







1、LeNet神经网络结构实现CIFAR10图片分类参考:
CIFAR10模型训练任务_weixin_51431157的博客-CSDN博客
2、VGG16网络结构参考:
经典网络(LeNet-5、AlexNet、VGGNet)_weixin_51431157的博客-CSDN博客
LeNet神经网络实现CIFAR10图片分类效果较差,故将网络结构换成VGG16看看效果。
3、使用VGG16
更换model.py文件里的内容(1中博客的model),将Links改为VGG16
更换后的model
初步结构:
import torch
from torch import nn
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), #输入图片为3*32*32 same卷积,增加通道数,输出64*32*32
nn.Conv2d(64,64,3,1,1),
nn.MaxPool2d(kernel_size=2,stride=2) #输出64*16*16
)
self.layer2 = nn.Sequential(
nn.Conv2d(64,128,3,1,1), #输出128*16*16
nn.Conv2d(128,128,3,1,1),
nn.MaxPool2d(2,2) #输出128*8*8
)
self.layer3 = nn.Sequential(
nn.Conv2d(128,256,3,1,1), #输出256*8*8
nn.Conv2d(256,256,3,1,1),
nn.Conv2d(256,256,3,1,1),
nn.MaxPool2d(2,2) #输出256*4*4
)
self.layer4 = nn.Sequential(
nn.Conv2d(256,512,3,1,1), #输出512*4*4
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2) #输出512*2*2
)
self.layer5 = nn.Sequential(
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.Conv2d(512,512,3,1,1),
nn.MaxPool2d(2,2) #输出512*1*1
)
self.fc = nn.Sequential(
nn.Flatten(), #输出512*1*1
nn.Linear(in_features=512,out_features=512),
nn.Linear(512,256),
nn.Linear(256,10)
)
self.model = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5,
self.fc
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
lk = VGG16()
input = torch.ones((64,3,32,32)) #batchsize:64 in_channels:3 高度:32 宽度:32
output = lk(input)
print('output.shape = ',output.shape)
为了防止在梯度下降过程中出现梯度消失或爆炸,还需在每一层卷积后使用归一化处理batchnorm,也可防止过拟合,全连接层和线性层后使用dropout随机失活防止过拟合;此外还需加上非线性激活函数Relu。
更改后的model:
import torch
from torch import nn
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), #输入图片为3*32*32 same卷积,增加通道数,输出64*32*32
nn.BatchNorm2d(num_features=64), #强行将数据拉回到均值为0,方差为1的正态分布上;一方面使得数据分布一致,另一方面避免梯度消失。
nn.ReLU(),
nn.Conv2d(64,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2) #输出64*16*16
)
self.layer2 = nn.Sequential(
nn.Conv2d(64,128,3,1,1), #输出128*16*16
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,128,3,1,1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2,2) #输出128*8*8
)
self.layer3 = nn.Sequential(
nn.Conv2d(128,256,3,1,1), #输出256*8*8
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,256,3,1,1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,256,3,1,1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2,2) #输出256*4*4
)
self.layer4 = nn.Sequential(
nn.Conv2d(256,512,3,1,1), #输出512*4*4
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,1,1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,1,1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2,2) #输出512*2*2
)
self.layer5 = nn.Sequential(
nn.Conv2d(512, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2,2) #输出512*1*1
)
self.fc = nn.Sequential(
nn.Flatten(), #输出512*1*1
nn.Linear(in_features=512,out_features=512),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(512,256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256,10),
)
self.model = nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5,
self.fc
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
lk = VGG16()
input = torch.ones((64,3,32,32)) #batchsize:64 in_channels:3 高度:32 宽度:32
output = lk(input)
print('output.shape = ',output.shape)
完整代码:
import numpy as np
import torch.optim
import torchvision
import matplotlib.pyplot as plt
from torch import nn
from torch.utils.data import DataLoader
from torch.utils import tensorboard
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("../logs_train")
from VGG16 import *
