






初学语义分割,由于Unet是2015年发布,距今已有八年,以现在的视角看,难免存在许多缺陷。
一、学习网络结构
原论文Unet网络结构图:
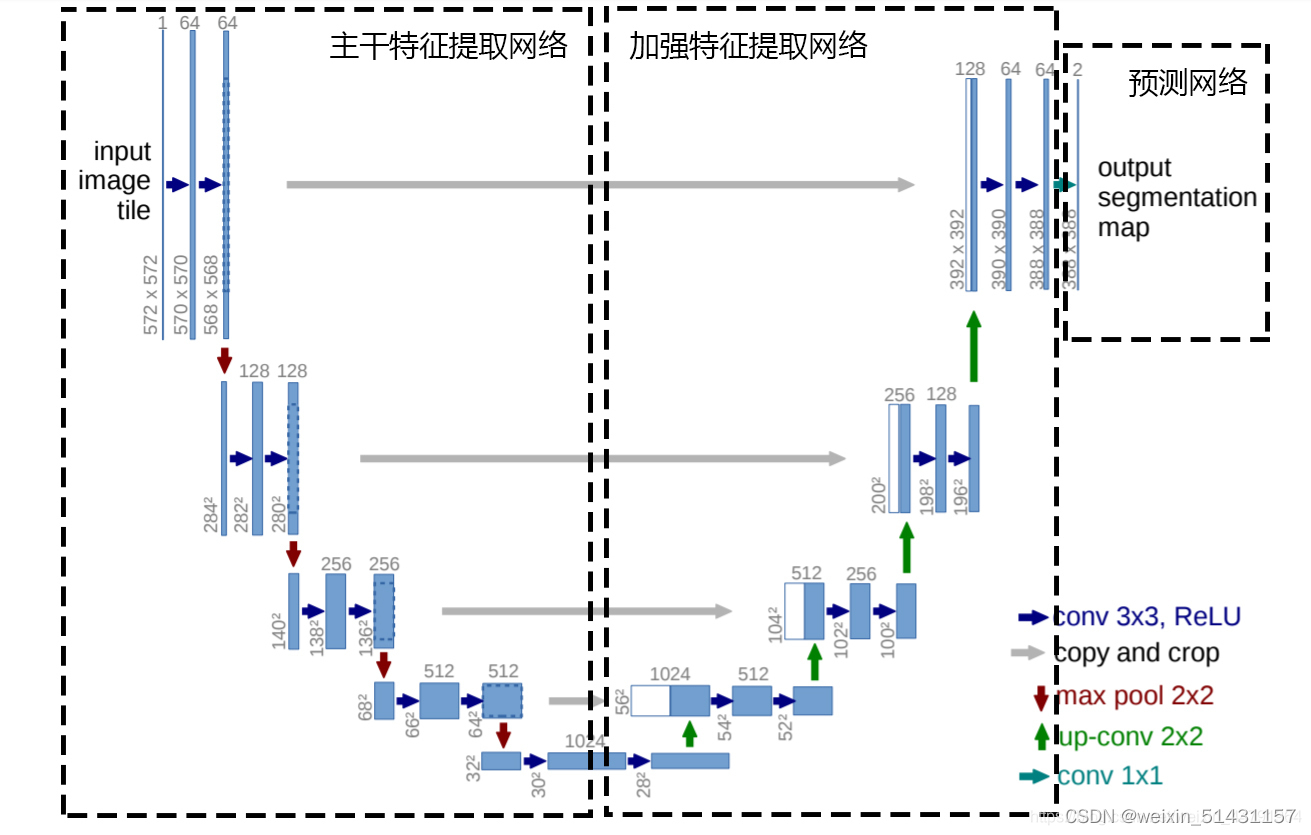
可注意到:
1、该结构输入与输出大小不同。
2、没有使用BN层,其中conv3x3的卷积层使用的是步长s=1,padding=0,每一次卷积都会减小大小为2的高度和宽度。
现在很多使用VGG16来代替这个主干特征提取网络,加强特征提取网络部分结构基本不变,仅仅是把copy and crop(裁剪和拼接)部分改为contact(拼接)。

其与原Unet类似,相比之下没有了部分缺点,3x3的卷积采用了步长为1,padding=1,如此一来便不会改变输入输出的大小,且在加强特征提取网络阶段不需要裁剪可直接与相同空间维度的特征层进行拼接操作,不至于丢失部分信息。
二、训练:
使用的数据集是VOC2007的数据集(20类),仅使用部分(六百多张图片)数据集进行训练,预训练权重使用unet_vgg_voc.pth。训练轮数100轮(由于是使用colab服务器训练,训练了1.5小时中断,最终训练轮数为90epoch),以下是训练结果:
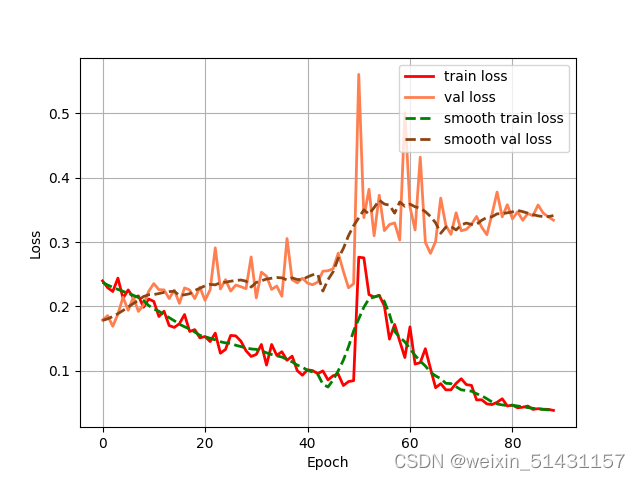
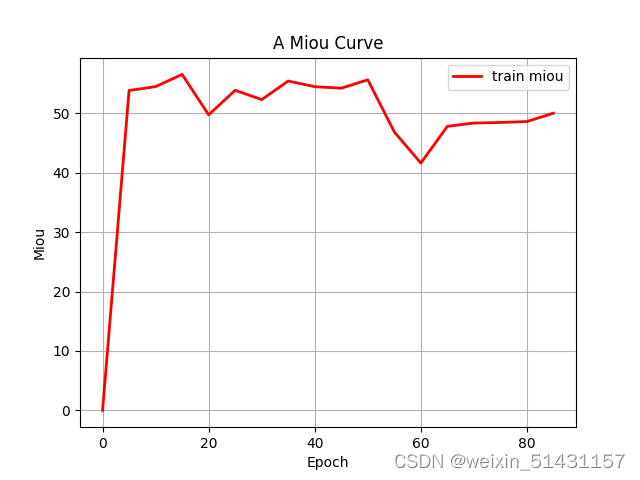
最好的一轮的训练结果:

分析:训练损失train loss总体趋于下降趋势,最低至0.038,但是验证损失val loss确是逐渐升高,最高可至0.334。
原因分析:可能是网络有一定深度,且数据集较少,导致发生了过拟合现象。
解决方法:为了防止发生过拟合,使用Resnet残差网络能有效解决此类问题。
三、预测:
使用训练结果最好的一轮权重进行预测。
















 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









