






一,深度学习基础
1. 了解常见的四个机器学习方法
监督学习、无监督学习、半监督学习、强化学习是我们日常接触到的常见的四个机器学习方法:
- 监督学习:通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出。
- 无监督学习:它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。
- 半监督学习 :在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确。
- 强化学习:我们设定一个回报函数(reward function),通过这个函数来确认否越来越接近目标,类似我们训练宠物,如果做对了就给他奖励,做错了就给予惩罚,最后来达到我们的训练目的。
2.损失函数(Loss Function)
损失函数(loss function)是用来估量模型的预测值(我们例子中的output)与真实值(例子中的y_train)的不一致程度,它是一个非负实值函数,损失函数越小,模型的鲁棒性就越好。
这里有一个重点:因为PyTorch是使用mini-batch来进行计算的,所以损失函数的计算出来的结果已经对mini-batch取了平均
常见(PyTorch内置)的损失函数有以下几个:
nn.L1Loss:
输入x和目标y之间差的绝对值,要求 x 和 y 的维度要一样(可以是向量或者矩阵),得到的 loss 维度也是对应一样的
loss(x,y)=1/n∑|xi−yi|loss(x,y)=1/n∑|xi−yi|
nn.NLLLoss:
用于多分类的负对数似然损失函数
loss(x,class)=−x[class]loss(x,class)=−x[class]
NLLLoss中如果传递了weights参数,会对损失进行加权,公式就变成了
loss(x,class)=−weights[class]∗x[class]loss(x,class)=−weights[class]∗x[class]
nn.MSELoss:
均方损失函数 ,输入x和目标y之间均方差
loss(x,y)=1/n∑(xi−yi)2loss(x,y)=1/n∑(xi−yi)2
nn.CrossEntropyLoss:
多分类用的交叉熵损失函数,LogSoftMax和NLLLoss集成到一个类中,会调用nn.NLLLoss函数,我们可以理解为CrossEntropyLoss()=log_softmax() + NLLLoss()
loss(x,class)=−logexp(x[class])∑jexp(x[j]))=−x[class]+log(∑jexp(x[j]))loss(x,class)=−logexp(x[class])∑jexp(x[j]))=−x[class]+log(∑jexp(x[j]))
因为使用了NLLLoss,所以也可以传入weight参数,这时loss的计算公式变为:
loss(x,class)=weights[class]∗(−x[class]+log(∑jexp(x[j])))loss(x,class)=weights[class]∗(−x[class]+log(∑jexp(x[j])))
