







1.4 数据标注(labelling)
-
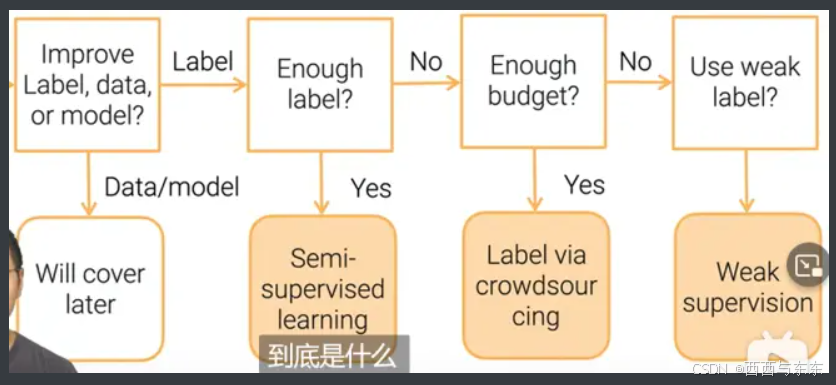 提升标注?数据质量?还是模型?
提升标注?数据质量?还是模型? -
是否有足够的标注?半监督学习
-
足够预算?众包,大家帮你标数据
-
弱监督学习
1.半监督学习 (Semi-Supervised Learning)
> 主要解决数据仅有一小部分有标注,其他大部分数据没有标注
> 为了使用未标注的数据,对数据分布做了以下假设:
> 连续性假设(Continuity assumption):相同特征的样本对应的标注也应该相同
> 聚类假设(Cluster assumption):数据一般会有内部的聚类结构,在同一个类的数据也应该有相同的标签
> 流形假设(Manifold assumption) :虽然一般收集的数据的维度都比较高(维度的值对应数据的特征数),但是实际上数据是分布在维度更低的流形空间。根据该假设,说明可以通过降维方法来得到更干净的数据
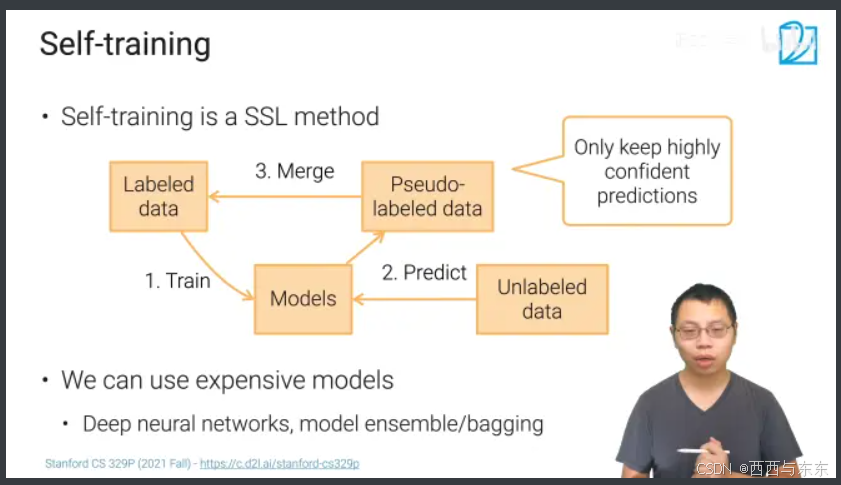
> 自学习算法(self-training)
> 算法步骤:
1.使用一小部分的有标注数据训练一个模型
2.用上一步训练好的模型预测未有标注数据的标签,这些标签称为伪标签(一般做法:这里仅仅留下模型比较确信的伪标签的数据keep highly confident predictions)
3.将上一步预测的伪标签的数据和原有标注数据进行合并形成一个更大的有标注的数据
4.使用上一步得到的更大的数据集再重新训练模型
5.以上4步重复迭代
 2.主动学习(Active Learning)
2.主动学习(Active Learning)
> 主要解决的问题是把所有的数据都给数据标注工标记的成本过高,可以使用模型将其中模型无法准确预测的未标注数据传给数据标注工,从而减少成本
> 与半监督学习场景很类似,但是主动学习过程中有人的干预,主动学习会将最有意思(most interesting)的未标注数据传给数据标注元进行标注
> 如何选择最有意思的未标注数据呢?
