







简介
主页:https://jia-wei-liu.github.io/DeVRF/
论文提出高效实用的学习范式,即静态→动态,用于学习变形辐射场,这背后的关键思想是,从多视点静态图像学习的三维体积标准空间可以引入归纳偏差[3],以解锁可变形辐射场的有效学习,有了这样的3D先验,一个动态场景只需要几个固定的摄像机就可以有效地建模,在实践中,这样的少量固定摄像机设置用于动态场景数据捕获比移动摄像机更方便。优化方面,使用粗到精的4D变形场训练策略,以进一步提高效率,提出三个目标,以鼓励DeVRF以高保真度重建动态辐射场,保持变形周期一致性、光流监测和总变化正则化
只需要几个相机进行数据捕获,在单个NVIDIA GeForce RTX3090 GPU上实现了大约10分钟的快速动态辐射场建模
贡献点
- 提出了一种新的DeVRF视角,它能够实现快速的非刚性神经场景重建,与具有同等高保真度的SOTA方法相比,它实现了令人印象深刻的100倍加速。
- 第一个将4D体素变形场纳入动态辐射场的
- 设计了一个静态→动态的学习范式,可以通过低成本但有效的捕获设置来提高性能
相关工作
动态NeRF
D-NeRF学习变形场,将动态场中的坐标映射到基于nerf的规范空间。
Nerfies进一步关联变形MLP和规范NeRF中的潜在代码,以处理更具有挑战性的场景,如移动的人。
HyperNeRF提出在高维空间中建模运动,通过切片多维空间来表示与时间相关的辐射场。
Video-NeRF将动态场景建模为4D时空辐射场,并使用场景深度解决运动模糊
NeRF加速
DVGO用显式和离散的体积表示对辐射场建模,将训练时间缩短到几分钟。
Plenoxels采用稀疏体素网格作为场景表示,并使用球形谐波来建模与视图相关的外观,达到了类似的训练加速。
Instant-ngp提出了多分辨率哈希编码;加上高度优化的GPU实现,它可以在几秒钟的训练后产生具有竞争力的结果
实现流程
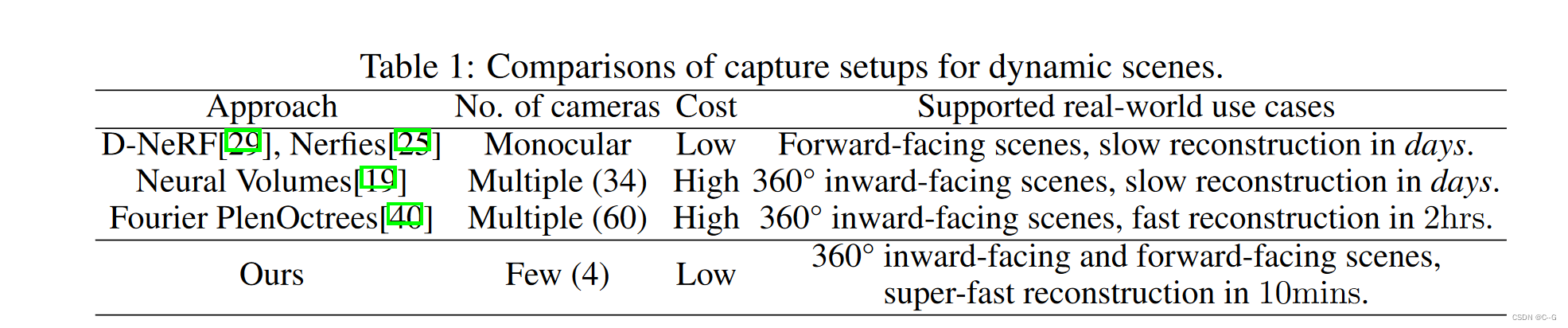
