaic等trick;训练策略和优化器,采用的是DETR类检测器常用的AdamW,毕竟模型主体还是DETR类的;
关于精度:
来看下RT-DETR和各大YOLO和DETR的精度对比:
(1)对比YOLO系列:
同级别下RT-DETR比所有的YOLO都更高,而且这还只是RT-DETR训练72个epoch的结果,先前精度最高的YOLOv8都是需要训500个epoch的,其他YOLO也基本都需要训300epoch,这个训练时间成本就不在一个级别了,对于训练资源有限的用户或项目是非常友好的。之前各大YOLO模型在COCO数据集上,同级别的L版本都还没有突破53 mAP的,X版本也没有突破54 mAP的,唯一例外的YOLO还是RT-DETR团队他们先前搞的PP-YOLOE+,借助objects365预训练只80epoch X版本就刷到了54.7 mAP,而蒸馏后的L版本更刷到了54.0 mAP,实在是太强了。此外RT-DETR的参数量FLOPs上也非常可观,换用HGNetv2后更优,虽然模型结构类似DETR但设计的这么轻巧还是很厉害了。

和YOLO对比
(2)对比DETR系列:
DETR类在COCO上常用的尺度都是800x1333,以往都是以Res50 backbone刷上45 mAP甚至50 mAP为目标,而RT-DETR在采用了YOLO风格的640x640尺度情况下,也不需要熬时长训几百个epoch 就能轻松突破50mAP,精度也远高于所有DETR类模型。此外值得注意的是,RT-DETR只需要300个queries,设置更大比如像DINO的900个肯定还会更高,但是应该会变慢很多意义不大。

论文精度速度表格
关于速度:
来看下RT-DETR和各大YOLO和DETR的速度对比:
(1)对比YOLO系列:
首先纯模型也就是去NMS后的速度上,RT-DETR由于轻巧的设计也已经快于大部分YOLO,然后实际端到端应用的时候还是得需要加上NMS的...嗯等等,DETR类检测器压根就不需要NMS,所以一旦端到端使用,RT-DETR依然轻装上阵一路狂奔,而YOLO系列就需要带上NMS负重前行了,NMS参数设置的不好比如为了拉高recall就会严重拖慢YOLO系列端到端的整体速度。
(2)对比DETR系列:
其实结论是显而易见的,以往DETR几乎都是遵循着800x1333尺度去训和测,这个速度肯定会比640尺度慢很多,即使换到640尺度训和测,精度首先肯定会更低的多,而其原生设计庞大的参数量计算量也注定了会慢于轻巧设计的RT-DETR。RT-DETR的轻巧快速是encoder高效设计、通道数、encoder数、query数等方面全方位改良过的。
关于NMS的分析:
论文其实并没有一开始就介绍模型方法,而是通过NMS分析来引出主题。针对NMS的2个超参数得分阈值和IoU阈值,作者不仅分析了不同得分阈值过滤后的剩余预测框数,也分析了不同NMS超参数下精度和NMS执行时间,结论是NMS其实非常敏感,如果真的实际应用,不仅调参麻烦而且精度速度波动很大。以往YOLO论文中都会比一个纯模型去NMS后的速度FPS之类的,其实也很容易发现各大YOLO的NMS参数不一,而且真实应用的时候都得加上NMS才能出精确的检测框结果,所以端到端的FPS和论文公布的FPS(纯模型)不是一回事,明显会更慢的多,可以说是虚假的实时性。
此外一般做视频demo展示时,为了视频上实时出结果其实都会改成另一套NMS参数,最常见的操作就是改高得分阈值,比如原先eval精度时可能是0.001现在直接改大到0.25,强行过滤众多低分低质量的结果框,尤其在Anchor Based的方法如yolov5 yolov7这种一刀切会更加提速,以及还需要降低iou阈值以进一步加速。而DETR的机制从根本上去除了NMS这些烦恼,所以其实个人觉得去NMS这个点才是RT-DETR和YOLO系列比的最大优势,真正做到了端到端的实时性。

NMS参数影响
关于YOLO终结者的称号:
去年YOLO领域出现了一波百家争鸣的情况,各大公司组织纷纷出品自己的YOLO,名字里带个YOLO总会吸引一波热度,其中YOLOv7论文还中了CVPR2023,再到今年年初的YOLOv8也转为Anchor Free并且刷了500epoch,各种trick几乎快被吃干抹尽了,再做出有突破性的YOLO已经很难了,大家也都希望再出来一个终结性的模型,不要再一味往上叠加YOLO版本号了,不然YOLOv9甚至YOLOv100得卷到何时才到头呢?
此外,虽然各大YOLO都号称实时检测,但都只公布了去NMS后的FPS,所以我们实际端到端出检测结果时就最常发现的一个问题,怎么自己实际测的时候FPS都没有论文里写的这么高? 甚至去掉NMS后测还是稍慢。那是因为端到端测的时候NMS在捣乱,去NMS的测速虽然准确公平,但毕竟不是端到端实际应用,论文中的FPS数据都可以说是实时性的假象,实际应用时不能忽略NMS的耗时。
YOLOv8出来的时候我也在想那下一个出来的YOLO名字该叫什么呢?v9吗还是xx-YOLO,效果能终结下YOLO领域吗?
而RT-DETR我觉得是算得上一个有终结意义的代表模型,因为它的设计不再是以往基于YOLO去小修小改,而是真正发现并解决了YOLO在端到端实时检测中的最大不足--NMS。其实先前把YOLO和Transformer这两个流量方向结合着做模型的工作也有一部分,比如某个YOLO的FPN Head加几层Transformer之类的,还能做毕业设计和水个论文,其实都更像是为了加模块刷点而去改进,这种基于YOLO去小修小改,其实都没改变YOLO端到端上实时性差的本质问题,而且大都也是牺牲参数速度换点精度的做法,并不可取。
而这个RT-DETR就换了种思路基于DETR去改进,同时重点是做实时检测去推广,直接对标对象是YOLO而不是以往的轻量级的快速的DETR,将DETR去NMS的思路真正应用到实时检测领域里,我觉得是RT-DETR从思路到设计都是比较惊艳的。
至于说RT-DETR是不是真正的YOLO终结者,如果只从精度速度来看那肯定也算是了,但更出彩的是它的设计理念。正如YOLOX第一个提出AnchorFree的YOLO,思路上的突破往往更让人记住,RT-DETR正是第一个提出以DETR思路去解决甚至推翻YOLO的实时检测模型,称之为“YOLO终结者”并不为过。
不过CNN和YOLO系列以往的技术都已经发展的非常成熟了,使用模型也不止是看精度速度,根据自己的实际需求和条件去选择才是最优的,CNN和YOLO系列应该还会有较长一段生存空间,但Transformer的大一统可能也快了。
#小目标检测
本文将从小目标的定义、意义和挑战等方面入手,全面介绍小目标检测的各种解决方案。
小目标检测是计算机视觉领域中的一个极具挑战性的问题。随着深度学习和计算机视觉领域的不断发展,越来越多的应用场景需要对小目标进行准确的检测和识别。本文将从小目标的定义、意义和挑战等方面入手,全面介绍小目标检测的各种解决方案。

定义
小目标检测广义是指在图像中检测和识别尺寸较小、面积较小的目标物体。通常来说,小目标的定义取决于具体的应用场景,但一般可以认为小目标是指尺寸小于 像素的物体,如下图 COCO 数据集的定义。当然,对于不同的任务和应用,小目标的尺寸和面积要求可能会有所不同。

在 COCO 数据集中,针对三种不同大小(small,medium,large)的图片提出了测量标准,其包含大约 41% 的小目标(area<32×32), 34% 的中等目标(32×32<area<96×96), 和 24% 的大目标(area>96×96)。其中,小目标的 AP 是很难提升的!
意义
小目标检测的意义在于它可以提高技术的应用范围,同时可以帮助大家更好地理解图像中的细节信息。此外,小目标检测其实在我们日常生活中的许多领域均有广泛的应用,例如交通监控、医学影像分析、无人机航拍等。举个例子:
- 在交通监控领域,小目标检测可用于识别交通信号灯、车牌等。
- 在医学影像分析领域,小目标检测可用于识别微小的肿瘤细胞等。
- 在自动驾驶领域,小目标检测可用于识别微小的障碍物,以弥补激光雷达难以探测的窘况。
挑战
做过检测任务的同学应该很清楚这一点,那便是小目标检测其实一直是一个极具挑战性的问题。下面随便举几个小例子给大家感受下:
- 小目标通常在图像中占据很小的区域,深度学习算法其实很难提取到有效的信息,更别提传统的特征提取方法。举个例子,对于一个室内会议场景,假设我们的摄像头装在左上角的上方区域,如果此时你训练完一个检测模型应用上去,会观察到在远离镜头的对角线区域其检测效果相对其它区域来说一般会差很多的,特别容易造成漏检和误检。
- 小目标并不具备常规尺寸目标的纹理、颜色等丰富的细节特征,这使得小目标的检测更加困难,而且容易被模型误认为是“噪声点”。
- 小目标其实有时候不好定义,以最简单的行人和车辆为例,不妨看下面这张图片:

大致划分了下,其中绿色框范围的目标其实是很容易标注的,主要是红色方框范围内的目标。大部分目标像素占比很小,标也不是,不标也不是,当然你可以采用ignore标签不计算损失或者干脆直接将这块区域mask掉,但现实就是很多情况下这种“小目标”其实很大概率会被漏打标,太多的话很容易造成训练曲线“抖动”。
解决方案
今天,让我们重点来聊聊如何解决小目标检测的难题。大家应具备批判性思维,根据实际情况针对性的采取合适的方式。
需要注意的是,双阶段目标检测算法由于存在RoI Pooling之类的操作, 因此小目标的特征会被放大,其特征轮廓也更为清晰,因此检出率通常也会更高。但本文还是主要围绕发展比较成熟的单阶段目标检测算法展开。
增大输入图像分辨率
图像分辨率,当之无愧是最大的罪魁祸首,想象一下,一张图像如果分辨率太小,假设我们就下采样32倍,理论上小于这个像素的目标信息基本就会完全丢失。因此,当处理小目标检测时,由于目标物体尺寸过小,通常需要将输入图像的分辨率提高,以便更好地捕捉目标的细节。通过提升输入图像分辨率,可以提高小目标检测的准确性和召回率,从而更好地识别和跟踪目标物体。
增大模型输入尺寸
图像缩放是另一种常用的解决方案,同样可以提高小目标检测的精度。常见的做法便是直接开启“多尺度训练”,设置比较大的尺寸范围。不过,增大模型输入尺寸可能会导致模型计算量的增加和速度的降低。因此,大家在使用时需要权衡精度和效率之间的平衡。通常需要根据实际需求和可用资源进行调整,以找到最佳的模型输入尺寸。
同样地,在推理时也可以视情况开启测试时增强Test Time Augmentation, TTA,特别是打比赛的时候。
特征融合
多尺度特征融合
由于小目标的尺寸较小,其特征信息往往分布在图像的多个尺度中,因此需要在多个尺度的特征图中进行融合,以提高模型对小目标的感知能力。常见的多尺度特征融合方法包括 Feature Pyramid Networks, FPN 和 Path Aggregation Network, PAN 等。

