







文章目录
基本概念
-
极限学习机,又称“超限学习机” -
极限学习机(Extreme Learning Machine,简称ELM)是一种
人工神经网络学习算法,由黄广斌教授于2006年提出。 -
它属于
前馈神经网络(Feedforward Neural Networks)的一种,尤其以其快速的学习速度和相对简单的实现过程而著称。 -
与传统的多层感知机或深度学习模型使用反向传播算法来迭代调整网络中所有权重
不同,ELM的主要特点包括:
-
随机初始化隐层权重:ELM的核心创新在于其
隐层节点的输入权重和偏置值是随机或者人为设定的,并且在整个学习过程中保持不变。这与需要通过迭代不断优化权重的常规神经网络算法有显著区别。 -
仅优化输出层权重:学习过程主要集中在计算
输出层的权重上,通常通过解线性方程组或使用最小二乘等方法一次性完成,而不是反复迭代,从而大大加快了学习速度。 -
广泛适用性:ELM既可以应用于
监督学习任务,如分类和回归,也适用于某些非监督学习场景。它在计算机视觉、生物信息学、环境科学等领域都有应用实例。 -
泛化性能:尽管其权重初始化是随机的,但研究表明,在很多情况下ELM仍能展现出良好的
泛化能力,即在未见过的数据上也能做出准确的预测或分类。
- 尽管ELM因其实现的简便性和学习效率而受到关注,但它也面临着一些批评,比如对于某些
复杂数据集可能无法达到如同精心调参的深度学习模型那样的高性能。 - y总体而言,ELM提供了一种不同的思路来处理机器学习问题,是机器学习和神经网络领域的一个有益补充。
当然,让我们更深入地探讨极限学习机(ELM)的工作原理,并涉及一些基本公式。
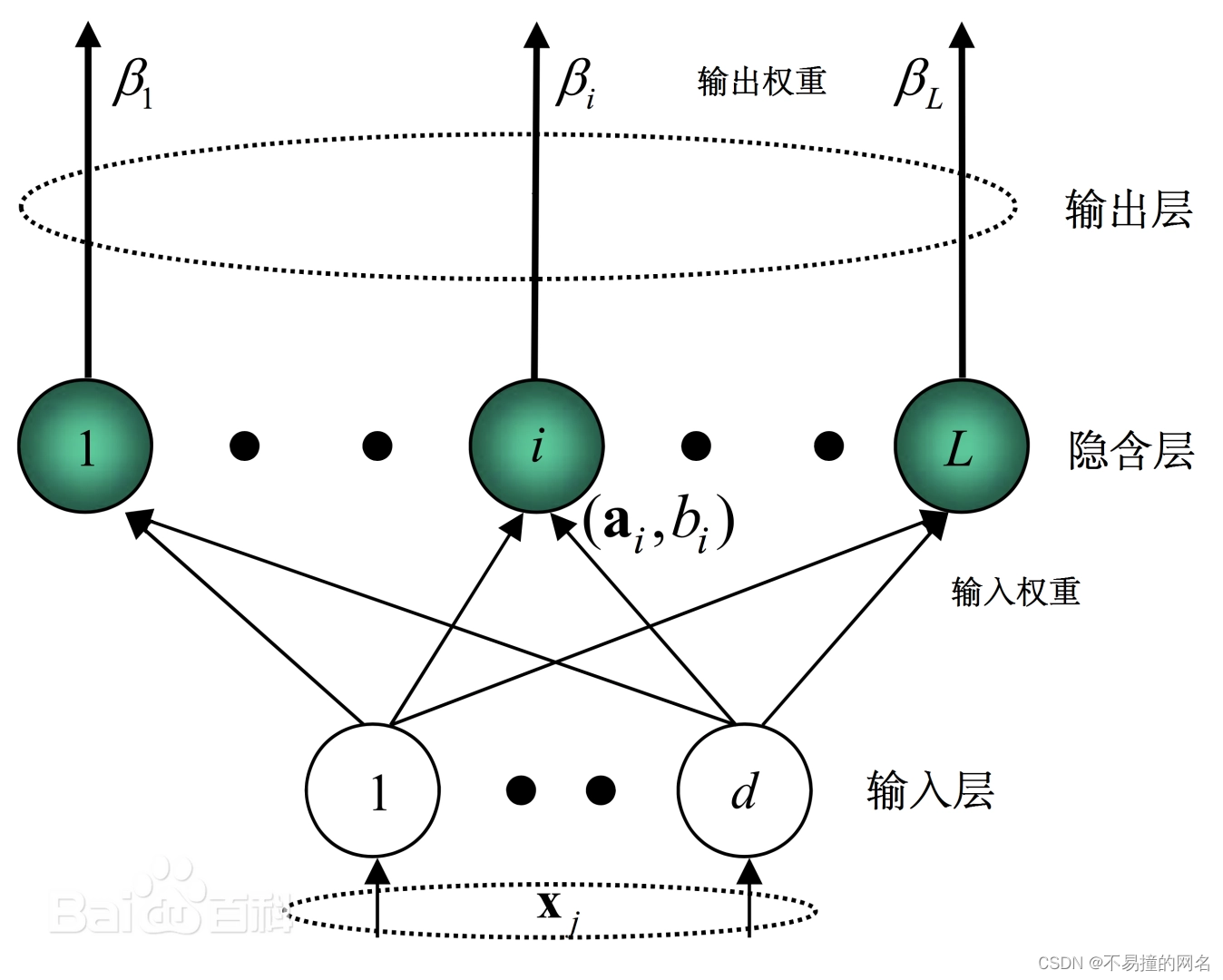
ELM的基本架构
ELM的基本架构包括输入层、隐藏层和输出层。
假设我们有一个带有 ( N ) 个样本的训练集
{
(
x
i
,
t
i
)
}
i
=
1
N
\{(\mathbf{x}_i, t_i)\}_{i=1}^N
{(xi,ti)}i=1N
其中
x
i
∈
R
d
是输入向量,