Capture Setup
可变形场景经历各种类型的变形和运动,这可能导致不同的场景属性,如物体的姿态、形状和遮挡,如果用多视角序列捕捉360°面向内的动态场景,因此需要数十台高质量相机。
在实际操作中,由于动态场景中存在各种类型的变形和产生的遮挡,特别是在快速变形的场景中,用单个移动摄像机捕捉真实世界的360°面向内的动态场景尤其具有挑战性,因此,后续的研究只能用单目摄像机捕捉现实世界动态场景的正向视频
论文将动态场景的捕获过程分为两个阶段
- 使用移动的单目相机捕捉静态状态
- 使用几个固定的摄像机捕捉动态场景
多视图静态图像提供了完整的三维几何和场景外观信息,而少视图动态序列显示了场景如何随着时间在三维空间中变形
资源消耗对比
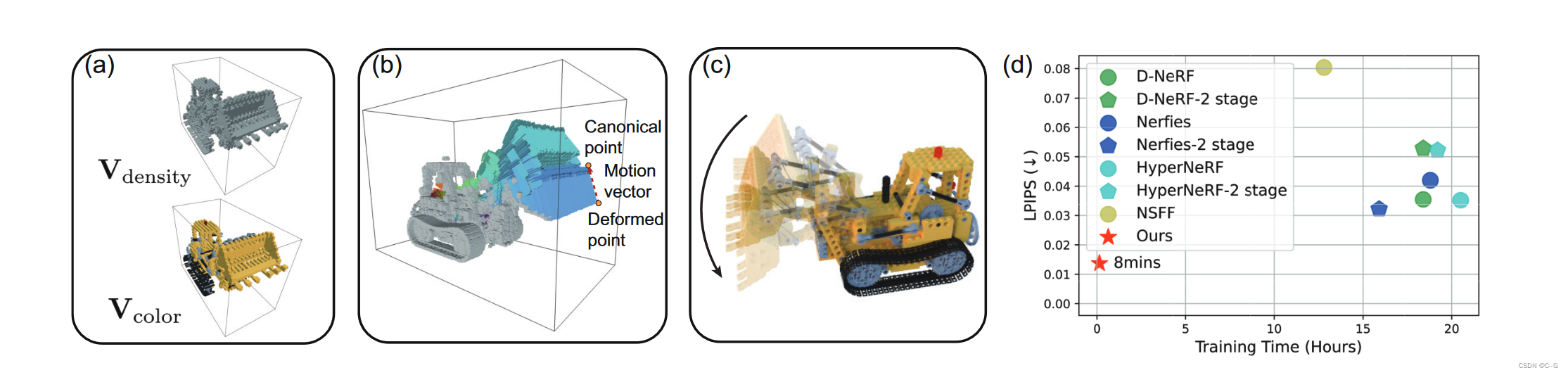
Deformable Voxel Radiance Fields
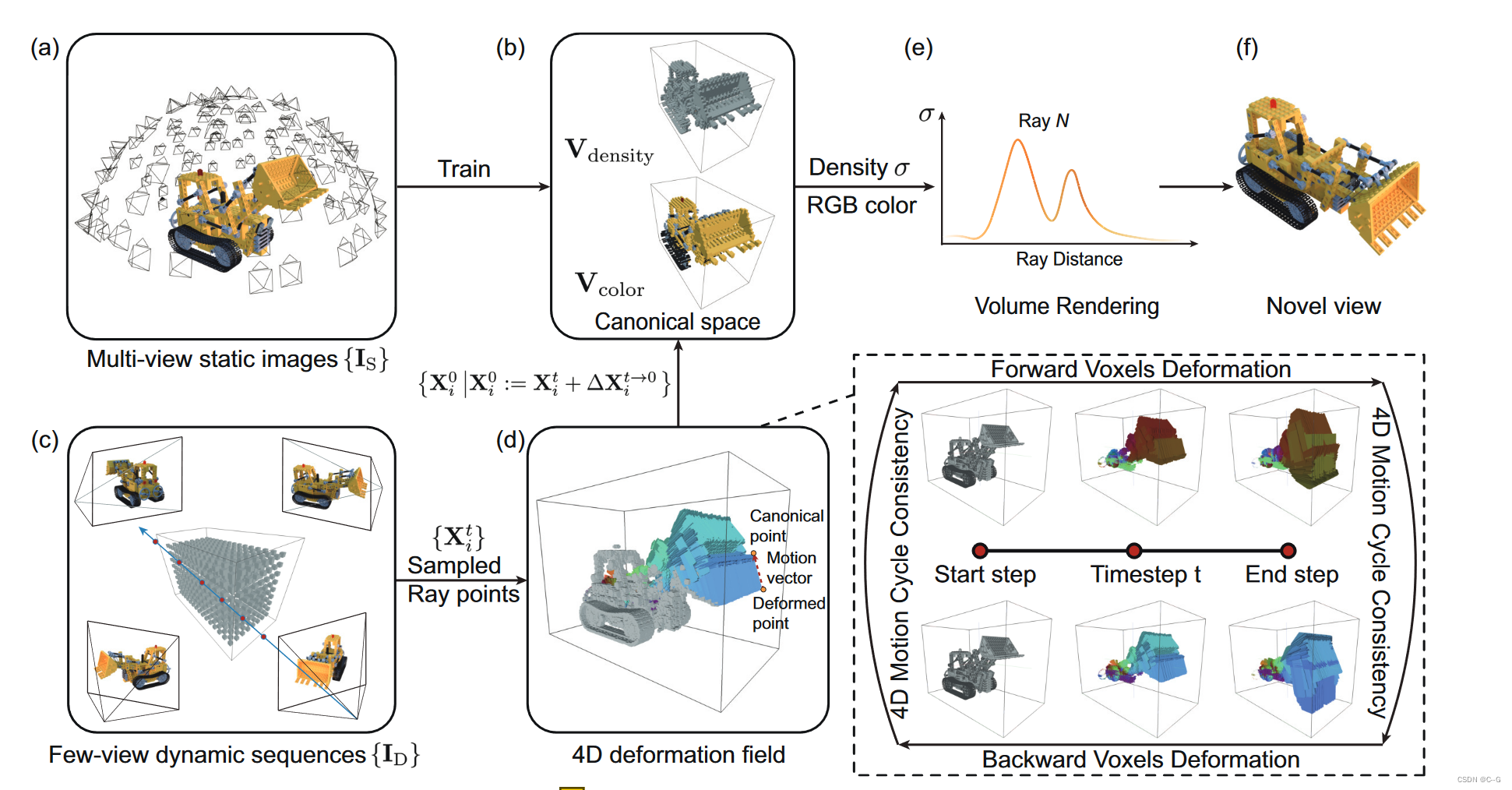
论文提出了DeVRF来建模具有显式和离散体素表示的非刚性场景的3D标准空间和4D变形场
在第一阶段,DeVRF从多视图静态图像(a)中学习三维体积标准先验(b)。即:将3D规范空间的密度和颜色等场景属性建模到体素网格中,这样能够通过其邻近体素的三线性插值有效地查询任何3D点的场景属性
在第二阶段,通过获取少视图动态序列(c)和3D标准先验(b),联合优化4D变形场(d)。对于从变形帧采样的射线点,可以从4D向后变形场(d)中有效地查询其到标准空间的变形。因此,可以在三维体标准空间中通过线性插值得到这些变形点的场景属性(即密度、颜色),并利用这些变形样本点通过体绘制(e)合成相应的新视图(f)。
3D Volumetric Canonical Space

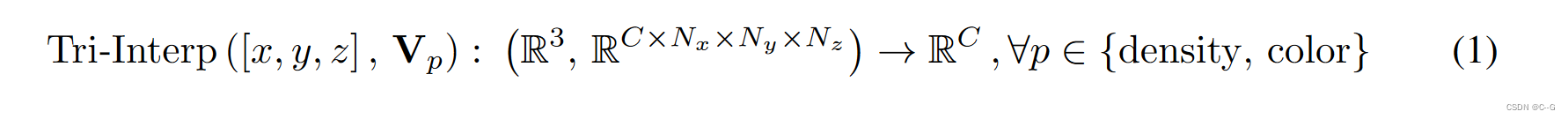
其中 C 为场景属性
V
p
V_p
Vp 的维度。
N
x
、
N
y
和
N
z
分别是
V
p
N_x、N_y和N_z分别是V_p
