







2.最小生成树MST
一个图可以有多个生成树,我们定义无向连通图的 最小生成树(Minimum Spanning Tree,MST)为 边权和最小的生成树。
【注意】:
- 最小生成树也可能有多个。
- 一个连通图的生成树是一个极小的连通子图,它含有图中全部的顶点。
- 如果一个连通图本身就是一棵树,则其最小生成树就是它本身。
- 只有连通图才有生成树,而对于非连通图,只存在生成森林。
构造最小生成树有多种算法,但大多数算法都利用了最小生成树的下列性质:
假设G=(V,E)是个带权连通无向图,U是顶点集V的一个非空子集(U∈V)。若(u,v)是一条具有最小权值的边,其中u∈U, v∈V-U,则必存在一棵包含边(u,v)的最小生成树。
基于该性质的最小生成树算法主要有Prim算法和Kruskal算法,它们都基于贪心算法的策略。下面介绍一个通用的最小生成树算法:
GENERIC_MST(G){
T=NULL;
while T 未形成一棵生成树;
do 找到一条最小代价边(u, v)并且加入T后不会产生回路;
T=T U (u, v);
}
通用算法每次加入一条边以逐渐形成一棵生成树,下面介绍两种实现上述通用算法的途径。
2.1 普里姆(Prim)算法
从一个顶点开始,每次将代价最小的新顶点纳入生成树,直到所有顶点都纳入为止。
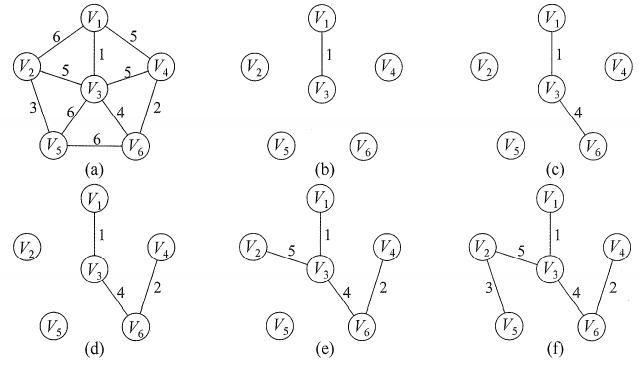
- Prim算法只和顶点个数有关系,它的时间复杂度是O(|V|2)。
- 适合于边稠密的图。
算法思路
创建两个数组isJoin标记各节点是否已经加入树,lowCost标记各节点加入树的最低代价。
初始化:把第一个结点v0的isJoin除了它自己全部标记为false,lowCost填入边的权值(不相连为∞)。
找出 lowCost 最小的结点v1加入(isJoin = true),这个时候,初始结点v0和这个新结点v1就是一个树,那么 lowCost 保存的是整棵树的的最低代价,所以需要遍历新加入的结点v1的边的权值,当初始节点v0的 lowCost 大于新结点v1的 lowCost ,则直接更新 lowCost 为那个更小的权值。
再在 lowCost 中寻找权值最小的结点,然后加入树,然后遍历它的 lowCost 进行替换。直到所有结点都加入生成树。
也就是每个结点都遍历一遍lowCost,所以时间复杂度为O(n2)。
初始化:
然后进行第一轮low的遍历

修改lowCost之后,修改isJoin:


然后这个点就结束了,再去寻找下一个lowCost最低的点:

…一直扫描所有点,直到isJoin全部为true:

