






1、word2vec简介
word2vec是Google研究团队里的Tomas Mikolov等人于2013年的《Distributed Representations ofWords and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,基本出发点和Distributed representation类似:上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。
word2vec在 2018 年之前非常流行,但是随着 BERT、GPT2.0 等方法的出现,这种方式已经不算效果最好的方法了。
2、word2vec中的基本概念
word2vec的基本思想:
句子之中相近的词之间是有联系的,比如今天后面经常出现上午、下午。所以它的基本思想就是用词来预测词。(准确的说,word2vec仍然是一种编码方式,将一个个的词给编码成向量,但是被他编码而成的向量并不是随便生成的,而是能够体现这些单词之间的关系(如相似性等))
word2vec主要包含两个模型:
跳字模型(skip-gram):
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
连续词袋模型(CBOW,continuous bag of words):
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

两种训练加速方法:
负采样
层次softmax。
3、Skip-gram(跳字模型)
接下来我们具体看一看word2vec中的跳字模型是如何实现的:
跳字模型的概念是在每一次迭代中都取一个词作为中心词汇,尝试去预测它一定范围内的上下文词汇。
所以这个模型定义了一个概率分布:给定一个中心词,某个单词在它上下文中出现的概率。我们会选取词汇的向量表示,从而让概率分布值最大化。重要的是,这个模型对于一个词汇,有且只有一个概率分布,这个概率分布就是输出,也就是出现在中心词周围上下词的一个输出。

拿到一个文本,遍历文本中所有的位置,对于文本中的每个位置,我们都会定义一个围绕中心词汇大小为2m的窗口,这样就得到了一个概率分布,可以根据中心词汇给出其上下文词汇出现的概率。
重点:
如上例中,我们已经得到了一个句子:problems turning into banking crises。现在我们记”into“这个词的位置为t,那么"into"这个词用wt表示。”problems“、”turing“、”banking“、"crises"分别表示为wt-2,wt-1,wt+1,wt+2。
那么在已知 “into" 这个词的情况下, ”problems“、”turing“、”banking“、"crises"这四个词出现的条件概率可以表示为P(wt-2|wt),P(wt-1|wt),P(wt+1|wt),P(wt+2|wt)。
现在这个已知的句子就是我们的一个样本,我们要进行第一次迭代,在迭代的过程中,我们的损失函数(或者说目标函数)是这个函数:
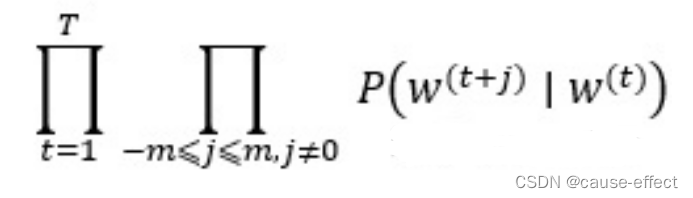