Nx、Ny和Nz分别是Vp 在x、y、z维的体素分辨率
上图a-b,通过体绘制的多视图静态图像 I S {I_S} IS ,学习了三维体积正则先验,即密度网格 V d e n s i t y V_{density} Vdensity和颜色网格 V c o l o r V_{color} Vcolor
遵循DVGO,在 v 密度下对一个三维点进行三线性插值后,使用了softplus和post-activation,因为这对锐利边界和高频几何重建至关重要,在 V c o l o r V_{color} Vcolor中对一个3D点进行三线性插值后应用一个浅MLP,以实现与视图相关的颜色效果
在静态→动态学习范式中,学习到的三维体积标准先验提供了目标动态场景的三维几何和外观的关键知识,因为只有少数视图动态序列很难以高保真度重建完整的可变形辐射场
4D Voxel Deformation Field

箭头方向表示体素的运动,颜色表示运动方向,箭头大小表示运动尺度
为了合成时间步 t 的新视图,在三维空间中通过图像像素和采样射线点 X t = X i t X_t = {X^t_i} Xt=Xit发射射线
通过在4D向后变形场中相邻时间步上相邻体素的四次插值,可以有效地查询到
X
t
X_t
Xt 到规范空间
X
0
=
{
X
i
0
∣
X
i
0
=
X
i
t
+
∆
X
i
t
→
0
}
X_0 = \{X^0_i | X^0_i = X^t_i +∆X^{t→0}_i\}
X0={Xi0∣Xi0=Xit+∆Xit→0}中对应的3D点的三维运动
∆
X
t
→
0
=
{
∆
X
i
t
→
0
}
∆X_{t→0} =\{∆X^{t→0}_i\}
∆Xt→0={∆Xit→0}。
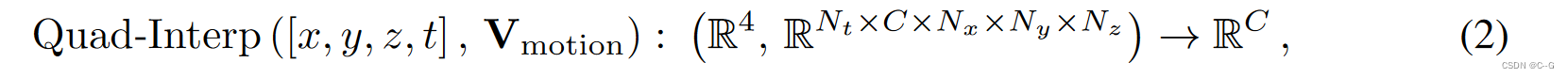
其中 C 为采样点运动的自由度(DoFs)。使用C = 3,即为每个采样点分配一个位移向量。
N
t
N_t
Nt是关键时间步骤的数量,可以根据场景运动属性自定义。
