






一、马尔科夫简述

二、HMM算法概述

三、隐马尔科夫模型(HMM)笔记(公式+代码)
参考
http://t.csdn.cn/KfRqp
隐马尔科夫模型(hidden Markov model,HMM)是可用于 标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。隐马尔可夫模型在语音识别、自然语言处理、生物信息、模式识别等领域有着广泛的应用。
3.1基本概念
3.1.1
- 隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。
- 隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence;
- 每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence。
- 序列的每一个位置又可以看作是一个时刻。
一个不一定恰当的例子:你只知道一个人今天是散步了,逛街了,还是在家打扫卫生,推测今天的天气;这个人在下雨天可能在家打扫卫生,也有可能雨中散步,晴天可能去逛街,也有可能散步,或者打扫卫生
隐藏状态 Y(不可见):下雨,晴天 观察状态 X(可见): 散步,逛街,打扫房间



3.1.2盒子和球模型
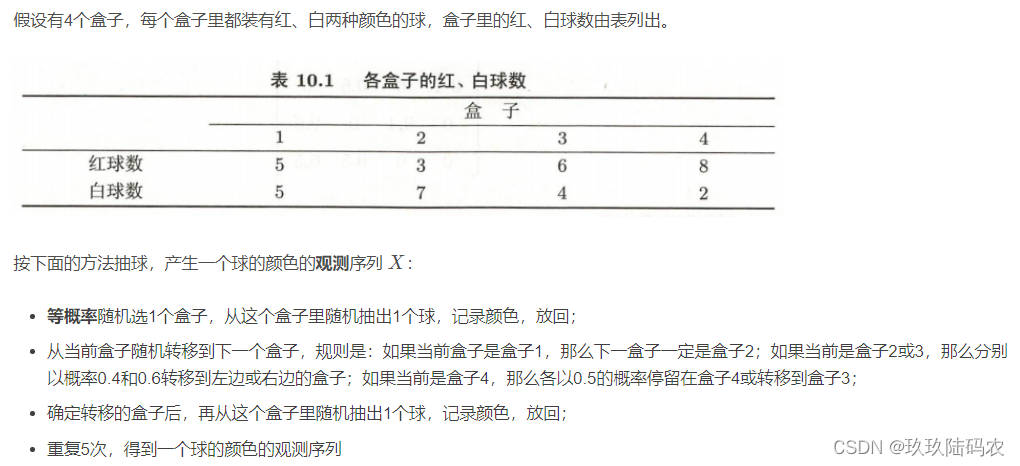

3.1.3观测序列生成过程

3.1.4HMM模型3个基本问题

3.2概率计算问题
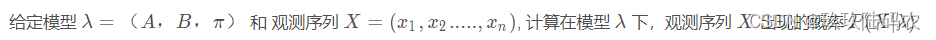
3.2.1直接计算法

3.2.2前向算法

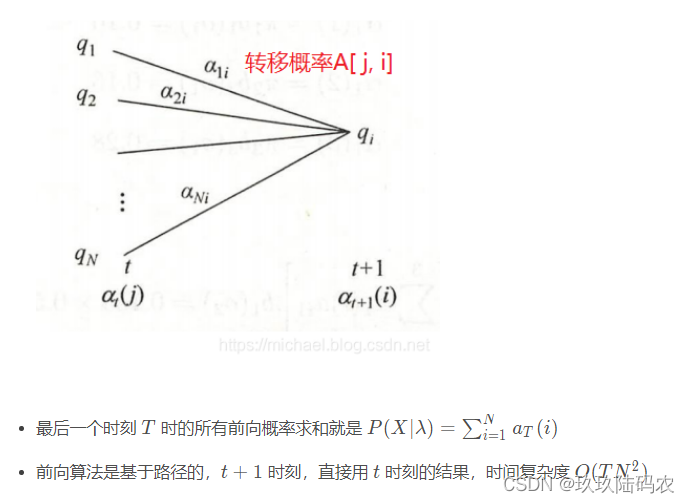
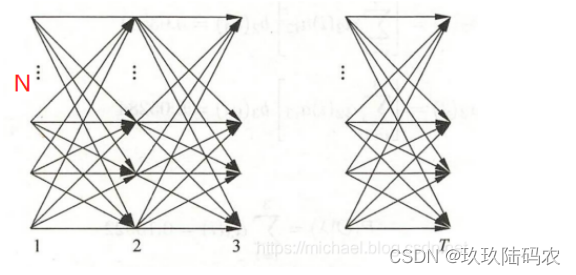
3.2.2.1前向公式证明

