






一、 关于训练GPU的带宽
大模型训练所需的总算力(Tlops)=6 * 模型的参数量 * 训练数据的 token
6 就是每个 token 在模型正向传播和反向传播的时候所需的乘法、加法计算次数。
我们先假设一个前提:如果以每个 head 交给一个 GPU 去算,并且通讯都是点对点来计算。
需要把那么计算量和通信量的比例是多少?
2 * 3 * embedding size / heads num / bytes per param
-
2:这是一个常数,表示每个参数在正向传播和反向传播过程中都会进行一次乘法和一次加法操作。 -
3:指的是一次正向两次反向,反向是梯度和权重。 -
embedding size:这是嵌入向量的维度,也就是模型中每个词的表示空间的大小。 -
heads num:这是 Transformer 模型中的头数,也就是模型在进行自注意力计算时的并行度。在 Transformer 模型中,输入的嵌入向量会被分割成多个“头”,每个“头”都会独立地进行自注意力计算。因此,除以heads num是因为每个“头”只需要处理一部分的嵌入向量,这可以减少每个参数的内存需求。 -
bytes per param:这是每个参数的字节数,通常情况下,如果参数是 BF/FP16 类型,那么每个参数就是 2字节。除以bytes per param是因为我们需要将内存需求从字节转换为参数的数量。
如果以每个 head 交给一个 GPU 去算,并且通讯都是点对点来计算,代入 4090 的 330 Tflops,如果想让通信不成为瓶颈,那么通信带宽至少需要是 330T / 384 = 859 GB/s,发送接收双向还得乘以 2,就是 1.7 TB/s。太大了,远远超过 PCIe Gen4 x16 的 64 GB/s,就算 NVLink 的 900 GB/s 都撑不住。
