







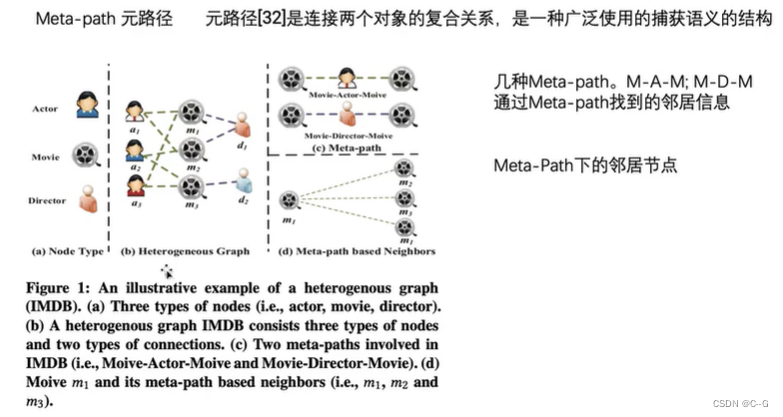
异构图(HAN)


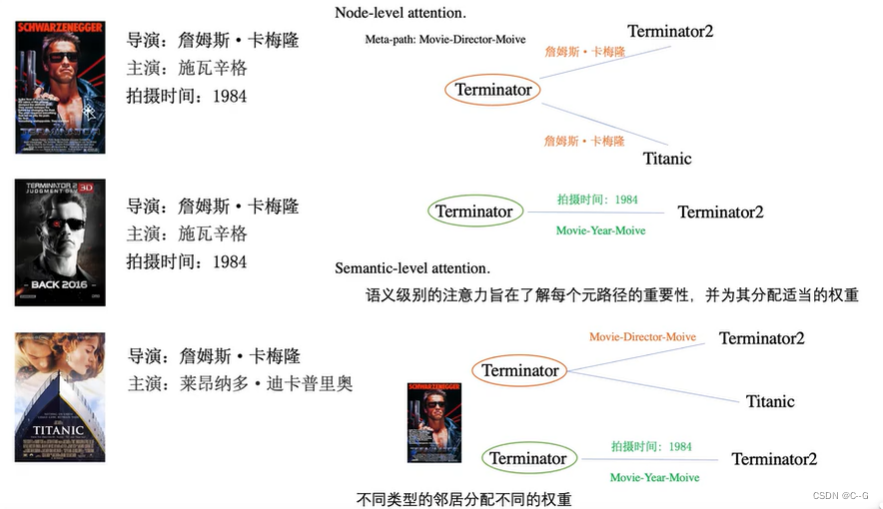
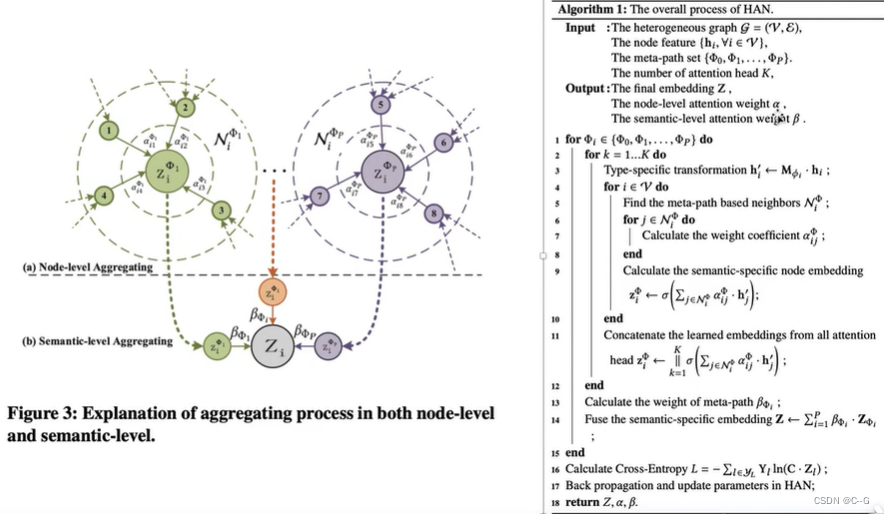
- Node-level Attention

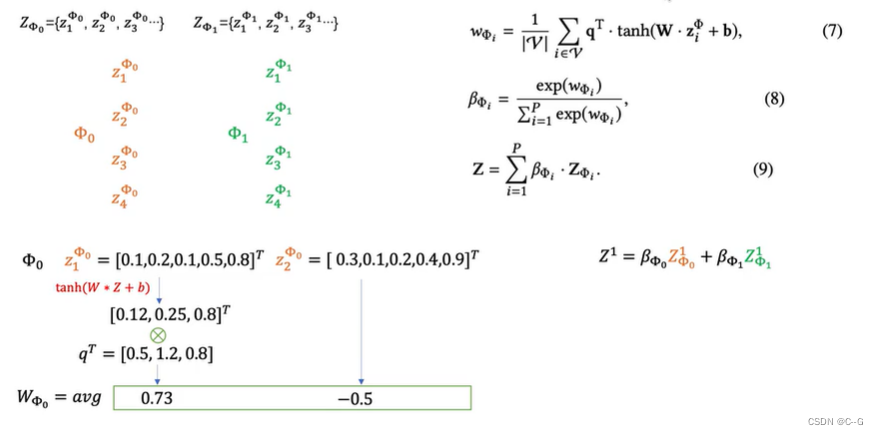
- Semantic-level Attention
核心代码
- 数据加载
def load_data(dataset, remove_self_loop=False):
if dataset == 'ACM':
return load_acm(remove_self_loop)
elif dataset == 'ACMRaw':
return load_acm_raw(remove_self_loop)
else:
return NotImplementedError('Unsupported dataset {}'.format(dataset))
def load_acm(remove_self_loop):
url = 'dataset/ACM3025.pkl'
data_path = get_download_dir() + '/ACM3025.pkl'
download(_get_dgl_url(url), path=data_path)
with open(data_path, 'rb') as f:
data = pickle.load(f)
labels, features = torch.from_numpy(data['label'].todense()).long(), \
torch.from_numpy(data['feature'].todense()).float()
num_classes = labels.shape[1]
labels = labels.nonzero()[:, 1]
if remove_self_loop:
num_nodes = data['label'].shape[0]
data['PAP'] = sparse.csr_matrix(data['PAP'] - np.eye(num_nodes))
data['PLP'] = sparse.csr_matrix(data['PLP'] - np.eye(num_nodes))
# Adjacency matrices for meta path based neighbors
# (Mufei): I verified both of them are binary adjacency matrices with self loops
author_g = dgl.from_scipy(data['PAP'])
subject_g = dgl.from_scipy(data['PLP'])
gs = [author_g, subject_g]
