






1.当数据有缺失值的时候, 你认为处理缺失值比较合理的方法(缺失值举例:泰坦尼克号幸存者数据中 有年龄 性别 职业 是否存活 四个特征 但某些样本的职业特征为空)。
- 若数据的缺失值太多,去掉其对应类别进行处理
- 其他情况:
(1)均值,极值,众数,中位数填补
(2)回归决策树预测,把label作为特征也加入到特征里来
2.请简述随机梯度下降,批梯度下降的区别和各自的优点
- (1)随机梯度下降就是计算一个样本的loss之后就进行梯度下降
a)优点:迭代速度快,可以跳出局部最小(因为震荡大)
b)缺点:收敛速度慢(因为震荡大) - (2)批梯度下降就是一批样本计算loss求均值后再反向传播(批用英文 batch表示)数值常常取2的n次方如2,4,8,16,32,64等。。。
a)优点:收敛快,震荡小
b)缺点:迭代速度慢,
3.线性判别分析(LDA)中,我们想要最优化的两个数值是什么(聚类算法也是以这两个数据为目标进行优化)
- 类内距离和类间距离
4.类别不平衡问题会带来什么影响,如何有效处理类别不平衡的问题。
- 更改损失函数,对少数项的惩罚力度加大
- 下采样,上采样
- Label smoothing
5.什么是k折交叉验证
- 将数据分为k组,每次从训练集中,抽取出k份中的一份数据作为验证集,剩余数据作为测试集。测试结果采用k组数据的平均值。
6.请写出交叉熵损失函数(CrossEntropyLoss)
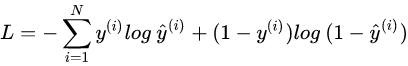
7.我们知道信息量的多少由信息的不确定性来衡量,信息量越大,信息的不确定性越大,信息熵的值越大。信息量越少,信息的不确定性越小,信息熵的值越小。请写出信息熵的公式。注:设集合D中第k类样本所占的比例为Pk(k=1,2,3,……,m)。

8.写出你知道的决策树算法
- ID3
- C4.5
- CART
9.单变量决策树的分类边界是什么样的: A
A.分类边界的每一段都是与坐标轴平行的
B.分类边界的每一段都是可以弯曲的曲线
C.分类边界的每一段都是倾斜的直线
D.分类边界的形状可以是曲线,也可以是直线
若我们把每个属性视为坐标空间中的一个坐标轴,则 d 个属性
描述的样本就对应了 d 维空间中的一个数据点,对样本分类则
意味着在这个坐标空间中寻找不同类样本之间的分类边界,决
策树所形成的决策边界有一个明显的特点:
轴平行(axis-parallel),
即它的分类边界由若干个与坐标轴平行的分段组成。
10.决策树模型如果过拟合,可以剪枝。线性归回过拟合可以加入正则项,那么为什么加入正则项可以有效防止过拟合
-
使模型变简单,向高偏差方向移动 可以看这个视频
https://www.bilibili.com/video/BV1V441127zE?p=5 -
正则化方法 L1正则化 L2正则化 (L1正则化还可以用于特征选择, 因为会使得矩阵变得稀疏) L2正则化也叫权值递减 会让权重变小
11.如何对决策树进行预剪枝(只需要回答预剪枝)
- 在决策数生成过程中对每个节点在划分前先进行估计,若当前节点的划分不能带来决策数泛化性能的提升,则停止划分并将当前节点标记为叶节点
12.决策树需要进行归一化处理吗
- 不需要
13.下面回归模型中的哪个步骤/假设最能影响过拟合和欠拟合之间的平衡因素: A
A. 多项式的阶数
B. 是否通过矩阵求逆或梯度下降学习权重
C.使用常数项
- 关于MLE(最大似然估计),下面哪一项或几项说法是正确的 (1,3)
1 MLE可能不存在
2 MLE总是存在
3 如果MLE存在,可能不是唯一的
4 如果MLE存在,肯定是唯一的
如果极大似然函数 L(θ) 在极大值处不连续,一阶导数不存在,则 MLE 不存在,如下图所示:

另一种情况是 MLE 并不唯一,极大值对应两个 θ。如下图所示:

16.常见的激活函数有那些?写出其公式并画出函数曲线
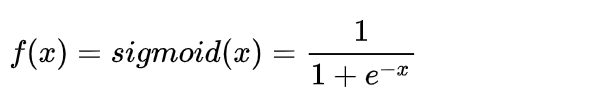

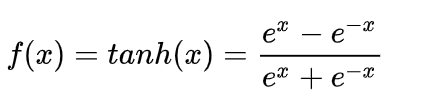



可看: https://zhuanlan.zhihu.com/p/122267172.
17.画出三层神经网络的结构图。
 18.如何避免局部最优。
18.如何避免局部最优。
-
使用随机梯度下降代替真正的梯度下降。可以这样理解,每次针对单个数据样例进行摸索前进时,本质上是在一个样例形成的误差曲面上摸索前进,而每个样例的曲面大体类似,又不尽相同,当你掉入一个坑里时,往往能被别的曲面拽出来。
-
设置冲量。人如其名,本次前进的步伐,根据上一次的步伐,适当调大,好比从高处降落的石头,会更有机率跨过一些小坑,如果坑非常大,依靠冲量的惯性是没法逃出的。
-
不同的初始权值进行训练。假定误差曲面是个坑坑洼洼的曲面,我们尝试第一次降落到随机的起点,然后再开始摸索前进,也许会有运气好的一次,能够不落在某个小坑附近,多次尝试权重,可能会找到好的全局点。
19.一个完整机器学习项目的流程。
1 抽象成数学问题
明确问题是进行机器学习的第一步。机器学习的训练过程通常都是一件非常耗时的事情,胡乱尝试时间成本是非常高的。
这里的抽象成数学问题,指的我们明确我们可以获得什么样的数据,目标是一个分类还是回归或者是聚类的问题,如果都不是的话,如果划归为其中的某类问题。
2 获取数据
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
数据要有代表性,否则必然会过拟合。
而且对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。
而且还要对数据的量级有一个评估,多少个样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。如果数据量实在太大,那就要考虑分布式了。
3 特征预处理与特征选择
良好的数据要能够提取出良好的特征才能真正发挥效力。
特征预处理、数据清洗是很关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。这些工作简单可复制,收益稳定可预期,是机器学习的基础必备步骤。
筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
4 训练模型与调优
直到这一步才用到我们上面说的算法进行训练。现在很多算法都能够封装成黑盒供人使用。但是真正考验水平的是调整这些算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。
5 模型诊断
如何确定模型调优的方向与思路呢?这就需要对模型进行诊断的技术。
过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。
误差分析 也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题……
诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试, 进而达到最优状态。
6 模型融合
一般来说,模型融合后都能使得效果有一定提升。而且效果很好。
工程上,主要提升算法准确度的方法是分别在模型的前端(特征清洗和预处理,不同的采样模式)与后端(模型融合)上下功夫。因为他们比较标准可复制,效果比较稳定。而直接调参的工作不会很多,毕竟大量数据训练起来太慢了,而且效果难以保证。
7 上线运行
这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。 不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。
这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。
20.什么是前馈神经网络
深度神经网络,简单来理解就是含有多个隐藏层的网络。一个深度神经网络总会有一个输入层,一个输出层,还有中间多个隐藏层,隐藏层的维数决定了网络的宽度。无论是输入层、隐藏层还是输出层,每一层都是由多个感知器组成,所以深度神经网络又称多层感知机。
前馈(feedforward)也可以称为前向,从信号流向来理解就是输入信号进入网络后,信号流动是单向的,即信号从前一层流向后一层,一直到输出层,其中任意两层之间的连接并没有反馈(feedback),亦即信号没有从后一层又返回到前一层。如果从输入输出关系来理解,则为当输入信号进入后,输入层之后的每一个层都将前一个层的输出作为输入。
在深度前馈网络中,链式结构也就是层与层之间的连接方式,层数就代表网络深度。如果我们把每一层看作一个函数,那么深度神经网络就是许多不同非线性函数复合而成,这里与之前典型的线性回归和逻辑回归明显的区别开来。比如,第一层函数为f(1),第二层函数为f(2),第三层函数为f(3),那么这个链式结构就可以表示为:f(x)=f(3)(f(2)(f(1)(x))),通过多次复合,实现输入到输出的复杂映射,链的全长也就代表模型深度。这种网络结构比较好搭建,应用也十分广泛,比如在图像识别领域占主导地位的卷积神经网络就是深度前馈网络的一种,学习这种网络,是我们通向循环神经网络的奠基石。
21.分类问题选择什么激活函数,原因是?
由于输出是单一变量,所以激活函数采用sigmoid函数:
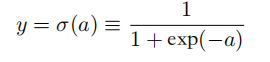
对于多分类问题:
使用“1-of-k”的表示方法表示类别,激活函数采用softmax函数