Extended Feature Pyramid Network for Small Object Detection
长跳跃连接
长跳跃连接是指将不同层级的特征图进行融合的一种方法,可以帮助模型更好地捕捉不同层级的特征信息。众所周知,浅层特征图的细节信息丰富但语义信息较弱,深层特征图则与之相反。因此,在小目标检测中,可以将低层级的特征图和高层级的特征图进行融合,以增强对小目标的定位能力。
注意力机制
注意力机制是一种能够将模型的注意力集中到重要区域的技术,可以通过对特征图进行加权处理,将更多的注意力集中到小目标所在的区域,从而提高对小目标的检测能力。常见的注意力机制包括SENet、SKNet等。
数据增强
数据增强是在保持数据本身不变的前提下,通过对数据进行随机变换来增加数据样本的数量和多样性,从而提高模型的泛化能力和鲁棒性。对于小目标检测任务,数据增强可以通过以下几种方式来解决:
尺度变换
对于小目标而言,其尺寸往往较小,因此可以通过对原始图像进行缩放或放大的操作来增加数据样本的尺度变化。例如,可以将原始图像缩小一定比例,从而得到多个尺寸较小的图像样本。
随机裁剪
对于包含小目标的图像,在不改变目标位置的情况下,可以通过随机裁剪的方式得到多个不同的图像样本,以增加数据的多样性。此外,可以使用非矩形的裁剪方式,例如多边形裁剪,来更好地适应小目标的不规则形状。
高级组合
这一块大家伙最熟悉的可能是 YOLO 中的 Mosaic 增强,其由多张原始图像拼接而成,这样每张图像会有更大概率包含小目标。此外,我们还可以通过诸如 Copy-Paste 的办法将各类小目标充分的“复制-黏贴”,从而增加小目标的“曝光度”,提升他们被检测的概率。
大图切分
Tiling
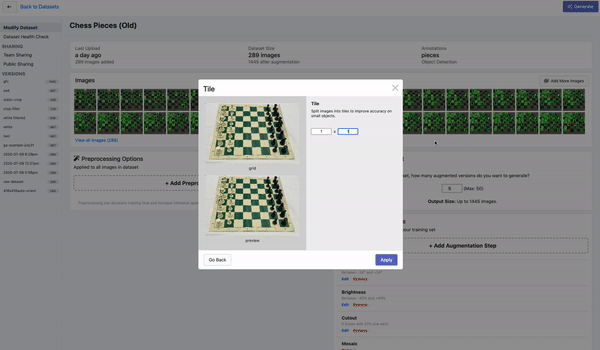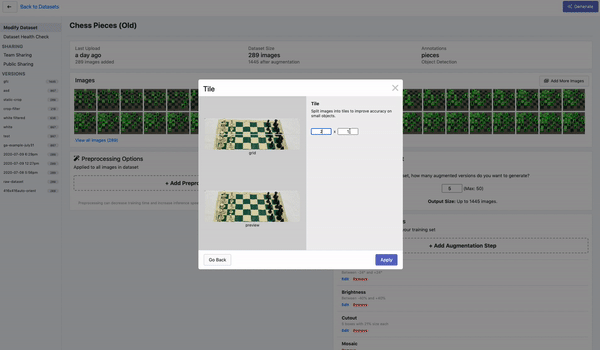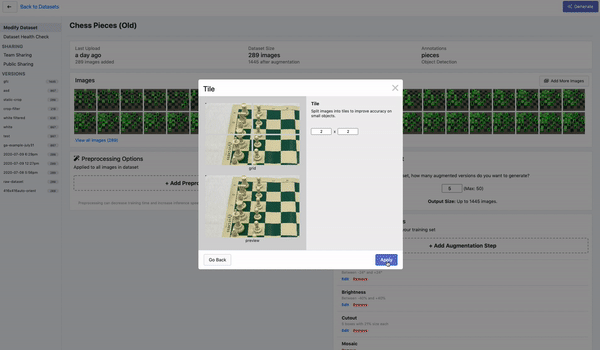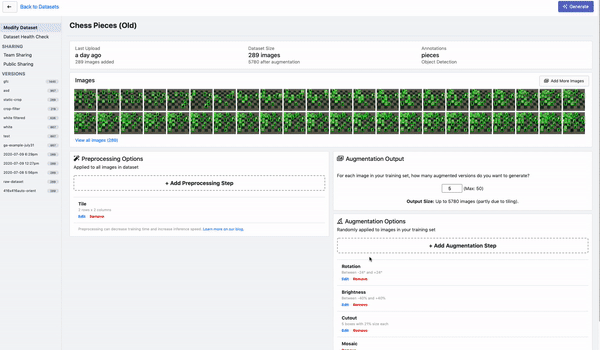
Tiling是一种对大图进行切分的有效预处理操作,上图为在Roboflow平台上的演示。通过tile可以有效地让目标检测网络更好的聚焦在小物体上,同时允许我们保持所需的小输入分辨率,以便能够运行快速推断。不过需要注意的是,在推理时也理应保持输入的一致性。
SAHI

Tiling 算是比较老旧的技术,目前笔者强烈推荐的还是Slicing Aided Hyper Inference, SAHI,即切片辅助超级推理,是一个专用于小目标检测的推理框架,理论上可以集成到任意的目标检测器上,无需进行任何微调。该方法目前已被多个成熟的目标检测框架和模型集成进去,如YOLOv5、Detectron2和MMDetection等。
损失函数
加权求和
这个非常好理解,就是我们可以自行定义小目标检测的尺寸,由于我们有 GT,因此在计算 Loss 的时候可以人为地对小目标施加更大的权重,让网络更加关注这部分。
Stitcher

Stitcher是早几年出的产物,其出自《Stitcher: Feedback-driven Data Provider for Object Detection》一文。作者通过统计分析观察到,小目标之所以检测性能很差是因为在训练时对损失的贡献很小(要么漏检要么漏标)。因此,文章中提出了一种基于训练时动态反馈的机制,即根据计算出来的损失,自动决定是否要进行图像拼接的操作。
其它
下面简单整理一些有代表性的小目标检测文章。
2023
- TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors

- YOLO-Drone: Airborne real-time detection of dense small targets from high-altitude perspective

2022
- Towards Large-Scale Small Object Detection: Survey and Benchmarks

2020
- Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network
2019
- Augmentation for small object detection
#NVDS+
更快更强更通用的视频深度估计框架
本文提出了NVDS+框架,这是一个用于视频深度估计的快速、强大且通用的扩展版本,包括一个即插即用的视频深度框架、一个新的大规模视频深度数据集VDW,以及一个完整的模型家族,从轻量级的NVDS-Small到性能更优的NVDS-Large模型。
本文介绍我们发表在顶级期刊IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 的论文《NVDS+: Towards Efficient and Versatile Neural Stabilizer for Video Depth Estimation》。NVDS+以我们发表在ICCV 2023的 NVDS为基础,做了进一步的创新与改进,形成了扩展版本的NVDS+,并已经被IEEE TPAMI 2024接收。本文主要介绍在ICCV 2023 NVDS的基础上,期刊版本的NVDS+包含的扩展内容。
论文:https://arxiv.org/pdf/2307.08695
代码:github.com/RaymondWang987/NVDS
视频:
https://www.bilibili.com/video/BV1WhxdenEga/?vd_source=806e94b96ef6755e55a2da
贡献总结
文章的主要贡献包括:(1) 针对任意单图深度预测模型,即插即用的视频深度框架NVDS+;(2) 为训练更鲁棒的视频深度模型,提出了当前该领域最大的视频深度数据集VDW,包含超过200万的视频帧;(3) 构建了完整的model family,从轻量化的可实时预测的NVDS-Small模型,到性能最优的NVDS-Large模型;(4) 在视频语义分割等其他任务上,也实现了SOTA的空间精度和时域稳定性,并在点云重建、视频散景、新视图生成等下游任务上,证明了算法的通用性和应用价值;(5) 设计了flow-guided consistency fusion策略,改进了NVDS中简单的双向预测模式,进一步提升预测结果的稳定性和一致性。
如Fig. 1所示,无论是NVDS+的Small或Large版本,我们相比于前序方法均实现了最优的效率和性能。其中Small版本能够实现超过30fps的实时处理,flow-guided consistency fusion相比于ICCV版本的简单双向预测能进一步提升一致性。我们的方法也适用于视频语义分割等稠密预测任务,在单图预测结果的基础上,即插即用地产生稳定的视频结果。

1 轻量化实时小模型和model family
针对不同类型的下游应用,为了平衡推理效率和模型性能,我们提供了一个综合完整的NVDS+ model family,模型体量从小到大。具体来讲,NVDS+ 的应用范式可以分为两方面。第一,为了追求空间精度和时间一致性的最佳性能,我们的Large模型可以采用各种高精度的单图深度大模型作为Depth Predictor。另一方面,为了满足实时处理和应用的需求,NVDS-Small可以与不同的轻量级单图深度预测器协同工作。
为了实现轻量的Small model,我们采用了基于注意力的轻量主干网络Mit-b0来编码深度感知特征。同时,小模型的注意力层数和特征嵌入维度均被缩减。此外,我们还应用了最新的模型剪枝策略以进一步提高效率。如实验结果所示,我们的小模型实现了超过 30 fps的处理速度 (Table 7),并在性能上也显著超越了已有的轻量深度模型 (Table 7 & Fig. 9)。


2 视频稠密预测中的通用性
作为稠密预测中的两个典型任务,深度预测和语义分割对于自动驾驶和虚拟现实等下游应用都至关重要。为了证明 NVDS+框架在视频稠密预测中的通用性,我们将NVDS+扩展至视频语义分割。与视频深度相似,视频语义分割旨在为视频帧预测准确且一致的语义标签。自然而然地,我们可以使用不同的单图语义分割模型作为Semantic Segmenter来产生初始单图预测。然后,通过即插即用的范式,NVDS+可以去除抖动并提高一致性。我们的 NVDS+在 CityScapes数据集上达到了视频语义分割任务的SOTA性能,超越了前序独立的视频语义分割模型,进一步证明了NVDS+框架的通用性和有效性。
具体来讲,在一个滑动窗口内,RGB 帧与Semantic Segmenter的单通道标签预测Q 拼接在一起,作为我们Stabilization network的输入。归一化操作被省略,因为不同分割器的标签预测 Q 具有统一的数据范围和格式。网络的输出则被调整为C 个通道,表征各个语义类别的概率。我们使用了常规的的语义解码器结构来输出结果,并使用交叉熵损失进行监督。NVDS+使用单通道的标签预测Q而非概率预测P作为初始输入,这主要有两个原因。首先,P的通道数C 等于语义类别的数量,而在实际中这个数量可能很大,将 P 作为多帧输入会显著增加计算代价。此外,不同数据集和场景中的通道数C也有所不同,输入通道的变化会限制模型设计的统一性。
最终,分割部分的实验结果如下所示,NVDS+在视频语义分割任务上也实现了SOTA的精度和一致性 (Table 8 & Fig. 10),并且也能够即插即用地适配不同的单图分割模型 (Table 9),例如SegFormer和OneFormer等。


3 基于光流引导的一致性融合
ICCV23当中NVDS的双向推理策略可以基于前向和后向预测增强时间一致性,其采用的直接平均是一种简单而有效的方法,本质上是使用固定权重将前向和后向深度融合,这扩大了时间感受野范围,并且不会引入过多的计算成本。然而,与直接平均相比,使用自适应权重来融合参考帧和目标帧的双向结果更为合理,因为相对于目标帧,存在较大运动幅度的帧或像素可能与最终的目标深度相关性较低。
为此,我们改进了双向推理,提出了一种基于光流引导的一致性融合策略,该策略能够自适应地融合来自参考帧和目标帧的双向深度结果。如Fig. 3所示,我们利用光流来表征参考帧和目标帧之间像素级的运动幅度和相关性图。双向光流在参考帧和目标帧之间计算。运动幅度则可以通过光流的幅度 (即 Frobenius 范数)来估计。参考帧中运动较大的像素与目标帧中对应像素的相关性通常更低。为了量化这一点,我们逐像素地计算自适应的相关性图和权重矩阵 (Fig. 4),用来自适应地融合多帧双向的深度预测结果。


Table 5的实验结果也表明,相比于简单的双向预测,光流引导的一致性融合策略能够进一步提升模型输出结果的时域一致性和稳定性。

整体实验结果与下游应用
整体来讲,如Table 2所示,NVDS+在多个数据集上均实现了SOTA的性能,并且能够促进多种下游应用的效果。

如Fig. 12和Fig. 14所示,我们将NVDS+的深度结果应用于三维重建、视频散景渲染、三维视频合成、时空新视图生成等下游任务,均能够取得令人满意的效果。以三维点云重建为例,相比于之前的Robust-CVD,NVDS+产生的深度图能够恢复出更完整的物体结构和更正确的几何关系,这些结果都证明了我们方法的应用价值。


#异构预训练Transformer颠覆本体视觉学习范式
通用机器人模型,如何解决异构性难题?来自MIT、Meta FAIR团队全新提出异构预训练Transformer(HPT),不用从头训练,即可破解。
通用机器人模型,目前最大的障碍便是「异构性」。
也就是说,必须收集全方位——每个机器人、任务和环境的特定数据,而且学习后的策略还不能泛化到这些特定设置之外。
由此,AI大神何恺明带队的MIT、Meta FAIR团队,提出了异构预训练Transformer(HPT)模型。
即预训练一个大型、可共享的神经网络主干,就能学习与任务和机器人形态无关的共享表示。
简单讲,就是在你的策略模型中间放置一个可扩展的Transformer,不用从头开始训练!
论文地址:https://arxiv.org/pdf/2409.20537
研究人员将不同本体视觉输入对齐到统一的token序列,再处理这些token以控制不同任务的机器人。
最后发现,HPT优于多个基准模型,并在模拟器基准和真实世界环境中,将未见任务微调策略性能,提升20%。
值得一提的是,这项研究被NeurIPS 2024接收为Spotlight。
在真实环境中,HPT加持下的机器人本体,能够自主向柴犬投食。

