






摘要
I. INTRODUCTION
拓扑信息是指物体的拓扑元素(项点Vertex、边Edge和表面Face)的个数、类型以及它们之间的相互关系信息。拓扑是研究在形变状态下图形空间性质保持不变的一个数学分支,着重研究图形内的相对位置关系。
计算机网络中的网络层与无线通信系统中的网络层有什么区别?
计算机网络中的网络层与无线通信系统中的网络层有所不同。在计算机网络中,网络层是负责将数据包从源主机传输到目的主机的协议层。而在无线通信系统中,网络层是负责将数据包从源设备传输到目的设备的协议层。两者的区别在于,无线通信系统中的网络层需要考虑无线信道的特性,如信道容量、干扰等因素,而计算机网络中的网络层则不需要考虑这些因素。此外,无线通信系统中的网络层还需要考虑移动性等因素,以保证数据包能够正确地传输到目的设备。
源: 与必应的对话, 2023/5/11
(1) 一篇文章,只用看三遍,终生不忘网络分层 - 知乎. https://zhuanlan.zhihu.com/p/380119935.
(2) 计算机网络基础(三):网络层 - 知乎. https://zhuanlan.zhihu.com/p/451667144.
(3) 计算机网络的7层、4层和5层模型 - 知乎. https://zhuanlan.zhihu.com/p/163691647.
无线信道的特性会影响无线通信系统的网络层。无线信道的特性包括信道容量、干扰等因素,这些因素会影响数据包的传输速率和可靠性。例如,当信道容量较小时,数据包的传输速率会降低;当干扰较大时,数据包的传输可靠性会降低。此外,无线通信系统中的网络层还需要考虑移动性等因素,以保证数据包能够正确地传输到目的设备。
源: 与必应的对话, 2023/5/11
(1) 一文读懂无线信道传播的各种特性 - 知乎. https://zhuanlan.zhihu.com/p/605877774.
(2) [4G&5G专题-42]:物理层-无线信道的特征:RSRP、SNR、BLER .... https://blog.csdn.net/HiWangWenBing/article/details/113979448.
(3) Wi-Fi 物理层 - 知乎. https://zhuanlan.zhihu.com/p/142166322.
来自可视数据的系统拓扑信息是什么
来自可视数据的系统拓扑信息是指计算机或电信网络的可视化表示,显示组成网络的组件以及它们的交互,包括路由器、设备、集线器、防火墙等²。它可以用于识别电网拓扑结构,以进行数据驱动和情境感知的电网运行¹。此外,系统拓扑信息可用于创建与外部数据链接的 Visio 中的详细网络图³。
源: 与必应的对话, 2023/5/11
(1) 硬核科普:什么是拓扑? - 知乎. https://zhuanlan.zhihu.com/p/214200642.
(2) 走进大数据之拓扑数据分析方法 - 知乎. https://zhuanlan.zhihu.com/p/24988537.
(3) 一文带你全面了解数据信息可视化 - 知乎. https://zhuanlan.zhihu.com/p/605993189.
System topology information from visual data refers to the visual representation of a computer or telecommunications network that shows the components that make up a network and how they interact, including routers, devices, hubs, firewalls, etc. ² It can be used to identify the topology of power networks for data-driven and situation-aware operation of power grids ¹. In addition, system topology information can be used to create a detailed network diagram in Visio linked to external data ³.
源: 与必应的对话, 2023/5/11
(1) What is a Network Diagram | Lucidchart. https://www.lucidchart.com/pages/network-diagram.
(2) Frontiers | Power System Network Topology Identification Based on .... https://www.frontiersin.org/articles/10.3389/fenrg.2020.613331/full.
(3) Create a detailed network diagram in Visio linked to external data. https://support.microsoft.com/en-us/office/create-a-detailed-network-diagram-in-visio-linked-to-external-data-495cd74f-0eae-497a-b020-ed0824f4d9d3.