22.回归问题选择什么激活函数,原因是?
对于回归问题,我们一般假设t服从高斯分布,均值与x有关,即

在这里插入图片描述对于以上条件,我们选择的激活函数是恒等函数即可,因为这样就可以近似任何从X到Y的连续函数。
23.池化是什么,有几类池化,分别解释各个池化的过程。
1.最大/平均池化
最大池化就是选择图像区域中最大值作为该区域池化以后的值,反向传播的时候,梯度通过前向传播过程的最大值反向传播,其他位置梯度为0。
使用的时候,最大池化又分为重叠池化和非重叠池化,比如常见的stride=kernel size的情况属于非重叠池化,如果stride<kernel size 则属于重叠池化。重叠池化相比于非重叠池化不仅可以提升预测精度,同时在一定程度上可以缓解过拟合。
重叠池化一个应用的例子就是yolov3-tiny的backbone最后一层,使用了一个stride=1, kernel size=2的maxpool进行特征的提取。
平均池化就是将选择的图像区域中的平均值作为该区域池化以后的值。
2. 随机池化
Stochastic pooling如下图所示,特征区域的大小越大,代表其被选择的概率越高,比如左下角的本应该是选择7,但是由于引入概率,5也有一定几率被选中。

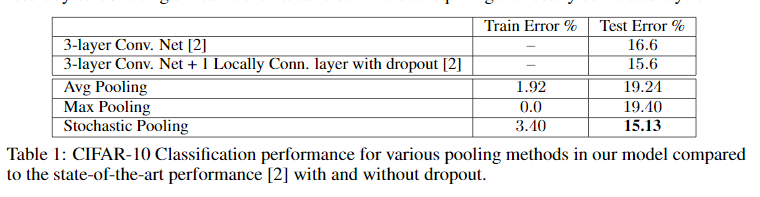
下表是随机池化在CIFAR-10上的表现,可以看出,使用随机池化效果和采用dropout的结果接近,证明了其有一定防止过拟合的作用。
3.中值池化
与中值滤波特别相似,但是用的非常少,中值池化也具有学习边缘和纹理结构的特性,抗噪声能力比较强。
4.组合池化
组合池化则是同时利用最大值池化与均值池化两种的优势而引申的一种池化策略。常见组合策略有两种:Cat与Add。常常被当做分类任务的一个trick,其作用就是丰富特征层,maxpool更关注重要的局部特征,而average pooling更关注全局特征。
更多方法:https://www.cnblogs.com/pprp/p/12456403.html
24.参数和超参数的区别是什么?
-
参数:指根据输入的数据,通过学习过程得到的变量,如网络的权重w和偏置b。
-
超参数:人为地根据经验设定,如学习率、网络层数、网络层节点数、迭代次数等。
25.有几种策略缓解BP网络过拟合?分别是?
- 增加L1正则和L2正则
- 增加训练样本数目
- 减少模型的参数个数
- 将训练方法改为trainbr(trainbr训练方法是改变了性能函数,其他方法的性能函数基本上是以训练样本误差方差,而trainbr训练方法则在其中加入了权值方值的和,此项是为了减少有效权值的个数。像贝叶斯算法是调整性能函数这两部分的比重)
26.为什么在机器学习中引入激活函数,例如在房价预测中加入激活函数
- 如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
- 如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
27用于识别猫的图像是“结构化”数据的一个例子,因为它在计算机中被表示为结构化矩阵,这句话对吗?为什么?
- 不对,猫图像识别的数据是典型的非结构化数据,常见的非结构化数据还有文本,图像,视频等
28.评价一个模型的好坏一般用什么来评价?
- 回归问题的评估指标
SSE 和方差
均方误差(MSE)
均方根误差(RMSE)
R Squared - 分类问题的评估指标
错误率
召回率(查全率)
精确率(查准率)
混淆矩阵和分类报告
P-R曲线
准确率
f1分值
什么时候关注召回率,什么时候关注精确率
详见:https://blog.csdn.net/qq_42363032/article/details/110449592
29.梯度下降法是什么?
梯度下降是通过迭代搜索一个函数极小值的优化算法。使用梯度下降,寻找一个函数的局部极小值的过程起始于一个随机点,并向该函数在当前点梯度(或近似梯度)的反方向移动。
在线性和对数几率回归中,梯度下降可以用于搜索最优参数。至于SVM和神经网络,我们之后才考虑。在很多模型中,比如对率回归或者SVM,优化标准是凸形的。凸形函数只有一个极小值,即全局最小值。相比之下,神经网络中的优化标准是非凸形的。不过,即使只找到局部最小值,在很多实际问题中也足够了。
详见:博客















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