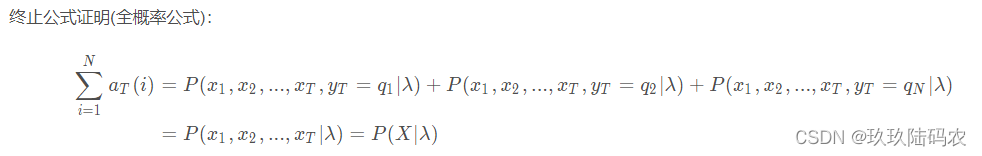
3.2.2.2盒子和球例子



3.2.2.3前向算法Python代码
# -*- coding:utf-8 -*-
# python3.7
# @Time: 2019/12/17 22:33
# @Author: Michael Ming
# @Website: https://michael.blog.csdn.net/
# @File: hiddenMarkov.py
import numpy as np
class HiddenMarkov:
def forward(self, Q, V, A, B, X, PI): # 前向算法
N = len(Q) # 隐藏状态数量
M = len(X) # 观测序列大小
alphas = np.zeros((N, M)) # 前向概率 alphas 矩阵
T = M # 时刻长度,即观测序列长度
for t in range(T): # 遍历每个时刻,计算前向概率 alphas
indexOfXi = V.index(X[t]) # 观测值Xi对应的V中的索引
for i in range(N): # 对每个状态进行遍历
if t == 0: # 计算初值
alphas[i][t] = PI[t][i] * B[i][indexOfXi] # a1(i)=πi B(i,x1)
print("alphas1(%d)=p%dB%d(x1)=%f" %(i,i,i,alphas[i][t]))
else:
alphas[i][t] = np.dot(
[alpha[t-1] for alpha in alphas], # 取的alphas的t-1列
[a[i] for a in A]) *B[i][indexOfXi] # 递推公式
print("alpha%d(%d)=[sigma alpha%d(i)ai%d]B%d(x%d)=%f"
%(t, i, t-1, i, i, t, alphas[i][t]))
print(alphas)
P = sum(alpha[M-1] for alpha in alphas) # 最后一列概率的和
print("P=%f" % P)
Q = [1, 2, 3]
V = ['红', '白']
A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]
B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]
# X = ['红', '白', '红', '红', '白', '红', '白', '白']
X = ['红', '白', '红'] # 书上的例子
PI = [[0.2, 0.4, 0.4]]
hmm = HiddenMarkov()
hmm.forward(Q, V, A, B, X, PI)
关于numpy的一些操作:
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> b
array([[ 7, 8],
[ 9, 10],
[11, 12]])
>>> np.dot(a[0],[B[1] for B in b])
64
>>> np.dot([A[0] for A in a],[B[1] for B in b])
132
>>> np.multiply(a[0],[B[1] for B in b])
array([ 8, 20, 36])
>>> np.multiply([A[0] for A in a],[B[1] for B in b])
array([ 8, 40, 84])
运行结果:(跟上面计算一致)
alphas1(0)=p0B0(x1)=0.100000
alphas1(1)=p1B1(x1)=0.160000
alphas1(2)=p2B2(x1)=0.280000
alpha1(0)=[sigma alpha0(i)ai0]B0(x1)=0.077000
[[0.1 0.077 0. ]
[0.16 0. 0. ]
[0.28 0. 0. ]]
alpha1(1)=[sigma alpha0(i)ai1]B1(x1)=0.110400
[[0.1 0.077 0. ]
[0.16 0.1104 0. ]
[0.28 0. 0. ]]
alpha1(2)=[sigma alpha0(i)ai2]B2(x1)=0.060600
[[0.1 0.077 0. ]
[0.16 0.1104 0. ]
[0.28 0.0606 0. ]]
alpha2(0)=[sigma alpha1(i)ai0]B0(x2)=0.041870
[[0.1 0.077 0.04187]
[0.16 0.1104 0. ]
[0.28 0.0606 0. ]]
alpha2(1)=[sigma alpha1(i)ai1]B1(x2)=0.035512
[[0.1 0.077 0.04187 ]
[0.16 0.1104 0.035512]
[0.28 0.0606 0. ]]
alpha2(2)=[sigma alpha1(i)ai2]B2(x2)=0.052836
[[0.1 0.077 0.04187 ]
[0.16 0.1104 0.035512]
[0.28 0.0606 0.052836]]
P=0.130218
3.2.3后向算法

