







简介
对于单目视频,在恢复静态环境的同时对动态目标进行分割和解耦是机器智能中广泛研究的问题。现有的解决方案通常在图像领域处理这个问题,限制了它们的性能和对环境的理解。论文引入了解耦动态神经辐射场(D2NeRF),这是一种自我监督的方法,它从单目视频中学习一个3D场景表示,从静态背景中解耦运动物体,包括它们的阴影。论文的方法通过两个单独的神经辐射场来表示运动对象和静态背景,其中只有一个允许时间变化。这种方法的简单实现会导致动态组件取代静态组件,因为前者的表示本质上更一般化,而且容易过拟合。为此,论文提出了一个新的损失,以促进正确的分离现象。论文进一步提出了一个阴影场网络来检测和解耦动态移动的阴影。
实现流程
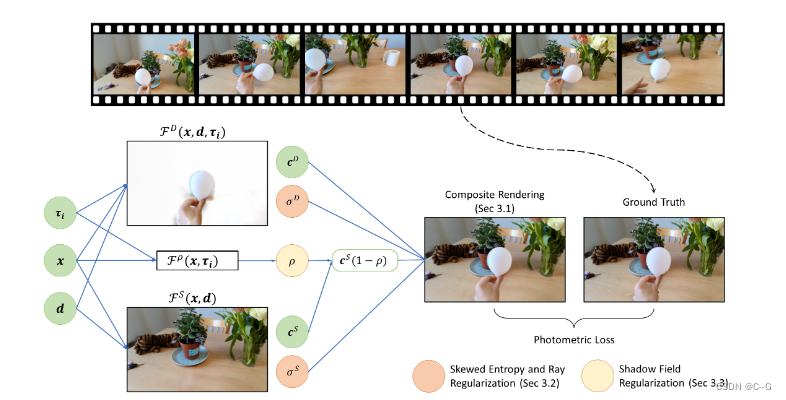
给定真实视图、相机姿态和时间框架,将底层场景重建为一个复合辐射场。动态对象用FD表示,静态场景用FS表示。阴影场Fρ模拟了输入视频中的非静态阴影
相关工作——Motion Decoupling(运动解耦)
为了获得动态和静态场景的解耦三维表示,以前的工作可以分为监督和自我监督两种方法
监督方法
- STNeRF通过预先训练的人类分割网络学习动态场景中每个人的带有变形场的单个nerf
- NSFF和DynNeRF依靠预先训练的语义和运动分割方法获得单眼视频中运动物体的掩码,并明确指导单独NeRF网络的训练,基于运动对场景进行解耦
自监督方法
- SIMONe合并了一个变压器编码器和变分自动解码器,以同时恢复新的视图、对象分割掩码和动态对象轨迹,但它们不允许单独合成动态或静态对象
- NeRF-W使用每帧嵌入在不受约束的照片集合中建模非光度一致的效果,但他们的设计不是为了在移动物体和静态场景之间进行干净的分离
- STaR通过自监督的方式优化两个nerf和一组时变物体姿态,同时对刚性动态物体和静态背景进行重构和分解,但仅适用于单个刚性动态物体场景,且需要多视图视频
- NeuralDiff融合了三种基于nerf的流线来分解背景,对象和参与者从一个自我中心的视频,然而,它使用朴素的时变NeRF架构导致模糊的结果,因此严重限制了它在场景分解和重建方面的性能。
Composite Neural Radiance Field
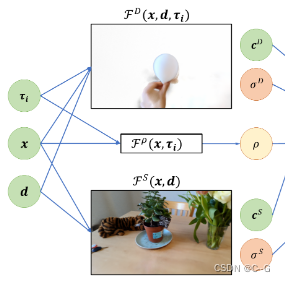
静态组件基于NeRF,使用多层感知器 FS(x,d) 将场景表示为连续的空间依赖密度σ和空间视依赖亮度c
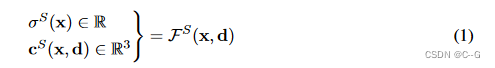
x∈R3为空间坐标,d∈R3,‖d‖= 1为视图方向
动态组件扩展于HyperNeRF——通过引入额外的自由度和网络容量,它可以准确地捕捉非刚性运动以及拓扑变化的场景,记为FD(x,d,τi)
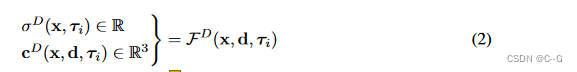
τi∈Rm为每帧时间潜在码
