







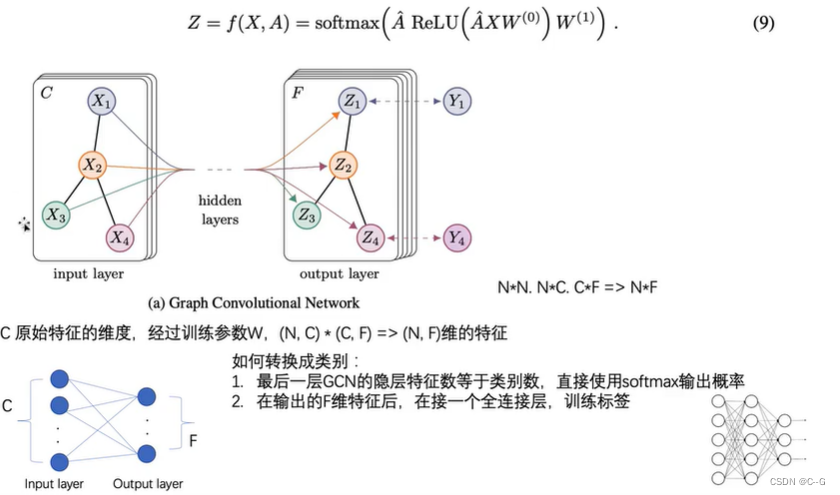
GCN



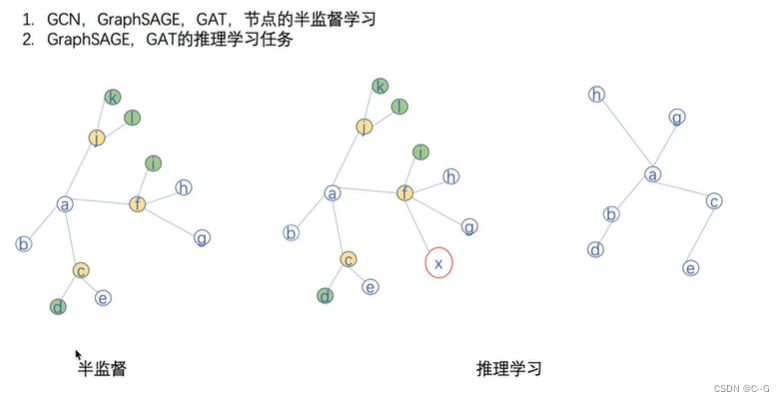
GraphSAGE(SAmple and aggreGatE)