所以一般多分类的情况会使用这个损失函数
nn.BCELoss:
计算 x 与 y 之间的二进制交叉熵。
loss(o,t)=−1n∑i(t[i]∗log(o[i])+(1−t[i])∗log(1−o[i]))loss(o,t)=−1n∑i(t[i]∗log(o[i])+(1−t[i])∗log(1−o[i]))
与NLLLoss类似,也可以添加权重参数:
loss(o,t)=−1n∑iweights[i]∗(t[i]∗log(o[i])+(1−t[i])∗log(1−o[i]))loss(o,t)=−1n∑iweights[i]∗(t[i]∗log(o[i])+(1−t[i])∗log(1−o[i]))
用的时候需要在该层前面加上 Sigmoid 函数。
3,梯度下降
在介绍损失函数的时候我们已经说了,梯度下降是一个使损失函数越来越小的优化算法,在无求解机器学习算法的模型参数,即约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一。所以梯度下降是我们目前所说的机器学习的核心,了解了它的含义,也就了解了机器学习算法的含义。
梯度
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。 例如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f(x,y)或者▽f(x,y)。
此处摘自百度百科
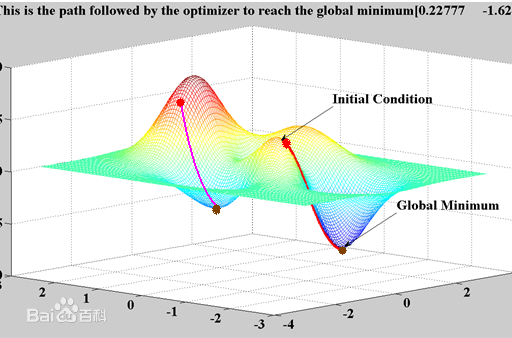

torch.optim是一个实现了各种优化算法的库。大部分常用优化算法都有实现,我们直接调用即可。
二,神经网络简介
在生物神经网络中,每个神经元与其他神经元相连,当它兴奋时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个阈值,那么它就会激活,即兴奋起来并向其他神经元发送化学物质。
在深度学习中也借鉴了这样的结构,每一个神经元(上面说到的简单单元)接受输入x,通过带权重w的连接进行传递,将总输入信号与神经元的阈值进行比较,最后通过激活函数处理确定是否激活,并将激活后的计算结果y输出,而我们所说的训练,所训练的就是这里面的权重w。
神经网络
我们可以将神经元拼接起来,两层神经元,即输入层+输出层(M-P神经元),构成感知机。 而多层功能神经元相连构成神经网络

输入层与输出层之间的所有层神经元,称为隐藏层如上图所示,输入层和输出层只有一个,中间的隐藏层可以有很多层(输出层也可以多个,例如经典的GoogleNet,后面会详细介绍)
激活函数
绍神经网络的时候已经说到,神经元会对化学物质的刺激进行,当达到一定程度的时候,神经元才会兴奋,并向其他神经元发送信息。神经网络中的激活函数就是用来判断我们所计算的信息是否达到了往后面传输的条件。
为什么激活函数都是非线性的