train_idx = torch.from_numpy(data['train_idx']).long().squeeze(0)
val_idx = torch.from_numpy(data['val_idx']).long().squeeze(0)
test_idx = torch.from_numpy(data['test_idx']).long().squeeze(0)
num_nodes = author_g.number_of_nodes()
train_mask = get_binary_mask(num_nodes, train_idx)
val_mask = get_binary_mask(num_nodes, val_idx)
test_mask = get_binary_mask(num_nodes, test_idx)
print('dataset loaded')
pprint({
'dataset': 'ACM',
'train': train_mask.sum().item() / num_nodes,
'val': val_mask.sum().item() / num_nodes,
'test': test_mask.sum().item() / num_nodes
})
return gs, features, labels, num_classes, train_idx, val_idx, test_idx, \
train_mask, val_mask, test_mask
- HAN模型

HAN
class HAN(nn.Module):
def __init__(self, num_meta_paths, in_size, hidden_size, out_size, num_heads, dropout):
super(HAN, self).__init__()
self.layers = nn.ModuleList()
self.layers.append(HANLayer(num_meta_paths, in_size, hidden_size, num_heads[0], dropout))
for l in range(1, len(num_heads)):
self.layers.append(HANLayer(num_meta_paths, hidden_size * num_heads[l-1],
hidden_size, num_heads[l], dropout))
self.predict = nn.Linear(hidden_size * num_heads[-1], out_size)
def forward(self, g, h):
for gnn in self.layers:
h = gnn(g, h)
return self.predict(h)
HANLayer
class HANLayer(nn.Module):
"""
HAN layer.