需要强调的是,注意力头(attention heads)在不同GPU之间的分割通常是指在进行大规模并行处理时,如在训练大型深度学习模型(比如Transformer模型)时,将不同的注意力头分配到不同的GPU上以提高计算效率。然而,这种分割通常限制在单个服务器内部的多个GPU之间。
把上述公式代入 4090 的 330 Tflops,如果想让通信不成为瓶颈,那么通信带宽至少需要是 330T / 384 = 859 GB/s,发送接收双向需要乘以 2,就是 1.7 TB/s。远远超过 PCIe Gen4 x16 的 64 GB/s。
在应用张量并行时,不应过度细分工作负载,确保每个GPU处理足够多的attention heads。这样,由于多个attention heads共享输入矩阵X,输入矩阵的通信开销可以在这些heads之间分摊,从而提高计算量与通信量的比例。以NVIDIA 4090 GPU为例,其计算能力和单向通信带宽为330Tflops和32GB/s(因为64GB/s的带宽需要除以2来考虑单向通信)。这种情况下,计算和通信的比例至少需要达到10000,计算得张量并行的GPU数量应不超过2.4。这意味着,使用张量并行时最多只能使用两个GPU,超过这一数量,GPU的计算能力就无法被充分利用。
然而,当使用更为先进的NVIDIA H100 GPU,情况则有所不同。H100的峰值计算能力为989Tflops,而NVLink的双向带宽为900GB/s。这使得计算量与通信量的比例至少需要1100,计算得出张量并行的GPU数量可以达到11。这表明,在单机配置8张GPU卡进行张量并行是可行的,对于embedding size等于8192的模型,通信不会成为限制因素。