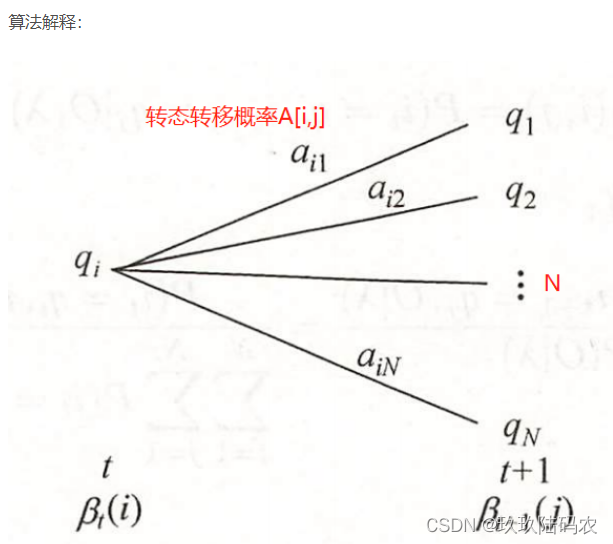
3.2.3.1后向公式证明

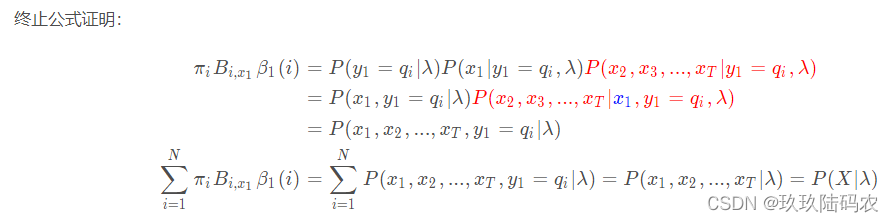

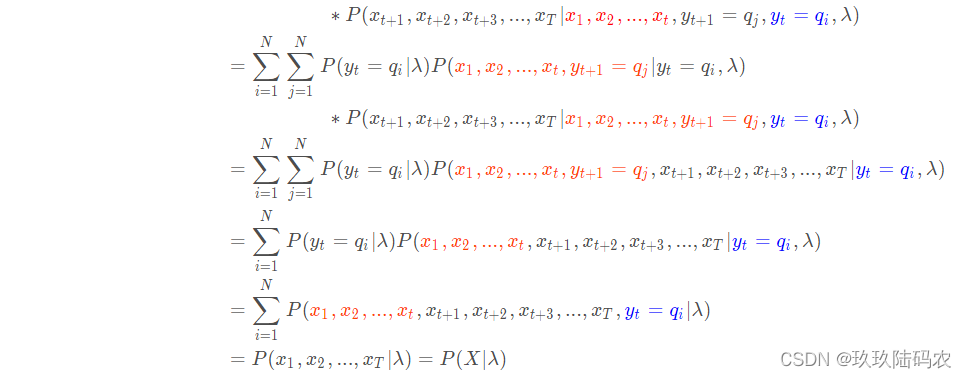
3.2.3.2后向算法Python代码
import numpy as np
class HiddenMarkov:
def backward(self, Q, V, A, B, X, PI): # 后向算法
N = len(Q) # 隐藏状态数量
M = len(X) # 观测序列大小
betas = np.ones((N, M)) # 后向概率矩阵 betas
for i in range(N):
print("beta%d(%d)=1" %(M, i)) # 后向概率初始为1
for t in range(M-2, -1, -1):
indexOfXi = V.index(X[t+1]) # 观测值Xi对应的V中的索引
for i in range(N):
betas[i][t] = np.dot(
np.multiply(A[i], [b[indexOfXi] for b in B]), # A的i行 B的Xi列 = 行
[beta[t+1] for beta in betas]) # 递推公式
realT = t+1 # 真实的时间,t从1开始
realI = i+1 # 状态标号,从1开始
print("beta%d(%d)=[sigma A%djBj(x%d)beta%d(j)]=("
%(realT, realI, realI, realT+1, realT+1), end='') # end,表示以该符号空开,不换行
for j in range(N):
print("%.2f*%.2f*%.2f+" %(A[i][j], B[j][indexOfXi],betas[j][t+1]), end=' ')
print("0)=%.3f" % betas[i][t])
print(betas)
indexOfXi = V.index(X[0])
P = np.dot(
np.multiply(PI, [b[indexOfXi] for b in B]),
[beta[0] for beta in betas])
print("P(X|lambda)=", end=" ")
for i in range(N):
print("%.1f*%.1f*%.5f+" % (PI[0][i], B[i][indexOfXi], betas[i][0]), end=" ")
print("0=%f" % P)
Q = [1, 2, 3]
V = ['红', '白']
A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]
B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]
# X = ['红', '白', '红', '红', '白', '红', '白', '白']
X = ['红', '白', '红'] # 书上的例子
PI = [[0.2, 0.4, 0.4]]
hmm = HiddenMarkov()
hmm.backward(Q, V, A, B, X, PI)
运行结果:
beta3(0)=1
beta3(1)=1
beta3(2)=1
beta2(1)=[sigma A1jBj(x3)beta3(j)]=(0.50*0.50*1.00+ 0.20*0.40*1.00+ 0.30*0.70*1.00+ 0)=0.540
beta2(2)=[sigma A2jBj(x3)beta3(j)]=(0.30*0.50*1.00+ 0.50*0.40*1.00+ 0.20*0.70*1.00+ 0)=0.490
beta2(3)=[sigma A3jBj(x3)beta3(j)]=(0.20*0.50*1.00+ 0.30*0.40*1.00+ 0.50*0.70*1.00+ 0)=0.570
beta1(1)=[sigma A1jBj(x2)beta2(j)]=(0.50*0.50*0.54+ 0.20*0.60*0.49+ 0.30*0.30*0.57+ 0)=0.245
beta1(2)=[sigma A2jBj(x2)beta2(j)]=(0.30*0.50*0.54+ 0.50*0.60*0.49+ 0.20*0.30*0.57+ 0)=0.262
beta1(3)=[sigma A3jBj(x2)beta2(j)]=(0.20*0.50*0.54+ 0.30*0.60*0.49+ 0.50*0.30*0.57+ 0)=0.228
[[0.2451 0.54 1. ]
[0.2622 0.49 1. ]
[0.2277 0.57 1. ]]
P(X|lambda)= 0.2*0.5*0.24510+ 0.4*0.4*0.26220+ 0.4*0.7*0.22770+ 0=0.130218
# 概率跟前向算法计算的是一致的
3.2.4一些概率与期望值