Arguments
---------
num_meta_paths : number of homogeneous graphs generated from the metapaths.
in_size : input feature dimension
out_size : output feature dimension
layer_num_heads : number of attention heads
dropout : Dropout probability
Inputs
------
g : list[DGLGraph]
List of graphs
h : tensor
Input features
Outputs
-------
tensor
The output feature
"""
def __init__(self, num_meta_paths, in_size, out_size, layer_num_heads, dropout):
super(HANLayer, self).__init__()
# One GAT layer for each meta path based adjacency matrix
# Node_attention
self.gat_layers = nn.ModuleList()
for i in range(num_meta_paths):
self.gat_layers.append(GATConv(in_size, out_size, layer_num_heads,
dropout, dropout, activation=F.elu))
# SemanticAttention
self.semantic_attention = SemanticAttention(in_size=out_size * layer_num_heads)
self.num_meta_paths = num_meta_paths
def forward(self, gs, h):
semantic_embeddings = []
for i, g in enumerate(gs):
semantic_embeddings.append(self.gat_layers[i](g, h).flatten(1))
semantic_embeddings = torch.stack(semantic_embeddings, dim=1) # (N, M, D * K)
return self.semantic_attention(semantic_embeddings) # (N, D * K)
SemanticAttention
class SemanticAttention(nn.Module):
def __init__(self, in_size, hidden_size=128):
super(SemanticAttention, self).__init__()
self.project = nn.Sequential(
nn.Linear(in_size, hidden_size),
nn.Tanh(),
nn.Linear(hidden_size, 1, bias=False)
)
def forward(self, z):
w = self.project(z).mean(0) # (M, 1)
beta = torch.softmax(w, dim=0) # (M, 1)
beta = beta.expand((z.shape[0],) + beta.shape) # (N, M, 1)
return (beta * z).sum(1) # (N, D * K)
Graph Transformer Nerworks(GTN)


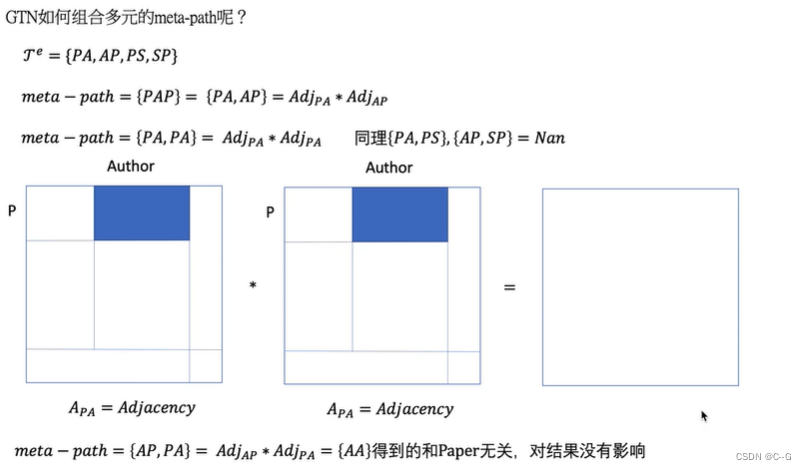
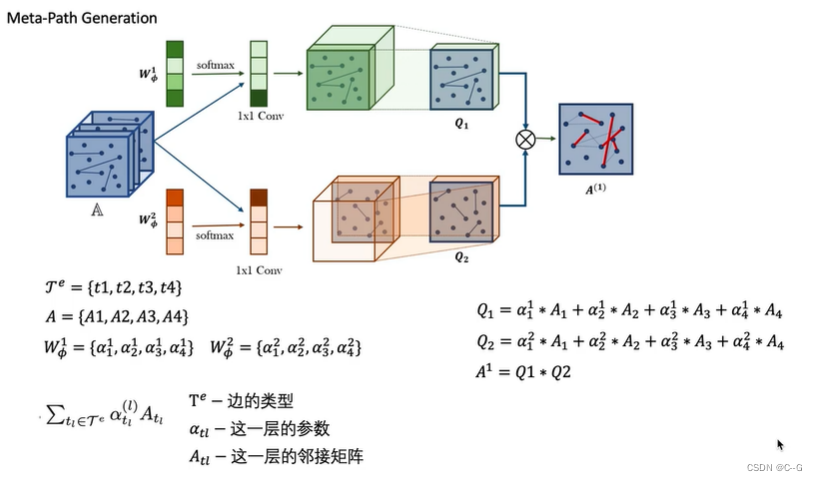
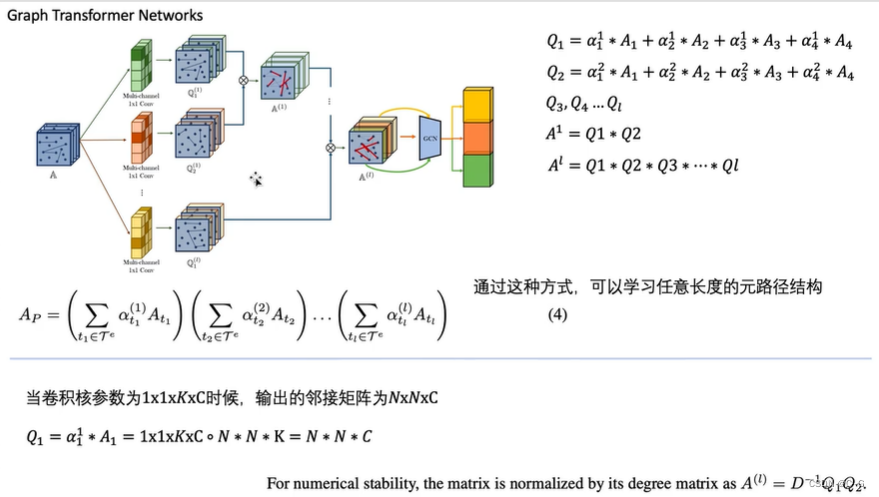

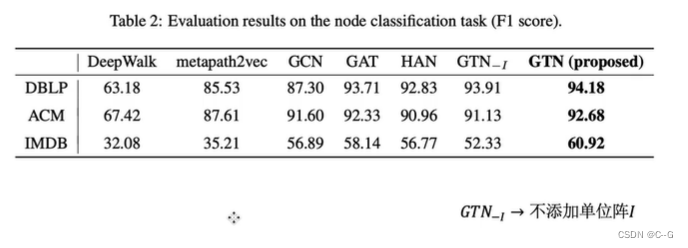
