







一、引言
近日Mistral - 7B模型在HuggingFace Hub上受到了业界的广泛关注:凭借着出色的算法设计和模型模型结构,就以7B的参数量在各种的测试集上效果都优于Llama2 - 13B。
同时,Mistral - 7B基于非常宽松的Apache2.0协议开源,免费,允许商业使用、修改和分发,相较于Llama2 更加友好。
今天我们就来看看Mistral - 7B是怎么实现在各项数据集上的表现都超过Llama2 - 13B的 🥸
二、Mistral 简介
论文:[2310.06825] Mistral 7B (arxiv.org)
Github:GitHub - mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model.
模型:mistralai (Mistral AI_) (huggingface.co)
Mistral - 7B是一个发布于2023年9月的大语言模型,其参数量约为73亿;官方强调的该模型的优势在于:
- 在所有的测试集上效果都优于Llama2 - 13B
- 在大多数的测试集上效果优于Llama1 - 34B
- 在代码能力上接Codellama - 7B的效果,同时在代码之外的测试集上依旧保留了良好的效果
- 使用GQA(grouped query attention)获得更快的推理速度
- 使用SWA (Sliding Window Attention)可以以相对小的显存代价处理更长的文本序列
- 以小胜大,意味着取得相似的效果硬件需求更少
三、具体方法
3.1 训练数据
关于训练数据量,很遗憾Mistral.ai并没有透露任何数据的细节,只有twitter上一个老哥发现他们似乎训练数据量达到了8T token,相较于Llama 2训练使用的2T token,直接翻了四倍!
(这也从侧面印证了Hoffmann等人的研究——在给定的计算预算下,最佳性能并不是由最大的模型实现的,而是由更多数据训练的较小模型实现的)
对于训练数据截止日期,官方没有具体说明训练数据截止日期;但经网友测试,2023年3月OpenAI发布GPT-4的事它也知道,即其训练数据截止日期最早就到2023年3月;相比之下Llama 2的预训练数据截止到2022年9月,只有部分微调数据最多到2023年6月。
3.2 Tokenizer
使用的是Byte-fallback BPE tokenizer,即在BPE的基础上开启了Byte-fallback(遇到UNK会继续按照byte进行进一步的切分),从而解决了oov的问题。
参见:https://github.com/google/sentencepiece/issues/621
3.3 模型架构
3.3.1 Grouped Query Attention (GQA)
自回归解码的标准做法是使用KV Cache,即缓存序列中先前token 的键 (K) 和值 (V) 对,以加快后续token的注意力计算。然而,随着上下文窗口或者批量大小的增加,多头注意力(MHA)模型中与KV Cache大小相关的内存成本会显著增加。对于大模型,KV Cache会成为推理时显存应用的一个瓶颈。
对于上述这种情况,Group Query Attention 如下图所示,GQA在不同的n (1<=n<=No. of heads)个query之间共享一份键 (K) 和值 (V) 对。
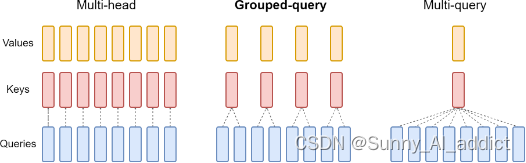
GQA通过将相关的查询分组在一起,然后集中地对这些组进行处理,从而提高了处理效率和效果。
关于GQA,可参考[LLM] Group query attention 加速推理 - 知乎 (zhihu.com)
Note: 目前很多开源模型都用到了GQA这一技术手段,最典型的是Llama 2
3.3.2 Sliding Window Attention (SWA)
Mistral 7B使用SWA滑动窗口注意力机制,其中每一层都关注前一层的window size W个隐藏状态 (mistral使用的W=4096)。
如下图所示,原始的单向注意力会计算某个token与其前所有token的注意力分数,因而操作次数在序列中是随着序列的长度进行二次方增长的,并且内存随着token的数量线性增加,在推理时,由于缓存可用性降低,这会导致更高的延迟和更小的吞吐量。
通过SWA的改进,每个token最多可以处理前一层的W个标记 (图中W = 3),操作次数在序列中是随着序列的长度进行一次方的增长,同时, 占用内存并不随着token的增加而增加,而是保持在一个稳定的数值。
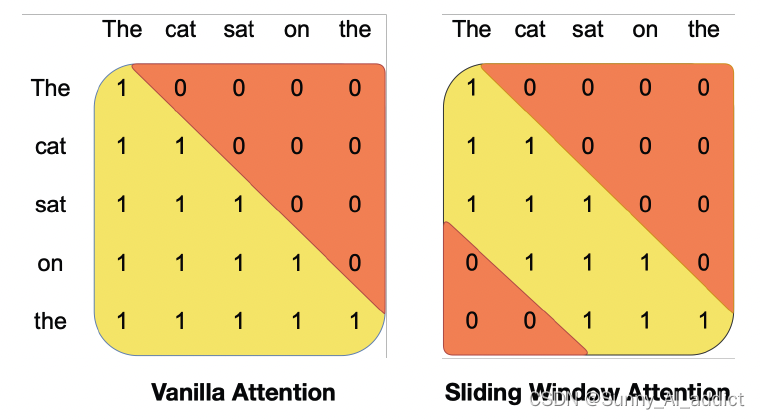
看到这里可能有些xdm会有一个问题——使用滑动窗口计算的注意力分数不是没有考虑整个序列吗?滑动窗口外的token不影响下一次单词的预测?