3.3学习算法

3.3.1监督学习方法

3.3.2无监督Baum-Welch 算法
先跳过
4.1预测算法
4.1.1近似算法

4.1.2维特比Viterbi算法

viterbi 算法:

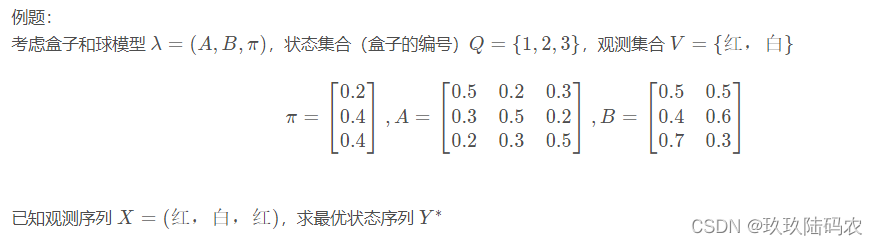
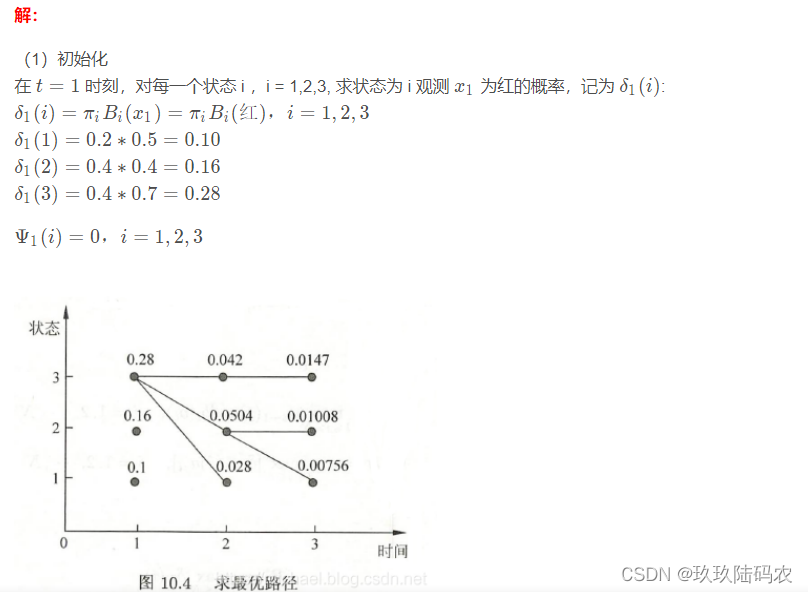



