



 联邦学习是一种在保护数据隐私的同时进行分布式机器学习的方法。横向联邦学习关注用户特征相同但样本不同的场景,如移动服务的用户输入预测;纵向联邦学习处理用户相同但特征不同的情况,如银行与电商平台的客户信用评级;联邦迁移学习用于特征和样本都不同的情况,如跨境数据迁移。联邦学习可分为集中式和分布式架构,以及同步和异步更新方式。此外,还有全局和个性化联邦学习,前者提供统一服务,后者兼顾本地个性化需求。
联邦学习是一种在保护数据隐私的同时进行分布式机器学习的方法。横向联邦学习关注用户特征相同但样本不同的场景,如移动服务的用户输入预测;纵向联邦学习处理用户相同但特征不同的情况,如银行与电商平台的客户信用评级;联邦迁移学习用于特征和样本都不同的情况,如跨境数据迁移。联邦学习可分为集中式和分布式架构,以及同步和异步更新方式。此外,还有全局和个性化联邦学习,前者提供统一服务,后者兼顾本地个性化需求。
联邦学习分类(吐血整理)
每日一诗: 《中秋李漕冰壶燕集》
宋·戴复古
诸亭环立一湖湾,区界无多眼界宽。
苍石传为伪刘物,绿波曾浴葛仙丹。
两边堤树四时碧,一片冰壶六月寒。
咫尺云烟接沧海,须知此地有龙蟠。

1 按照数据特征划分
根据参与各方数据源分布的情况不同,联邦学习可以被分为三类:横向联邦学习、纵向联邦学习、联邦迁移学习。
在实际应用中,各方数据源分布的情况往往具有不同的分布特点。
据此,联邦学习可以分为三类:横向联邦学习、纵向联邦学习、联邦迁移学习。
| 横向联邦学习 | 纵向联邦学习 | 联邦迁移学习 | |
|---|---|---|---|
| 特点 | 数据集特征 X 和标签信息Y相同,但样本ID不同 | 各数据集特征 X 和标签信息Y不同,但样本ID信息相同 | 数据集特征 X、标 签信息 Y 和样本 ID 信息都不同 |
| 举例说明 | 在用户输入法数据上训练的下一词预测模型。不同的手机用户具 有相同的数据特征,数百万个安卓手机在云服务 器的协调下训练共享的全局模型,其本质是将多 方对不同目标的相同特征描述进行训练提取。 | 同一地区的银行和电商平台: 银行拥有当地用户的收支记录 x1,电商平台拥有 用户的消费记录和浏览记录 x2,双方想通过数据 联合对客户信用 Y 进行评级,从而提供更个性化 的服务,其本质是将多方对相同目标的不同特征 描述进行训练提取。 | 中国的电商平台与其他国家银行之间的数据迁移,由于跨部门跨国的数据交流。 |
| X、Y看作数据集,ID看作产生数据集的对象(用户) | 数据集基本相同(词组习惯),但是产生数据集的对象(不同安卓设备)不同 | 特征数据不同(银行、电商平台业务不同 所建立的数据库中特征数据不同),但是产生数据集合的对象(顾客)基本相同(同一地区 可认为两大平台服务的对象群体基本相同) | 数据特征不同(两平台数据库差异),服务对象不同(不同国家) |
1.1 数据源分布情况
假设有处于同一个领域的两个小公司A和B,A公司和B公司都拥有各自的数据集DA和DB都以矩阵形式表示,两个矩阵的行数据代表用户样本数据,矩阵的列数据代表用户特征,其中还分别拥有标签。A公司和B公司在进行联合训练时,可能存在以下四种情况:
(1)在数据集中,用户特征部分重叠较多,但是用户样本部分重叠较少。
(2)在数据集中,用户特征部分重叠较少,但是用户样本部分重叠较多。
(3)在数据集中,用户特征部分和用户样本部分都重叠较少。
(4)在数据集中,用户特征部分和用户样本部分都重叠较多。
1.2 横向联邦学习
横向联邦学习的主要应用场景为用户特征部分重叠较多,但是用户样本部重叠较少。如果两个或者多个数据集中的用户特征部分重叠较多,那么我们就按照横向切分的方式从数据集中取出特征完全相同但是用户不同的数据进行训练。
简单来说,横向联邦学习根据用户维度进行切分(如图所示),是一种基于用户样本的联邦学习方式。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2XPpXDGq-1660716621613)(%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E5%88%86%E7%B1%BB.assets/20618853-246719d355cbd2b3.png)]](https://i-blog.csdnimg.cn/blog_migrate/81044869d2d1ce878fe47ae416e5af0d.png)
研究者将横向联邦学习总结为
XA =XB, YA =YB, IA ≠IB ,∀ DA ,DB
式中,DA指的是A公司的数据集,DB指的是B公司的数据集;XA指的是A公司的特征, YA 指的是A公司的标签, IA 指的是A公司的用户样本.