在神经网络的计算过程中,每层都相当于矩阵相乘,无论神经网络有多少层输出都是输入的线性组合,就算我们有几千层的计算,无非还是个矩阵相乘,和一层矩阵相乘所获得的信息差距不大,所以需要激活函数来引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中,增加了神经网络模型泛化的特性。
早期研究神经网络主要采用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入。 近些年Relu函数及其改进型(如Leaky-ReLU、P-ReLU、R-ReLU等),由于计算简单、效果好所以在多层神经网络中应用比较多。
常见的激活函数:
sigmoid 函数
a=11+e−za=11+e−z 导数 :a′=a(1−a)a′=a(1−a)
在sigmoid函数中我们可以看到,其输出是在(0,1)这个开区间,它能够把输入的连续实值变换为0和1之间的输出,如果是非常大的负数,那么输出就是0;如果是非常大的正数输出就是1,起到了抑制的作用
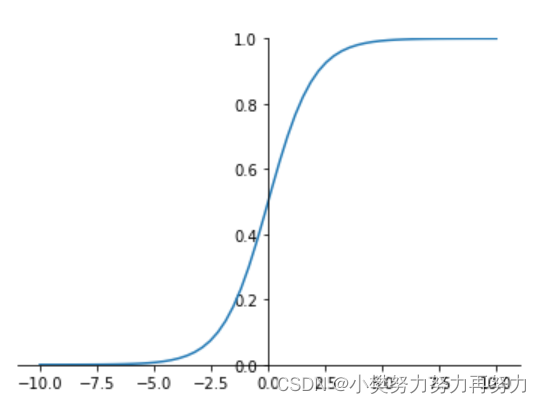
但是sigmod由于需要进行指数运算(这个对于计算机来说是比较慢,相比relu),再加上函数输出不是以0为中心的(这样会使权重更新效率降低),当输入稍微远离了坐标原点,函数的梯度就变得很小了(几乎为零)。在神经网络反向传播的过程中不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。这些不足,所以现在使用到sigmod基本很少了,基本上只有在做二元分类(0,1)时的输出层才会使用。
tanh 函数
a=ez−e−zez+e−za=ez−e−zez+e−z 导数:a′=1−a2a′=1−a2
tanh是双曲正切函数,输出区间是在(-1,1)之间,而且整个函数是以0为中心的

与sigmoid函数类似,当输入稍微远离了坐标原点,梯度还是会很小,但是好在tanh是以0为中心点,如果使用tanh作为激活函数,还能起到归一化(均值为0)的效果。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数,但是随着Relu的出现所有的隐藏层基本上都使用relu来作为激活函数了
ReLU 函数
Relu(Rectified Linear Units)修正线性单元
a=max(0,z)a=max(0,z) 导数大于0时1,小于0时0。
也就是说: z>0时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度。然而当 z<0时,梯度一直为0。 ReLU函数只有线性关系(只需要判断输入是否大于0)不管是前向传播还是反向传播,都比sigmod和tanh要快很多
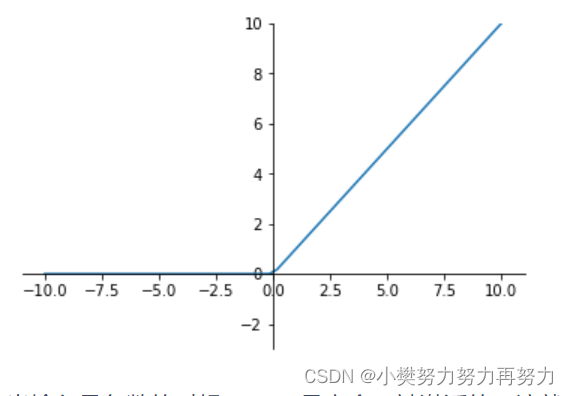
当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。 但是实际的运用中,该缺陷的影响不是很大。
Leaky Relu 函数
为了解决relu函数z<0时的问题出现了 Leaky ReLU函数,该函数保证在z<0的时候,梯度仍然不为0。 ReLU的前半段设为αz而非0,通常α=0.01 a=max(αz,z)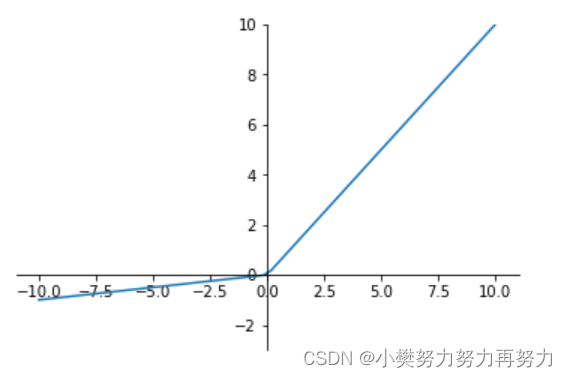