即2 * 3 * (embedding size / 张量并行 GPU 数量) / bytes per param = 2 * 3 * 8192 / 张量并行 GPU 数量 / 2 >= 1100,解得:张量并行 GPU 数量 <= 11,也就是单机 8 卡做张量并行,对于 embedding size = 8192,的模型刚刚好,通信不会成为瓶颈。
NVIDIA H200的计算能力(Tflops)与H100相同,但其GPU显存和内存速度有很大提升,那么这将带来如下影响。
1. 显存提升的影响
-
更大的模型容量:更大的显存允许训练更大规模的模型或使用更大的batch size,从而可能提高模型的性能和训练效率。
-
减少显存不足的情况:显存的提升可以减少由于显存不足而需要减小batch size或使用梯度累加的情况,从而简化训练过程。
2. 内存速度提升的影响
-
更快的数据传输:内存速度的提升意味着数据在GPU内部的传输速度更快,这可以减少数据传输的瓶颈,提高计算效率。
-
更高的计算与通信比例:更快的内存速度可以提高计算与通信的比例,使得更多的计算资源能够被充分利用。
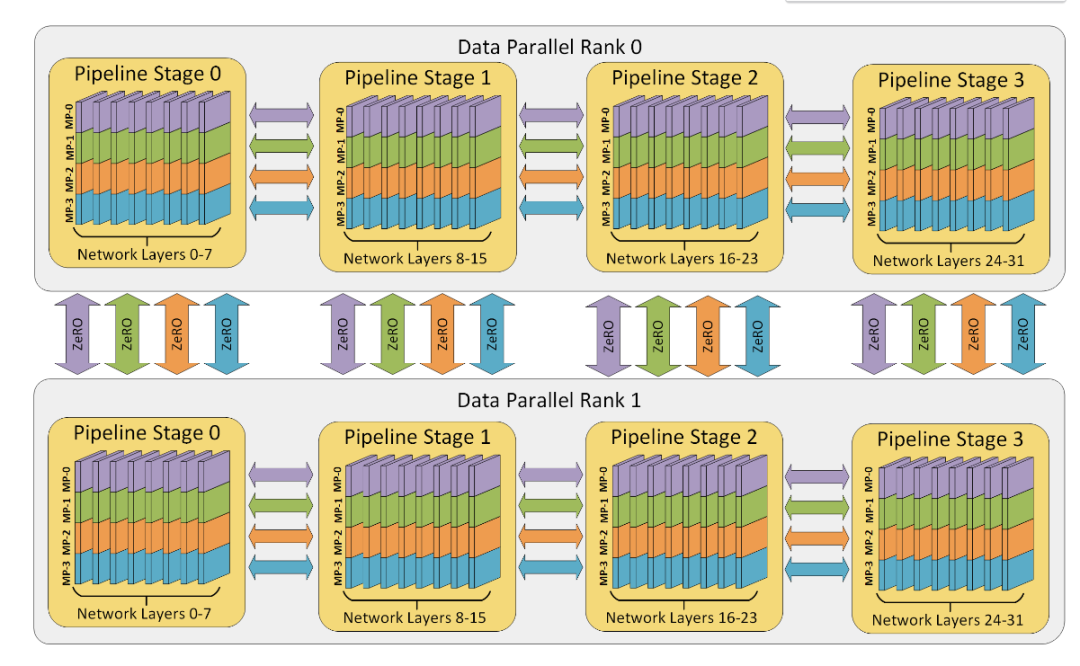
二、3D并行
Tensor parallelism、Pipeline parallelism、Data parallelism 几种并行方式,分别在模型的层内、模型的层间、训练数据三个维度上对 GPU 进行划分。三个并行度乘起来,就是这个训练任务总的 GPU 数量。
