







联邦学习联邦学习DLG攻击_NeurIPS2019_Deep Leakage from Gradients_深度梯度泄露
发现了梯度可以倒推参数的问题
要开始看些安全的内容了!
那就都记录在这里!
一、Abstract
- 发现可以 从公开共享的梯度中获得私有的训练数据
- 把这个缺陷叫做 Deep Leakage from Gradients
- 同时发现:在不改变训练设置的情况下,最有效的防御方法是梯度修剪
二、Introduction
2.1 联邦学习的背景:
- 分布式训练是加快大规模数据集训练速度的必要条件
- 划分client和server,本地训练,传递梯度或者参数,云端聚合
- 保持了数据之间相互独立,得到广泛使用
2.2 提出疑问:「梯度共用」计划有否保障每名参加者的训练资料集的私隐?
- 大多数场景中,假设梯度共享是安全的,并且不会暴露训练数据
- 但是,最近的一些个研究:
- 梯度揭示了训练数据的一些属性
- property classifier (具有某些属性的样本是否在批处理中) ,并使用生成对抗网络来生成与训练图像相似的图片
- 证明 从梯度中完全窃取训练数据 是可行的
2.3 DLG : 共享梯度可以泄漏私有的训练数据
- 提出了一个优化算法:
- 仅仅几轮迭代,便可以获得训练的输入数据和标签
- 首先,随机生成一对“虚拟”输入和标签
- 然后,执行通常的正向和反向操作
- 在从虚拟数据推导出虚拟梯度之后,优化虚拟输入和标签,以最小化虚拟梯度和实际梯度之间的距离,而不是像典型的训练那样优化模型权重
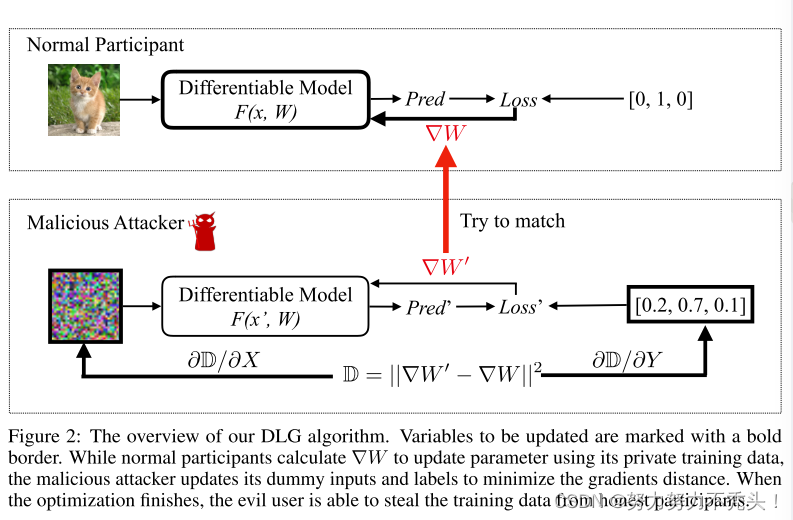
- 匹配的梯度使虚拟数据接近原始数据
- 当优化完成后,私有的训练数据(包括输入和标签)将完全显示
2.4 DLG特点
- DLG不需要额外的训练集先验知识
- 可以从共享梯度中推断标签,并且DLG产生的结果(图像和文本)是确切的原始训练样本,而不是合成的外观相似的替代品
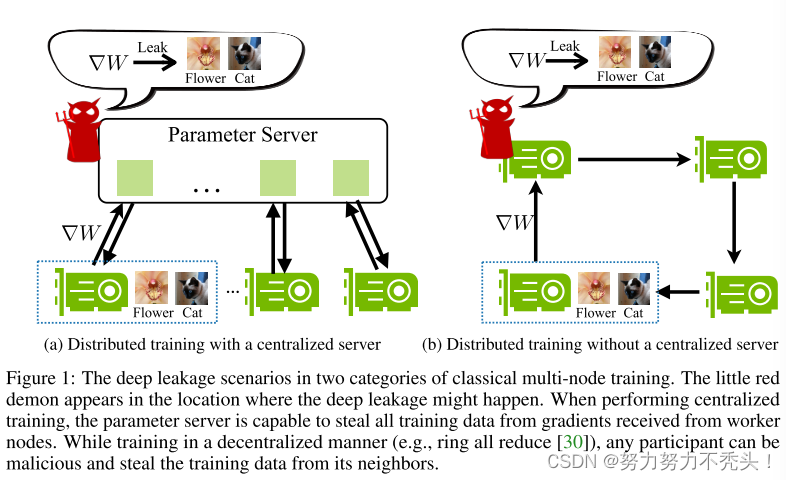
2.5 DLG提出背景(集中式和分散式均会泄露)
- 集中式分布式训练中,通常不存储任何训练数据的参数服务器能够窃取所有参与者的本地训练数据
- 对于分散式分布式训练,情况变得更糟,因为任何参与者都可以窃取其邻居的私人训练数据
- 为了防止深度泄漏,三种防御策略下进行实验:梯度扰动,低精度和梯度压缩
2.6 文章贡献
- 证明了从公开共享的梯度中获得私有训练数据是可能的。DLG是第一个实现它的算法
- DLG只需要梯度,可以显示像素级精确图像和标记级匹配文本。而传统的方法通常需要额外的信息来攻击,并且只能产生部分属性或合成替代品
- 为了防止重要数据的潜在泄漏,我们分析了各种设置下的攻击难点,并讨论了几种防御策略
三、Related Work
3.1 分布式训练 Distributed Training
分布式背景+联邦学习出现背景
3.2 "浅层"泄漏 “Shallow” Leakage from Gradients
- 以往的研究工作对如何从梯度中推断训练数据的信息做了一些探索
- 对于某些层,梯度已经泄漏了一定程度的信息
- embedding层仅为训练数据中出现的单词产生梯度,这揭示了其他参与者的训练集中使用了哪些单词
- 但这种泄漏是“浅”的:泄漏的单词是无序的,由于歧义,很难推断出原文的句子
- 全连接层,其中梯度更新的观察可以用于推断输出特征值
- 然而,这不能扩展到卷积层,因为特征的大小远远大于权重的大小。
- embedding层仅为训练数据中出现的单词产生梯度,这揭示了其他参与者的训练集中使用了哪些单词
- 最近的一些工作开发了基于学习的方法来推断批次的属性。
- 二元分类器可以记录batch内的一些信息
- 使用GAN模型合成图像,使其看起来与梯度的训练数据相似,但攻击是有限的,并且仅在所有类成员看起来相似时才有效
四、Method
- 证明了从梯度中窃取图像像素和句子标记是可能的
4.1 方法概述
本质是通过不断更新 真实梯度和虚假梯度的距离差 ,让当前距离最小化,来获得推理出的训练数据
4.2 DLG算法概述
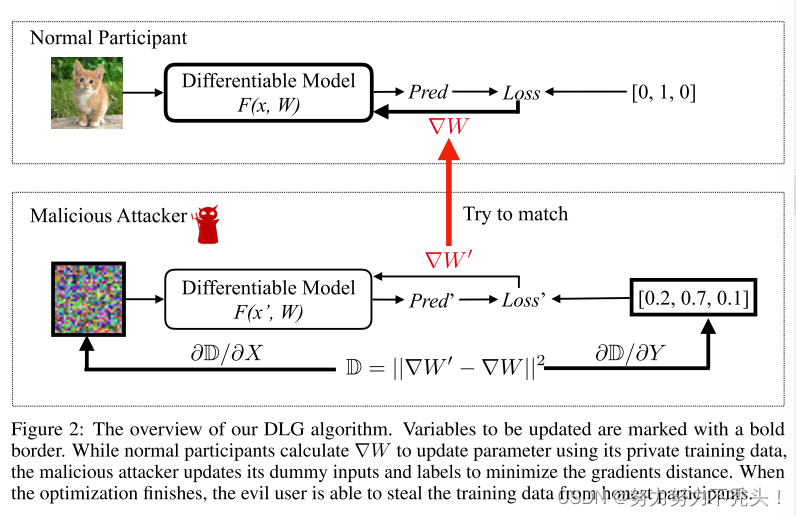
- 要更新的变量用粗体边框标记
- 当正常参与者使用其私有训练数据来计算梯度以更新参数时,恶意攻击者通过最小化梯度距离来更新虚拟输入和标签
- 当优化完成时,邪恶的用户能够从诚实的参与者那里窃取训练数据
4.3 DLG算法伪代码