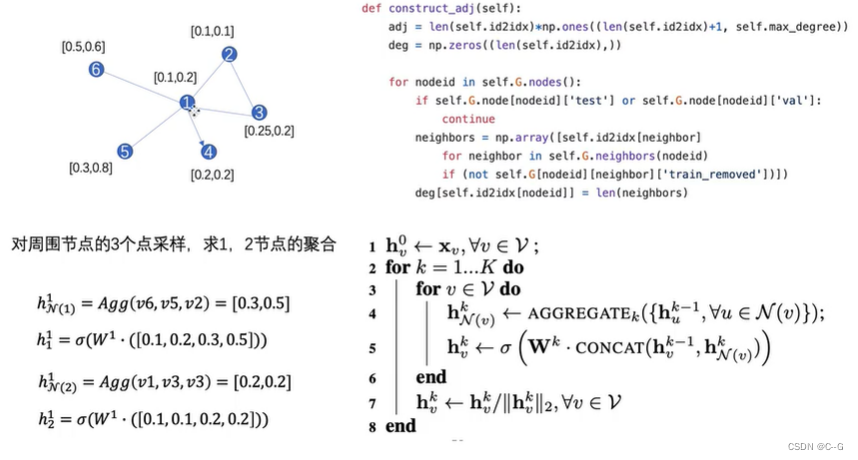

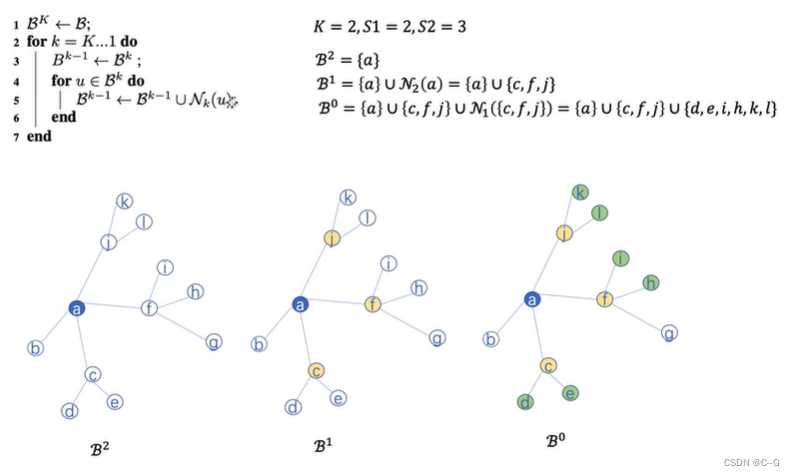
GraphSAGE Minbatch


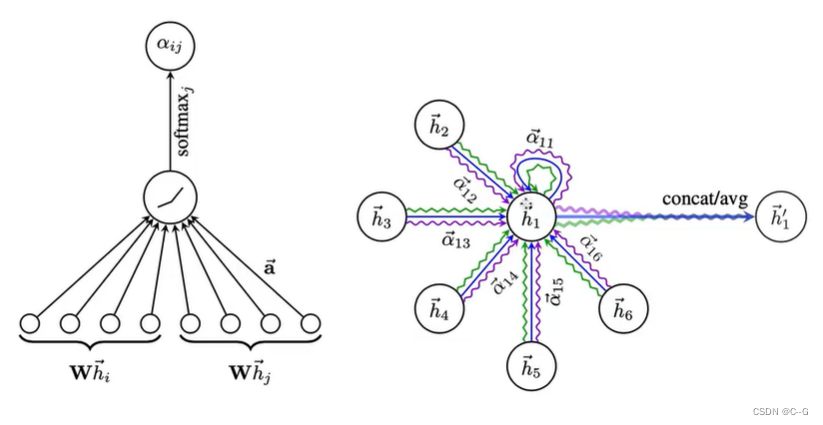
GAT(GRAPH ATTENTION NETWORKS)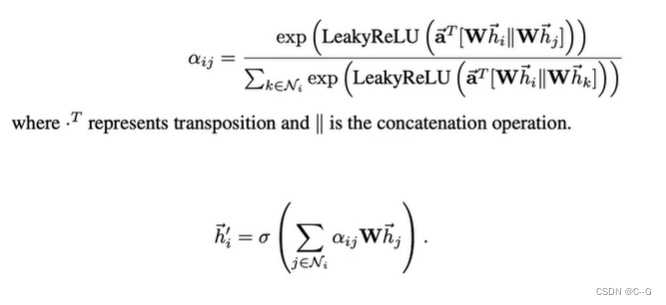



图网络应用
PyG
- 创建anaconda环境
conda create -n graph python=3.6.8
- 安装pytorch(cpu)
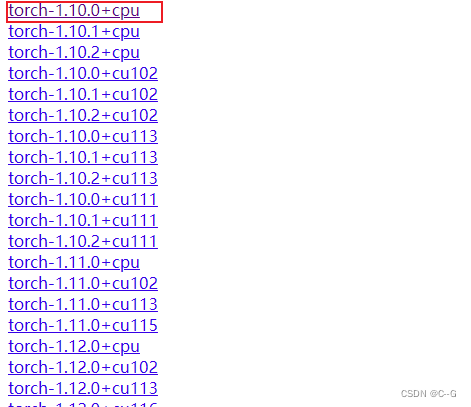
pytorch安装地址
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cpuonly -c pytorch
- 安装PyG(cpu)
https://data.pyg.org/whl/
这里安装torch1.10.0 cpu版本
下载4个文件
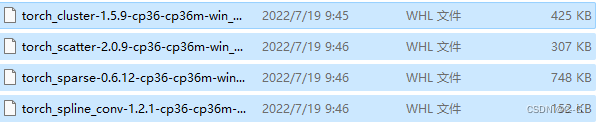
pip install torch_cluster-1.5.9-cp36-cp36m-win_amd64.whl
pip install torch_scatter-2.0.9-cp36-cp36m-win_amd64.whl
pip install torch_sparse-0.6.12-cp36-cp36m-win_amd64.whl
pip install torch_spline_conv-1.2.1-cp36-cp36m-win_amd64.whl
pip install torch-geometric
附加PyG GPU版本安装,torch安装省略
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html
pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html
pip install torch-cluster -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html
pip install torch-spline-conv -f https://pytorch-geometric.com/whl/torch-${TORCH}+${CUDA}.html
pip install torch-geometric
其中torch换成自己的torch版本,CUDA换成自己的CUDA版本
- 安装结果测试
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
print(data)