理论上来讲,Leaky ReLU有ReLU的所有优点,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
ReLU目前仍是最常用的activation function,在隐藏层中推荐优先尝试!
正向传播
对于一个神经网络来说,把输入特征a[0]a[0]这个输入值就是我们的输入xx,放入第一层并计算第一层的激活函数,用a[1]a[1]表示,本层中训练的结果用W[1]W[1]和b[l]b[l]来表示,这两个值与,计算的结果z[1]z[1]值都需要进行缓存,而计算的结果还需要通过激活函数生成激活后的a[1]a[1],即第一层的输出值,这个值会作为第二层的输入传到第二层,第二层里,需要用到W[2]W[2]和b[2]b[2],计算结果为z[2]z[2],第二层的激活函数a[2]a[2]。 后面几层以此类推,直到最后算出了a[L]a[L],第LL层的最终输出值y^y^,即我们网络的预测值。正向传播其实就是我们的输入xx通过一系列的网络计算,得到y^y^的过程。
在这个过程里我们缓存的值,会在后面的反向传播中用到。
反向传播
对反向传播的步骤而言,就是对正向传播的一系列的反向迭代,通过反向计算梯度,来优化我们需要训练的WW和bb。 把δa[l]δa[l]值进行求导得到δa[l−1]δa[l−1],以此类推,直到我们得到δa[2]δa[2]和δa[1]δa[1]。反向传播步骤中也会输出 δW[l]δW[l]和δb[l]δb[l]。这一步我们已经得到了权重的变化量,下面我们要通过学习率来对训练的WW和bb进行更新,
W=W−αδWW=W−αδW
b=b−αδbb=b−αδb
这样反向传播就就算是完成了
三,卷积神经网络
卷积神经网络由一个或多个卷积层和顶端的全连通层(也可以使用1x1的卷积层作为最终的输出)组成一种前馈神经网络。2006年后,随着深度学习理论的完善,尤其是计算能力的提升和参数微调(fine-tuning)等技术的出现,卷积神经网络开始快速发展,在结构上不断加深,各类学习和优化理论得到引入,2012年的AlexNet、2014年的VGGNet、GoogLeNet 和2015年的ResNet,使得卷积神经网络几乎成为了深度学习中图像处理方面的标配。
卷积神经网络结构组成
1.卷积层
卷积计算
在每一个卷积层中我们都会设置多个核,每个核代表着不同的特征,这些特征就是我们需要传递到下一层的输出,而我们训练的过程就是训练这些不同的核
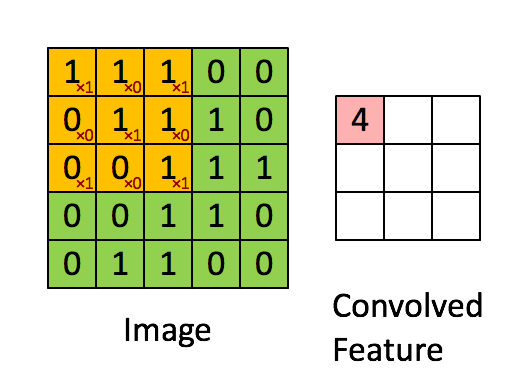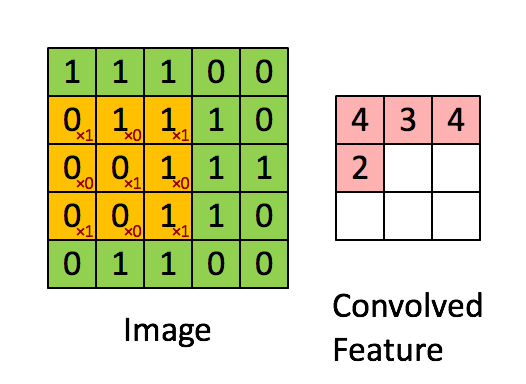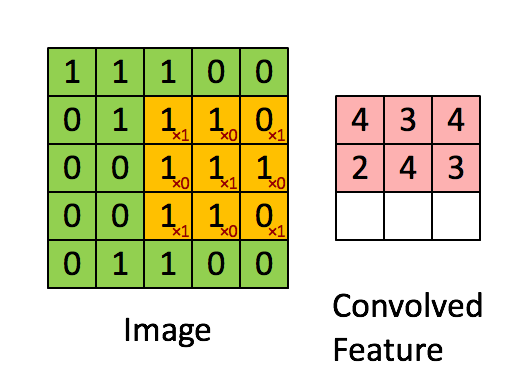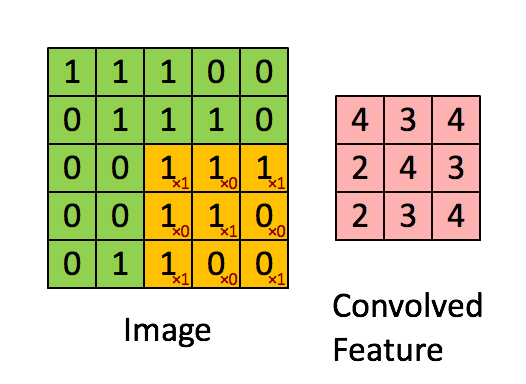
