







 本文提出了一种针对联邦学习的客户端隐私泄漏(CPL)攻击框架。该框架能够通过分析客户端上传的参数更新来重建其私有训练数据,揭示了不同设置下攻击的有效性和成本。此外,文章还探讨了几种潜在的防御策略。
本文提出了一种针对联邦学习的客户端隐私泄漏(CPL)攻击框架。该框架能够通过分析客户端上传的参数更新来重建其私有训练数据,揭示了不同设置下攻击的有效性和成本。此外,文章还探讨了几种潜在的防御策略。
摘要
联合学习(FL)是一个新兴的分布式机器学习框架,用于与客户网络(边缘设备)进行协作式模型训练。联合学习允许客户将其敏感数据保存在本地设备上,并且只与联合服务器共享本地训练参数更新,从而默认客户隐私。然而,最近的研究表明,即使是将本地参数更新从客户端分享到联合服务器,也可能会受到梯度泄漏攻击,并侵犯客户端关于其训练数据的隐私。在本文中,我们提出了一个原则性的框架来评估和比较不同形式的客户端隐私泄露攻击。我们首先提供了形式上的和实验上的分析,表明对手如何通过简单地分析本地训练的共享参数更新(如本地梯度或权重更新向量)来重建私有的本地训练数据。然后,我们分析了联合学习中不同的超参数配置和不同的攻击算法设置如何影响攻击的有效性和攻击成本。我们的框架还测量、评估和分析了在使用通信高效 FL协议时,不同梯度压缩率下的客户端隐私泄漏攻击的有效性。我们的实验还包括一些初步的缓解策略,以强调提供一个系统的攻击评估框架的重要性,以深入了解联合学习中各种形式的客户端隐私泄漏威胁,并为攻击缓解奠定理论基础。
主要内容
这篇文章主要阐述了一个CPL(client privacy leakage)的隐私泄漏的攻击方法,并且由于敌手座位一个FL的参与者,知道模型的参数,故进行白盒攻击
伪代码

第4-6行将权重更新转换为梯度值
第9行是为了从实际的梯度共享中获得标签从本地训练中获取标签。
第10-14行介绍了迭代重建过程,该过程产生了基于客户端梯度更新的重建私有训练数据。
由于对训练输入数据的真实标签的局部训练更新与其他标签相比应该是最积极的(最积极的 也可以说是最正面的),所以私有数据集中数据的真实标签的梯度符号将与其他类不同,其绝对值通常是最大的。(PS:在机器学习的过程中,正确的和错误的内容产生的梯度通常是差别很大的)
其实这个攻击就是先搞一个分辨率和别的训练集的图片一样的图片,然后用模型训练这个图片,将得到的梯度和别人用正确图片训练出来的梯度进行比较,然后得到一个距离的差值,然后不断地添加扰动,来改进这个差值,最后当差值收敛的时候,证明咱的图片也训练好了,因为咱的图片和别人的图片在这个模型中的梯度是几乎一致的了。
本文的框架将研究FL超参数的不同配置对隐私泄露攻击的成功率和成本的影响。
值得注意的是,即使客户端和服务器之间的网络连接是安全的,在本地参数更新准备上传到服务器之前,客户端隐私泄露攻击也可能发生在被攻击的客户端上。(原文提到的,具体我也没搞明白他是怎么在上传之前泄漏的,可能是在上传之前也能接触到其他人的梯度,我觉得可能是因为FL是一个多客户端一起训练的内容,故不一定需要使用某个人的梯度,可以直接使用之前已经产生的模型来推测你的私有数据集)
不同设定对于CPL攻击的影响
不同的初始化
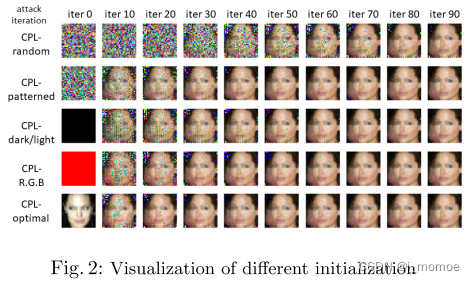
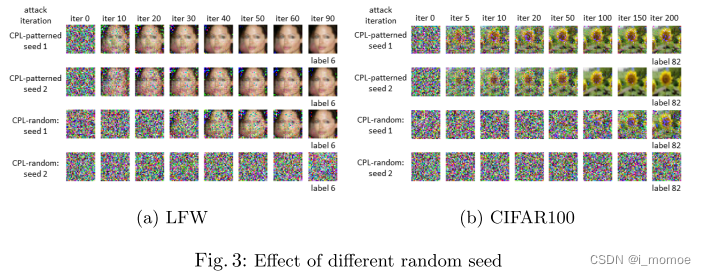
不同的随机种子
不同的攻击终止条件
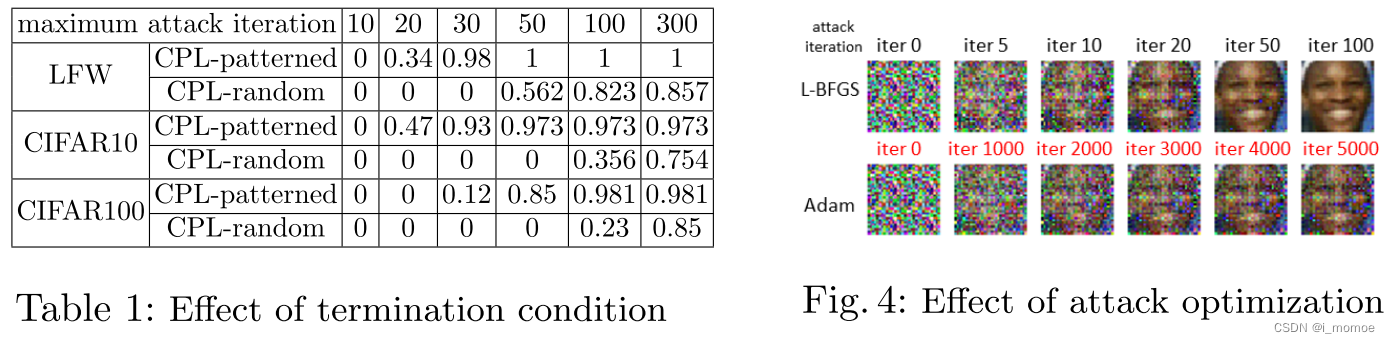
在任何情况下,迭代次数的增加都会增加攻击的成功率,因此在所有情况下,我们只要寻找一个迭代次数使成功率上升至我们能接受的情况下,而初始化的设定就会关系到迭代的次数,所以本质上还是选择初始化方法然后根据不同的初始化方法选择适当的迭代次数就可以了
不同的损失函数
部分损失函数会使训练变的慢
不同的攻击优化
虽然一阶优化技术易于计算且耗时较少,但二阶技术在摆脱鞍点周围的缓慢收敛路径方面效果更好
不同的 batch size