横向联邦学习中多方联合训练的方式与分布式机器学习(Distributed Machine Learning)有部分相似的地方。分布式机器学习涵盖了多个方面,包括把机器学习中的训练数据分布式存储、计算任务分布式运行、模型结果分布式发布等,参数服务器是分布式机器学习中一个典型的例子。参数服务器作为加速机器学习模型训练过程的一种工具,它将数据存储在分布式的工作节点上,通过一个中心式的调度节点调配数据分布和分配计算资源,以便更高效的获得最终的训练模型。而对于联邦学习而言,首先在于横向联邦学习中的工作节点代表的是模型训练的数据拥有方,其对本地的数据具有完全的自治权限,可以自主决定何时加入联邦学习进行建模,相对地在参数服务器中,中心节点始终占据着主导地位,因此联邦学习面对的是一个更复杂的学习环境;其次,联邦学习则强调模型训练过程中对数据拥有方的数据隐私保护,是一种应对数据隐私保护的有效措施,能够更好地应对未来愈加严格的数据隐私和数据安全监管环境。
案例
比如,对于不同地区的数据运营商服务(如四川省的移的动服务、云南省的移动服务等)来说,因为其分布在不同的区域,所以用户样本部分重叠较少,但是这些不同区域的业务特征是很相似的,因此特征空间的重叠区域较大。这样的数据集就适合采用横向联邦学习的方式进行训练。
横向联邦学习的典型应用场景是“端-云”服务框架。该场景主要针对拥有同构数据的大量终端用户,比如在互联网中使用同一个 App 的用户,服务商通过融合不同终端用户的数据进行联合建模。在经过用户授权后,用户的个人隐私均不出个人终端设备(手机、平板电脑等)就可以参与模型的训练与更新。横向联邦学习通过去中心化、分布式的建模方式在保证用户个人隐私的前提下,利用了不同用户的数据,建立了有价值的联邦学习模型。
1.3 纵向联邦学习
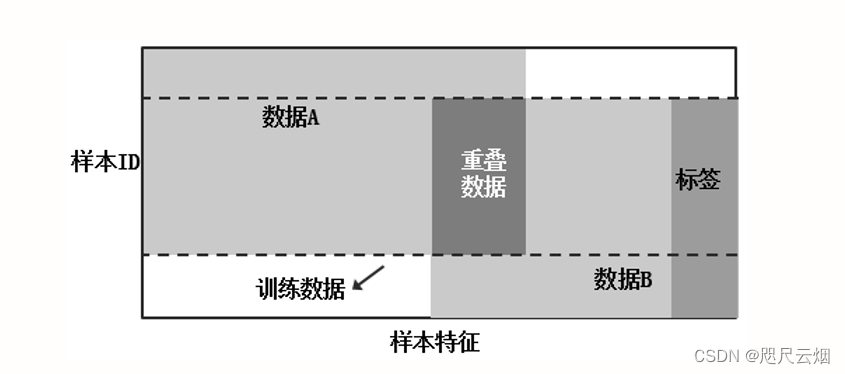
在两个数据集的用户重叠较多而用户特征重叠较少的情况下,我们把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。这种方法叫做纵向联邦学习。
简单来说,纵向联邦学习根据特征维度进行切分,如图所示是一种基于特征维度的联邦学习方式。
目前,很多模型都已经在纵向联邦学习中得到了较好的应用,如人工神经网络模型、逻辑回归模型、随机森林模型等。
纵向联邦学习将多个参与方的数据集中的特征汇总在一起,并且通过同态加密等方式保护数据隐私安全,其中用户模型是一致的。在纵向联邦学习中,各方都使用一致的方法模型(数据不同),因此可以通过联合模型管理所有的模型。
研究者将纵向联邦学习总结为
XA ≠XB, YA ≠YB, IA =IB ,∀ DA ,DB
案例
通过一个公司A与信贷公司的合作案例来理解纵向联邦学习的建模过程。公司A作为数据提供方,拥有大量用户的行为特征和部分信贷数据(标签);信贷公司拥有大量的用户信贷数据。现在对公司A数据和信贷公司数据中同一批用户进行联邦建模,就属于纵向联邦学习。
统一利用双方的数据信息建立模型,通过纵向联邦学习建模之后取得了很好的实验结果,对不同用户的风险识别KS(Kolmogorov-Smirnov)指标均大幅度上升,使得风控模型对信用良好用户和失信用户有更好的区分。
纵向联邦学习用于具有类似客户群体和不同特征数据的公司间的合作。
又比如有两个不同机构,一家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民,因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力的联邦学习。目前机器学习模型如逻辑回归、决策树等均是建立在纵向联邦学习系统框架之下的。
1.4 联邦迁移学习
联邦迁移学习是联邦学习和迁移学习的结合体。
在学习联邦迁移学习之前,我们先来认识迁移学习。随着机器学习的广泛应用,在很多有监督学习场景中常常需要进行大量数据标注,这是一项十分耗时且乏味的工作,因此迁移学习就被引入了。
迁移学习的出发点是减少人工标注数据的时间,使得模型可以通过已有的标注数据将已学知识迁移到未标注的数据中。