在邻接矩阵中:
// 最小生成树MST - Prim算法
// 贪心, O(n^2), 适用于稠密图
void MiniSpanTree_Prim(MGraph G){
int i, j;
int v, min; //min是最小权值,v是最小权值的下标
int adjvex[G.vexnum]; //保存相关顶点下标
int lowCost[G.vexnum]; //保存标记各节点加入树的最低代价
//初始化
lowCost[0] = 0; //初始化第一个权值为0,即v0加入生成树
//lowCost的值为0,在这里就是此下标的顶点已经加入生成树
adjvex[0] = 0; //初始化第一个顶点下标为0
for(i=0; i<G.vexnum; i++){
lowCost[i] = G.Edge[0][i]; //将v0顶点与之组成边的权值存入数组
adjvex[i] = 0; //初始化都为v0的下标
}
//寻找
for(i=1; i<G.vexnum; i++){
min = INFINITY; //初始化最小权值为∞,通常设置一个不可能的很大的数字
j = 1; //0已经初始化,从1开始
v = 0;
//循环全部顶点找最小权值
while(j < G.vexnum){
//如果权值不为0且权值小于min
if(lowCost[j]!=0 && lowCost[j]<min){
min = lowCost[j]; //则让当前权值成为最小值
v = j; //将当前最小值的下标存入k
}
j++;
}
printf("(%d, %d)", adjvex[v], v); //打印当前顶点边中权值的最小边
for(j=1; j<G.vexnum; j++){ //修改lowCost数组
//若下标为v顶点各边权值小于此前这些顶点未被加入生成树权值
if(lowCost[j]!=0 && G.Edge[v][j] < lowCost[j]){
lowCost[j] = G.Edge[v][j]; //将较小权值存入lowCost
adjvex[j] = v; //将下标为v的顶点存入adjvex
}
}
}//for
}
由算法代码中的循环嵌套可得知此算法的时间复杂度为O(n2)。
2.2 克鲁斯卡尔(Kruskal)算法
与Prim算法从顶点开始扩展最小生成树不同,Kruskal 算法是一种按权值的递增次序选择合适的边来构造最小生成树的方法。
这个算法不选择一开始的顶点,直接找权值最小的边,从小到大加入边,是个贪心算法。
- Kruskal算法只关系边的个数,它的时间复杂度是O(|E|log2|E|)。
- 适合于边稀疏的图。
算法思路
因为 kruskal 算法每次找的是权值最小的边,所以可以预处理把所有的边进行排序。用 weight, V1, V2 保存这样一个边的信息,weight是权值,V1, V2是它连接的两个结点。
一开始,每一个结点都可以看作不同的集合。当一个边的权值足够小,并且两个结点V1, V2属于不同的集合,那么这时候就可以把两个结点连起来(选择这条边)构成一个新的集合。
一直从小到大遍历完所有的边。

