







1.General Guide
【1】检查model在训练集上的loss
【1.1】在训练集上的loss很大
说明在训练集上就没有学习成功,原因①model的bias②optimization做得不够好。
【1.1.1】model太过简单带来的问题。重新设计一个model,来增加弹性,比如增加输入的feature,或者用deep learning。
【1.1.2】在优化时找到的loss不是最小的(或者说不够小),参数并非最优解。如果增加model的层数依然得不到更好的loss,说明是optimization的方法不够好。
【1.2】在训练集上loss很小(好)→检查在测试集上的loss
【1.2.1】在测试集上的loss很大.
【1.2.1.1】overfitting的问题(过拟合)
模型弹性很大但是训练集不够大的时候,模型拟合训练集之后在没有数据的地方会自由发挥,就会造成在非训练集时结果误差极大的情况。
①增加训练集。
②修改模型不要让它有那么大的弹性。
(1)减少参数:减少神经元的数量;让model共用一些参数
(2)减少feature
(3)early stoping
(4)regularization
(5)dropout
【2.1.1.2】mismatch的问题,训练集和测试集的分布不同,训练集没有帮助。
【2.1.2】在测试集上loss很小→model非常好

问题:过于简单的model会有model的bias;过于复杂的model会产生overfitting

交叉验证(cross validation)
把训练资料分成training set和testing set。还有n-fold cross validation,把训练集切分为n等份,分别使之成为validation set。
2.optimization(【1.1.2】中优化方法不够好的问题)
2.1local minima vs. saddle point
随著你的参数不断的update,你的training的loss不会再下降,但是训练效果并不理想。
(此处判断方法比较复杂,暂时略过)
①local minima
②saddle point

2.2batch
shuffle:在每个epoch开始之前重新分一次batch,这样每个epoch的batch都不一样。
为什么要用batch?
计算gradient所需的时间随batch size的增加而增长,但实际上由于GPU的并行运算能力增长,batch size一般情况下不会很影响时间,除非size真的很大。
更小的batch会产生很多的noisy,但是这些noisy gradient可以帮助训练。一个可能的解释:如果是full batch,在更新参数的时候可能是沿着一个loss function来更新的,很可能到一个local minima或者saddle point就停下来了。但假如是small batch,每次更新参数时用的loss function都是有差异的,这样就不容易卡住,所以这种noisy的update方式对训练是有帮助的。
小的 Batch,你会 Update 的方向比较 Noisy,大的 Batch Update 的方向比较稳定,但是 Noisy 的update 的方向,反而在 Optimization 的时候会佔到优势,而且在 Testing 的时候也比较有优势,所以大的Batch 跟小的 Batch,它们各自有它们擅长的地方。
所以Batch Size成为一个非常重要的Hyperparameter。
(希望我能在后续的学习中回头参透这个问题,在这里贴上李老师推荐的论文吧)
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes | EECS at UC Berkeley
[1711.04325] Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes (arxiv.org)
[1706.02677] Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour (arxiv.org)
2.3Momentum
Momentum,这也是另外一个,有可能可以对抗 saddle point,或 local minima 的技术。在物理的世界,一个球从高处滚下来,由于惯性,它可能不会被saddle point或者local minima卡住。
一般的gradient descent是计算gradent然后往gradient的反方向更新参数。加上momentum,每次移动参数的时候不止往gradient的反方向移动,再加上前一步移动的方向去调整参数。
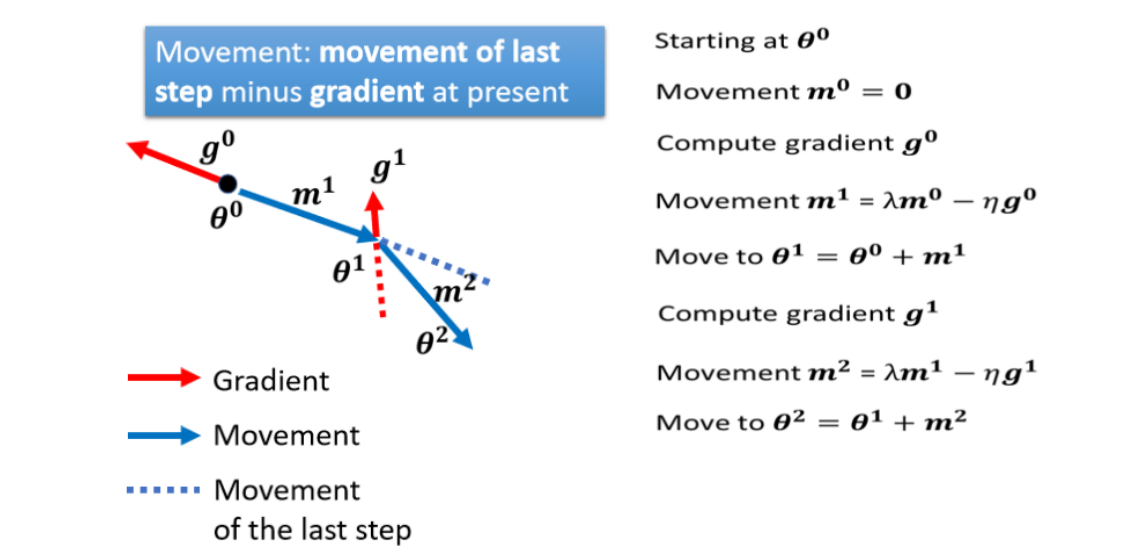
①设定初始参数,假设前一步参数更新的量为0