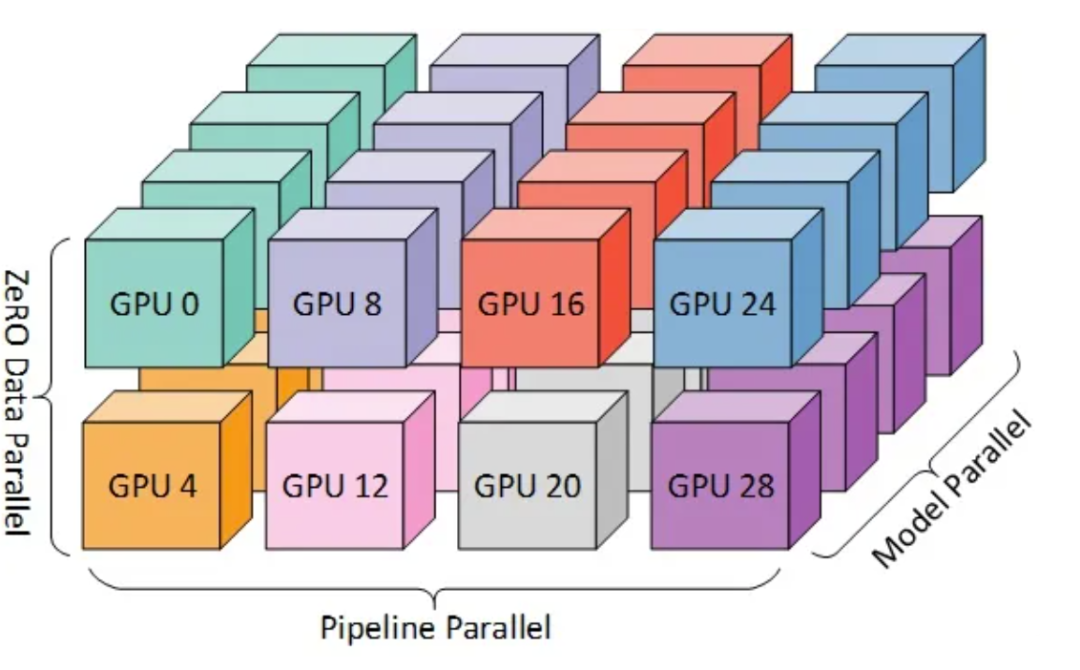
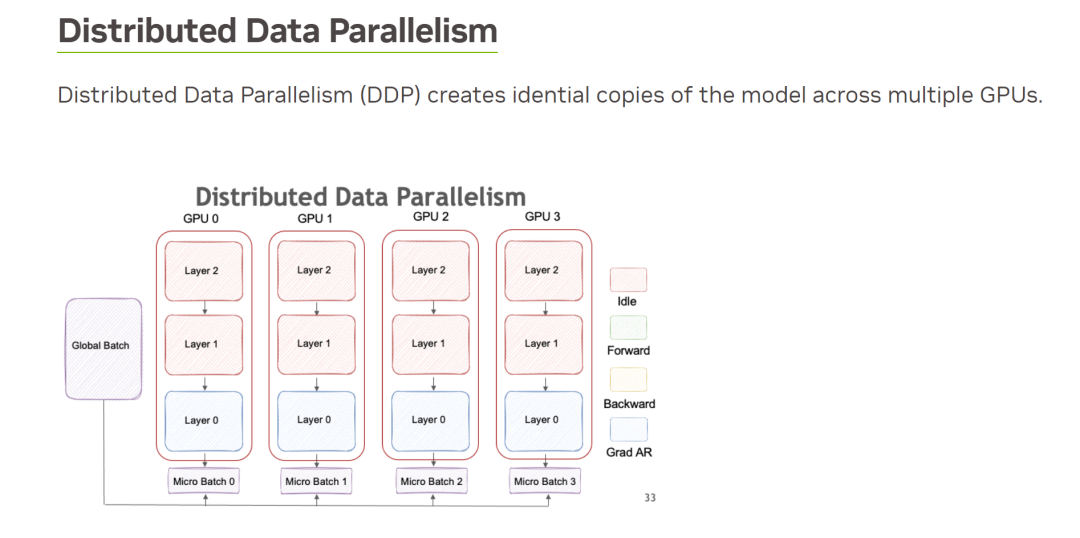
数据并行是最容易想到的并行方式。每个 GPU 分别计算不同的输入数据,计算各自的梯度(也就是模型参数的改变量),再把梯度汇总起来,取个平均值,广播给各个 GPU 分别更新(allreduce)。
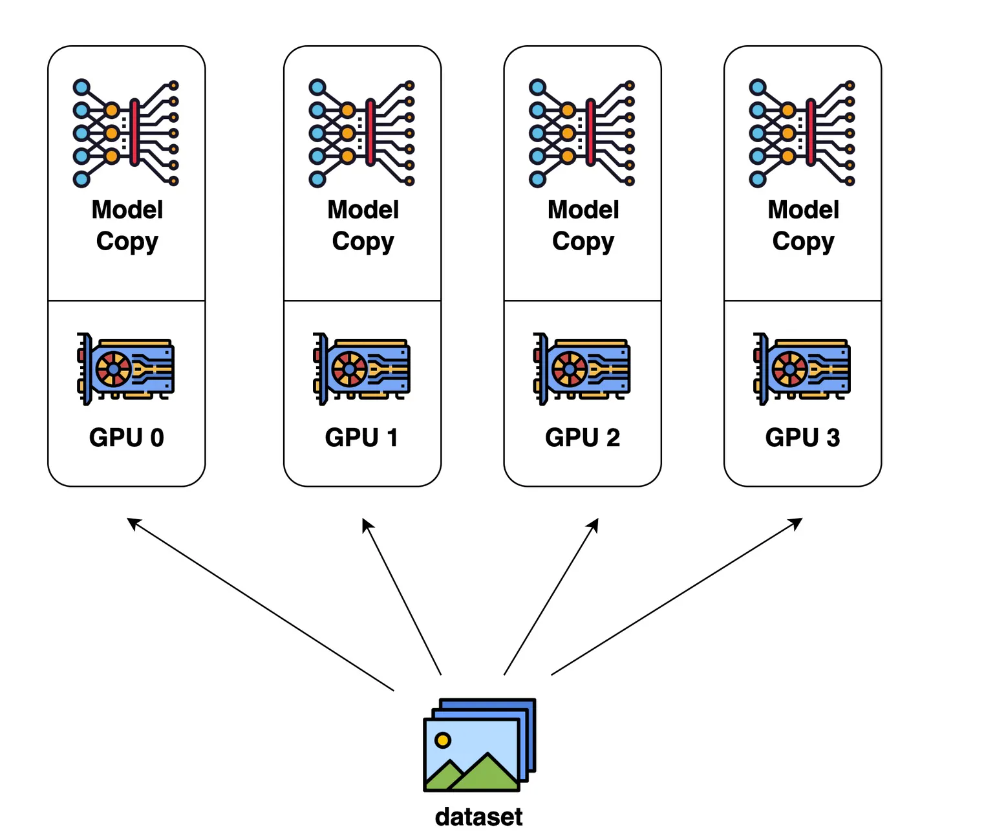
但只用数据并行是肯定不行的,因为一块 GPU 放不下整个 LLaMA 70B 模型。
就模型训练需要多少 GPU 内存呢?训练需要的内存包括模型参数、反向传播的梯度、优化器所用的内存、正向传播的中间状态(activation)。
Pipeline parallelism(流水线并行)
既然一块 GPU 放不下,用就需要多个GPU来放模型,即 model parallelism(模型并行),可以大致分为 pipeline parallelism 和 tensor parallelism。
pipeline parallelism,模型的层分成几组,每组算连续的几层,穿成一条链。
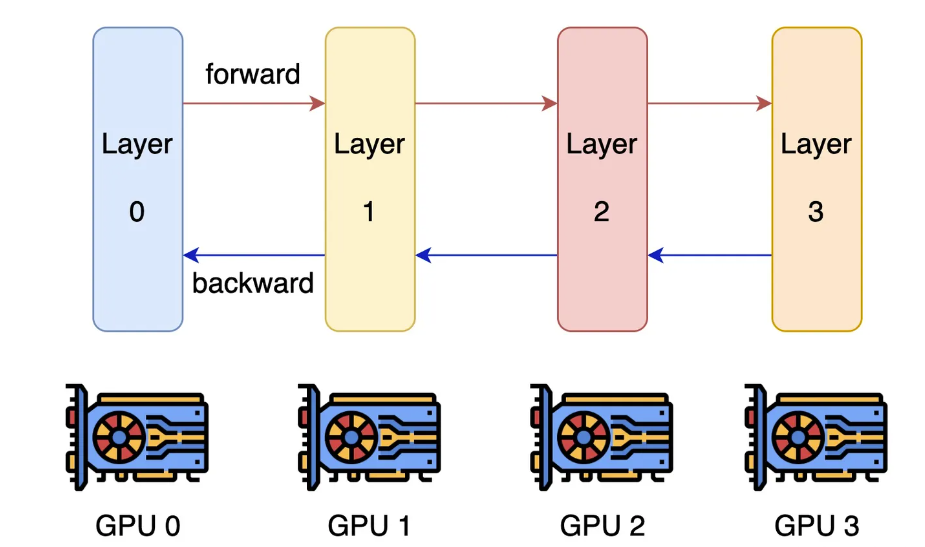
这样就有个问题,一条链上只有一个 GPU 在干活,剩下的都在干等。所以就需要把可以把一个 batch 分为若干个 mini-batch,每个 mini-batch 分别计算。
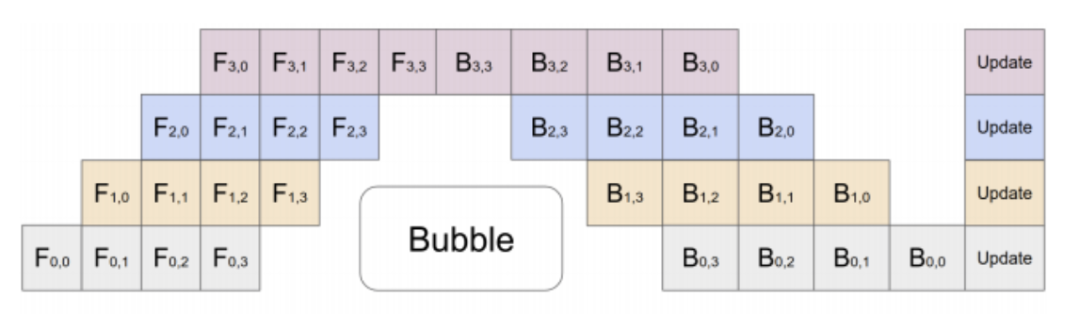
那么,是不是把 pipeline 搞的越深越好,每个 GPU 只算一层?