#from model import *
# 增强数据集transforms
train_dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32,padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
#准备训练数据集
train_data = torchvision.datasets.CIFAR10(root='../data',train=True,transform=train_dataset_transform
,download=True)
#准备测试数据集
test_data = torchvision.datasets.CIFAR10(root='../data',train=False,transform=test_dataset_transform
,download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('训练集的大小为{} \n测试集的大小为{}'.format(train_data_size,test_data_size))
#利用Dataloader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# # 查看图像大小
# for data in train_dataloader:
# imgs, targets = data
# print(imgs[0].shape)
# break
#创建网络模型
#lk = Links()
lk = VGG16()
lk = lk.cuda()
#损失函数
#loss_fn = nn.MSELoss() #交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
#优化器
learning_rate = 0.01
optimizer = torch.optim.Adam(params=lk.parameters(),lr=learning_rate,betas=(0.9,0.999),eps=1e-08,weight_decay=0)
#optimizer = torch.optim.SGD(lk.parameters(),lr = learning_rate) #随机梯度下降
#设置学习率衰减
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda epoch:1/(epoch+1))
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 30
for i in range(epoch):
print('-----------第{}轮训练开始-----------'.format(i+1)) #因为batch_size大小为64,50000/64=781.25,故每训练781次就会经过一轮epoch
#训练步骤开始
lk.train() #设置模型进入训练状态,仅对dropout,batchnorm...等有作用,如果有就要调用这里模型暂时没有可不调用
for data in train_dataloader: #train_dataloader的batch_size为64,从训练的train_dataloader中取数据
imgs , targets = data #
imgs = imgs.cuda()
targets = targets.cuda()
outputs = lk(imgs) #将img放入神经网络中进行训练
loss = loss_fn(outputs,targets) #计算预测值与真实值之间的损失
#优化器优化模型
optimizer.zero_grad() #运行前梯度清零
loss.backward() #反向传播
optimizer.step() #随机梯度下降更新参数
total_train_step = total_train_step + 1 #训练次数加一
if total_train_step % 100 == 0:
print('训练次数:{},Loss:{}'.format(total_train_step,loss.item())) #.item()的作用是输出数字,与训练次数格式相同
writer.add_scalar('train_loss',loss.item(),total_train_step)
#测试步骤开始
lk.eval() #设置模型进入验证状态,仅对dropout,batchnorm...等有作用,如果有就要调用这里模型暂时没有可不调用
total_test_loss = 0
total_test_accuracy = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = lk(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item() #所有loss的加和,由于total_test_loss是数字,而loss是Tensor数据类型,故加.item()
accuracy = (outputs.argmax(dim=1) == targets).sum() #输出每次预测正确的个数
total_accuracy = total_accuracy + accuracy #测试集上10000个数据的正确个数总和
print('整体测试集上的loss:{}'.format(total_test_loss))
print('整体测试集上的正确率:{}'.format(total_accuracy / test_data_size))
writer.add_scalar('test_loss',total_test_loss,total_test_step)
writer.add_scalar('test_accuracy',total_accuracy / test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(lk,'lk_{}.pth'.format(i))
print('模型已保存')
scheduler.step()
writer.close()
比起原代码多了数据增强的步骤(transform)
运行结果(由于运行时间较久,这里仅设置epoch为30,最后第三十轮的测试集正确率达到70%,且有继续提升的趋势,相信提高epoch轮次可获得更高的正确率):
-----------第30轮训练开始-----------
训练次数:22700,Loss:0.9906561970710754
训练次数:22800,Loss:0.8402963280677795
训练次数:22900,Loss:0.839271605014801
训练次数:23000,Loss:0.7975962162017822
训练次数:23100,Loss:0.8357958197593689
训练次数:23200,Loss:0.838142454624176
训练次数:23300,Loss:1.118470311164856
训练次数:23400,Loss:0.7780863046646118
整体测试集上的loss:133.92985653877258
整体测试集上的正确率:0.703000009059906
模型已保存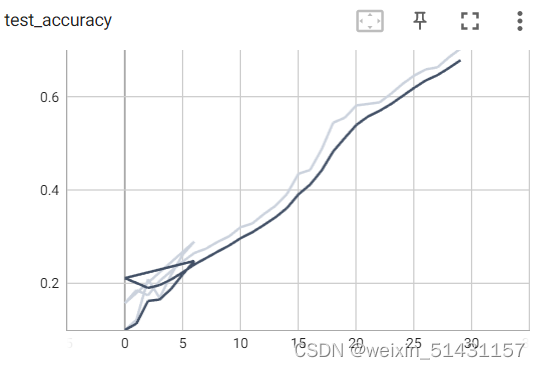
由tensorboard中的曲线趋势可见,提高epoch轮次,正确率还可进一步提升。
但由于VGG网络层数较多,且使用的是Relu激活函数,后期可能会出现训练退化现象(训练到后面效果会变差),故对于层数较多的网络需采用残差结构。














 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









