







共28小题
1.当数据又缺失值的时候,你认为处理缺失值比较合理的方法是什么?(缺失值举例:泰坦尼克号幸存者数据中,又年龄、性别、职业、是否存活四个特征,但某些样本的职业特征为空)
答:如果有缺失值的样本数量相比于样本总数量很小的话,可以直接去除含有缺失值的样本;如果含有缺失值的样本占一定比例的话,我们可以用所缺失特征的均值、众数、中位数等进行填补。在决策树算法中,我们也可以将缺失的特征当作Label来进行分类预测,也可以获得缺失值。
2.请简述随机梯度下降和批量梯度下降的区别和各自的优点。
答:批量梯度下降的主要公式如下:
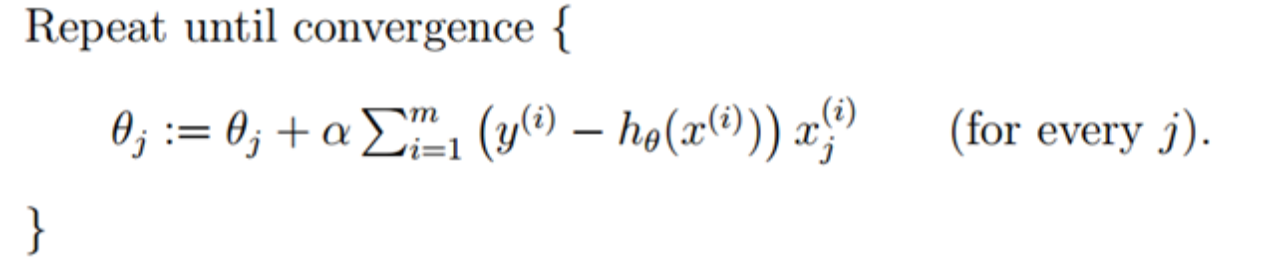
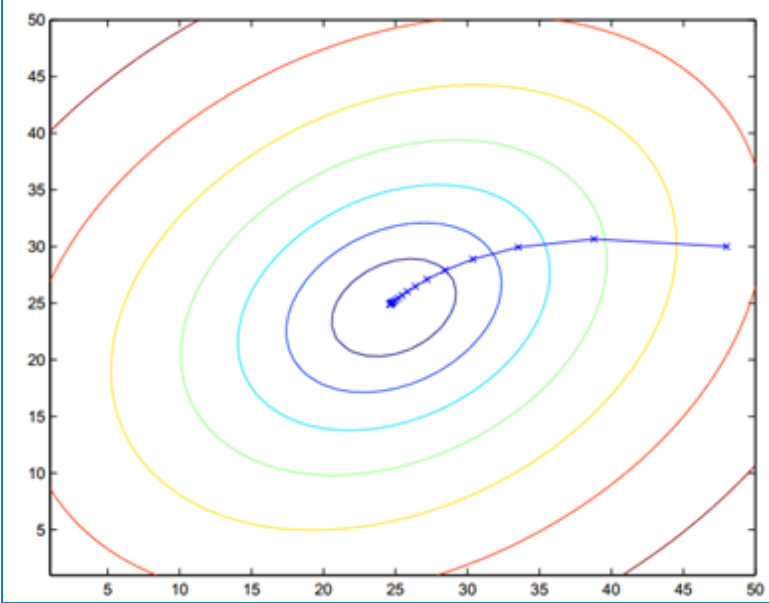
上面的表达式中 θ \theta θj每更新一次,就需要计算所有的训练样本,所以批量梯度下降算法的迭代速度很慢,但优点是收敛的快且震荡小。下图表示了批量梯度下降的收敛过程:
随机梯度下降算法的主要公式:
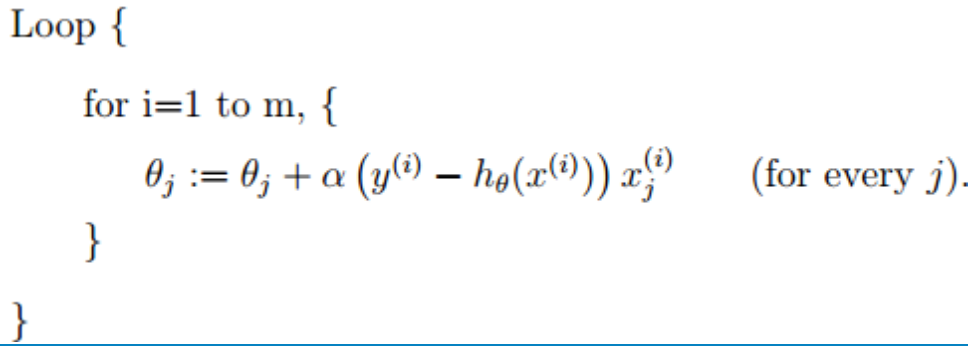
随机梯度下降算法在计算下降最快的方向时时随机选一个数据进行计算,而不是扫描全部训练数据集,这样就加快了迭代速度。随机梯度下降并不是沿着J(θ)下降最快的方向收敛,而是以震荡的方式趋向极小点。收敛过程大致如图:

其优点是迭代速度快,由于震荡大,故可以跳出局部最小,缺点是收敛的速度慢,也是因为震荡大。
3.线性判别分析(LDA)中,我们想要最优化的两个数值是什么?(聚类算法也是以这两个数据为目标进行优化)
答:西瓜书原文:LDA的思想非常朴素,给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离。故我们想要优化的两个数值为类内距离(尽可能小),类间距离(尽可能大)。
4.类别不平衡问题会带来什么样的影响,如何有效处理类别不平衡的问题?
答:类别不平衡就是指分类任务中不同类别的训练样例数目差别很大的情况,导致分类结果会偏向大类。
处理类别不平衡(假设为二分类问题,且正例多余反例):
a.欠采样,也称“下采样”,即去除一些正例使得正反例数目相近,然后再进行学习。
b.过采样,也称“上采样”,即增加一些正例使得正反例数目相近,然后再进行学习。
c.阈值转移,直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将“再放缩”嵌入到决策过程中。
5.什么是k折交叉验证?
答:将数据集等分为k份,每次用k份中的k-1份作为训练集,将剩下的一份作为测试集,直到每一份数据都被当做测试集,最后将得到的结果求均值。
6.请写出交叉熵损失函数。
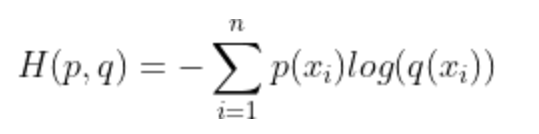
7.我们知道信息量的多少由信息的不确定性来衡量,信息量越大,信息的不确定性越大,信息熵的值越大。信息量越少,信息的不确定性越小,信息熵的值越小。请写出信息熵的公式。注:设集合D中第k类样本所占的比例为Pk(k=1,2,3,……,m)。

8.写出你知道的决策树算法。
答:ID3(以信息增益为划分依据)、C4.5(以信息增益率为划分依据)、CART(以基尼系数为划分依据)。
9.单变量决策树的分类边界是什么样的:
A.分类边界的每一段都是与坐标轴平行的
B.分类边界的每一段都是可以弯曲的曲线
C.分类边界的每一段都是倾斜的直线
D.分类边界的形状可以是曲线,也可以是直线
答: A。分类边界的每一段都是与坐标轴平行的,这样的分类边界使得学习结果有较好的解释性,因为每一段的划分都直接对应了某个属性的取值。
10.决策数模型如果过拟合,可以剪枝。线性回归过拟合可以加入正则项,那为什么加入正则项可以有效防止过拟合?
答:过拟合的时候,拟合函数的系数往往非常大,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
如图:

11. 如何对决策树进行预剪枝?
答: 预剪枝是要对划分前后的泛化性能进行评估,对比决策树某节点生成前与生成后的泛化性能。
12.决策树需要进行归一化处理吗?
答:不需要
13.下面回归模型中的哪个步骤最能影响过拟合和欠拟合之间的平衡因素:
A. 多项式的阶数
B. 是否通过矩阵求逆或梯度下降学习权重
C.使用常数项
答: A
14. 关于MLE(最大似然估计),下面哪一项或者几项的说法是正确的?
1 MLE可能不存在
2 MLE总是存在
3 如果MLE存在,可能不是唯一的
4 如果MLE存在,肯定是唯一的
答:1、3。如果极大似然函数 L(θ) 在极大值处不连续,一阶导数不存在,则 MLE 不存在,另一种情况是 MLE 并不唯一,极大值对应两个 θ。
15.常见的激活函数有那些?写出其公式并画出函数曲线。
答:

16…画出三层神经网络的结构图。
答:

17.如何避免局部最优?
答:1.以不同的参数值初始化多个神经网络,取最小的作为结果。
2.使用“模拟退火”技术。“模拟退火”在每一步都会以一定的概率接受比当前更差的结果,从而有助于“跳出”局部最小,在每一步的迭代的过程中,接受“次优解”的概率要随着时间的推移而不断的降低.
3. 使用“随机梯度下降”
18.简述一个完整机器学习项目的流程。
答:a.抽象为数学问题;
b.获取数据;
c.数据预处理与特诊选择;
d.训练模型与调优;
e.模型诊断;
f.模型融合;
g.上线运行。
19.什么是前馈神经网络?
答:当输入特征时,神经网络会进行前向传播计算输出值,通过逐层的计算,得到网络最后的输出。
20.分类问题选择什么激活函数,原因是?
答:sigmoid、softmax。sigmoid多用于二分类中,它可以将输入样本转化为0-1之间的数,即该样本的概率,当该概率大于设定的阈值时,归为一类,否则归为另一类。softmax又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。概率最大项就是所归的类。
21.回归问题选择什么激活函数,原因是?
答:回归问题的最后一层不需要激活函数,中间层可以用sigmoid、tanh、relu等等,根据自己的需要选择适合的激活函数。
22.池化是什么,有几类池化,分别解释各个池化的过程。
答:池化操作通常也叫做子采样(Subsampling)或降采样(Downsampling),在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。
常见池化方式有最大池化、平均池化、随机池化等等。
最大池化就是选择图像区域中最大值作为该区域池化以后的值,反向传播的时候,梯度通过前向传播过程的最大值反向传播,其他位置梯度为0;平均池化就是将选择的图像区域中的平均值作为该区域池化以后的值;随机池化,特征区域的大小越大,代表其被选择的概率越高。
23…参数和超参数的区别是什么?
答:模型参数是模型内部的配置变量,可以用数据估计模型参数的值;模型超参数是模型外部的配置,必须手动设置参数的值。
24.有几种策略缓解BP网络过拟合?分别是?
答:a.增加L1正则和L2正则
b.增加训练样本数目
c.减少模型的参数个数
d.将训练方法改为trainbr(trainbr训练方法是改变了性能函数,其他方法的性能函数基本上是以训练样本误差方差,而trainbr训练方法则在其中加入了权值方值的和,此项是为了减少有效权值的个数。
25.为什么在机器学习中引入激活函数,例如在房价预测中加入激活函数?
答:以放假预测为例,将线性的数值非线性化,可以更加贴合实际数据。
26.用于识别猫的图像是“结构化”数据的一个例子,因为它在计算机中被表示为结构化矩阵,这句话对吗?为什么?
答:不是,图片是非结构化数据。
27.评价一个模型的好坏一般用什么来评价?
答:评价分类结果:精准度、混淆矩阵、精准率、召回率、F1 Score、ROC曲线,AUC值等;评价回归结果:MSE、RMSE、MAE、R Squared,调整 R Squared。
28.梯度下降法是什么?
答:梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。















 5183
5183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