实际上SWA并没有此类的问题。如下图所示,位于第k层第i位的隐藏状态hi,负责处理前一层位置在i - W和i之间的所有隐藏状态。递归地,hi可以访问输入层距离为W × k个tokens。在最后一层,如果使用窗口大小W = 4096,n_layers=32,那么理论上注意力广度约为131K个tokens。
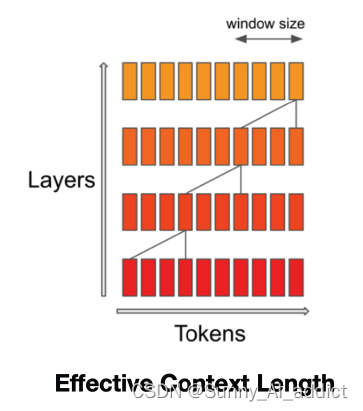
在实际应用中,相较于FlashAttention和xFormers FlashAttention 和 xFormer所做的更改,SWA使模型序列长度为16,窗口为4k的情况下,速度提高了2倍。
3.3.3 Rolling Buffer Cache
SWA滑动窗口注意力机制实现了固定的注意力广度,这意味着内存并不随着token的增加而增加,而是保持在一个稳定的数值(W)。
基于此,实际上实现了一个滚动缓存区——该高速缓存的大小固定为W,我们将位置i的(key,value)存储在缓存位置i mod W中。当位置i大于W时,该高速缓存中的过去的值被覆盖,即当position i大于窗口W的时候,通过i mod W覆盖原位置。
如下图所示,假设W=4,当在i<W的时候,正常计算(key,value)并储存在i位置; 当i>W时,计算完(key,value),根据i mod W的余数,覆盖在该位置。
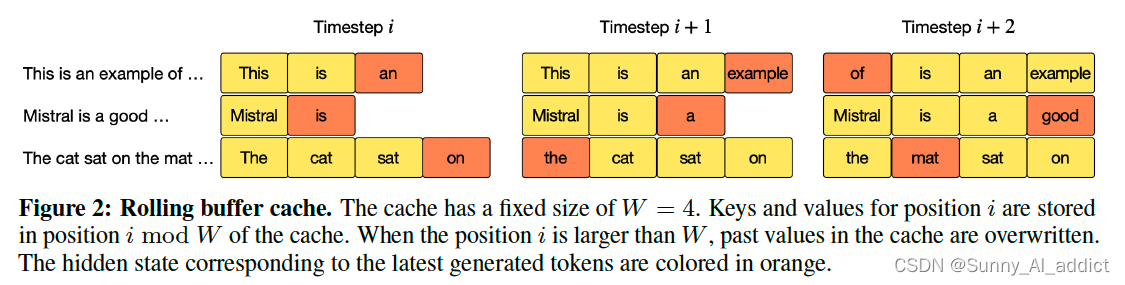
通过此种Rolling Buffer Cache的方式,将内存控制在一个稳定的数值,同时并不影响性能。
3.3.4 Pre-fill and Chunking
当生成一个序列时,我们需要一个一个地预测标记(由于自注意力的单向方式),但是提示符(prompts) 是预先知道的,可以用提示符预先填充 (key, value) 缓存。如果提示符非常大,可以将其分成更小的块,并用每个块预填充缓存。为了更好地分块来适应模型其他的机制,我们可以选择窗口大小作为块大小来切割提示符,并使用每个块预填充缓存。