核心代码

GTConv
class GTConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(GTConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.weight = nn.Parameter(torch.Tensor(out_channels,in_channels,1,1))
self.bias = None
self.scale = nn.Parameter(torch.Tensor([0.1]), requires_grad=False)
self.reset_parameters()
def reset_parameters(self):
n = self.in_channels
nn.init.constant_(self.weight, 0.1)
if self.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias, -bound, bound)
def forward(self, A):
A = torch.sum(A*F.softmax(self.weight, dim=1), dim=1)
return A
GTLayer
class GTLayer(nn.Module):
def __init__(self, in_channels, out_channels, first=True):
super(GTLayer, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.first = first
if self.first == True:
self.conv1 = GTConv(in_channels, out_channels)
self.conv2 = GTConv(in_channels, out_channels)
else:
self.conv1 = GTConv(in_channels, out_channels)
def forward(self, A, H_=None):
if self.first == True:
a = self.conv1(A)
b = self.conv2(A)
H = torch.bmm(a,b)
W = [(F.softmax(self.conv1.weight, dim=1)).detach(),(F.softmax(self.conv2.weight, dim=1)).detach()]
else:
a = self.conv1(A)
H = torch.bmm(H_,a)
W = [(F.softmax(self.conv1.weight, dim=1)).detach()]
return H,W
GTN
class GTN(nn.Module):
def __init__(self, num_edge, num_channels, w_in, w_out, num_class,num_layers,norm):
super(GTN, self).__init__()
self.num_edge = num_edge
self.num_channels = num_channels
self.w_in = w_in
self.w_out = w_out
self.num_class = num_class
self.num_layers = num_layers
self.is_norm = norm
layers = []
for i in range(num_layers):
if i == 0:
layers.append(GTLayer(num_edge, num_channels, first=True))
else:
layers.append(GTLayer(num_edge, num_channels, first=False))
self.layers = nn.ModuleList(layers)
