










本文目录:
📢📢📢📣📣📣
🌻🌻🌻Hello,大家好我叫是Dream呀,一个有趣的Python博主,多多关照😜😜😜
🏅🏅🏅作者简介:Python领域优质创作者🏆 CSDN年度博客之星🏆 阿里云专家博主🏆 华为云享专家🏆 51CTO专家博主🏆
💕入门须知:这片乐园从不缺乏天才,努力才是你的最终入场券!🚀🚀🚀
💓最后,愿我们都能在看不到的地方闪闪发光,一起加油进步🍺🍺🍺
🍉🍉🍉一万次悲伤,依然会有Dream,我一直在最温暖的地方等你~🌈🌈🌈
🌟🌟🌟✨✨✨
前言:
❤️本文选自: 【零基础学Python】本课程是针对Python入门&进阶打造的一全套课程,在这里,我将会一 一更新Python基础语法、Python爬虫、Web开发、 Django框架、Flask框架以及人工智能相关知识,帮助你成为Python大神,如果你喜欢的话就抓紧收藏订阅起来吧~💘💘💘
一、数据集
1.可用数据集
- 公司内部 百度
- 数据接口 花钱
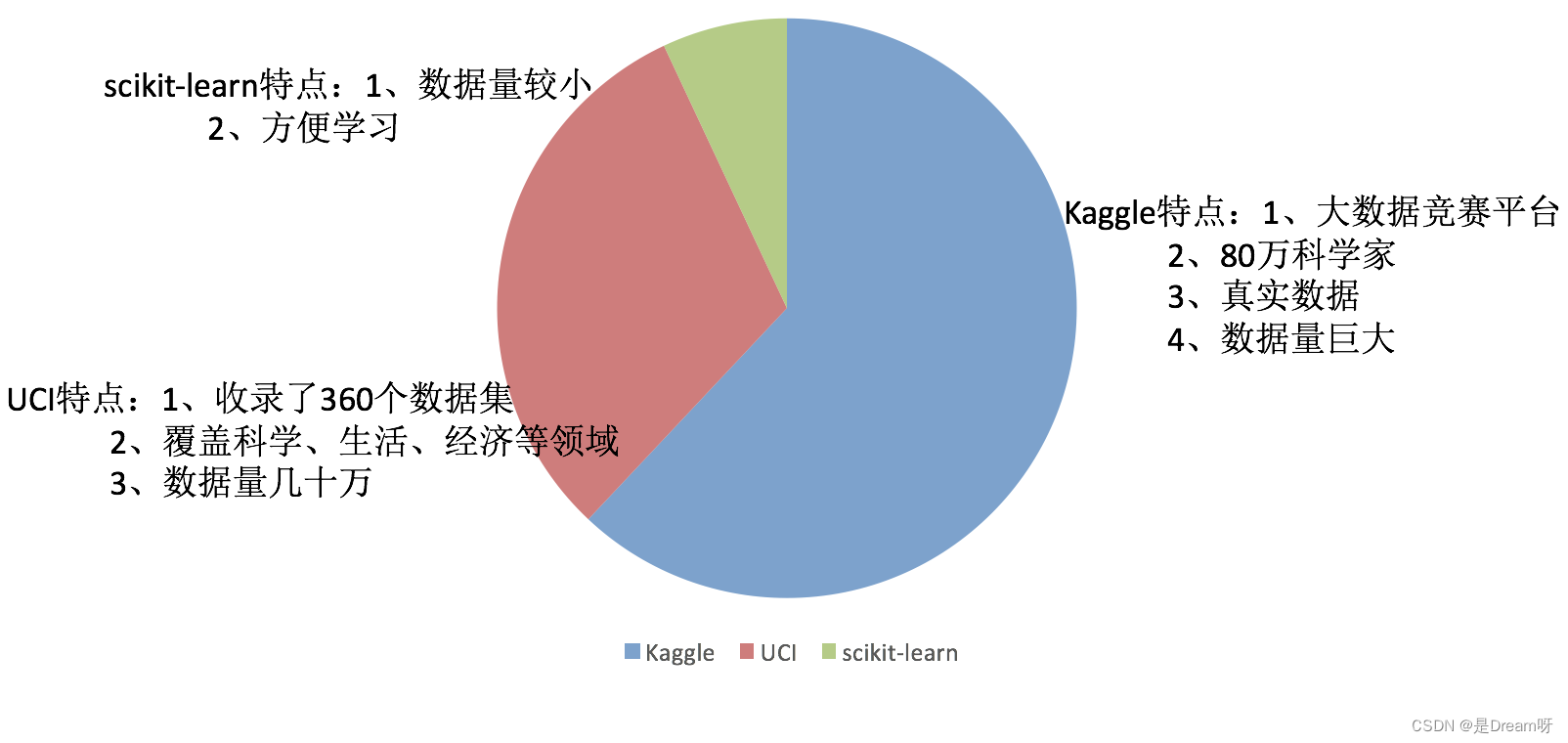
- 学习阶段可用的数据集:1.sklearn, 2.kaggle, 3.UCI
Kaggle网址:https://www.kaggle.com/datasets
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
1.1Scikit-learn工具介绍