batchsize = 1时效果最好,且当数据集的类间差距较小时,效果较好
不同的图片分辨率
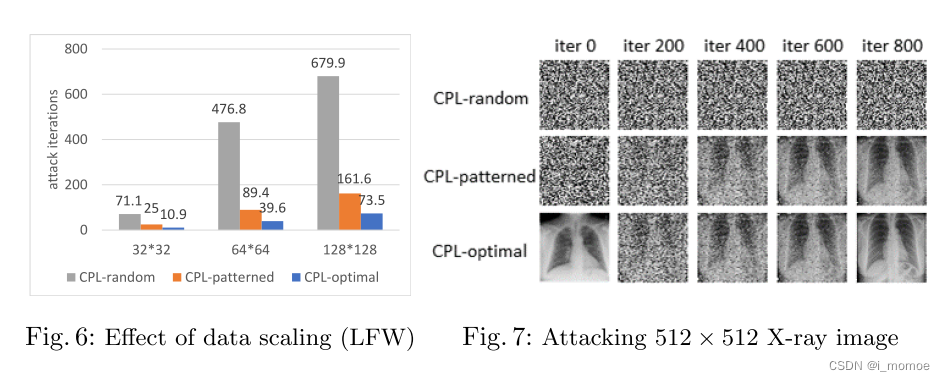
明显的,分辨率越小迭代的次数越少,训练的速度越快
不同的激活函数
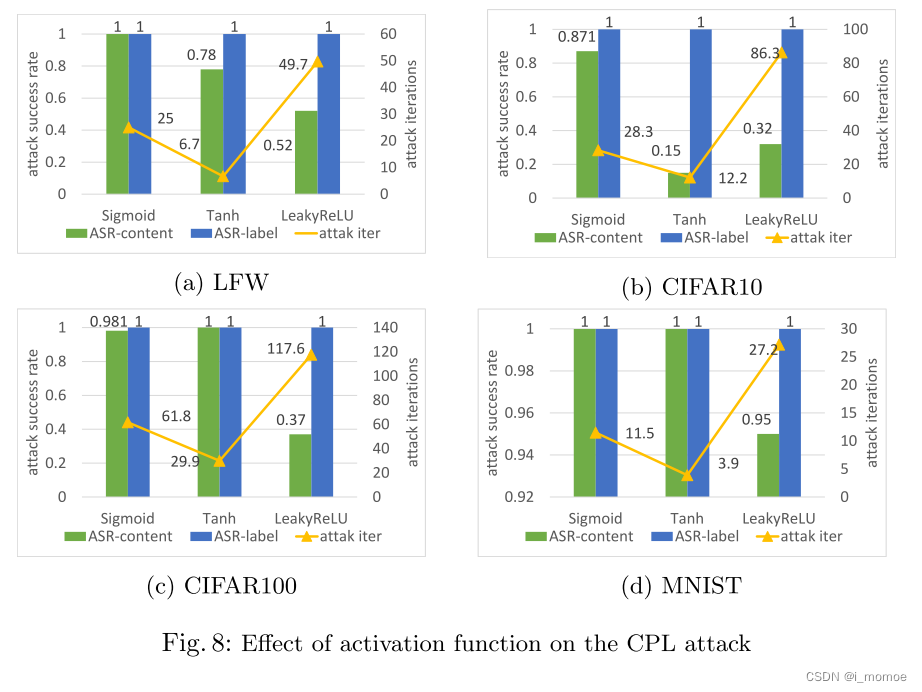
这里很清楚的表明了激活函数会影响CPL攻击的成功率,并且通过对激活函数的比较和理论知识,得出,当我们影响了梯度的完整性和唯一性的时候,都能影响CPL攻击的成功率
我们观察到,ReLU自然会阻止使用梯度对训练数据进行全面重建,因为ReLU的负部分的梯度将为0,即那部分可训练的参数将停止对误差的变化做出反应,在优化过程中不会得到调整。这个垂死的ReLU问题剔除了CPL攻击所需的梯度信息。相比之下,Sigmoid和Tanh都是diff定的双射,可以以几乎无损的方式将梯度从一层传到另一层。LeakyReLU为ReLU的负数部分设置了一条略微倾斜的线,以减轻垂死的ReLU的问题,因此容易受到CPL攻击。
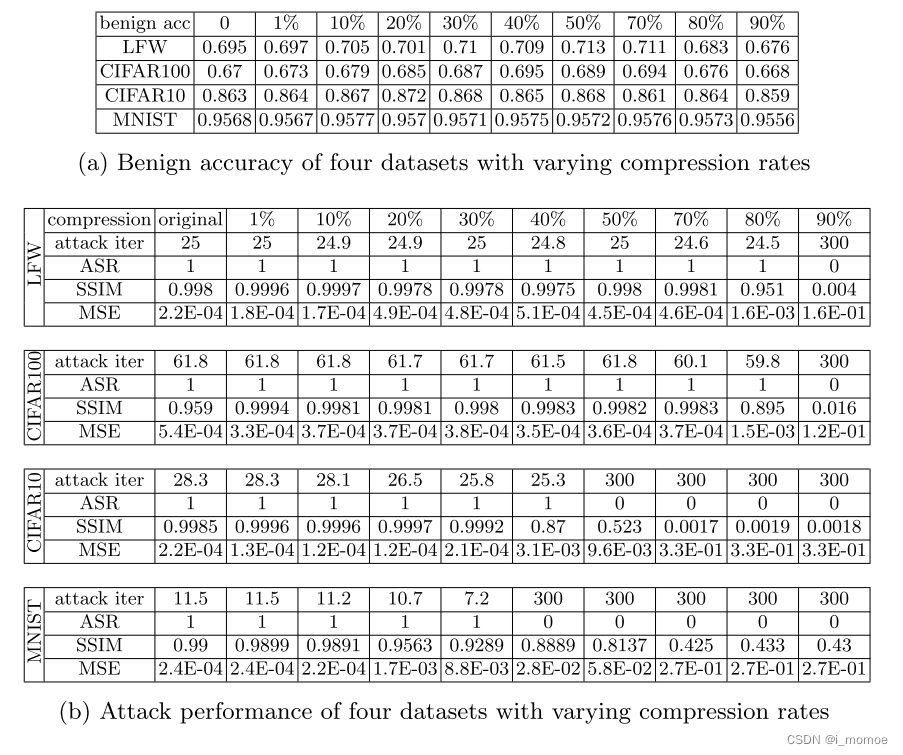
不同的压缩率