目前,迁移学习主要应用在将训练好的模型参数迁移到新的模型中辅助新的模型进行训练。
基于源域(Source Domain)和目标域(TargetDomain)将迁移学习分为归纳迁移学习、直推式迁移学习和无监督迁移学习三种方向。
在最近的研究中,对迁移学习的研究主要集中在基于特征表示的迁移学习方法,其已经在图像分类、文本分类、自然语言处理(NLP)等领域取得了很好的效果。
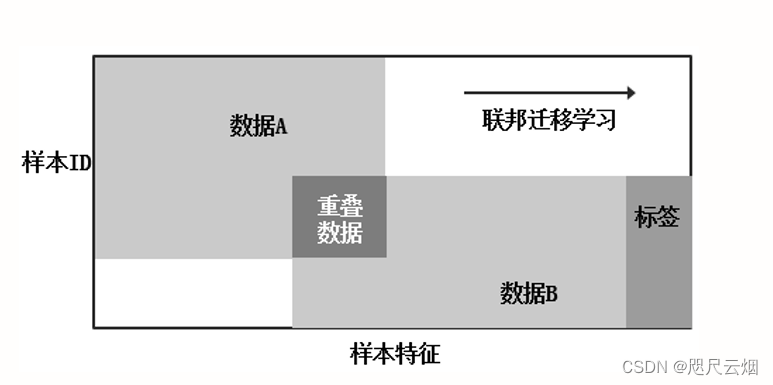
在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而可以利用迁移学习来克服数据或标签不足的情况。这种方法叫做联邦迁移学习。联邦迁移学习主要对应上面数据集中的第三种情况,即如果两个或者多个数据集中的用户样本和用户特征都不太相同,那么我们就按照迁移学习的方式从数据集中来弥补数据不足或者标签不足进行训练。简单来说,联邦迁移学习不对数据切分(如图所示),是一种基于知识迁移的联邦学习方式。
研究者将联邦迁移学习总结为:
XA ≠ XB, YA≠ YB, IA ≠ IB ,∀ DA ,DB
案例
假设现在有中国某银行的数据集和美国某外卖公司的数据集,因为在不同的国家,所以用户的交叉很少。
因为银行业务和外卖公司业务相差很大,所以用户特征的交叉也很少。如果用户需要进行有效的联邦建模,就需要借助迁移学习技术,解决单边数据缺乏或者标签少的问题,从而更有效地进行联邦模型训练。
比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受到地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习,来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
2 按照网络拓扑结构划分
2.1 集中式联邦学习(CFL)
一个CFL系统包含一个中央服务器和一组执行FL模型的客户端。在单轮训练中,所有客户端使用自己的数据集并行地参与网络模型的训练。然后,所有客户端将训练后的参数传输到中央服务器,中央服务器使用各种聚合算法,例如加权平均算法(如Federated平均化(FedAvg)将它们聚合起来。然后,将计算出的全局模型发送回所有客户端,以便进行下一轮训练。
各种集中式联邦学习框架可见主页
2.2 分散式联邦学习(DFL)
DFL所有客户端以点对点(P2P)的方式连接在一起进行AI训练。在每一轮通信中,客户端也会基于自己的数据集进行本地训练。然后,每个客户端通过P2P通信从邻居客户端接收到的模型更新来实现模型聚合,实现对全局更新的共识。
集中式联邦学习是在FL-IoT系统中最流行的FL架构之一,当与服务器的通信不可用或网络拓扑高度可伸缩时,分散式联邦学习(DFL)被设计为完全或部分替代集中式联邦学习(CFL)。
由于现代特性,DFL可以与基于P2P的通信技术如区块链集成,构建分散的FL系统。这样,DFL客户端可以通过区块链账本进行通信,其中模型更新可以卸载到区块链,以进行安全模型交换和聚合。
3 按照应用目的划分
3.1 全局联邦学习
该模型为每个客户端提供相同的服务,常见的应用场景为多个银行联合各自私有的用户数据联合学习用户风控模型。
经典的联邦学习模型大多是全局联邦学习。
FedSGD
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CxIVtwQY-1660716621616)(%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E5%88%86%E7%B1%BB.assets/image-20220817135510946.png)]](https://i-blog.csdnimg.cn/blog_migrate/d74ea1eae995d19e41d7ee0cbbf9787c.png)
FedAvg