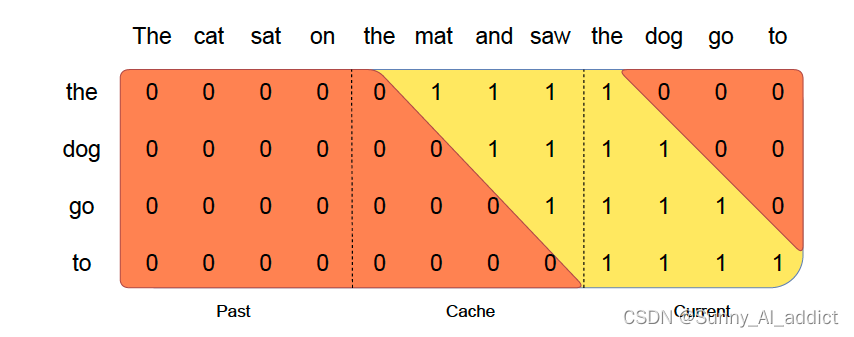
在缓存预填充期间,长序列被分块以限制内存使用。根据下图所示,我们把一个序列根据W (W=4) 分成三个部分,“the cat sat on”,“the mat and saw”,“the dog go to”。该图显示了第三个块 (“the dog go to”) 的情况:它使用因果掩码(最右边的块)来关注自己,使用滑动窗口(中心块)来关注缓存,并且不关注过去的令牌,因为它们在滑动窗口之外。
3.4 指令微调
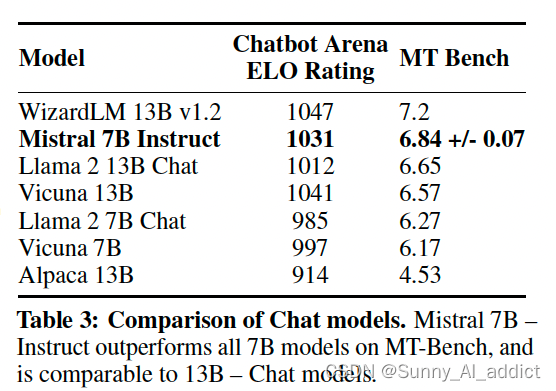
为了评估Mistral 7B的泛化能力,研究团队在指令数据集上对其进行了微调。当仅使用在hug Face存储库中公开提供的数据(没有使用专有数据或训练技巧)的情况下,Mistral 7B - Instruct,与MT-Bench上的所有7B模型相比,表现出优越的性能,并且与13B - Chat模型相当。
Mistral 7B - Instruct是一个简单而初步的演示,表明当基本模型表现足够优秀时,可以很容易地在基本模型的基础上进行微调以获得更加良好的性能。
四、实现结果及启示
4.1 模型表现 (在所有任务上都超过Llama2 -13B!)
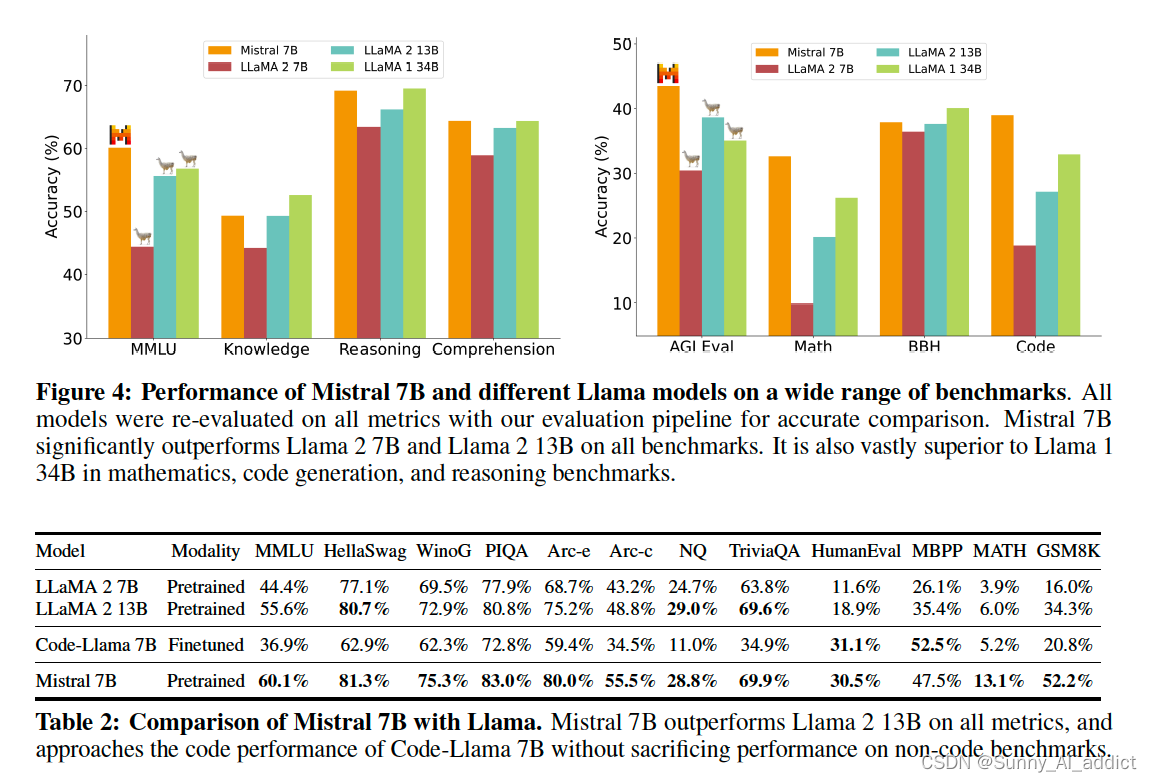
将Mistral 7B与Llama 2系列进行了比较。Mistral 7B在所有指标上明显优于Llama 2 13B,在代码任务上表现与Code-Llama 7B相当,并且并未牺牲其他任务的性能。
送给Mistral: 🐮!!!