而且, 即便是洒了一地狗粮,机器人也能用抹布,将其收到一起。
而在模拟环境中,HPT架构让机器人任务操作,更加精准。
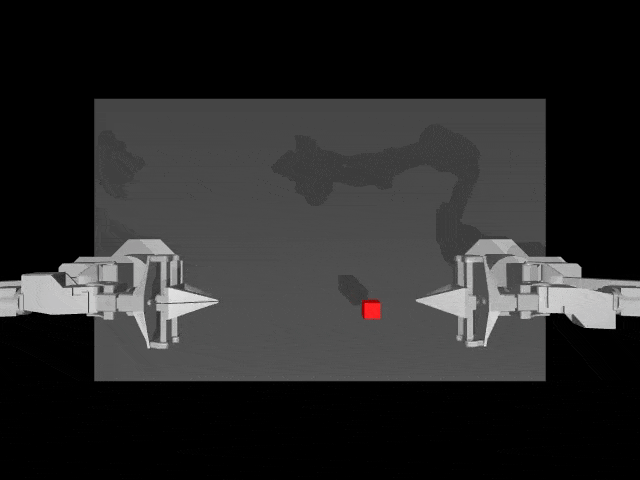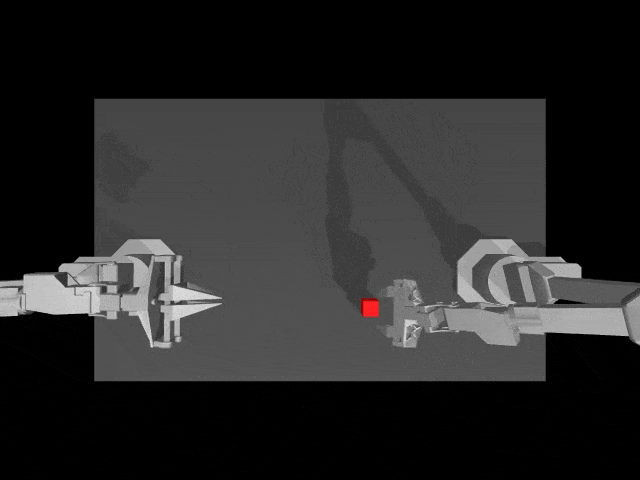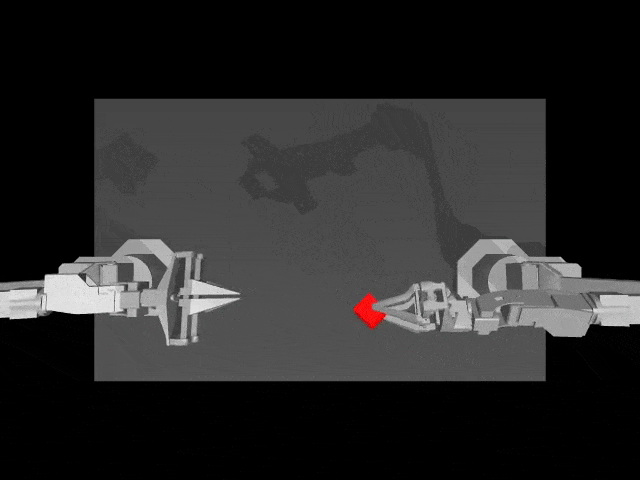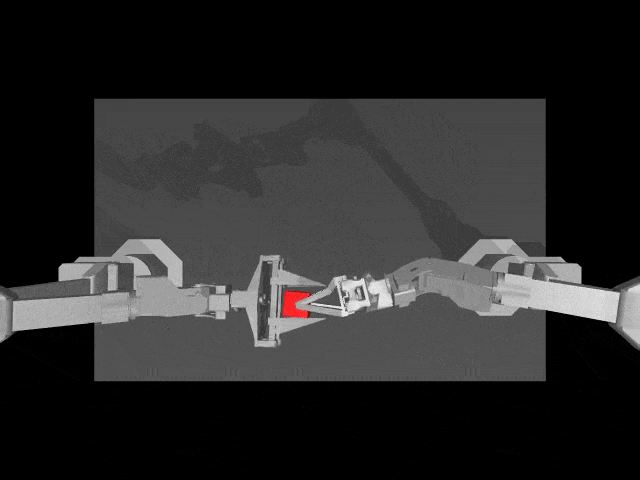
接下来,一起深度了解下异构预训练Transformer(HPT)模型的核心要素吧。
搭建「异构性」桥梁
如今,构建特定的机器人策略很困难,其中最大的难题就是数据收集和缺少泛化性。
不同硬件的机器人在物理上具有不同的本体(embodiment),每种实例可以有不同的「本体感觉」(proprioception),包括不同的自由度、末端执行器、运动控制器和为特定应用构建的工作空间配置。
此外,另一种常见的异构性就是视觉异构性。
不同机器人搭载了不同的视觉传感器,而且通常配备在不同位置(比如手腕/第三视角);每个机器人的外观也会因环境和任务而有很大差异。
正是由于这些难以跨越的异构性障碍,因此通常需要收集每个机器人、任务和环境的特定数据,并且学习到的策略不能泛化到这些特定设置之外。
虽然机器人领域已经积累了海量的开源数据,但异构性让数据集很难被共同利用。
从图4中就可以看出,仅仅是按环境分类,机器人领域的数据就能被「瓜分」为远程遥控、模拟、野外、人类视频等接近4等份。
机器人领域数据集的异质性
近些年来NLP和CV领域的突飞猛进,让我们看到了彻底改变机器学习领域的一个历史教训:对大规模、高质量和多样化数据进行预训练,可以带来通常优于特定模型的通用模型。
话至此处,当今机器人领域的一个中心问题浮出水面:如何利用异构数据来预训练机器人基础模型?
除了更多数据带来的好处之外,不同任务的训练还可以增强表示(representation)的通用性。
这类基础模型将会在各种任务上实现高成功率、对异常值更加稳健,并且能够灵活地适应新任务。
那么,到底应该如何充分利用异构化的数据集?
如图1所示,一个基本的思路是,将来自不同领域和任务的输入信号映射到高维表示空间,并让它们表现出一致的缩放行为。
之后,只需要最少的微调,就可以将得到的高维表示迁移到特定的下游任务,同时获得良好的性能。
HPT概念示意图
HPT所要做的,就是找到一种共享的策略「语言」,能够对齐来自不同预训练的异质的本体感觉和视觉信息,将自己的信号映射到共享的潜在空间。
HPT模型架构
HPT全称为Heterogeneous Pre-trained Transformers,是一个架构系列,采用了模块化的设计思路,从异构本体的数据中进行可扩展学习。
受到多模态数据学习的启发,HPT使用了特定于本体的分词器(stem)来对齐各种传感器输入,映射为固定数量的token,之后送入Transformer结构的共享主干(trunk),将token映射为共享表示并进行预训练。
在对每种本体的输入进行标记化(tokenize)之后,HPT就运行在一个包含潜在token短序列的共享空间上运行。
论文提到,这种层次结构的动机,也是来源于人类身体的脊髓神经回路层面中,特定运动反应和感知刺激之间的反馈循环。
预训练完成后,使用特定于任务的动作解码器(head)来产生下游动作输出,但所用的实例和任务在预训练期间都是未知的。
预训练包含了超过50个单独的数据源,模型参数超过1B,模型的代码和权重都已公开发布。
HPT架构
stem结构
从上面的描述来看,要解决异构性问题,最直接和最关键的就是如何训练stem,将来自异构的本体和模态的传感器输入对齐到共享表示空间中。
如图3所示,stem包含两个主要部分,即本体感受分词器和视觉分词器,将来自不同本体的异构输入映射为固定维度、固定数量的token,让trunk能够以相同的方式处理。
其中的关键思想,是利用cross-attention机制,让固定数量的可学习token关注到各种特征。
虽然这篇论文主要处理本体感觉和视觉,但处理触觉、3D和动作输入等其他类型的异构传感器信号也可以在stem中灵活扩展。
HPT中的stem架构
按照时间顺序单独处理每个模态后,将所有token拼接在一起并添加额外的模态嵌入和正弦位置嵌入,就得到了trunk的输入序列。
为了避免过拟合,stem被设计为仅有少量参数,只包含一个MLP和一个注意力层。
trunk结构
作为预训练的核心组件,trunk是一个有潜在d维空间的Transormer结构,参数量固定,在不同的本体和任务之间共享,以捕获复杂的输入-输出关系。
预训练
给定从不同分布中采样的异构本体的数据集𝒟_1,…,𝒟_k,…,𝒟_K ,令𝒟_k={τ^(i)}_{1≤i≤M_k} 表示𝒟_k中一组轨迹M_k,τ^(i)={o_t^(i), a_t^(i)}_{1≤t≤T}表示第i个最大长度为T的轨迹,每个元组包含observation变量和action变量。
训练目标如公式(1)所示,需要最小化数据集中的以下损失:

其中ℒ是行为克隆损失,计算为预测结果和真实标签之间的Huber 损失。
该训练过程有两个数据缩放轴:单个数据集D_k的体量M_k,以及数据集总数K。
在预训练阶段,每次迭代时仅更新trunk部分参数,并且基于训练批次采样更新特定于每个异构本体和任务的stem和head部分。
论文进行了一系列预训练实验,包括不同规模的网络参数和数据集大小,旨在回答一个问题:HPT预训练在跨域异构数据中是否展现出了扩展能力?
总体而言,某种程度上,HPT随着数据集数量、数据多样性、模型体量和训练计算量呈现出缩放行为。
HPT网络详细信息,宽度表述turnk transformer的潜在维度,深度表示block数量,默认设置为HPT-Small型号
预训练数据集详细信息,默认使用来自RT-X的27个数据集的16k个轨迹进行训练
数据缩放
数据方面,如图5所示,即使在异构程度逐渐增大的本体中也具有稳定且可扩展的验证损失。
此外,作者还发现,计算量(相当于每次训练运行看到的样本量)和数据量需要共同扩展,才能在训练过程中更接近收敛。
epoch缩放
如图6所示,增加批大小(左)相当于有效地扩展训练token数(右),通常可以提高模型性能,直至最后收敛。
另一个观察结果是,使用分布式方法,在每个训练批中聚合尽可能更多的数据集,用更大的批大小来弥补异构训练中的较大方差。
模型缩放
如图7所示,固定数据集和轨迹数量,沿着模型大小(从1M到1B)进行缩放,并逐渐将批大小从256增加到 2048(模型大小每增加一倍),并使用具有170k轨迹的更大数据集。
可以观察到,当我们扩展到具有更大计算量(红线)的更大模型时,预训练可以实现较低的验证损失,直到达到稳定水平,但没有发现缩放模型深度和模型宽度之间存在显著差异。
图8中的实验结果表明,HPT可以相当有效地处理异构数据。尽管与真实机器人存在很大的差距,但对其他本体的数据集(例如模拟环境和人类视频数据集)进行预训练是可能的。
迁移学习
如上,作者使用了最后一次迭代中验证集上的损失来评估预训练。
接下来,他们将通过实验,去验证机器人在迁移学习中,任务成功率的问题:
预训练的HPT模型,是否可以迁移到模拟和现实世界中的全新本体、任务、以及环境中?
模拟环境
如下图10(a)中,研究人员在闭环模拟中测试了下游任务的模型,并观察到使用HPT-B到HPTXL预训练模型,提到的任务成功率。
在图10(b)中,他们在最近发布的Simpler基准上运行HPT,它允许在高保真模拟上与Octo、RT1-X、RT2-X进行比较。
在Google EDR机器人中,研究人员重点关注三个不同的任务「关闭抽屉」、「选可乐罐」。
对于每个任务,他们测试了几种不同的初始化,所有任务总共有300+ episode。
现实世界
这里,作者采用了与前一节类似的迁移学习方法,并在真实世界的评估协议下,评估预训练的HPT表示。
他们以256批大小和$5 e^{-6}$训练率训练策略20000次迭代。
图12显示的定量结果,研究人员观察到,预训练策略相比No-Trunk和From-Scratch基准获得了更好的成功率。
特别是在倒水的任务中,From-Scratch基准使用了最先进的扩散策略架构,以展示预训练表示的灵活性。
图11定性结果显示,作者观察到预训练的HPT在面对不同姿势、物体数量、相机配置、光照条件时,表现出更好的泛化能力和鲁棒性。
在表3中,作者对Sweep Leftover任务进行了消融研究。
尽管最近数据规模激增,但由于异构性的存在,机器人学习的通用性仍然受到限制。
研究人员提出的HPT——一种模块化架构和框架,通过预训练来应对这种异构性。
他希望这一观点能够启发未来的工作,以处理机器人数据的异构性本质,从而为机器人基础模型铺平道路。
参考资料:
https://liruiw.github.io/hpt/
https://x.com/LiruiWang1/status/1841098699436351742
#Reinforcement Finetuning,ReFT
图像领域再次与LLM一拍即合!idea撞车OpenAI强化微调,西湖大学发布图像链CoT
MAPLE实验室提出通过强化学习优化图像生成模型的去噪过程,使其能以更少的步骤生成高质量图像,在多个图像生成模型上实现了减少推理步骤,还能提高图像质量。
OpenAI最近推出了在大语言模型LLM上的强化微调(Reinforcement Finetuning,ReFT),能够让模型利用CoT进行多步推理之后,通过强化学习让最终输出符合人类偏好。
无独有偶,齐国君教授领导的MAPLE实验室在OpenAI发布会一周前公布的工作中也发现了图像生成领域的主打方法扩散模型和流模型中也存在类似的过程:模型从高斯噪声开始的多步去噪过程也类似一个思维链,逐步「思考」怎样生成一张高质量图像,是一种图像生成领域的「图像链CoT」。与OpenAI不谋而和的是,机器学习与感知(MAPLE)实验室认为强化学习微调方法同样可以用于优化多步去噪的图像生成过程,论文指出利用与人类奖励对齐的强化学习监督训练,能够让扩散模型和流匹配模型自适应地调整推理过程中噪声强度,用更少的步数生成高质量图像内容。
论文地址:https://arxiv.org/abs/2412.01243
研究背景
扩散和流匹配模型是当前主流的图像生成模型,从标准高斯分布中采样的噪声逐步变换为一张高质量图像。在训练时,这些模型会单独监督每一个去噪步骤,使其具备能恢复原始图像的能力;而在实际推理时,模型则会事先指定若干个不同的扩散时间,然后在这些时间上依次执行多步去噪过程。
这一过程存在两个问题:
- 经典的扩散模型训练方法只能保证每一步去噪能尽可能恢复出原始图像,不能保证整个去噪过程得到的图像符合人类的偏好;
- 经典的扩散模型所有的图片都采用了同样的去噪策略和步数;而显然不同复杂度的图像对于人类来说生成难度是不一样的。
如下图所示,当输入不同长度的prompt的时候,对应的生成任务难度自然有所区别。那些仅包含简单的单个主体前景的图像较为简单,只需要少量几步就能生成不错的效果,而带有精细细节的图像则需要更多步数,即经过强化微调训练后的图像生成模型就能自适应地推理模型去噪过程,用尽可能少的步数生成更高质量的图像。
值得注意的是,类似于LLM对思维链进行的动态优化,对扩散模型时间进行优化的时候也需要动态地进行,而非仅仅依据输入的prompt;换言之,优化过程需要根据推理过程生成的「图像链」来动态一步步预测图像链下一步的最优去噪时间,从而保证图像的生成质量满足reward指标。
方法
MAPLE实验室认为,要想让模型在推理时用更少的步数生成更高质量的图像结果,需要用强化微调技术对多步去噪过程进行整体监督训练。既然图像生成过程同样也类似于LLM中的CoT:模型通过中间的去噪步骤「思考」生成图像的内容,并在最后一个去噪步骤给出高质量的结果,也可以通过利用奖励模型评价整个过程生成的图像质量,通过强化微调使模型的输出更符合人类偏好。
OpenAI的O1通过在输出最终结果之前生成额外的token让LLM能进行额外的思考和推理,模型所需要做的最基本的决策是生成下一个token;而扩散和流匹配模型的「思考」过程则是在生成最终图像前,在不同噪声强度对应的扩散时间(diffusion time)执行多个额外的去噪步骤。为此,模型需要知道额外的「思考」步骤应该在反向扩散过程推进到哪一个diffusion time的时候进行。
为了实现这一目的,在网络中引入了一个即插即用的时间预测模块(Time Prediction Module, TPM)。这一模块会预测在当前这一个去噪步骤执行完毕之后,模型应当在哪一个diffusion time下进行下一步去噪。
具体而言,该模块会同时取出去噪网络第一层和最后一层的图像特征,预测下一个去噪步骤时的噪声强度会下降多少。模型的输出策略是一个参数化的beta分布。
由于单峰的Beta分布要求α>1且β>1,研究人员对输出进行了重参数化,使其预测两个实数a和b,并通过如下公式确定对应的Beta分布,并采样下一步的扩散时间。
在强化微调的训练过程中,模型会在每一步按输出的Beta分布随机采样下一个扩散时间,并在对应时间执行下一个去噪步骤。直到扩散时间非常接近0时,可以认为此时模型已经可以近乎得到了干净图像,便终止去噪过程并输出最终图像结果。
通过上述过程,即可采样到用于强化微调训练的一个决策轨迹样本。而在推理过程中,模型会在每一个去噪步骤输出的Beta分布中直接采样众数作为下一步对应的扩散时间,以确保一个确定性的推理策略。
设计奖励函数时,为了鼓励模型用更少的步数生成高质量图像,在奖励中综合考虑了生成图像质量和去噪步数这两个因素,研究人员选用了与人类偏好对齐的图像评分模型ImageReward(IR)用以评价图像质量,并将这一奖励随步数衰减至之前的去噪结果,并取平均作为整个去噪过程的奖励。这样,生成所用的步数越多,最终奖励就越低。模型会在保持图像质量的前提下,尽可能地减少生成步数。
将整个多步去噪过程当作一个动作进行整体优化,并采用了无需值模型的强化学习优化算法RLOO [1]更新TPM模块参数,训练损失如下所示:
在这一公式中,s代表强化学习中的状态,在扩散模型的强化微调中是输入的文本提词和初始噪声;y代表决策动作,也即模型采样的扩散时间;
代表决策器,即网络中A是由奖励归一化之后的优势函数,采用LEAVE-One-Out策略,基于一个Batch内的样本间奖励的差值计算优势函数。
通过强化微调训练,模型能根据输入图像自适应地调节扩散时间的衰减速度,在面对不同的生成任务时推理不同数量的去噪步数。对于简单的生成任务(较短的文本提词、生成图像物体少),推理过程能够很快生成高质量的图像,噪声强度衰减较快,模型只需要思考较少的额外步数,就能得到满意的结果;对于复杂的生成任务(长文本提词,图像结构复杂)则需要在扩散时间上密集地进行多步思考,用一个较长的图像链COT来生成符合用户要求的图片。
通过调节不同的γ值,模型能在图像生成质量和去噪推理的步数之间取得更好的平衡,仅需要更少的平均步数就能达到与原模型相同的性能。
同时,强化微调的训练效率也十分惊人。正如OpenAI最少仅仅用几十个例子就能让LLM学会在自定义领域中推理一样,强化微调图像生成模型对数据的需求也很少。不需要真实图像,只需要文本提词就可以训练,利用不到10,000条文本提词就能取得不错的明显的模型提升。
经强化微调后,模型的图像生成质量也比原模型提高了很多。可以看出,在仅仅用了原模型一半生成步数的情况下,无论是图C中的笔记本键盘,图D中的球棒还是图F中的遥控器,该模型生成的结果都比原模型更加自然。
针对Stable Diffusion 3、Flux-dev等一系列最先进的开源图像生成模型进行了强化微调训练,发现训练后的模型普遍能减少平均约50%的模型推理步数,而图像质量评价指标总体保持不变,这说明对于图像生成模型而言,强化微调训练是一种通用的后训练(Post Training)方法。
结论
这篇报告介绍了由MAPLE实验室提出的,一种扩散和流匹配模型的强化微调方法。该方法将多步去噪的图像生成过程看作图像生成领域的COT过程,通过将整个去噪过程的最终输出与人类偏好对齐,实现了用更少的推理步数生成更高质量图像。
在多个开源图像生成模型上的实验结果表明,这种强化微调方法能在保持图像质量的同时显著减少约50%推理步数,微调后模型生成的图像在视觉效果上也更加自然。可以看出,强化微调技术在图像生成模型中仍有进一步应用和提升的潜力,值得进一步挖掘。
参考资料:
https://arxiv.org/abs/2412.01243
#HunyuanVideo
一键部署腾讯混元超牛视频生成器【HunyuanVideo】,130亿参数铸就极致体验
HunyuanVideo作为腾讯混元大模型在视频生成方向的重要成果,展现出了强大的技术实力。它拥有高达130亿的参数量,以文生视频为核心功能,当前生成视频的分辨率为1080p。不仅如此,其发展规划十分宏大,后续计划推出8k/4k分辨率版本,并且在功能拓展上也有着明确的方向,即将实现图生视频、视频自动配乐等功能,旨在为用户提供更加丰富、高质量的视频生成体验。
- github:https://github.com/Tencent/HunyuanVideo
应用场景
- 创意内容创作:HunyuanVideo是创作者的得力助手,能快速将灵感转化为视频。
- 广告与营销:为企业提供新推广方式。企业依产品和目标输入提示,能快速生成高质量广告视频。
- 教育与培训:将抽象知识以视频呈现,增强教学效果。
- 虚拟现实与增强现实:是VR和AR应用的内容基石。
- 社交媒体与个人娱乐:开启创意分享新潮流。
HunyuanVideo模型已经在趋动云『社区项目』上线,无需自己创建环境、下载模型,一键即可快速部署,快来体验HunyuanVideo带来的精彩体验吧!
- 项目入口1:https://open.virtaicloud.com/web/project/detail/519920263119269888
- 项目入口2:https://open.virtaicloud.com/web/project/detail/520193589964206080
视频教程:
,时长04:58
启动开发环境
进入HunyuanVideo项目主页中,点击运行一下,将项目一键克隆至工作空间,『社区项目』推荐适用的算力规格,可以直接立即运行,省去个人下载数据、模型和计算算力的大量准备时间。

配置完成,点击进入开发环境,根据主页项目介绍进行部署。

使用方法
WebUI界面操作:找到使用说明.ipynb,选中WebUI界面操作单元格,点击运行,等待生成local URL,右侧添加端口7860,浏览器访问外部访问链接

WebUI界面

效果展示
效果展示一:官方效果
,时长01:23
效果展示二:A cat walks on the grass, realistic style.
,时长00:05
➫温馨提示: 完成项目后,记得及时关闭开发环境,以免继续产生费用!

#基于深度学习的轮胎缺陷检测
本文主要介绍一个基于深度学习轮胎缺陷检测系统方案。
背景介绍
由于全球制造业面临着在最短的时间内向市场推出多种最高质量产品的压力,因此所有职能向人工智能驱动的自动化的转变已成为必然。
在质量检测方面,人工智能驱动的计算机视觉系统已经能够简化生产流程,使产品符合公司制定的质量标准。这反过来又带来了更高效率、更低运营成本的优势,同时实现 24/7 生产和更快的决策。
全球轮胎制造商一直是质量保证等各个领域人工智能技术的早期采用者之一。人工智能的主要应用之一是使用基于深度学习的计算机视觉系统进行轮胎缺陷检测。由于轮胎制造过程中使用的原材料的性质,轮胎部件可能会受到金属或非金属杂质(例如钢丝、螺钉和塑料碎片)、气泡和重叠的污染。当轮胎有缺陷的车辆高速行驶时,这些缺陷会导致轮胎寿命缩短,甚至爆胎。

轮胎缺陷检测
要准确检测轮胎缺陷,需要解决的主要问题是:
- 模仿手动测试并集成到现有的制造和质量控制流程中
- 具有机械夹具,可自动调整以适应操作员放置的不同轮胎尺寸,并旋转,以便在一次旋转中捕获轮胎的内壁和外壁。
- 以最佳旋转速度捕获图像、处理、分析和检测故障。
- 在每个故障位置停车并在轮胎上标记缺陷
- 轻松安全地释放轮胎
轮胎缺陷类型
在轮胎制造过程中常见的 80 多种可能存在的缺陷中,我们会进行隔离以创建严重程度集合。各个轮胎制造商根据其独特的化学配方和机械制造工艺,有自己特定的分类方法。通常,大约 30 多个此类类别被认为是高度严重的。下图描述了这些缺陷类别的有限样本:

图 1:有缺陷的轮胎:从左到右:SWC — 侧壁裂纹、RLC — 轮辋线裂纹、SWB — 侧壁气泡、模板编号偏移、倒角缺陷图 1:有缺陷的轮胎:从左到右:SWC — 侧壁裂纹、RLC — 轮辋线裂纹、SWB — 侧壁气泡、模板编号偏移、倒角缺陷
轮胎缺陷检测
轮胎质量检查的典型方法是使用 X 射线机并使用加权纹理差异等技术。然而,X 光机需要很大的空间并且非常昂贵。相反,我们使用 RGB 相机来捕捉轮胎的图像。为了解决轮胎缺陷检测问题,选择了实例分割(对象检测和分割的结合),以便可以识别图像中每个缺陷的每个实例,而不是像语义分割那样对每个像素进行分类。
数据生成
为了生成数据,使用了从已识别和标记缺陷的多个轮胎捕获的图像。使用 1080p 分辨率的摄像头来拍摄有缺陷的图像和“良好”图像的视频。从不同角度进行图像捕捉以提高概括性。
数据准备
数据准备是在处理和分析之前清理和转换原始数据的过程。这是处理之前的重要步骤,通常涉及标记数据、重新格式化数据和对数据进行更正。数据是通过从几个生成的视频中转储帧来收集的。然后使用LabelMe等标记工具标记感兴趣区域 (ROI) 内的缺陷部分。
实例分割
实例分割是一种检测对象然后在单个像素级别进行屏蔽的技术。它结合了 1) 对象检测,其中对帧中的每个单独对象进行分类和定位,以及 2. 语义分割,其中将每个像素分为预定义的类别。实例分割允许将标签附加到图像的每个像素。
Mask-RCNNMask-RCNN
Mask-RCNN 是一种深度神经网络,用于解决计算机视觉中的实例分割问题。Mask R-CNN 结合了两种著名的网络拓扑——Faster R-CNN 和全连接网络 (FCN)。Mask-RCNN 遵循两步过程。第一步,对于每个输入图像,生成有关对象可能存在的区域的建议。在第二步中,预测对象的类别,并根据第一步生成的建议为对象生成像素级掩模。
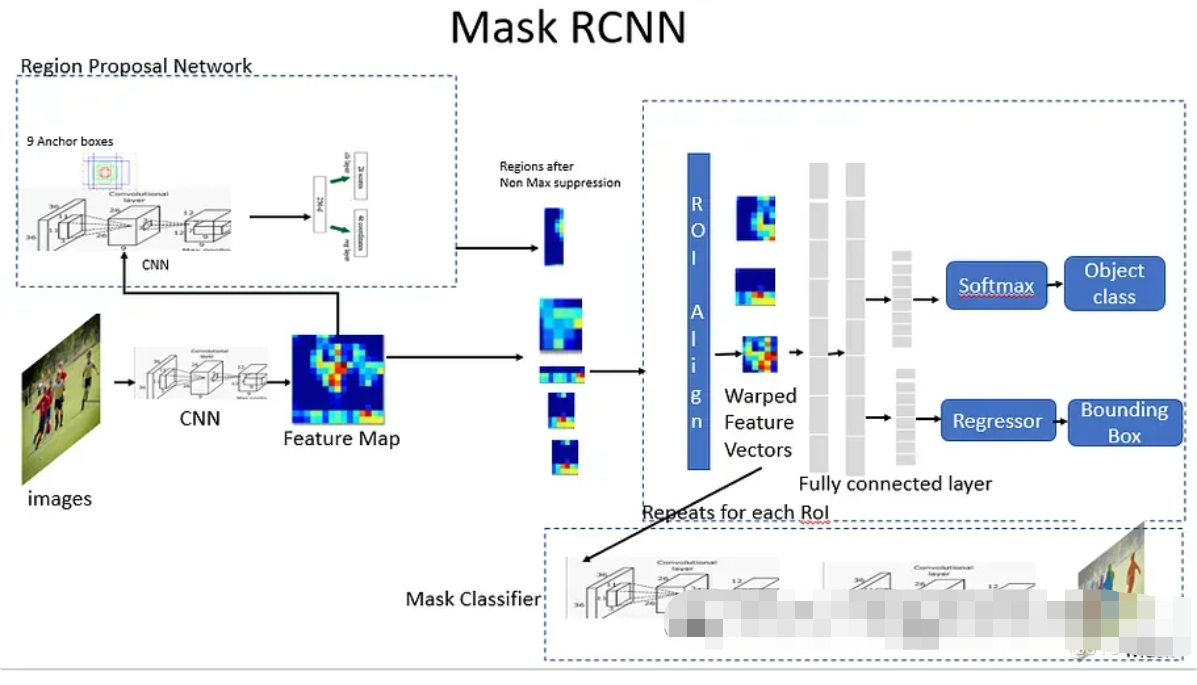
执行
我们使用 Mask-RCNN 的定制变体构建推理管道。基本的 Keras 实现可以在https://github.com/matterport/Mask_RCNN.git找到,相应的参考论文可以在https://arxiv.org/pdf/1703.06870.pdf找到
推理时间
未优化模型的推理时间如下表所示。

通过模型优化技术,每张图像的延迟可降低至 150 毫秒以下。
准确性
我们的定制模型能够实现 96% 的检测准确率。
结论
这项检测轮胎缺陷的研发工作表明,实现轮胎质量检测过程的显着自动化是可能的。在实际系统中,如果需要高检测吞吐量,则需要自动检测夹具。这将包括多个摄像头,用于同时查看轮胎的外表面和内表面,一个用于将轮胎旋转 360 度的电机组件,以及一个可以同步轮胎运动、图像捕获和检测的控制系统。
#使用 MobileNe 迁移学习识别手语
迁移学习是一种技术,您可以采用现有模型(已经在大型数据集上训练的模型)对其进行微调以解决新问题。当您的数据集较小且您的输入与原始模型训练所依据的输入相似时,它特别有用。您不是从头开始训练新模型,而是在已经了解基础知识的基础上进行构建。
例如,假设您要构建一个老虎识别模型,并且您已经有一个猫/狗分类器。该模型已经学会了识别耳朵、毛皮、腿、尾巴等低级特征。您只需修改一些内容并重新调整其用途以识别老虎,从而节省时间和资源。
就我而言,我想从事一个识别美国手语 (ASL) 的小项目。ASL 是一种视觉语言,这使其非常适合计算机视觉。凭借清晰的手势和大量现实世界的潜力,它在技术上是可行的,在社会上也是有意义的。
我使用了手势 |来自 Kaggle 的 ASL 手语数据。在这篇文章中,我将向您介绍我如何微调预先训练的 MobileNet 模型,以使用图像数据识别 ASL 字母。
https://www.kaggle.com/datasets/jeyasrisenthil/hand-signs-asl-hand-sign-data我将介绍数据集加载、预处理、模型设置、训练过程和结果。
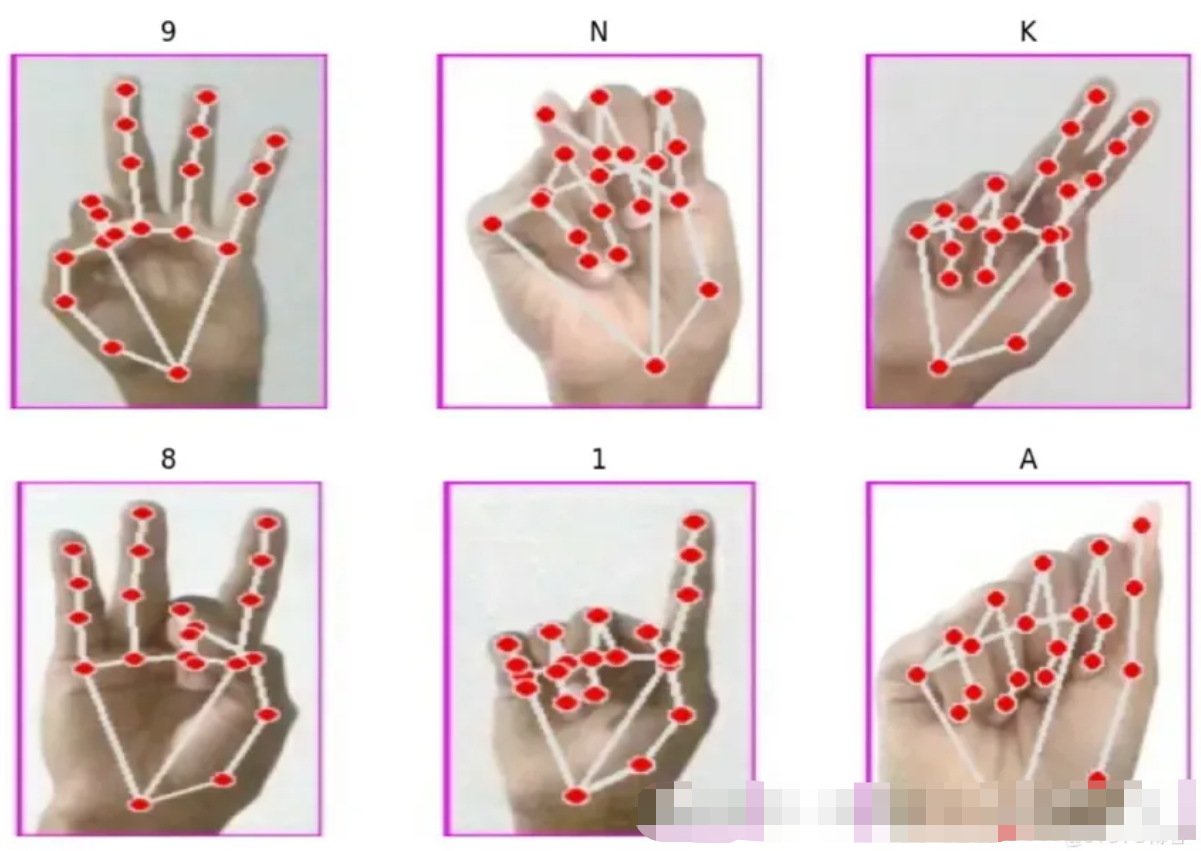
数据集
以下是数据集中的示例。每个图像都表示对应于 ASL 字母或数字的手势。该数据集总共包括 36 个类:26 个字母 (A-Z) 和 10 位数字 (0-9)。
数据加载和预处理
我们将首先使用 TensorFlow 的内置函数image_dataset_from_directory,直接从目录结构加载数据集。
在深度学习中,通常将数据集划分为较小的组,称为小批量。这使得训练更高效,并减少了计算开销。在本例中,我们将使用 a of 32,这意味着每个小批量包含 32 张图像。BATCH_SIZE
我们正在处理 36 个类 — 字母表中的 26 个字母 (A-Z) 和数字 (0-9)。我选择将每张图像的大小调整为 160x160 像素。您可以根据 GPU 可用性选择更高的分辨率。
使用机器学习模型时,评估模型在处理以前未见过的数据时的性能非常重要。这就是为什么我们将数据集分为两部分:
- 训练集 — 模型用于学习模式
- 验证集 — 用于检查模型的泛化程度
我们可以使用validation_split argument 轻松做到这一点。在这个项目中,我们使用了典型的 80:20 训练验证拆分,这意味着 80% 的数据用于训练模型,20% 的数据用于验证其在未见过的示例中的性能。
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
NUM_CLASSES = 36 # Adjust this as per your dataset
directory = "dataset/"
train_dataset = image_dataset_from_directory(data_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE,
validation_split=0.2,
subset='training',
seed=42)
validation_dataset = image_dataset_from_directory(data_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE,
validation_split=0.2,
subset='validation',
seed=42)为了帮助我们的模型更好地泛化,我们可以添加简单的增强,如旋转和随机翻转。这会训练模型识别角度或镜像方向略有不同的手势。
# function for data augmentation
def data_augmenter():
'''
Create a Sequential model composed of 2 layers
Returns:
tf.keras.Sequential
'''
data_augmentation = tf.keras.Sequential([
tfl.RandomFlip("horizontal"),
tfl.RandomRotation(0.1),
])
return data_augmentation让我们快速看一下当我们将这个增强应用于我们的一个输入图像时会发生什么。