首先,正向传播中间状态(activation)的存储容量会成倍增加,加剧内存容量不足的问题。比如流水线的第一级算出了正向传播的中间状态,如果有 N 个流水级,那就要正向流过后面的 N - 1 个流水级,再等反向传播 N - 1 个流水级,也就是 2N - 2 轮之后才能用到这个正向传播的中间状态。不要忘了每一轮都会产生这么多中间状态,因此一共是保存了 2N - 1 个中间状态。如果 N 比较大,这个存储容量是非常恐怖的。
其次,pipeline 的相邻流水级(pipeline stage)之间是要通信的,级数越多,通信的总数据量和总时延就越高。
最后,要让这样的 pipeline 流起来,batch size 需要等于 Transformer 里面的层数,一般是几十,再乘以 data parallelism 的并行数,batch size 会很大,影响模型收敛的速度或模型收敛后的精度。
因此,在内存容量足够的情况下,最好还是少划分一些流水级。
对于 LLaMA-2 70B 模型,模型参数需要 140 GB,反向传播的梯度需要 140 GB,优化器的状态(如果用 Adam)需要 840 GB。
正向传播的中间状态跟 batch size 和选择性重新计算的配置有关,我们在算力和内存之间取一个折中,那么正向传播的中间状态需要 token 长度 * batch size * hidden layer 的神经元数量 * 层数 * (10 + 24/张量并行度) 字节。假设 batch size = 8,不用张量并行,那么 LLaMA-2 70B 模型的正向传播中间状态需要 4096 * 8 * 8192 * 80 * (10 + 24) byte = 730 GB,是不是很大?