攻击评价度量(4种)
-
Attack success rate (ASR)
-
MSE
使用均方根偏差来衡量重建的输入x rec和真实输入x之间的相似度
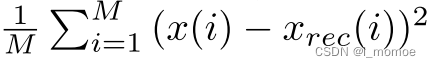
-
SSIM
衡量两个图像之间的结构相似性是基于感知的模型[Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)],该模型认为图像退化是感知的变化
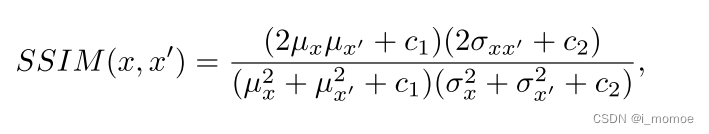
其中μ x和μ x0是x和x 0的平均值,σ 2 x和σ 2 x0是x和x 0的方差,σ xy是x和x 0的协方差
SSIM越接近1,图像重建方面的攻击质量就越好。SSIM的设计是为了改进传统的方法,如图像相似性的MSE。
-
Attack iteration
总体表现出本文的CPL攻击模式优于深度梯度攻击以及梯度倒置攻击,并且表现出CPL更快、更有效、成功率更高、迭代次数更少,与此同时SSIM很高(为1最好)、MSE很低,表明重建数据的质量与私有训练数据几乎相同
一部分情况下(如下图),压缩率增大时,迭代次数反而在下降,这说明在梯度中有很多是非必要(不重要)的内容CPL方法在类很多的时候效果可能会更好,一种可能的原因是:因为当有很多类时,信息的梯度会更集中
文中给出的防御方法
1.加噪声(高斯噪声 / 拉普拉斯噪声)
2.本地多迭代几次,并将最后一次迭代的梯度进行上传,也就是说不是每次迭代的梯度数据都上传

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