给定一个来自o且方向为d的相机射线r = o + td,根据预先定义的深度范围[tn, tf]内的体积渲染对亮度进行积分,将这两个模型合成,得到复合NeRF,计算相机射线的颜色ˆC
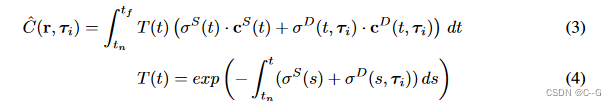
简化公式为 σ(t) ≡ σ(r(t)) and c(t) ≡ c(r(t), d),具有这样的相加分解,来自两个领域的样本都能够终止相机射线和遮挡另一个。
Supervision Losses
使用了一个光度损失,以确保复合NeRF (Eq. 3)的输出图像序列与输入视频帧对齐
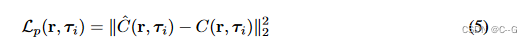
C(r, τi)为第i个输入视频帧得到的摄像机射线r的真实颜色
动态组件可以通过不正确地将静态对象的占用分配给动态NeRF来自然地接管静态对等物,而且光度损失本身也不能保证正确的分离
因此论文引入一组正则化器,以自我监督的方式促进这种解耦
Dynamic vs. Static Factorization
在引入正则化器前,我们需要明确,物理物体不能在同一个空间位置共存,即有一个静态场景或一个动态物体在空间中的任何位置,但不能两者都有,将动态与静态密度的空间比率表示为
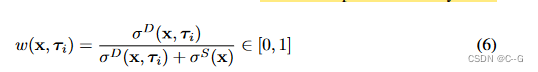
通过二进制熵损失来惩罚其对分类{0,1}分布的偏离
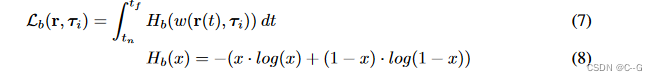
由于动态网络的表达能力很强(Eq. 2),优化损失(Eq. 7)导致该技术将场景的部分建模为动态的,无论它们是动态的还是静态的
为此,引入一个倾斜的熵损失,使损失稍微偏向于带有偏斜度超参数 k 的场景的静态解释

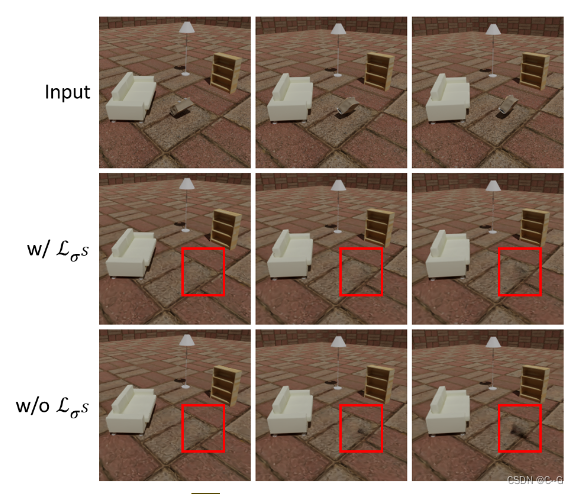
Skewed entropy-(左),skewed(k > 1)和 classical(k = 1)熵损失。倾斜熵促使 w 减小的范围更大,在0.5附近有较大的梯度,但当 w 接近0时,其梯度消失。(右)当原始、适当倾斜和过倾斜的二进制熵损失被应用时,解耦 α Mask(掩膜)和静态组件。
Ray Regularization
选择偏度k的大值会导致场景的静态部分出现模糊的浮蚊(低密度的粒子);如上图(右,k=10)所示。从上图(左)可以直观地理解,这是由于随着x趋于零,Hb(xk)的梯度较小造成的。为了减轻这种影响,并减少重建中的模糊性,惩罚沿着每个相机射线的w的最大值
这种损失可以直观地解释为约束动态分量,使其占用尽可能少的像素,同时保持对所有样本整体损失的影响最小。注意Lr只移除那些沿着相机射线而不与任何动态物体相交的密度浮动物
Static Regularization
静态组件可能滥用相机姿势作为提示当前的时间框架和学习动态效果稀疏的云,导致高频外观变化。这种模糊性是因为使用的是单目视频,在捕捉过程中,相机几乎从不访问完全相同的位置两次。也就是说,摄像机姿态与时间变量之间存在一对一的映射关系。
