







简介
论文:https://arxiv.org/abs/2203.03821
github:https://arxiv.org/pdf/2203.03821.pdf
transformer 输入图像的空间维度上产生了相当大的冗余,导致大量的计算成本。
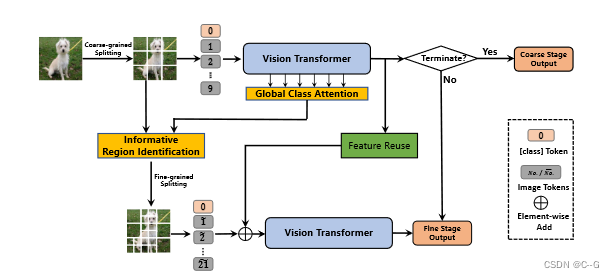
论文提出一种粗到细的vision transformer(CF-ViT)来减轻计算负担,同时保持性能
CF-ViT在不影响性能的情况下,比LV-ViT降低了53%的FLOPs,吞吐量也达到了2.01×
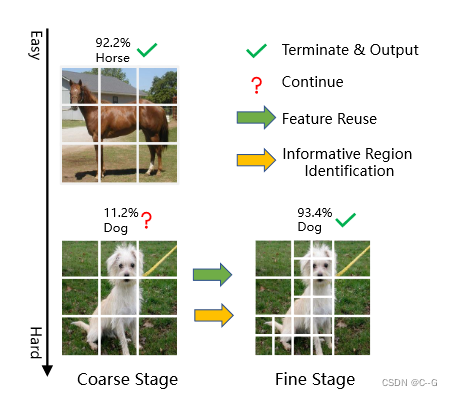
vit transformer 加速方法
- Static ViT Compression
致力于通过手动设计模块,无论输入图像如何,都具有固定的计算图,从而降低网络复杂性 - Dynamic ViT Compression
动态ViT根据其输入图像调整计算图
vis transformer公式
编码、输入
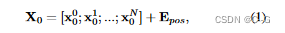
注意力权重
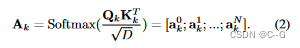
FFN
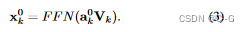
实现流程
主要思想是减少输入序列长度来降低计算成本
理论依据是
- 粗粒度的补丁分割也可以很好地定位信息对象
- 大多数图像在较短的序列长度内都能被ViT模型很好地识别
论文方法将vis transformer的过程分为两阶段实现
在粗推理阶段使用较小长度的标记序列实现图像识别,如果预测结果没达到阈值,进一步分割信息区域以进行细粒度识别
Coarse Inference Stage
输入
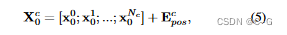
假设有 k 个编码器,输出为