t
i
∈
R
c
是对应的输出向量(对于分类任务,
t
i
可能是一个独热编码向量;对于回归任务,则直接是实数值)。
其中 \mathbf{x}_i \in \mathbb{R}^d 是输入向量, t_i \in \mathbb{R}^c 是对应的输出向量(对于分类任务, t_i 可能是一个独热编码向量;对于回归任务,则直接是实数值)。
其中xi∈Rd是输入向量,ti∈Rc是对应的输出向量(对于分类任务,ti可能是一个独热编码向量;对于回归任务,则直接是实数值)。
隐藏层激活
对于每个输入样本 x i ,隐藏层 L 个神经元的激活值 h i = [ h i 1 , h i 2 , . . . , h i L ] T 可以表示为: 对于每个输入样本 \mathbf{x}_i ,隐藏层 L 个神经元的激活值 \mathbf{h}_i = [h_{i1}, h_{i2}, ..., h_{iL}]^T 可以表示为: 对于每个输入样本xi,隐藏层L个神经元的激活值hi=[hi1,hi2,...,hiL]T可以表示为:
h i l = g ( a l T x i + b l ) h_{il} = g(\mathbf{a}_l^T\mathbf{x}_i + b_l) hil=g(alTxi+bl)
这里, g ( ⋅ ) 是激活函数(如 s i g m o i d 、 R e L U 等), a l 是第 l 个隐藏层神经元的输入权重向量, b l 是偏置项,它们都是随机初始化的,并且在学习过程中保持不变。 这里, g(\cdot) 是激活函数(如sigmoid、ReLU等), \mathbf{a}_l 是第 l 个隐藏层神经元的输入权重向量, b_l 是偏置项,它们都是随机初始化的,并且在学习过程中保持不变。 这里,g(⋅)是激活函数(如sigmoid、ReLU等),al是第l个隐藏层神经元的输入权重向量,bl是偏置项,它们都是随机初始化的,并且在学习过程中保持不变。
输出权重计算
ELM的主要计算步骤在于确定从隐藏层到输出层的权重
β
=
[
β
1
,
β
2
,
.
.
.