路由算法是指计算机网络中的一种算法,用于确定数据包从源节点到目标节点的路径。常见的路由算法有Dijkstra算法、Bellman-Ford算法等¹。其中Dijkstra算法是一种单源最短路径算法,用于计算一个节点到其他所有节点的最短路径²。Bellman-Ford算法是一种求解最短路径问题的算法,可以处理有负权边的图,但不能处理负权回路²。
源: 与必应的对话, 2023/5/11
(1) 路由选择、路由协议与路由算法_春风来不来的博客 .... https://blog.csdn.net/a1414345/article/details/72579410.
(2) 路由算法(Dijkstra, Bellman-Ford算法)_风间琉璃•的博客 .... https://blog.csdn.net/qq_53144843/article/details/121254000.
(3) 路由算法(通网五) - 知乎. https://zhuanlan.zhihu.com/p/149943677.
(4) 路由算法(全网最细) - 知乎. https://zhuanlan.zhihu.com/p/138122809.
馈电误差是指在电力系统中,由于电源电压、负载电流和线路阻抗等因素的影响,使得电源端和负载端的电压或电流存在误差。这种误差称为馈电误差。¹ 馈电误差是一种常见的误差类型,它会对电力系统的稳定性和可靠性产生影响。²
源: 与必应的对话, 2023/5/11
(1) 馈电是什么意思,你了解多少 - 知乎. https://zhuanlan.zhihu.com/p/37058015.
(2) 请问当我们讨论插电混动时,“馈电”到底指的是 .... https://www.zhihu.com/question/441249737.
(3) 馈电_百度百科. https://baike.baidu.com/item/%E9%A6%88%E7%94%B5/2732138.
II. AN OVERVIEW OF RELATED WORK
a) Datasets:
深度图像(Depth Images),也被称为距离影像(Range Images),是指将图像采集器采集到的场景中各点的距离(深度)值作为像素值的图像,它直接反映了景物可见表面的几何形状,利用它可以很方便地解决 3D 目标描述中的许多问题。¹ 深度图像经过坐标转换可以计算为点云数据,有规则及必要信息的点云数据可以用于三维重建、三维建模、三维视觉等领域。²
源: 与必应的对话, 2023/5/11
(1) 什么是深度图像|极客笔记. https://bing.com/search?q=%e6%b7%b1%e5%ba%a6%e5%9b%be%e5%83%8f%e6%98%af%e4%bb%80%e4%b9%88.
(2) 深度图像基础知识(一)_什么是深度图_shine_cherise的 .... https://blog.csdn.net/shine_cherise/article/details/79283887.
(3) 什么是深度图像|极客笔记. https://deepinout.com/camera-terms/what-is-depth-image.html.
(4) 关于深度图像_DDsoup的博客-CSDN博客. https://blog.csdn.net/m0_61897853/article/details/122266031.
(5) 深度图像 - 知乎. https://zhuanlan.zhihu.com/p/371517878.
图像各点的深度指的是图像中每个像素点的深度值,也就是该像素点到摄像机的距离。在深度图像中,每个像素点的灰度值代表了该像素点到摄像机的距离,因此深度图像可以用于三维重建、三维建模、三维视觉等领域。¹ 深度图像可以通过激光雷达、结构光、ToF(Time of Flight)等方式获取。²
源: 与必应的对话, 2023/5/11
(1) 图像的通道和深度_通道深度_lcczzu的博客-CSDN博客. https://blog.csdn.net/lcczzu/article/details/90318489.
(2) 深度图像基础知识(一)_什么是深度图_shine_cherise的 .... https://blog.csdn.net/shine_cherise/article/details/79283887.
(3) 图像基础-像素,分辨率,深度,通道理解 - 浮沉沉浮 .... https://www.cnblogs.com/fcfc940503/p/11435439.html.