构建迁移学习模型
本文我们将了解如何使用预训练模型来修改分类器任务,使其能够识别 ASL 手势。
我使用 MobileNetV2 作为基本模型,并构建了一个用于 ASL 手势检测的自定义分类头。MobileNetV2 旨在提供快速且计算高效的性能。它已在 ImageNet 上进行了预训练,ImageNet 是一个包含超过 1400 万张图像和 1000 个类别的数据集。
迁移学习策略:
我们只想训练模型的最后一层,同时保持网络的其余部分处于冻结状态。为了实现这一目标,我们:
- 通过设置include_top=False
- 通过设置 冻结基础模型 ,这可以防止在训练期间更新预训练的权重base_model.trainable = False
- 添加 Global Average Pooling 图层,将每个通道的空间特征压缩为单个值
- 插入速率为 0.2 的 Dropout 图层,以降低过拟合的风险
- 添加一个具有 36 个神经元的 Dense 输出层,每个 ASL 类一个(26 个字母 A-Z 和 10 个数字 0-9)
下面是模型构造函数,它初始化 MobileNetV2 函数并根据我们的情况进行自定义:
# === Build the Transfer Learning Model ===
def asl_model(image_shape=IMG_SIZE, data_augmentatinotallow=data_augmenter()):
''' Define a tf.keras model for binary classification out of the MobileNetV2 model
Arguments:
image_shape -- Image width and height
data_augmentation -- data augmentation function
Returns:
tf.keras.model
'''
input_shape = image_shape + (3,)
base_model = MobileNetV2(input_shape=IMG_SIZE + (3,),
include_top=False,
weights='imagenet')
# freeze the base model by making it non trainable
base_model.trainable = False
# create the input layer (Same as the imageNetv2 input size)
inputs = tf.keras.Input(shape=input_shape)
# apply data augmentation to the inputs
x = data_augmentation(inputs)
# data preprocessing using the same weights the model was trained on
x = preprocess_input(x)
# set training to False to avoid keeping track of statistics in the batch norm layer
x = base_model(x, training=False)
# add the new Binary classification layers
# use global avg pooling to summarize the info in each channel
x = tf.keras.layers.GlobalAveragePooling2D()(x)
# include dropout with probability of 0.2 to avoid overfitting
x = tf.keras.layers.Dropout(0.2)(x)
# use a prediction layer with one neuron (as a binary classifier only needs one)
outputs = tf.keras.layers.Dense(36, activatinotallow='softmax')(x)
model = tf.keras.Model(inputs, outputs)
return model编译模型并训练
在这个阶段,我们只需检查模型摘要,确认基础层被冻结,只有我们的自定义层是可训练的。
# === Compile and Train (Frozen Base) ===
model = asl_model(IMG_SIZE, data_augmentation)
model.summary()
现在,我们已准备好训练模型。我们将使用:
- Adam 优化器:用于高效的梯度更新
- SparseCategoricalCrossentropy,因为我们正在处理整数标记的多类分类
- Early stopping 用于停止训练,如果验证损失停止改善。
- restore_best_weights=True确保在训练结束后,模型将恢复到验证性能最佳时期的权重。
early_stop = EarlyStopping(patience=5, restore_best_weights=True)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
fine_tune_history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=30,
callbacks=[early_stop]
)训练日志
该模型在 30 个 epoch 中继续稳步改进,训练和验证准确性都显著攀升。提前停止的耐心设置为 5,但由于性能不断提高,训练一直持续到第 30 个时期。
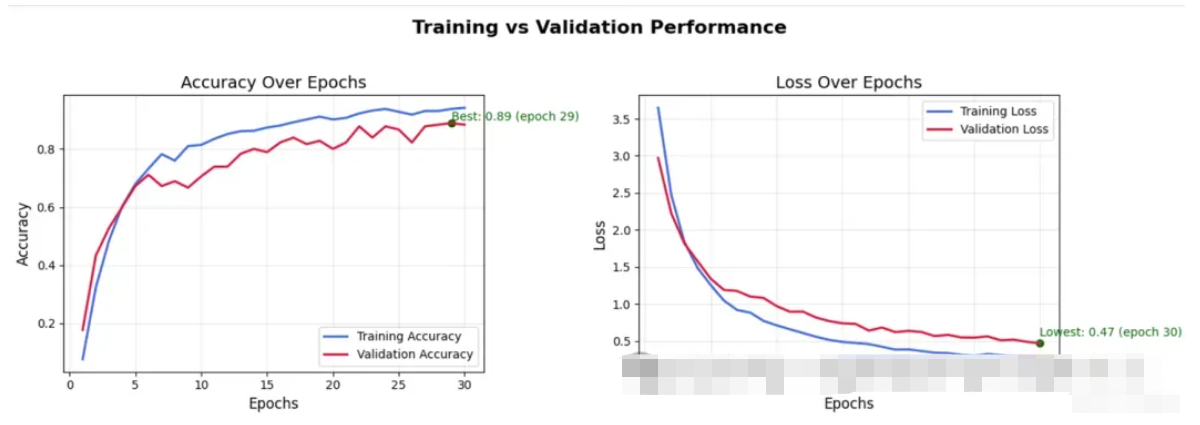
最佳验证准确率:89%
最低验证损失:0.47
我们可以看到,该模型在训练结束时仍在改进,这表明它可以从进一步的微调中受益,尤其是通过专注于它难以处理的示例。
微 调
在初步培训之后,我注意到一些特定的 ASL 标志一直被错误分类。我没有对模型进行全面改革,而是应用了有针对性的微调策略:
首先,从验证集中创建错误预测的图像数组。
wrong_images = []
wrong_preds = []
wrong_labels = []
class_names = validation_dataset.class_names
# Go through validation dataset
for images, labels in validation_dataset:
preds = model.predict(images)
pred_classes = np.argmax(preds, axis=1)
true_classes = labels.numpy()
for i in range(len(images)):
if pred_classes[i] != true_classes[i]:
wrong_images.append(images[i].numpy().astype("uint8"))
wrong_preds.append(pred_classes[i])
wrong_labels.append(true_classes[i])然后我遵循一个简单的策略:
- 取消批处理原始数据集以处理单个样本。
- 使用默认权重 1.0 标记每个样本。从错误分类(“硬”)示例创建新数据集,并为它们分配更高的权重(例如 2.0)。
- 合并两个数据集、shuffle、repeat 和 batch。
这使模型能够更频繁地看到更难的示例,并在训练期间赋予它们更大的影响力。
# STEP 1: Add weights to original train_ds (unbatched)
train_ds_unbatched = train_dataset.unbatch()
def add_default_weight(image, label):
return image, label, tf.constant(1.0, dtype=tf.float32)
train_ds_weighted = train_ds_unbatched.map(add_default_weight)
# STEP 2: Create a weighted dataset of hard examples
wrong_images = np.array(wrong_images)
wrong_labels = np.array(wrong_labels, dtype=np.int32)
wrong_weights = np.full(len(wrong_labels), 2.0, dtype=np.float32)
hard_ds = tf.data.Dataset.from_tensor_slices((wrong_images, wrong_labels, wrong_weights))
# STEP 3: Combine and batch
combined_train_ds = train_ds_weighted.concatenate(hard_ds)
combined_train_ds = (
combined_train_ds.shuffle(1000)
.cache()
.repeat()
.batch(32)
.prefetch(tf.data.AUTOTUNE)
)使用新的权重继续训练:
在构建包含具有更高权重的困难示例的新combined_train_ds示例后,我继续训练了几个 epoch 以让模型进行调整:
model.fit(combined_train_ds, validation_data=validation_dataset, epochs=10, steps_per_epoch=len(train_dataset))最终结果:
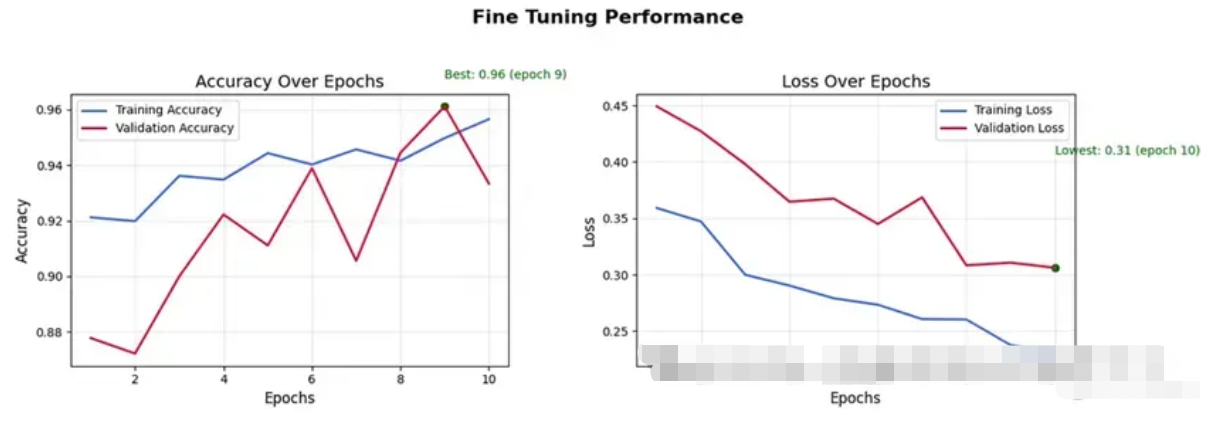
微调性能
最终验证准确率达到 96%,验证损失降至 0.31,与之前的基线相比,这是一个令人印象深刻的提升。
总 结
以下是我完成的工作:
- 使用 MobileNetV2 和迁移学习开发了 ASL 分类器,并针对速度和准确性进行了优化
- 通过有效的训练和模型调整实现了 96% 的验证准确率
- 通过有针对性的图像增强策略增强增强稳健性
- 通过重新加权难以预测的迹象以进行集中微调来提高性能
- 证明微小的战略性调整可以带来显著的性能改进
源码下载:
https://github.com/Dnyana9/tranafer-learning-with-MobileNetV2#Vec2Face
1. 亮点
- 此工作提出的Vec2Face模型首次实现了从特征向量生成图片的功能,并且向量之间的关系,如相似度,和向量包含的信息,如ID和人脸属性,在生成的图片上也会得到继承。
- Vec2Face可以无限生成不同的身份 (synthetic ID) 的图像! 之前的生成式模型 (GAN, Diffusion model, Stablediffusion model) 最多只能生成8万个不同身份的图像[1]。本文中, 利用Vec2Face生成了来自于300K个人的15M张图片。
- 用Vec2Face生成的HSFace10k训练的模型,首次在上实现了性能超越同尺度的真实数据集 (CASIA-WebFace[1])。另外,当持续增大合成ID的数量后,精度能够平稳地提高。为合成数据集生成方法提供了新的范式。
论文链接: https://arxiv.org/abs/2409.02979
代码链接: https://github.com/HaiyuWu/Vec2Face
Demo链接: https://huggingface.co/spaces/BooBooWu/Vec2Face
1. 研究动机
现有的人脸合成数据集生成方法是基于与训练模型或者风格迁移模型,然而这些方法普遍存在两个缺点:1)无法有效的生成大量不同的合成ID,2)需要用额外的模型来提高每个ID图片的多样性。这两点要么使得在合成的人脸数据集训练的模型性能表现不佳,要么难以合成大型数据集。因此,我们通过让提出的Vec2Face模型学习如何将特征向量转化为对应的图片,并且在生成时对随机采样的向量加以约束,来实现高质量训练集的生成。这一方法可以轻松解决上述两点问题,而且无需额外的模型进行辅助。此外我们还提出了Attribute Operation algorithm来定向的生成人脸属性,这一优势也可以被用来补足各类人脸任务的数据缺陷。
在性能上,我们生成的0.5M图片规模的训练集在5个测试集(LFW, AgeDB-30, CFP-FP, CALFW和CPLFW)上实现了state-of-the-art的平均精度(92%),并且在CALFW上超越了真实数据集(CASIA-WebFace)的精度,见Table 1。当我们将数据集规模提升到15M的时候,精度达到了93.52%(见Table 2)。
2. Vec2Face训练和生成方法Vec2Face训练
数据集:从WebFace4M[2]中随机抽取的5万个人的图片。

statistical_information
为了让模型充分理解特征向量里的信息,我们的输入仅有用预训练的人脸识别模型提取出来的特征向量(IM feature)。随后将由特征向量扩展后的特征图(Feature map)输入到feature masked autoencoder(fMAE)里来获取能够解码成图片的特征图。最后用一个图片解码器(Image decoder)来生成图片。整个训练目标由4个损失函数组成。
用于缩小合成图()和原图()之间的差异:
用于缩小合成图和原图对于人脸识别模型的相似度:
感知损失[3]和GAN损失 用于提高合成图的图片质量。我们使用patch-based discriminator[4/5]来组成GAN范式训练.
生成
因为Vec2Face仅需输入特征向量(512-dim)来生成人脸图片并且能够保持ID和部分人脸属性的一致,所以仅需采样ID vector并确保 即可保证生成的数据集的inter-class separability。至于intra-class variation,我们仅需在ID vector加上轻微的扰动 就能够在ID一致的情况下实现图片的多样性。
然而,由于在训练集里的大部分图像的头部姿态都是朝前的(frontal),这使得增加随机扰动很难生成大幅度的头部姿态(profile)。因此,我们提出了Attribute Operation(AttrOP)算法。它通过梯度下降的方法调整ID vector里的数值来使得生成的人脸拥有特定的属性。

Eq. 5:

attr_loss
3. 实验性能对比
我们在5个常用的人脸识别测试集,LFW[6],CFP-FP[7],AgeDB[8],CALFW[9],CPLFW[10],上和现有的合成数据集进行对比。使用的损失函数是ArcFace[11],网络是SE-IResNet50[12]。

Table 1: Comparison of existing synthetic datasets on five real-world test sets. †, *, and ◊ represent diffusion, 3D rendering, and GAN approaches, respectively, for constructing these datasets. We also list the results of training on a real-world dataset CASIA-WebFace.
结果总结如下:1)Vec2Face生成的HSFace10K数据集达到了state-of-the-art的平均精度;2)HSFace10K首次实现了,在同等数据规模下,在CALFW上的精度超越了真实数据集;3)HSFace10K首次实现了GAN范式训练超越其他范式。
扩大数据集规模的有效性
我们将HSFace数据集的规模从0.5M扩大到了15M,达到了现有最大人脸合成训练集的12.5倍。这也使平均精度提高了1.52%。同时,添加了HSFace10K的数据后,CASIA-WebFace数据集在最终的平均识别精度上提高了0.71%。