> Uncertainty sampling:与半监督学习算法的第二步正好相反,选择的是模型特别不确信的伪标签数据,然后将这些数据传给数据标注工进行标注
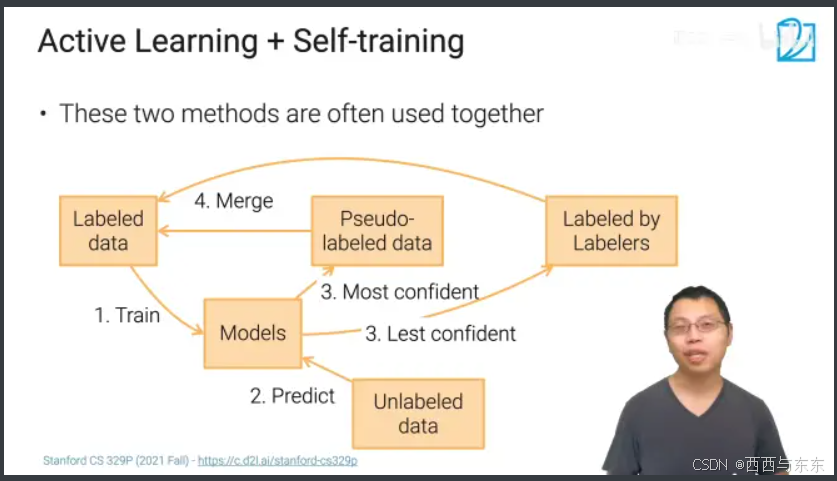
 3.主动学习+半监督学习(Active Learning + Self-training)
3.主动学习+半监督学习(Active Learning + Self-training)
> 常混合以上两种方法来标注数据集中大量的未标注数据
1.使用有标注的数据来训练模型
2.使用训练好的模型来预测数据集中的未标注数据的标签(伪标签),其中模型很确信的未标注数据与原有标注的数据合并(半监督学习),模型很不确信的未标注数据传给数据标注工标注(主动学习),标注后的数据与原有标注数据合并
3.使用合并后的有标注数据再训练模型
4.以上3步重复迭代,直至数据集中的所有数据都已标注
 4.弱监督学习(Weak Supervision)
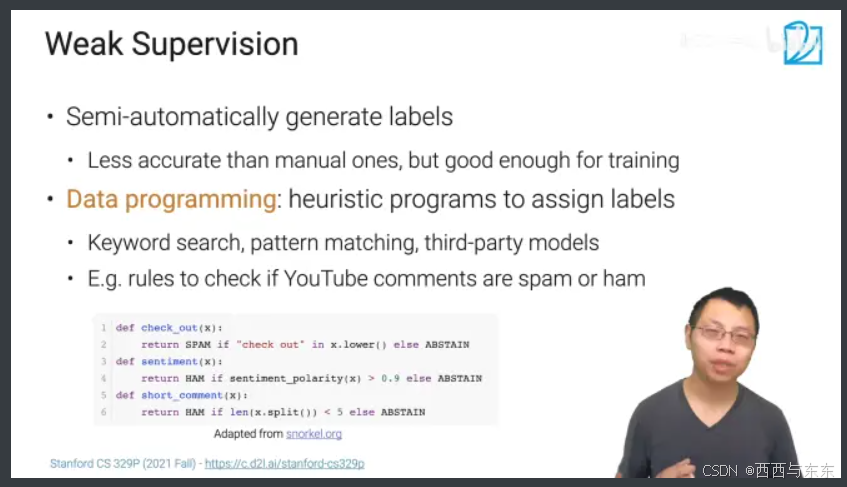
4.弱监督学习(Weak Supervision)
> 半自动地生成标注:标注的正确率比人工标注低一点,但是也足够训练一个不错的模型
> Data programming(数据编程):启发式编程来进行标注
例如:判断Youtube的评论是垃圾还是正常评论?
> 可以设置一些判断语句(规则),如果评论的词数≤5,那么是正常评论;如果评论中含有“check out",那么为垃圾评论,等等一些规则来进行标注
 5.小结
5.小结



















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











