







文章目录
前言
昨天还在小红书上看到这样一篇帖子,他谈到突然感觉研究深度学习毫无意义。今天上课的时候,人工智能课的老师也在说,现在的学生都在搞深度学习,你搭一个10层的网络,我搭一个20层的网络,我比你精度高,我就可以发paper了。听着虽然蛮荒诞蛮搞笑蛮夸张的,但也算是事实。我之前就有这样的感觉了,感觉大学基本上所有的老师都在做深度学习。风往一边刮,人往一边倒,计算机、电子信息类专业、甚至是一些医学专业甚至机械专业更或者是土木一些完全和计算机不搭边的专业,都会去搞深度学习,(因为好发paper)但这个东西真的感觉非常玄学。说白了还是个黑匣子。如今一大堆高水平的学生、学者、企业在“卷”这个东西,看上去有点好无厘头,可解释性还是太差了。(尽管gpt算是某种意义上的成功)
我们国家落后的技术还是蛮多的,游戏引擎、计算机系统、芯片这些硬核。我真的非常不希望看到将来某一天中国又会因为这些技术而被卡脖子。我朋友今天问我,如何看待中国现代化之路,我的答案是任重而道远。加油吧,我们这一辈人。
我觉得或许现在人们对于深度学习的研究看上去是无厘头的,就像是牛顿当时研究物理学一样,任何事物的开头都会有无数的前人去做实验。希望这一切的研究在未来的人们看来不会觉得是搞笑的,而是奠定了人工智能的基石。
~2023-5-17 21:47 笔者留
这几天在忙着项目的复习,在backbone中用到了MobileNetV2,寻思着就把MobileNet系列都复习一遍吧,先从V1开始。
论文题目:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文地址:https://arxiv.org/abs/1704.04861
Github:MobileNet
1. 简介
深度学习领域内在努力促使神经网络向小型化发展。在保证模型准确率的同时体积更小,速度更快。Mobilenet就是主打一个轻量化,让模型能够在移动端、嵌入式设备上跑起来。
2. MobileNetV1
2. Depthwise Separable Convolution:深度可分离卷积
在讲这个之前,得先讲一下DW卷积和PW卷积。实际上深度可分离卷积就是二者组合而成的。
2.1 depthwise convolution:深度卷积
标准卷积的计算成本为 D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F} DK⋅DK⋅M⋅N⋅DF⋅DF,注意,这里的计算成本指的是要计算的次数。
其中,M为输入通道,N为输出通道,卷积核大小为 D K D_{K} DK,feature map大小为 D F D_{F} DF。
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时 操作输入图片的每个通道。
DW卷积:
- 卷积核channel=1
- 输入特征矩阵channel=卷积核个数=输出特征矩阵channel
深度卷积的计算量为:
D
K
⋅
D
K
⋅
M
⋅
D
F
⋅
D
F
D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F}
DK⋅DK⋅M⋅DF⋅DF
而参数量为:
D
K
⋅
D
K
⋅
M
D_{K} \cdot D_{K} \cdot M
DK⋅DK⋅M

2.2 pointwise convolution:逐点卷积
逐点卷积在我看来更像是1x1卷积,只是换了一种说法。

参数量:
1
⋅
1
⋅
M
⋅
N
1\cdot 1 \cdot M \cdot N
1⋅1⋅M⋅N
计算量: 1 ⋅ 1 ⋅ M ⋅ N ⋅ D F ⋅ D F 1\cdot 1 \cdot M \cdot N \cdot D_{F} \cdot D_{F} 1⋅1⋅M⋅N⋅DF⋅DF
因此,计算一次深度可分离卷积相较于普通卷积的计算量为