(4) 图像处理中的深度(通道)到底是什么意思? - 知乎. https://www.zhihu.com/question/591041026.
(5) 图像深度(Image Depth)_图像深度怎么计算_没有你的夜 .... https://blog.csdn.net/qq_26671365/article/details/53218372.
ViWi-BT数据集是一个用于视觉辅助毫米波束跟踪的数据集,它包含了用于预测未来毫米波用户的光束的 RGB 图像和先前观察到的连续 8 个光束。²
希望这能回答您的问题。如果您需要更多关于 ViWi-BT 数据集的信息,请告诉我。
源: 与必应的对话, 2023/5/12
(1) The ViWi-BT Competition. https://www.viwi-dataset.net/viwi-bt.html.
(2) The ViWi Dataset. https://www.viwi-dataset.net/.
(3) ViWi Vision-Aided mmWave Beam Tracking: Dataset, Task .... https://www.x-mol.com/paper/1225934037989740544.
DeepSense 6G 是一个真实的多模态数据集,包括了在现实无线环境中收集的共存的多模态感知和通信数据,如 mmWave 无线通信、摄像头、GPS 数据、LiDAR 和雷达。它是世界上第一个大规模的真实世界感知-通信数据集。¹²
希望这能回答您的问题。如果您需要更多关于 DeepSense 6G 的信息,请告诉我。
源: 与必应的对话, 2023/5/12
(1) DeepSense 6G. https://deepsense6g.net/.
(2) Data Collection – DeepSense. https://deepsense6g.net/data-collection/.
(3) DeepSense 6G: A Large-Scale Real-World Multi-Modal .... https://arxiv.org/pdf/2211.09769v1.
(4) [2211.09769] DeepSense 6G: A Large-Scale Real-World .... https://arxiv.org/abs/2211.09769.
b) Applications:
毫米波通信是指以毫米波作为传输信息的载体而进行的通信。毫米波是指波长在毫米数量级的电磁波,其频率大约在30GHz~300GHz之间。根据通信原理,无线通信的最大信号带宽大约是载波频率的5%左右,因此载波频率越高,可实现的信号带宽也越大。在毫米波频段中,28GHz频段和60GHz频段是最有希望使用在5G的两个频段。² 毫米波通信具有带宽大、数据传输快等优点,但由于毫米波的穿透能力较差,需要在传输过程中增加中继站等设备来保证通信质量。⁴
源: 与必应的对话, 2023/5/11
(1) 5G关键技术之毫米波 - 知乎. https://zhuanlan.zhihu.com/p/21800636.
(2) 干货文章!毫米波优缺点及应用大全 - 知乎. https://zhuanlan.zhihu.com/p/425840620.
(3) 一文读懂5G之毫米波通信 - 与非网. https://www.eefocus.com/article/458480.html.
(4) 5G纯干货|毫米波概述与优缺点 - CSDN博客. https://blog.csdn.net/hongsongjiaoyu/article/details/104837540.
You Only Look Once (YOLO) 是一种目标检测网络,它是一种one-stage目标检测网络,这个模型之所以叫you only look once,是因为作者想用这种网络去实现像人们只需要瞥一眼图片就知道图片中由什么物体,物体的位置及它们之间的联系的模型表现效果。¹²³
希望这能回答您的问题。如果您需要更多关于 YOLO 的信息,请告诉我。
源: 与必应的对话, 2023/5/12
(1) 【论文阅读】《You Only Look Once: Unified, Real-Time .... https://zhuanlan.zhihu.com/p/388491947.
(2) 【物体検出手法の歴史 : YOLOの紹介】 - Qiita. https://qiita.com/cv_carnavi/items/68dcda71e90321574a2b.
(3) You Only Look Once: Unified, Real-Time Object Detection. https://arxiv.org/abs/1506.02640.
(4) Home - Ultralytics YOLOv8 Docs. https://docs.ultralytics.com/.