Communication-Efficient Learning of Deep Networks from Decentralized Data
本文提出了一种实用的基于平均迭代的联邦学习深度神经网络方法——Federated Averaging算法,将每个客户机上的局部随机梯度下降(SGD) 与 执行模型参数平均的服务器结合起来。
证明了它对不平衡和非iid数据分布是稳健的,相较于同步随机梯度下降方法(FedSGD)的通信次数减少10-100倍大大提高了联邦学习得模型效率。
实验部分考虑五种不同的模型架构和四种数据集
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PImbeBPb-1660716621616)(%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E5%88%86%E7%B1%BB.assets/image-20220817135739396.png)]](https://i-blog.csdnimg.cn/blog_migrate/338c4fbbd03b82fa2e8cc9e804d462da.png)
FedCS
Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge
本文所要解决的问题是异构客户资源(数据资源:异质size more data more time、计算能力:需要更长时间更新模型、无线信道条件:传输 更新时间变长)——延长服务器的聚合更新步骤,进而降低网络模型更新的效率。
为解决上述问题,作者提出了FedCS框架, 相较于传统的模型,其创新点在于增加了 Resource Request步骤,该步骤可以帮助移动边缘计算(MEC)服务器依据工人上传信息评估其“优劣”。 显然 针对上述三种异构情况, 若某工人的本地数据集太大/小,计算能力弱、信道状况差会通过工人选择算法(基于贪婪)直接被pass掉,进而保证全局模型训练效率
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-atd3fBzO-1660716621617)(%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E5%88%86%E7%B1%BB.assets/image-20220808162401487.png)]](https://i-blog.csdnimg.cn/blog_migrate/d938fdd7993e4dac134ec45226ab3910.png)
3.2个性化联邦学习
联邦学习自提出以来获得了广泛的关注,并在一些场景中得以应用。
联邦学习解决了数据汇聚的问题,使得一些跨机构、跨部门的机器学习模型、算法的设计和训练成为了可能。
对于一些没有足够的私人数据来开发精确的本地模型的用户(客户机)来说,通过联邦学习能够大大改进机器学习模型和算法的性能。
但是,由于联邦学习侧重于通过分布式学习所有参与客户机(设备)的本地数据来获得高质量的全局模型,因此它无法捕获每个设备的个人信息,从而导致推理或分类的性能下降。
此外,传统的联邦学习需要所有参与设备就协作训练的共同模型达成一致,这在实际复杂的物联网应用中是不现实的。
研究人员将联邦学习在实际应用中面临的问题总结如下:(1)统计异构型:由于客户端上的训练数据是由客户端自己根据其本地环境和使用模式收集的,因此本地数据集的大小和分布在不同的客户端之间通常会有很大的差异,如数据不平衡,非独立同分布等数据异构。;(2) 系统异构性:通信传输瓶颈、存储能力、计算能力、联网能力、电池等资源限制导致的stragglers问和容错问题。。
为了解决这些异构性挑战,一种有效的方法是在设备、数据和模型级别上进行个性化处理,以减轻异构性并为每个设备获得高质量的个性化模型,即个性化联邦学习(Personalized Federated Learning)。