,
β
L
]
T
\mathbf{\beta} = [\beta_1, \beta_2, ..., \beta_L]^T
β=[β1,β2,...,βL]T
假设输出层使用线性组合,则输出
t
^
i
可以表示为:
假设输出层使用线性组合,则输出 \hat{t}_i 可以表示为:
假设输出层使用线性组合,则输出t^i可以表示为:
t ^ i = ∑ l = 1 L β l h i l = β T h i \hat{t}_i = \sum_{l=1}^L \beta_l h_{il} = \mathbf{\beta}^T \mathbf{h}_i t^i=l=1∑Lβlhil=βThi
为了最小化所有样本的整体预测误差,可以通过最小二乘法或最速下降法等方法找到输出权重 β。具体来说,如果考虑最小化均方误差,可以通过求解以下正规方程来获得β:
β = ( H T H ) − 1 H T T \mathbf{\beta} = (\mathbf{H}^T\mathbf{H})^{-1}\mathbf{H}^T\mathbf{T} β=(HTH)−1HTT
这里, H = [ h 1 , h 2 , . . . , h N ] T 是隐藏层激活值矩阵, T = [ t 1 , t 2 , . . . , t N ] T 是目标输出矩阵。 这里, \mathbf{H} = [\mathbf{h}_1, \mathbf{h}_2, ..., \mathbf{h}_N]^T 是隐藏层激活值矩阵, \mathbf{T} = [t_1, t_2, ..., t_N]^T 是目标输出矩阵。 这里,H=[h1,h2,...,hN]T是隐藏层激活值矩阵,T=[t1,t2,...,tN]T是目标输出矩阵。
ELM的变体和优化
- ELM的基本形式可以进一步扩展和优化,例如引入
正则化项防止过拟合,或者使用更复杂的优化策略来处理大规模数据集和高维特征空间。 - 此外,通过
堆叠多个隐藏层,ELM也可以被扩展为深度ELM(Deep ELM),以增强模型的表达能力和学习复杂模式的能力。
例子
ELM模型详细实验过程(简约)
1. 数据预处理
首先,我们需要整理数据,并将其转换为方便计算的格式。给定的数据集如下:
| 房屋编号 | 面积(平方米) | 房间数 | 价格(万元) |
|---|---|---|---|
| 1 | 50 | 2 | 180 |
| 2 | 60 | 3 | 220 |
| 3 | 70 | 2 | 200 |
| 4 | 90 | 3 | 260 |
| 5 | 100 | 4 | 300 |
- 特征矩阵 X:将面积和房间数作为
特征,构建特征矩阵,其中每一行代表一个样本的特征向量。
X = [ 50 2 60 3 70 2 90 3 100 4 ] \mathbf{X} = \begin{bmatrix} 50 & 2 \\ 60 & 3 \\ 70 & 2 \\ 90 & 3 \\ 100 & 4 \end{bmatrix} X= 5060709010023234
- 目标向量 T: 价格作为目标变量,构建目标向量。
T = [ 180 220 200 260 300 ] \mathbf{T} = \begin{bmatrix} 180 \\ 220 \\ 200 \\ 260 \\ 300 \end{bmatrix} T= 180220200260300
2. 随机初始化隐层参数
- 假设我们有
L = 10 个隐层节点,每个节点需要两个权重(对应面积和房间数)和一个偏置项。 - 随机生成隐层权重矩阵 A 和偏置向量 B。
A = [ a 11 a 12 a 21 a 22 ⋮ ⋮ a 101 a 102 ] , B = [ b 1 b 2 ⋮ b 10 ] \mathbf{A} = \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ \vdots & \vdots \\ a_{101} & a_{102} \end{bmatrix}, \quad \mathbf{B} = \begin{bmatrix} b_1 \\ b_2 \\ \vdots \\ b_{10} \end{bmatrix} A= a11a21⋮a101a12a22⋮a102 ,B= b1b2⋮b10
其中 a i j 和 b k 是从某一随机分布(比如均匀分布或高斯分布)中抽取的。 其中 a_{ij} 和 b_k 是从某一随机分布(比如均匀分布或高斯分布)中抽取的。 其中aij和bk是从某一随机分布(比如均匀分布或高斯分布)中抽取的。
3. 计算隐层激活值
- 对于每个输入样本 x i ,计算其在隐层的激活值 h i 对于每个输入样本 \mathbf{x}_i ,计算其在隐层的激活值 \mathbf{h}_i 对于每个输入样本xi,计算其在隐层的激活值hi
- 常用的激活函数是 sigmoid 或 tanh,这里我们采用 sigmoid 函数:
h i l = 1 1 + e − ( a l T x i + b l ) h_{il} = \frac{1}{1 + e^{-(\mathbf{a}_l^T\mathbf{x}_i + b_l)}} hil=1+e−(alTxi+bl)1 - 组织所有样本的激活值形成
