






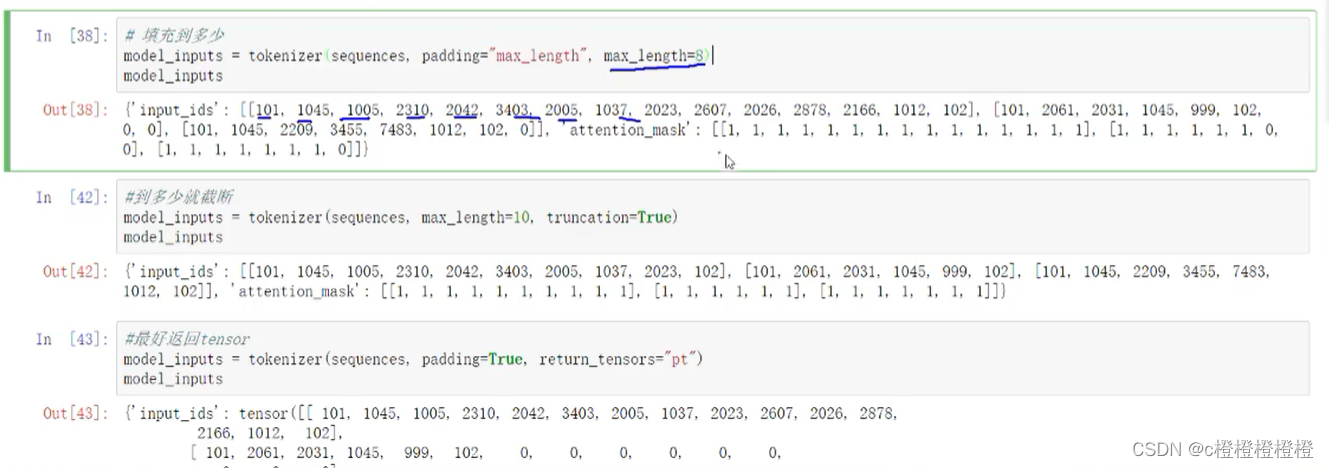
padding 是否需要用0填充(attention_mask中为0的不参与计算)
max_length 处理的最大长度
truncation 截断,超过最长的不处理
return_tensor 可以指定返回pytorch的类型
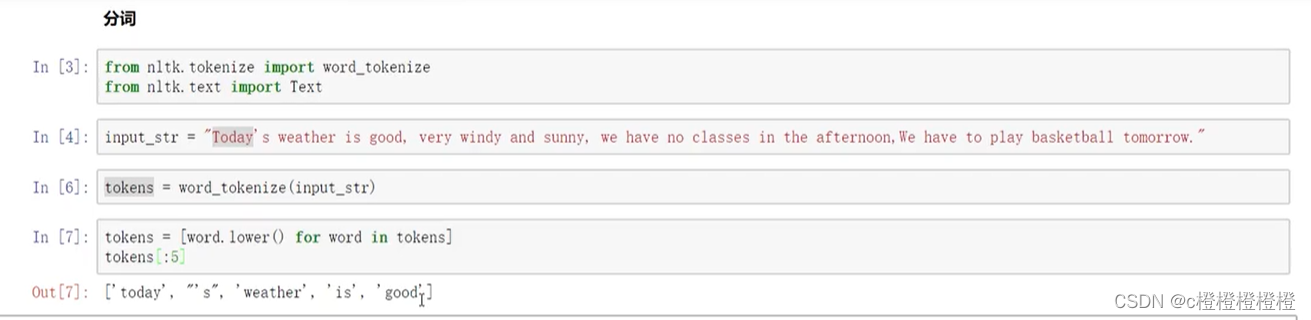
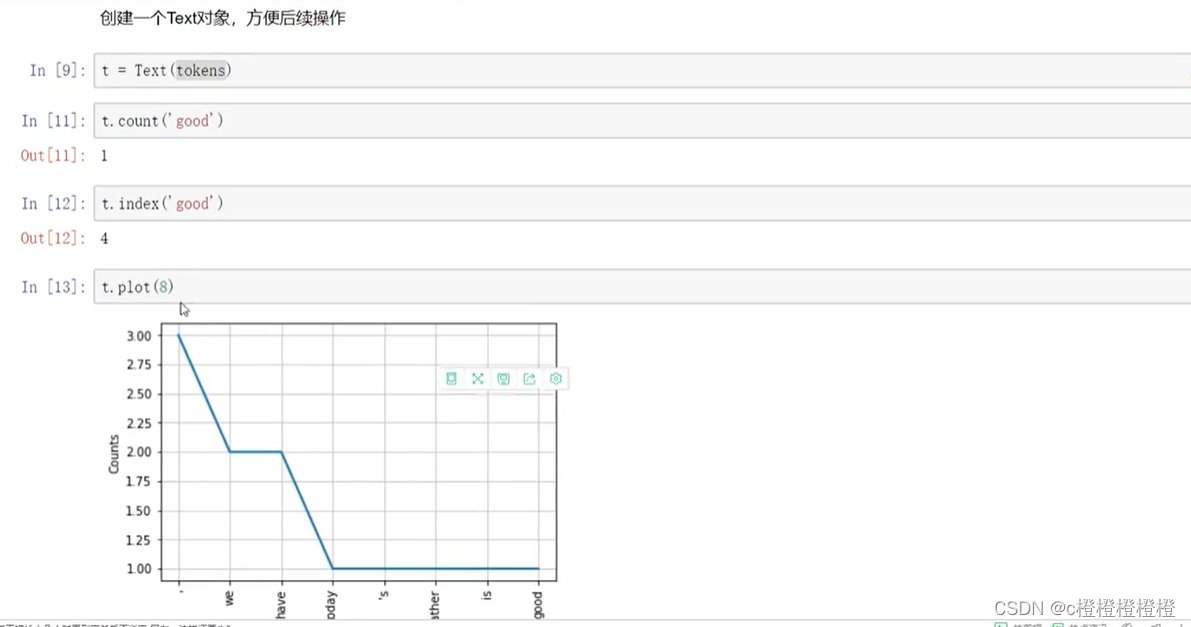
NLTK包(英文分词)
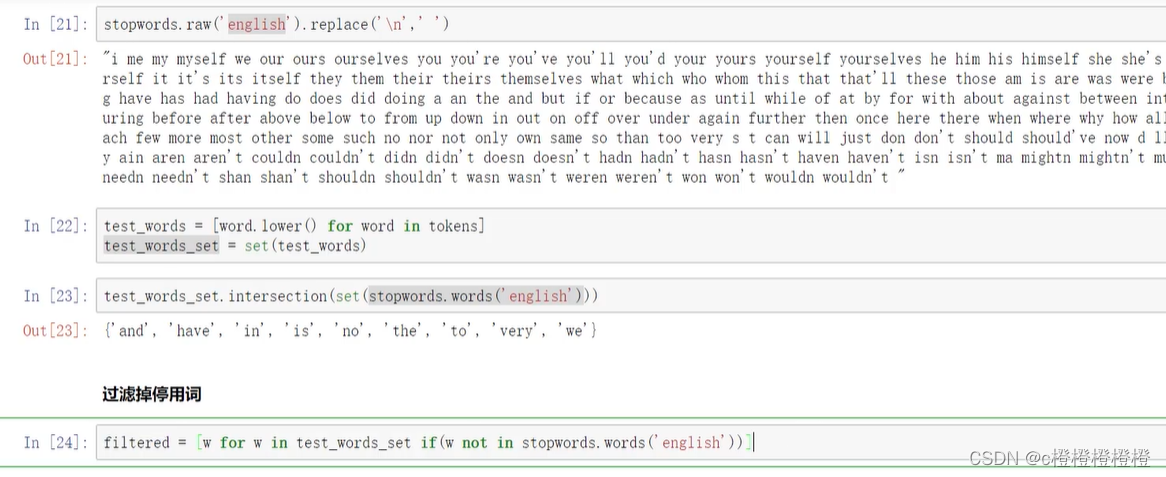
停用词过滤
词性标注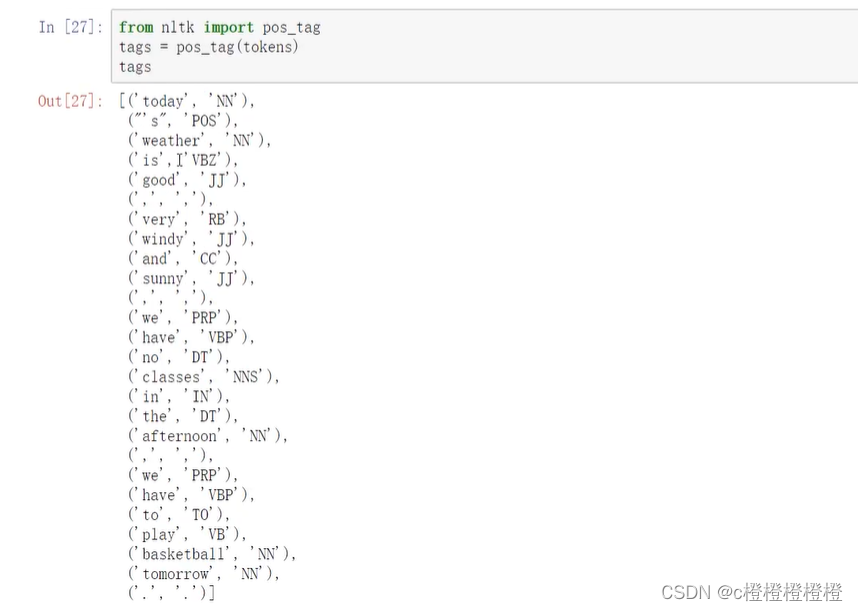