X t X_t Xt 的场景性质可以通过在体积正则空间中通过三线性插值查询其对应的正则点 X 0 X_0 X0的场景性质得到
Optimization
Coarse-to-Fine Optimization
对于 N t × C × N x × N y × N z N_t ×C ×N_x ×N_y ×N_z Nt×C×Nx×Ny×Nz分辨率的密集4D体素变形场,可能存在数百万个自由参数,这些参数容易出现过拟合和次优解
论文使用由粗到精的训练策略,逐步提高了4D体素变形场的 x-y-z 分辨率,从10 × 10 × 10到160 × 160 × 160
Re-rendering Loss
利用
X
t
X_t
Xt处的采样属性,通过体绘制可以计算出像素的颜色,即沿着射线 r 对
X
t
X_t
Xt 的密度和颜色进行积分
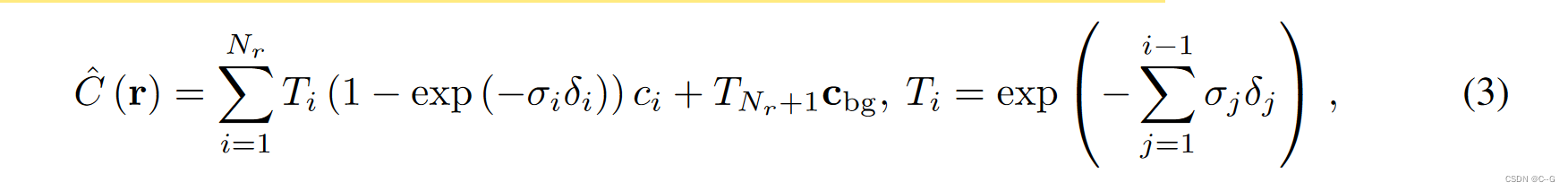
N
r
N_r
Nr 为沿射线采样的变形点数,
T
i
T_i
Ti 为光通过射线 r 传到第 i 个采样点的概率,
1
−
e
x
p
(
−
σ
i
δ
i
)
1−exp(−σ_iδ_i)
1−exp(−σiδi) 为光在第 i 个采样点终止的概率。
δ
i
δ_i
δi 为相邻采样点之间的距离,
σ
i
、
c
i
σ_i、c_i
σi、ci 分别为变形点 i 的密度和颜色。
C
b
g
C_{bg}
Cbg 是预定义的背景色
对于具有校正姿态 { I D } \{I_D\} {ID} 的少视图训练动态序列,DeVRF通过最小化观测像素颜色 C® 和渲染像素颜色 C ^ ( r ) \hat{C}(r) C^(r)之间的光度MSE损失来优化。
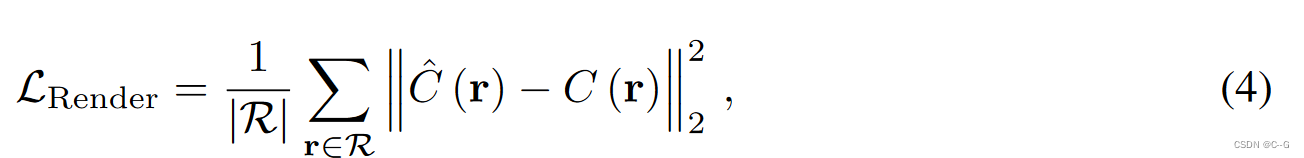
R是小批量射线的集合
4D Deformation Cycle Consistency
强制前后运动的4D变形周期一致,使学习到的变形场正则化,在4D变形循环中,逆向运动向量
∆
X
t
→
0