该函数又称为似然函数,这里表示在给定中心词的情况下,在2m窗口内的所有其他词出现的概率(T表示词库里所有词的总数)。我们的目标是要通过调节参数,从而最大化这个函数(因为这个函数越大,表示与实际情况越吻合)。(注意:这里假设给定中心词的情况下背景词的生成相互独立)
另外,根据平时的习惯,我们通常喜欢最小化损失函数,而不是最大化损失函数。因此我们对该函数取负对数,且除以T,得到新的损失函数(对数似然函数):
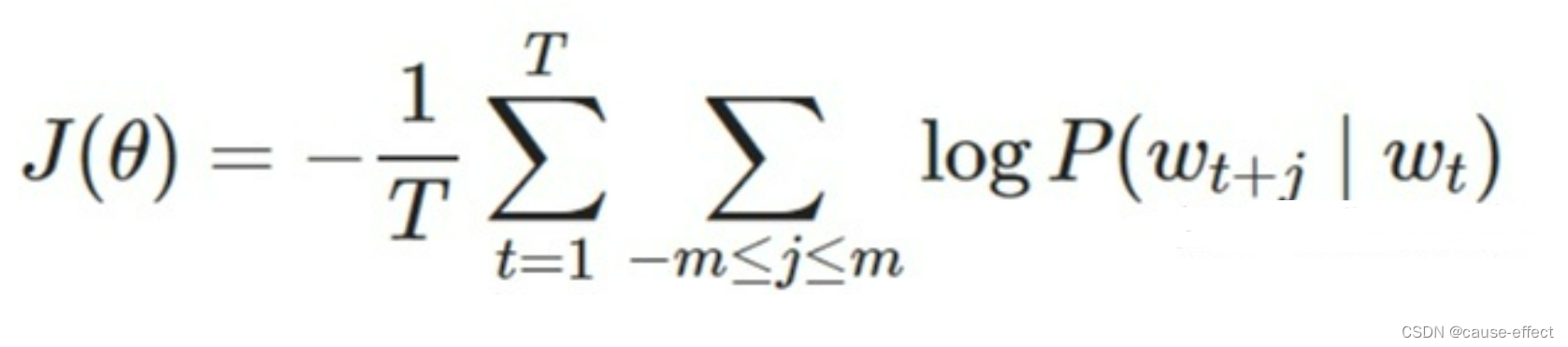
该函数又称为似然函数,这里表示在给定中心词的情况下,在2m窗口内的所有其他词出现的概率(T表示词库里所有词的总数)。我们的目标是要通过调节参数,从而最大化这个函数(因为这个函数越大,表示与实际情况越吻合)。(注意:这里假设给定中心词的情况下背景词的生成相互独立)
另外,根据平时的习惯,我们通常喜欢最小化损失函数,而不是最大化损失函数。因此我们对该函数取负对数,且除以T,得到新的损失函数(对数似然函数):
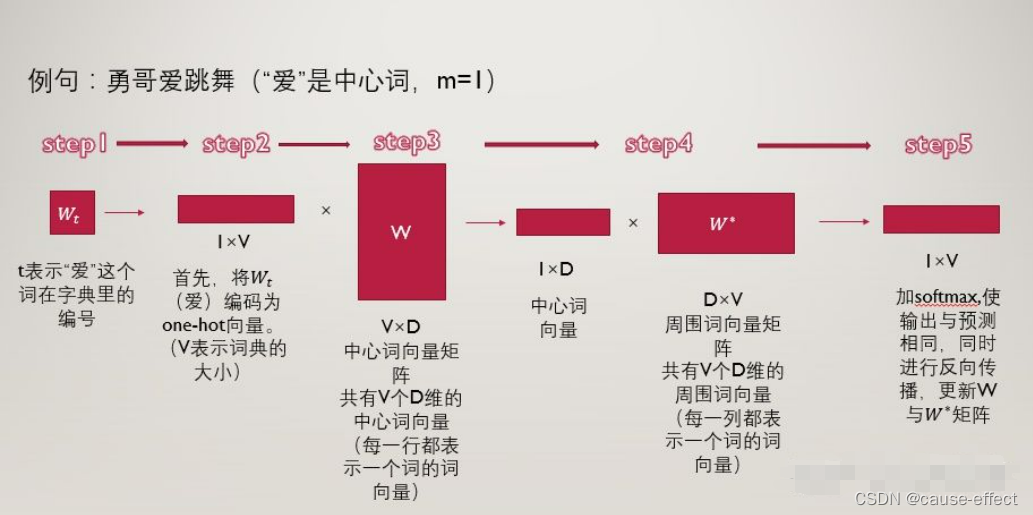
例句为”勇哥爱跳舞“,中心词取”爱“,步长m取1,也就是范围内的词为“勇哥”和“跳舞”。
第一步 :t表示“爱”这个词在词典中的位置,那么“爱”用wt表示,“勇哥”用wt-1表示,“跳舞”用wt+1表示。
第二步:将“爱”这个词首先表示为one-hot编码,方便进行后续的矩阵操作。
接下来我们构建两个参数矩阵,分别为中心词矩阵和周围词矩阵,这两个矩阵分别是V×D维和D×V维,其中V表示词典的大小,D表示我们要构建的词向量的维度,是一个超参数,我们暂时认为其是固定的,不去管它。
以中心词矩阵为例,其为V×D维的,而我们的词表里一共有V个词,也就是说,该矩阵的每一行都表示一个单词的中心词向量(低维、稠密的),同理,周围词向量矩阵是D×V维的,每一列表示一个单词的周围词向量表示。
了解了中心词向量和周围词向量的概念后,我们来看第三步:
第三步:用第二步中的得到的,“爱”的one-hot编码乘以中心词向量矩阵W,得到一个1×D维的向量,这个向量可以认为是该词的中心词向量表示。
第四步:用该中心词向量乘以周围词向量矩阵w*,该步骤可以理解为对于“爱”这个词,我们分别与每一个词作内积,最终得到的1×V向量中的每一个元素,便是该位置的词与“爱”这个词的内积大小。
第五步:对于最终的得到的向量,我们再进一步的做softmax归一化,归一化之后的概率越大,表示该词与“爱”的相关性越大,现在我们的目标就是要使得:“勇哥”这个词的概率较大,我们如何去实现这个目标呢?那就是通过调整参数矩阵w和w*,(这里就可以明白这两个矩阵其实只是辅助矩阵,我们根据损失函数,使用反向传播算法来对参数矩阵进行调节,最终实现损失函数的最小化。
小tip:对于“爱”这个词,我们要迭代两次,第一次是使得“勇哥”这个词的概率尽量大,第二次使得“跳舞”这个词的概率尽量大。然后“爱”这个词迭代完了之后,我们再去遍历这个词表里的所有词,通过一次次的迭代,逐步降低损失函数。
提问:为什么一个词汇要用两种向量表示(中心词向量和背景词向量)?