个性化联邦学习逐渐趋向于全局知识和局部知识的融合,不 管是基于公共数据集的知识蒸馏,还是融合了全局知识的全局参数模型 与局部参数模型的协调,其核心思想总归是如何有效的融合全局知识, 在此基础上构建适用于自身的个性化模型。
以下是几个实现个性化联邦学习的框架:
Per-FedAvg:
Personalized Federated Learning: A Meta-Learning Approach
在本文中,我们研究了联邦学习的一个个性化变体,我们的目标是找到一个初始共享模型,当前或新用户可以通过对自己的数据执行一个或几个步骤的梯度下降,轻松地适应自己的本地数据集。这种方法保留了联邦学习体系结构的所有优点,并通过结构为每个用户提供更个性化的模型。我们表明这个问题可以在模型不可知论元学习(mml)框架内进行研究。在这种联系的启发下,我们研究了著名的联邦学习的个性化变体。
这篇文章利用元学习来实现联邦个性化学习,将用户看作元学习中的多个任务。和元学习一样,其目标是找到一个初始化模型,当前用户或新用户只需对他们的本地数据执行一步或几步梯度下降,便可将模型适应他们的本地数据集。这样当有一个新用户进来时,就可以通过一步或几步梯度下降快速获得一个高效的个性化模型。
文章主要内容有三点:
1、将元学习和FL进行结合,具体以FedAvg为框架,以MAML为内容,提出Per-FedAvg算法。
2、从理论角度分析Per-FedAvg在非凸函数下的收敛性。
3、描述“用户数据底层分布的相似度”对Per-FedAvg性能的影响

FedProx
FEDERATED OPTIMIZATION IN HETEROGENEOUS NETWORKS
联邦学习不同于传统的分布式优化的两个关键挑战:高度的系统和统计异构性。引入了一个框架,FedProx以解决联邦网络的异构性(统计异构 系统异构)。FedProx可以看作是FedAvg的泛化、重构,
对于非独立分布(统计异质性)的训练数据,框架提供收敛性保证(统计异构);允许每个参与的设备执行可变数量的工作(系统异构性)来遵守设备级系统约束。FedProx在一组真实的联邦数据集上比FedAvg更健壮的收敛。特别是,在高度异构的环境下,FedProx表现出比FedAvg更稳定和准确的收敛行为——平均提高22%的绝对测试精度。
FedAvg在FedSGD的基础上为每个节点设定统一的E (epochs),用以增大本地计算量 提升本地模型更新的精度,进而加快全局拟合速度,减少通信次数;同时可以解决非凸损失函数的问题。
从系统异构角度:FedAvg不允许参与设备根据其系统约束执行可变数量的本地工作;相反,通常是简单地丢弃在指定时间段内无法计算E个epoch的设备
从统计角度:FedAvg在数据非独立同分布的情况下适应性弱,因此FedAvg很难在现实场景中(多为非独立同分布)进行理论分析来保证其收敛性。
MOCHA
链接: Federated multi-task learning
主要是为了解决联邦学习中的系统难题和统计难题而提出的联邦学习框架。
MTL(多任务学习)通过学习每个节点的独立模型,利用任意的凸损失函数为每个节点训练出独立的权重向量。并且考虑节点模型间的相关性来解决联邦环境中的统计难题,并且提升样本容量,但是目前的MTL难以解决系统难题。
在集中环境分布式多任务训练模型CoCoA的基础上进行改进,本文提出联邦多任务学习框架MOCHA,为模型参数W开发有效的分布式优化更新方法。
本文将多任务学习与联邦学习进行结合,利用多任务学习解决联邦学习中的统计难题;针对联邦学习的系统难题,在COCOA的基础上进行拓展得到联邦多任务学习框架MOCHA,通过引入θht并在每轮次更新开始时由节点根据多种因素确定其值进而解决了系统难题(eg.掉队)。
FedMD
FedMD: Heterogenous Federated Learning via Model Distillation
高性能的深度学习网络通常是计算型和参数密集型的,难以应用于资源受限的边缘设备. 为了能够在低资源设备上运行深度学习模型,需要研发高效的小规模网络.