Table 2: Impact of scaling the proposed HSFace dataset to 1M images (20K IDs), 5M images (100K IDs), 10M images (200K IDs), 15M images (300K IDs). Continued improvement is observed. We also list the performance obtained by training on the real-world dataset CASIA-WebFace and its combination with HSFace10K. The latter combination yields even higher accuracy.
计算资源对比
我们与Arc2Face,state-of-the-art模型,进行了计算资源上的对比。首先Arc2Face的模型是Vec2Face的5倍。其次,Arc2Face在使用LCM-LoRA(https://arxiv.org/abs/2311.05556)的前提下,Vec2Face在一个Titan-Xp GPU上速度达到了Arc2Face的311倍。最后,Vec2Face在重建LFW (in-the-wild)和Hadrian(indoor)图片上也实现了更好的FID。

Table 3: Computing cost and FID measurement of Arc2Face and Vec2Face.
其他实验AttrOP的影响

此实验表明AttrOP可以有效控制生成图片的质量和人脸属性从而提高特殊人脸属性在数据集中的表达。
衡量现有合成数据集的ID分离度

扰动采样中 对于精度的影响

ID分离度对于精度的影响 (Avg. ID sim越大,分离度越小)

从上表可以看出,虽然ID的分离度会提高模型的性能,但是这个提升随着分离度的增大在逐渐降低。
身份泄露实验

在人脸识别领域中,有效生成新的ID是考量生成模型性能的重要指标之一。我们对比了合成数据集和训练集里ID的相似度从而检测是否合成数据集里包含了真实ID。我们使用0.7作为阈值。从上表可以看出,即使生成5M个ID,也未检测到有身份泄露问题。
References
[1] Learning face representation from scratch
[2] Webface260m: A benchmark for million-scale deep face recognition
[3] The unreasonable effectiveness of deep features as a perceptual metric
[4] Image-to-image translation with conditional adversarial networks
[6] Labeled faces in the wild: A database for studying face recognition in unconstrained environments
[7] Frontal to profile face verification in the wild
[8] AgeDB: The First Manually Collected, In-the-Wild Age Database
[9] Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments
[10] Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments
[11] ArcFace: Additive Angular Margin Loss for Deep Face Recognition
[12] Deep residual learning for image recognition
#PixelPonder
多视觉条件控制新架构!时间步意识自回归组合视觉特征,更强的视觉控制能力!
本文介绍了PixelPonder,一种新型的多视觉控制架构,通过动态Patch适应和时间步意识的自回归组合视觉特征,解决了多视觉条件控制图像生成中的冲突指导问题,显著提升了多视觉控制任务的性能和视觉和谐度。
ControlNet架构定义了视觉控制的全新范式,但其统一的时序视觉控制信号阻碍了多模态视觉控制的协同作用,这导致难以实现多视觉联合控制图像生成。最近出现的PixelPonder是一种新型的多视觉控制解决方案,在多视觉控制任务中显示出多模态融合的巨大潜力。在这项工作中提出了Patch Adaption,这是一种多视觉控制的全新解决方案,具有多视觉控制任务所需的适应性。与先前的解决方案在多类测试集的大量实验表明,所提出的Patch Adaption在patch级别上整合了各模态的优势,并在控制力度上优于传统的单视觉控制方案和现有的多视觉控制方案,展示了多视觉控制任务上ControlNet的全新可能。
题目:PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
论文:https://arxiv.org/abs/2503.06684
项目主页:https://hithqd.github.io/projects/PixelPonder/
背景
最近在基于扩散的文本到图像生成方面的进展,通过视觉条件控制展示了令人鼓舞的结果。然而,现有的类似ControlNet的方法在组合视觉条件方面面临挑战——在多个异构控制信号之间同时保持语义保真度,同时维持高视觉质量。它们采用独立的控制分支,这往往在去噪过程中引入冲突的指导,导致生成图像中的结构扭曲和伪影。为了解决这个问题,我们提出了PixelPonder,这是一种新颖的统一控制框架,允许在单一控制结构下有效控制多个视觉条件。具体而言,我们设计了一种基于补丁的自适应条件选择机制,能够在子区域级别动态优先考虑空间相关的控制信号,从而实现精确的局部指导而不干扰全局信息。此外,我们还部署了一种时间感知的控制注入方案,根据去噪时间步调节条件影响,逐步从结构保留过渡到纹理细化,充分利用来自不同类别的控制信息,以促进更和谐的图像生成。大量实验表明,PixelPonder在不同基准数据集上超越了之前的方法,在空间对齐精度上表现出显著提升,同时保持高文本语义一致性。

方法

PixelPonder 的整体流程如上图所示。对于各类视觉信号,在每个时间步,采用Patch Adaption获取patch级别上的重构信号,用于控制网络实现精细化的控制信号注入,从而实现高可控生成。其中,在获取重构信号的过程中,ISB通过各类视觉信号特征以及重构信号的组成状态获取统合概率图。统合概率图表征了各图像特征的patch挑选倾向,基于概率图,通过自回归的反复迭代获取最终的重构信号,作为ControlNet架构下网络所需输入的统一信号。参考ControlNet,控制网络由一个较小的流匹配网络构成,与flux的主干网络一一对应,各个模块的输出用于修正主干网络的流生成,从而实现精细的图像控制。
Patch Adaption Module (PAM)
Patch Adaption Module(PAM)的目标是将各种视觉条件在补丁级别重新组合成统一的视觉条件。这是通过自回归迭代组合过程实现的,该过程在不同视觉条件之间组合补丁。
我们将各类视觉特征视为由patch组合而成,也就是:

基于此,PAM的自回归更新过程可以简略表达如下:

自回归的机制通过Image Stream Block(ISB)能够注意到各类视觉特征中已被挑选的patch和备选patch的隐含关联,并基于当前时间步下图像去噪的状态获取更优的统一信号以优化流匹配路径。这一过程显著提升了各类模态之间的高低频信息协同作用。其中,ISB获取概率图的计算公式如下:

具体而言,ISB基于FLUX的Double Stream Block(DSB)而得,其中包含一个完整的DSB流程。不同的是,为了确保控制信号的全局信息高度一致,ISB所接受的文本信号以及时序信号是一致的。
最终的概率输出为:

时间步意识的控制注入:来自PAM的统合信号传递到ControlNet。ControlNet使用一个较小的流匹配网络处理具有时间步特征的统合信号,获取修正流,并注入主干网络,数学形式如下:

实验结果

如视觉展示所示,在多视觉控制注入的情况下,现有的其他方法会产生伪影和扭曲的生成。而PixelPonder能利用各个模态互补的视觉要素生成更稳定,充满细节的视觉图像。
多类别对比实验

单类别对比实验

结论
在两类不同主题的测试集上,大量的数据(约1w张)结果表明PixelPonder相较于单视觉控制和多视觉控制方案,在视觉和谐度和可控度上有了极大的提升。同时,在视觉控制和文本控制的trade-off下,文图一致性也保持着领先的水平。
消融实验



总结
在本文中,我们提出了PixelPonder,这是一种用于基于扩散的图像生成的组合视觉条件的新框架。我们的关键贡献在于解决现有方法在处理来自多个控制信号的冲突指导时的基本局限性。具体而言,我们引入了两个新组件:一种基于补丁的自适应条件适配机制,通过可学习的注意力门动态解决空间冲突,以及一种时间感知的控制注入方案,协调去噪阶段中的条件影响。在多个基准测试上的大量实验表明,相较于最先进的方法,PixelPonder显著提高了性能。通过PixelPonder,用户可以利用各种视觉条件描绘对象的不同方面,从而准确实现他们的各种创作。
#CountAnything 如何彻底改变工业计数场景
T-Rex2 是一个基于视觉提示的零样本开放集检测模型,它提供了一种更直观的方式来识别难以用语言描述的稀有或视觉复杂物体。这一特性对于解决各种行业场景中的长尾检测问题尤其有效,尤其是在工业环境中。因此,T-Rex2 的一个重要应用是事物计数,这促成了另一个有效计数工具——CountAnything 的开发。
一、技术优势
计数是众多行业的关键需求。CountAnything 利用 T-Rex2 独特的技术架构和卓越的性能,为以下领域带来革命性的解决方案:
1. 零样本物体检测能力
T-Rex2 在 COCO 数据集上展现出卓越的零样本检测能力。这意味着 CountAnything 无需专门训练即可识别和计数新物体,为计数应用带来以下优势:
立即部署:无需收集大量训练数据集或为每个新对象重新训练模型;
处理未知物体:能够统计以前未见过的物体类别;
降低技术门槛:非技术用户可以快速开始计算新物体。
2. 长尾检测能力
T-Rex2 在 LVIS 数据集上对稀有类别的出色表现,为统计不常见物体提供了关键支持:
稀有物体计数:准确计数数据集中极少出现的物体;
类别不平衡处理:在包含大量常见物体和少量罕见物体的场景中保持高精度;
长尾分布适应性:有效处理通常遵循长尾特征的现实世界对象分布。
3. 跨域泛化能力
T-Rex2 在 ODinW 和 Roboflow100 数据集上展现出优异的跨域泛化能力,这意味着 CountAnything 在各种跨域情况下的表现都远超同类计数产品,包括:
环境适应性:在不同的光照条件、角度和背景下保持计数精度;
多场景支持:从室内到室外、从微观到宏观,计数性能始终一致。
二、应用场景
CountAnything 针对主流行业需求和计数场景进行了专门的优化。它通过便捷的产品体验和精准的模型性能,将易出错的手动计数任务转变为高效准确的流程。
1. 制药行业
在药品生产和仓储中,药品、药盒以及各类医用耗材的计数至关重要。传统的人工计数方式效率低下,且在长时间高强度工作中容易出错。计数错误会导致药品生产数量不一致、库存管理混乱等严重问题。
CountAnything 可以快速扫描药品货架和生产线,精准识别并盘点各种药品和耗材。无论是整齐排列的药箱,还是形态各异的医疗器械,都能快速完成盘点,大大提高药企生产和仓储管理的效率,保障医药供应链的精准运转。

2. 农业产业
在农业领域,作物植株统计、果实产量估算以及农业设施(如温室数量、灌溉喷头数量)的计数对于农业决策和产量估算至关重要。传统的人工计数费时费力,且准确性容易受到地形、作物生长模式等因素的影响。
CountAnything 可以通过拍摄田间和果园照片,快速识别并准确计数农作物和水果,同时还能精确统计农业设施。无论是姿态各异的花朵,还是生长形态各异的树枝上的果实,CountAnything 都能精准计数,帮助农民合理规划农业活动,科学估算产量。

3. 木材工业
在木材行业中,高效、准确地盘点原木至关重要。传统的人工盘点方式在面对外观均质的木材时,容易出现漏盘或重复盘点,效率低下,无法满足行业日益增长的数字化管理需求。
CountAnything帮助木材企业大幅提升运营效率,显著提高装卸速度,大幅减少人工盘点错误,为木材企业生产流程优化和资源管理提供坚实的数据基础,有效推动木材资源管理数字化。

4. 畜牧业
在农场,牲畜计数是日常管理的重要环节。传统的人工计数不仅耗费人力,而且在牲畜活动频繁时容易出现错计、漏计,影响养殖成本核算、饲料规划等关键环节。
CountAnything可以准确识别和统计鸡、鸭、猪等各种牲畜数量,即使在动物聚集或移动时也能准确计数,帮助养殖者科学规划养殖规模,合理安排养殖资源。

5. 工业与建筑业
以建筑工地为例,钢筋计数是一项繁琐而重要的工作,传统的人工逐根计数钢筋效率低且容易出错,影响施工进度和成本控制。
CountAnything 可拍摄堆放的钢筋,并借助 T-Rex2 强大的图像识别能力,快速准确地识别并计数。无论是排列整齐的钢筋,还是随意堆放的钢筋,都能即时提供精准的计数结果,有效提升工业生产中材料盘点的效率和准确性,保障项目顺利进行。

6. 制造业
在制造业的日常生产运营中,零部件的计数和管理是一项基础而重要的工作。传统的人工计数方式,面对复杂、繁多的零部件,不仅耗费大量的人力和时间,而且由于工人疲劳以及零部件外观相似等原因,容易出现错计数、漏计数,影响生产计划的精准执行和成本核算的准确性。
在装配车间,CountAnything 可以实时统计待装配部件数量,确保生产线物料供应准确及时,避免因部件短缺或过剩而导致生产停滞或资源浪费。在仓储环节,CountAnything 可以快速盘点库存部件,帮助企业准确掌握库存水平,合理规划采购和生产计划。制造企业引入 CountAnything 可以大幅提升生产管理效率,减少人工盘点错误,优化供应链管理,增强市场竞争力。