我们会定义一个权重矩阵,也就是我们说的W(一般对于卷积来说,称作卷积的核kernel也有有人称做过滤器filter),这个权重矩阵的大小一般为3 * 3 或者5 * 5,但是在LeNet里面还用到了比较大的7 * 7,现在已经很少见了,因为根据经验的验证,3和5是最佳的大小。 我们以图上所示的方式,我们在输入矩阵上使用我们的权重矩阵进行滑动,每滑动一步,将所覆盖的值与矩阵对应的值相乘,并将结果求和并作为输出矩阵的一项,依次类推直到全部计算完成。
2,卷积核大小 f
刚才已经说到了一个重要的参数,就是核的大小,我们这里用f来表示
3,边界填充 (p)adding
我们看到上图,经过计算后矩阵的大小改变了,如果要使矩阵大小不改变呢,我们可以先对矩阵做一个填充,将矩阵的周围全部再包围一层,这个矩阵就变成了7*7,上下左右各加1,相当于 5+1+1=7 这时,计算的结果还是 5 * 5的矩阵,保证了大小不变,这里的p=1
4,步长 (s)tride
从动图上我们能够看到,每次滑动只是滑动了一个距离,如果每次滑动两个距离呢?那就需要使用步长这个参数。
计算公式
n为我们输入的矩阵的大小,n−f+2ps+1n−f+2ps+1 向下取整
这个公式非常重要一定要记住
激活函数
由于卷积的操作也是线性的,所以也需要进行激活,一般情况下,都会使用relu。
池化层(pooling)
池化层是CNN的重要组成部分,通过减少卷积层之间的连接,降低运算复杂程度,池化层的操作很简单,就想相当于是合并,我们输入一个过滤器的大小,与卷积的操作一样,也是一步一步滑动,但是过滤器覆盖的区域进行合并,只保留一个值。 合并的方式也有很多种,例如我们常用的两种取最大值maxpooling,取平均值avgpooling
池化层的输出大小公式也与卷积层一样,由于没有进行填充,所以p=0,可以简化为 n−fs+1n−fs+1
dropout层
dropout是2014年 Hinton 提出防止过拟合而采用的trick,增强了模型的泛化能力 Dropout(随机失活)是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,说的通俗一点,就是随机将一部分网络的传播掐断,听起来好像不靠谱,但是通过实际测试效果非常好。 有兴趣的可以去看一下原文Dropout: A Simple Way to Prevent Neural Networks from Overfitting这里就不详细介绍了。
全连接层
全链接层一般是作为最后的输出层使用,卷积的作用是提取图像的特征,最后的全连接层就是要通过这些特征来进行计算,输出我们所要的结果了,无论是分类,还是回归。
我们的特征都是使用矩阵表示的,所以再传入全连接层之前还需要对特征进行压扁,将他这些特征变成一维的向量,如果要进行分类的话,就是用sofmax作为输出,如果要是回归的话就直接使用linear即可。
以上就是卷积神经网络几个主要的组成部分,下面我们介绍一些经典的网络模型
经典模型
1998, Yann LeCun 的 LeNet5 官网
卷积神经网路的开山之作,麻雀虽小,但五脏俱全,卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件
- 用卷积提取空间特征;
- 由空间平均得到子样本;
- 用 tanh 或 sigmoid 得到非线性;
