






大模型,大资料,loss会降低,准确率会增加
1大模型
1.1模型的顿悟时刻
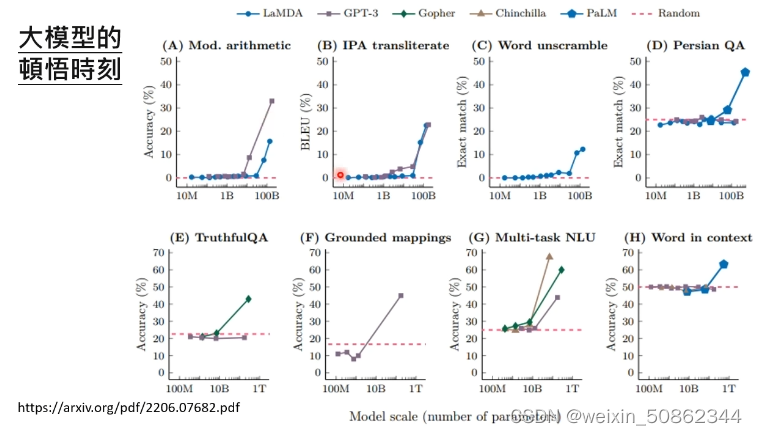
举了一个一知半解的例子
1.2 模型
chain of thought
模型足够大时才会有比较好的作用

calibration
检测模型对于答案的confidence
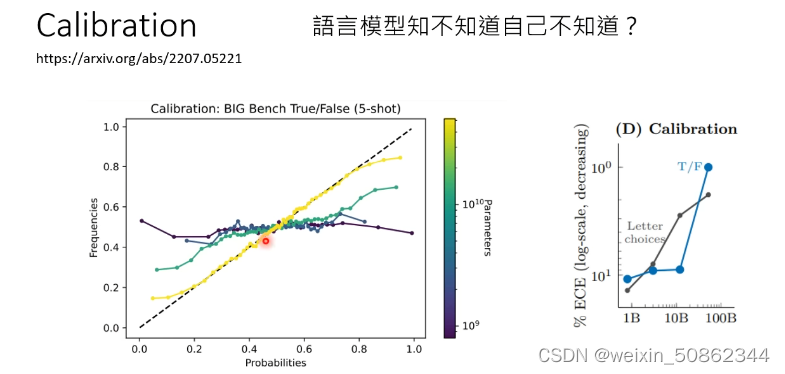
会出现 “u-shape”
2.大资料
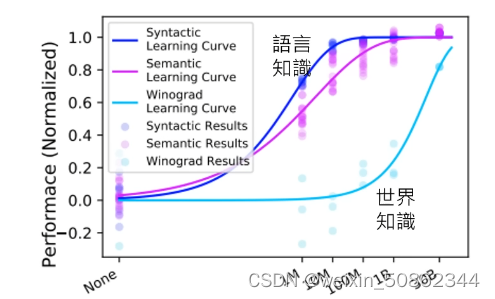
文法和对世界了解需要的数据量不相同
2.1 资料的前处理
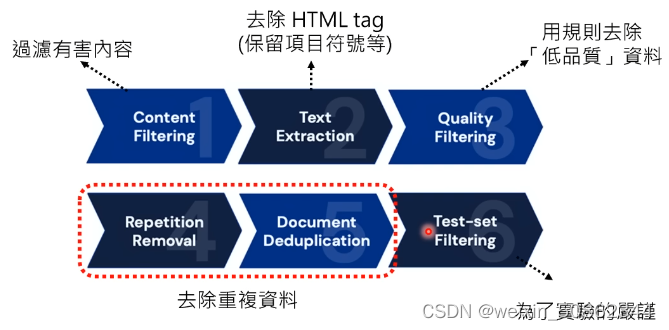
重复训练资料,避免模型硬背
2.2 运算资源固定

给出了在一定资源情况下,数据量和参数量的合理配比。
小模型大资料 完胜 大模型小资料
【LLaMA】也是参考了这种思想
2.3 模型调整
2.3.1 instruction-tuning
对于对应问题的finetune
2.3.2 整体架构
pretrained -> finetune ->reinenforce learning
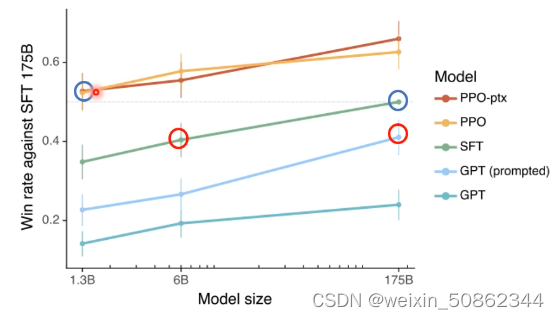
(1)小模型finetune效果会比大模型好
(2)小模型reinenforce learning效果会比大模型好
3. 跳出“大模型大资料”
3.1 knn lm
常规:
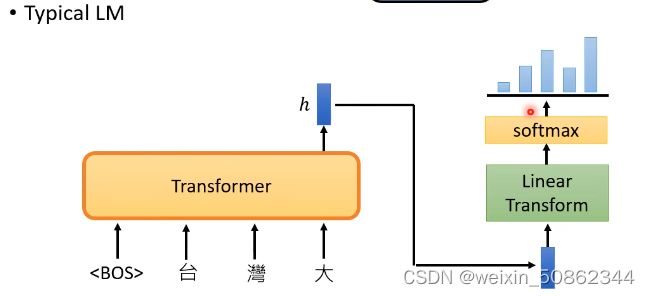
当成分类问题来解决
KNN LM:
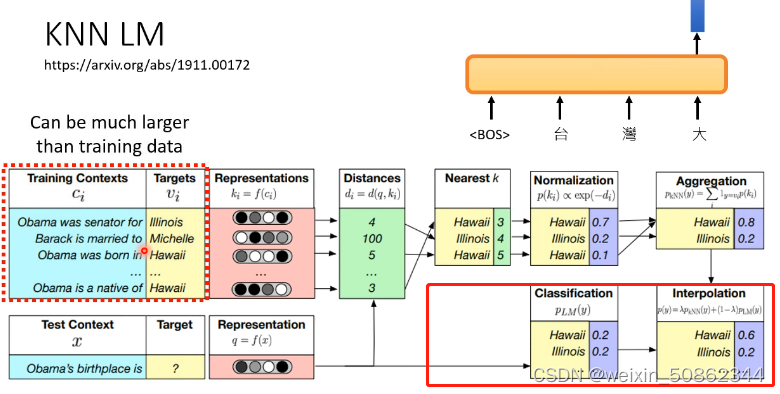
(1)求目标和源向量
(2)求目标和源之间距离
红色框:与常规方式搭配(加权)使用
3.1.1 缺点
inference 时间太久了
3.2 RETRO
通过查询避免模型记忆(比如Π的数值)















 5997
5997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