总共需要 140 + 140 + 840 + 730 = 1850 GB,这可比单放模型参数的 140 GB 大多了。一张 A100/H100 卡也只有 80 GB 内存,这就至少要 24 张卡;如果用 4090,一张卡 24 GB 内存,就至少需要 78 张卡。
LLaMA-2 模型一共就只有 80 层,一张卡放一层,是不是正好?这样就有 80 个流水级,单是流水线并行就有 80 个并行的 batch 才能填满流水线。
这样,正向传播的中间状态存储就会大到无法忍受,这可是 80 * 2 = 160 轮的中间状态,翻了 160 倍。就算是使用选择性重新计算,比如把 80 层分成 8 组,每组 10 层,中间状态存储仍然是翻了 16 倍。
除非是用最极端的完全重新计算,反向传播到每一层都重新从头开始计算正向传播的中间结果,但这样计算开销可是随模型层数平方级别的增长,第 1 层算 1 层,第 2 层算 2 层,一直到第 80 层算 80 层,一共算了 3240 层,计算开销可是比正常算一次 80 层翻了 40 倍,这还能忍?
中间状态存储的问题就已经够大了,再看这 2048 张卡之间的通信开销。按照一张卡放一层,并且用不同的输入数据让它完全流水起来的做法,这 2048 张卡分别在计算自己的 mini-batch,可以认为是独立参与到 data parallelism 里面了。前面讲过,在数据并行中,每一轮需要传输的是它计算出的梯度和全局平均后的梯度,梯度的数据量就等于模型的参数数量。
把 70B 模型分成 80 层,每一层大约有 1B 参数,由于优化器用的是 32 bit 浮点数,这就需要传输 4 GB 数据。那么一轮计算需要多久呢?总的计算量 = batch size * token 数量 * 6 * 参数量 = 8 * 4096 * 6 * 1B = 196 Tflops,在 4090 上如果假定算力利用率 100%,只需要 0.6 秒。而通过 PCIe Gen4 传输这 4 GB 数据就已经至少需要 0.12 秒了,还需要传两遍,也就是先传梯度,再把平均梯度传过来,这 0.24 秒的时间相比 0.6 秒来说,是占了比较大的比例。
当然我们也可以做个优化,让每个 GPU 在 pipeline parallelism 中处理的 80 组梯度数据首先在内部做个聚合,这样理论上一个 training step 就需要 48 秒,通信占用的时间不到 1 秒,通信开销就可以接受了。当然,通信占用时间不到 1 秒的前提是机器上插了足够多的网卡,能够把 PCIe Gen4 的带宽都通过网络吐出去,否则网卡就成了瓶颈。假如一台机器上插了 8 块 GPU,这基本上需要 8 块 ConnectX-6 200 Gbps RDMA 网卡才能满足我们的需求。
最后再看 batch size,整个 2048 张卡的集群跑起来,每个 GPU 的 mini-batch 我们刚才设置为 8,那可真是 batch size = 16384,已经是大规模训练中比较大的 batch size 了,如果再大,可能就影响模型的收敛速度或收敛后的精度了。
因此,单纯使用流水线并行和数据并行训练大模型的最大问题在于流水线并行级数过多,导致正向传播中间状态(activation)存储容量不足。
Tensor parallelism(张量并行)
那就没办法了吗?我们还有最后一招,就是 Tensor parallelism(张量并行)。它也是模型并行的一种,但不像流水线并行那样是在模型的层间划分,而是在模型的层内划分,也就是把一层内的 attention 计算和 Feed Forward Network 划分到多个 GPU 上处理。