再经过一个分类器 F,得到各个patch的 n-分类结果
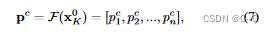
取最大的分类概率值
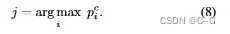
使用阈值 η 来实现性能和计算之间的权衡,如果
p
j
c
>
η
p^c_j > η
pjc>η,那么输出分类结果为 j 类,否则进入细推理阶段
Informative Region Identification
并不是对所有patch都进行细分,识别并重新划分这些对性能提高最有利的信息 patch
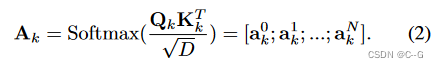
使用类注意力 a k 0 a^0_k ak0 作为分数来指示一个令牌是否具有信息
全局类注意力:此外,使用指数移动平均(EMA)将不同编码器之间的类注意结合起来,以更好地识别信息补丁
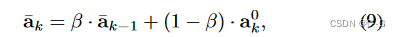
β
=
0.99
\beta = 0.99
β=0.99 全局类注意力从第 4 个编码器开始,在最后一个编码器
α
ˉ
K
\bar{\alpha}_K
αˉK 中选取全局类注意力得分较高的patch
Fine Inference Stage
通过注意力权重大小对patch进行排序后,进一步限制细推理的patch数量
限定细粒度分裂后的patch数为
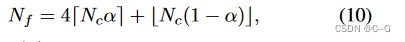
α
∈
[
0
,
1
]
\alpha \in [0,1]
α∈[0,1]提供了准确性和效率之间的权衡
α = 0表示没有很好的推断,结果 patch 最少,虽然计算上很经济,但如果测试集充满了“硬”图像,性能就会下降
α = 1导致CF-ViT精细推理阶段退化到传统的ViT模型
α设为0.5
Feature Reuse
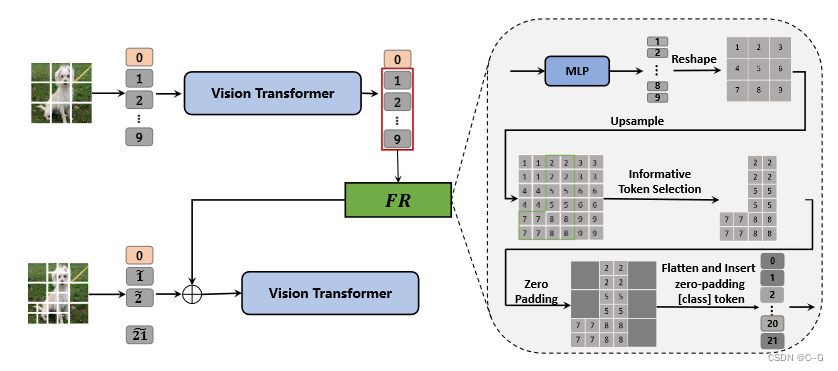
经过patch限定后的输入patch为:
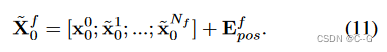
为了不丢失原有的信息,将划分前的patch信息注入到四个细粒度补丁中
如上上图所示, x ~ 0 f \tilde{x}_0^f x~0f首先经过一个MLP映射,然后复制4份,再根据粗推理阶段的预测结果进行筛选,得到 X r = F R ( x K 1 ; x L 2 ; ⋯ ; x K N c ) X_r = FR(x^1_K;x^2_L;\cdots;x_K^{N_c}) Xr=FR(xK1;xL2;⋯;xKNc),然后分别与细粒度划分后的patch相加
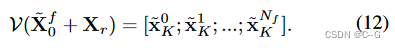
简单而言,就是每个划分后的小patch应该继承划分前大patch的信息
划分后再经过一个分类器得到预测分类结果
p
f
p^f
pf
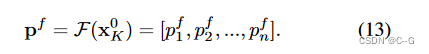
实验
损失函数
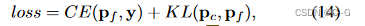
交叉熵损失 和 Kullback-Leibler散度
使用的η = 1,这意味着对每个输入图像都会执行精细推断阶段,η值越大,进入精细推理阶段的输入越多,性能越好,但计算成本也越大,反之亦然
result
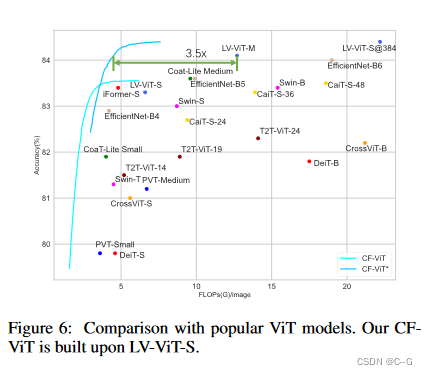
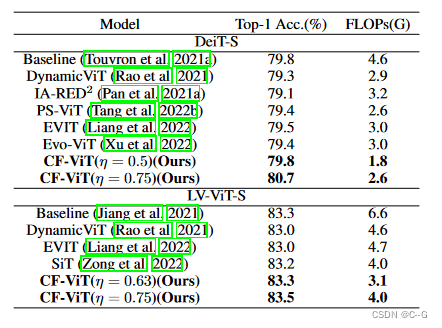















 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









