







目录
zero-shot learning 相比传统监督学习优点:
机器学习任务按照对 样本量 的需求可以分为:传统监督式学习、Few-shot Learning、One-shot Learning、Zero-shot Learning。
Zero Shot、Few Shot、One Shot 技术的出现,主要是为了解决传统深度学习方法在数据不足或目标任务变化时的不足。 在传统的深度学习中,需要大量的带标注样本数据来训练模型,这对于一些特定场景来说是非常困难和耗费时间的。例如,当我们面对一些新的类别或任务时,我们可能无法获得充足的带标注数据。此时,使用传统的深度学习方法可能会导致模型表现不佳。

一、传统监督式学习
传统learning,炼丹模式。传统深度学习的学习速度慢,往往需要学习海量数据和反复训练后才能使网络模型具备不错的泛化能力,传统learning可以总结为:海量数据 + 反复训练(炼丹模式)。
二、Zero-shot learning
定义:
Zero-shot 学习指模型仅通过任务描述(Task Description)理解任务,并在没有任何示例的情况下预测输出结果。它完全依赖于预训练阶段中学习到的通用知识,不需要针对具体任务的额外数据。
它是一种机器学习方法,它可以对新的分类进行分类,即使在训练数据中没有这些分类的任何示例。换句话说,它可以在测试时识别出训练数据中没有见过的类别。
人类学习的过程包含了大量零样本学习的思路,也就是说一个小孩子从来没见过一些类别的东西,在家长和老师的描述之后,他也能在一堆图片里找出那件东西。在2016 年中国计算机大会上,谭铁牛院士指出,生物启发的模式识别是一个非常值得关注的研究方向,“比如人识别一个动物(并不需要看到过该动物),只需要一句话的描述就能识别出来该动物”,比如被广泛引用的人类识别斑马的例子:假设一个人从来没有见过斑马这种动物,即斑马对这个人来说是未见类别,但他知道斑马是一种身上有着像熊猫一样的黑白颜色的、像老虎一样的条纹的、外形像马的动物,即熊猫、老虎、马是已见类别。那么当他第一次看到斑马的时候, 可以通过先验知识和已见类,识别出这是斑马。人类通过语义知识作为辅助信息,识别了未见类,零样本学习也正是基于这样的思想、基于人类学习过程,进行算法的研究。
虽然物体的类别不同,但是物体间存在相同的属性,提炼出每一类别对应的属性并利用若干个学习器学习。在测试时对测试数据的属性预测,再将预测出的属性组合,对应到类别,实现对测试数据的类别预测。

zero-shot learning 相比传统监督学习优点:
- 不需要重新收集和标注大量数据就可以进行新的分类任务。这在实践中非常重要,因为数据收集和标注都需要投入大量人力和时间。
- 可以应对数据集中的类别失衡问题。因为它不依赖于大量的训练示例,所以即使某个类别的数据很少,也可以进行分类。
- 有利于应对数据集中的长尾分布。对长尾分类也可以进行比较准确的预测,因为预测更加依赖于语义空间中的关联,而不是训练示例的数量。
长尾分布: 在一个典型的长尾分布中,数据集中存在少数出现频率极高的 “头部” 数据,这些数据占据了大部分的出现次数或比例。然而,除了头部数据外,还有大量频率极低但种类繁多的 “尾部” 数据,这些数据虽然单个出现的频率很低,但它们的总体数量却非常庞大,使得分布的尾部拖得很长,就像一条长长的尾巴,这也是 “长尾分布” 名称的由来。
特点:
-
无示例:模型仅通过任务描述执行推理。
-
广泛适用:适合没有标注数据的新任务。
-
性能受限:对复杂任务的预测准确率较低。
与one-shot区别:

三、Few-shot learning
基本思想:

few shot learning的目标是让机器自己学会学习。可以这么理解,我拿一个很大的数据集来训练神经网络,学习的目的不是让模型知道什么是大象,什么是老虎,并不是让模型学会识别没见过的大象和老虎,学习的目的是让模型理解事物的异同,学会区分不同的事物。给两张图片,不是让模型识别出两张图片是什么,而是让模型知道两张图片里面是相同的东西还是不同 的东西。
详细介绍:

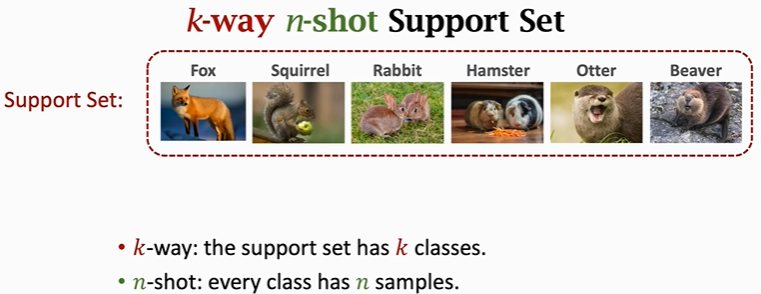
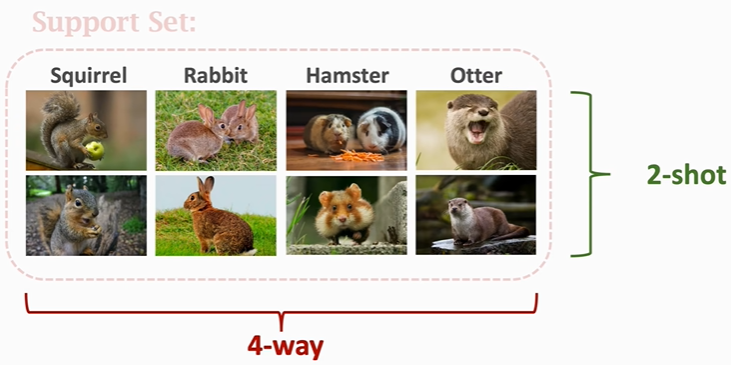
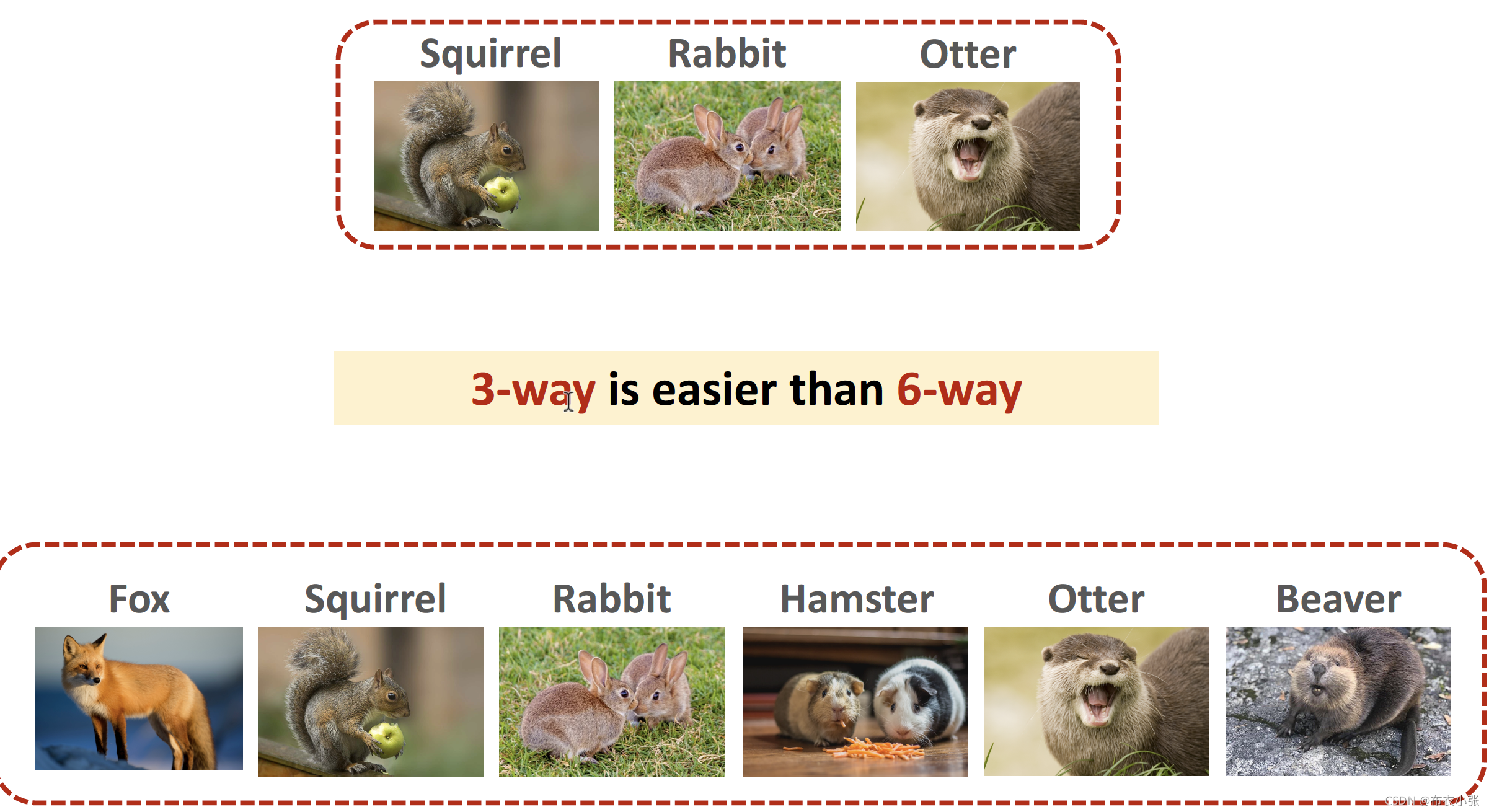
Support set指的是一个很小的数据集,比如有六类,里面有一张图片。把这些带标签的图片称为support set。
注意support set和训练集的区别: 训练集规模很大,每一类下面都有很多张图片,由于训练集足够大,所以可以用来训练一个深度神经网络,相比之下Support set很小,每一类下面只有一张或者几张图片,根本不足以训练一个大的神经网络,Support set只能在做预测的时候提供一些额外信息!用足够大的训练集来训练一个大模型,比如深度神经网络,训练的目的不是让模型来识别训练集里的大象老虎,而是让模型知道事物之间的异同,现在靠Support set提供了一点点信息,模型就能判断出query图片是水獭,尽管训练集里面没有水獭这个类别。


培养小朋友自主学习就是meta learning
监督学习和few shot learning区别:
监督学习是训练模型让模型知道这个类是什么?而少样本学习是让模型学会不同类的区别,根据support set 能快速对照未见过图像的类别。



四、One-shot learning
如果训练集当中,不同类别的样本只有一个,则成为One-shot learning.
One-shot learning 属于Few-shot learning的一种特殊情况。


















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