∆X_{t→0}
∆Xt→0 模拟从
X
t
X_t
Xt 到
X
0
X_0
X0 的运动;而正向运动向量
∆
X
0
→
t
∆X_{0→t}
∆X0→t 则模拟了动态空间中从
X
0
X_0
X0到相应3D点的运动情况,
∆
X
~
t
=
{
X
~
i
t
∣
X
~
i
t
=
X
i
0
+
∆
X
i
0
→
t
}
∆\tilde{X}_t = \{ \tilde{X}^t_i | \tilde{X}^t_i = X^0 _i +∆X^{0→t}_i \}
∆X~t={X~it∣X~it=Xi0+∆Xi0→t}。4D运动周期一致性现在可以通过最小化以下周期一致性损失
L
C
y
c
l
e
(
t
)
L_{Cycle}(t)
LCycle(t)来实现
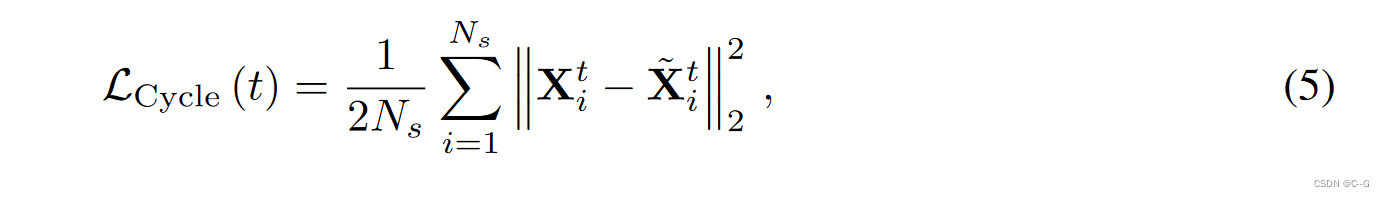
N
s
N_s
Ns为小批中采样的3D点数量
Optical Flow Supervision
利用预训练的RAFT模型,从每个动态序列的连续帧估计二维光流间接监督DeVRF。对于
X
t
X_t
Xt及其对应的
X
0
X_0
X0,首先通过前向运动法计算出
X
0
X_0
X0在 t−1 时间步时对应的3D点,方法为:
X
~
t
−
1
=
X
~
i
t
−
1
∣
X
~
i
t
−
1
=
X
i
0
+
∆
X
i
0
→
t
−
1
\tilde{X}_{t−1} = { \tilde{X}^{t−1}_i | \tilde{X}^{t−1}_i = X^0_i +∆X^{0→t−1}_i}
X~t−1=X~it−1∣X~it−1=Xi0+∆Xi0→t−1。然后,在参考相机上投影
X
~
t
−
1
\tilde{X}_{t−1}
X~t−1,得到它们的像素位置
P
~
t
−
1
=
P
~
i
t
−
1
\tilde{P}_{t−1} ={\tilde{P}^{t−1}_i}
P~t−1=P~it−1,并计算
X
t
X_t
Xt 光线从像素位置
P
t
=