②在 计算gradient的方向
计算gradient的方向 。更新参数时加上前一步的方向:
。更新参数时加上前一步的方向:

③继续更新参数:

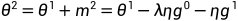
......
momentum存在的意义就是,当每次移动不止取决于gradient的时候,即使遇见了gradient为0的点,仍然会继续移动,这样就可以避免local minima和saddle point带来的局限、
2.4Adaptive Learning Rate

训练时,loss不再下降,但可能gradient的大小并不小,也许是gradient在error surface山谷的谷壁之间来回震荡。可能是learning rate太大了,但实际上有可能会遇见convex的optimization问题,太大的learning rate会让loss在山谷中震荡,但太小的learning rate又会难以前进。
结论:不同的参数需要不同的学习率。
如果在某一个方向上,我们的gradient的值很小,非常的平坦,那我们会希望learning rate调大一点,如果在某一个方向上非常的陡峭,坡度很大,那我们其实期待,learning rate可以设得小一点。
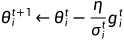
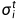 决定于i和t,不同的参数和不同的迭代次数(iteration)都需要不同的。
决定于i和t,不同的参数和不同的迭代次数(iteration)都需要不同的。
①Root Mean Square
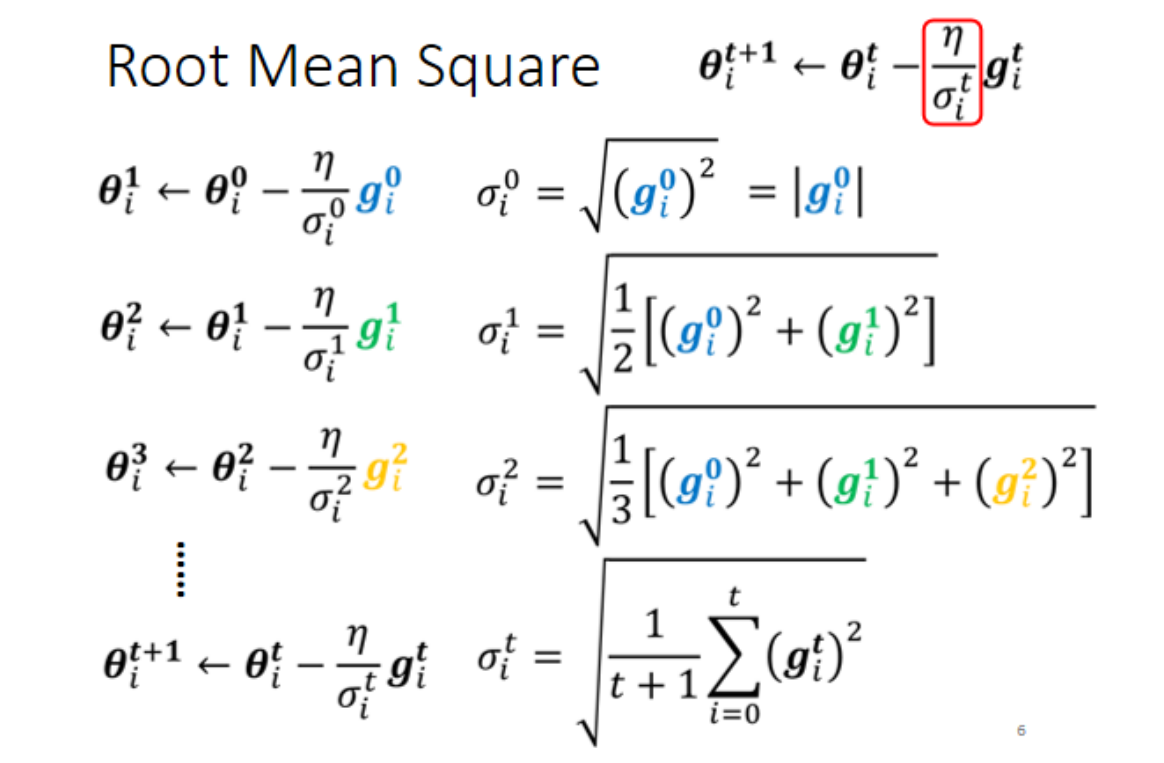
被用于Adagrad,坡度小时g小,则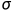 小,相应地learning rate就大。这样就可以随着每个参数gradient的不同来调整learning rate的大小。
小,相应地learning rate就大。这样就可以随着每个参数gradient的不同来调整learning rate的大小。
②RMSProp