4.1.3维特比算法python代码
import numpy as np
class HiddenMarkov:
def viterbi(self, Q, V, A, B, X, PI): # 维特比算法,求最优状态序列
N = len(Q) # 隐藏状态数量
M = len(X) # 观测序列大小
deltas = np.zeros((N, M))
psis = np.zeros((N, M))
Y = np.zeros((1, M)) # 最优(概率最大)状态序列
for t in range(M):
realT = t+1 # 真实时刻,从1开始
indexOfXi = V.index(X[t]) # 观测值Xi对应的V中的索引
for i in range(N):
realI = i+1 # 状态序号,从1开始
if t == 0:
deltas[i][t] = PI[0][i]* B[i][indexOfXi] # 初始值
psis[i][t] = 0
print("delta1(%d)=pi_%d * B%d(x1)=%.2f * %.2f=%.2f" %
(realI, realI, realI, PI[0][i], B[i][indexOfXi], deltas[i][t]))
print('psis1(%d)=0' % realI)
else:
deltas[i][t] = np.max(
np.multiply([delta[t-1] for delta in deltas],[a[i] for a in A])) \
* B[i][indexOfXi] # 递推公式
print("delta%d(%d)=max[delta%d(j)Aj%d]B%d(x%d)=%.2f*%.2f=%.5f"
% (realT, realI, realT-1, realI, realI, realT,
np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])),
B[i][indexOfXi], deltas[i][t]))
psis[i][t] = np.argmax(
np.multiply([delta[t-1] for delta in deltas],[a[i] for a in A])) + 1 # 序号从1开始
print("psis%d(%d)=argmax[delta%d(j)Aj%d]=%d" %
(realT, realI, realT-1, realI, psis[i][t]))
print(deltas)
print(psis)
Y[0][M-1] = np.argmax([delta[M-1] for delta in deltas]) +1 # 序号从1开始
print("Y%d=argmax[deltaT(i)]=%d" %(M, Y[0][M-1])) # 最优路径的终点
for t in range(M-2, -1, -1): # 逆序推导前面的路径
Y[0][t] = psis[int(Y[0][t+1])-1][t+1] # 寻找前面路径
print("Y%d=psis%d(Y%d)=%d" %(t+1, t+2, t+2, Y[0][t]))
print("最大概率的状态序列Y是: ", Y)
Q = [1, 2, 3]
V = ['红', '白']
A = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]
B = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]
# X = ['红', '白', '红', '红', '白', '红', '白', '白']
X = ['红', '白', '红'] # 书上的例子
PI = [[0.2, 0.4, 0.4]]
hmm = HiddenMarkov()
hmm.viterbi(Q, V, A, B, X, PI)
运行结果:(与上面计算一致)
delta1(1)=pi_1 * B1(x1)=0.20 * 0.50=0.10
psis1(1)=0
delta1(2)=pi_2 * B2(x1)=0.40 * 0.40=0.16
psis1(2)=0
delta1(3)=pi_3 * B3(x1)=0.40 * 0.70=0.28
psis1(3)=0
delta2(1)=max[delta1(j)Aj1]B1(x2)=0.06*0.50=0.02800
psis2(1)=argmax[delta1(j)Aj1]=3
delta2(2)=max[delta1(j)Aj2]B2(x2)=0.08*0.60=0.05040
psis2(2)=argmax[delta1(j)Aj2]=3
delta2(3)=max[delta1(j)Aj3]B3(x2)=0.14*0.30=0.04200
psis2(3)=argmax[delta1(j)Aj3]=3
delta3(1)=max[delta2(j)Aj1]B1(x3)=0.02*0.50=0.00756
psis3(1)=argmax[delta2(j)Aj1]=2
delta3(2)=max[delta2(j)Aj2]B2(x3)=0.03*0.40=0.01008
psis3(2)=argmax[delta2(j)Aj2]=2
delta3(3)=max[delta2(j)Aj3]B3(x3)=0.02*0.70=0.01470
psis3(3)=argmax[delta2(j)Aj3]=3
[[0.1 0.028 0.00756]
[0.16 0.0504 0.01008]
[0.28 0.042 0.0147 ]]
[[0. 3. 2.]
[0. 3. 2.]
[0. 3. 3.]]
Y3=argmax[deltaT(i)]=3
Y2=psis3(Y3)=3
Y1=psis2(Y2)=3
最大概率的状态序列Y是: [[3. 3. 3.]]
4.1.4 实战
链接
https://blog.csdn.net/qq_21201267/article/details/103624237















 1983
1983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