P
i
t
P_t = {P^t_i}
Pt=Pit 投射的诱导光流。通过最小化
L
F
l
o
w
(
t
)
L_{Flow} (t)
LFlow(t)来使诱导流量与估计流量相同,
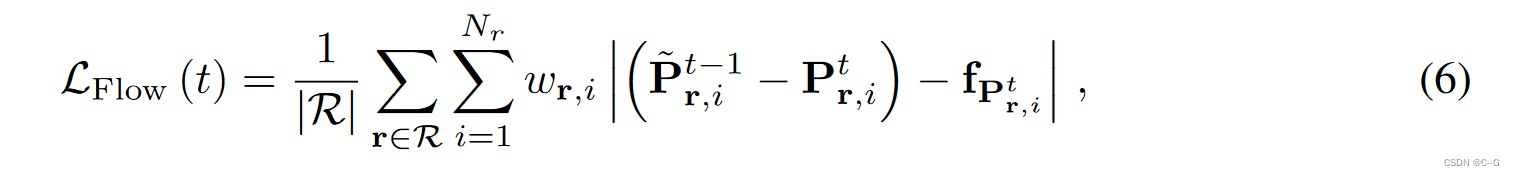
其中
W
r
,
i
=
T
i
(
1
−
e
x
p
(
−
σ
i
δ
i
)
)
W_{r,i} = T_i ( 1−exp(−σ_iδ_i))
Wr,i=Ti(1−exp(−σiδi))为式(3)中的射线终止权值,
f
P
r
,
i
t
为像素
P
r
,
i
t
f_{P^t_{r,i}} 为像素 P^t_{r,i}
fPr,it为像素Pr,it处估计的二维反向光流。
Total Variation Regularization
使用了总变异先验来加强相邻体素之间的运动平滑性。在时间步骤 t
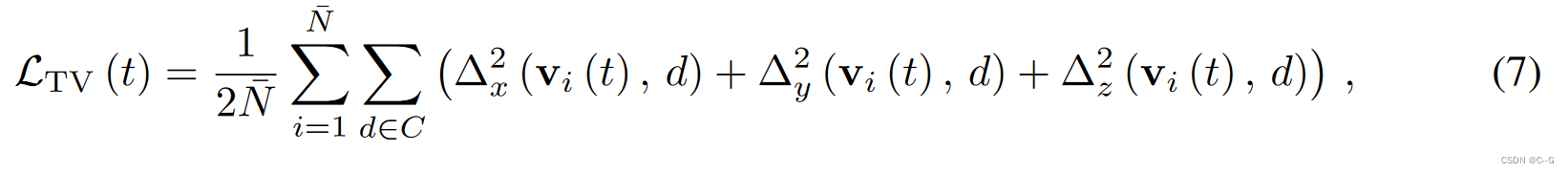
∆
x
,
y
,
z
2
∆^2_{x,y,z}
∆x,y,z2是体素vi与其相邻体素沿 x,y,z 轴的运动向量差的平方。
N
ˉ
=
N
x
×
N
y
×
N
z
\bar{N} = N_x × N_y × N_z
Nˉ=Nx×Ny×Nz为体素数。
Training Objective
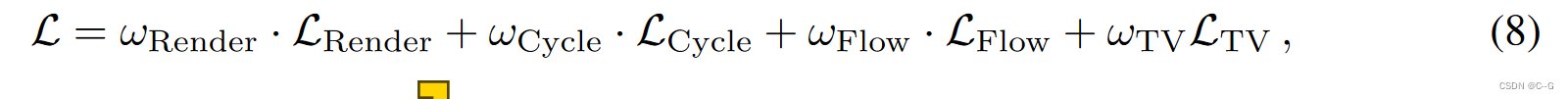
ω
R
e
n
d
e
r
=
1
,
ω
C
y
c
l
e
=
100
,
ω
F
l
o
w
=
0.005
,
ω
T
V
=
1
ω_{Render} = 1, ω_{Cycle} =100 , ω_{Flow}=0.005, ω_{TV}=1
ωRender=1,ωCycle=100,ωFlow=0.005,ωTV=1 对应损失的权重
效果
















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