RMSProp和root mean square的不同在于,在root mean square中每个gradient都有同等的重要性,但是在RMProp中可以调整每个gradient的权重。这个α需要自己调整,也是一个hyperparameter,当α接近0时,说明当下的g相对之前的比较重要。
常用的optimization策略:adam:RMSProp+Momentum
Adam: A Method for Stochastic Optimization (arxiv.org)
2.5Learning Rate Scheduling
把 设定为一个跟时间有关的数,随着时间进行参数更新,越来越小。这样在不断接近终点的时候慢慢刹车,避免大的爆发。
设定为一个跟时间有关的数,随着时间进行参数更新,越来越小。这样在不断接近终点的时候慢慢刹车,避免大的爆发。
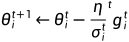
Warm Up
这个方法是让learning rate先变大后变小,这个变大变小的速度和大小也是hyperparameter。这个方法像是一个黑科技,有一个可能的解释是,在一开始不要让参数离初始地太远,需要先进行探索(learning rate比较小),等统计得比较精确以后再让learning rate慢慢爬升。
[1908.03265] On the Variance of the Adaptive Learning Rate and Beyond (arxiv.org)
[1706.03762] Attention Is All You Need (arxiv.org)
小结

3.batch normalization
遇见不好train的error surface时我们通过修改optimization的方法来解决,另一个思路是直接把不好的error surface推平。
eg.一个线性的二维模型,x1的值很小,x2的值很大,那么在train的时候,w1的改变不会引起loss的很大变换,但w2的改变会很大影响loss,每个维度的值scale差距很大的时候就可能产生不同方向斜率差很大的error surface。此时我们需要给不同的dimension同样的数值范围,就可以创造比较好的error surface,让training变得更加容易。这些方法统称为feature normalization。
特征标准化
假设x1到xr是所有训练资料的feature vector,把所有训练资料的feature vector集合起来,把不同资料的同一维度的值取出来取平均记为mi,第i个维度的标准差记为 ,这样就可以进行标准化:
,这样就可以进行标准化:
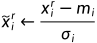
标准化以后,这个维度的数值就会平均是0,方差为1,这排数值分布就会在0左右,这样不同维度的数值都会在0上下,就可以创造一个比较好的error surface。
对于深度学习来说,这个标准化的工作可以放在activation function的前后都可以。在实际中,我们支队一个batch中的data做标准化,也即是batch normalization。(如果你选择的是 Sigmoid,那可能比较推荐对 z 做 Feature Normalization,因為Sigmoid 是一个 s 的形状,那它在 0 附近斜率比较大,所以如果你对 z 做 Feature Normalization,把所有的值都挪到 0 附近,那你到时候算 gradient 的时候,算出来的值会比较大)