知识蒸馏是获取高效小规模网络的一种新兴方法, 其主要思想是将学习能力强的复杂教师模型中的“知识”迁移到简单的学生模型中. 同时,它通过神经网络的互学习、自学习等优化策略和无标签、跨模态等数据资源对模型的性能增强也具有显著的效果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LYF3upOu-1660716621618)(%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E5%88%86%E7%B1%BB.assets/image-20220817134952177.png)]](https://i-blog.csdnimg.cn/blog_migrate/156eb5108554b5e08e5e18ff4787ee3a.png)
FedProx虽然能实现每个节点的异构更新,自适应的根据节点自 身条件调节训练时间,但其最终训练的是一个统一模型,精度提升有限
FedMD的难点在于如何构建质量高、有代表性的公共数据集。
MOCHA框架中,每个节点都需要参与训练,难以实现异步。 HFL-LA 的全局参数神经网络层和局部参数神经网络层的分割不够明确。
4 按照聚合更新方式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6slrto1m-1660716621618)(%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E5%88%86%E7%B1%BB.assets/v2-66e5e4431b7ba62f4b546785b6126ed3_r(1)].png)](https://i-blog.csdnimg.cn/blog_migrate/92cdd4eca254f3cde94b1ee9f79e743e.png)
4.1 同步联邦学习
如图(a)所示,在同步联邦学习(SFL)中,每一轮训练需要等到所有参与设备的模型上传完成后,再进行模型汇聚。由于设备资源的差异和设备上训练数据的差异,速度较快的设备在每轮训练中必须等待速度较慢的设备,这极大降低了联邦学习训练效率。
现阶段各种成熟的联邦学习框架大多是基于同步联邦学习展开研究的。
4.2 异步联邦学习
如图(b)所示,在异步联邦学习(AFL)中,其模型汇聚服务器在收集到少量本地模型后立即进行全局聚合,避免受到速度较慢设备的拖累。
即同步FL (SFL),要求所有参与者步调一致; 异步FL (AFL),它使其参与者独立工作。
AFL在实际应用中更具有普适性,它能适应于设备不断变化(单个设备自身的硬件性能、添加去除设备、多异构设备协同)的现实场景,并极大地提升联邦学习的训练效率。
A triple-step asynchronous federated learning mechanism for client activation, interaction optimization, and aggregation enhancement
TrisaFed
A triple-step asynchronous federated learning mechanism for client activation, interaction optimization, and aggregation enhancement
本文针对异步神经网络固有的过度拟合、通讯受限、加权聚合等问题,提出了TrisaFed,针对三大挑战分别提出应对策略:ICA根据信息型客户端激活策略激活具有丰富信息的客户端、MLU多层更新策略来优化客户端和服务器的交互、时权退减策略(TWF)和丰富权重增强策略(IWE) 增强聚合函数。
具体详情见另见跳转链接。
Reference:
You, Linlin, et al. “A triple-step asynchronous federated learning mechanism for client activation, interaction optimization, and aggregation enhancement.” IEEE Internet of Things Journal (2022).
Sattler, Felix, et al. “Communication-efficient federated distillation.” arXiv preprint arXiv:2012.00632 (2020).
Li, Tian, et al. “Federated optimization in heterogeneous networks.” Proceedings of Machine Learning and Systems 2 (2020): 429-450
Smith, Virginia, et al. “Federated multi-task learning.” Advances in neural information processing systems 30 (2017).
周传鑫, 孙奕, 汪德刚,等. 联邦学习研究综述[J]. 网络与信息安全学报.
Zhao, Yue, et al. “Federated learning with non-iid data.” arXiv preprint arXiv:1806.00582 (2018).
Sattler, Felix, et al. “Robust and communication-efficient federated learning from non-iid data.” IEEE transactions on neural networks and learning systems 31.9 (2019): 3400-3413


















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