图形的数据处理
图形通过节点与边的关系进行建模,PyG由torch_geometirc.data.Data实例描述
- data.x: 节点的特征矩阵,形状为 [num_nodes, num_node_features]
- data.edge_index: COO格式的图的边 shape [2, num_edges] and type torch.long
- data.edge_attr:边的特征矩阵 shape [num_edges, num_edge_features]
- data.y: 训练数据的标签,节点级的目标 shape [num_nodes, *] or 图级的目标 shape [1, *]
- data.pos: 节点的位置矩阵 shape [num_nodes, num_dimensions]
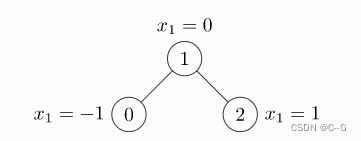
import torch
from torch_geometric.data import Data
# 一个无权无向图的例子
# 边的索引 COO格式 就是说第一行代表行索引 第二行代表列索引
# 节点0 1之间有一条边 12之间有一条边
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
# 节点0 1 2的特征分别是
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
# 不是COO格式的边 是使用边的两个节点的元组形式
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1],
[1, 0],
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous())
data提供了如下方法进行访问
# 可以使用类似字典的方式
print(data.keys)
>>> ['x', 'edge_index'] # 前面带箭头的表示输出
print(data['x'])
>>> tensor([[-1.0],
[0.0],
[1.0]])
for key, item in data:
print(f'{key} found in data')
>>> x found in data
>>> edge_index found in data
'edge_attr' in data
>>> False
data.num_nodes # 节点数量
>>> 3
data.num_edges # 边数量
>>> 4
data.num_node_features # 节点特征数量
>>> 1
data.has_isolated_nodes() # 是否有孤立的节点
>>> False
data.has_self_loops() # 是否有 自己到自己的边
>>> False
data.is_directed() # 是否是有向图
>>> False
# 也可以向PyTorch一样转到GPU里面
device = torch.device('cuda')
data = data.to(device)
通用基准数据集
PyG包含大量常见的基准数据集,例如,所有Planetoid数据集(Cora,Citeseer,Pubmed)
使用PyG处理数据非常简单,并且下载下来就是源文件格式(raw file,可能在一些程序中看见这个单词),并且会自动处理为Data格式,例如
from torch_geometric.datasets import TUDataset
# 导入数据集 参数分别为:保存的文件 导入数据集的名字
dataset = TUDataset(root='./data/ENZYMES', name='ENZYMES')
>>> ENZYMES(600) # 这个数据集包含600张图
len(dataset)
>>> 600
dataset.num_classes
>>> 6
#节点特征数
dataset.num_node_features
>>> 3
# 查看第一张图
data = dataset[0]
>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])
data.is_undirected()
>>> True # 无向图
我们可以看到数据集中的第一个图包含37个节点,每个节点有3个特性。有168/2 = 84条无向边,图被分配到一个类中。此外,数据对象只持有一个图级目标。
我们甚至可以使用切片、long或bool张量来分割数据集。例如,要创建90/10的训练/测试分割
train_dataset = dataset[:540]
>>> ENZYMES(540)
test_dataset = dataset[540:]
>>> ENZYMES(60)
# 同样 也可以打乱数据
dataset = dataset.shuffle()
>>> ENZYMES(600)
# 等于这个操作
perm = torch.randperm(len(dataset))
dataset = dataset[perm]
>> ENZYMES(600)
Cora,半监督图节点分类的标准基准数据集,这个数据集是图神经网络论文中经常看见的数据集,是一个论文的引用图,节点的特征为论文的词向量
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
>>> Cora()
len(dataset)
>>> 1 # 数据集只有一张图
dataset.num_classes
>>> 7 # 分为7类
dataset.num_node_features
>>> 1433 # 每个节点有1433维特征
data = dataset[0]
>>> Data(edge_index=[2, 10556], test_mask=[2708],
train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
data.is_undirected()
>>> True
Data对象保存每个节点的标签,以及额外的节点级属性:train_mask、val_mask和test_mask,其中
Train_mask表示要训练哪个节点(140个节点),
Val_mask表示使用哪些节点进行验证,例如,执行早期停止(500个节点),
Test_mask表示要测试哪个节点(1000个节点)。
比如data.train_mask是一个一维的bool类型的tensor,里面的数据是True就代表是训练数据
data.train_mask.sum().item()
>>> 140
data.val_mask.sum().item()
>>> 500
data.test_mask.sum().item()
>>> 1000
Mini-Batches
神经网络通常以批处理方式进行训练。PyG通过创建稀疏块对角邻接矩阵(由edge_index定义)和连接节点维上的特征和目标矩阵来实现小批量的并行化。这种组合允许在一个批处理中不同数量的节点和边:
PyG包含它自己的torch_geometric.loader.DataLoader,它已经处理了这个连接过程。其实使用的过程和torch里面的DataLoader是一样的:
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='./data/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
batch
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
batch.num_graphs
>>> 32
torch_geometric.data.Batch从torch_geometric.data.Data继承,并包含称为batch的附加属性。batch是一个列向量,保存了batch中每个节点和对应图的映射关系。
可以使用batch来计算batch中每个图中各个节点的平均特征
from torch_scatter import scatter_mean
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for data in loader:
data
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
data.num_graphs
>>> 32
# 按图维度求平均
x = scatter_mean(data.x, data.batch, dim=0)
x.size()
>>> torch.Size([32, 21])
Data Transforms
ShapeNet数据集是包含17000个3D点云的数据集
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='./data/ShapeNet', categories=['Airplane'])
dataset[0]
>>> Data(pos=[2518, 3], y=[2518])
通过transforms将点云生成最近邻图,将点云数据集转换为图数据集
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
# 主要就是加了最后一个参数pre_transform
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],pre_transform=T.KNNGraph(k=6))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
pre_transform参数可以在数据存入磁盘之前进行转换,在下次使用时,数据集将自动包含边。
此外,我们可以使用transform参数来随机增强一个Data对象,例如,将每个节点的位置转换为一个小数字
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6),
transform=T.RandomTranslate(0.01))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
图学习方法
GCN
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./data/Cora', name='Cora')
然后定义一个两层的GCN,和torch里面的定义方式一样,只是在传入GCN网络时传的是两个参数,第一个是数据特征,第二个是边的index。数据特征x就是每个节点的特征向量,edge_index就是(2,节点数)的Tensor,表示哪两个节点之间有边。卷积层后面的ReLU激活函数以及dropout层也是常用的
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv,SAGEConv,GATConv
class GCN_Net(torch.nn.Module):
def __init__(self,features,hidden,classes):
super(GCN_Net,self).__init__()
self.conv1 = GCNConv(features, hidden)
self.conv2 = GCNConv(hidden, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
对网络进行训练,训练的方式也是和torch中形式一样
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN_Net(dataset.num_node_features,16,dataset.num_classes).to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
训练精度进行测试
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
>>> Accuracy: 0.8150
GraphSAGE
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv,SAGEConv,GATConv
class GraphSAGE_Net(torch.nn.Module):
def __init__(self,features,hidden,classes):
super(GraphSAGE_Net,self).__init__()
self.sage1 = GCNConv(features, hidden)
self.sage2 = GCNConv(hidden, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.sage1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.sage2(x, edge_index)
return F.log_softmax(x, dim=1)
GAT
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv,SAGEConv,GATConv
class GAT_Net(torch.nn.Module):
def __init__(self,features,hidden,classes,heads=1):
super(GAT_Net,self).__init__()
self.gat1 = GATConv(features, hidden,heads=heads)
self.gat2 = GATConv(hidden*heads, classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.gat1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.gat2(x, edge_index)
return F.log_softmax(x, dim=1)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