4.2 模型优势
4.2.1 任务表现领先
Mistral 7B和Llama 2(7B/13/70B)在MMLU、常识推理、世界知识和阅读理解方面的结果。Mistral 7B在所有评估中大部分都优于Llama 2 13B,只有在知识基准测试中表现相当(这可能是由于其有限的参数数量,限制了它可以压缩的知识量)。
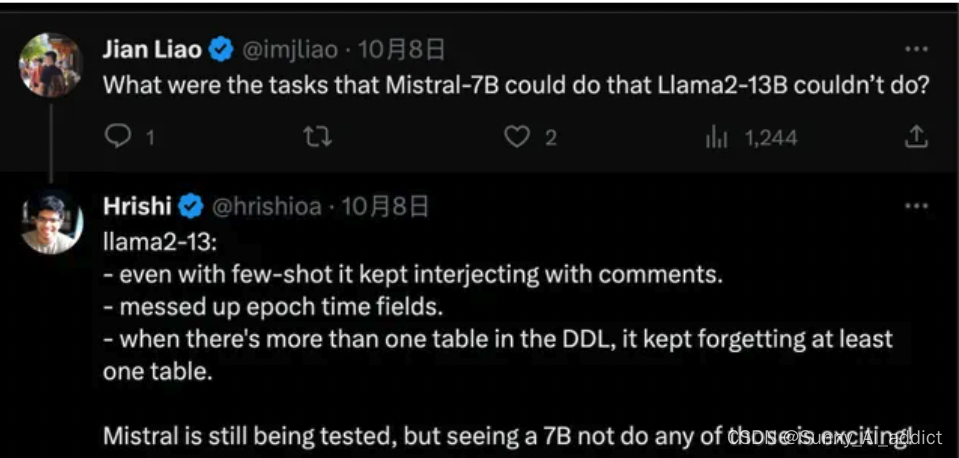
有很多网友测试了一些Llama 2无法回答正确的问题,Mistral-7B可以回答对:

4.2.2 硬件要求低
在推理、理解和STEM推理(MMLU)方面,Mistral 7B的性能相当于比它大3倍多的Llama 2。这意味着在内存节省和吞吐量增加方面获得了相当大的优势。
官方也特别说明用了各种优化手段,FlashAttention,Grouped-Query Attention,Sliding Window Attention一起上。
现在已经看到很多开发者晒自己在苹果笔记本跑起来的经验。
4.2.3 开源协议更宽松
Mistral基于非常宽松的Apache2.0协议开源,免费,允许商业使用、修改和分发。
相比之下Meta为Llama 2准备的协议,甚至被开源界批评为严格来讲不算真正的开源。
4.2.4 安全性与实用性的平衡更好
Llama 2的安全对齐措施非常充分严格,甚至损失了一部分实用性。而Mistral -7B在经过系统提示后,在某些问题上可以更好的平衡实用性和安全性,例如下面这个问题:

同时,Mistral 7B模型也可以用作内容审查员。
Mistral 7B可以用来将用户提示或生成的答案分类为以下几类:
- 非法活动,如恐怖主义、虐待儿童或欺诈
- 充满仇恨、骚扰或暴力的内容,如歧视、自我伤害或欺凌
- 在法律、医疗或金融领域提供不合格的建议
Mistral 7B可以与一个自我反思提示一起使用,使模型对提示或生成的答案进行分类。这个功能可以用来防止某些类型的内容用于高风险应用。
4.3 启示
研究团队对Mistral 7B的研究表明,语言模型可能比以前认为的更能压缩知识。这开辟了有趣的观点:到目前为止,大语言模型的重点是二维的缩放定律(直接将模型能力与训练成本联系起来);经过Mistral -7B这个模型的实际操作,启示了业界,提升大语言模型的能力这个问题是三维的(模型能力、训练成本、推理成本)。
用尽可能小的模型获得最佳性能还有很多有待探索的地方。
参考资料:

















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









