









加权迁移学习用于改进基于运动想象的脑-机接口
Weighted Transfer Learning for Improving Motor Imagery-Based Brain–Computer Interface
来源
作者:Ahmed M. Azab , Studentmember,IEEE, Lyudmila Mihaylova , SeniorMember,IEEE, Kai Keng Ang , SeniorMember,IEEE, and Mahnaz Arvaneh , Member,IEEE
期刊:IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING, VOL. 27, NO. 7, JULY 2019
摘要
问题: 会话/被试间脑信号特性存在差异,校准时间较长,需要大量训练数据
方法: 分类域迁移学习(当只有少数特定受试者的试验可用于训练时,通过结合其他用户先前记录的数据来改善分类参数的估计。在分类器的目标函数中加入正则化参数,使得分类参数尽可能地接近与目标主体特征空间相似的先前用户的分类参数。)
目的: 在不牺牲分类精度的情况下,减少校准时间
结果: 与特定受试者分类器相比,所提出的加权迁移学习分类器提高了分类结果,特别是当用于训练的特定受试者试验较少时。
方法
基于逻辑回归的迁移学习算法LTL
对每个先前记录的session,用目标函数计算分类参数
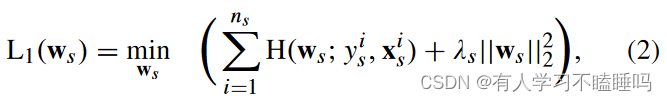
H和| | . | | 2分别表示交叉熵和2 -范数函数。事实上,在L1 ( ws )中,交叉熵旨在寻找使错误率最小的ws,而2 -范数惩罚ws的大值以降低过拟合的风险。采用特定于被试的正则化参数λ s来控制惩罚程度。
目标函数L1 ( ws )可能无法估计新受试者的分类参数,因为很少有可用的特定受试者试验通常不能准确地表示特征的分布。将公式(2)优化为公式(4)
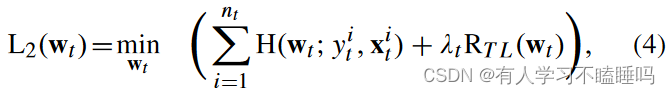
RTL是惩罚wt和先前计算的ws之间差异的正则化项。正则化参数λt根据分类参数在最小化误差和新目标主题与先前会话之间的差异之间进行权衡。
基于加权逻辑回归的迁移学习算法
所提出的LTL算法试图通过结合先前记录的会话数据来改进对新主题的分类参数的估计。然而,它对待不同的特征空间与以前的会话类似,而EEG信号的分布可以在不同的会话和不同的受试者之间不同,从而导致不同的受试者特定的CSP特征空间。因此,根据EEG信号的分布,新受试者的EEG特征可能与先前记录的一些会话的EEG特征相似,而与其他一些会话的EEG特征非常不同。因此,考虑到这些差异可能会进一步改进对一个新主题的分类参数的估计。为了解决这个问题,在提出的基于加权逻辑回归的迁移学习算法中,为先前记录的会话分配不同的权重,以根据特征的分布来表示这些会话和新主题之间的相似性。
使用两个正态分布之间的KL散度来衡量EEG特征之间的散度。
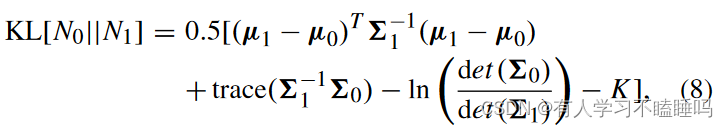
目标主题dt的特征集与前一个会话/被试ds的特征集之间的相似度权重αs
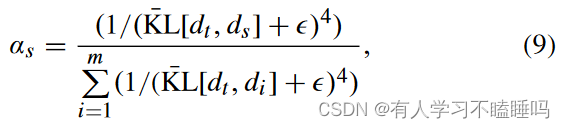
KL是利用目标被试dt的少量可用训练试次的特征分布计算的总散度
KL,可以通过两种方式进行计算,即有监督和无监督。在有监督的情况下,总散度是通过对每个类单独计算的KL散度进行平均来计算的。另一方面,在无监督的情况下,总的散度等于不考虑类别标签时两会话间的KL散度。
较大的权重对应较相似的分布,较小的权重对应较不相似的分布

结果
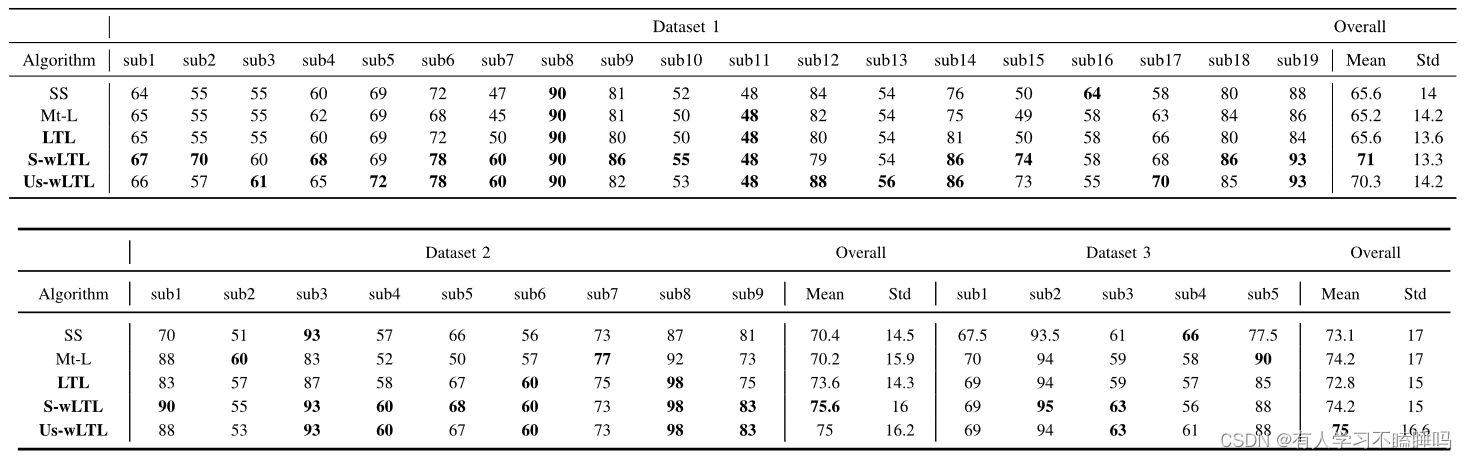
表1给出了当新受试者每类仅有10个试次进行训练时,本文提出的迁移学习算法( LTL、S - wLTL、Us - wLTL)和基准算法( SS , Mt-L)的分类结果。















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