静态正则化,通过在静态组件沿每个相机射线鼓励一个更集中的密度分布,恢复的背景包含较少的视相关的工件。
通过对沿射线的密度分布进行先验处理来解决这个问题,惩罚会导致云状伪影的密度分布
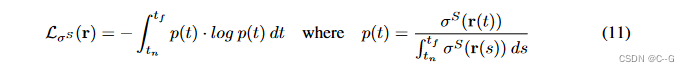
Shadow Fields
神经辐射场不能忠实地建模独立的阴影,除非对其架构建模材料和照明进行必要的重大更改,如NeRFactor;
动态物体快速移动的简单情况下,它们可以作为静态表面上半透明层的动态辐射场学习。然而,对于不怎么移动的阴影,或者与相机视图高度相关的阴影,这往往是失败的。由于阴影是没有纹理的,理解它们的运动是不明确的,将它们表示为半透明层会给优化带来困难;

阴影模糊-当阴影在输入数据中频繁出现时,平均阴影被集成到静态组件中,而动态组件错误地学习了这个平均值的微分,并出现一个更亮的表面。这可以通过对静态区域(即阴影场)进行动态暗化的阴影效果进行更直接的建模来避免。
为了克服这个问题,在直接照明模型的假设下(即可以忽略的全局照明效果),观察到一个投下的阴影可以表示为静态场景亮度的逐点下降,并将其纳入公式3中:
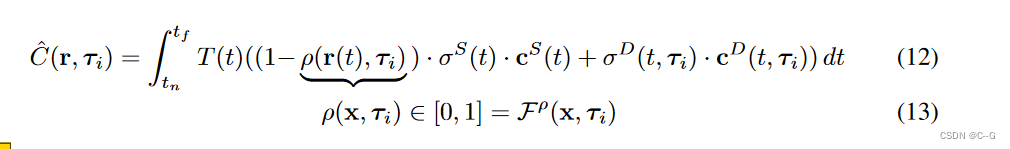 其中ρ(x, τi)是一个按比例缩小静态场景亮度以纳入阴影的阴影比。
其中ρ(x, τi)是一个按比例缩小静态场景亮度以纳入阴影的阴影比。
为了避免过度解释场景的黑暗区域而产生的阴影比例,惩罚沿着光线的平均平方大小:
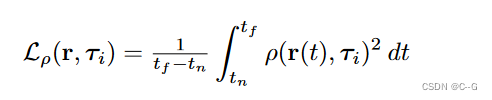
从动态对象投射到其他动态对象上的阴影已经通过动态分支的亮度项表达出来了,不需要显式建模
细节
总损失
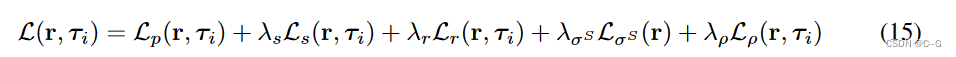
λs、λr、λσS、λρ分别为正则项的权值
对于混合有动态物体和阴影的场景,应用阴影衰减和λρ=0.1,设置λρ=0.001仅用于具有视相关动态阴影的场景
不使用阴影场来评估合成场景,因为根据经验发现,阴影场不需要学习正确的阴影。还禁用了合成场景的视图方向输入,因为它们不包含强烈的视图相关效果
超参数的最佳选择,尤其是λb、λr和偏度k,受到物体运动水平、相机运动和视频长度的强烈影响
对合成的真实世界场景和DAVIS中的一些场景进行了网格搜索,以建立一组适用于各种场景的超参数
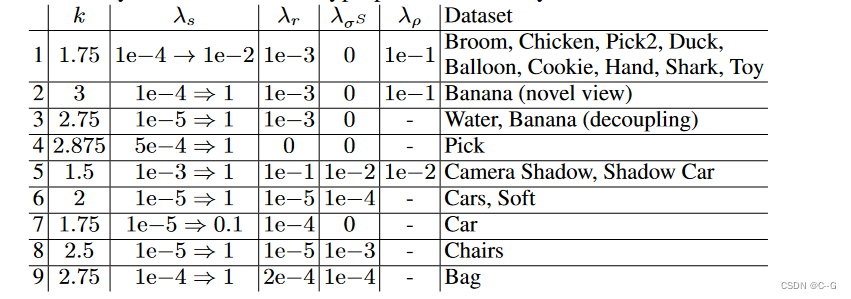
第1-4行指定了包含动态对象和阴影混合的真实场景的超参数,而第5行只适用于只有动态阴影的真实场景。第6-9行包含合成场景的超参数。
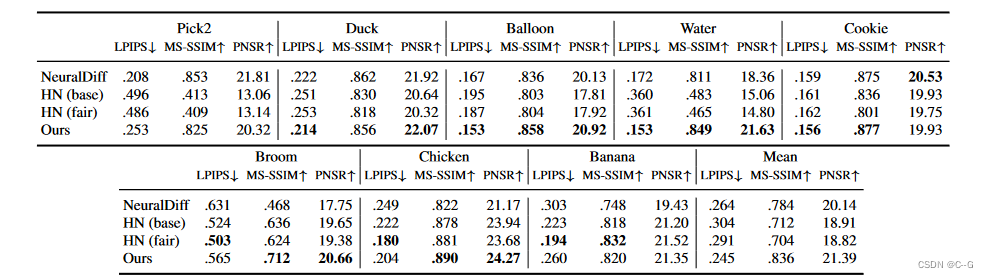
效果



















 7034
7034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