III. AN EXAMPLE OF APPLYING DL-BASED CV TO BEAMFORMING
A. Problem Defifinition
B. Framework Architecture and Methods
1) ResNet, ResNext and 3D ResNext:
什么是梯度爆炸/梯度消失?_浩瀚之水_csdn的博客-CSDN博客![]() https://blog.csdn.net/a8039974/article/details/122381069深度神经网络训练的时候,采用的是反向传播方式,该方式使用链式求导,计算每层梯度的时候会涉及一些连乘操作,因此如果网络过深。
https://blog.csdn.net/a8039974/article/details/122381069深度神经网络训练的时候,采用的是反向传播方式,该方式使用链式求导,计算每层梯度的时候会涉及一些连乘操作,因此如果网络过深。
那么如果连乘的因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生变化.
那么如果连乘的因子大部分大于1,最后乘积可能趋于无穷,这就是梯度爆炸
(1条消息) 通俗易懂的反向传播法(python 代码实现)_python反向传播算法_莱维贝贝、的博客-CSDN博客![]() https://blog.csdn.net/A496608119/article/details/115489420(1条消息) 深度学习-链式求导_长野飘荡的博客-CSDN博客
https://blog.csdn.net/A496608119/article/details/115489420(1条消息) 深度学习-链式求导_长野飘荡的博客-CSDN博客![]() https://blog.csdn.net/weixin_40476348/article/details/94434483
https://blog.csdn.net/weixin_40476348/article/details/94434483
2) Long Short-Term Memory (LSTM) Network:
3) Feature-Fusion Module (FFM):
特征融合模块是深度学习中的一种技术,用于将不同层次的特征进行融合,以提高模型的性能。在深度学习的很多工作中(例如目标检测、图像分割),融合不同尺度的特征是提高性能的一个重要手段。³⁴
如果您需要更多关于特征融合模块的信息,请告诉我。
源: 与必应的对话, 2023/5/12
(1) 特征融合 & FFM(Feature Fusion Module) 特征融合模块(add .... https://blog.csdn.net/hxxjxw/article/details/113632745.
(2) 深度学习中有哪些魔改的特征融合方法? - 知乎. https://www.zhihu.com/question/584973666.
(3) 即插即用系列!| CFNet:一种新颖的多尺度融合方法,显著 .... https://zhuanlan.zhihu.com/p/607577626.
(4) 【WACV 2021】Attentional Feature Fusion - 知乎. https://zhuanlan.zhihu.com/p/424031096.
在深度学习中,低层特征和高层特征是指在卷积神经网络(CNN)中的不同层次的特征。低层特征通常是一些基本的、局部的、底层的特征,例如边缘、纹理等,而高层特征则是一些抽象的、全局的、高层次的特征,例如物体的形状、类别等。¹⁴
希望这能回答您的问题。如果您需要更多关于低层特征和高层特征的信息,请告诉我。
源: 与必应的对话, 2023/5/12
(1) CVPR 2017 - FPN理解 - 简单高效的特征金字塔 - 知乎. https://zhuanlan.zhihu.com/p/111342763.
(2) 低层次特征和高层次特征是什么? - 知乎. https://www.zhihu.com/question/317549043.
(3) 深度特征融合---高低层(多尺度)特征融合 - CSDN博客. https://blog.csdn.net/xys430381_1/article/details/88370733.
(4) 对图像中语义信息、高层和底层特征的理解_低层特征和高层 .... https://blog.csdn.net/qq_30121457/article/details/108918519.
(5) CNN中的底层、高层特征、上下文信息、多尺度 - CSDN博客. https://blog.csdn.net/Rolandxxx/article/details/127207350.