1:数学上处理更加简单
让每个单词用两个向量表示,这两个表示是相互独立的,所以在做优化的时候,他们不会相互耦合,让数学处理更加简单。
2:实际效果更好
如果每个单词用一个向量来表示,那么中心词预测下一个词是自己本身的概率就会很大,因为我们是向量内积来定义;两个单词之间的相似性。所以用两种向量表示在通过效果上会比一种向量表示更好。
在训练结束后,对于词典中任一索引为i的词,我们都会得到两组词向量,在自然语言处理应用中,一般使用跳字模型的中心词向量作为词的表征向量。
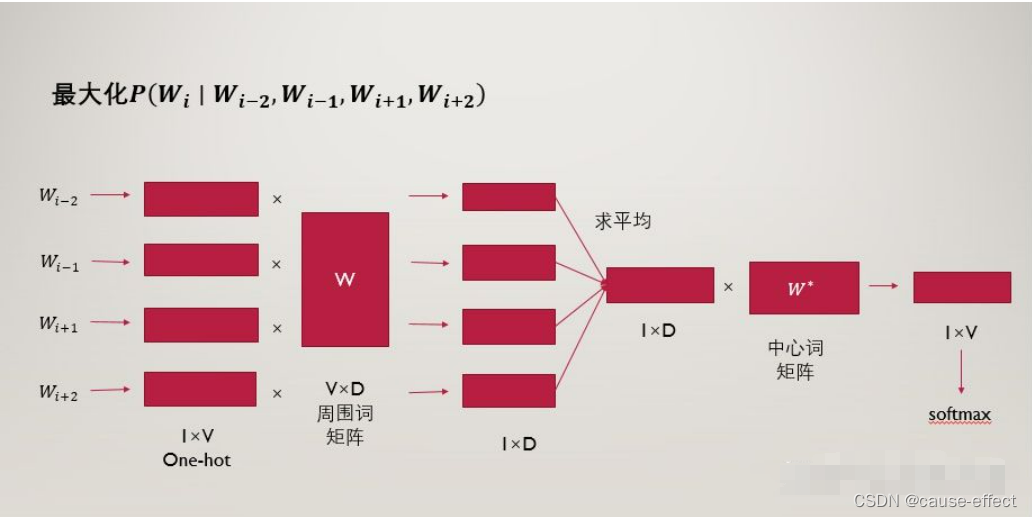
4、CBOW(连续词袋模型)
连续词袋模型与跳字模型类似,最大的不同在于,连续词袋模型假设基于某中心词在文本序列前后的背景词来生成该中心词。
例如:‘我’,‘爱’,‘红色’,‘这片’,‘土地’,窗口大小为2,就是用‘我’,‘爱’,‘这片’,‘土地’这四个背景词,来预测生成 ‘红色’ 这个中心词的条件概率,即:
P(红色|我,爱,这片,土地)
给定一个长度为T的文本序列,设时间步t的词为W(t),背景窗口大小为m。则连续词袋模型的目标函数(损失函数)是由背景词生成任一中心词的概率。
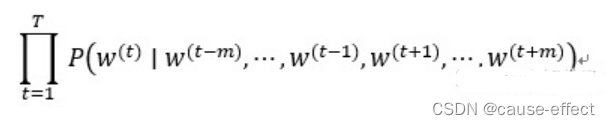
因为连续词袋模型的背景词有多个,我们将这些背景词向量取平均,然后使用和跳字模型一样的方法来计算条件概率。
具体步骤图解:















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