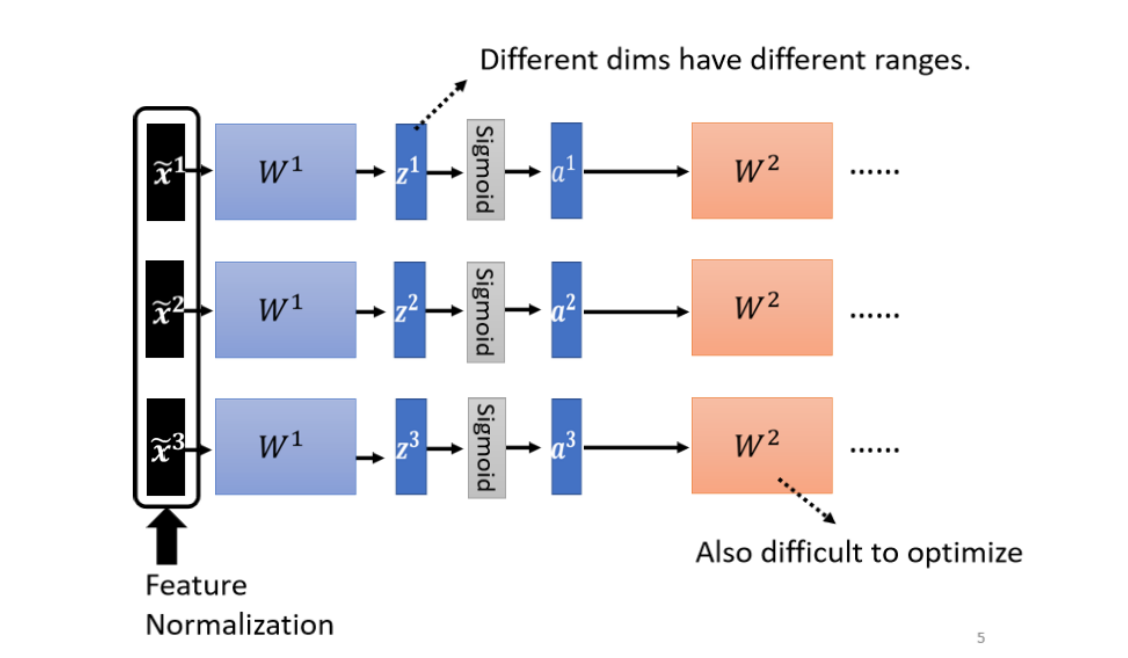
对z做feature normalization:
把z看作feature,算出平均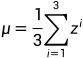 ,算出方差
,算出方差 ,然后就得到
,然后就得到 。
。
这个batch normalization只适用于batch size比较大的时候。当batch size比较大的时候这个batch里面的数据就比较适合整个数据集,这样就可以把feature normalization改成batch normalization。
另一个设计:
在计算出 之后,要将其再乘一个向量
之后,要将其再乘一个向量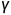 (按元素),再加上
(按元素),再加上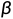 。和是network的参数,另外再learn出来。这是因为做完normalization之后的平均为0,可能会带来一些限制,所以把和加回去。和的设定为初始值(eg.都为1,为0)。这样得到的network一开始训练的时候每个维度的分布都比较接近,训练一段时间找到一个比较好的error surface之后再加上和。
。和是network的参数,另外再learn出来。这是因为做完normalization之后的平均为0,可能会带来一些限制,所以把和加回去。和的设定为初始值(eg.都为1,为0)。这样得到的network一开始训练的时候每个维度的分布都比较接近,训练一段时间找到一个比较好的error surface之后再加上和。
testing/inference
和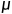 都来自batch,在testing的时候,没有batch。
都来自batch,在testing的时候,没有batch。
在training的时候,每一个batch的和都会拿出来算moving average:
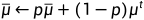
其中p也是一个hyper parameter。在pytorch中,p=0.1。这样在testing的时候不用算batch里面的和了。
Internal Covariate Shift(【2.1.1.2】中的问题)
covariate shift:训练集和预测集样本分布不一致的问题就叫做“covariate shift”现象
batch normalization是有帮助的,但是也有人认为这不是这样的。
[1805.11604] How Does Batch Normalization Help Optimization? (arxiv.org)
其他normalization的方法:
[1803.08494] Group Normalization (arxiv.org)
[1607.08022] Instance Normalization: The Missing Ingredient for Fast Stylization (arxiv.org)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