7. 零售业
在日常零售门店运营中,盘点是一项高频工作。人工盘点不仅耗时耗力,而且在商品种类繁多、陈列复杂的情况下,容易出现遗漏和错误,影响补货决策和销售策略的制定。
CountAnything 允许门店工作人员使用手持设备拍摄货架商品,快速识别各类商品并进行精准计数。无论是货架上的常规商品,还是促销展示中的特色商品,它都能精准计数,帮助零售商实时监控库存动态,及时补货,优化商品陈列布局,提升门店运营效益。

此外,在超市等涉及大量硬币交易的场所,人工点算硬币既耗时又容易出错。CountAnything 可以通过拍摄硬币堆快速识别并准确点算硬币,大大提高点算效率,降低人工成本和错误概率,助力高效的金融交易、零售结算等流程。

8. 物流业
在物流仓库中,包裹、托盘盘点以及货物类盘点都是劳动密集型工作,对效率要求较高。传统的人工盘点速度慢,容易在物流高峰期造成货物积压、发货延误。
CountAnything 允许物流人员使用手持设备拍摄货物,快速识别并准确计数包裹和托盘,清晰区分不同货物类型。即使在货物堆放密集、包装多样的情况下,也能精准计数,显著提升物流仓库管理效率,确保货物高效周转。

结 论
CountAnything通过不断优化物体检测技术,并与行业伙伴和个人用户紧密合作,为各行各业的专业场景提供高效、准确的通用计数解决方案。
此外,为了更好地满足行业的长尾需求,在一些对准确率要求极高、对数据准确性和可靠性要求严格的应用场景中,CountAnything 为用户提供了定制化的 OVP 模板。该功能解决了传统模型训练需要海量数据集和复杂流程的弊端,只需 15 到 20 张图片即可快速完成针对特定目标的定制化检测模型。这种高效、低成本的定制方式大大降低了模型训练的门槛。未来,更多用户将能够轻松利用先进的目标检测技术来满足其业务需求,惠及小型企业和个人开发者。
参考链接
(1)论文:《T-Rex2:通过文本-视觉提示协同实现通用物体检测》,作者:蒋庆、李锋、曾昭阳、任天河、刘世龙、张磊。
https ://arxiv.org/abs/2403.14610(2)通过DINO-X平台访问T-Rex2 API:
https://cloud.deepdataspace.com/(3)CountAnything,基于 T-Rex2 的快速精准计数工具:
https://deepdataspace.com/products/countanything#SimpleAR
自回归的捍卫者来了:复旦联手字节Seed开源纯AR图像生成模型
本篇分享论文SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL,复旦联手字节Seed开源纯AR图像生成模型。
- 论文链接:https://arxiv.org/abs/2504.11455
- 代码地址:https://github.com/wdrink/SimpleAR
序言
基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。虽然也有一些早期工作如Parti[1]、LlamaGen[2],尝试用更强的视觉tokenizer和Transformer架构来提升自回归生成的效果,但他们论文中的结果表明,只有更多的参数量才能让自回归模型勉强和扩散模型“掰掰手腕”。
这也让越来越多的研究者质疑自回归视觉生成是否是一条可行、值得探索的路径。通常来说,大家的担忧集中在三个方面:
- 离散的token必然带来更多的信息损失:当下改进视觉tokenizer也是一个备受关注的方向,最新的方法无论是离散或连续都可以取得非常好的重建效果(至少不会制约生成模型),因此相信这一点不会是制约两条路线的核心原因;
- 视觉token序列往往较长、因此很难建模token间的关系:对于一个512分辨率的图像来说,16倍压缩比的tokenizer意味着视觉token序列的长度是1024。对于采用因果掩码(causal mask)的自回归模型来说,建模这么长的序列无疑是很有挑战性的;
- 下一个token预测的效率太低:相比于扩散模型或MaskGIT[3]那样一步出整图或多个token,自回归模型串行预测token的方式在生成速度方面存在明显劣势。
近些时间,也有一些工作如VAR[4]和MAR[5]尝试重新定义视觉里自回归的形式,比如下一个尺度预测、或用连续token做自回归。这些方法在ImageNet这样的学术数据集上取得了不错的效果,但是也潜在地破坏了视觉模态和语言模型的对齐性。
带着好奇的心态,来自复旦视觉与学习实验室和字节Seed的研究者们希望“验一验”自回归视觉生成模型的能力,他们保持“Next-token prediction”这样简洁优美的形式,而通过优化训练和推理过程来探究自回归视觉生成是否可以像扩散模型一样取得不错的文生图效果。
方法
先说结论!这篇工作有三点惊艳的发现:
- 在0.5B的参数规模下,纯自回归模型可以生成1024分辨率的高质量图像,且在常用文生图基准上取得了非常有竞争力的结果,例如在GenEval上取得了0.59, 是1B以内模型的SOTA;
- 通过“预训练-有监督微调-强化学习”这样的三阶段训练,模型可以生成出具有很高美学性的图像,且有监督微调(SFT)和基于GRPO[6]的强化学习可以持续提升模型的指令跟随能力以及生成效果;
- 当用vLLM[7]进行部署时,0.5B的模型可以在14秒以内生成1024分辨率的图像。
性能比较
本文提出的SimpleAR在GenEval和DPG上都取得了不错的结果,其中0.5B模型显著超越了SDv2.1和LlamaGen。值得一提的是,扩散模型和Infinity这类方法都依赖于外挂的文本编码器,如Infinity [7]使用了3B的FlanT5-XL[8],而本文提出的自回归模型则将文本(prompt)编码和视觉生成集成在了一个decoder-only的Transformer里,不仅可以更好地学习跨模态对齐,也能更加高效地利用参数。

1.5B模型的性能距离Infinity[7]还有差距,但本文相信这主要是由数据规模导致的,当用更多的高质量数据训练时,模型的性能还可以被进一步提升。此外,本文选择了Cosmos[9]作为视觉tokenizer,其在重建低分辨率图像和人脸等细节上十分有限,因此生成能力还有充分被改进的空间。
本文还首次在文生图上成功应用了GRPO进行后训练,结果表明:利用CLIP这样非常简单的reward函数,也依然可以观察到非常有潜力的reward曲线、并在GenEval上了取得了显著的性能提升:

最后是关于效率问题。本文首先尝试了用vLLM[10]将模型部署到A100上,结果表明其可以显著地提升模型的推理速度:仅需13.55秒就能生成1024分辨率的高质量图像,这显著缩小了和扩散模型的差距,并由于可以使用KV Cache技术而相比于MaskGIT更有优势。本文也实现了推断采样,其可以有效降低2倍的自回归推理步数。

可视化结果

总结和几点思考
顾名思义,SimpleAR只是团队关于自回归视觉生成的一次简单尝试,但从中可以看到自回归模型相较于扩散模型的几点优势:
- 将文本和视觉token摆上平等的地位,更好地支持不同模态之间的建模学习,从而有利于构建原生的多模态理解和生成模型;
- 与现有支持语言模型后训练和推理加速的技术兼容性高:通过强化学习可以显著提升模型的文本跟随能力和生成效果、通过vLLM可以有效降低模型的推理时间;
本文训练及测试代码以及模型权重均已开源,希望鼓励更多的人参与到自回归视觉生成的探索中。
引用
[1] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation.
[2] Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation.
[3] MaskGIT: Masked Generative Image Transformer. [4] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction.
[5] Autoregressive Image Generation without Vector Quantization.
[6] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.
[7] Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis.
[8] Scaling Instruction-Finetuned Language Models.
[9] https://github.com/NVIDIA/Cosmos-Tokenizer
[10] https://github.com/vllm-project/vllm
#UniToken
为统一多模态理解与生成打造信息完备的视觉表征
来自复旦大学和美团的研究者们提出了 UniToken —— 一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。
UniToken通过融合连续和离散视觉表征,有效缓解了以往方法中“任务干扰”和“表示割裂”的问题,为多模态统一建模提供了新的范式。为了便于社区内研究者们复现与进一步开发,代码与模型已全部开源👇
- 论文标题:UniToken: Harmonizing Multimodal Understanding and Generation through Unified Visual Encoding
- 论文链接:https://arxiv.org/pdf/2504.04423
- 代码地址:https://github.com/SxJyJay/UniToken
任务背景:统一建模的挑战
在传统图文理解或图像生成模型中,其视觉编码的底层特性差异较大。譬如图文理解模型(如LLaVA、Qwen-VL等)要求从图像中抽取高层语义,从而进一步结合文本进行协同理解;而图像生成模型(如DALL-E、Stable Diffusion等)则要求保留充分的底层细节以高保真图像的生成。由此,开发理解生成一体化的多模态大模型面临着以下几大难题:
- 视觉编码割裂:理解任务偏好具有高层语义的连续视觉特征(如CLIP),而生成任务依赖保留底层细节的离散视觉特征(如VQ-GAN编码的codebook);
- 联合训练干扰:理解与生成任务差异而带来的冲突性使得在统一模型中训练时难以兼顾两个任务的性能,存在“一个优化,另一个退化”的现象。
为了应对上述挑战,领域内的相关工作通常采取两类范式:以VILA-U等为代表的工作通过结合图像重建与图文对比学习的训练目标,来提升离散视觉编码的语义丰富度;以Janus等为代表的工作通过为理解和生成任务分别定制相应的视觉编码器与预测头,来实现两个任务之间的解耦。
然而,前者在理解任务上目前依旧难以与连续视觉编码驱动的多模态大模型匹敌;后者则在应对更复杂的多模任务(例如多轮图像编辑等)时面临严重的上下文切换开销及单边信息缺失等问题。
UniToken:统一视觉表示,融合两种世界
1. 核心设计:连续+离散双编码器

不同于Janus的多任务解耦的设计思路,UniToken为所有下游任务均提供一套完备的视觉信息,促使多模态大模型以指令驱动的形式从中吸收相应的知识。具体而言,UniToken采取统一的双边视觉编码器,其中将VQ-GAN的离散编码与SigLIP的连续表征以下述方式进行拼接,从而得到一套兼备高层语义与底层细节的视觉编码:
[BOS][BOI]{离散图像token}[SEP]{连续图像embedding}[EOI]{文本}[EOS]
2. 多阶段训练策略
为了协调理解与生成任务的特性,UniToken采用三阶段训练流程:
阶段一:视觉语义空间对齐:基于Chameleon作为基座,本阶段旨在为LLM接入SigLIP的连续视觉编码。为此,在训练时冻结LLM,仅训练SigLIP ViT和Adapter,使其输出与语言空间对齐。
阶段二:多任务联合训练:基于第一阶段对齐后的双边编码器所提供的完备视觉信息,本阶段在大规模图文理解与图像生成数据集上联合训练,通过控制数据配比(10M:10M)以均衡提升模型理解与生成任务的性能。
阶段三:指令强化微调:通过测试发现,第二阶段训练后的模型在指令跟随、布局图像生成等方面的表现均有待加强,故在本阶段进一步引入高质量多模态对话(423K)与精细化图像生成数据(100K),进一步增强模型对复杂指令的跟随能力。
3. 细粒度视觉增强
得益于保存了双边视觉编码的完备性,UniToken可无缝衔接现有的细粒度视觉增强技术。具体而言,UniToken在连续视觉编码侧引入两项增强策略
- AnyRes:将高分辨率图像划分为多个子图,分别提取特征后进行相应空间位置的拼接,以提升对图像的细粒度感知;
- ViT端到端微调:在模型的全训练流程中,动态微调连续视觉编码器的权重,结合精细的学习率控制策略以避免模型崩溃,进而适应广泛的任务场景。
实验结果:超越SOTA,多模态统一的“优等生”
在多个主流多模态基准(图文理解+图像生成)上,UniToken均取得了媲美甚至领先于领域内专用模型的性能:
![]()
![]()

![]()
与此同时,研究者们对于训练策略及视觉编码的影响进行了进一步深入的消融分析:

- 在大规模数据场景下(>15M),1:1的理解+生成数据比例能够兼顾理解与生成任务的性能

- 在应对理解与生成的任务冲突时,统一的连续+离散的视觉编码相较于仅采用离散编码的方案具有较强的鲁棒性
结语与未来展望:迈向通用理解生成一体化的多模态大模型
从发展趋势上来看,目前图文理解模型在通用性上远远领先于图像生成模型。而Gemini-2.0-Flash与GPT-4o在指令跟随的图像生成方面的惊艳表现,带来了通用图像生成模型未来的曙光。在这样的时代背景下,UniToken仅是初步的尝试,而其信息完备的特性也为进一步挖掘其更深层次的潜力提供了更多信心:
- 模型规模扩展:借助更大的语言模型,进一步探索统一模型在理解与生成上的“涌现能力”;
- 数据规模扩展:引入更大规模的训练数据(如Janus-Pro使用的近2亿样本),推动模型性能极限;
- 任务类型扩展:从传统的理解与生成拓展至图像编辑、故事生成等图文交错的任务,追逐通用生成能力的上限。

















 903
903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