self.weight = nn.Parameter(torch.Tensor(w_in, w_out))
self.bias = nn.Parameter(torch.Tensor(w_out))
self.loss = nn.CrossEntropyLoss()
self.linear1 = nn.Linear(self.w_out*self.num_channels, self.w_out)
self.linear2 = nn.Linear(self.w_out, self.num_class)
self.reset_parameters()
def reset_parameters(self):
nn.init.xavier_uniform_(self.weight)
nn.init.zeros_(self.bias)
def gcn_conv(self,X,H):
X = torch.mm(X, self.weight)
H = self.norm(H, add=True)
return torch.mm(H.t(),X)
def normalization(self, H):
for i in range(self.num_channels):
if i==0:
H_ = self.norm(H[i,:,:]).unsqueeze(0)
else:
H_ = torch.cat((H_,self.norm(H[i,:,:]).unsqueeze(0)), dim=0)
return H_
def norm(self, H, add=False):
H = H.t()
if add == False:
H = H*((torch.eye(H.shape[0])==0).type(torch.FloatTensor))
else:
H = H*((torch.eye(H.shape[0])==0).type(torch.FloatTensor)) + torch.eye(H.shape[0]).type(torch.FloatTensor)
deg = torch.sum(H, dim=1)
deg_inv = deg.pow(-1)
deg_inv[deg_inv == float('inf')] = 0
deg_inv = deg_inv*torch.eye(H.shape[0]).type(torch.FloatTensor)
H = torch.mm(deg_inv,H)
H = H.t()
return H
def forward(self, A, X, target_x, target):
A = A.unsqueeze(0).permute(0,3,1,2)
Ws = []
for i in range(self.num_layers):
if i == 0:
H, W = self.layers[i](A)
else:
H = self.normalization(H)
H, W = self.layers[i](A, H)
Ws.append(W)
#H,W1 = self.layer1(A)
#H = self.normalization(H)
#H,W2 = self.layer2(A, H)
#H = self.normalization(H)
#H,W3 = self.layer3(A, H)
for i in range(self.num_channels):
if i==0:
X_ = F.relu(self.gcn_conv(X,H[i]))
else:
X_tmp = F.relu(self.gcn_conv(X,H[i]))
X_ = torch.cat((X_,X_tmp), dim=1)
X_ = self.linear1(X_)
X_ = F.relu(X_)
y = self.linear2(X_[target_x])
loss = self.loss(y, target)
return loss, y, Ws














 6319
6319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