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
1.2安装
pip3 install Scikit-learn==0.19.1

安装好之后可以通过以下命令查看是否安装成功
import sklearn
注:安装scikit-learn需要Numpy, Scipy等库
1.3Scikit-learn包含的内容
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
2.sklearn数据集
2.1scikit-learn数据集API介绍
sklearn.datasets:
- 加载获取流行数据集
- datasets.load_*(): 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
2.2sklearn小数据集
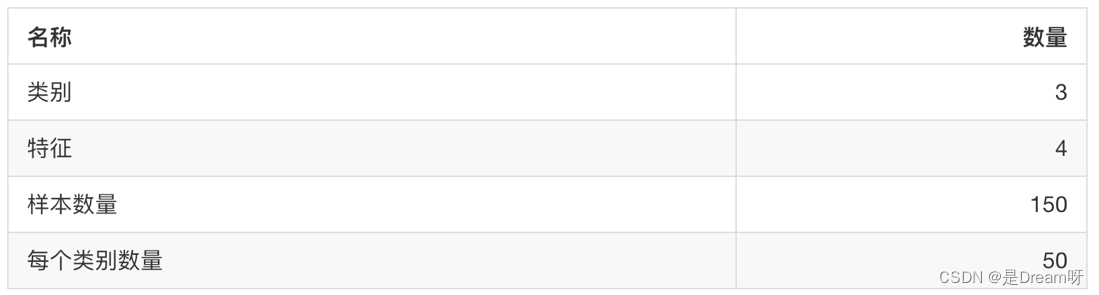
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
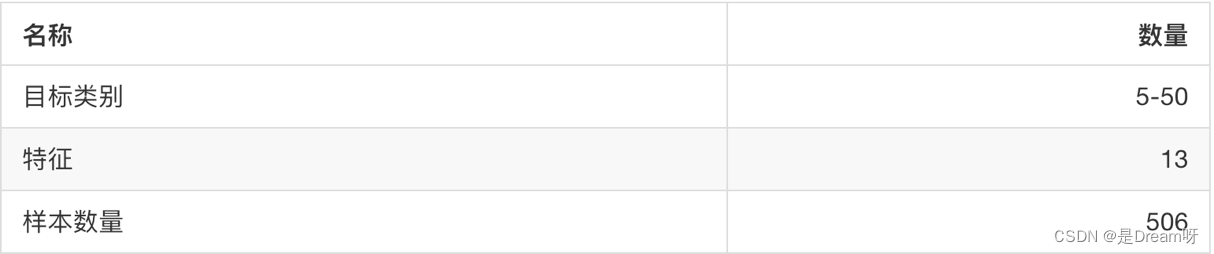
sklearn.datasets.load_boston()
加载并返回波士顿房价数据集
2.3sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset:‘train’或者’test’,‘all’,可选,选择要加载的数据集。
训练集的“训练”,测试集的“测试”,两者的“全部”
2.4sklearn数据集的使用
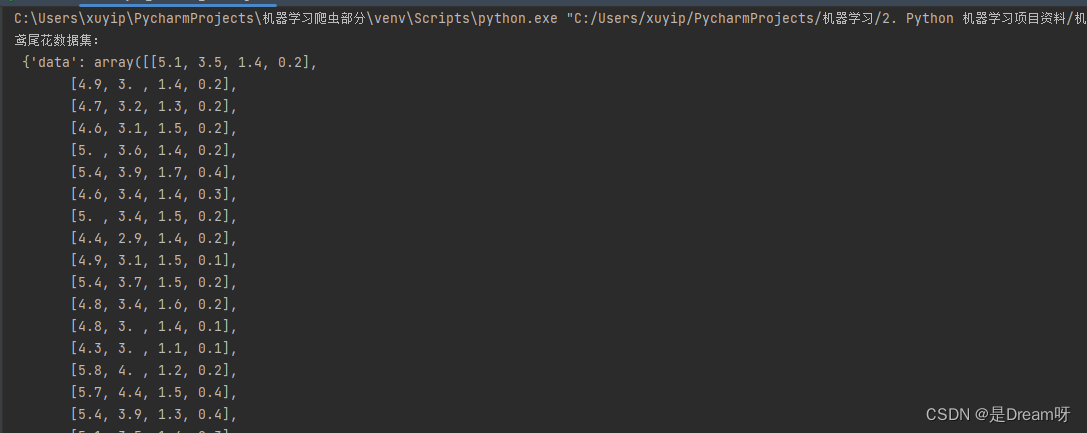
以鸢尾花数据集为例:

sklearn数据集返回值介绍
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
from sklearn.datasets import load_iris
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
思考:拿到的数据是否全部都用来训练一个模型?
3.数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%(测试集 20%~30%)
数据集划分api
sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
"""
对鸢尾花数据集的演示
:return: None
"""
# 1、获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)
# 2、对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 随机数种子
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("如果随机数种子一致:\n", x_train1 == x_train2)
return None