CVPR 2017 - FPN理解 - 简单高效的特征金字塔 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/111342763
https://zhuanlan.zhihu.com/p/111342763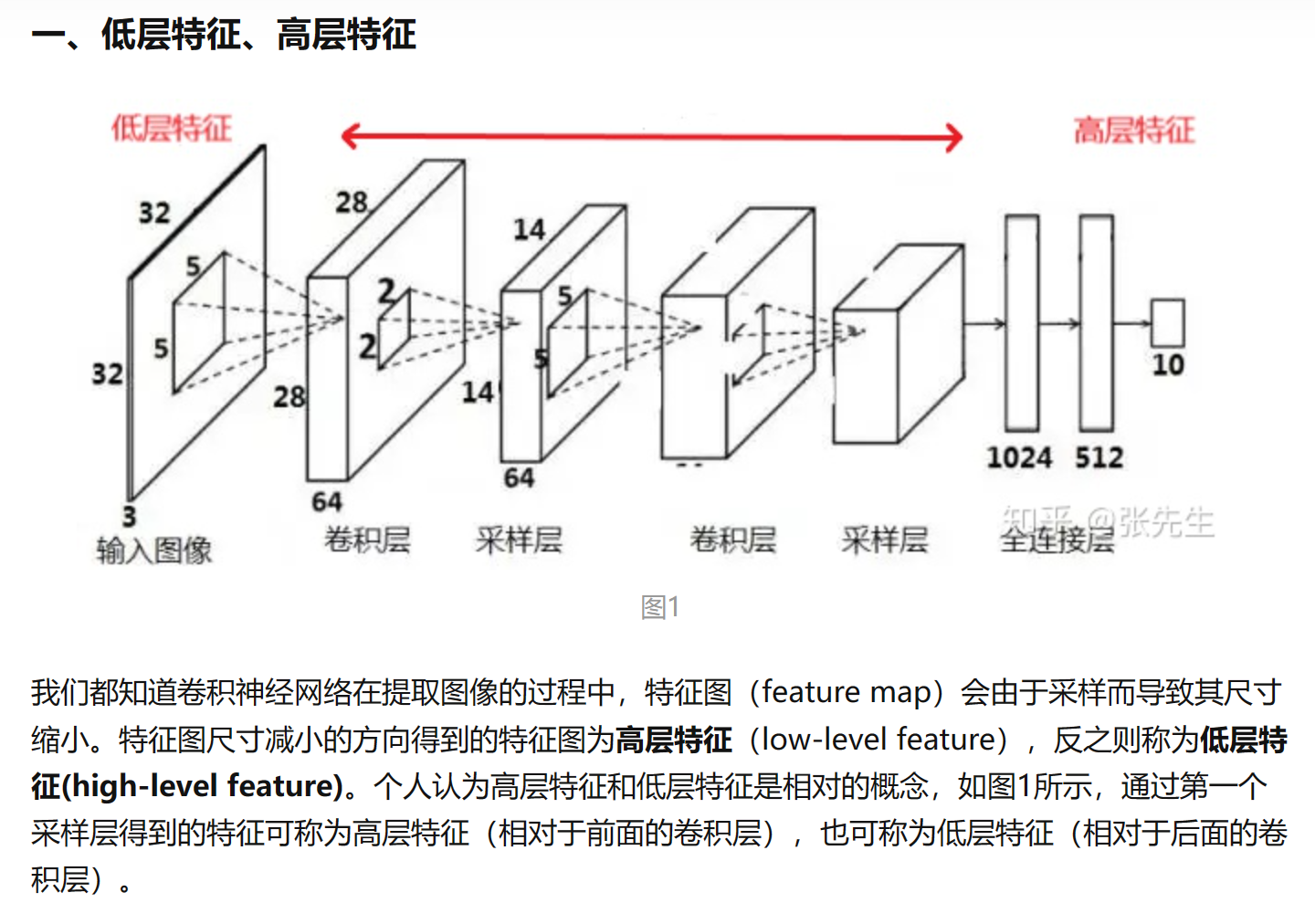
对于目标检测来说,其任务可概述为 分类+定位 。由此我们可以联想到,对于分类任务来说,使用高层特征更加有助于分类正确;而对于定位任务(即Bouning box的获取),使用低层特征更加精确。由此我又想到,目前出现的算法大都是使用一个CNN(即one stage)直接得到结果,如此看来,必须要找到合适的低层特征和高层特征的融合方式,从而提升目标检测的性能。
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种具有局部连接、权值共享等特点的深层前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一,擅长处理图像特别是图像识别等相关机器学习问题,比如图像分类、目标检测、图像分割等各种视觉任务中都有显著的提升效果,是目前应用最广泛的模型之一。¹²
CNN的基本结构包括卷积层、池化层和全连接层。其中,卷积层是CNN的核心部分,它通过卷积操作提取输入数据的特征,池化层则用于降低特征图的维度,全连接层则用于将特征图映射到输出空间。²⁴
希望这能回答您的问题。如果您需要更多关于卷积神经网络的信息,请告诉我。
源: 与必应的对话, 2023/5/12
(1) 【CNN】深入浅出讲解卷积神经网络(介绍、结构、原理 .... https://bing.com/search?q=%e5%8d%b7%e7%a7%af%e7%a5%9e%e7%bb%8f%e7%bd%91%e7%bb%9c%e8%af%a6%e7%bb%86%e4%bb%8b%e7%bb%8d.
(1条消息) 【CNN】深入浅出讲解卷积神经网络(介绍、结构、原理)_cnn结构图_程序遇上智能星空的博客-CSDN博客![]() https://blog.csdn.net/kevinjin2011/article/details/124944728
https://blog.csdn.net/kevinjin2011/article/details/124944728