- 用 multi-layer neural network(MLP)作为最终分类器;
- 层层之间用稀疏的连接矩阵,以避免大的计算成本。

输入:图像Size为3232。这要比mnist数据库中最大的字母(2828)还大。这样做的目的是希望潜在的明显特征,如笔画断续、角点能够出现在最高层特征监测子感受野的中心。
输出:10个类别,分别为0-9数字的概率
- C1层是一个卷积层,有6个卷积核(提取6种局部特征),核大小为5 * 5
- S2层是pooling层,下采样(区域:2 * 2 )降低网络训练参数及模型的过拟合程度。
- C3层是第二个卷积层,使用16个卷积核,核大小:5 * 5 提取特征
- S4层也是一个pooling层,区域:2*2
- C5层是最后一个卷积层,卷积核大小:5 * 5 卷积核种类:120
- 最后使用全连接层,将C5的120个特征进行分类,最后输出0-9的概率
四,循环神经网络
我们的大脑区别于机器的一个最大的特征就是我们有记忆,并且能够根据自己的记忆对未知的事务进行推导,我们的思想拥有持久性的。但是本教程目前所介绍的神经网络结构各个元素之间是相互独立的,输入与输出是独立的。
RNN的网络结构及原理
循环神经网络的基本结构特别简单,就是将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。我们可以看到网络在输入的时候会联合记忆单元一起作为输入,网络不仅输出结果,还会将结果保存到记忆单元中,下图就是一个最简单的循环神经网络在输入时的结构示意图。图片来源

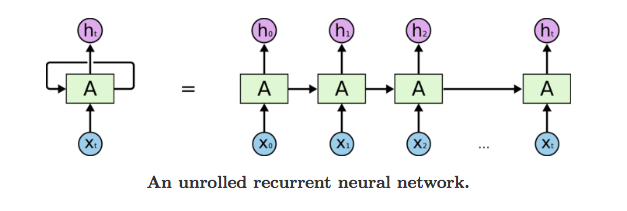
RNN 可以被看做是同一神经网络的多次赋值,每个神经网络模块会把消息传递给下一个,我们将这个图的结构展开 网络中具有循环结构,这也是循环神经网络名字的由来,同时根据循环神经网络的结构也可以看出它在处理序列类型的数据上具有天然的优势。因为网络本身就是 一个序列结构,这也是所有循环神经网络最本质的结构。
循环神经网络具有特别好的记忆特性,能够将记忆内容应用到当前情景下,但是网络的记忆能力并没有想象的那么有效。记忆最大的问题在于它有遗忘性,我们总是更加清楚地记得最近发生的事情而遗忘很久之前发生的事情,循环神经网络同样有这样的问题。
pytorch 中使用 nn.RNN 类来搭建基于序列的循环神经网络,它的构造函数有以下几个参数:
- input_size:输入数据X的特征值的数目。
- hidden_size:隐藏层的神经元数量,也就是隐藏层的特征数量。
- num_layers:循环神经网络的层数,默认值是 1。
- bias:默认为 True,如果为 false 则表示神经元不使用 bias 偏移参数。
- batch_first:如果设置为 True,则输入数据的维度中第一个维度就是 batch 值,默认为 False。默认情况下第一个维度是序列的长度, 第二个维度才是 - - batch,第三个维度是特征数目。
- dropout:如果不为空,则表示最后跟一个 dropout 层抛弃部分数据,抛弃数据的比例由该参数指定。