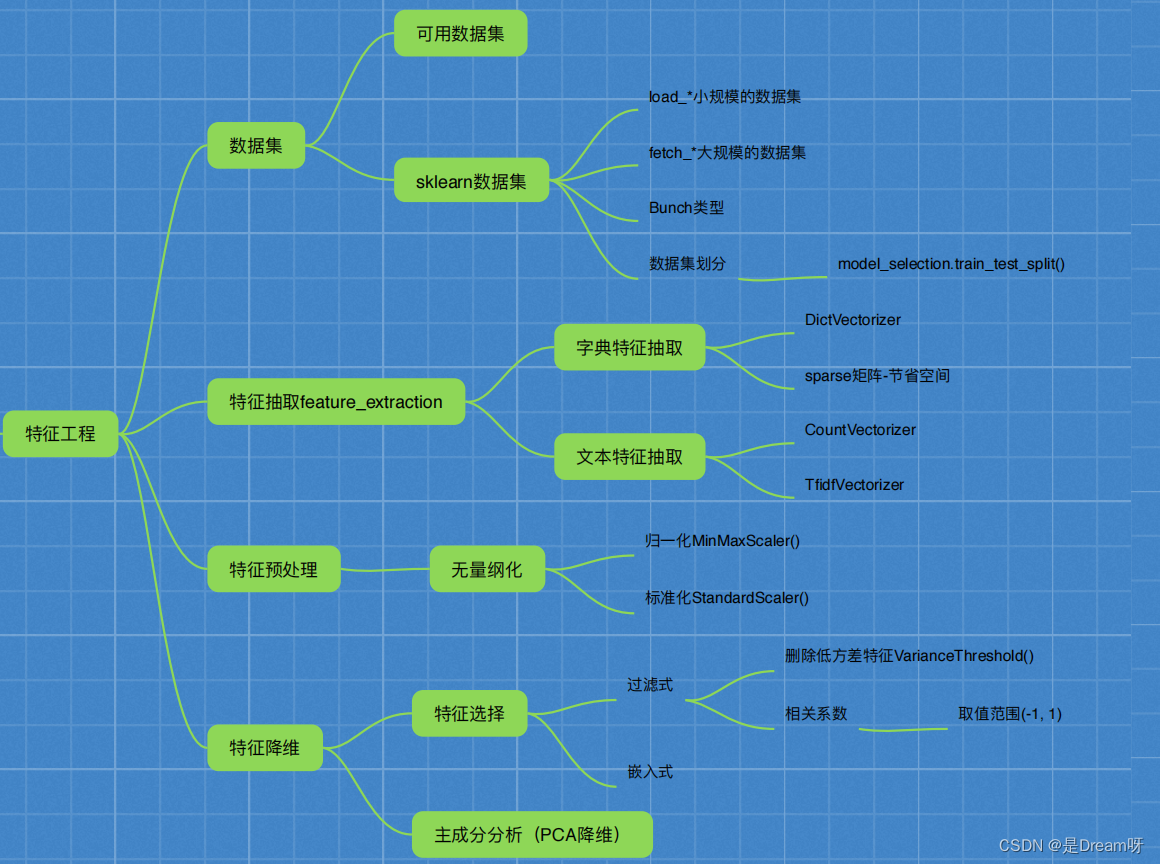
二、特征工程介绍
用的是同一个算法,结果为什么会不同呐,这就是我们要说的特征工程的意义。
1.为什么需要特征工程(Feature Engineering)
机器学习领域的大神Andrew Ng(吴恩达)老师说“Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering. ”
注:业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
2.什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:会直接影响机器学习的效果
3.特征工程的位置与数据处理的比较

pandas:一个数据读取非常方便以及基本的处理格式的工具(数据清洗和清理)
sklearn:对于特征的处理提供了强大的接口(特征工程)
特征工程包含内容
- 特征抽取
- 特征预处理
- 特征降维
【系列好文推荐】
🎯🎯🎯
零基础学Python 开篇–全套学习路线
零基础学Python–Web开发(七):登录实现及功能测试
零基础学Python 机器学习实战——疫情数据分析与预测实战
🎯🎯🎯
欢迎订阅本专栏: 零基础学Python 系列课程是针对Python入门&进阶打造的一全套课程,在这里,我将会一 一更新Python基础语法、Python爬虫、Web开发、 Django框架、Flask框架以及人工智能相关知识,帮助你成为Python大神,如果你喜欢的话就抓紧收藏订阅起来吧~💘💘💘
💕💕💕 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!✨ ✨ ✨
🍻🍻🍻如果你喜欢的话,就不要吝惜你的一键三连了~


⬇️⬇️ ⬇️ 商务合作|交流学习|粉丝福利|Python全套资料⬇️ ⬇️ ⬇️ 欢迎联系~















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