有了张量并行,就可以缓解 GPU 放不下模型导致的流水级太多的问题。分到 80 个 GPU 才能放下的模型,如果用单机 8 卡张量并行,就只需要划分 10 个流水级。同时,张量并行还可以降低 batch size,因为张量并行的几个 GPU 是在算同一个输入数据。
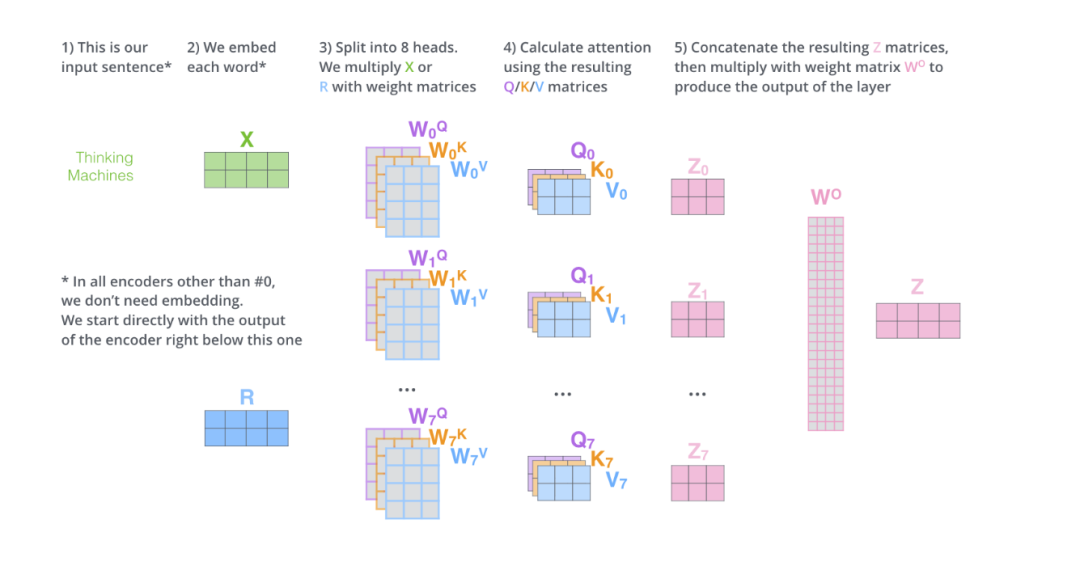
Attention 的计算过程是比较容易并行的,因为有多个 head,用来关注输入序列中的不同位置的,那么把这些 head 分别拆开就行了。
三、Batch size的公式
global_batch_size =
gradient_accumulation_steps
* nnodes (节点数)
* nproc_per_node (每个节点卡数)
* per_device_train_batch_si(micro bs大小)
我们想象一个场景:
假设情景:
-
batch_size = 10 #每批次大小
-
total_num = 1000 #数据总量
按照 训练一个批次数据,更新一次梯度;
训练步数 train_steps = 1000 / 10 = 100
梯度更新步数 = 1000 / 10 = 100
当显存不足以支持每次 10 的训练量!需要减小 batch_size
通过设置gradient_accumulation_steps = 2
batch_size = 10 / 2 =5
即训练2个批次数据,更新一次梯度,每个批次数据量为5(减小了显存压力,但未改变梯度更新数据量–10个数据一更新)
结果:训练步数 tran_steps = 1000 / 5 = 200 增加了一倍
梯度更新步数 1000 / 10 = 100 未改变
总结:梯度累加就是,每获取1个batch的数据,计算一次梯度,梯度不清空,不断累加,累加到gradient_accumulation_steps次数后,根据累加梯度更新参数,清空梯度,进行下一次循环。
在显存不足以支持每次10的训练量的情况下,直接将batch size调小是一个可行的解决方案,但需要考虑以下几点:
直接调小Batch Size的影响
- 训练稳定性:
- 较小的batch size可能会导致梯度估计的方差增大,从而使训练过程变得不稳定。较大的batch size通常能提供更稳定的梯度估计。
- 训练时间:
- 较小的batch size意味着每次更新参数所需的训练步数会增加,从而可能导致训练时间变长。
- 学习率调整:
- 较小的batch size可能需要调整学习率。通常情况下,较小的batch size需要较小的学习率,以避免梯度更新过大导致训练不稳定。
使用梯度累加的优势
相比直接调小batch size,使用梯度累加(Gradient Accumulation)有以下优势:
- 保持有效批次大小:
- 通过梯度累加,可以在显存有限的情况下,保持较大的有效批次大小,从而获得更稳定的梯度估计。
- 减少训练步数:
- 梯度累加可以减少训练步数,因为每次参数更新仍然基于较大的有效批次大小。
零基础入门AI大模型
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以点击下方链接免费领取🆓
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
资料领取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击下方链接免费领取【保证100%免费】


















 1844
1844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