4.4 方法详解
4.4.1 梯度计算
x_t,i 和 y_t,i 分别表示原始数据和对应的 one-hot 标签,W为模型参数
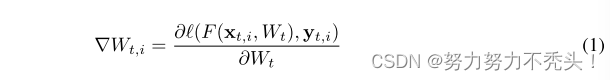
4.4.2 server端进行梯度平均
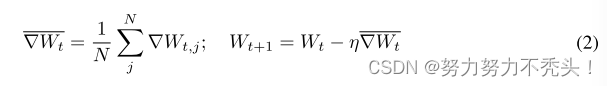
- 目标是:窃取 client k 上的梯度,进而推断出来训练数据
4.4.3 初始化虚假 data 和 label
- 随机初始化一个伪输入x和标签输入y(伪代码 line 2)

4.4.4 获得虚假梯度
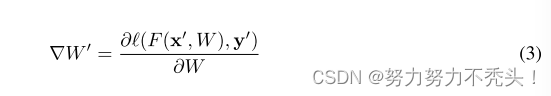
4.4.5 最小化梯度距离,获取训练数据
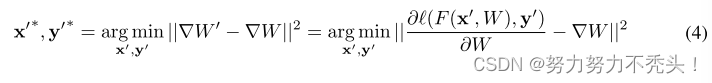

















 3138
3138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