RNN 中最主要的参数是 input_size 和 hidden_size,这两个参数务必要搞清楚。其余的参数通常不用设置,采用默认值就可以了。RNN其实也是一个普通的神经网络,只不过多了一个 hidden_state 来保存历史信息。这个hidden_state的作用就是为了保存以前的状态,我们常说RNN中保存的记忆状态信息,就是这个 hidden_state 。
对于RNN来说,我们只要己住一个公式:
ht=tanh(Wihxt+bih+Whhh(t−1)+bhh)ht=tanh(Wihxt+bih+Whhh(t−1)+bhh)
这个公式来自官网: https://pytorch.org/docs/stable/nn.html?highlight=rnn#torch.nn.RNN
这个公式里面的 xtxt 是我们当前状态的输入值,h(t−1)h(t−1) 就是上面说的要传入的上一个状态的hidden_state,也就是记忆部分。 整个网络要训练的部分就是 WihWih 当前状态输入值的权重,WhhWhh hidden_state也就是上一个状态的权重还有这两个输入偏置值。这四个值加起来使用tanh进行激活,pytorch默认是使用tanh作为激活,也可以通过设置使用relu作为激活函数。
上面讲的步骤就是用红框圈出的一次计算的过程
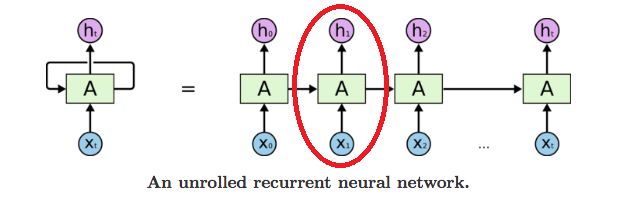
这个步骤与普通的神经网络没有任何的区别,而 RNN 因为多了 序列(sequence) 这个维度,要使用同一个模型跑 n 次前向传播,这个n就是我们序列设置的个数。 下面我们开始手动实现我们的RNN:参考的是karpathy大佬的文章:https://karpathy.github.io/2015/05/21/rnn-effectiveness/
LSTM
LSTM 是 Long Short Term Memory Networks 的缩写,按字面翻译就是长的短时记忆网络。LSTM 的网络结构是 1997 年由 Hochreiter 和 Schmidhuber 提出的,随后这种网络结构变得非常流行。 LSTM虽然只解决了短期依赖的问题,并且它通过刻意的设计来避免长期依赖问题,这样的做法在实际应用中被证明还是十分有效的,有很多人跟进相关的工作解决了很多实际的问题,所以现在LSTM 仍然被广泛地使用
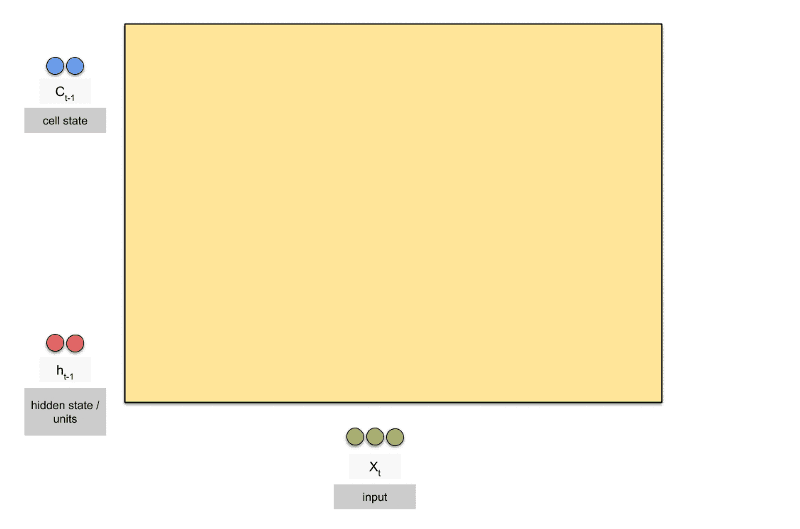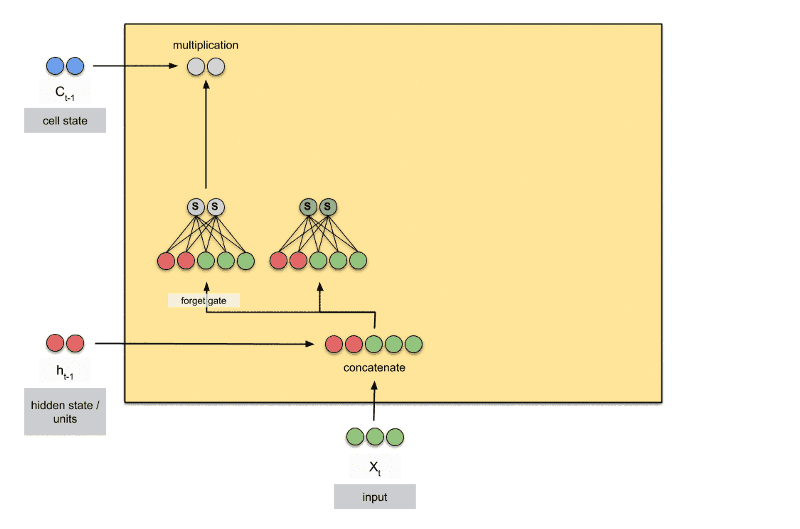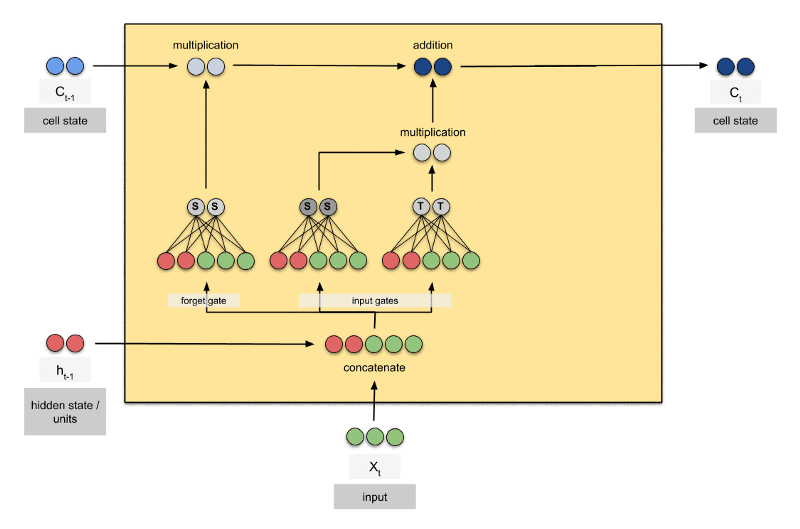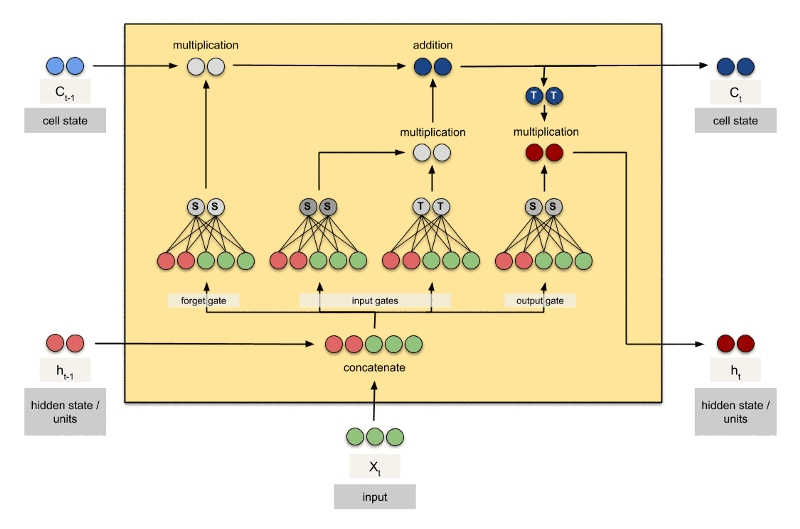
个简单的层结构,而 LSTM 内部有 4 个层结构:
第一层是个忘记层:决定状态中丢弃什么信息
第二层tanh层用来产生更新值的候选项,说明状态在某些维度上需要加强,在某些维度上需要减弱
第三层sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的状态不需要更新