(2) 【CNN】深入浅出讲解卷积神经网络(介绍、结构、原理 .... https://blog.csdn.net/kevinjin2011/article/details/124944728.
(3) 一文入门卷积神经网络:CNN通俗解析 - 知乎. https://zhuanlan.zhihu.com/p/44464548.
(4) 卷积神经网络超详细介绍_呆呆的猫的博客-CSDN博客. https://blog.csdn.net/jiaoyangwm/article/details/80011656.
(5) 卷积神经网络 - 知乎. https://www.zhihu.com/topic/20043586/intro.
(6) 卷积神经网络(CNN)基础及经典模型介绍 - 知乎. https://zhuanlan.zhihu.com/p/344562609.
训练卷积神经网络的过程通常包括以下几个步骤:
1. 数据预处理:将数据集分为训练集、验证集和测试集,并进行数据增强等操作。
2. 网络设计:选择合适的网络结构,包括卷积层、池化层和全连接层等。
3. 损失函数的选择:根据任务的不同,选择合适的损失函数。
4. 优化器的选择:根据损失函数的不同,选择合适的优化器。
5. 训练模型:使用训练集对模型进行训练,并在验证集上进行验证,直到模型收敛或达到预设的训练轮数。
6. 模型评估:使用测试集对模型进行评估。
希望这能回答您的问题。如果您需要更多关于卷积神经网络的信息,请告诉我。
卷积神经网络(CNN)和循环神经网络(RNN)是两种不同的神经网络结构,它们在处理数据时有着不同的方式。
CNN主要用于处理图像、视频等数据,它通过卷积层和池化层提取输入数据的特征,然后通过全连接层将特征图映射到输出空间。CNN的优点是可以处理高维数据,且具有一定的平移不变性和局部连接性,因此在图像分类、目标检测等视觉任务中表现出色。
RNN主要用于处理序列数据,如自然语言、音频等数据,它通过循环层对序列数据进行建模,从而捕捉序列中的时间依赖关系。RNN的优点是可以处理变长序列数据,并且具有一定的记忆能力,因此在机器翻译、语音识别等任务中表现出色。
希望这能回答您的问题。如果您需要更多关于卷积神经网络或循环神经网络的信息,请告诉我。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