spacy库
# 导入spaCy库
import spacy
# 加载英语语言模型
nlp = spacy.load("en_core_web_sm")
# 创建一个文档
doc = nlp("This is a sentence. l love you. hello bob! jack go to china")
# 打印文档中每个单词的文本和词性标签
print([(w.text, w.pos_) for w in doc])
#[('This', 'PRON'), ('is', 'AUX'), ('a', 'DET'), ('sentence', 'NOUN'), ('.', 'PUNCT'), ('l', 'NOUN'), ('love', 'VERB'), ('you', 'PRON'), ('.', 'PUNCT'), ('hello', 'PROPN'), ('bob', 'PROPN'), ('!', 'PROPN'), ('jack', 'PROPN'), ('go', 'VERB'), ('to', 'ADP'), ('china', 'PROPN')]
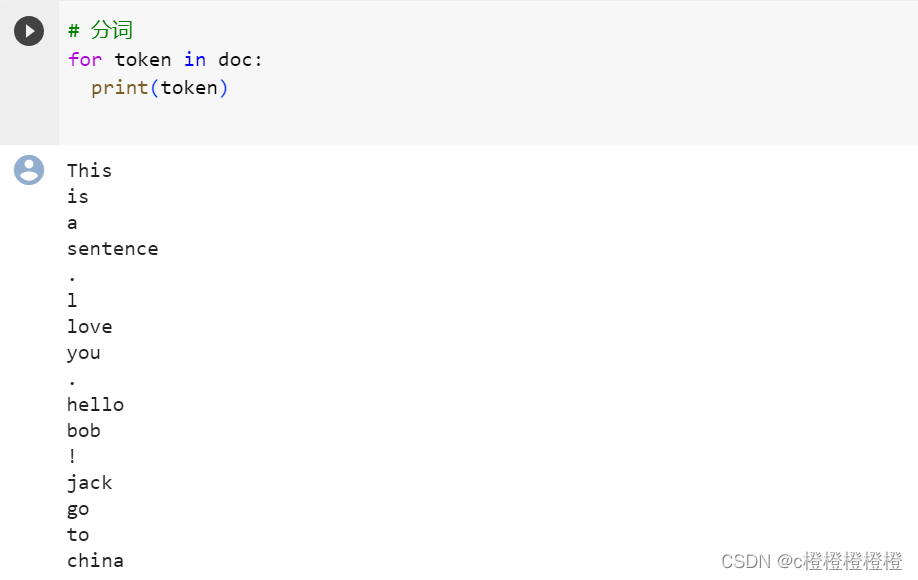

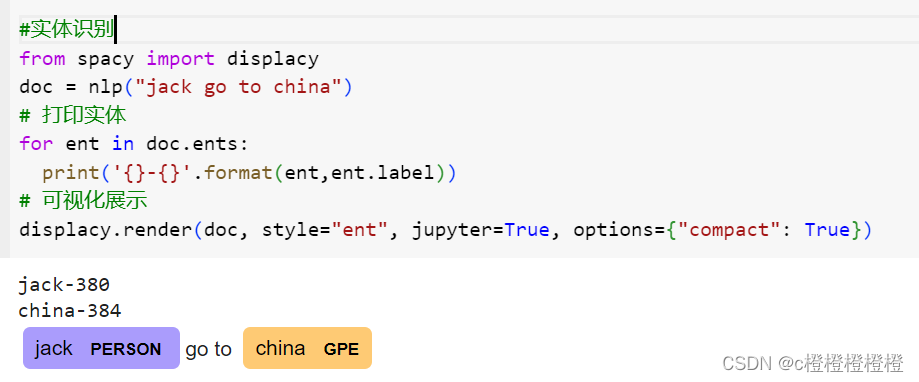















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