最后一层决定输出什么,输出值跟状态有关。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。
词嵌入(word embedding)
学习之前先了解一下啥是embedding叭
深度学习中 Embedding层两大作用的个人理解_罗小丰同学的博客-CSDN博客_embedding层的作用 https://blog.csdn.net/weixin_42078618/article/details/82999906
https://blog.csdn.net/weixin_42078618/article/details/82999906
在我们人类交流过程中表征词汇是直接使用英文单词来进行表征的,但是对于计算机来说,是无法直接认识单词的。为了让计算机能够能更好地理解我们的语言,建立更好的语言模型,我们需要将词汇进行表征。
在图像分类问题会使用 one-hot 编码。比如LeNet中一共有10个数字0-9,如果这个数字是2的话类,它的编码就是 (0,0,1,0, 0,0 ,0,0,0,0),对于分类问题这样表示十分的清楚,但是在自然语言处理中,因为单词的数目过多比如有 10000 个不同的词,那么使用 one-hot 这样的方式来定义,效率就特别低,每个单词都是 10000 维的向量。其中只有一位是 1 , 其余都是 0,特别占用内存,而且也不能体现单词的词性,因为每一个单词都是 one-hot,虽然有些单词在语义上会更加接近.但是 one-hot 没办法体现这个特点,所以 必须使用另外一种方式定义每一个单词。用不同的特征来对各个词汇进行表征,相对与不同的特征,不同的单词均有不同的值这就是词嵌入。
词嵌入不仅对不同单词实现了特征化的表示,还能通过计算词与词之间的相似度,实际上是在多维空间中,寻找词向量之间各个维度的距离相似度,我们就可以实现类比推理,比如说夏天和热,冬天和冷,都是有关联关系的。
在 PyTorch 中我们用 nn.Embedding 层来做嵌入词袋模型,Embedding层第一个输入表示我们有多少个词,第二个输入表示每一个词使用多少维度的向量表示。
# an Embedding module containing 10 tensors of size 3
embedding = torch.nn.Embedding(10, 3)
# a batch of 2 samples of 4 indices each
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
output = embedding(input)
print(output.size())torch.Size([2, 4, 3])
注意力模型
对于使用编码和解码的RNN模型,我们能够实现较为准确度机器翻译结果。对于短句子来说,其性能是十分良好的,但是如果是很长的句子,翻译的结果就会变差。 我们人类进行人工翻译的时候,都是一部分一部分地进行翻译,引入的注意力机制,和人类的翻译过程非常相似,其也是一部分一部分地进行长句子的翻译。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