3. 网络结构
一般在Mobilenet中,深度可分离卷积会代替传统卷积,作为最基本的模块。

下图为MobileNetV1的基本结构:
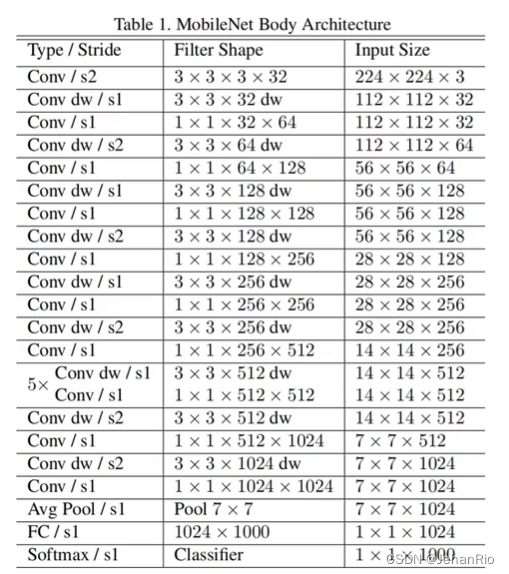
4. 宽度因子
MobileNet本身的网络结构已经比较小并且执行延迟较低,但为了适配更定制化的场景,MobileNet提供了称为宽度因子(Width Multiplier)的超参数给我们调整。宽度因子在MobileNetV1、V2、V3都可以运用。
通过宽度因子,可以调整神经网络中间产生的特征的大小,调整的是特征数据通道数大小,从而调整了运算量的大小。
宽度因子简单来说就是新网络中每一个模块要使用的卷积核数量相较于标准的MobileNet比例。对于深度卷积结合1x1方式的卷积核,计算量为:

其中,M为输入通道,N为输出通道,卷积核大小为
D
K
D_{K}
DK,feature map大小为
D
F
D_{F}
DF。
算式中α即为宽度因子,α常用的配置为1,0.75,0.5,0.25;当α等于1时就是标准的MobileNet。通过参数α可以非常有效的将计算量和参数数量约减到α的平方倍。
5. 分辨率因子
MobileNet还提供了另一个超参数分辨率因子(Resolution Multiplier)供我们自定义网络结构,分辨率因子同样在MobileNetV1、V2、V3都可以运用。
分辨率因子一般用β来指代,β的取值范围在(0,1]之间,是作用于每一个模块输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了,结合宽度因子α,深度卷积结合1x1方式的卷积核计算量为:

其实就是将图片分辨率降低。在计算自愿紧张的情况下,可以通过该分辨率因子对模型精度和计算量做取舍。
6. 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
# 定义DSC结构:DW+PW操作
def BottleneckV1(in_channels, out_channels, stride):
# 深度可分卷积操作模块: DSC卷积 = DW卷积 + PW卷积
return nn.Sequential(
# dw卷积,也是RexNeXt中的组卷积,当分组个数等于输入通道数时,输出矩阵的通道输也变成了输入通道数时,组卷积就是dw卷积
nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=3, stride=stride, padding=1,
groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.ReLU6(inplace=True),
# pw卷积,与普通的卷积一样,只是使用了1x1的卷积核
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# 定义MobileNetV1结构
class MobileNetV1(nn.Module):
def __init__(self, num_classes=5):
super(MobileNetV1, self).__init__()
# torch.Size([1, 3, 224, 224])
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True),
)
# torch.Size([1, 32, 112, 112])
# 叠加的基本结构是: DW+PW(DW用来减小尺寸stride=2实现,PW用来增加通道out_channels增加实现)
self.bottleneck = nn.Sequential(
BottleneckV1(32, 64, stride=1), # torch.Size([1, 64, 112, 112]), stride=1
BottleneckV1(64, 128, stride=2), # torch.Size([1, 128, 56, 56]), stride=2
BottleneckV1(128, 128, stride=1), # torch.Size([1, 128, 56, 56]), stride=1
BottleneckV1(128, 256, stride=2), # torch.Size([1, 256, 28, 28]), stride=2
BottleneckV1(256, 256, stride=1), # torch.Size([1, 256, 28, 28]), stride=1
BottleneckV1(256, 512, stride=2), # torch.Size([1, 512, 14, 14]), stride=2
BottleneckV1(512, 512, stride=1), # torch.Size([1, 512, 14, 14]), stride=1
BottleneckV1(512, 512, stride=1), # torch.Size([1, 512, 14, 14]), stride=1
BottleneckV1(512, 512, stride=1), # torch.Size([1, 512, 14, 14]), stride=1
BottleneckV1(512, 512, stride=1), # torch.Size([1, 512, 14, 14]), stride=1
BottleneckV1(512, 512, stride=1), # torch.Size([1, 512, 14, 14]), stride=1
BottleneckV1(512, 1024, stride=2), # torch.Size([1, 1024, 7, 7]), stride=2
BottleneckV1(1024, 1024, stride=1), # torch.Size([1, 1024, 7, 7]), stride=1
)
# torch.Size([1, 1024, 7, 7])
self.avg_pool = nn.AvgPool2d(kernel_size=7, stride=1) # torch.Size([1, 1024, 1, 1])
self.linear = nn.Linear(in_features=1024, out_features=num_classes)
self.dropout = nn.Dropout(p=0.2)
self.softmax = nn.Softmax(dim=1)
self.init_params()
# 初始化操作
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear) or isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.first_conv(x) # torch.Size([1, 32, 112, 112])
x = self.bottleneck(x) # torch.Size([1, 1024, 7, 7])
x = self.avg_pool(x) # torch.Size([1, 1024, 1, 1])
x = x.view(x.size(0), -1) # torch.Size([1, 1024])
x = self.dropout(x)
x = self.linear(x) # torch.Size([1, 5])
out = self.softmax(x) # 概率化
return x
if __name__ == '__main__':
net = MobileNetV1().cuda()
summary(net, (3, 224, 224))
2. MobileNetV2
2.1 简介
MobileNetV2主要是引入了线性瓶颈结构和反向残差结构,对V1进行了改进。
MobileNetV2网络模型中有共有17个Bottleneck层(每个Bottleneck包含两个逐点卷积层和一个深度卷积层),一个标准卷积层(conv),两个逐点卷积层(pw conv),共计有54层可训练参数层。MobileNetV2中使用线性瓶颈(Linear Bottleneck)和反向残差(Inverted Residuals)结构优化了网络,使得网络层次更深了,但是模型体积更小,速度更快了。
2.2 网络亮点
- Inverted Residuals(倒残差结构)
- 1*1卷积升维
- 3*3卷积DW
- 1*1卷积降维
下图是ResNet和倒残差网络块的区别。
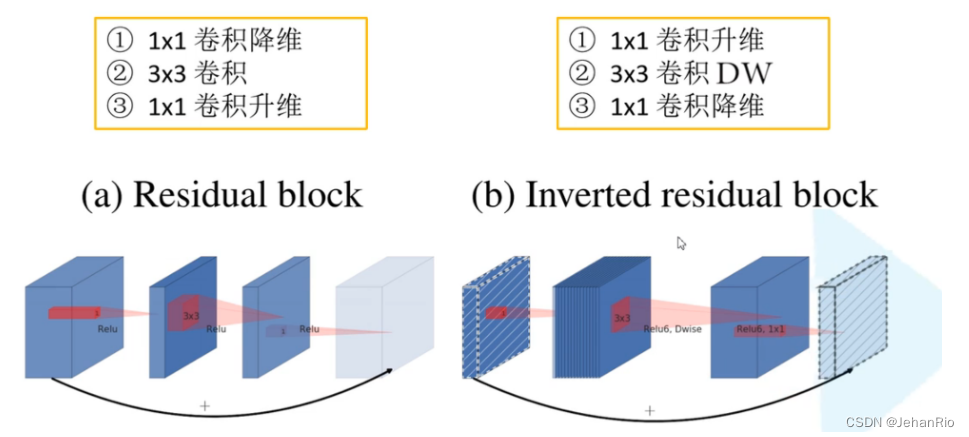
- Linear Bottleneck
最后的激活函数采用线性激活函数:因为ReLU激活函数对低维特征信息造成大量损失,对高维的损失小,所以使用线性激活函数,避免信息损失。这就是V2的第二个亮点。

当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接
References
【轻量化网络系列(1)】MobileNetV1论文超详细解读(翻译 +学习笔记+代码实现)
轻量级神经网络MobileNet全家桶详解















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