算法虽简单,但需要相应的数据结构来支持……具体来说,维护一个森林,查询两个结点是否在同一棵树中,连接两棵树。
抽象一点地说,维护一堆 集合,查询两个元素是否属于同一集合,合并两个集合。
其中,查询两点是否连通和连接两点可以使用并查集维护。
如果使用 O(mlog m) 的排序算法,并且使用 O(mα(m,n)) 或 O(mlog m) 的并查集,就可以得到时间复杂度为 O(mlog m) 的 Kruskal 算法。
于是Kruskal算法代码如下:
/*Kruskar算法生成最小生成树*/
void MiniSpanTree_Kruskal(MGraph G){
int i, n, m;
Edge edges[MAXEDGE]; //定义边集数组
int parent[MAXVEX]; //定义一数组用来判断边与边是否形成环路
/*此处省略将邻接矩阵G转化为边集数组edges并按照权由小到大排序的代码*/
for(i=0; i<G.numVertexes; i++){
parent[i] = 0; //初始化数组为0
}
for(i=0; i<G.numVertexes; i++){
n = Find(parent, edges[i].begin);
m = Find(parent, edge[i],end);
//假如n与m不等,说明此边没有与现有生成树形成环路
if(n != m){
//将此边的结尾顶点放入下标为起点的parent中表示此顶点已经在生成树集合中
parent[n] = m;
printf("(%d, %d, %d)", edges[i].begin, edges[i].end, edges[i].weight);
}
}
}
/*查找连线顶点的尾部下标*/
int Find(int *parent, int f){
while(parent[f] > 0){
f = parent[f];
}
return f;
}
此算法的Find函数由边数n决定,时间复杂度为O(logn),而外面有一个for循环n次。所以克鲁斯卡尔算法的时间复杂度为O(nlogn)。
对比两个算法,克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势;而普里姆算法对于稠密图,即边数非常多的情况会更好一些。
2.3 Boruvka 算法
考研不考
很容易发现,对于某些毒瘤的问题,边的数量极其大,而边集内部又存在各种规律可能需要套上各种数据结构加以优化。但是此时Kruskal和Prim并不能很好的嵌合进这些数据结构。此时我们可以引入Boruvka算法。
该算法的思想是前两种算法的结合。它可以用于求解无向图的最小生成森林。(无向连通图就是最小生成树。)在边具有较多特殊性质的问题中,Boruvka 算法具有优势。例如 CF888G 的完全图问题。
对于Boruvka算法,一个比较笼统的表述是,一个多路增广版本的Kruskal。
2.3.1基本原理
在并查集算法中,初始状态下我们将每个点视为一个独立的点集,并不断地合并集合。
在Brouvka算法中,我们在一开始将所有点视为独立子集,每次我们找到两个集合(即为连通块)之间的最短边,然后扩展连通块进行合并。不断扩大集合(连通块)直到所有点合并为一个集合(连通块)
可以发现,Boruvka算法将求解最小生成树的问题分解为求连通块间最小边的问题。它的基本思想是:生成树中所有顶点必然是连通的,所以两个不相交集必须连接起来才能构成生成树,而且所选择的连接边的权重必须最小,才能得到最小生成树。
通过一张动态图来举一个例子:
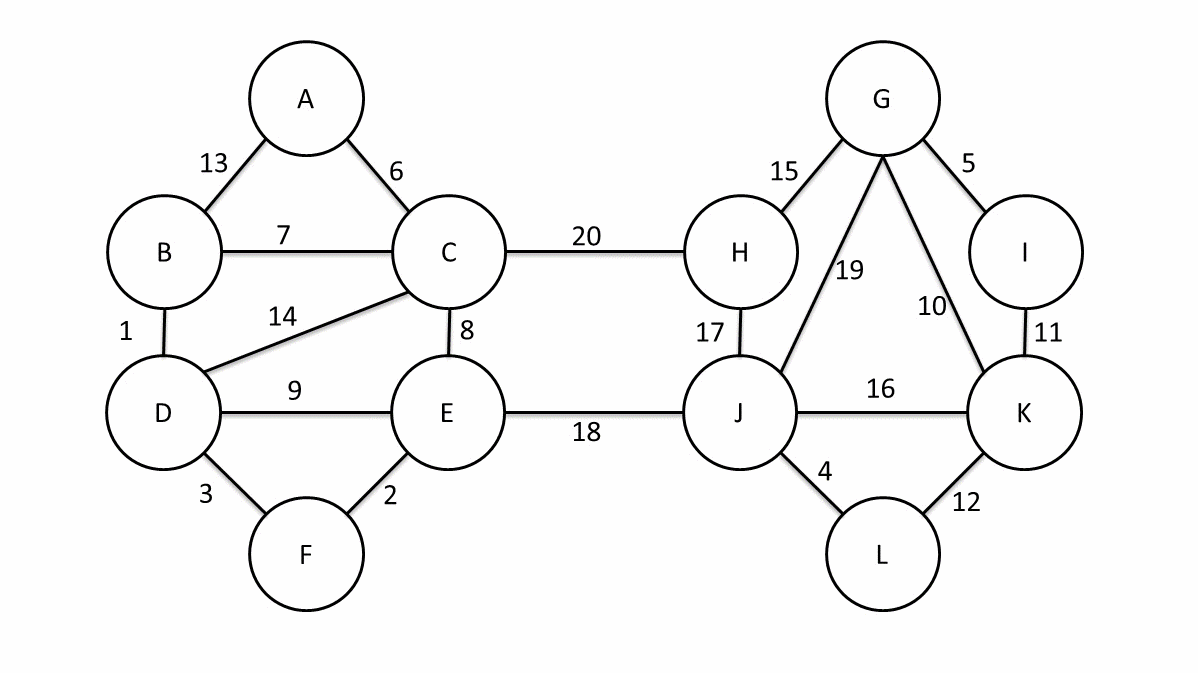
2.3.2基本过程
- 首先将所有点视为各自独立的集合,初始化一个空的MST;
- 当子集个数大于1的时候,对各个子集和执行以下操作:
- 找到与当前集合有边的集合,选出权值最小的边;
- 如果该权值最小的边不在MST中;
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
const int M = 1e6 + 10;
struct node { int u, v, w; } edge[M];
int f[N], best[N];
bool vis[N];
int n, m;
int find(int x){
return f[x] == x ? x : find(f[x]);
}
inline const bool cmp(int u, int v){
if(v == 0) return 1;
if(edge[u].w != edge[v].w) return edge[u].w < edge[v].w;
return u < v;
}
inline void init(){
cin >> n >> m;
for(int i = 1; i <= m; i++) cin >> edge[i].u >> edge[i].v >> edge[i].w;
for(int i = 1; i <= n; i++) f[i] = i;
}
inline int boruvka(){
memset(vis, 0, sizeof(vis));
int ans = 0, cnt = 0;
bool status = true;
while(true){
status = false;
//遍历边集
for(int i = 1; i <= m; i++){
if(!vis[i]){
int uu = find(edge[i].u), vv = find(edge[i].v);
if(uu == vv) continue;
if(cmp(i, best[uu])) best[uu] = i;
if(cmp(i, best[vv])) best[vv] = i;
}
}
//遍历点集
for(int i = 1; i <= n; i++){
if(best[i] && !vis[best[i]]){
status = true, cnt++, ans += edge[best[i]].w;
vis[best[i]] = 1;
int uu = find(edge[best[i]].u), vv = find(edge[best[i]].v);
f[uu] = vv;
}
}
}
if(cnt == n - 1) return ans;
return -1;
}
signed main(){
init();
boruvka();
return 0;
}















 5671
5671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