隐藏层激活矩阵H。
4. 求解输出层权重
- 使用
最小二乘法加上正则化项来求解输出层权重 β:
β = ( H T H + λ I ) − 1 H T T \mathbf{\beta} = (\mathbf{H}^T\mathbf{H} + \lambda\mathbf{I})^{-1}\mathbf{H}^T\mathbf{T} β=(HTH+λI)−1HTT - 其中λ 是正则化系数,
用于避免过拟合,I 是单位矩阵,T 代表上述的目标向量。
5. 预测新样本
- 对于一个新的房屋,假设面积为 x new 平方米,房间数为 y new ,其特征向量为 x new = [ x new , y new ] T 。 对于一个新的房屋,假设面积为 x_{\text{new}} 平方米,房间数为 y_{\text{new}} ,其特征向量为 \mathbf{x}_{\text{new}} = [x_{\text{new}}, y_{\text{new}}]^T 。 对于一个新的房屋,假设面积为xnew平方米,房间数为ynew,其特征向量为xnew=[xnew,ynew]T。
- 计算该样本在隐层的激活值向量 h new 。 计算该样本在隐层的激活值向量 \mathbf{h}_{\text{new}} 。 计算该样本在隐层的激活值向量hnew。
- 利用已得的 β 进行预测:
预测价格 = β T h new \text{预测价格} = \mathbf{\beta}^T\mathbf{h}_{\text{new}} 预测价格=βThnew
实际计算步骤简化演示
由于直接计算涉及大量具体数值,这里仅展示概念性步骤,实际数值运算通常需要借助编程语言(如Python)和相应的数学库(如NumPy)完成。下面是使用Python的一个简化示例流程:
请注意,上述代码仅为示例,实际应用中还需考虑更多因素,如数据归一化、模型评估等。
示例代码
import numpy as np
def sigmoid(x):
"""Sigmoid激活函数"""
return 1 / (1 + np.exp(-x))
def predict_price_with_given_weights(X_train, T_train, x_new, A, B, lambda_reg=0.01):
"""
使用ELM模型及给定的隐层参数预测新样本的价格
:param X_train: 训练集特征矩阵
:param T_train: 训练集目标向量
:param x_new: 新样本特征向量
:param A: 隐层权重矩阵
:param B: 隐层偏置向量
:param lambda_reg: 正则化参数
:return: 预测价格
"""
# 计算隐层激活值矩阵 H
H = sigmoid(np.dot(A, X_train.T) + B)
print("计算隐层激活值矩阵 H:",H)
# 求解输出层权重 beta
beta = np.linalg.inv(np.dot(H, H.T) + lambda_reg * np.eye(A.shape[0])) @ np.dot(H, T_train)
print("输出层权重 β:",beta)
# 预测新样本的隐层激活值
h_new = sigmoid(np.dot(A, x_new) + B)
print("预测新样本的隐层激活值:",h_new)
# 预测价格
predicted_price = np.dot(beta.T, h_new)
return predicted_price[0][0]
# 示例数据
X_train = np.array([[50, 2], [60, 3], [70, 2], [90, 3], [100, 4]])
T_train = np.array([[180], [220], [200], [260], [300]])
# 给定的隐层参数
A = np.array([[-0.5, 0.2], [0.3, -0.1]])
B = np.array([[-1], [0.5]])
# 新样本特征
x_new = np.array([[100], [5]])
# 预测新样本价格
predicted_price = predict_price_with_given_weights(X_train, T_train, x_new, A, B)
print(f"预测价格: {predicted_price:.2f}万元")
计算隐层激活值矩阵 H: [
[7.62186519e-12 6.27260226e-14 3.46032144e-16 1.91880359e-20 1.57912682e-22],[9.99999773e-01 9.99999988e-01 9.99999999e-01 1.00000000e+00 1.00000000e+00]]
输出层权重 β: [[-3.93541785e-08],[ 2.31536940e+02]]
预测新样本的隐层激活值: [[1.92874985e-22],[1.00000000e+00]]
预测价格: 231.54万元


















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











